IT-инфраструктура штабов Навального и сбор подписей: Жнец-2018
Это третья часть материала про IT-инфраструктуру штабов Навального. В предыдущих главах было рассказано про разработку сайта «Навальный 20!8», организацию сети в штабах и производство сканеров документов.
В этой главе рассказывается о создании системы для сбора подписей за выдвижение Навального кандидатом в президенты. Описаны этапы работы и получившиеся решения. Описана система физического хранения листов с подписями.

Листы, QR-коды и способы работы с ними
Подписной лист — основной документ в нашей системе. Первое, что хочется сделать для работы с большой коллекцией объектов, — присвоить им уникальный идентификатор, чтобы связать каждый объект с записью в базе данных. Но форма подписного листа очень строго прописана в законе, любое ее нарушение — это повод забраковать вообще все подписи кандидата. На листе, который подается в избирком, не допускается никаких лишних пометок и символов.
При сборе подписей в Новосибирске мы каждый лист помещали в мультифору (прозрачный «файл»), на которой маркером записывались ID листа и все служебные пометки. Это подошло для четырех тысяч листов, но не сработает для сотен тысяч. В этот раз мы посчитали использование мультифор ненадежным и неудобным решением.

Юристы изобрели способ, который позволил нам идентифицировать каждый лист и не нарушить форму подписного листа. В законе ничего не сказано о физическом размере подписного листа. Это позволило нам спроектировать лист так, чтобы идентификационные коды наносились на его верхнюю часть, а перед подачей в избирком просто обрезались.
Код листа состоит из 6 символов. Можно использовать цифры и буквы латиницы, имеющие графические аналоги в кириллице (в формах можно писать в любой раскладке). Для удобства добавили разделители: 91−X7−BA.
Этот же идентификатор печатается в виде QR-кода для автоматического распознавания на различных этапах работы. QR-коды победили по надежности и скорости распознавания все другие виды штрихкодов.

Жизнь штабов полна трудностей, поэтому QR-коды тщательно тестировали в различных стрессовых для листов ситуациях…

… и решили, что трех кодов будет достаточно, чтобы обработать любой живой лист.

Юристы и дизайнеры серьезно поработали, чтобы верстка соответствовала одновременно и закону, и здравому смыслу. Отдельно тестировали количество подписей на листе. Мало подписей — слишком много листов, много лишней писанины (данные сборщика и доверенного лица), больше ошибок в заверительной надписи. Много подписей — неудобно вносить данные избирателя, больше ошибок в строках подписей. После экспериментов с прототипами остановились на пяти подписях.
Каждый лист (точнее, идентификатор листа) создается в базе, после чего его можно распечатать на бумаге формата A4. Но нельзя просто взять и напечатать лист на ближайшем принтере. По закону изготовление подписных листов должно быть оплачено с избирательного счета кандидата. Обычно их изготавливает внешний подрядчик. Поэтому мы сделали техническую сторону максимально дружественной и гибкой. Листы или печатаются прямо из браузера, или предварительно сохраняются в многостраничный PDF-файл, который можно передать подрядчику любым удобным способом.
Сыч: подготовка к сбору подписей
Сбор физических подписей в подписные листы можно начинать лишь после выдвижения кандидата и открытия специального избирательного счета. Закон отводит на это крайне мало времени. Нам важно было как можно больше операций проделать заранее, чтобы отладить все процессы и после официального объявления выборов максимально ускорить работу. Для предварительной проверки данных наших сторонников, для тренировки штабов и тестирования механики сбора мы запустили процедуру верификации.
Верификация — это бета-версия сбора подписей: в настоящих штабах, с тем же оборудованием, с теми же строгими проверками документов, но без внесения подписи в бумажный лист. Для работы с данными верифицируемых людей было разработано приложение Сыч.
Состав Сыча
Бэкенд с RESTful API: Python 3.6, aiohttp, aiohttp_admin, SQLAlchemy.
Базы данных: PostgreSQL, Redis.
Демон уведомлений.
Демон распознавания номеров паспорта.
Демон для сборки аналитики.
Сервис проверки паспорта по его номеру.
Коробочная версия Кладр-API для работы с адресами (PHP 5.6 + MongoDB).
Мы решили сделать для Сыча отдельный бэкенд с RESTful API, потому что планировалось интегрировать его с несколькими сервисами, включая сайт «Навальный 20!8». В качестве хранилища использовали отдельную базу PostgreSQL и Redis — для кэширования. Для управления пользователями подошла библиотека aiohttp_admin, которую мы модифицировали под свои нужды.
Внутренний интерфейс оператора — это пошаговая форма сканирования паспорта и заполнения персональных данных. Из-за большого количества возможных состояний эту форму написали на React.
Взаимодействие с сайтом «Навальный 20!8» велось через API, который защищен токеном и доступен только по локальной сети между виртуальными машинами.
Запись на верификацию
Чтобы равномерно распределить по времени нагрузку на штабы, придумали запись на верификацию. После регистрации на сайте человек получал доступ к интерфейсу записи, где он выбирал удобный штаб и время.
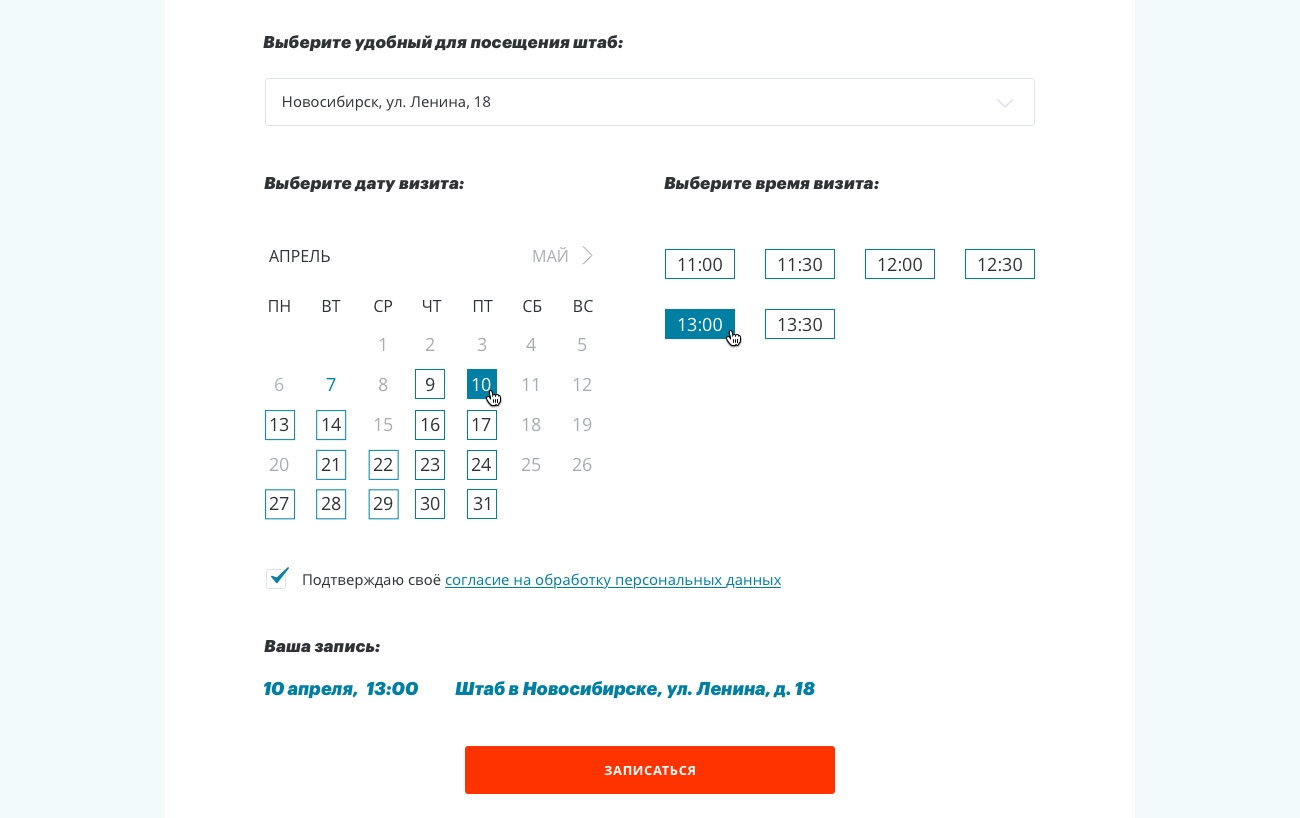
Для контроля загруженности, управления записями и расписанием мы разработали отдельный интерфейс, доступный региональному менеджеру и координатору штаба:

