Как я, в итоге, написал новую RTOS, протестированную и стабильную
Я работаю со встраиваемыми системами в течение нескольких лет: наша компания разрабатывает и производит бортовые компьютеры для автомобилей, зарядные устройства, и т.д.

Процессоры, используемые в наших продуктах — это, в основном, 16- и 32-битные микроконтроллеры Microchip, имеющие RAM от 8 до 32 кБ, и ROM от 128 до 512 кБ, без MMU. Иногда, для самых простых устройств, используются еще более скромные 8-битные чипы.
Очевидно, что у нас нет (разумных) шансов использовать ядро Linux. Так что нам нужна какая-нибудь RTOS (Real-Time Operating System). Находятся даже люди, которые не используют никаких ОС в микроконтроллерах, но я не считаю это хорошей практикой: если железо позволяет мне использовать ОС, я ее использую.
Несколько лет назад, когда мы переходили с 8-битников на более мощные 16-битные микроконтроллеры, мои коллеги, которые были гораздо более опытными, чем я, рекомендовали вытесняющюю RTOS TNKernel. Так что это — та ОС, которую я использовал в разных проектах в течение пары лет.
Не то, чтобы я был очень доволен ею: например, в ней нет таймеров. И она не позволяет потоку ждать сообщения сразу из нескольких очередей. И в ней нет программного контроля переполнения стека (это действительно напрягало). Но она работала, так что я подолжал ее использовать.
Просто чтобы убедиться, что мы с вами понимаем друг друга, я сделаю краткий обзор того, как работает вытесняющая ОС в принципе. Я извиняюсь, если вещи, которые я здесь излагаю, слишком тривиальны для читателя.
Запуск нескольких потоков
Микроконтроллеры «однопоточны»: они могут выполнять только одну инструкцию в каждый момент времени (конечно, существуют многоядерные процессоры, но сейчас речь не об этом). Чтобы запустить несколько потоков на одноядерном процессоре, нам нужно переключаться между потоками, так что пользователю кажется, что они выполняются параллельно.
Это — то, для чего нужна ОС в первую очередь: она переключает управление между потоками. Как именно она это делает?
Микроконтроллер имеет набор регистров. Т.к. микроконтроллеры однопоточны, этот набор регистров принадлежит только одному потоку. Например, когда мы находим сумму двух чисел:
//-- assume we have two ints: a and b
int c = a + b;
На самом деле происходит что-то вроде следующего (конечно, конкретная последовательность действий зависит от архитектуры, но в целом идея остается той же):
# the MIPS disassembly:
LW V0, -32744(GP) # загружаем значение переменной a из RAM в регистр V0
LW V1, -32740(GP) # загружаем значение переменной b из RAM в регистр V1
ADDU V0, V1, V0 # значения регистров V1 и V0 суммируются, результат сохраняется в V0
SW V0, -32496(GP) # сохраняем значение регистра V0 в RAM (по адресу переменной c)
Тут 4 действия. Т.к. в вытесняющей ОС один поток может вытеснить другой поток в любой момент времени, то, конечно, это может произойти в середине этой последовательности. Представим, что другой поток вытесняет текущий после того, как в регистры V0 и V1 были загружены значения для суммирования. У нового потока есть свои дела и, следовательно, он использует эти регистры так, как ему нужно. Конечно, два потока не должны мешать друг другу, так что, когда первый поток опять получает управление, значения регистров V0 и V1 (и других) должны быть такими, какими они были до вытеснения.
Значит, когда мы переключаемся с потока A на поток B, в первую очередь мы должны куда-нибудь сохранить значения всех регистров потока А, затем восстановить значения всех регистров потока В. И только тогда поток В получает управление, и продолжает работать.
Так что более точная диаграмма переключения потоков будет выглядеть так:
Когда нужно переключиться с одного потока на другой, ядро получает управление, производит необходимые служебные действия (как минимум, сохраняет и восстанавливает значения регистров), и затем управление передается следующему потоку.
Куда именно сохраняются значения регистров для каждого потока? Очень часто, это — стек потока.
Стек потока
В современных ОС, (пользовательский) стек растет динамически благодаря MMU: чем больше потоку нужно, тем больше он получает (если ядро ему разрешит). Но микроконтроллеры, с которыми я работаю, не имеют подобной роскоши: вся RAM отображена на адресное пространство статически. Так что каждый поток получает свою некоторую часть RAM, которая используется под стек; и если поток использует больше стека, чем ему было выделено, то это приводит к порче памяти и, следовательно, к некорректной работе. Фактически, пространство стека для каждого потока — это просто массив байт.
Когда мы решаем, сколько стека нужно каждому конкретному потоку, сначала мы просто прикидываем, сколько ему может понадобиться, и берем с некоторым запасом. Например, если это поток GUI с глубокой вложенностью, он может требовать несколько килобайт, но если это небольшой поток, обрабатывающий ввод пользователя, то нескольких сотен байт может быть достаточно.
