История победы на международном соревновании по распознаванию документов команды компании SmartEngines
Привет, Хабр! Сегодня мы расскажем о том, как нашей команде из Smart Engines удалось победить на международном конкурсе по бинаризации документов DIBCO17, проводимом в рамках конференции ICDAR. Данный конкурс проводится регулярно и уже имеет солидную историю (он проводится 9 лет), за время которой было предложено множество невероятно интересных и безумных (в хорошем смысле) алгоритмов бинаризации. Несмотря на то, что в своих проектах по распознаванию документов при помощи мобильных устройств мы по возможности не используем подобные алгоритмы, команде показалось, что нам есть что предложить мировому сообществу, и в этом году мы впервые приняли решение участвовать в конкурсе.

Для начала расскажем вкратце в чем состоит его суть: дано подготовленное организаторами множество цветных изображений документов S (пример одного из таких изображений приведен на рисунке слева) и множество соответствующих им идеальных (с точки зрения все тех же организаторов) бинарных образов I (ground truth, ожидаемый результат для примера приведен на рисунке справа). Требуется построить алгоритм A, переводящий исходные изображения из S в двухуровневые черно-белые a(A) (т.е. решить задачу классификации каждого пикселя как принадлежащего объекту или фону), таким образом, чтобы эти результирующие изображения оказались как можно «ближе» к соответствующим идеальным из I. Множество метрик, по которым оценивается эта близость, конечно же, зафиксировано в условиях конкурса. Особенностью данного конкурса является то, что ни одно тестовое изображение конкурсантам заранее не предоставляется, для настройки и подготовки доступны данные с прошедших контестов. При этом, новые данные каждый раз содержат свою собственную «изюминку», отличающую их от предыдущих конкурсов (например, наличие тонких «акварельных» текстовых начертаний или просвечивающиеся с противоположной стороны символы) и предъявляющие новые вызовы для участников. Конкурс регулярно собирает порядка двух-трех десятков участников со всего мира. Далее приводится описание нашего конкурсного решения.