Если у штаба возникает ЧП, координатор может массово отменить будущие записи на верификацию. Однако самостоятельно он этого сделать не может — надо запросить код подтверждения отмены у регионального менеджера. Нам пришлось неоднократно пользоваться этой опцией.
Уведомления
В Сыче была реализована ветвистая система уведомлений. Подписант должен был получать уведомления по почте, когда записался на верификацию, пропустил запись, через неделю после отмены записи, после успешной верификации, после отмены записи штабом и еще в нескольких случаях.
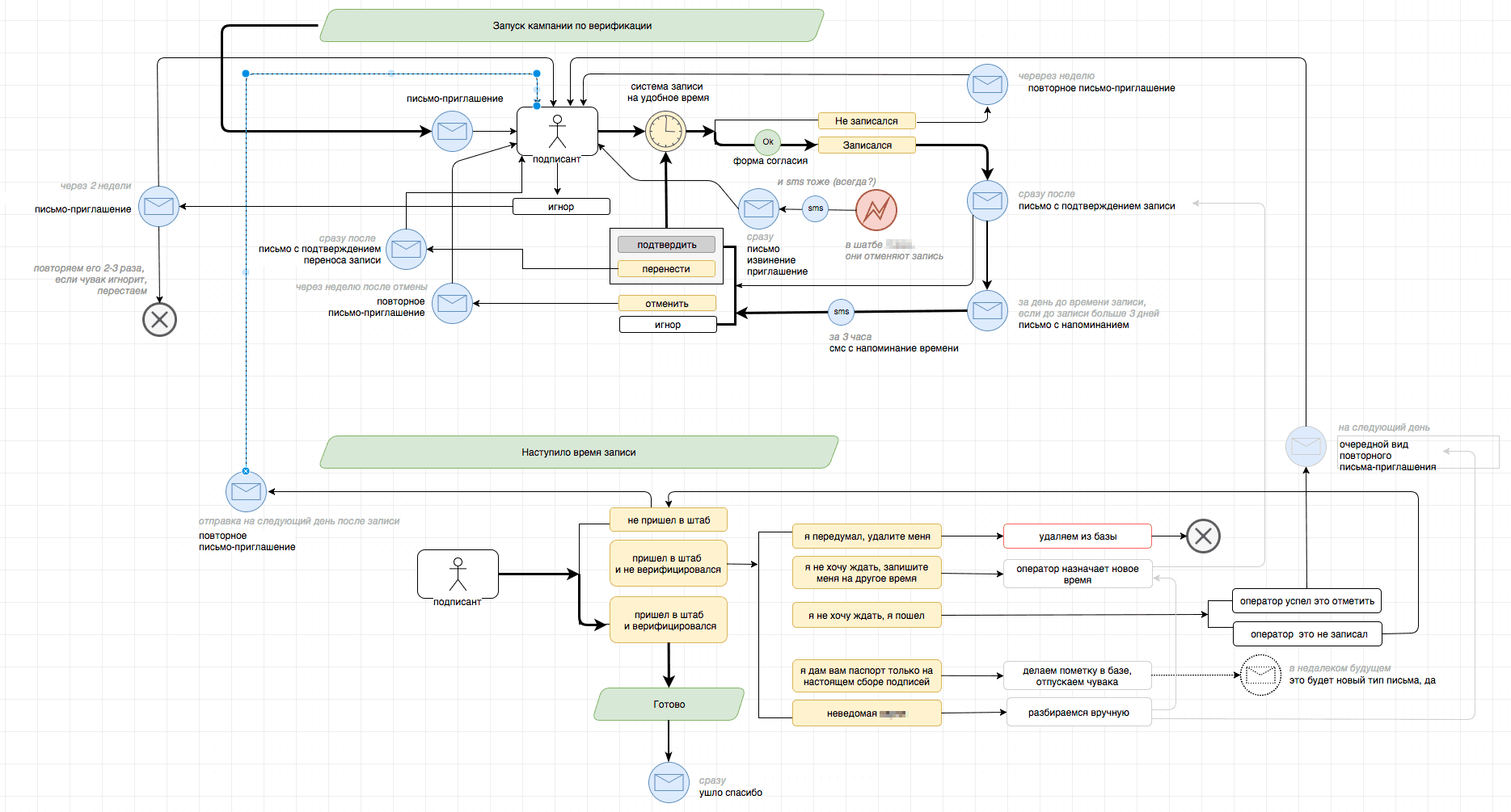
SMS-уведомления отправлялись для напоминания о записи за три часа и для информирования о том, что штаб отменил запись. Очередь уведомлений была сделана по тому же принципу, что и на сайте «Навальный 20!8»: таблицы в БД с сообщениями, которые отправлялись группами через почтовые и SMS-шлюзы.
Распознавание паспортных данных
Чтобы оценить работу операторов и определить процент ошибок при вводе данных, хотелось иметь дополнительное распознавание сканов. Надежное автоматическое распознавание сделать было невозможно из-за вариативности паспортов, поэтому рассматривалось два варианта: отсылать сканы в Яндекс.Толоку, чтобы их распознавали ее пользователи, или взять группу волонтеров, которые занимались бы этим в офисе. Но вопрос безопасности персональных данных пресек оба варианта, и мы оставили автоматическое распознавание только для номера паспорта.
Аналитика Сыча
Во время верификации мы не только уточняли и проверяли нашу базу сторонников, но и тестировали работу штабов, инфраструктуру, оборудование и механику сбора подписей. Чтобы наблюдать за процессом и корректировать его, мы сделали Простенькую аналитику.
Так как в штабе есть три уровня управления процессами — координаторы штабов (отвечают за работу одного штаба), региональные менеджеры (следят за группой штабов в нескольких регионах) и менеджмент федерального штаба (следит за всем и всеми), — система группировала данные по-разному для каждой категории пользователей.
Больше всего деталей мы показывали координатору штаба. Он видел статистику всех операторов и динамику ключевых показателей и мог принимать на их основе управленческие решения: выставить больше или меньше операторов, усилить оповещение, изменить график работы в выходные, уволить или перевоспитать сотрудников, которые часто ошибаются, и т. д.
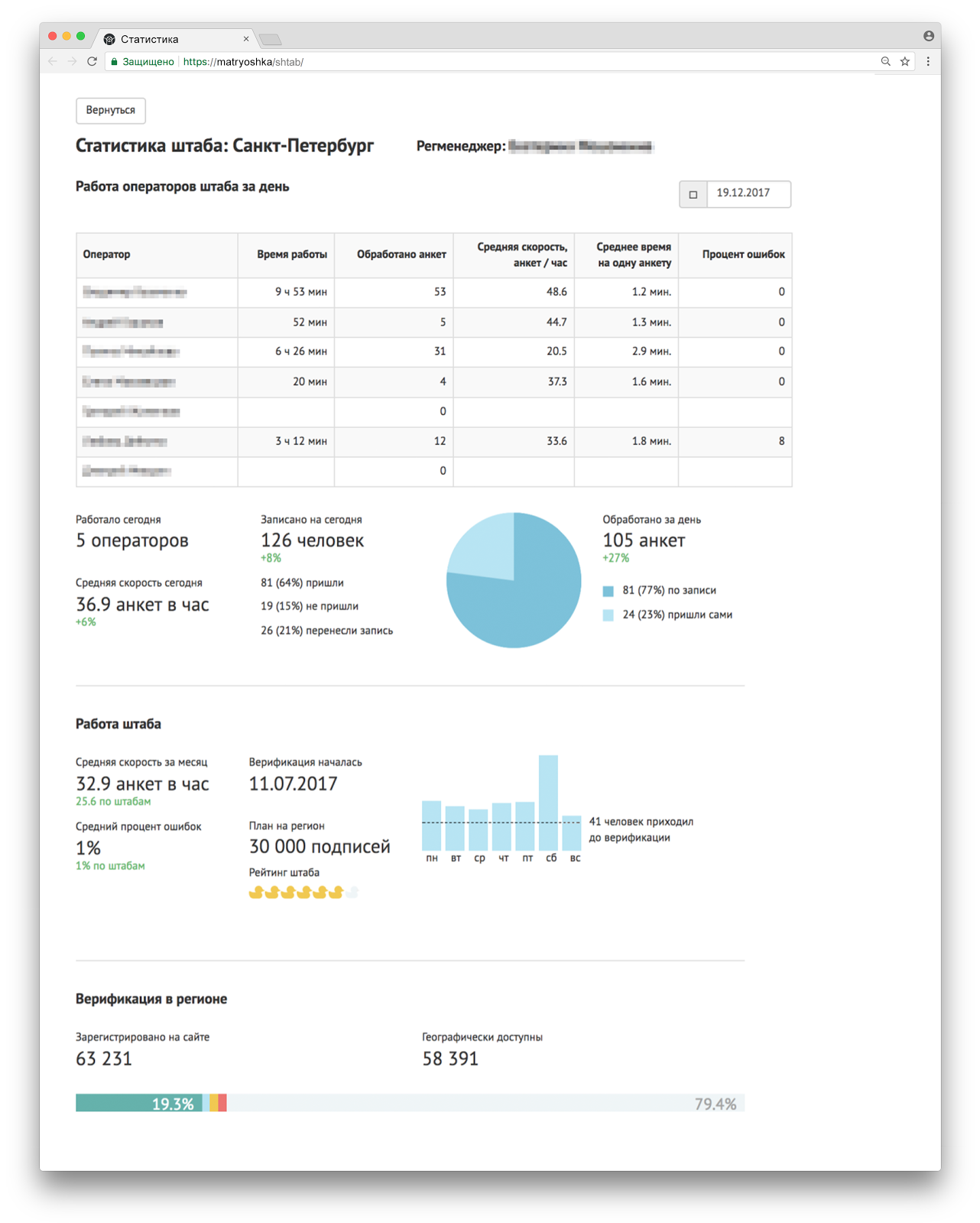
Регионального менеджера мы избавили от лишних подробностей, и на первом экране он видел только самые важные вещи по своей группе штабов: ключевые показатели, рейтинги и проблемные штабы (обозначены тревожным красным). К «проблемным» мы относили штабы с показателями на N% ниже среднего значения, хронически недогруженные (им требовалось дополнительное оповещение) и перегруженные по количеству записей (это означало, что не все люди могут записаться и нужно увеличить количество операторов).
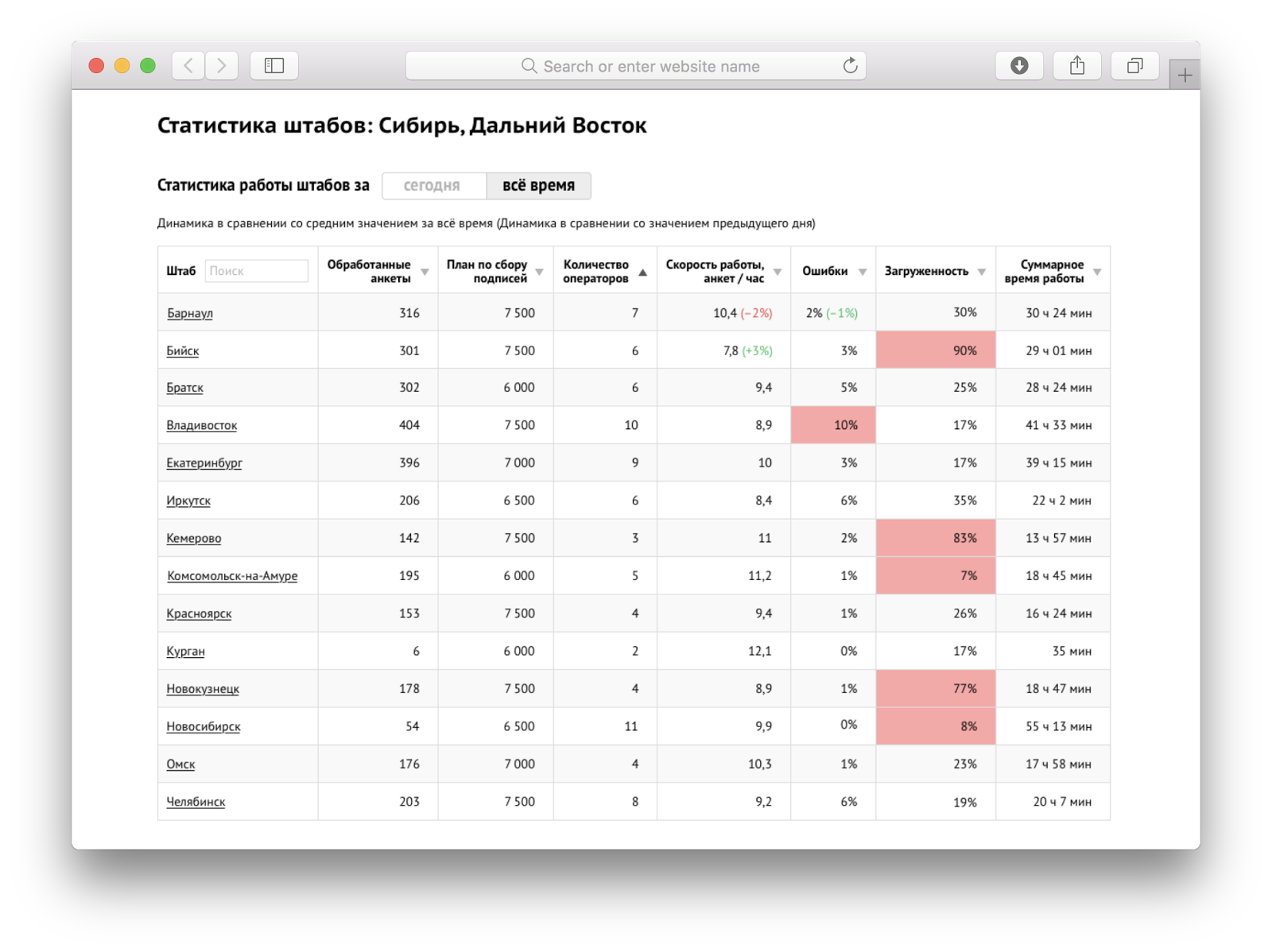
Чтобы лучше разобраться с обнаруженной проблемой, региональный менеджер легко мог посмотреть детальную статистику по каждому штабу и увидеть все данные, которые доступны координатору.