Давайте предположим, что у нас есть три потока, и их потребление стека выглядит следующим образом:
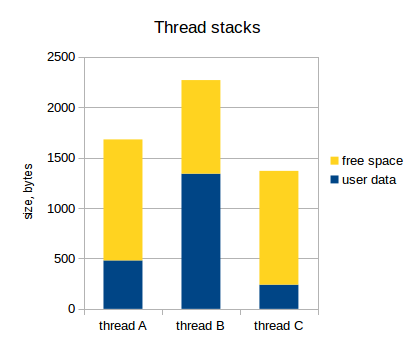
Как я уже указал, набор значений регистров для каждого потока сохраняются в стек этого потока. Этот набор значений регистров называют контекст потока. Следующая диаграмма отражает это (активный поток обозначен звездочкой):
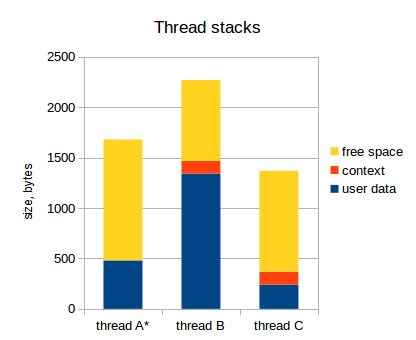
Заметьте, что у активного потока (thread A) контекст не сохранен в стек. Указатель стека в микроконтроллере указывает на вершину пользовательских данных потока А, и весь набор регистров микроконтроллера принадлежит потоку А (на самом деле, могут быть еще специальные регистры, не относящиеся к потоку, но это нас сейчас не интересует).
Когда ядро решает, что нужно переключить управление с потока А на поток В, оно делает следующее:
- Сохраняет значения всех регистров в стек (то есть, в стек потока А);
- Переключает указатель стека на вершину стека потока В;
- Восстанавливает значения всех регистров из стека (то есть, из стека потока В).
После этого, имеем следующее:

И поток В продолжает заниматься своими делами.
Прерывания
Мы пока не затрагивали очень важную тему: прерывания.
Прерывание — это когда выполняемый в данный момент поток приостанавливается (чаще всего, по причине внешнего события), процессор на какое-то время переключается на что-то другое (на обработку прерывания), и потом возвращается к прерванному потоку. Прерывание может быть сгенерировано в любой момент времени, и мы должны быть к этому готовы.
Микроконтроллеры, использующиеся для встраиваемых систем, обычно имеют достаточно много периферии: таймеры, приемо-передатчики (UART, SPI, CAN, и т.д.), АЦП, и т.д. Эта периферия может генерировать прерывания, когда наступает определенное событие: например, периферия UART может генерировать прерывание, когда принят новый байт, так что программа может сохранить его куда-нибудь. Таймеры генерируют прерывание по переполнению, так что программа может использовать это для каких-то периодических задач, и т.д.
Обработчик прерывания называют ISR (Interrupt Service Routine).
Прерывания могут иметь разные приоритеты: например, когда генерируется какое-то низкоприоритетное прерывание, выполняемый поток приостанавливается, и ISR получает управление. Теперь, если будет сгенерировано высокоприоритетное прерывание, то текущий ISR, опять же, приостанавливается, и ISR нового прерывания получает управление. Очевидно, когда он завершается, то первый ISR продолжает свою работу, и когда он тоже завершается, то, в итоге, управление передается обратно к прерванному потоку.
Есть короткие периоды времени, когда прерывания недопустимы: например, если мы обрабатываем какие-то данные, которые могут измениться в ISR. Если мы обрабатываем эти данные в несколько шагов, то прерывание может произойти в середине обработки и изменить данные. В итоге, поток обработает нецелостные данные, что приводит к некорректной работе программы.
Эти короткие периоды времени называют «критическими секциями»: когда мы входим в критическую секцию, мы запрещаем прерывания, и когда мы выходим из нее, то разрешаем прерывания обратно. То есть, если какое-то прерывание сгенерировано внутри критической секции, то ISR будет вызван только в момент выхода из нее (когда прерывания будут разрешены).
Очень интересный вопрос: куда сохранять стек ISR?
Стек прерываний
В целом, у нас есть два варианта:
- Использовать стек потока, который был прерван;
- Использовать отдельный стек для прерываний.
Если мы используем стек прерванного потока, это выглядит следующим образом (в диаграмме ниже, поток В прерван):
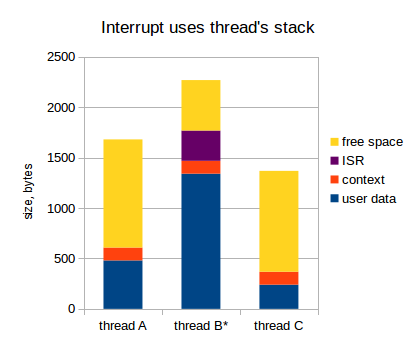
Когда прерывание сгенерировано:
- Контекст текущего потока сохраняется в стек потока (так что, когда ISR завершается, мы можем сразу переключиться на другой поток);
- ISR делает свои дела (обрабатывает прерывание);
- Если нужно переключиться на другой поток, переключаемся (как минимум, модифицируем указатель стека);
- Контекст потока восстанавливается из стека;
- Поток продолжает свою работу.
Это может работать достаточно быстро, но в контексте встраиваемых систем, где наши ресурсы очень ограничены, такой подход обладает существенным недостатком. Догадались, каким именно?
