Иван Тулуп: асинхронщина в JS под капотом
А вы знакомы с Иваном Тулупом? Скорее всего да, просто вы еще не знаете, что это за человек, и что о состоянии его сердечно-сосудистой системы нужно очень заботиться.
Об этом и о том, как работает асинхронщина в JS под капотом, как Event Loop работает в браузерах и в Node.js, есть ли какие-то различия и, может быть, похожие вещи рассказал Михаил Башуров (SaitoNakamura) в своем докладе на РИТ++. С удовольствием делимся с вами расшифровкой этого познавательного выступления.

О спикере: Михаил Башуров — fullstack веб-разработчик на JS и .NET из Luxoft. Любит красивый UI, зеленые тесты, транспиляцию, компиляцию, технику compiler allowing и улучшать dev experience.
От редактора: Доклад Михаила сопровождался не просто слайдами, а демо-проектом, в котором можно понажимать на кнопочки и самостоятельно посмотреть за выполнением тасок. Оптимальным вариантом будет открыть презентацию в соседней вкладке и периодически к ней обращаться, но и по тексту будут даны отсылки на конкретные страницы. А теперь передаем слово спикеру, приятного чтения.
Дед Иван Тулуп
У меня была кандидатура на Ивана Тулупа.

Но я решил пойти более конформистским путем, поэтому встречайте — дед Иван Тулуп!

О нем нужно знать на самом деле только две вещи:
- Он любит играть в карты.
- У него, как и у всех людей, есть сердце, и оно бьется.
Факты об инфаркте
Возможно, вы слышали, что в последнее время участились случаи сердечных заболеваний и смертности от них. Наверное, самое распространенное сердечное заболевание — это инфаркт, то есть сердечный приступ.
Что интересного известно об инфаркте?
- Чаще всего он возникает утром в понедельник.
- У одиноких людей риск возникновения инфаркта в два раз выше. Тут, возможно, дело исключительно в корреляции, а не в причинно-следственной связи. К сожалению (или к счастью), тем не менее, это так.
- Десять дирижеров погибли от инфаркта во время дирижирования (по-видимому, очень нервная работа!).
- Инфаркт — это некроз сердечной мышцы, вызванный недостатком притока крови.
У нас есть коронарная артерия, которая подводит к мышце (миокарду) кровь. Если кровь начинает к ней плохо поступать, мышца постепенно отмирает. Естественно, на сердце и на его работу это оказывает крайне негативное воздействие.
У деда Ивана Тулупа тоже есть сердце, и оно бьется. Но наше сердце качает кровь, а сердце Ивана Тулупа качает наш код и наши таски.
Таски: большой круг кровообращения
Что такое таски? Что вообще может быть таской в браузере? Зачем они вообще нужны?
Например, мы выполняем код из скрипта. Это одно биение сердца, и вот у нас пошел кровоток. Мы нажали на кнопку и подписались на событие — у нас выплюнулся обработчик этого события — тот Callback, который мы передали. Поставили setTimeout, Callback сработал — еще одна таска. И так по частям, одно биение сердца — это одна таска.