Схема решения
Первым делом были собраны данные со всех предыдущих конкурсов. Всего удалось загрузить 65 изображений рукописных документов и 21 изображение печатных. Очевидно, что для достижения высоких результатов необходимо было смотреть на проблему более широким взглядом, поэтому помимо анализа изображений от организаторов, своими силами был осуществлен поиск открытых датасетов с архивными печатными и рукописными документами. Организаторами не запрещалось использование сторонних датасетов. Было успешно найдено несколько тысяч изображений, по своей природе подходящих под условия конкурса (данные с различных тематических конкурсов, организованных ICDAR, проект READ и другие). После изучения и классификации этих документов стало понятно с какими классами проблем мы можем столкнуться в принципе, и какие из них оставались до сих пор проигнорированы организаторами конкурса. Например, ни в одном из предшествующих конкурсов документы не содержали никаких элементов разграфки, хотя таблицы нередко встречаются в архивах.
При подготовке к конкурсу мы шли параллельно несколькими путями. Помимо классических алгоритмических подходов, хорошо исследованных нами ранее, было решено опробовать методы машинного обучения для пиксельной классификации объект-фон, несмотря на столь незначительное множество исходно предоставленных данных. Поскольку в конце концов именно этот подход оказался наиболее эффективным, о нем мы и расскажем.
Выбор архитектуры сети
В качестве первоначального варианта была выбрана нейронная сеть архитектуры U-net. Подобная архитектура хорошо зарекомендовала себя при решении задач сегментации в различных соревнованиях (например 1, 2, 3). Важным соображением было и то, что большой класс известных алгоритмов бинаризации явно выразим в такой архитектуре или подобной архитектуре (в качестве примера можно взять модификацию алгоритма Ниблэка с заменой среднеквадратичного отклонения на средний модуль отклонения, в этом случае сеть строится особенно просто).
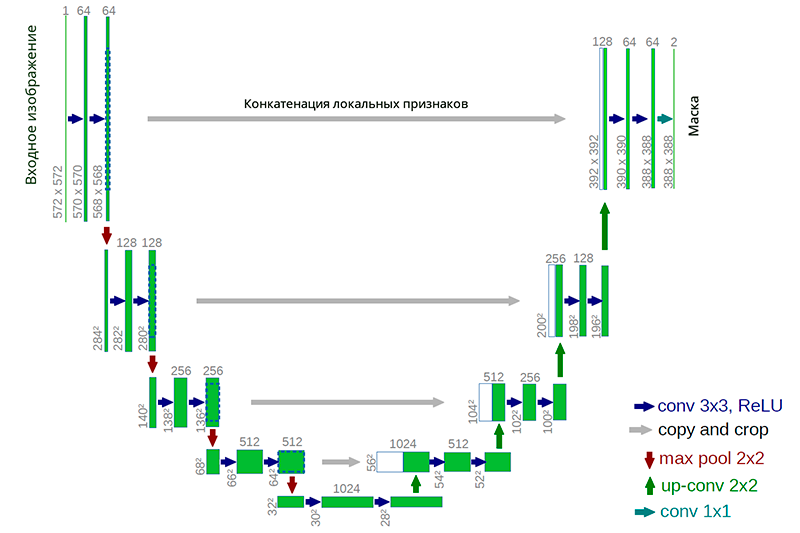
Пример нейронной сети U-net архитектуры
Преимущество же такой архитектуры состоит в том, что для обучения сети можно создать достаточное количество обучающих данных из небольшого числа исходных изображений. При этом сеть имеет сравнительно малое число весов за счет своей сверточной архитектуры. Но есть и свои нюансы. В частности, используемая искусственная нейронная сеть, строго говоря, не решает задачу бинаризации: каждому пикселю исходного изображения она ставит в соответствие некоторое число от 0 до 1, которое характеризует степень принадлежности данного пикселя к одному из классов (содержательное заполнение или фон) и которое необходимо еще преобразовать в финальный бинарный ответ.
В качестве обучающей выборки было взято 80% исходных изображений. Остальные 20% изображений были выделены на валидацию и тестирование. Изображения из цветных были сконвертированы в градации серого, для избежания переобучения, после чего все они были нарезаны на неперекрывающиеся окна размером 128×128 пикселей. Оптимальный размер окна подбирался эмпирически (пробовались окна от 16×16 до 512×512). Первоначально не применялось никаких методов аугментации и таким образом из сотни первоначальных изображений было получено порядка 70 тысяч окон, которые подавались на вход нейронной сети. Каждому такому окну изображения была поставлена в соответствие бинарная маска, вырезанная из разметки.

Примеры окон
Настройка параметров нейронной сети, процесса обучения и аугментации данных происходили в ручном режиме, поскольку время каждого эксперимента (аугментация данных, обучение / дообучение сети, валидация и тестирование решения) составляло несколько часов, да и принцип работы «внимательно вглядываться и понимать, что происходит» по нашему мнению более предпочтителен, чем запускать hyperopt на неделю. В качестве метода стохастической оптимизации был выбран Adam. Кросс-энтропия была использована в качестве метрики для функции потерь.
Первичные эксперименты
Уже первые эксперименты показали, что подобный подход позволяет достичь качества выше, чем простейшие необучаемые методы (типа Отцу или Ниблэка). Нейронная сеть хорошо обучалась и процесс обучения быстро сходился к приемлемому минимуму. Далее приведено несколько примеров анимации процесса обучения сети. Первые два изображения взяты из оригинальных датасетов, третье найдено в одном из архивов.
Каждая из анимаций была получена следующим образом: в процессе обучения нейронной сети, по мере улучшения качества, через сеть прогоняется одно и то же исходное изображение. Полученные результаты работы сети склеиваются в одну gif анимацию.
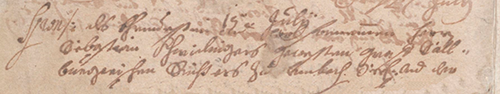
Исходное изображение рукописного текста со сложным фоном

Результат бинаризации по мере обучения сети
Сложность бинаризации вышеприведённого примера в том, чтобы отличить неоднородный фон от витиеватого почерка. Часть букв размыта, с оборота проступает текст с другой страницы, кляксы. Тот, кто писал эту рукопись, явно не самый аккуратный человек своего времени =).

