К чему может привести ослабление уровня изоляции транзакций в базах данных
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу приурочить к запуску курса «PostgreSQL», на который прямо сейчас открыт набор.
Введение
В прошлый раз мы с вами поговорили про то, что транзакции в базах данных служат для решения двух задач: обеспечения отказоустойчивости и доступа к данным в конкурентной среде. Для полноценного выполнения этих задач транзакция должна обладать свойствами ACID. Сегодня мы подробно поговорим про букву I (isolation) в данной аббревиатуре.
Изоляция
Изоляция решает задачу доступа к данным в конкурентной среде, фактически предоставляя защиту от race condition’ов. В идеале, изоляция означает сериализацию, то есть свойство, обеспечивающее то, что результат выполнения транзакций параллельно такой же, как если бы они выполнялись последовательно. Основная проблема данного свойства заключается в том, что оно очень тяжело обеспечивается технически и как следствие сильно бьет по производительности системы. Именно поэтому изоляцию часто ослабляют, принимая риски возникновения некоторых аномалий, о которых речь пойдет ниже. Возможность возникновения тех или иных аномалий как раз таки и характеризует уровень изоляции транзакций.
Наиболее известными аномалиями являются: dirty read, non-repeatable read, phantom read, но самом деле их еще 5: dirty write, cursor lost update, lost update, read skew, write skew.
Dirty write
Суть аномалии заключается в том, что транзакции могут перезаписывать незакоммиченные данные.
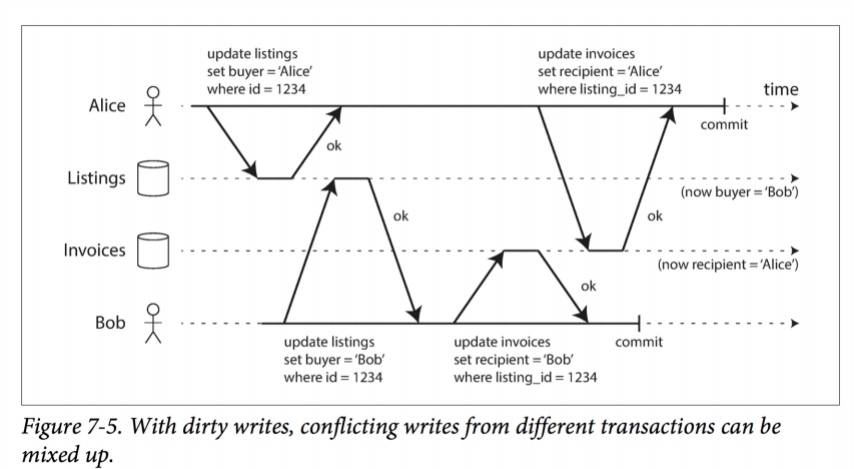
Данная аномалия опасна не только тем, что данные могут конфликтовать после коммита обеих транзакций (как на картинке), но и тем, что нарушается атомарность: потому что мы разрешим перезаписывать незакоммиченные данные, то непонятно, как откатить одну транзакцию, не задев при этом другую.
Лечится аномалия достаточно просто: вешаем блокировку на запись перед началом записи, запрещая другим транзакциям менять запись до тех пор, пока блокировка не будет снята.
Dirty read
Dirty read означает прочтение незакоммиченных данных.
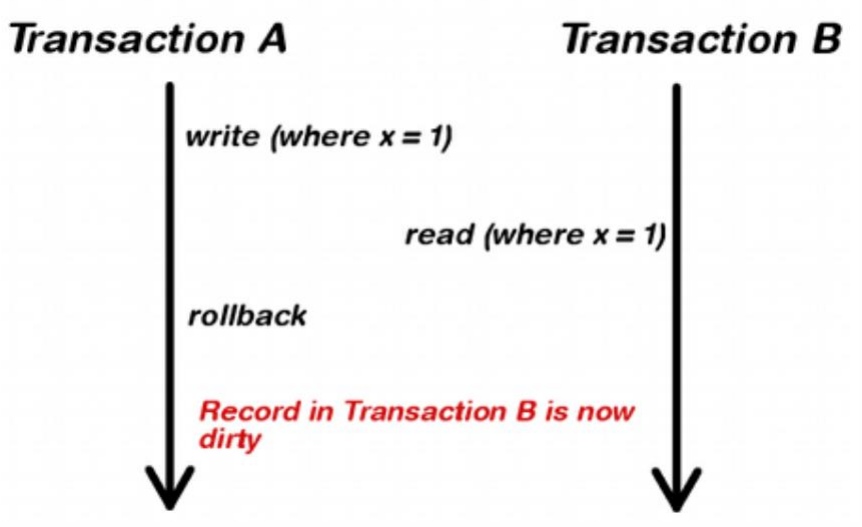
Проблемы возникают, когда на основе выборки необходимо осуществить какие-то действия или принять решения.
