Изучаем ELK. Часть I — Установка Elasticsearch
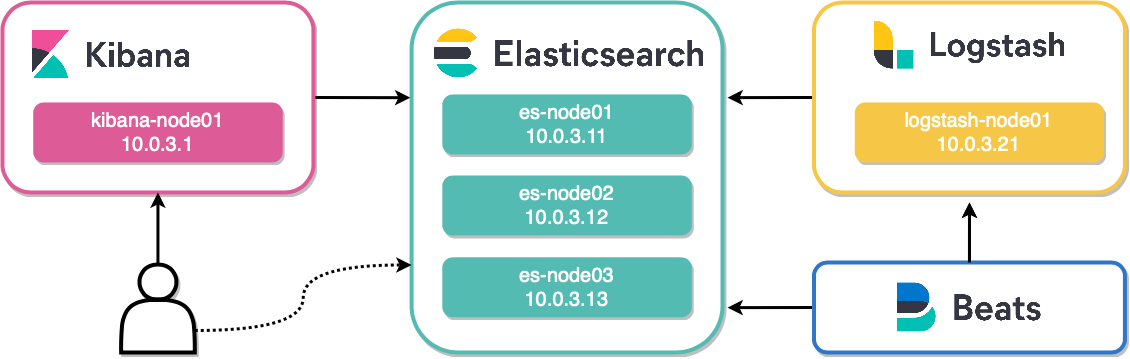
Вступительное слово
Эта статья является первой в серии статей по стеку Elasticsearch, Logstash, Kibana (ELK). Цикл статей ориентирован на тех, кто только начинает знакомится со стеком ELK, и содержит минимально необходимый набор знаний, чтобы успешно запустить свой первый кластер ELK.
В рамках данного цикла будут рассмотрены такие темы, как:
установка и настройка компонентов ELK,
безопасность кластера, репликация данных и шардирование,
конфигурирование Logstash и Beat для сборки и отправки данных в Elasticsearch,
визуализация в Kibana
запуск стека в Docker.
В данной статье будет рассмотрена процедура установки Elasticsearch и конфигурирование кластера.
План действий:
Скачиваем и устанавливаем Elasticsearch.
Настраиваем кластер.
Запускаем и проверяем работоспособность кластера.
Делаем важные настройки.
Скачиваем и устанавливаем Elasticsearch
Существует множество вариантов установки Elasticsearch, под любые нужды и желания. С перечнем можно ознакомится на официальном сайте. Не смотря на то, что на своем стенде я использовал установку из Deb пакетов, считаю правильным так же описать установку из RPM пакетов и архива tar.gz для Linux системы.
Установка из Deb пакетов
Импортируем Elasticsearch PGP ключ:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -Устанавливаем
apt-transport-httpsпакет:
sudo apt-get install apt-transport-httpsПеред установкой пакета необходимо добавить репозиторий Elastic:
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.listУстанавливаем Elasticsearch из пакета:
sudo apt-get update && sudo apt-get install elasticsearchНастраиваем Elasticsearch для автоматического запуска при запуске системы:
sudo /bin/systemctl daemon-reload && sudo /bin/systemctl enable elasticsearch.serviceУстановка из RPM пакетов
Импортируем Elasticsearch PGP ключ:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchВ директории
/etc/yum.repos.d/создаем файл репозитория Elasticsearchelasticsearch.repo:
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-mdУстанавливаем Elasticsearch c помощью пакетного менеджера в зависимости от операционной системы,
yumилиdnfдляCentOS,Red Hat,FedoraилиzypperдляOpenSUSE:
# Yum
sudo yum install --enablerepo=elasticsearch elasticsearch
# Dnf
sudo dnf install --enablerepo=elasticsearch elasticsearch
# Zypper
sudo zypper modifyrepo --enable elasticsearch && \
sudo zypper install elasticsearch; \
sudo zypper modifyrepo --disable elasticsearchУстановка из архива tar.gz
Скачиваем архив с Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-linux-x86_64.tar.gzИзвлекаем данные из архива и переходим в каталог с Elasticsearch:
tar -xzf elasticsearch-7.10.1-linux-x86_64.tar.gz
cd elasticsearch-7.10.1/Текущий каталог считается, как $ES_HOME.
Конфигурационные файлы лежать в каталоге $ES_HOME/config/.
На этом шаге установка из архива считается завершенной.
Для запуска Elasticsearch можно создать отдельного пользователя, предоставив все необходимые права к каталогу с Elasticsearch и указывая данного пользователя при настройке файловых дескрипторов.
