К глобальной куче без пробок. Исследуем менеджеры памяти
Как-то, анализируя дефект в разрабатываемом продукте, я наткнулся на архитектурную особенность менеджера памяти, который мы использовали. Дефект приводил к увеличению времени создания некоторых объектов. Особенность архитектуры заключалась в использовании паттерна Singleton при работе с менеджером памяти (далее X allocator). Схематично это выглядит так: 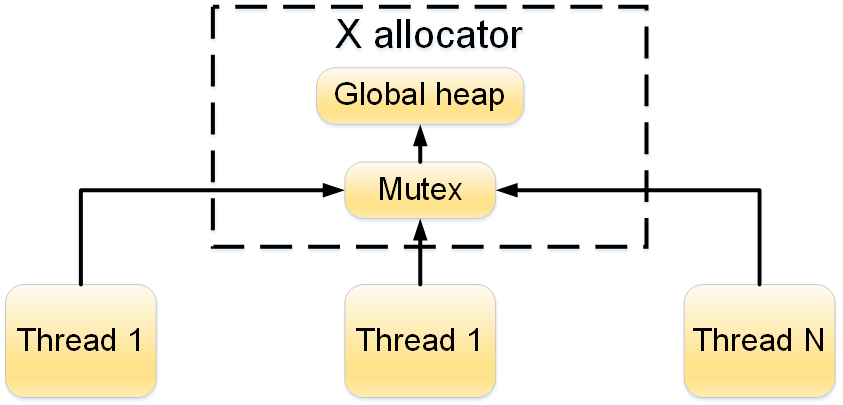 Рисунок 1 — Структурная схема работы X allocator
Рисунок 1 — Структурная схема работы X allocator
Из схемы видно, что доступ к глобальной куче защищен мьютексом. Такая архитектура, при интенсивном создании однотипных объектов из нескольких потоков, может привести к тому, что потоки будут вставать в очередь на этом мьютексе. А ведь одна из главных особенностей продукта — это возможность его масштабирования за счет увеличения количества потоков обработки (потоков выполняющих одинаковые действия). Поэтому такой подход потенциально может стать узким местом.Осознав масштаб угрозы, я решил просветиться и полез в Интернет искать информацию про многопоточные менеджеры памяти (multi-threaded pooled allocators). Пока искал, наткнулся на несколько проектов: • Hoard (http://www.hoard.org/), распространяемый под лицензией GPL v. 2.0; • TBB Memory Allocator от Intel (отбросил, т.к. библиотека платная); • Thread-Caching Malloc из состава gperftools от Google (https://code.google.com/p/gperftools/).
Также в процессе поиска нашел очень интересную статью, в которой описываются различные подходы при работе с динамической памятью — www.realcoding.net/article/view/2747.
Имея на руках несколько решений, я решил поэкспериментировать: сравнить производительность различных менеджеров памяти и подсмотреть решение для оптимизации X allocator.
Когда я проанализировал реализацию Hoard и TCMalloc, у меня сложилось понимание, что реализованные в них менеджеры памяти используют кеширование по потокам (альтернатива такого подхода — использование lock-free списков). Кеширование позволяет при удалении объекта возвращать память не в глобальную кучу, а помещать в кэш этого потока. Так что при повторном создании такого же объекта потоку не придется лезть под мьютекс в общую кучу. Схематично этот подход можно изобразить следующим образом (рисунок 2):
 Рисунок 2 — Структурная схема работы X allocator с использование кеширования потоков
Рисунок 2 — Структурная схема работы X allocator с использование кеширования потоков
Реализовав на коленке кеширование в X allocator (далее pooled X allocator), я приступил к сравнению производительности.
Исследование поведения менеджеров памяти проводилось при интенсивном потреблении CPU. Тест заключался в создании X объектов на N потоках, при этом проверялась гипотеза, что время выполнения теста обратно пропорционально количеству потоков. Пример для идеального мира: создание 1000 объектов на 1 потоке будет выполняться в 2 раза дольше, чем создание 1000 объектов на 2х потоках (по 500 объектов на поток).
Проводимые тесты можно разбить по следующим категориям:1. Тип ОС: a. Windows; b. Linux.2. Размер объектов: a. 128b; b. 1Kb; c. 1Mb.3. Менеджер памяти: a. системный менеджер памяти; b. TCMalloc (Google); c. Hoard; d. pooled X allocator (заменил X allocator singleton на массив X allocator«ов, при выделении и освобождении памяти номер X allocator«а высчитывается по tid потока).e. X allocator;4. Количество потоков: от 1 до 8;5. Каждый эксперимент я проводил по 5 раз, после рассчитал среднее арифметическое значение.
Ниже приведу только один график (рисунок 3) и результаты эксперимента для него (таблица 1), так как для всех случаев результаты получились похожими. Результаты приведены для ОС Linux объекты размером 1 Kb.
 Рисунок 3 — Результаты исследования производительности менеджеров памяти
Рисунок 3 — Результаты исследования производительности менеджеров памяти
На графике ось абсцисс — это количество потоков, ось ординат — это относительное время выполнения теста (за 100% берется время выполнения теста на одном потоке с использованием системного менеджера памяти).
Таблица 1 — Результаты исследования производительности менеджеров памяти
По полученным результатам можно сделать следующие выводы:1. X allocator, который мы используем, показал хорошую производительность только на 1 потоке, при увеличении количества потоков производительность падает (из-за конкуренции на мьютексе);2. остальные менеджеры памяти справились с задачей распараллеливания, действительно, при увеличении количества потоков задача стала выполняться быстрее;3. TCMalloc показал лучшую производительность.
Конечно, я понимал, что эксперимент искусственный и в реальных условиях рост производительность не будет таким же значительным (некоторые тесты показали рост производительности в 80 раз). Когда я заменил в своем проекте X allocator на TCMalloc и провел эксперимент на реальных данных, увеличение производительности составило 10%, и это достаточно хороший прирост.Производительность — это, конечно, замечательно, но X allocator предоставляет возможность анализировать потребляемую память и искать утечки. А как с этим обстоят дела у остальных менеджеров памяти? Это сравнение я постараюсь подробно раскрыть в следующей статье.