Существует множество разных источников тасок, по спецификации их огромное количество. Наше сердце продолжает биться, и пока оно бьется, у нас все хорошо.
Event Loop в браузере: упрощенная версия
Это можно представить на очень простой диаграмме.
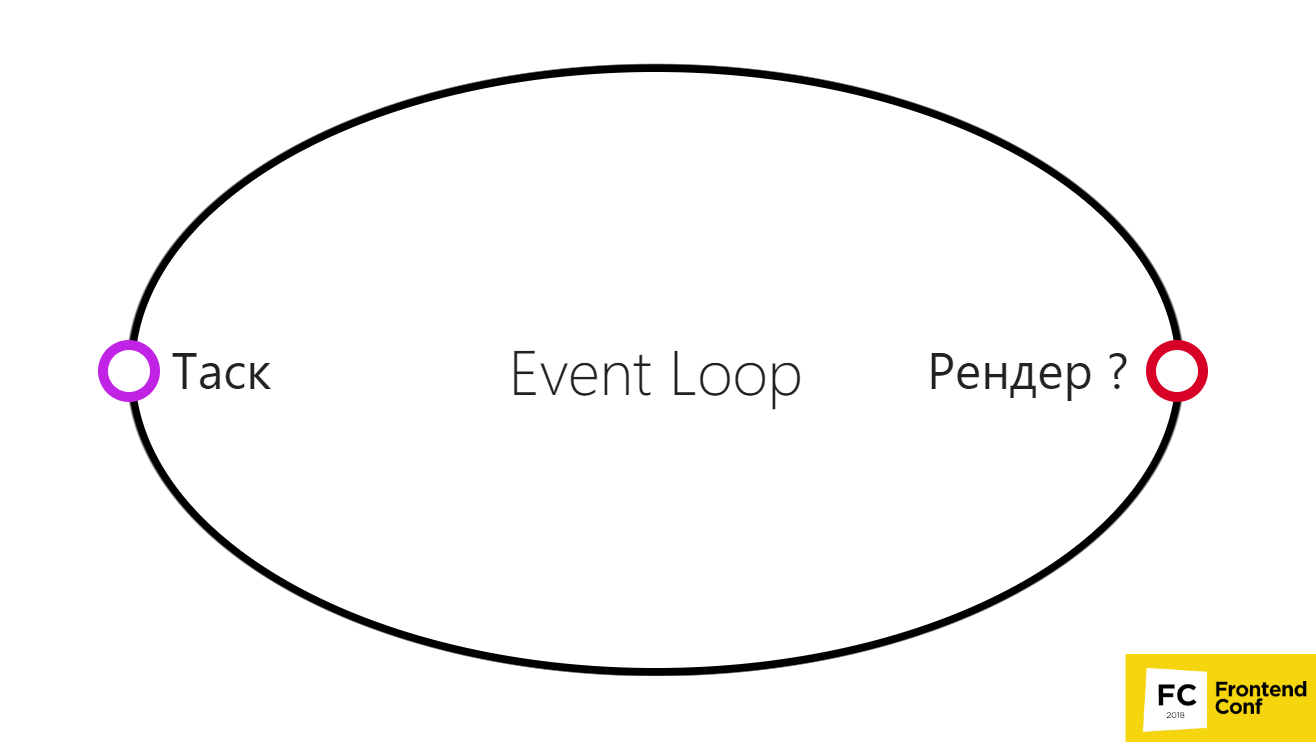
- Есть таска, мы ее выполнили.
- Затем мы выполняем браузерный рендер.
Но на самом деле это не обязательно, потому что браузер в некоторых случаях может не выполнить рендер между двумя тасками.
Это может произойти, например, если браузер может решить сгруппировать несколько таймаутов или несколько событий прокрутки. Или в какой-то момент что-то пойдет не так, и браузер решит вместо 60 fps (обычная частота кадров, чтобы все шло классно и плавненько) показывать 30 fps. Таким образом, у него будет гораздо больше времени для выполнения вашего кода и другой полезной работы, он сможет выполнить несколько тасок.
Поэтому рендер на самом деле не обязательно выполняется после каждой таски.
Таски: классификация
Существует два типа потенциальных операций:
- I/O bound;
- CPU bound.
CPU bound — это наша полезная работа, которую мы делаем (считаем, выводим на экран и т.д.)
I/O bound — это те точки, в которых мы можем наши задачи поделить. Это может быть:
- Таймаут.
Мы сделали setTimeout 5000 мс, и эти 5000 мс мы просто ждем, а можем выполнять другую полезную работу. Только когда это время пройдет, мы достанем Callback, и выполним какую-то работу в нем.
- xhr / fetch.
Мы пошли в сеть. Пока мы ждем ответа от сети, мы просто ждем, но можем и что-то полезное делать.
- Сеть (бд).
Или, например, мы ходим в сеть Network BD. Мы же и про Node.js говорим, в том числе, и, если мы хотим из Node.js пойти куда-то в сеть пожалуйста — это такая же потенциальная I/O bound задача (input/output). Прочитать файл — потенциально это вообще не CPU bound таска. В Node.js она выполняется в thread pool из-за немножко кривого API у Linux, если быть честным.
Тогда CPUbound это:
- Например, когда мы делаем цикл for of / for (;;) или по массиву как-то еще дополнительными методами проходимся: filter, map и пр…
- JSON.parse или JSON.stringify, то есть сериализация / десериализация сообщений. Это все выполняется на CPU, мы не можем просто ждать, пока все это где-то выполнится волшебным образом.
- Подсчет хэшей, то есть, например, майнинг крипты.
Конечно, крипту можно майнить и на GPU, но я думаю — GPU, CPU — вы понимаете эту аналогию.
Таски: аритмия и тромб
В итоге получается, что наше сердце бьется: оно выполняет одну таску, вторую, третью — до тех пор, пока мы что-то не делаем неправильно. Например, мы проходимся по массиву из 1 млн элементов и считаем сумму. Казалось бы, это не так сложно, но может занять ощутимое время. Если мы постоянно занимаем ощутимое время, не отпуская таску, у нас рендер не может выполняться. Он завис в этой таске, и все — начинается аритмия.
Думаю, что все понимают, что аритмия — это довольно неприятное сердечное заболевание. Но с ним еще можно жить. Что будет, если вы поместите такую задачу, которая просто повесит весь Event Loop в бесконечный цикл? Вы как бы поместите тромб в коронарную или еще какую-то артерию, и все станет совсем печально. К сожалению, наш дедушка Иван Тулуп погибнет.
Вот и помер дед Иван…