Федеральному штабу важно было сразу видеть полную картину, поэтому мы собрали на один экран ключевые метрики кампании и сделали сводную таблицу по всем городам, где идет верификация. В таблице можно выбрать интересующий штаб, чтобы посмотреть полный набор данных по нему.
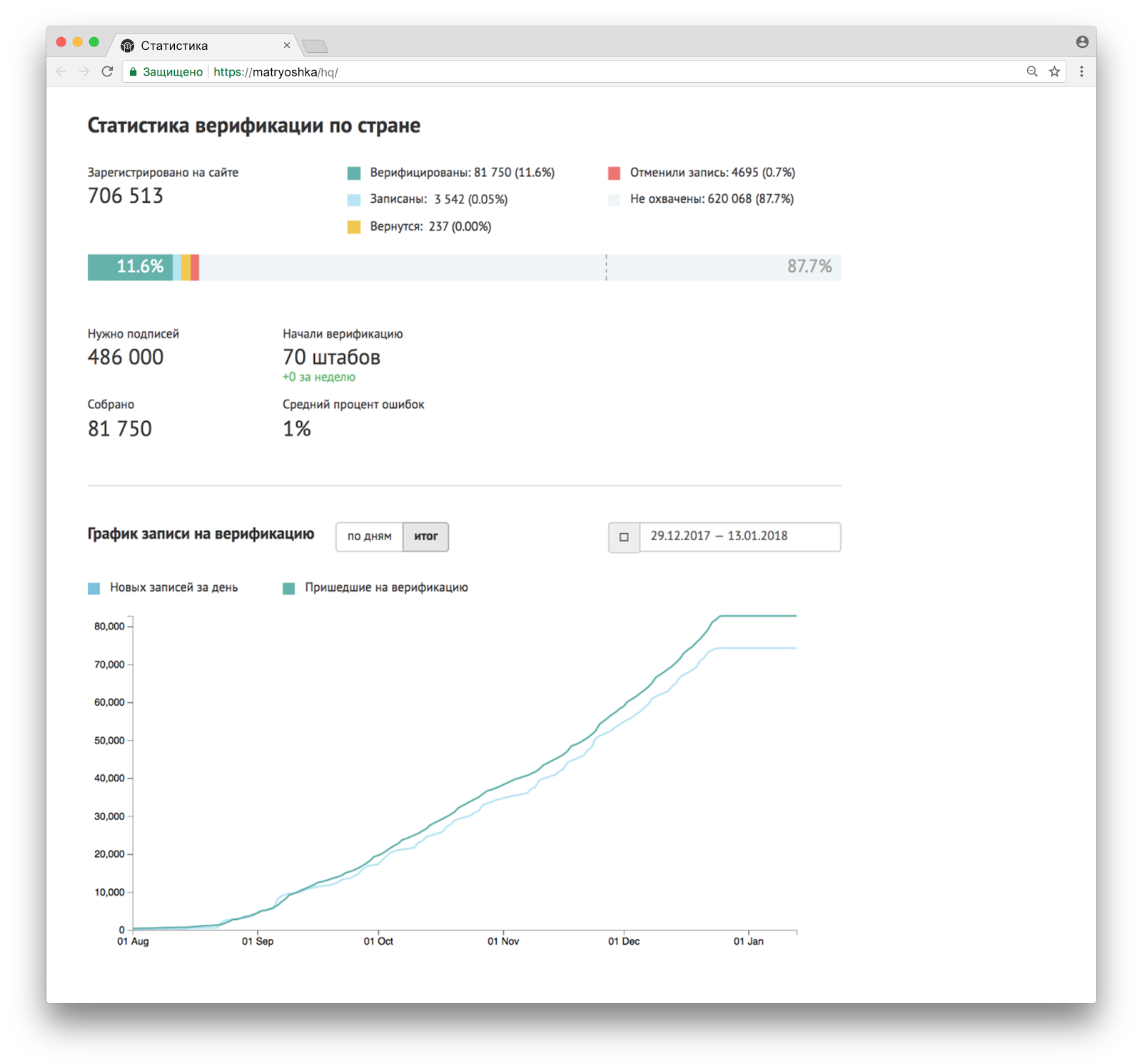
Всего в аналитике выводилось более 50 показателей. Гибкости SQLAlchemy хватило, чтобы ни разу не перейти на чистый SQL и чтобы код оставался читабельным. Для наиболее трудозатратных показателей сначала сделали кэширование в Redis, но оказалось проще периодически обсчитывать их в бэкграунде и при запросах брать из файла.
Жнец-2018: система для сбора подписей
Параллельно с ходом верификации разрабатывалась система для сбора подписей. За основу была взята архитектура системы, использованной в Новосибирске и умеющей работать с физическими объектами — листами и подписями.
Со стороны бэкенда Жнец-2018 — наследник старого Жнеца, но интерфейс оператора он получил от системы верификации. Некоторые экраны были доработаны после анализа отзывов о работе Сыча. Кроме того, были добавлены интерфейсы для нескольких уровней проверки данных и для управления движением листов.
Интерфейс оператора
В процессе получения подписи оператор должен отсканировать паспорт избирателя, заполнить анкету (учитывая, что адрес, указанный в штампе о регистрации, может быть записан совсем не в нужном формате) и внести в подписной лист данные, следуя указаниям системы. Но сначала мы должны проверить, соответствует ли избиратель трем ключевым условиям:
1. На момент выборов он должен быть старше 18 лет.
2. Если избирателю 20 или 45 лет, у него должен быть новый паспорт.
3. Паспорт не должен числиться в списке недействительных.
Проверка по базе недействительных паспортов — простая операция, но и в ней есть свои тонкости. Базу раздает МВД на своем сайте. Раньше перед выборами они зачем-то выключали возможность выгрузки этой базы, поэтому мы заранее начали ежедневно скачивать актуальную версию базы (не забыть бы это выключить).
Сейчас в базе более 110 миллионов записей (серии и номера паспортов). Для быстрого поиска при небольшом объеме базы и индексов была придумана такая схема: в PostgreSQL создается таблица с миллионом записей, первичным ключом в которой является номер паспорта (от 0 до 999999), а во втором поле записаны все серии недействительных паспортов для этого номера. Для уменьшения объема серии переведены в бинарный формат (по два байта) и сжаты с использованием zlib (просто захотелось). Исходно база занимает около 1 Гб без учета индексов. После обработки получается 260 Мб вместе с индексом. Одна запись проверяется в среднем за 15 мс.
0,6% паспортов людей, проходивших верификацию, нашлись в базе недействительных паспортов. Это значит, что без такой проверки мы бы потратили 12% от лимита недействительных подписей только на данный вид ошибок.0,88% паспортов нам не подошли, поскольку гражданину исполнилось 20 или 45 лет, но он еще не заменил паспорт. И это еще 18% от лимита недействительных подписей.
В подписном листе 4 колонки, заполняемые оператором: ФИО, год рождения, номер паспорта и адрес постоянной регистрации. Все эти данные проходили через Жнеца для проверки и коррекции возможных ошибок. Например, в полях для имени и отчества работает поиск опечаток:

