Как я Лигу Легенд парсил
Привет, Хабр!
Осмелюсь сегодня рассказать, как мне довелось извлекать данные прямо из видеозаписей турнирных игр по игре League of Legends с помощью глубоких нейронных сетей: зачем это нужно, какие архитектуры и приёмы использовались, и с какими сложностями я столкнулся.
Шаг 0: Разбираемся, что к чему

Лига Легенд (League of Legends, LoL) — популярная MOBA игра, с ежемесячной аудиторией более чем в 100 млн игроков всему миру. LoL была разработана компанией Riot Games и выпущена в далёком 2009-м году.
Именно благодаря политике компании Riot Games мне и довелось познакомиться с данной задачей извлечения статистик прямо из турнирных видео. Дело в том, что Риоты с очень большой неохотой отдают турнирные данные, из-за чего проведение анализа сильно осложняется. К примеру китайский чемпионат вообще имеет закрытое апи и получить ну хоть какие-то игровые статистики становится невозможным. Почти…
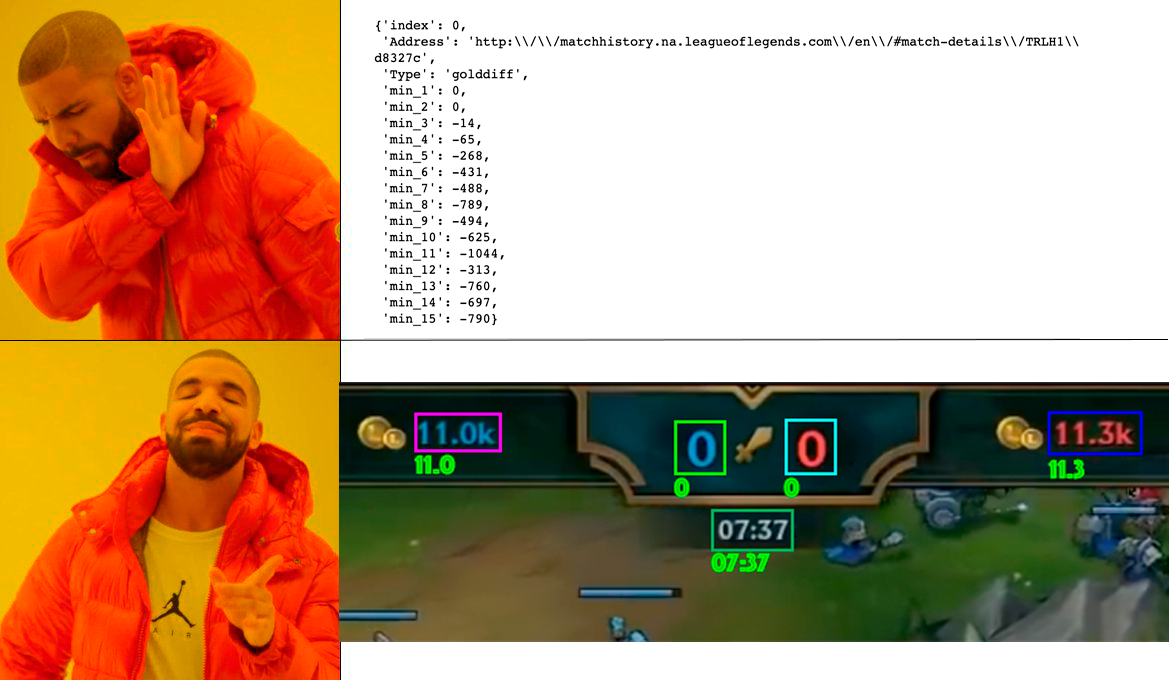
 Скриншот стрима матча континентальной лиги. LCL Летний Сплит 2020.
Скриншот стрима матча континентальной лиги. LCL Летний Сплит 2020.Для начала разберёмся с игровым HUD-ом (Heads-Up Display — визуальный интерфейс игры). На картинке выше цветами выделены основные его части:
Верхняя панель (зеленый цвет) — пожалуй основная панель, содержащая в себе базовые игровые статистики для синей и красной стороны, такие как: количество убийств, количество разрушенных башен — оборонительных сооружений-редутов на карте, количество заработанного командой золота — валюта внутри игры, использующая для покупки предметов в магазине, игровой таймер.
Боковые панели (фиолетовый цвет) — две панели, содержащие в себе информацию о чемпионах — игровых персонажах обеих команд. Панели показывают количество жизненной силы и маны чемпиона, а также набор его способностей с индикацией использования.