Настраиваем кластер
На текущем этапе у нас есть три хоста с установленным Elasticsearch. Следующим и самым важным этапом является настройка каждого узла для объединения их в единый кластер.
Для настройки Elasticsearch используется YAML файл, который лежит по следующему пути /etc/elasticsearch/elasticsearch.yml при установке из Deb или RPM пакетов или $ES_HOME/config/elasticsearch.yml — при установке из архива.
Ниже будут приведены пример конфигурации для узла
es-node01.Аналогичные настройки необходимо сделать на каждом узле, указав соответствующие имя и адрес.
Указываем имя узла и определяем роли. Укажем для узла роли
masterиdata:
# ------------------------------------ Node ------------------------------------
node.name: es-node01 # Имя ноды
node.roles: [ master, data ] # Роли узла
masterДанная роль дает возможность узлу быть избранным, как управляющий узел кластера
dataузел с данной ролью содержит данные и выполняет операции с этими даннымиСо списком всех ролей узла можно ознакомится тут.
Настраиваем адрес и порт, на которых узел будет принимать запросы:
# ---------------------------------- Network -----------------------------------
network.host: 10.0.3.11 # Адрес узла
http.port: 9200 # ПортЕсли указать
0.0.0.0или просто0, то Elasticsearch будет принимать запросы на всех интерфейсах.
Определяем имя кластера и начальный список узлов в голосовании по выбору
masterузла:
# ---------------------------------- Cluster -----------------------------------
cluster.name: es_cluster # Имя кластера
cluster.initial_master_nodes: ["es-node01","es-node02","es-node03"] # Начальный набор мастер узлов
cluster.initial_master_nodesПри начальной загрузке кластера определяются узлы, участвующие в голосовании по выбору мастера, поэтому в новом кластере мы должны указать перечень этих узлов. Если данный параметр оставить пустым (по умолчанию), то узел будет ожидать подключения к уже созданному кластеру.
Данный параметр следует удалить после создания кластера и не использовать при добавлении новых узлов в существующий кластер.
Указываем список
masterузлов кластера:
# --------------------------------- Discovery ----------------------------------
discovery.seed_hosts: ["10.0.3.11", "10.0.3.12", "10.0.3.13"] # Узлы кластераДо версии 7.0 в конфигурации Elasticsearch также использовался параметр
discovery.zen.minimum_master_nodes, который можно увидеть и сейчас в некоторых конфигурациях. Этот параметр был необходим, чтобы защитится от Split Brain, и определял минимальное количествоmasterузлов для голосования. Начиная с версии 7.0 данный параметр игнорируется, так как кластер автоматически защищает себя. Более подробно о том, как это работает, можно прочитать в данной статье.
Определяем, где будем хранить данные и логи
# ----------------------------------- Paths ------------------------------------
path.data: /var/lib/elasticsearch # Директория с данными
path.logs: /var/log/elasticsearch # Директория с логамиНа выходе мы должны получить следующий конфигурационный файл:
# ------------------------------------ Node ------------------------------------
node.name: es-node01 # Имя ноды
node.roles: [ master, data ] # Роли узла
#
# ---------------------------------- Network -----------------------------------
network.host: 10.0.3.11 # Адрес узла
http.port: 9200 # Порт
#
# ---------------------------------- Cluster -----------------------------------
cluster.name: es_cluster # Имя кластера
cluster.initial_master_nodes: ["es-node01","es-node02","es-node03"] # Начальный набор мастер узлов
#
# --------------------------------- Discovery ----------------------------------
discovery.seed_hosts: ["10.0.3.11", "10.0.3.12", "10.0.3.13"] # Узлы кластера
#
# ----------------------------------- Paths ------------------------------------
path.data: /var/lib/elasticsearch # Директория с данными
path.logs: /var/log/elasticsearch # Директория с логамиПри необходимости настраиваем межсетевой экран на хосте:
9200— прием HTTP запросов (согласно конфигурации вышеhttp.port). По умолчанию Elasticsearch использует диапазон 9200–9300 и выбирает первый свободный.9300-9400— порты (по умолчанию) для коммуникации между узлами кластера. Elasticsearch будет использовать первый свободный из данного диапазона (для настройки данного порта в Elasticsearch можно использовать параметрtransport.port).
Запускаем и проверяем
Запускаем на каждом узле службу elasticsearch:
sudo systemctl start elasticsearch.serviceДля установки из архива используем:
$ES_HOME/bin/elasticsearchили если мы хотим запустить Elasticsearch как демон, то:
$ES_HOME/bin/elasticsearch -d -p pidДля выключения службы используйте
Ctrl-Cдля первого варианта запуска (из архива) илиpkill -F pidдля второго варианта.