Для подсказок по именам в API есть метод, который сравнивает значение с большим списком и возвращает три варианта ответа:
— все OK, есть такое имя;
— есть похожее имя (такое-то);
— неизвестное имя (редкое имя или серьезные ошибки в написании).
Отдельная история — буква «ё». Существуют паспорта, в которых она используется, но в большинстве случаев она заменяется на «е», поэтому мы выводим предупреждение, если в каком-то поле паспортных данных есть «ё».
Система ничего не исправляет сама, только информирует. Оператор и проверяющие должны обратить внимание на такие случаи и принять верное решение.
Сканирование документов
Для получения изображений документов мы используем сканеры собственного производства, а в качестве операторской станции — Raspberry Pi. Подробно это описано во второй главе.
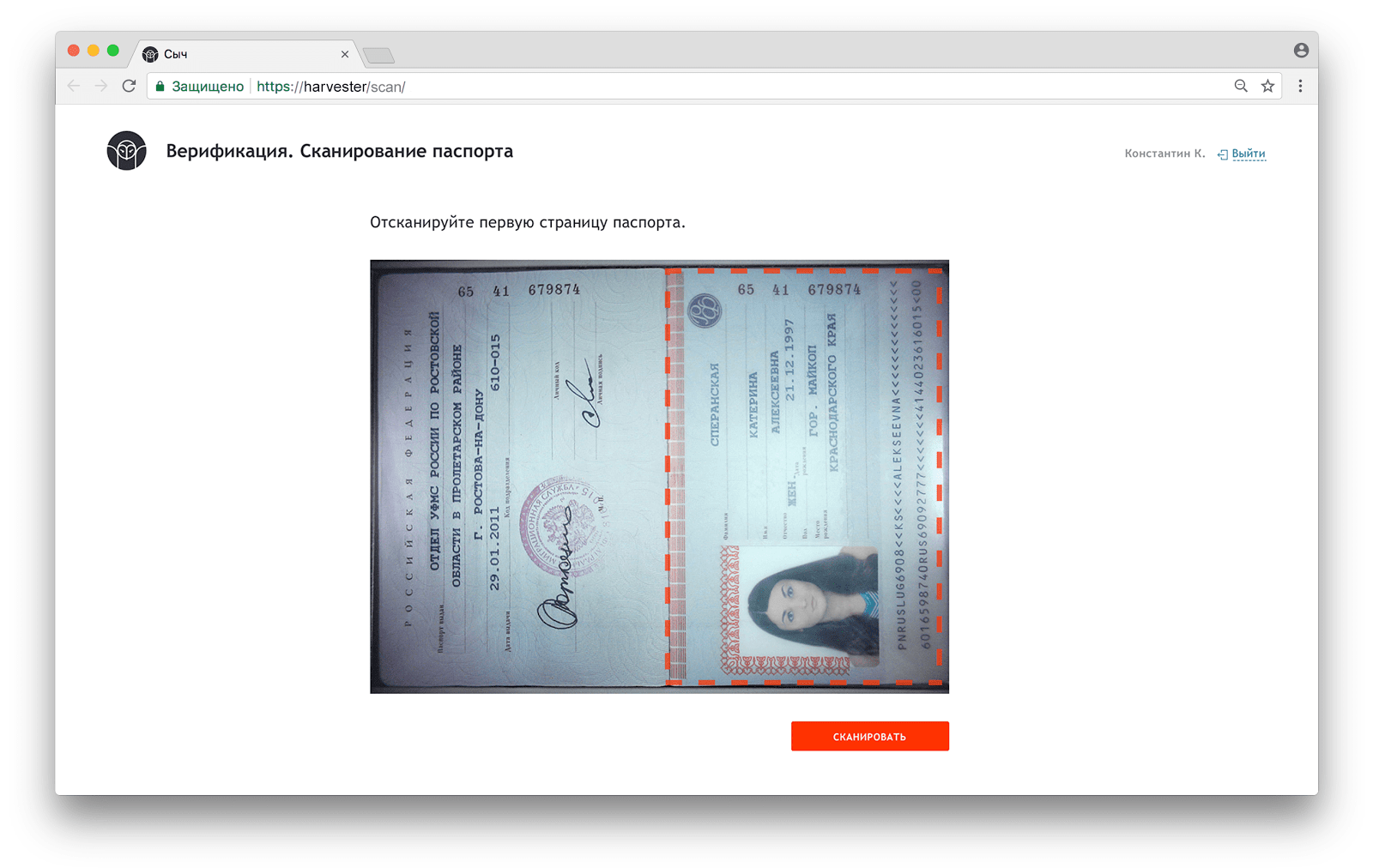
Данное изображение не является сканом паспорта, а собрано в графическом редакторе из случайных данных.
Изображение получается на клиентской стороне из HTML 5 Canvas API и отправляется на сервер в виде строки base64, в которой лежит JPEG. С точки зрения фронтенда сканеры могут работать в двух режимах: USB web-камера и стриминг видеопотока с компьютера в локальной подсети. Сыч работает только с USB-камерами, а Жнец-2018 позволяет переключаться между режимами. Оператор сам выбирает, какой сканер использовать.
С выбором видеопотока соседних компьютеров возникла небольшая проблема: столы и сканеры можно двигать, а операторы могут пересаживаться. Мы не знаем, какой сканер окажется рядом с оператором в следующий раз. Пришлось перебирать штабную подсеть и дать оператору возможность выбрать любой из живых сканеров. Но оказалось, что сервер видеотрансляции сканера, хоть и ставят корректные CORS-заголовки (Access-Control-Allow-Origin: *), не отвечают на OPTIONS-запросы. Браузер запрещал ajax-запросы на соседние хосты, из-за чего для поиска не получалось использовать обычный jQuery.ajax (). JSONP-запросы тоже не помогли, поскольку их не получалось отменить программно, а несколько десятков ожидающих запросов полностью блокировали страницу. Решить проблему помогли картинки. Мы добавляли в DOM теги и прописывали им src видеопотока. Если картинка меняла размеры в соответствии с размерами потока, то поток считался живым и показывался оператору.
Отображение видеопотока в браузере заметно нагружает скромные процессоры Raspberry Pi, поэтому нам пришлось сделать «скринсейвер»: после 5 минут бездействия браузер ставит трансляцию на паузу.
Нам важно выбрать актуальную информацию о месте регистрации. На развороте паспорта может быть 6 штампов, но нужен только один. Интерфейс предлагает выбрать его с помощью стрелок на клавиатуре или кликом по нужному штампу на превью.
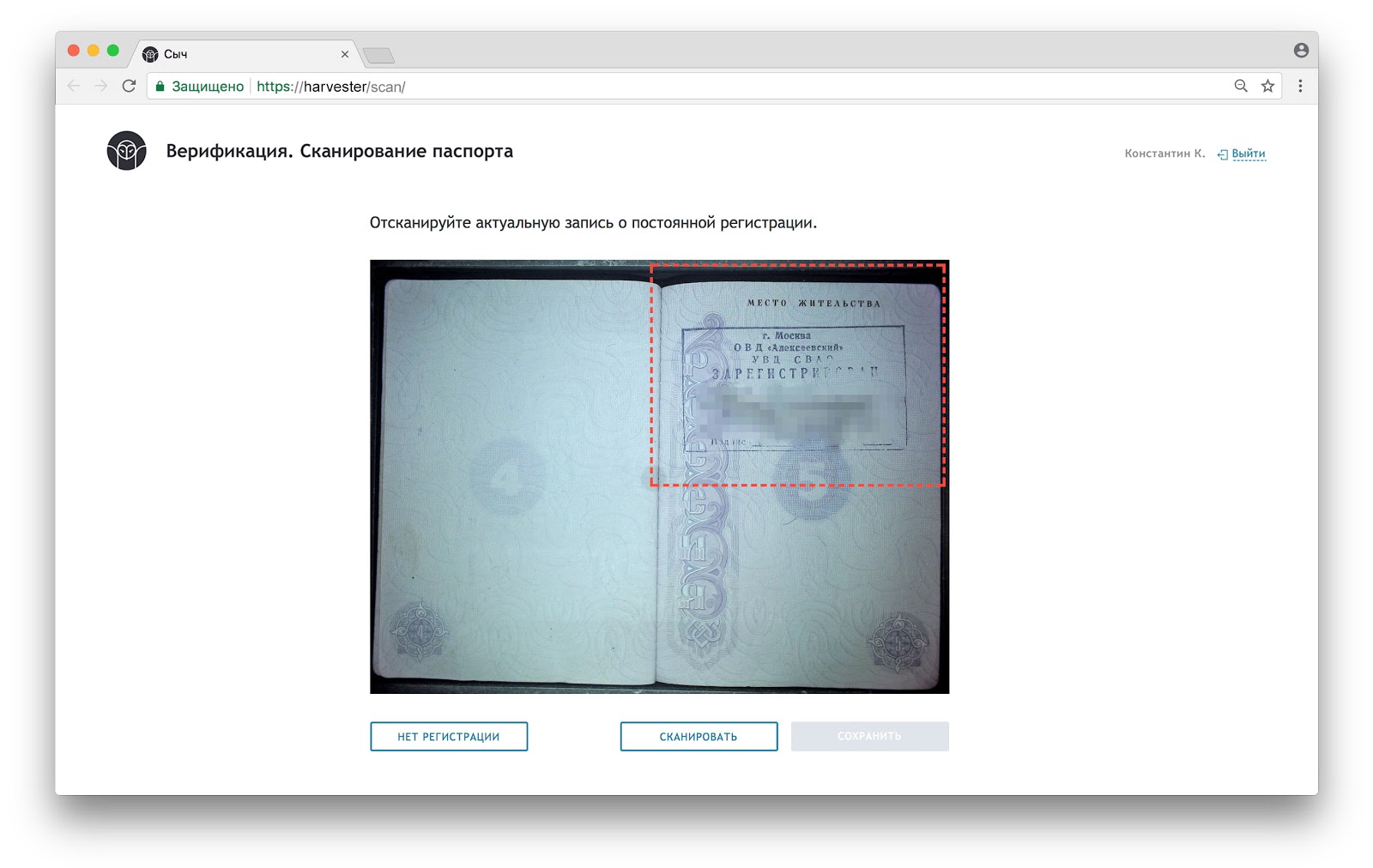
Еще регистрации может и не быть. Таких избирателей записывают в отдельный подписной лист с пустым регионом и адресом, а сканирование регистрации пропускается.
Обработка адресов
Самая сложная часть в заполнении подписного листа — адрес избирателя. Больше половины ошибок, из-за которых подпись признается недействительной, связаны с адресом.
К адресу регистрации есть большой список юридических требований. Например:
— это должен быть адрес по базе ФИАС (федеральная информационная адресная система);
— для переименованных улиц нужно указывать новые названия, даже если в паспорте было старое;
— законом устанавливается определенный формат иерархии адресных объектов, которые нужно записать (например, нельзя указывать городской район).
Это только базовые пункты, но есть и множество мелочей, список которых пополнялся при каждом взаимодействии с избирательной комиссией. Несоблюдение даже незначительных требований — повод для избиркома не принять подпись.
На сборе подписей в Новосибирске из-за претензий к полю «адрес» были признаны недействительными около 3,5% подписей. И это 70% от лимита, который установлен для подписей за выдвижение кандидата в президенты.
Чтобы выполнить все требования, мы вынуждены каждый адрес прогонять через компьютер, чтобы сформировать правильный формат и указать сборщику с точностью до символа, что он должен вписать в подписной лист.
Мы стараемся, когда это возможно, не использовать API сторонних сервисов, чтобы не отдавать данные о наших пользователях и чтобы не оказаться в ситуации, когда API внезапно выключат в самый ответственный момент. Работа с адресами — критическая для сбора подписей функция, поэтому нам пришлось сделать свой API к базе ФИАС.
В базе ФИАС пока еще нет достаточно качественных и полных сведений о домах и квартирах, поэтому мы остановились на уровне улиц. В таком виде база со всеми дополнительными построениями весит около 2 ГБ и вполне комфортно живет в виде PostgreSQL. Для импорта использовались модифицированные скрипты из репозитория fias2pgsql.
Для универсальной всероссийской формы ввода адреса нельзя просто сделать поля «город», «улица», «дом», т. к. существует множество разных форматов адресов и типов адресных объектов. Известный пример непривычного формата — Зеленоград, в котором есть дома без названия улицы. Но, поверьте, в масштабах всей страны это довольно тривиальный случай.
После серии экспериментов мы остановились на форме из трех полей:
— субъект РФ — он есть всегда, это самое понятное поле;
— адрес по ФИАС — поле с автодополнением по адресам данного региона внутри ФИАС;
— дом/корпус/квартира — строка, куда данные переписываются точно в соответствии со штампом о постоянной регистрации.