Панель мини-карты (синий цвет) — буквально мини-карта, показывающая расположение всех чемпионов на игровой локации, плюс некоторую доп. информацию о движении миньонов — существ с каждой стороны, наиболее часто взаимодействующих с чемпионами, состоянии башен.
Нижняя панель (красный цвет) — наиболее нагруженная панель, показывающая более детальные статистики по каждому чемпиону, такие как: K/D/A (Kills/Deaths/Assists), кол-во убитых миньонов, а также набор предметов в инвентаре чемпиона.
Шаг 1: Парсинг верхней панели

Первично была произведена аннотация данных. С использованием утилиты CVATбыли выделены обрамляющими прямоугольниками необходимые поля, а также в ручном режиме выписаны их числовые значения. Хоть и задача распознавания чисел на картинке и не кажется сложной для современных нейронных сетей, в ручном режиме необходимость всё же была, т.к. эти самые современные нейронные сети (Google OCR, Yandex OCR) показали откровенно плохие результаты на некоторых типах полей при тестировании, не говоря уже об открытых движках для распознавания (Tesseract OCR, EasyOCR).
Далее нам необходимо научиться выделять (детектировать) нужные нам поля. Для решения данной задачи было принято использовать segmentation-based подход. Я взял сеть Unet
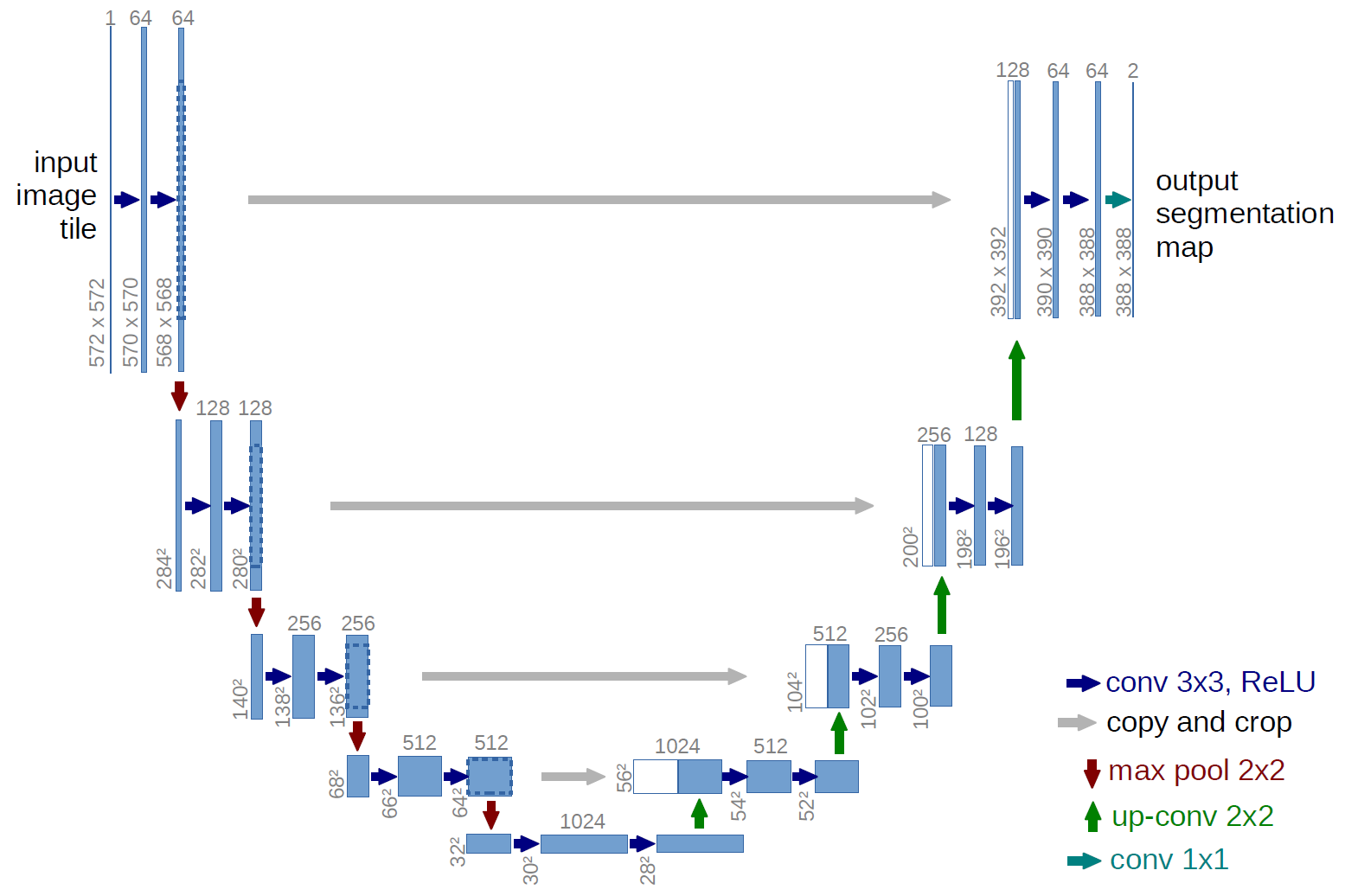 c предобученным efficientnet энкодером и обучил решать задачу instance сегментации для трех классов: башни (жёлтый цвет), золото (зелёный цвет) и кол-во убийств (фиолетовый цвет). Имплементация модели была взята из репозитория segmentation_models.pytorch. Хороший код для обучения таких моделей на Pytorch Lightning вы можете найти в репозитории Владимира Игловикова по сегментированию одежды.