Помните, что прерывание может произойти в любой момент времени, так что, очевидно, мы не можем знать заранее, какой поток будет активен, когда прерывание произойдет. Так что, когда мы прикидываем размер стека для каждого потока, мы должны предположить, что все существующие прерывания могут произойти именно в этом потоке, с учетом их наихудшей вложенности. Это может значительно увеличить размер стеков для всех потоков: на 1 кБ легко, а может и больше (полностью зависит от приложения, конечно). Для примера, если в нашем приложении есть 7 потоков, то требуемый размер RAM для прерываний равен 1 * 7 = 7 кБ. Если наш микроконтроллер имеет только 32 кБ RAM (а это уже богатый микроконтроллер), то 7 кБ это 20%! Oh shi~.
Итого, стек каждого потока должен вмещать в себя следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Данные всех ISR с учетом наихудшей вложенности.
Хорошо, переходим к следующему варианту, когда мы используем отдельный стек для прерываний:
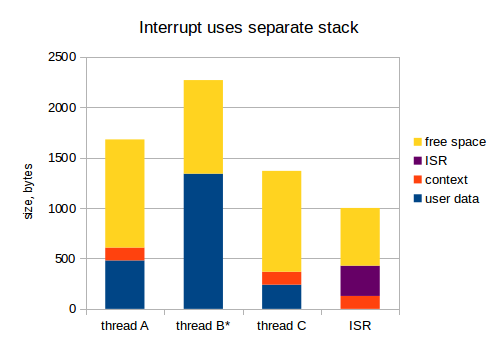
Теперь, 1 кБ для ISR из предыдущего примера должен быть выделен только один раз. Я считаю, что это гораздо более грамотный подход: во встраиваемых системах, RAM — очень дорогой ресурс.
После такого поверхностного обзора принципов работы RTOS, переходим дальше.
Как я указал в начале статьи, мы использовали TNKernel для наших разработок на 16- и 32-битных микроконтроллерах.
К сожалению, автор порта TNKernel для PIC32, Alex Borisov, использовал подход, когда прерывания используют стек прерванного потока. Это тратит кучу RAM впустую и не делает меня очень счастливым, но в остальном TNKernel выглядела хорошо: она компактная и быстрая, так что я продолжал ее использовать. Вплоть до дня X, когда я был очень удивлен, узнав, что на самом деле все гораздо хуже.
Фэйл TNKernel под PIC32
Я работал над очередным проектом: девайс, анализирующий аналоговый сигнал с автомобильной свечи, и позволяющий пользователю посмотреть некоторые параметры этого сигнала: длительности, амплитуды, и т.д. Поскольку сигнал меняется быстро, нам нужно его измерять достаточно часто: раз в 1 или 2 микросекунды.
Для этой задачи был выбран процессор Microchip семейства PIC32 (с ядром MIPS).
Задача не должна быть очень сложной, но в один прекрасный день у меня появились проблемы: иногда, когда устройство начинало измерения, программа падала в совершенно неожиданном месте. «Должно быть, дело в испорченной памяти» — подумал я, и очень расстроился, т.к. процесс поиска ошибок, связанных с порчей памяти, может быть долгим и совсем нетривиальным: как я уже говорил, никакого MMU нет, и вся RAM доступна всем потокам в системе, так что если один из потоков выходит из-под контроля и портит память другого потока, то проблема может проявляться очень далеко от фактического места с ошибкой.
Я уже говорил, что TNKernel не имеет программного контроля переполнения стека, так что, когда есть подозрение на порчу памяти, в первую очередь стоит проверить, не переполнен ли стек какого-нибудь потока. Когда поток создается, его стек инициализируется определенным значением (в TNKernel под PIC32, это просто 0xffffffff), так что мы можем легко посмотреть, «испачкано» ли окончание стека. Я проверил, и действительно, стек потока idle явно переполнен:
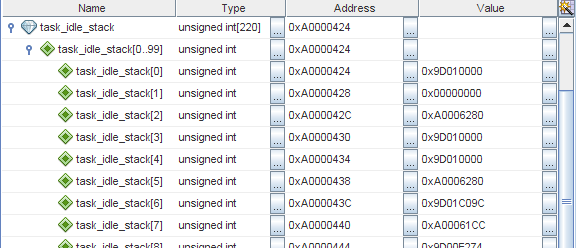
На MIPS, стек растет вниз, так что task_idle_stack[0] — это последнее доступное слово в стеке потока idle.
Хорошо, это уже что-то. Но дело в том, что стек для этого потока был выделен с большим запасом: когда устройство работает нормально, используется только около 300 байт из 880! Должна быть какая-то дикая ошибка, которая так жестко переполняет стек.
Тогда я стал изучать память более тщательно, и стало ясно, что стек был заполнен повторяющимися паттернами. Смотрите: последовательность 0xFFFFFFFF, 0xFFFFFFFA, 0xA0006280, 0xA0005454:
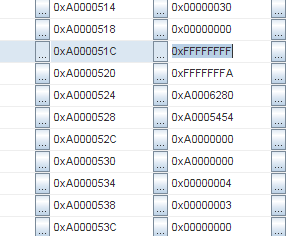
И та же самая последовательность снова:
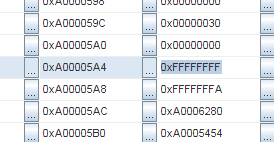
Адреса 0xA000051C и 0xA00005A4. Разница 136 байт. Поделим на 4 (размер слова), это 34 слова.
Хмм, 34 слова… Это как раз размер контекста в MIPS! И тот же самый паттерн повторяется снова и снова. Так что, похоже, что контекст сохранен несколько раз подряд. Но… Как это может быть?!