Юристы составили таблицу преобразований адресов, при помощи которой мы приводили адреса ФИАС в формат, соответствующий законодательству о выборах. Чаще всего нужно было исключить один из элементов адреса. Какие-то адреса исключали целиком (гаражные кооперативы, дворовые территории и другие подобные объекты). IT-отдел получал таблицу с правилами, а юридический отдел в ответ получал по 10 примеров на каждый из 44 типов адресов.

После нескольких таких итераций база была готова к работе.
Техническая часть задачи заключалась в организации удобного и быстрого поиска с автодополнением, который выдержит нагрузку в 1 миллион запросов за день. В качестве поискового движка использовали Sphinx. Запрос очищается от лишних символов и передается в Sphinx, а он возвращает полные адреса объектов, ранжируя их по заданным правилам.
Sphinx индексирует поле адреса, записанное в формате XML. Такой формат хранения оказался удобен тем, что все метаданные можно спрятать в XML-атрибуты, которые Sphinx не использует для поиска, но держит в памяти и возвращает в результатах без дополнительного обращения к базе данных. Где-то на фронтенде эти атрибуты используются для формирования красивой строки адреса.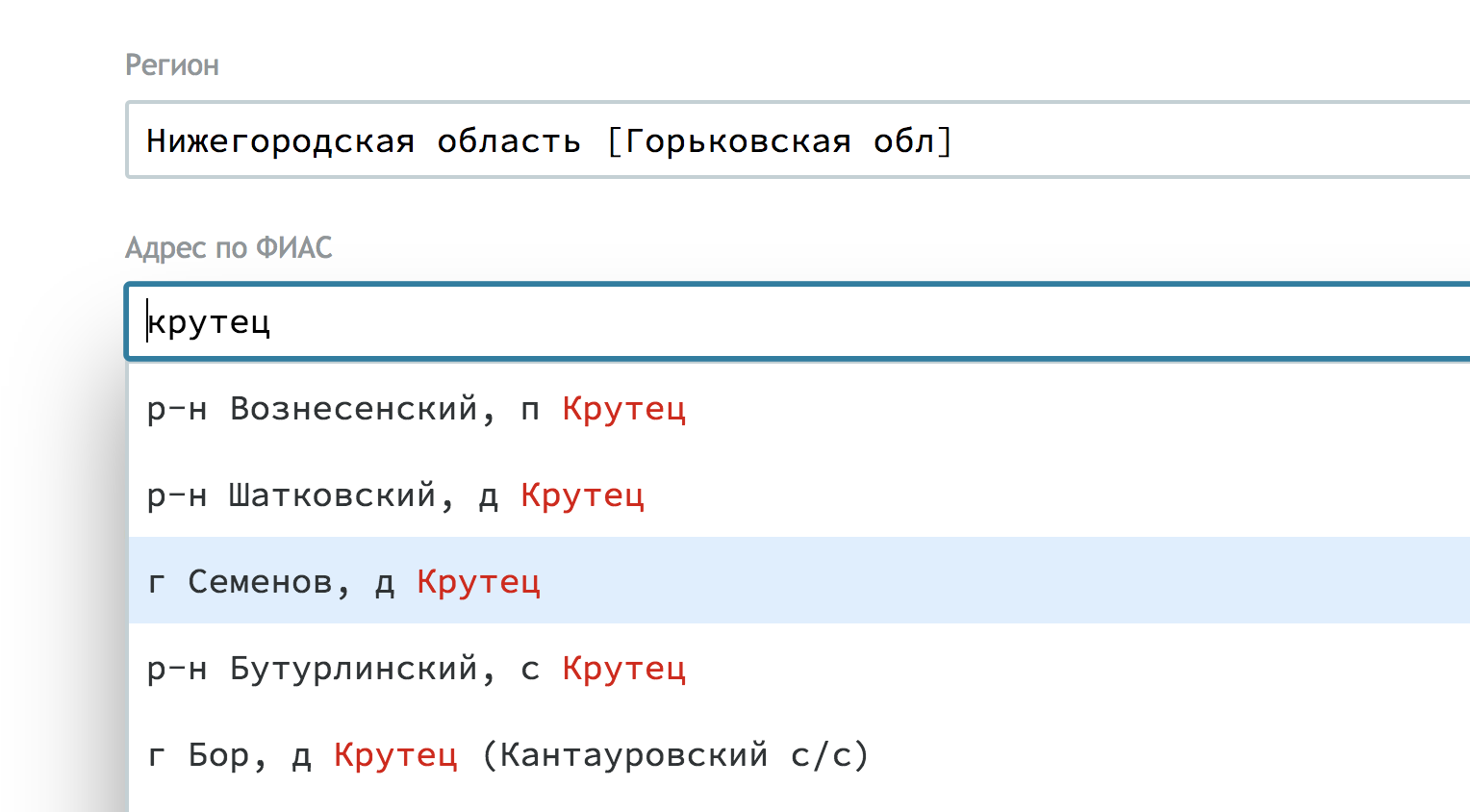
Решение получилось удобным и быстрым. Один запрос к suggest API выполняется за 15–20 мс, бэкенд спокойно обрабатывает 300 одновременных соединений на не самой мощной виртуалке.
Заполнение подписного листа
Подписи должны вноситься в листы того субъекта российской федерации, к которому принадлежит адрес постоянной регистрации гражданина (или в специальные листы без региона, если регистрации нет). Жнец сообщает оператору, лист какого региона нужно взять, и не дает внести подпись на лист другого региона.
Представьте, что вы хотите решить такую задачу без компьютера, собирая подписи на вокзале, где будет много людей из различных регионов и не будет картотечного хранилища с пустыми листами, отсортированными по региону. Примерно в трети паспортов штамп о регистрации не содержит название региона, а случайные прохожие не знают правила игры и легко могут что-то перепутать. Это выглядит как источник большого количества ошибок, что недопустимо при установленном законом лимите в 5%.
Заполнение подписного листа — сложная и ответственная процедура. На листе есть строки подписей, заверительная надпись сборщика и подпись доверенного лица. Все эти блоки должны быть заполнены в соответствии со строгими формальными требованиями. На каждом этапе заполнения возможны ошибки, которые могут сделать весь лист или часть подписей недействительными.
Мы разработали такие сценарии работы оператора, которые уменьшают вероятность возникновения типичных ошибок. Заверительные надписи листов «домашнего» региона (около 80% подписей будут из региона, в котором находится штаб) заполняются сборщиком заранее, в спокойной обстановке. Для всех блоков листа Жнец показывает, как именно они должны быть заполнены.