c предобученным efficientnet энкодером и обучил решать задачу instance сегментации для трех классов: башни (жёлтый цвет), золото (зелёный цвет) и кол-во убийств (фиолетовый цвет). Имплементация модели была взята из репозитория segmentation_models.pytorch. Хороший код для обучения таких моделей на Pytorch Lightning вы можете найти в репозитории Владимира Игловикова по сегментированию одежды.Теперь мы умеем получать маски с классами, а после применения watershed алгоритмадаже целые отдельные области нахождения наших полей. Пора научиться их распознавать. Вдохновением для решения данной задачи послужили статьи по распознаванию номеров домов SVHN
 , а конкретно multihead архитектуры. Идея такова, что если мы имеем последовательности чисел фиксированной небольшой длины (а мы имеем), то мы можем не возиться с RNN или же детектировать отдельные символы. Мы можем взять энкодер и поставить за ним несколько отдельных голов по количеству цифр в числе, с 11-ю (11-ый для случаев, когда цифры нет) выходами в каждой. Каждая голова будет отвечать за предсказание отдельной цифры в числе, но учится все они будут вместе. Схожий подход можно найти имплементированным на Pytorch здесь.
, а конкретно multihead архитектуры. Идея такова, что если мы имеем последовательности чисел фиксированной небольшой длины (а мы имеем), то мы можем не возиться с RNN или же детектировать отдельные символы. Мы можем взять энкодер и поставить за ним несколько отдельных голов по количеству цифр в числе, с 11-ю (11-ый для случаев, когда цифры нет) выходами в каждой. Каждая голова будет отвечать за предсказание отдельной цифры в числе, но учится все они будут вместе. Схожий подход можно найти имплементированным на Pytorch здесь.Но не будем забывать, что мы имеем дело с видео. Т.е. нам нужно научить модель работать с последовательностями кадров. Для этого был выбран простейший подход:, а давайте просто заменим все 2D свёртки на трёхмерные. Как итог, практически без изменения архитектуры сети, мы добиваемся нужного результата, ведь размерности выходов у этих слоёв одинаковы. Добавление 3D свёрток сильно уменьшает количество выбросов распознавания, ведь сеть учится, что после числа N может идти либо само это чисто, либо же N+1.
Последним шагом остаётся постпроцессинг выходных данных модели: маппинг статистик ко значению таймера, сглаживание выбросов, интерполяция игровых пауз и моментов повторов, в случаях, когда интерфейсы закрыты или не видны совсем.
 Multihead OCR архитектураНо зачем таймер-то парсить?
Multihead OCR архитектураНо зачем таймер-то парсить? Если вы подумали, что в этом нет необходимости и зная одно лишь начало игры таймер восстанавливается однозначно, то я поспешу вас расстроить. Таймер на видео (внимание) не является линейным. Скажу даже больше, если вам интересно — можете посмотреть данный пятисекундный ролик и объяснить, почему семнадцатая секунда длится по времени как две:/
Шаг 2: Парсинг боковых панелей

Размечаем маски необходимых нам полей, куда без этого: заклинания чемпиона (синий цвет), иконка чемпиона (красный цвет), здоровье и мана чемпиона (салатовый и фиолетовый цвета соотвественно). Обучаем Unet из прошлого шага.