К сожалению, чтобы разобраться во всем, мне потребовалось достаточно много времени. В первую очередь, я попробовал изучить сохраненный контекст более подробно: кроме прочего, там должен быть адрес в программной памяти, где прерванный поток должен возобновить работу позже. На PIC32, программная память отображена в регион от 0x9D000000 to 0x9D007FFF, так что эти адреса легко отличимы от остальных данных. Я взял эти адреса из сохраненого контекста: один из них был 0x9D012C28. Смотрим в дизассемблер:
9D012C04 AD090000 SW T1, 0(T0)
9D012C08 8FA80008 LW T0, 8(SP)
9D012C0C 8FA9000C LW T1, 12(SP)
9D012C10 01000013 MTLO T0, 0
9D012C14 01200011 MTHI T1, 0
9D012C18 8FA10010 LW AT, 16(SP)
9D012C1C 8FA20014 LW V0, 20(SP)
9D012C20 8FA30018 LW V1, 24(SP)
9D012C24 8FA4001C LW A0, 28(SP)
9D012C28 8FA50020 LW A1, 32(SP) # <- вот он
9D012C2C 8FA60024 LW A2, 36(SP)
9D012C30 8FA70028 LW A3, 40(SP)
9D012C34 8FA8002C LW T0, 44(SP)
9D012C38 8FA90030 LW T1, 48(SP)
9D012C3C 8FAA0034 LW T2, 52(SP)
9D012C40 8FAB0038 LW T3, 56(SP)
9D012C44 8FAC003C LW T4, 60(SP)
9D012C48 8FAD0040 LW T5, 64(SP)
9D012C4C 8FAE0044 LW T6, 68(SP)
9D012C50 8FAF0048 LW T7, 72(SP)
9D012C54 8FB0004C LW S0, 76(SP)
9D012C58 8FB10050 LW S1, 80(SP)
9D012C5C 8FB20054 LW S2, 84(SP)
9D012C60 8FB30058 LW S3, 88(SP)
9D012C64 8FB4005C LW S4, 92(SP)
9D012C68 8FB50060 LW S5, 96(SP)
9D012C6C 8FB60064 LW S6, 100(SP)
9D012C70 8FB70068 LW S7, 104(SP)
9D012C74 8FB8006C LW T8, 108(SP)
9D012C78 8FB90070 LW T9, 112(SP)
9D012C7C 8FBA0074 LW K0, 116(SP)
9D012C80 8FBB0078 LW K1, 120(SP)
9D012C84 8FBC007C LW GP, 124(SP)
9D012C88 8FBE0080 LW S8, 128(SP)
9D012C8C 8FBF0084 LW RA, 132(SP)
9D012C90 41606000 DI ZERO
9D012C94 000000C0 EHB
9D012C98 8FBA0000 LW K0, 0(SP)
9D012C9C 8FBB0004 LW K1, 4(SP)
9D012CA0 409B7000 MTC0 K1, EPC
Эта характерная последовательность из LW (Load Word) с адресов относительно SP (Stack Pointer) — процедура восстановления контекста. Теперь ясно, что поток был вытеснен в момент восстановления контекста из стека. Хорошо, это может произойти из-за прерывания, но почему так много раз подряд? У меня даже нет столько прерываний в системе.
До этого, я просто использовал TNKernel без четкого понимания того, как она работает, потому что она просто работала. Так что мне было даже в некоторой степени страшно лезть глубоко в ядро. Но на этот раз, мне пришлось.
Переключение контекста в TNKernel под PIC32
Мы уже обсуждали процесс переключения контекста в общем, но сейчас, давайте освежим эту тему и добавим некоторые детали конкретной реализации (TNKernel).
Когда ядро решает переключить контекст с потока А на поток В, оно делает следующее:
- Сохраняет значения всех регистров в стек (то есть, в стек потока А);
- Запрещает прерывания;
- Переключает указатель стека на вершину стека потока В;
- Переключает указатель на дескриптор активного потока (на дескриптор потока В)
- Разрешает прерывания;
- Восстанавливает значения всех регистров из стека (то есть, из стека потока В).
Как видно, тут есть короткая критическая секция, пока ядро оперирует указателями на дескриптор потока и на вершину стека: иначе может произойти ситуация, когда прерывание будет сгенерировано между этими действиями, и нецелостность данных, конечно, приведет к некорректной работе.
Прерывания в TNKernel под PIC32
В TNKernel под PIC32 есть два типа прерываний:
- Системные прерывания: они могут вызывать сервисы ядра, которые могут привести к переключению контекста сразу после выполнения ISR. Когда такое прерывание вызывается, ядро сохраняет полный контекст в стек текущего потока
- Пользовательские прерывания: они не могут вызывать сервисы ядра. Ядро не производит никаких действий, когда генерируется такое прерывание.
Сейчас нам интересны только Системные прерывания. И TNKernel имеет ограничение для этого типа прерываний: все Системные прерывания в приложении должны иметь одинаковый приоритет, так что эти прерывания не могут быть вложенными.
В качестве небольшого напоминания, вот что происходит, когда генерируется прерывание:
- Контекст текущего потока сохраняется в стек потока;
- ISR получает управление.