Для нас это означает, что зависнет вообще вся вкладка — нельзя будет кликнуть ни на что, а потом Chrome скажет: «Aw, Snap!»
Это даже гораздо хуже багов на веб-сайте, когда что-то пошло не так. Но если вообще все зависло, да еще, наверное, CPU нагрузило и у пользователя вообще все повесилось, то он, скорее всего, на ваш сайт больше никогда не пойдет.
Поэтому идея такая: у нас есть таска, и нам не нужно в этой таске зависать очень долго. Нам нужно побыстрее её отпустить, чтобы браузер, если что, смог отрендерить (если захочет). Если не захочет — прекрасно, пляшем!
Демо Филипа Робертса: Loupe by Philip Roberts
Рассмотрим пример:
$.on(’button', ‘click', function onClick(){
console.log('click');
});
setTimeout(function timeout() {
console log("timeout");
}. 5000);
console.log("Hello world");
Суть такая: у нас есть кнопочка, мы на нее подписываемся (addEventListener), вызывается Timeout на 5 с и сразу в console.log пишем «Hello, world!», в setTimeout пишем Timeout, в onClick пишем Click.
Что будет, если мы это запустим и много раз на кнопочку покликаем — когда Timeout на самом деле выполнится? Посмотрим демо:
Код начинает исполняться, попадает на стек, Timeout идет. Тем временем мы покликали на кнопочку. Внизу в очередь добавилось несколько событий. Пока выполняется Click, Timeout ждет, хотя 5 с уже прошло.
Здесь onClick выполняется быстро, но если вы поместите более долгую задачу, то вообще все зависнет, как уже было выяснено ранее. Это очень упрощенный пример. Здесь одна очередь, а в браузерах на самом деле все не так.
В каком порядке выполняются события — что об этом говорит спецификация HTML?
Она говорит следующее: у нас есть 2 понятия:
- task source;
- task queue.
Task source — это своеобразный тип задач. Это может быть User interaction, то есть onClick, onChange — что-то, с чем пользователь взаимодействует; или таймеры, то есть setTimeout и setInterval, или PostMessages; или вообще совершенно дикие типа Canvas Blob Serialization task source — тоже отдельный тип.
Спецификация говорит, что для одного и того же task source задачи будут гарантированно выполняться в порядке добавления. Для всего остального ничего не гарантируется, потому что task queue может быть неограниченное количество. Браузер сам решает, сколько их будет. С помощью task queue и их создания браузер может приоритезировать те или иные задачи.
Приоритеты браузеров и очереди задач
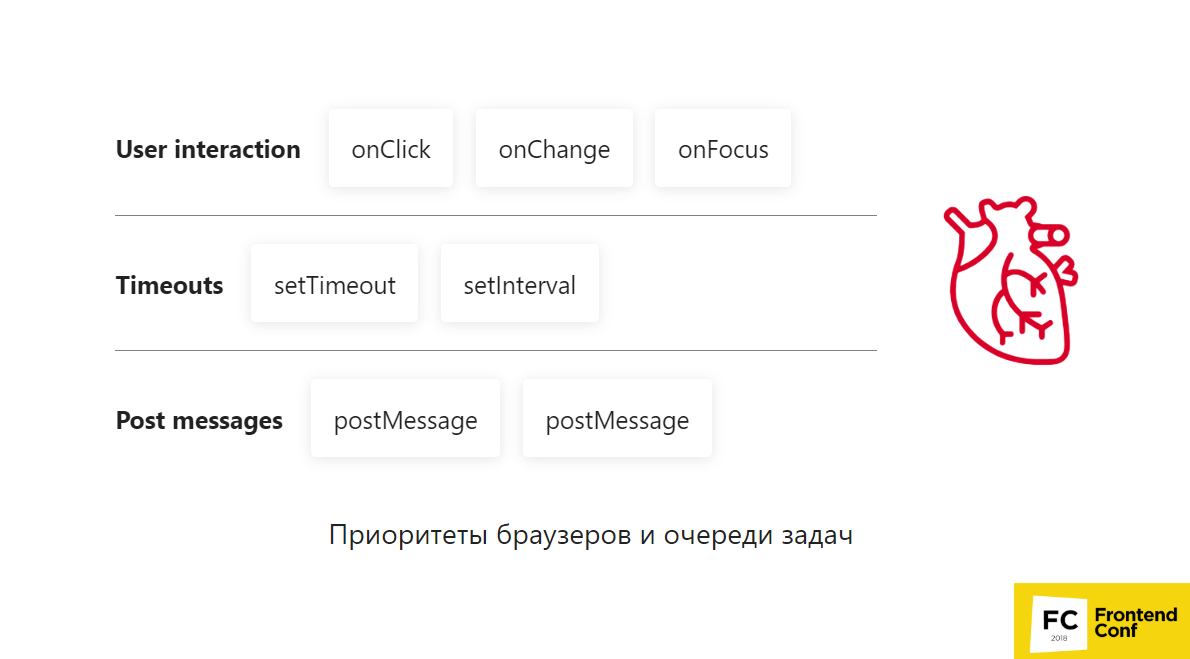
Представим, что у нас есть 3 очереди:
- user interaction;
- timeouts;
- post messages.
Браузер начинает доставать таски из этих очередей:
- Сначала он берет onFocus user interaction — это очень важно — одно биение сердца у нас пошло.
- Потом он берет postMessages — хорошо, postMessages довольно приоритетный, классно!
- Следующий — onChange — тоже снова из user interaction в приоритете.
- Дальше отправляется onClick. Очередь user interaction на этом закончилась, мы вывели пользователю все, что нужно.
- Потом берем setInterval, добавляем postMessages.
- setTimeout выполнится только самым последним. Он был где-то в конце очереди.
Это опять тоже очень упрощенный пример, и, к сожалению, никто не может гарантировать, как это будет работать в браузерах, потому что они сами все это решают. Вам нужно самим это тестировать, если вы хотите выяснить, что это такое.
Например, postMessages приоритетнее, чем setTimeout. Возможно, вы слышали о такой штуке, как setImmediate, которая, например, в браузерах IE была, только нативная. Но есть полифилы, которые основаны в основном не на setTimeout, а на создании канала postMessages и подписывании на него. Это работает в целом быстрее, потому что браузеры это приоритезируют.
Хорошо, эти таски у нас выполняются. В какой момент мы заканчиваем выполнять нашу таску и понимаем, что можем взять следующую, или что мы можем отрендерить?
Стек
Стек — это простая структура данных, которая работает по принципу «last in — first out», т.е. «последнего положил — его же первого достаешь» . Самый близкий, наверно, реальный аналог — это колода карт. Поэтому наш дед Иван Тулуп любит играть в карты.
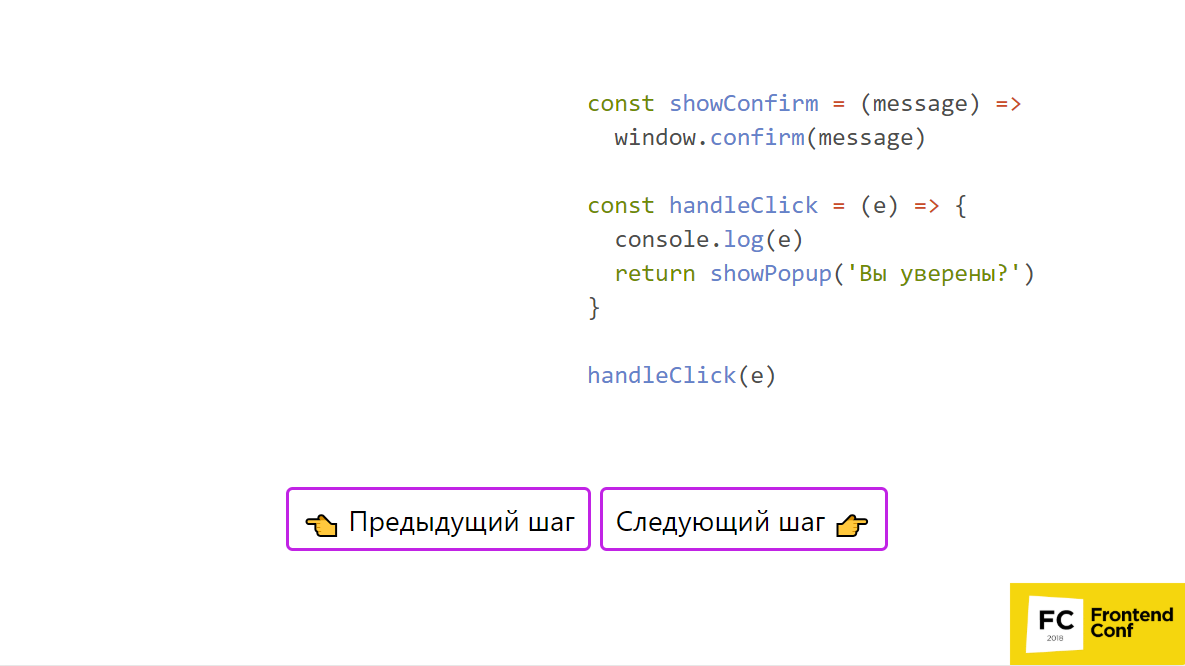
Выше пример, в котором есть некоторый код, этот же пример можно потыкать в презентации. В каком-то месте мы вызываем handleClick, вводим console.log, вызываем showPopup и window. confirm. Давайте формировать стек.
- Итак, сначала мы берем handleClick и кладем в стек вызов этой функции — отлично!
- Потом мы заходим в его тело и выполняем его.
- Кладем на стек console.log, и тут же его выполняем, потому что для его выполнения все есть.
- Далее мы кладем showConfirm — это вызов функции — отлично.
- Положили в стек функции — кладем ее тело, то есть window.confirm.
Больше у нас ничего нет — выполняем. Выведется окошечко: «Вы уверены?», нажмем на «Да», и все уйдет со стека. Теперь мы закончили тело showConfirm и тело handleClick. Наш стек очистился и можно переходить к следующей задаче. Вопрос: хорошо, я теперь знаю, что нужно разбивать это все на маленькие кусочки. Как мне, например, это сделать в самом элементарном случае?
Разбиение массива на чанки и их асинхронная обработка
Давайте рассмотрим самый «в лоб» пример. Сразу предупреждаю: пожалуйста, не пытайтесь повторить это дома — он не скомпилируется.