Для исправления аномалии можно повесить блокировку на чтение, но это сильно ударит по производительности. Гораздо проще сказать, что для rollback’а транзакции исходное состояние данных (до начала записи) обязательно должно быть сохранено в системе. Почему бы не читать оттуда? Это достаточно недорого, поэтому большинство баз данных убирают dirty read по-умолчанию.
Lost update
Lost update означает потерянные обновления, и перевод достаточно точно отображает суть проблемы:
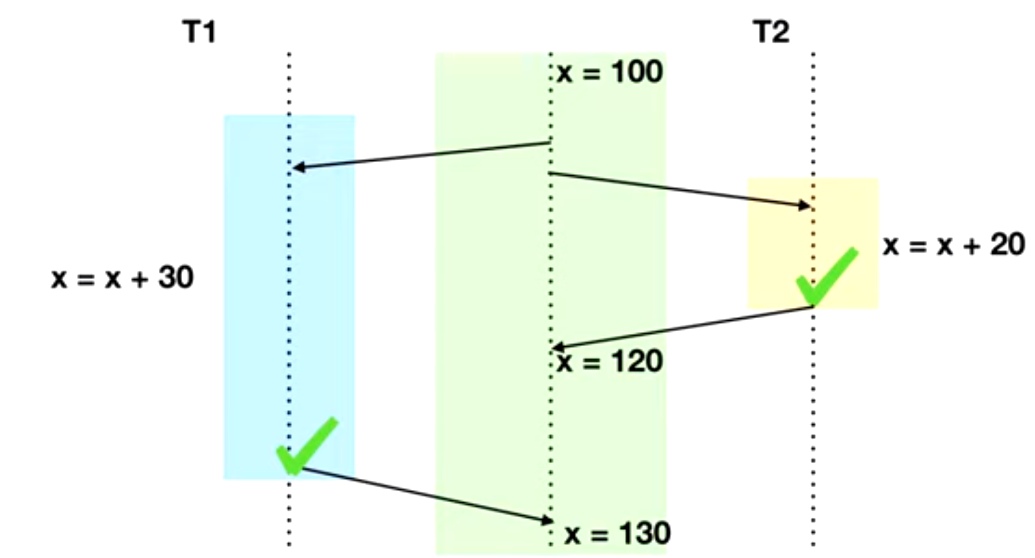
Фактически, результат транзакции Т2 был отменен. Исправляется такая ситуация явными или неявными блокировками записи. То есть мы либо просто осуществляем обновление записи, и тогда возникает неявная блокировка, либо мы выполняем select for update, вызывая возникновение блокировки на чтение и на записи. Обратите внимание на то, что такая операция достаточно опасна: своим «невинным» чтением, мы блокируем другие чтения. Некоторые базы предлагают более безопасный select for share, позволяющий читать данные, но не разрешающий их изменять.
Cursor lost update
Для более тонкого контроля базы могут предлагать другие инструменты, например, курсор. Курсор- это структура, содержащая набор строк и позволяющая по ним итерироваться. declare cursor_name for select_statement. Содержимое курсора описывается select’ом.
Зачем нужен курсор? Дело в том, что некоторые базы данных предлагают блокировку на все записи, выбранные select’ом (read stability), либо только на ту запись, на которой находится в данный момент курсор (cursor stability). При cursor stability осуществляется short lock, что позволяет снизить количество блокировок в том случае, если мы итерируемся по большой выборке данных. Поэтому аномалию lost update выделяют для курсора отдельно.
Non-repeatable read
Non-repeatable read заключается в том, что во время выполнения нашей транзакции 2 последовательных чтения одной и той же записи приведет к получению различных результатов, потому что другая транзакция вмешалась между этими двумя чтениями, поменяла наши данные и была закоммичена.