Интерфейс заполнения имитирует реальный подписной лист, который в данный момент лежит на столе перед оператором. Показаны занятые строки, колонки для заполнения, номер листа, крупно — данные для внесения.
Для заполненной строки оператор должен указать ее статус (не всегда строку получается заполнить успешно с первого раза). Каждому исправлению и вычеркиванию должна соответствовать пометка от сборщика на листе и соответствующий статус базе данных.
После заполнения всего листа на нем проставляется дата и подпись сборщика. Лист передается на проверку.
Проверка подписей, работа с листами в штабе
В конце каждого рабочего дня все листы с подписями попадают на проверку, которая происходит поздним вечером или ночью (штабы у нас небольшие, вести все процессы параллельно просто негде). Проверяющий (он же — доверенное лицо кандидата) просматривает каждый лист и каждую подпись, сравнивает с фрагментами отсканированных страниц паспорта, проверяет по чек-листу все значимые элементы. Если обнаруживаются ошибки, это отмечается в специальном интерфейсе.
Отдельно проверяется заверительная запись. Ошибки при заверении особенно опасны, поскольку затрагивают сразу весь лист. Такими ошибками обусловлено происхождение примерно 9% всех недействительных подписей.
Некоторые ошибки можно исправить, но вносить исправления в строки подписей может только сборщик, а его вечером/ночью в штабе нет, поэтому вся необходимая для исправления информация передается в электронном виде. Для понимания контекста, необходимо видеть все, что происходило со строкой ранее. Так появился «чат» между проверяющим, оператором и юристом.
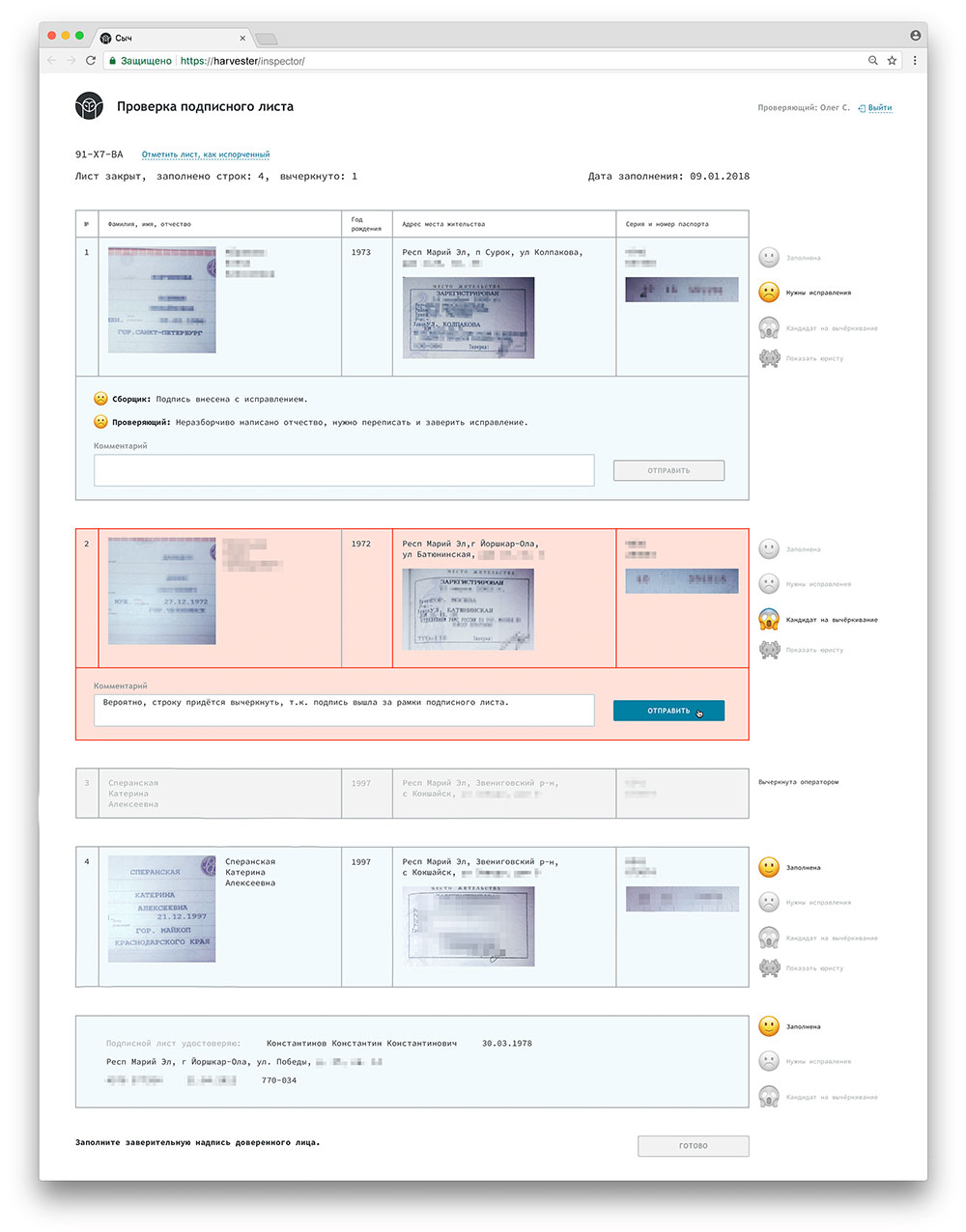
Все имена и другие данные на изображении являются выдуманными
Если ошибки кажутся фатальными или есть какие-то сомнения, лист отправляется к юристу. Если подписи не содержат ошибок или все исправления уже сделаны, проверяющий ставит подпись доверенного лица и передает лист на отправку в центральный штаб.
Смайлики и нейрофизиология счастья
Для быстрого и безошибочного выбора статуса проверяемой строки мы использовали кнопки в виде смайликов. У этого есть глубокие нейрофизиологические причины. В зрительной системе мозга есть древние низкоуровневые механизмы, которые реагируют на определенные образы. Быстрее всего зрительная система реагирует на отрезки прямых линий разных ориентаций, поскольку линии легко детектируются первичной зрительной корой. Во вторичной зрительной коре распознаются простые геометрические фигуры (этому нужно учиться) и схема лица. Причем, распознается не просто лицо, а основные мимические выражения. То есть, смайлики. Как и распознавание прямых линий, это врожденная способность. Благодаря такой низкоуровневой системе смайлики узнаются значительно быстрее и точнее, чем текст.