Начнём с самого простого: определение кол-ва здоровья и маны чемпиона. Для начала стоит предобработать вырезанные прямоугольные области
 . Переведём их в цветовую модель HSV(данный переход нужен для более простых манипуляций с цветами) и оставим лишь цвета из нужного диапазона: зелёного для здоровья и синего для маны. Теперь всё просто: итерируемся по матричному представлению одного из каналов изображения (или всех вместе) и ищем наиболее резкий переход между цветом и его подложкой. Разделив x-координату на размер всей области, из относительного перехода получаем значение кол-ва здоровья/маны чемпиона. Данный элементарный метод, как ни странно, показывает отличные результаты, являясь в достаточной мере робастным и точным.
. Переведём их в цветовую модель HSV(данный переход нужен для более простых манипуляций с цветами) и оставим лишь цвета из нужного диапазона: зелёного для здоровья и синего для маны. Теперь всё просто: итерируемся по матричному представлению одного из каналов изображения (или всех вместе) и ищем наиболее резкий переход между цветом и его подложкой. Разделив x-координату на размер всей области, из относительного перехода получаем значение кол-ва здоровья/маны чемпиона. Данный элементарный метод, как ни странно, показывает отличные результаты, являясь в достаточной мере робастным и точным.Далее нам нужно распознать классы заклинаний чемпиона и их статус (готовы заклинания к использованию или нет). О статусе заклинания можно узнать по наличию постепенно уходящего затемнения по часовой стрелке
 , чуть позже мы научимся определять прогресс этого отката. А пока вспомним, что такое multihead архитектура нейронной сети и применим ёё и здесь. Вместо предобученного энкодера возьмём простой набор из нескольких свёрточных и пуллинг слоёв в качестве кодировщика и пару голов с полносвязными слоями, одна из которых будет отвечать за предсказание класса заклинания, а другая за его состояние (активен/нет активен).
, чуть позже мы научимся определять прогресс этого отката. А пока вспомним, что такое multihead архитектура нейронной сети и применим ёё и здесь. Вместо предобученного энкодера возьмём простой набор из нескольких свёрточных и пуллинг слоёв в качестве кодировщика и пару голов с полносвязными слоями, одна из которых будет отвечать за предсказание класса заклинания, а другая за его состояние (активен/нет активен).К сожалению, свёрточные нейронные сети хуже приспособлены к тому, чтобы решать регрессионные задачи, а задача определения прогресса, когда заклинание будет готово является таковой. В процессе рисёрча я наткнулся на статью, в которой исследователи (да, кто-то публикует статьи про LoL) решили её за меня. Основная идея заключалась в том, чтобы взять неглубокую свёрточную нейросеть и решать ей задачу классификации, разделив набор вариантов отката заклинания на 20-ть интервалов


 воспринимая их как 20-ть отдельных классов и считая финальное число как взвешенную среднюю активаций выходных нейронов. Я слегка изменил данный подход, сделав не 20-ть, а 100 интервалов, вычисляя финальное число как argmax по выходам сети (в целом, так делать теоретически правильнее).
воспринимая их как 20-ть отдельных классов и считая финальное число как взвешенную среднюю активаций выходных нейронов. Я слегка изменил данный подход, сделав не 20-ть, а 100 интервалов, вычисляя финальное число как argmax по выходам сети (в целом, так делать теоретически правильнее).На сладкое остаётся задача классификации чемпиона по его иконке. Её также можно решать обучив простую нейросеть классификации. На первое время так и сделаем, для того, чтобы набрать данных для обучения другой сети, более архитектурно подходящей для наших баранов. Подход с простой сетью-классификатором ограничен проблемой, которая называется OOD (Out-of-Domain), ведь разработчики достаточно часто добавляют новых чемпионов в игру, и чтобы не переобучать сеть каждый раз я решил обучить другую, основанную наподходе metric learning. Данный подход позволяет обучать сеть находить схожие изображения. Для этого я взял простую сеть-классификатор и вместо оптимизации кросс-энтропии и случайного сэмплирования оптимизировал hinge-loss с hard-negative triplet сэмплированием, чтобы сеть научалась выучивать эмбеддинги чемпионов.
Сначала я долгое время удивлялся, как моя двухслойная нейронка научилось идеально предсказывать время отката заклинания, а потом понял, что сама задача очень сильно похожа на исследования, по сути послужившие началом сверточных нейронных сетей. Конкретно я говорю об исследованиях над кошачьим visual cortex.