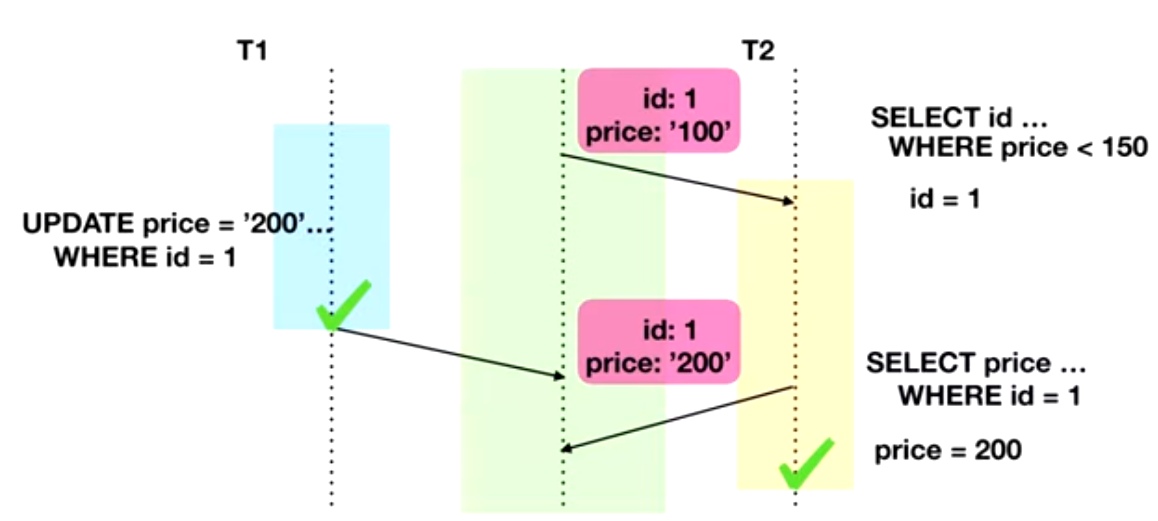
Почему это вообще проблема? Представьте себе, что цель транзакции Т2 на картинке выбрать все товары, цена которых меньше, чем 150 у.е. Кто-то другой обновил цену до 200 у.е. Таким образом, установленный фильтр не сработал.
Данные аномалии перестают возникать при добавлении двухфазных блокировок или при использовании механизма MVCC, о чем хотелось бы поговорить отдельно.
Phantom read
Фантомным называется чтение данных, которые были добавлены другой транзакцией.

В качестве примера можно наблюдать неправильную выборку самого дешевого товара при возникновении данной аномалии.
Избавиться от фантомных чтений уже достаточно сложно. Обычной блокировки недостаточно, ведь бы не можем заблокировать то, чего еще нету. 2PL-системы используют предикативную блокировку, тогда как MVCC-системы планировщик транзакций отменяет транзакции, которые могут быть нарушены вставкой. Как первый, так и второй механизмы достаточно тяжеловесны.
Read skew
Read skew возникает когда мы работаем с несколькими таблицами, содержание которых должно меняться согласованно.
Предположим, имеются таблицы, представляющие посты и их метаинформацию:

Одна транзакция читает из таблиц, другая их изменяет:
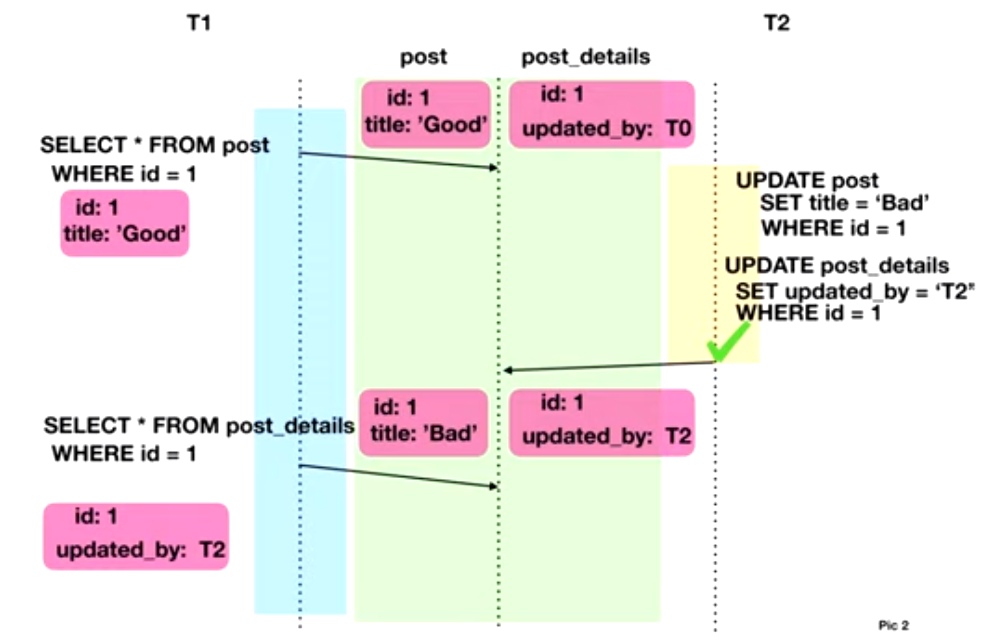
В результате выполнения транзакции Т1, у поста title = Good, а updated_by = T2, что является некоторым несоответствием.