Иконки в виде смайликов хорошо соответствуют смыслу статусов, которые проверяющий может присвоить подписи: «хорошая», «есть проблемы», «плохая». Были некоторые сомнения со смайликом «показать юристу», но мы с этим справились.
Еще есть мнение, что смайлики очеловечивают интерфейс и тем самым немного улучшают жизнь оператора. Это важно, т.к. операторы должны были проводить долгие часы за работой с нашей системой и не терять бдительность.
Отправка листов
Готовые листы каждый день отправляются в центральный штаб. Листов может быть много, несколько сотен. Мы хотим точно знать, какие листы готовы и уехали из штаба, но ручная их регистрация — это долго и ненадежно. Для учета отправляемых листов написано мобильное приложение.
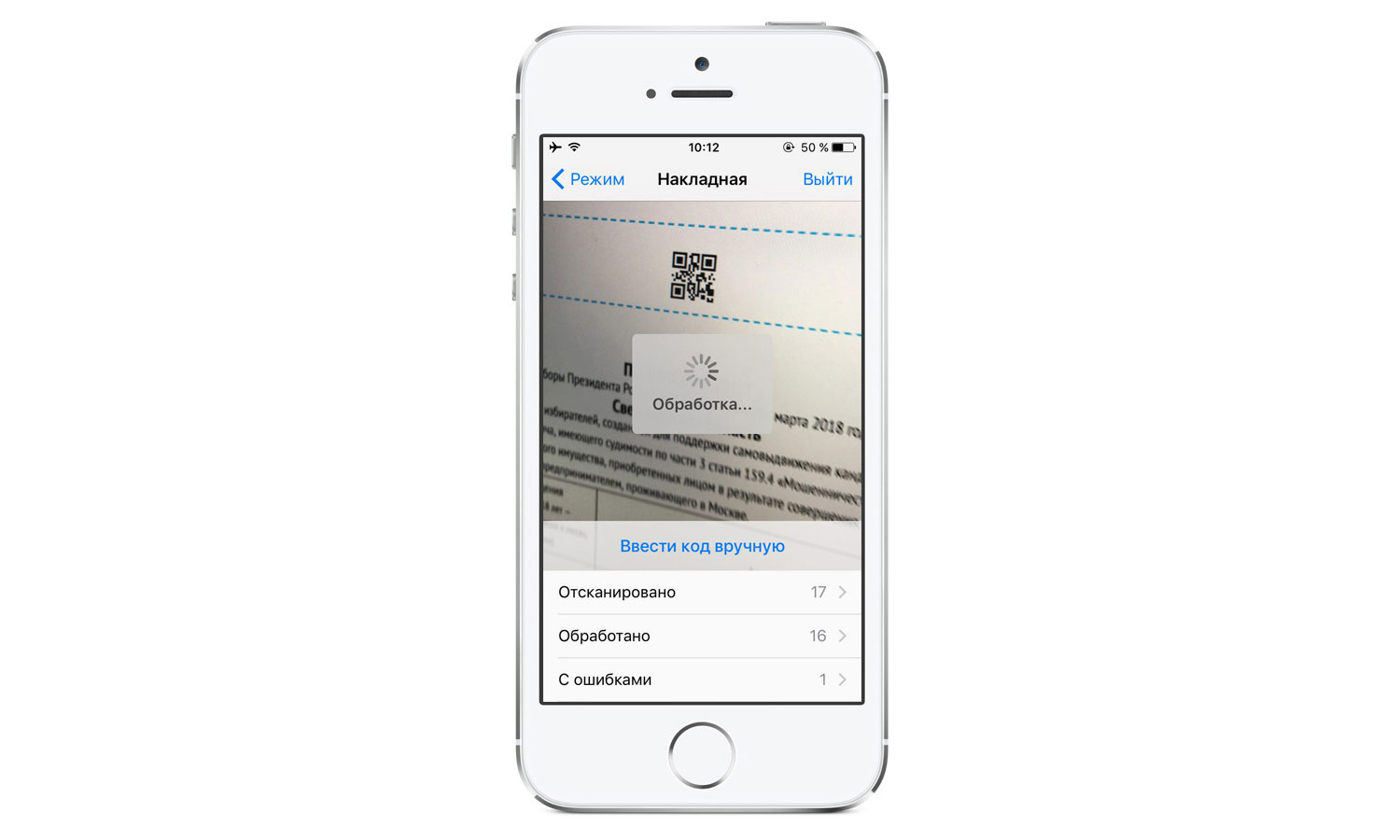
У него есть режим, который позволяет быстро просканировать коды сотен листов, и сообщает, если какой-то лист пытаются отправить по ошибке, когда он еще не прошел все этапы обработки в штабе. На сканирование одного листа уходит 1–2 секунды.
После сканирования листы упаковывают и отправляют в Москву.
Детали форм
Все паспортные данные вводятся и отображаются моноширинным шрифтом Source Code Pro Regular. В нем ноль легко отличить от буквы «О», а символы достаточно похожи на те, что обычно используются в современных паспортах.
Все формы сделаны так, чтобы между полями и основными кнопками можно было переключаться табуляцией. Фокус ввода находится в нужном поле не только при загрузке страницы, но и после закрытия сообщения об ошибке. Модальные диалоги захватывают фокус, чтобы переключение происходило только между их элементами управления.

Все кнопки, при нажатии которых происходит что-то продолжительное, показывают это всем своим видом. Поля ввода на время отправки данных выключаются. При ошибках появляются подробные пояснения.
Логистика и физическое хранение листов
Перекладывание бумажек — один из видов деятельности, в котором человечество достигло невероятных успехов. Казалось бы, можно пойти в магазин канцтоваров, купить набор для сбора подписей «Федеральный» и не думать о подробностях. Но есть проблема: все офисные решения стоят слишком дорого. Мы не можем поставить в каждый штаб сканеры документов за несколько десятков тысяч рублей и шкафы с подвесными папками за сто тысяч, поэтому на каждом этапе приходилось что-то изобретать и создавать из подручных материалов.
Немного фактов о физике процесса
Нам нужно сдать 315 тысяч подписей. Для этого, с учетом региональных квот и запаса на различные ошибки, нужно собрать и обработать около 1 миллиона подписей. На каждом листе может быть максимум пять подписей, но в реальности будет где-то 3–4. Это дает нам, грубо говоря, 300 тысяч листов.
Лист бумаги формата А4 имеет площадь 1/16 м².
Плотность обычной офисной бумаги — 80 г/м², каждый лист весит 5 г.
Высота пачки из 500 листов — 4,5 см для чистых листов, более 6 см для заполненных.
Получается, все собранные листы будут весить 1,5 тонны, а сложенные в одну пачку они будут около 36 метров в высоту.
Как все это хранить?
Подписные листы печатаются, заполняются подписями, проверяются, заверяются и ежедневно отправляются в центральный штаб. Один штаб отправляет в день несколько сотен листов, поэтому на данном этапе проблемы быть не должно.
Самое интересное начинается в центральном штабе. Там нужно организовать такую систему хранения, которая позволит легко принимать листы из региональных штабов и работать с ними до конца сбора. После завершения сбора листы должны быть сгруппированы по регионам (регион листа говорит о том, жители какого региона оставляют в нем подписи) и сшиты в папки для избиркома.
Мы не можем просто складывать листы в бесконечные пачки, поскольку юристы в любой момент могут захотеть изъять часть листов по определенной выборке. Нужно знать, где конкретно находится каждый лист, уметь быстро достать его и вернуть обратно.
Для быстрого доступа была придумана система индексации физической базы листов. Индекс состоит из нескольких уровней: штаб (ящик), коробка, папка. Адрес папки в архиве выглядит так: 77−1−15. Внутри каждой папки лежит 25 листов (в произвольном порядке).

На левой верхней картинке — коробка на 500 подписных листов в бумажных папках.
На правой картинке — ящик на 2000 листов в подвесных папках.
Получение и сортировка листов
Все листы, приезжающие из регионов, сканируются автоматическим двухсторонним сканером (он уже был в офисе, поэтому не пришлось собирать его самим из LEGO и Arduino). Этот аппарат умеет заливать результат на сервер по SFTP. Там сканы прогоняются через python-скрипт, который ищет QR-коды в стандартных местах, распознает их и привязывает сканы к общей базе данных. Скрипт надежно обрабатывает даже мятые листы.

После сканирования листы идут на сортировку. Каждый лист сканируется при помощи мобильного приложения (режим сортировки). Оно находит лист в системе, меняет статус на «приехал в центральный штаб» и показывает координаты папки, в которую лист нужно положить. Оператор подтверждает, что положил лист в указанную папку (закрывает транзакцию).