У нас есть большой-большой массив, и мы что-то по нему хотим посчитать, например, распарсить какие-то бинарные данные. Мы можем просто разбить его на чанки: обработать этот кусочек, этот и этот. Выбираем размер чанка, допустим, 10 тысяч элементов, считаем, сколько у нас будет чанков. У нас есть функция parseData, которая входит в CPU bound и может действительно делать что-то тяжелое. Потом разбиваем массив на чанки, делаем setTimeout (() => parseData (slice), 0).
В этом случае браузер опять же сможет приоритезировать User interaction и выполнять рендер в промежутках. То есть вы хотя бы отпускаете ваш Event Loop, и он продолжает работать. Ваше сердце продолжает биться, и это хорошо.
Но это реально очень «в лоб» пример. Сейчас в браузерах есть множество API, которые помогут это сделать более специализированно.
Помимо setTimeout и setInterval, есть API, которые выходят за пределы тасок, такие как, например, requestAnimationFrame и requestIdleCallback.
Наверное, многие знакомы с requestAnimationFrame, и даже уже его используют. Он выполняется перед рендером. Его прелесть в том, что, во-первых, он старается выполняться каждые 60 fps (или 30 fps), вo-вторых, это все выполняется непосредственно перед созданием CSS Object Model и пр.

Поэтому если даже у вас есть несколько requestAnimationFrame, они фактически сгруппируют все изменения, и фрейм выйдет целостный. В случае setTimeout вы конечно такого получить и гарантировать не можете. Один setTimeout изменит что-то одно, другой другое, а между этим может проскочить рендер — у вас будет дерганье экрана или еще что-то. RequestAnimationFrame для этого подходит замечательно.
Помимо этого, есть еще requestIdleCallback. Может быть, вы слышали, что он используется в React v16.0 (Fiber). RequestIdleCallback работает таким образом, что если браузер понимает, что у него между фреймами (60 fps) есть время, чтобы выполнить что-то полезное, и при этом они уже все сделал — таску сделал, requestAnimationFrame сделал — вроде бы все классно, то он может выдать маленькие кванты, скажем, по 50 мс, чтобы вы что-то сделали (режим IDLE).
На диаграмме выше его нет, потому что он не находится в каком-то конкретном месте. Браузер может решить поместить его до фрейма, после фрейма, между requestAnimationFrame и рендером, после таски, до таски. Этого никто гарантировать не может.
Гарантированно вам то, что если у вас есть работа, не связанная с изменением DOM (потому что тогда requestAnimationFrame — анимация и прочее), при этом она не супер приоритетная, но ощутимая, то requestIdleCallback — это ваш выход.
Итак, если у нас есть долгая CPU bound операция, то мы можем постараться разбить ее на части.
- Если это изменение DOM, то используем requestAnimationFrame.
- Если это неприоритетная, недолгая и не тяжелая задача, которая будет не слишком нагружать CPU, то requestIdleCallback.
- Если у нас большая мощная задача, которую надо исполнять постоянно, тогда мы выходим за пределы Event Loop и используем WebWorkers. Другого выхода нет.
Итоги по таскам в браузерах:
- Дробите все на маленькие задачи.
- Есть много типов задач.
- Задачи приоритезируются по этим типам через очереди по спецификации.
- Многое решается браузерами, и единственный способ понять, как это работает — просто проверить, запустить тот или иной код.
- Но спецификация соблюдается не всегда!
Проблема в том, что наш Иван Тулуп — старый дед, потому что реализации Event Loop в браузерах тоже на самом деле очень старые. Они были созданы еще до того, как была написана спецификация, поэтому спецификация, к сожалению, соблюдается постольку поскольку. Даже если вы читаете, что по спецификации должно быть так, никто не гарантирует, что все браузеры это поддержали. Так что обязательно проверяйте в браузерах, как это работает на самом деле.
Дед Иван Тулуп в браузерах — это человек слабопредсказуемый, с какими-то интересными особенностями, надо об этом помнить.
Терминатор-Санта: маскот Loop в Node.js
Node.js больше похоже на кого-то такого.

Потому, что с одной стороны это тот же самый дед с бородой, но при этом все распределено по фазам и четко расписано, где что выполняется.
Фазы Event Loop в Node.js:
- timers;
- pending callback;
- idle, prepare;
- poll;
- check;
- close callbacks.
Все, кроме последнего, не очень-то и понятно, что значит. У фаз такие странные названия, потому что под капотом, как мы уже знаем, у нас Libuv, дабы править всеми:
- Linux — epoll / POSIX AIO;
- BSD — kqueue;
- Windows — IOCP;
- Solaris — event ports.
Тысячи их всех!
Помимо этого, Libuv также предоставляет тот самый Event Loop. В нем нет специфики Node.js, а есть фазы, и Node.js их просто использует. Но названия она зачем-то взяла оттуда.
Посмотрим, что каждая фаза на самом деле означает.
Фаза Timers исполняет:
- Callback готовых таймеров;
- setTimeout и setInterval;
- Но НЕ setImmediate — это другая фаза.
Фаза pending callbacks
До этого в документации фаза называлась I/O callbacks. Совсем недавно эту документацию поправили, и она перестала противоречить сама себе. До этого в одном месте было написано, что I/O callbacks исполняется в этой фазе, в другом — что в poll фазе. Но теперь там написано все однозначно и хорошо, поэтому читайте документация — что-то станет гораздо более понятным.
В фазе pending callback исполняются коллбэки от некоторых системных операций (TCP error). То есть, если в Unix ошибка в TCP-socket, в этом случае он хочет не сразу ее выкинуть, а в коллбэке, который как раз будет исполнен на этой фазе. Это все, что нам нужно о ней знать. Нам она практически не интересна.
Фаза Idle, prepare
В этой фазе мы вообще ничего не можем сделать, поэтому забудем о ней в принципе.