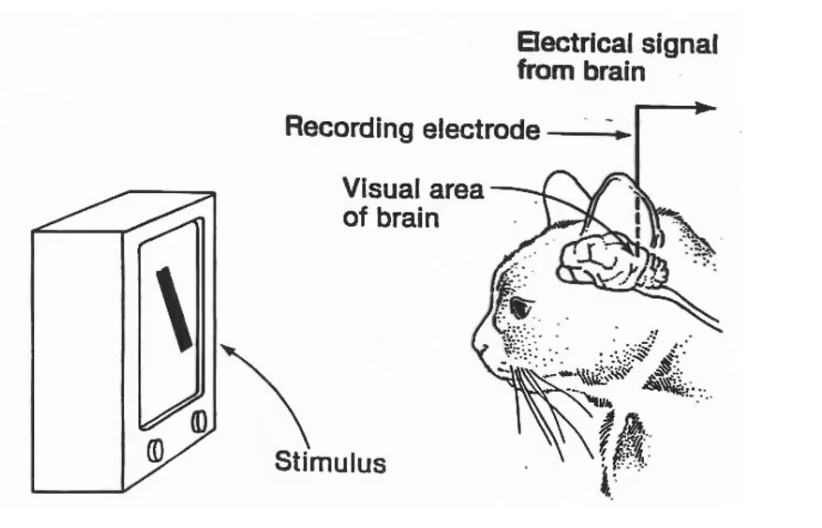
В целом вопрос хороший. На самом деле саму задачу можно научиться решать вообще без использования нейросетей, т.к. сама по себе она является задачей pattern recogntion. Но при тестировании методы pattern recogntion оказались очень медленными и не робастными, поэтому от них я отказался.

Шаг 3: Парсинг мини-карты
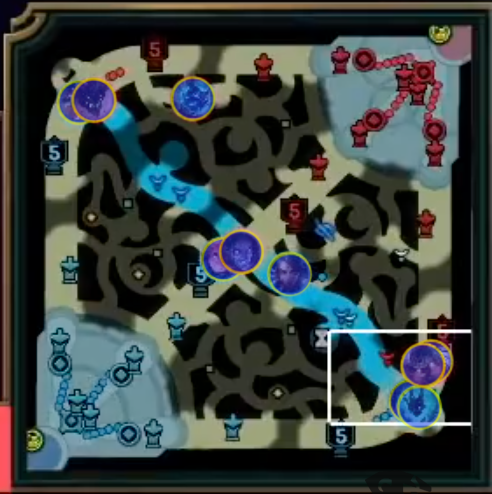
Ещё одна задача, которую кто-то уже решал до меня. Человек под ником Farza собрал датасет из ста тысяч изображений (огромное спасибо ему за это) и обучил на нём модель детекции Yolo, получив неплохие метрики детекции, но не особо хорошие классификации чемпионов. Давайте применим немного другой подход, используя его датасет.
Yolo - anchor-based архитектура детекции, которая не очень хорошо справляется с коллизиями объектов. Мне же нравится идея применить segmentation-based подход. Для начала сгенерируем маски. Используя имеющуюся разметку будем генерировать два вида масок: маска чемпиона (синий цвет), граница изображения чемпиона (желтый цвет). Это довольно известный приём для instance сегментации, идея которого состоит в предсказании всего двух видов масок, а потом в вычитании границ.
Вновь обучаем Unet.
Далее в ход идёт уже упомянутый watershed алгоритм. Теперь нужно научиться понимать, что за чемпиона вы отсегментировали. Вспоминаем, что у нас уже обучена нейросеть, которая выдаёт нам векторные представления чемпионов. Просто итерируемся по уже найденным героям на боковых панелях и сравниваем используя косинусное расстояние, их изображения с нашим отсегментированным.
Вжух, всё готово. Остаётся только лишь эвристически выровнять координаты чемпионов на мини-карте.
Шаг N: Итоги
На этом моменте, думаю, можно закончить рассказ о том, как я парсил это детище Riot Games. Подробный проход по шагам извлечения данных из нижней панели, думаю, можно опустить, ведь в нём применяются уже разобранные идеи.
Также я хотел бы извиниться за то, что не предоставляю исходный код получившегося фреймворка и опускаю некоторые моменты обучения сетей.
Спасибо за внимание!