Теперь ISR активен, и использование стека выглядит следующим образом:
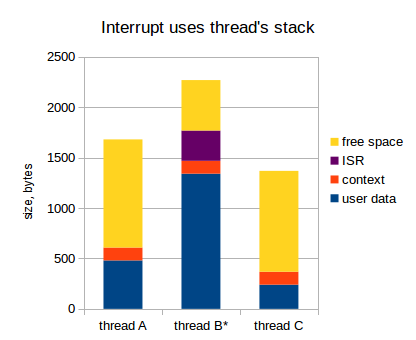
Как уже было сказано, этот подход значительно увеличивает требуемый размер стека для потоков: каждый поток должен быть достаточно большим, чтобы вместить следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Данные всех ISR с учетом наихудшей вложенности.
Необходимость умножать стек ISR на количество потоков — не самая приятная вещь, но, вообще говоря, с этим я был готов жить.
Прерывание в момент переключения контекста
А что произойдет, если прерывание будет сгенерировано в процессе переключения контекста, т.е. пока контекст текущего потока сохраняется в стек или восстанавливается из стека?
Думаю, вы догадались: т.к. прерывания не запрещены в процессе сохранения/восстановления контекста, контекст будет сохранен дважды. Вот:
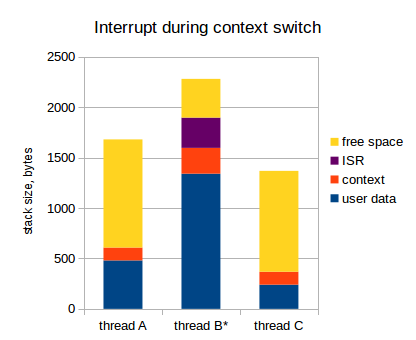
Так что, когда ядро решает переключиться с потока В на поток А, происходит вот что:
- Контекст сохраняется в стек потока В;
- В середине этого процесса происходит прерывание;
- В стеке потока В выделяется место для еще одного контекста, и контекст сохраняется туда
- ISR получает управление, делает свои дела и завершается
- Когда ISR завершается, ядро смотрит, какому потоку следует передать управление (это поток А: помните, мы хотели переключиться на поток А еще перед тем, как произошло прерывание)
- Запрещаем прерывания
- Переключаем указатель стека и указатель на дескриптор текущего потока
- Разрешаем прерывания
- Контекст восстанавливается из стека (т.е. с вершины стека задачи А)
Получаем следующую картину:
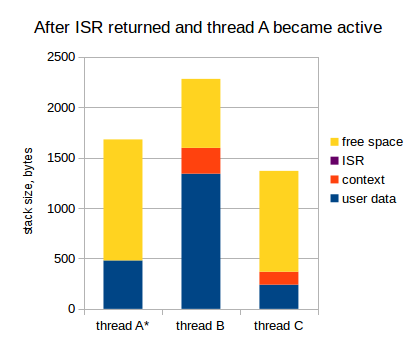
Смотрите: контекст сохранен дважды в стеке потока В. На самом деле, это еще не катастрофа, если стек не переполнен, т.к. этот дважды сохраненный контекст будет дважды восстановлен, как только поток В получит управление. Например, предположим, что поток А уходит в ожидание чего-либо, и ядро переключает управление обратно на поток В:
- Контекст сохраняется в стек потока А;
- Запрещаем прерывания, переключаем указатель стека, и т.д., разрешаем прерывания;
- Контекст восстанавливается из стека потока В.
Теперь мы, фактически, вернулись в тот момент, когда контекст сохранялся в стек потока В перед переключением на поток А. Так что мы просто продолжаем сохранять контекст:
- Завершаем сохранение контекста в стек потока В;
- Берем поток, который нужно активировать (на самом деле, он уже активирован: поток В);
- Восстанавливаем контекст обратно.
После этого, поток В продолжает работать, как ни в чем не бывало:
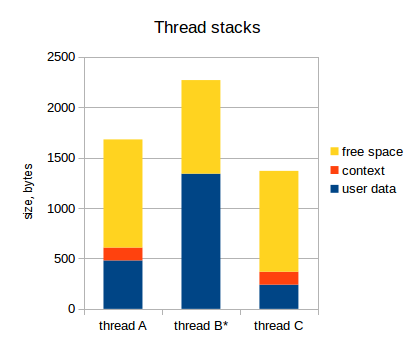
Как видите, на самом деле, ничего не сломалось, но мы должны сделать важный вывод из этого исследования: наше предположение о том, что должен вмещать контекст каждого потока, было неверным. Как минимум, он должен вмещать два контекста, а не один.
Как помните, все системные прерывания в TNKernel должны иметь одинаковый приоритет, так что они не могут быть вложенными: значит, контекст не может быть сохранен больше двух раз.
Раз так, то итоговое заключение: стек каждого потока должен вмещать в себя следующее:
- Собственные данные потока;
- Контекст потока (значения всех регистров);
- Второй контекст на случай, если прерывание произойдет в момент сохранения контекста;
- Данные всех ISR с учетом наихудшей вложенности.
Ох… еще 136 байт для кадого потока. Опять же, умножаем на количество потоков: для 7 потоков это уже почти 1 килобайт: еще 3% от 32 кБ.
Ок. Хорошо. Я, возможно, был бы согласен и на такое положение дел, но наше итоговое заключение, на самом деле, не совсем итоговое. Все еще хуже.