Фаза poll
Это самая интересная фаза в Node.js, потому что она занимается основной полезной работой:
- Исполняет I/O-коллбэки (не pending callback фаза!).
- Ждет событий от I/O;
- Здесь круто делать setImmediate;
- Нет таймеров;
Забегая вперед, setImmediate исполнится на следующей фазе check, то есть гарантированно раньше таймеров.
А Также фаза poll контролирует поток Event Loop. Например, если у нас нет таймеров, нет setImmediate, то есть никто таймер не сделал, setImmediate не вызывал, мы просто в этой фазе заблокируемся и будем ждать события от I/O, если нам что-то придет, если есть какие-то коллбэки, если мы на что-то подписались.
Как реализуется неблокирующая модель? Например, у того же Epoll мы можем подписаться на событие — открыли socket и ждем, когда что-нибудь в него напишут. Помимо этого, вторым аргументом идет timeout, т.е. мы Epoll будет ждать, но если timeout закончится, а событие от I/O не придет, то он выйдет из timeout. Если нам придет событие из сети (кто-то в socket напишет), то придет оно.
Поэтому фаза poll достает из heap (куча — структура данных, которая позволяет хорошо отсортированно доставать и доставлять) самый ранний коллбэк, берет его timeout, записывает в этот timeout и отпускает все. Таким образом, даже если у нас никто в socket не напишет, timeout сработает, возвратится в фазу poll и работа продолжится.
Важно заметить, что в фазе poll есть лимит по количеству коллбэков за раз.
Печально, что в остальных фазах его нет. Если вы добавите 10 млрд timeout, вы добавите 10 млрд timeout. Поэтому следующая фаза — это фаза check.
Фаза check
Здесь исполняется setImmediate. Фаза прекрасна тем, что setImmediate, вызванный в poll-фазе, выполнится гарантированно раньше, чем таймер. Потому что таймер будет только на следующем тике в самом начале, а из poll-фазы раньше. Поэтому мы можем не бояться конкуренции с другими таймерами и использовать эту фазу для тех вещей, которые мы не хотим по каким-то причинам исполнять в коллбэке.
Фаза close callbacks
Эта фаза не исполняет все наши коллбэки закрытия socket и прочего типа:
socket.on('close', …).
Она исполняет их только в том случае, если это событие вылетело неожиданно, например, кто-то на том конце послал: «Все — закрываем socket — иди отсюда, Вася!» Тогда сработает эта фаза, потому что событие неожиданное. Но на нас это не особенно влияет.
Неверная асинхронная обработка чанков в Node.js
Что будет, если мы такой же паттерн, который мы брали в браузерах с setTimeout, положим на Node.js — то есть разобъем массив на чанки, для каждого чанка сделаем setTimeout — 0.
const bigArray = [1..1_000_000]
const chunks = getChunks(bigArray)
const parseData = (slice) => // parse binary data
for (chunk of chunks) {
setTimeout(() => parseData(slice), 0)
}
Как вы думаете, есть ли какие-то проблемы с этим?
Я уже немного забежал вперед, когда сказал, что, если добавить 10 тысяч timeout (или 10 млрд!), в очереди будут 10 тысяч таймеров, и он будет их доставать и исполнять — никакой защиты от этого нет: доставать — исполнять, доставать — исполнять и так до бесконечности.
Только poll фаза, если у нас постоянно событие от I/O приходит, все время в socket кто-то что-то пишет, чтобы мы хотя бы таймеры и setImmediate могли исполнить, имеет защиту на лимит, причем системозависимый. То есть он будет отличаться на разных ОС.
К сожалению, другие фазы, в том числе таймеры и setImmediate, такой защиты не имеют. Поэтому если вы сделаете так, как в примере, у вас все зависнет и до poll-фазы доходить не будет очень долго.
А как вы думаете, что-то изменится, если мы заменим setTimeout (() => parseData (slice), 0)на setImmediate (() => parseData (slice))? — Естественно, нет, там тоже нет никакой защиты на фазе check.
Чтобы решить эту проблему, можно вызывать рекурсивную обработку.
const parseData = (slice) => // parse binary data
const recursiveAsyncParseData = (i) => {
parseData(getChunk(i))
setImmediate(() => recursiveAsyncParseData(i + 1))
}
recursiveAsyncParseData(0)
Суть в том, что мы взяли функцию parseData и написали ее рекурсивный вызов, но не просто самой себя, а через setImmediate. Когда ты вызываешь это в фазе setImmediate, то оно попадает уже на следующий тик, а не в текущий. Поэтому это отпустит Event Loop, он пойдет дальше по кругу. То есть у нас есть recursiveAsyncParseData, куда мы передаем некий индекс, достаем чанк по этому индексу, отпарсили — и дальше поставили в очередь setImmediate со следующим индексом. Он попадет у нас на следующий тик и мы таким образом можем рекурсивно обрабатывать все это дело.
Правда, проблема в том, что это все равно какая-то CPU bound задача. Возможно, она все равно будет в Event Loop как-то весить и занимать время. Скорее всего, вы хотите, чтобы у вас Node.js была чисто I/O bound.
Поэтому лучше для этого использовать какие-то другие вещи, например, process fork / thread pool.
Теперь мы знаем про Node.js, что:
- все распределено по фазам — хорошо, мы это четко знаем;
- есть защита от слишком долгой poll-фазы, но не остальных;
- можно применять паттерны рекурсивной обработки, чтобы не блокировать Event Loop;
- Но лучше использовать process fork, thread pool, child process
С thread pool тоже надо быть осторожным, потому что Node.js итак немало вещей там запускает, в частности, DNS resolving, потому что в Linux почему-то функция DNS resolve не асинхронная. Поэтому ее приходится в ThreadPool исполнять. В Windows, к счастью, не так. Но там и файлы можно читать ассинхронно. В Linux, к сожалению, нельзя.
По-моему, стандартный лимит — это 4 процесса в ThreadPool. Поэтому если вы что-то активно там будете делать, то оно будет конкурировать со всеми остальными — с fs и прочими. Можно рассмотреть вариант увеличения ThreadPool, но тоже очень осторожно. Поэтому почитайте что-нибудь на эту тему.
Микротаски: малый круг кровообращения
У нас есть таски в Node.js и таски в браузерах. Возможно, вы уже слышали о микротасках. Давайте разберемся, что это такое и как они работают, и начнем с браузеров.
Микротаски в браузерах
Чтобы понять, как работают микротаски, обратимся к алгоритму работы Event Loop по стандарту whatwg, то есть пойдем в спецификацию и посмотрим, как это все выглядит.