После запуска первого узла в логах можно увидеть, что узел ожидает подключение других узлов, чтобы определить, кто возьмет роль master:
[es-node01] master not discovered yet, this node has not previously joined a bootstrapped (v7+) cluster, and this node must discover master-eligible nodes [es-node01, es-node02, es-node03] to bootstrap a cluster: have discovered [{es-node01}{olhmN6eCSuGxF4yH0Q-cgA}{CHniuFCYS-u67R5mfysg8w}{10.0.3.11}{10.0.3.11:9300}{dm}{xpack.installed=true, transform.node=false}]; discovery will continue using [10.0.3.12:9300, 10.0.3.13:9300] from hosts providers and [{es-node01}{olhmN6eCSuGxF4yH0Q-cgA}{CHniuFCYS-u67R5mfysg8w}{10.0.3.11}{10.0.3.11:9300}{dm}{xpack.installed=true, transform.node=false}] from last-known cluster state; node term 0, last-accepted version 0 in term 0После включения остальных узлов в логах появится запись о том, что кластер собрался:
[es-node01] master node changed {previous [], current [{es-node02}{VIGgr6_aS-C39yrnmoZQKw}{pye7sBQUTz6EFh7Pqn7CJA}{10.0.3.12}{10.0.3.12:9300}{dm}{xpack.installed=true, transform.node=false}]}, added {{es-node02}{VIGgr6_aS-C39yrnmoZQKw}{pye7sBQUTz6EFh7Pqn7CJA}{10.0.3.12}{10.0.3.12:9300}{dm}{xpack.installed=true, transform.node=false}}, term: 1, version: 1, reason: ApplyCommitRequest{term=1, version=1, sourceNode={es-node02}{VIGgr6_aS-C39yrnmoZQKw}{pye7sBQUTz6EFh7Pqn7CJA}{10.0.3.12}{10.0.3.12:9300}{dm}{xpack.installed=true, transform.node=false}}Проверяем состояние кластера, обратившись к любому его узлу:
curl -X GET "http://10.0.3.11:9200/_cluster/health?pretty"
{
"cluster_name" : "es_cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Узнаем, какой узел взял на себя роль master. В нашем примере это узел es-node02:
curl -X GET "http://10.0.3.11:9200/_cat/master?pretty"
VIGgr6_aS-C39yrnmoZQKw 10.0.3.12 10.0.3.12 es-node02Делаем важные настройки
Для нормальной работы кластера необходимо произвести еще некоторые настройки.
Heap size
Так как Elasticsearch написан на Java, то для работы необходимо настроить размер «кучи» (heap size). В каталоге установки Elasticsearch имеется файл jvm.options, в котором уже указаны размеры, по умолчанию — это 1 Гб. Однако, для настройки рекомендуется указать новые параметры в файле каталога jvm.options.d, который находится там же.
-Xms16g
-Xmx16gПример выше использует минимальный Xms и максимальный Xmx размер heap size, равный 16 Гб. Для настройки данных параметров следует использовать следующие рекомендации:
установите значения
XmxиXmsне более 50% от имеющейся физической памяти узла. Оставшуюся память Elasticsearch будет использовать для других целей. Чем большеheap size, тем меньше памяти используется под системные кеш;устанавите значение не более того значения, которое использует
JVMдля сжатия указателей, он жеcompressed object pointers. Данное значение составляет около 32 Гб. Стоит также отметить, что рекомендуется ограничиватьheap sizeеще одним параметромJVM, а именноzero-based compressed oops(обычно размер около 26 Гб). Узнать подробнее об этих параметрах можно тут.
Отключаем подкачку
Подкачка негативно сказывается на производительности и стабильности работы Elasticsearch, ведь система может выгрузить страницы JVM на диск. Есть несколько вариантов работы с подкачкой:
Полное отключение подкачки. Перезапуск Elasticseach при этом не требуется.
sudo swapoff -aОграничение подкачки через значение
vm.swappiness=1дляsysctl.Использование
mlockallдля блокировки адресного пространства в оперативной памяти.