Листы одного региона размещаются в папке последовательно, пока в ней есть место, поэтому весь процесс происходит очень быстро.
Бэкенд
Жнец-2018 сделан на Django со стандартным шаблонизатором и ORM. В качестве базы данных используется PostgreSQL. Служебные части системы — ФИАС, проверка паспортов, работа с данными предварительной регистрации — вынесены в отдельные модули (django app) со своими базами данных.
Физический мир подписей представлен в виде нескольких классов объектов: подписной лист, строка в листе, подпись. У объектов этих классов есть атрибуты, отражающие состояние объекта в реальном мире. Для управления состояниями использован шаблон «конечный автомат» (машина состояний, finite state machine) и библиотека django-fsm. Все переходы между состояниями прописаны в виде FSM-транзакций, внутри которых проводятся необходимые проверки и дополнительные действия с объектом.
Схема состояний выглядит примерно так:
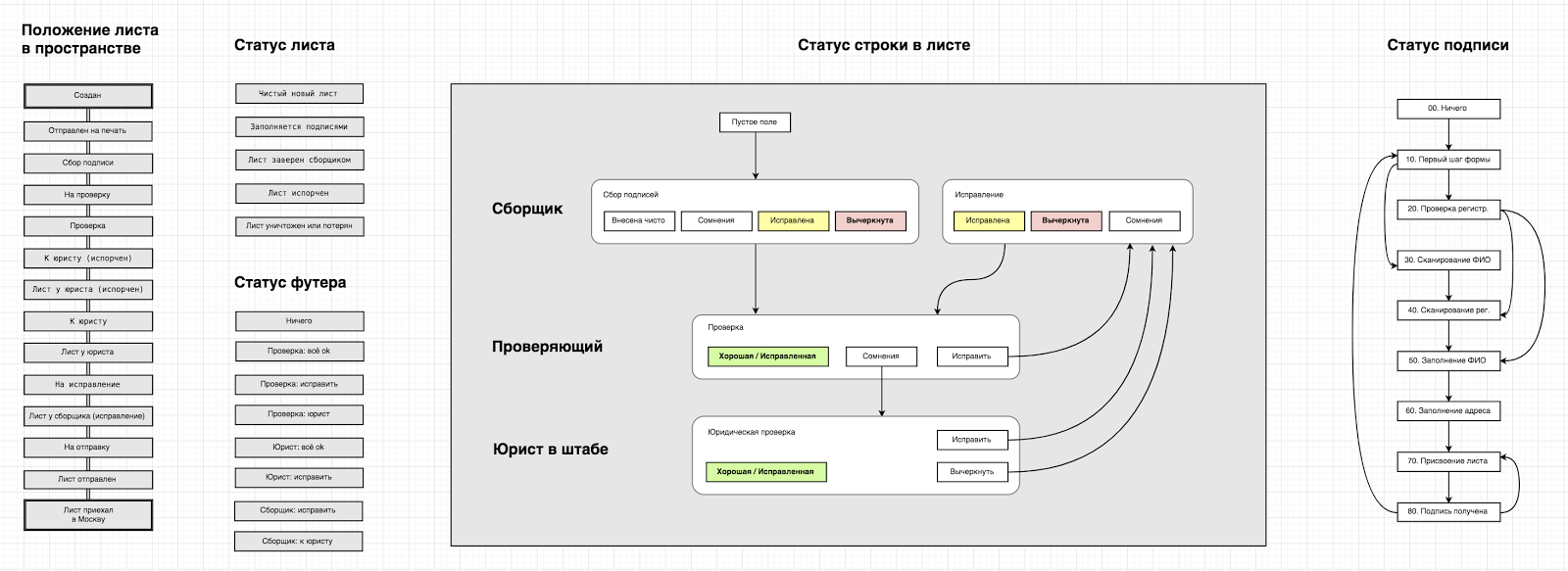
Положение листа в пространстве определяется состоянием строк, которые в нем содержатся. Если есть строки, которые должен проверить юрист, лист получает статус «к юристу». Как только юрист взял лист и ввел его код в интерфейсе проверки, лист получает статус «у юриста». Таким образом мы всегда знаем точное положение всех листов и понимаем их ближайшую судьбу.
Тестирование
У системы сбора подписей слишком много различных состояний и переходов между ними, чтобы проверять это вручную. Для автоматизации проверок все сценарии, связанные с работой операторов и проверяющих, покрыты тестами на стороне django.
Бесполезно смотреть на систему сбора миллиона подписей, когда в ней нет этих подписей. Для наполнения базы были написаны скрипты, которые инициализируют типичное состояние базы в процессе сбора, чтобы можно было посмотреть на систему, наполненную чем-то похожим на реальные данные.
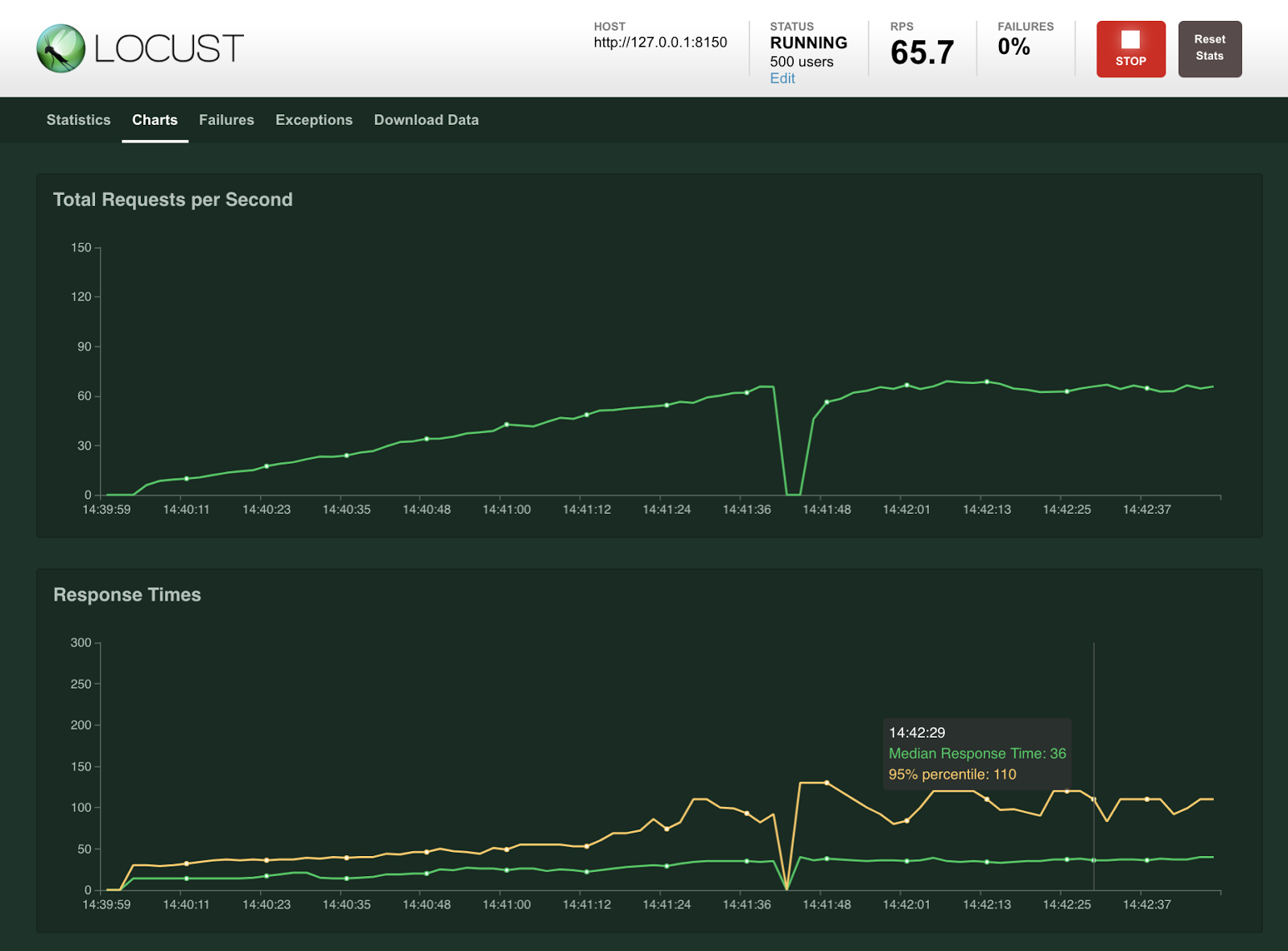
Сбор подписей сильно ограничен по времени, а значительная часть этого времени приходится в этот раз на новогодние праздники. Мы ожидали, что нагрузка на штабы и систему сбора будет неравномерной. Важно было, чтобы система легко справлялась с любым реалистичным потоком подписей. В пиковые моменты ожидалось до 10 тысяч подписей за час. Для обычного веб-сайта это выглядит несерьезно, но в нашем случае такой порядок «посетителей» может создать большую нагрузку на сервер. Это не просто посещения или регистрации: получение каждой подписи предполагает около 50 запросов к серверу и обработку нескольких изображений высокого разрешения.
Нагрузочное тестирование проводилось при помощи Locust. Это простой инструмент, доступный через PyPI. Сценарии описываются в виде кода на питоне, примерно как юнит-тесты в Django:

Тесты можно запускать через веб-интерфейс, в котором выводятся графики скорости запросов, количества клиентов и времени ответа сервера.
Развертывание проекта организовано так же, как для сайта «Навальный 20!8».
Доступ к веб-приложениям Жнеца возможен только через