Переводя на человеческий язык, выглядит это примерно так:
- Берем свободную таску из нашей очереди,
- Выполняем ее,
- Выполняем microtask checkpoint — ОК, мы еще не знаем, что это, но запомнили.
- Обновляем рендеринг (если необходимо), и возвращаемся на круги своя.

Они выполняются в месте, обозначенном на схеме, и еще в нескольких местах, о которых мы скоро узнаем. То есть таска закончилась, микротаски выполняются.
Источники микротасок
- Promise.then.
Важно — не сам Promise, а именно Promise.then. Тот коллбэк, который поместили в then — это микротаска. Если вы вызвали 10 then — у вас 10 микротасок, 10 тысяч then — 10 тысяч микротасок.
- Mutation observer.
- Object.observe, который deprecated и никому не нужен.
Многие ли используют Mutation observer?
Думаю, что немногие используют Mutation observer. Скорее всего, больше используется Promise.then, поэтому именно его мы и рассмотрим в примере.
Особенности работы microtask checkpoint:
- Мы выполняем все — это значит, что мы выполняем все микротаски, которые у нас есть в очереди до конца. Мы ничего не отпускаем — просто все, что есть, берем и делаем — они ведь микро должны быть, правда?
- Еще можно порождать новые микротаски в процессе, и они будет выполнены в этом же microtask checkpoint.
- Что еще немаловажно — они исполняются не только после исполнения таски, но и после очистки стека.
Это интересный момент. Получается, что можно порождать новые микротаски и мы все их до конца выполним. К чему это нас может привести?

У нас есть два сердца. Первое сердце я анимировал JS анимацией, а второе — CSS-анимацией. Существует еще одна замечательная функция, которая называется starveMicrotasks. Мы вызываем Promise.resolve, а потом в then помещаем эту же самую функцию.
Посмотрите в презентации, что произойдет, если вызвать эту функцию.
Да, сердце JS остановится, потому что мы добавляем микротаску, а потом в ней добавляем микротаску, а потом в ней добавляем микротаску… И так бесконечно.
То есть рекурсивный вызов микротасок повесит все. Но, казалось бы, у меня все асинхронное! Должно отпуститься, я же setTimeout там вызывал. Нет! К сожалению, с микротасками надо быть осторожным, поэтому если вы как-то используете рекурсивный вызов, будьте внимательны — вы можете все заблокировать.
К тому же, как мы помним, микротаски исполняется в конце очистки стека. Мы помним, что такое стек. Получается, что как только мы из нашего кода вышли, коллбэк setTimeout исполнили — все — тут же пошли микротаски. Это может привести к интересным side-эффектам.
Рассмотрим пример.

Есть кнопка и серый контейнер, в котором она лежит. Мы подписываемся на клик и кнопки, и контейнера. События, как мы знаем, всплывают, то есть они появятся там и там.
В хэндлерах мы делаем 2 вещи:
- Promise.resolve;
- .then, в который вводим console.log («RO»)
В самом хэндлере мы потом вводим «FUS», а в хэндлере на контейнере — «DAH!» (когда у нас событие всплывет).
Как вы думаете, что у нас появится в консоли? В этих сообщениях есть небольшая подсказка, и как ни странно, выведется именно «FUS RO DAH!» Отлично! Все работает, как мы ожидали.

Рассмотрим теперь абсолютно тот же самый пример, но раньше мы кликали по кнопке и браузер за нас вызывал хэндлер, а сейчас мы сами программно вызовем этот клик. Казалось бы — какая разница. Думаете, что-нибудь изменится или нет?

Конечно изменится! Потому что иначе я бы этот вопрос не задавал.