Копаем глубже
Давайте изучим процесс сохранения двойного контекста глубже: даже после наших последних исследований, мы все еще не можем объяснить, как так получилось, что контекст сохранен в стеке потока много раз: ведь когда прерывание сгенерировано, то текущий уровень прерываний процессора повышен (до приоритета сгенерированного прерывания), и если произойдет еще одно системное прерывание, то оно будет обработано уже после того, как текущий ISR вернет управление.
Взглянем еще раз на эту диаграмму: ISR уже вернул управление, и мы переключились на поток А:
В этот момент, уровень прерываний процессора опять понижен, а контекст сохранен в стек потока В дважды.
Догадались, что дальше?
Правильно: когда мы переключаемся обратно на поток В, и пока ее контекст восстанавливается, может произойти еще одно прерывание. Рассмотрим:
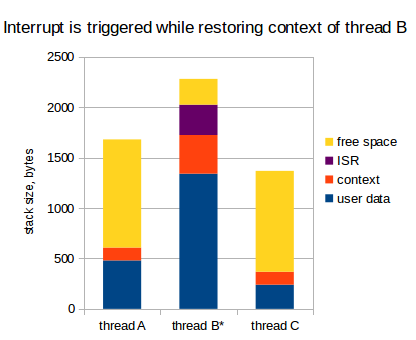
Да, контекст сохранен в стек потока уже трижды. И, что хуже, это даже может быть то же самое прерывание: одно и то же прерывание может сохранить контекст в стеке потока несколько раз.
Так что, если вам настолько не повезет, что прерывание будет генерироваться периодически, и именно с той же частотой, с которой потоки будут переключаться туда-сюда, то контекст будет сохраняться в стеке потока снова и снова, что, в конечном итоге, приводит к переполнению стека.
Это явно не было учтено автором порта TNKernel под PIC32.
И именно это произошло с моим устройством, который измерял аналоговый сигнал: прерывание АЦП генерировалось именно с такой «удачной» частотой. Вот, что происходило:
- Периферия АЦП завершает очередное измерение, и генерирует прерывание;
- Мой ISR вызывается, берет результат измерений, и отправляет сообщение в высокоприоритетный поток АЦП, который уже что-то делает с измеренным значением;
- Когда ISR завершается, ядро переключает управление на поток АЦП (т.к. его приоритет выше, чем приоритет прерванного потока);
- Поток АЦП быстро делает свою работу и переходит в ожидание следующего измерения;
- Ядро переключает управление на предыдущий поток, которая была приостановлена из-за прерывания АЦП. И пока ее контекст восстанавливается, происходит следующее прерывание по АЦП.
- Идем в пункт 2.
Разумеется, это мой косяк, что прерывания по АЦП генерируются так часто, но поведение системы совершенно неприемлемо. Корректное поведение: мои потоки перестают получать управление (т.к. некогда) до тех пор, пока такая частая генерация прерываний не будет прекращена. Стек не должен быть заполнен кучей сохраненных контекстов, и когда прерывания перестанут генерироваться так часто, система спокойно продолжает свою работу.
И еще одно следствие: даже если у нас нет таких периодических прерываний, то все равно остается ненулевая вероятность того, что разные прерывания, существующие в приложении, произойдут именно в такие неудачные моменты, что контекст будет сохранен снова и снова. Встраиваемые системы часто рассчитаны на непрерывную работу в течение долгого времени (месяцы и годы): например, автомобильные сигнализации, бортовые компьютеры, и т.д. И если время работы устройства будет стремиться к бесконечности, то вероятность такого развития событий будет стремиться к единице. Рано или поздно, это происходит. Конечно, это неприемлемо, так что оставлять текущее положение вещей нельзя.
Хорошо: как минимум, теперь я знаю причину проблем. Следующий вопрос: как эту причину устранить?
Возможно, самый быстрый и грязный хак — просто запретить прерывания на период сохранения / восстановления контекста. Да, это устранит проблему, но это очень и очень плохое решение: критические секции должны быть как можно короче, и запрещать прерывания на такие долгие промежутки времени — вряд ли хорошая идея.
Гораздо более удачное решение — использовать отдельный стек для прерываний.
Существует другой порт TNKernel под PIC32 by Anders Montonen, и он использует отдельный стек для прерываний. Но этот порт не имеет некоторых удобных плюшек, присутствующих в порте Алекса Борисова: удобных Сишных макросов для объявления системных прерываний, сервисов для работы с системными тиками, и других.
Так что я решил его форкнуть и реализовать то, что мне нужно. Конечно, чтобы производить подобные изменения в ядре, мне нужно было хорошо понимать, как оно работает. И чем больше я изучал код TNKernel, тем меньше он мне нравился. TNKernel создает впечатление проекта, написанного на коленке: куча дублированного кода и нет никакой целостности.
Примеры плохой реализации
Нарушение правила «Одна точка входа, одна точка выхода»
Наиболее частый пример, встречающийся в ядре повсеместно — это код вроде следующего:
int my_function(void)
{
tn_disable_interrupt();
//-- do something
if (error()){
//-- do something
tn_enable_interrupt();
return ERROR;
}
//-- do something
tn_enable_interrupt();
return SUCCESS;
}
Если у нас есть несколько операторов return, а тем более, если нам нужно обязательно произвести какие-то действия перед возвратом, такой код — залог проблем. Гораздо лучше будет переписать его следующим образом:
int my_function(void)
{
int rc = SUCCESS;
tn_disable_interrupt();
if (error()){
rc = ERROR;
} else {
//-- so something
}
tn_enable_interrupt();
return rc;
}
Теперь, нам не нужно помнить, что перед возвратом нужно обязательно разрешить прерывания. Пусть компилятор сделает за нас эту работу.