Фактически, это non-repeatable read, но в составе нескольких таблиц.
Для исправления, Т1 может вешать блокировки на все строки, которые она будет читать, что не даст транзакции Т2 менять информацию. В случае MVCC транзакция Т2 будет отменена. Защита от данной аномалии может стать важной, если мы используем курсоры.
Write skew
Эту аномалию тоже проще объяснить на примере: предположим, что в нашей системе хотя бы один доктор должен быть на дежурстве, но оба доктора решили свое дежурство отменить:
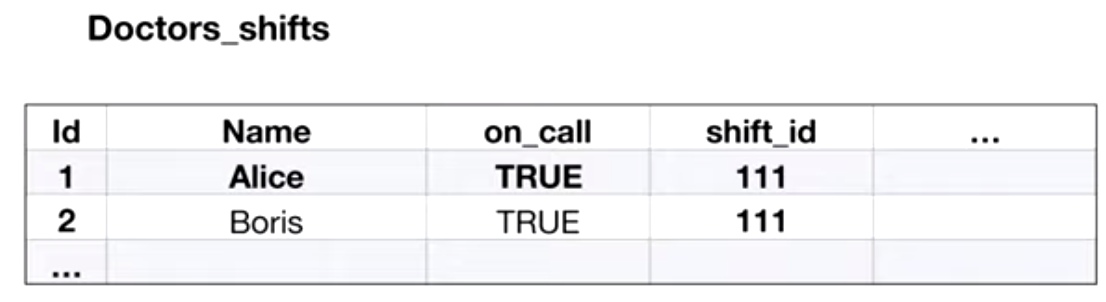

Аномалия привела к тому, что ни один из докторов не выйдет на дежурство. Почему так получилось? Потому что транзакция проверяла условие, которое может быть нарушено другой транзакцией, а из-за изоляции мы не увидели это изменение.
Это тот же non-repeatable read. Как вариант, select’ы могут вешать блокировки на эти записи.
Write skew и read skew являются комбинациями предыдущих аномалий. Можно рассмотреть write skew, являющийся по сути phantom read’ом. Рассмотрим таблицу, в которой есть имена сотрудников, их зарплата и проект, на котором они работают:
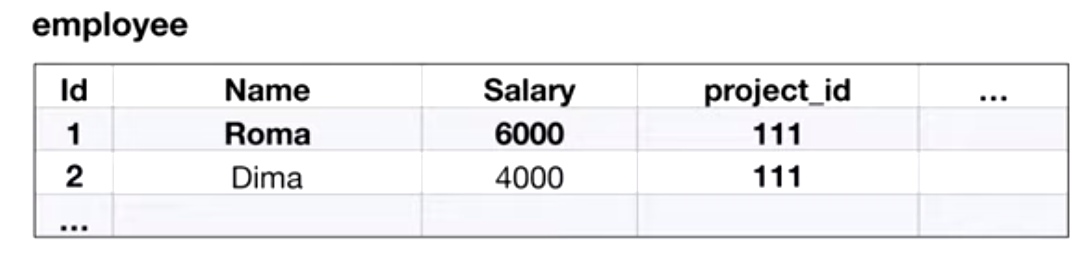

В итоге, мы получаем следующую картину: каждый менеджер думал, что его изменение не приведет к выходу за бюджет, поэтому они внесли кадровые изменения, которые в сумме привели к перерасходу.
Причина возникновения проблемы точно такая же, как и в фантомном чтении.
Выводы
Ослабление уровня изоляции транзакций в базе данных является компромиссом между безопасностью и производительностью, к выбору данного уровня следует подходить исходя из потенциальных рисков для бизнеса при возникновении тех или иных аномалий.
Узнать подробнее о курсе.