Чтобы включить mlockall в конфигурации Elasticseach elasticsearch.yml указываем для параметра bootstrap.memory_lock значение true.
bootstrap.memory_lock: trueПерезапускаем Elasticsearch и проверяем настройки через запрос к любому узлу:
curl -X GET "http://10.0.3.12:9200/_nodes?filter_path=**.mlockall&pretty"
{
"nodes" : {
"olhmN6eCSuGxF4yH0Q-cgA" : {
"process" : {
"mlockall" : true
}
},
"VIGgr6_aS-C39yrnmoZQKw" : {
"process" : {
"mlockall" : true
}
},
"hyfhcEtyQMK3kKmvYQdtZg" : {
"process" : {
"mlockall" : true
}
}
}
}Если перезапуск Elasticsearch завершился ошибкой вида:
[1] bootstrap checks failed
[1]: memory locking requested for elasticsearch process but memory is not lockedили проверка показывает, что данная настройка не применилась, необходимо сделать следующее в зависимости от способа установки:
Установка из архива
Установите ulimit -l unlimited перед запуском Elasticsearch или значению memlock устанвоите unlimited в файле /etc/security/limits.conf.
Установка из пакета RPM или Deb
Установите значение параметра MAX_LOCKED_MEMORY как unlimited в /etc/sysconfig/elasticsearch для rpm или /etc/default/elasticsearch для dep.
Если вы используете systemd для запуска Elasticsearch, то лимиты должны быть указаны через настройку параметра LimitMEMLOCK. Для этого выполните команду:
sudo systemctl edit elasticsearchи укажите следующее значение:
[Service]
LimitMEMLOCK=infinityНастройка файловых дескрипторов
Elasticsearch работает с большим количеством файловых дескрипторов, и их нехватка может катастрофически сказаться на его работе. Согласно официальной документации необходимо указать значение файловых дескрипторов не ниже 65 536.
Если Elasticsearch установлен из
RPMилиDebпакетов, то настройка не требуется.Для установки из архива необходимо в файле
/etc/security/limits.confустановить параметрnofileдля пользователя, который осуществляет запуск Elasticsearch. В примере ниже таким пользователем являетсяelasticsearch:
elasticsearch - nofile 65536Проверить установленные значения можно следующим образом:
curl -X GET "http://10.0.3.11:9200/_nodes/stats/process?filter_path=**.max_file_descriptors&pretty"
{
"nodes" : {
"olhmN6eCSuGxF4yH0Q-cgA" : {
"process" : {
"max_file_descriptors" : 65535
}
},
"VIGgr6_aS-C39yrnmoZQKw" : {
"process" : {
"max_file_descriptors" : 65535
}
},
"hyfhcEtyQMK3kKmvYQdtZg" : {
"process" : {
"max_file_descriptors" : 65535
}
}
}
}Настройка виртуальной памяти
Elasticsearch по умолчанию использует каталог mmapfs для хранения индексов, и ограничение операционной системы по умолчанию для счетчиков mmap может привести к нехватки памяти. Для настройки запустите из-под root следующую команду:
sysctl -w vm.max_map_count=262144Чтобы настройка сохранилась после перезапуска системы, необходимо указать параметр vm.max_map_count в файле /etc/sysctl.conf.
Если Elasticsearch установлен из RPM или Deb пакетов, то настройка не требуется.
Настройка потоков
Необходимо убедиться, что количество потоков, которые Elasticsearch может создавать, было не менее 4096.
Это можно сделать, установив ulimit -u 4096 или установив значение nproc равным 4096 в файле /etc/security/limits.conf.
Если Elasticsearch работает под управлением systemd, то настройка не требуется.
DNS кеширование
По умолчанию Elasticsearch кеширует результат DNS на 60 и 10 секунд для положительных и отрицательных запросов. В случае необходимости можно настроить эти параметры, а именно es.networkaddress.cache.ttl и es.networkaddress.cache.negative.ttl, как JVM опции в каталоге /etc/elasticsearch/jvm.options.d/ для RPM и Deb или в $ES_HOME/config/jvm.options.d/ для установки из архива.
Временный каталог для JNA
Elasticsearch использует Java Native Access (JNA) для запуска кода, необходимого в его работе, и извлекает этот код в свой временный каталог директории /tmp. Следовательно, если каталог смонтирован с опцией noexec, то данный код невозможно будет выполнить.
В данном случае необходимо или перемонтировать каталог /tmp без опции noexec, или изменить настройку JVM, указав другой путь через опцию -Djna.tmpdir=.
На этом шаге дополнительные настройки Elasticsearch окончены.
Заключение
Дойдя до этого места, вы должны иметь работоспособный кластер Elasticsearch.
В следующей статье будут описаны процедуры установки и настройки Kibana и Logstash. А в качестве проверки работоспособности кластера соберём данные из файла и посмотрим на них с помощью Kibana.