Давайте разберемся, почему так происходит.
Итак, у нас есть наш первый код, в котором есть очередь микротасок, и у нас есть стек. Можно посмотреть, как это все выполняется в первом случае.
- Первый раз мы сначала заходим в наш хэндлер — buttonHandleClick, кладем его на стек.
- Потом мы добавляем Promise.resolve. Он тоже попадает на стек. Мы его выполнили, и он нам добавил микротаску console.log («RO») в очередь. Мы ее выполнили.
- Затем мы вводим и отрабатываем console.log («FUS»).
- После этого buttonHandleClick у нас практически закончился и стек очистился. Мы можем достать нашу микротаску и выполнить ее.
- Теперь событие всплывает, мы переходим во второй хэндлер (divHandleClick) и выполняем его код, выводим «DAH!».
- HandleClick закончился.
Казалось бы, все классно и все логично. Почему в следующем примере у нас все не так? Давайте проследим поток выполнения во втором случае:
- Выполняется button.click (). Мы кладем его на стек.
- Переходим в button HandleClick.
- Выполняем Promise.resolve с then. Он добавляет нам микротаску в очередь, Promise.resolve исполняется.
- Дальше переходим в console.log и вводим «FUS».
- Мы закончили тело buttonHandleClick и выходим из него, снимаем его со стека.
Но наш синхронный метод (click) не закончился, потому что там еще другие хэндлеры есть, и стек не очищен. Поэтому мы переходим в divHandleClick и, естественно, исполняем console.log («DAH!») исполнили. И только после этого у нас очистился стек, и мы можем исполнять нашу микротаску.
Это очень неприятно, например, когда мы вызываем button.click во всевозможных тестах.
С помощью этого легко выстрелить себе в ногу. Всплытие событий используется, например, в модальных окнах. Часто бывает, что модальное окно закрывается, если вне его кликнуть.
Обычно это реализуется так: мы подписываемся на документ (клик) и на сам контейнер модального окна (тоже на клик). Если мы где-то кликнули, и оно дошло до модального окна, мы делаем stopPropagation. Если нет, то оно доходит до документа, всплывает клик, мы понимаем, что мы где-то за пределами кликнули, закрываем окно.
А что, если какой-то злой гений (или junior-программист) попытается построить интересную логику — типа мы нажимаем на кнопку «Подтвердить», у нас идет promise, который резолвится, а потом в then мы решаем, закрыть что-нибудь или нет. В таком случае получится, что в интерфейсе будет одно поведение, а в тестах другое: либо тест упадет, а интерфейс не упадет, либо наоборот. Будет очень неприятно. Поэтому лучше вообще не завязываться на это поведение, не пытаться что-то придумать поверх этого и делать максимально просто.
Сейчас большинство браузеров (я проверял 4) работают с микротасками хорошо, и это все выполняют правильно в правильном порядке. Но раньше этого не было, и никто вам, к сожалению, не может гарантировать, что не будет багов и каких-то дополнительных хитрых кейсов. Так что лучше делать просто и не завязываться на это выполнение.
О микротасках в браузерах мы узнали, что:
- С их помощью можно заблокировать Event Loop. Это неприятно.
- Они выполняются каждый раз после таски и каждый раз, когда пустеет стек.
То есть на самом деле посередине таски они тоже могут выполниться, потому что стек очистился. Клик — это одна таска, но стек очистился посередине нее, микротаски вылезли.
Микротаски в Node.js
Микротаски в Node.js это Promise.then и process.nextTick. И они тоже выполняются каждый раз, когда пустеет стек — не в конце фазы. Просто каждый раз, когда фаза заканчивается, стек, как ни странно, пустеет.
process.nextTick
Хорошо, но зачем нам нужен process.nextTick, если есть setImmediate? Зачем нам вообще микротаски в Node.js в принципе?
Давайте посмотрим на пример. У нас есть функция createServer, она создает EventEmitter, дальше возвращает нам объект, у которого есть метод listen (подписаться на порт), и этот метод эмиттит наше событие.
const createServer = () => {
const evEmitter = new EventEmitter()
return {
listen: port => {
evEmitter.emit('listening', port)
return evEmitter
}
}
}
const server = createServer().listen(8080)
server.on('listening', () => console.log('listening'))
Потом мы вызываем функцию, создаем сервер, слушаем порт 8080, подписываемся на событие listening и в console.log пишем что-то элементарное.
Давайте подумаем, как на самом деле выполняется этот код, и есть ли с ним какая-то проблема.
Мы выполняем функцию createServer, и она возвращает объект. У этого объекта мы вызываем метод listen, в котором мы уже эмитим событие, но мы еще не успели на него подписаться. У нас еще последняя строчка даже не исполнилась.
Таким образом, мы на событие подписались, но его не получили. Что можно сделать? Можно использовать process.nextTick: заменить evEmitter.emit («listening», port) на process.nextTick (() => evEmitter.emit («listening», port)).
Суть в том, что process.nextTick стоит использовать для вызова коллбэков, которые были переданы вам. С точки зрения EventEmitter, это тоже по сути коллбэк. Получается, вам передали коллбэк, но от вас ожидают асинхронного API, потому что этот коллбэк выполнится не синхронно. Поэтому мы используем process.nextTick, и этот emit произойдет сразу после того, как userland код закончится. То есть мы объявили функцию createServer, исполнили ее, исполнили listen, подписались на событие listening. Стек у нас очистился — в этот момент process.nextTick — бум! Эмитим событие, мы уже на него подписались, все классно.
Этот кейс для опроса process.nextTic