За последствиями далеко ходить не надо: вот функция из последней на данный момент TNKernel 2.7:
int tn_sys_tslice_ticks(int priority,int value)
{
TN_INTSAVE_DATA
TN_CHECK_NON_INT_CONTEXT
tn_disable_interrupt();
if(priority <= 0 || priority >= TN_NUM_PRIORITY-1 ||
value < 0 || value > MAX_TIME_SLICE)
return TERR_WRONG_PARAM;
tn_tslice_ticks[priority] = value;
tn_enable_interrupt();
return TERR_NO_ERR;
}
Смотрите: если в функцию переданы некорректные параметры, то возвращается TERR_WRONG_PARAM, а прерывания остаются запрещенными. Если бы мы следовали правилу одна точка входа, одна точка выхода, то эта ошибка, скорее всего, не произошла бы.
Нарушение принципа DRY
(don't repeat yourself)
Оригинальный код TNKernel 2.7 содержит огромное количество дублирования кода. Очень много похожих вещей делаются в разных местах посредством простого копирования.
Если у нас есть несколько похожих сервисов (например, сервисы, отправляющие сообщение: из потока, из потока без ожидания, или из прерывания), то это три очень похожих функции, в которых отличаются 1-2 строчки, без каких-либо попыток обобщить вещи.
Переключения между состояниями потоков реализованы очень нецелостно. Например, когда нам нужно переместить поток из состояния Runnable в состояние Wait, недостаточно просто снять один флаг и поставить другой: нам также нужно убрать его из очереди на запуск, в которой поток состоял, потом, возможно, найти следующий поток на запуск, установить причину ожидания, добавить поток в очередь на ожидание (если нужно), установить таймаут (если нужно), и т.д. В TNKernel 2.7, нет общего механизма для этого, для каждого случая код написан «здесь и сейчас».
Тем временем, корректный способ реализовать эти вещи — это написать три функции для каждого состояния:
- Ввести поток в заданное состояние;
- Вывести поток из заданного состояния;
- Проверить, состоит ли поток в заданном состоянии.
Теперь, когда нам нужно перевести поток из одного состояния в другое, нам обычно нужно просто вызвать две функции: одну для вывода потока из старого состояния, и другую для ввода ее в новое состояние. Просто и надежно.
Как следствие регулярного нарушения правила DRY, когда нам нужно что-то поменять, то нам нужно править код в нескольких местах. Нет нужды говорить, что это порочная практика.
Короче говоря, в TNKernel есть куча вещей, которые должны быть реализованы иначе.
Я решил отрефакторить его капитально. Чтобы убедиться, что я ничего не сломал, я начал реализовывать юнит-тесты для ядра. И очень скоро стало ясно, что TNKernel вообще не тестировалась: в самом ядре есть неприятные баги!
Для конкретной информации о найденных и исправленных багах, см. Why reimplement TNKernel.
В определенный момент стало ясно, что то, что я делаю, выходит далеко за рамки «рефакторинга»: я, фактически, переписывал почти все полностью. Плюс к этому, в API TNKernel есть некоторые вещи, которые меня давно напрягали, так что я слегка изменил API; а также есть вещи, которых мне не хватало, так что я их реализовал: таймеры, программный контроль переполнения стека, возможность ожидания сообщений из нескольких очередей, и т.д.
Я думал насчет названия довольно долго: мне хотелось обозначить прямую связь с TNKernel, но добавить что-то свежее и клевое. Так что первое название было: TNeoKernel.
Но, спустя некоторое время, оно само собой сократилось до лаконичного TNeo.
TNeo имеет стандартный для RTOS набор фич, плюс некоторые плюшки, которые есть не везде. Большинство возможностей опциональны, так что их можно отключить, тем самым сэкономив памяти и слегка увеличив производительность.
- Задачи, или потоки: самая основная возможность, для которой ядро вообще было написано;
- Мютексы: объекты для защиты разделяемых ресурсов:
- Рекурсивные мютексы: опционально, мютексы позволяют вложенную блокировку
- Определение взаимной блокировки (deadlock): если deadlock происходит, ядро может оповестить вас об этом, вызвав произвольную коллбэк-функцию
- Семафоры: объекты для синхронизации задач
- Блоки памяти фиксированного размера: простой и детерминированный менеджер памяти
- Группы флагов: объекты, содержащие биты событий, которые потоки могут ожидать, устанавливать и сбрасывать;
- Соединение групп флагов с другими объектами РТОС: очень полезная возможность соединить другие объекты РТОС с какой-либо группой флагов: например, когда потоку нужно ожидать сообщения сразу из нескольких очередей
- Очереди сообщений: FIFO буфер сообщений, которые потоки могут отправлять и принимать
- Таймеры: позволяют попросить ядро вызвать определенную функцию в будущем.
- Отдельный стек для прерываний: такой подход значительно экономит RAM
- Программный контроль переполнения стека: очень полезно, когда нет аппаратного контроля переполнения стека
- Динамический тик: если системе нечего делать, то можно не отвлекаться на периодическую обработку системных тиков
- Профайлер: позволяет узнать, сколько времени каждый из потоков выполнялся, максимальное время выполнения подряд, и другую информацию
Проект размещен на bitbucket: TNeo.
В данный момент, ядро портировано на следующие архитектуры:
- ARM Cortex-M cores: Cortex-M0/M0+/M1/M3/M4/M4F (supported toolchains: GCC, Keil RealView, clang, IAR)
- Microchip: PIC32/PIC24/dsPIC
Полная документация доступна в двух вариантах: html и pdf.
Конечно, очень сложно охватить реализацию всего ядра в одной статье; вместо этого, я постараюсь вспомнить, что было не ясно мне самому, и сфокусируюсь на этих вещах.
Но прежде всего, мы должны рассмотреть одну внутреннюю структуру: связанный список.
Связанные списки
Связанный список — широко известная структура данных, и читатель, скорее всего, уже знаком с ней. Тем не менее, для полноты, давайте рассмотрим реализацию связанных списков в TNeo.
Связанные списки используются в TNeo повсеместно. Более конкретно, используется кольцевой двунаправленный связанный список. Структура на C выглядит следующим образом:
/**
* Circular doubly linked list item, for internal kernel usage.
*/
struct TN_ListItem {
///
/// pointer to previous item
struct TN_ListItem *prev;
///
/// pointer to next item
struct TN_ListItem *next;
};
Она объявлена в файле src/core/tn_list.c.
Как видно, структура содержит указатели на экземпляры той же самой структуры: на предыдущий и на следующий элементы. Мы можем организовать цепочку таких структур, так что они будут связаны следующим образом:
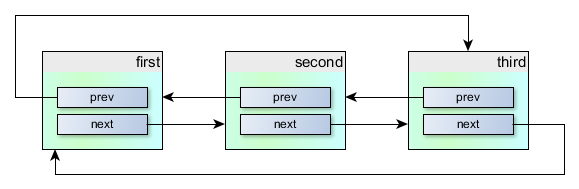
Это здорово, но пользы от этого не очень много: мы бы хотели иметь какие-то полезные данные в каждом объекте, не так ли?
Решение — встроить struct TN_ListItem в другую структуру, экземпляры которой мы хотим связывать. Например, предположим, что у нас есть структура MyBlock:
struct MyBlock {
int field1;
int field2;
int field3;
};
И мы хотим иметь возможность построить последовательность из экземпляров этой структуры. В первую очередь, встраиваем struct TN_ListItem внутрь нее.
Для этого примера, было бы логично поместить struct TN_ListItem в начало struct MyBlock, но просто чтобы подчеркнуть, что struct TN_ListItem может быть в любом месте, не только в начале, давайте поместим ее в середину:
struct MyBlock {
int field1;
int field2;
//-- say, embed it here.
struct TN_ListItem list_item;
int field3;
};
Окей, и теперь создадим несколько экземпляров:
//-- blocks to put in the list
struct MyBlock block_first = { /* ... */ };
struct MyBlock block_second = { /* ... */ };
struct MyBlock block_third = { /* ... */ };
И теперь, еще один важный момент: создать сам список, который может быть как пустым, так и не пустым. Это просто экземпляр той же самой структуры struct TN_ListItem, но не встроенный никуда:
//-- list head
struct TN_ListItem my_blocks;
Когда список пустой, то оба его указателя на предыдущий и следующий элементы указывают на сам my_blocks.
Теперь мы можем организовать список следующим образом:
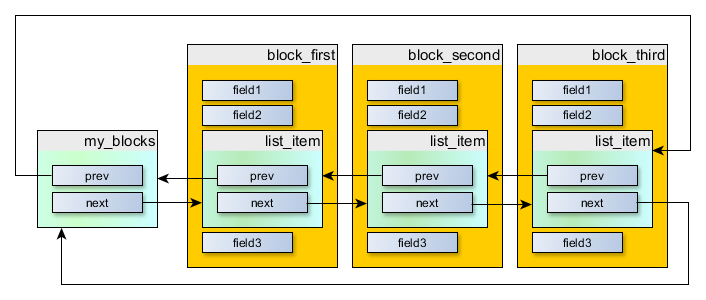
Он может быть создан с помощью кода вроде следующего:
//-- Конечно, было бы плохой идеей всегда создавать списки вот так,
// вручную. Этот код просто для иллюстрации.
my_blocks.next = &block_first.list_item;
my_blocks.prev = &block_third.list_item;
block_first.list_item.next = &block_second.list_item;
block_first.list_item.prev = &my_blocks;
block_second.list_item.next = &block_third.list_item;
block_second.list_item.prev = &block_first.list_item;
block_third.list_item.next = &my_blocks;
block_third.list_item.prev = &block_second.list_item;
Это отлично, но из вышеизложенного видно, что у нас по-прежнему есть список из TN_ListItem, а не из MyBlock. Но идея в том, что смещение от начала MyBlock до его list_item — одинаковое для всех экземпляров MyBlock. Так что, если у нас есть указатель на TN_ListItem, и мы знаем, что этот экземпляр встроен в MyBlock, то мы можем вычесть из указателя определенное смещение, и получим указатель на MyBlock.
Для этого есть специальный макрос: container_of() (определен в файле src/core/internal/_tn_sys.h):
#if !defined(container_of)
/* given a pointer @ptr to the field @member embe