Исходное изображение печатного текста с проступившим текстом предыдущей страницы

Результат бинаризации по мере обучения сети
На этом примере, помимо неоднородного фона также присутствует текст, проступивший с предыдущей страницы. Отличие, по которому можно определить, что проступивший текст нужно классифицировать как «фон» — неправильное «зеркальное» начертание символов.


Изображение с таблицей и результат его бинаризации в процессе обучения сети
После каждого эксперимента мы дополнительно оценивали релевантность полученной модели на множестве отобранных данных из открытых архивов и на различных типах печатных документов и анкет. Было замечено, что при применении сети к примерам из этих данных результат работы алгоритма являлся зачастую неудовлетворительным. Было принято решение добавить такие изображения в обучающую выборку. Наиболее проблемными случаями являлись края страниц документов и линии их разметки. Всего было выбрано 5 дополнительных изображений, содержащих интересующие объекты. Первичная бинаризация была проведена с помощью имеющейся версии сети, после чего пиксели были верифицированы экспертом, а получившиеся изображения были добавлены в обучающую выборку.


На примере выше можно заметить, что сеть выделяет края страниц, что является ошибкой


Здесь, помимо ошибок сети на краях страниц, есть ещё очень «неуверенное» выделение линий таблицы и текста внутри неё
Применяемые техники аугментации и как они помогают
В процессе обучения сети, и анализа ошибок для повышения качества использовались методы аугментации данных. Применялись следующие виды искажений: отражения изображений относительно осей, яркостные, проективные, шумы (гауссов шум, соль-перец), пробовались эластичные трансформации, наподобие вот таких таких, вариация масштаба изображения. Применение каждого из них обусловлено спецификой задачи, наблюдаемыми ошибками в работе сети, а также распространенными практиками.

Пример комбинации нескольких методов аугментации, применяющихся «на лету» в процессе обучения сети
Поскольку при генерации данных со всеми различными искажениями и их комбинациями число примеров растёт стремительно, применяется аугментация на лету, при которой раздутие выборки происходят непосредственно перед подачей примеров на обучение. Схематично это можно изобразить так:
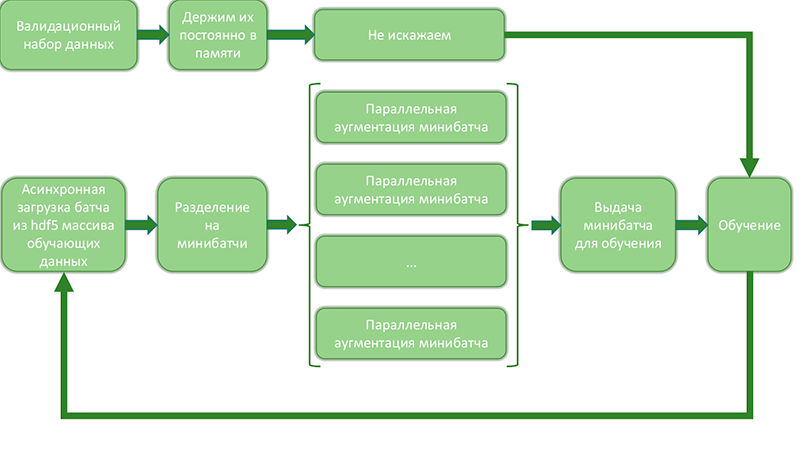
Схема, отображающая процесс раздутия данных на лету и выдачу на обучение
Подобный подход позволяет оптимизировать процесс раздутия данных и обучения сети, поскольку:
- уменьшается число обращений к дисковому массиву и оно происходит последовательно, что позволяет многократно ускорить загрузку данных.
- параллельная аугментация данных в минибатчах происходит независимо и эффективно использует все ядра машины. Часть самых ресурсозатратных операций можно переписать с помощью theano/tensorflow и вычислять на 2-ом gpu.
- переодически происходит сохранение отдельных минибатчей на диск, что позволяет проверять процесс обучения и раздутия данных.
- большая часть памяти остаётся незанятой, поскольку одновременно в ней хранится около 20% всех данных (валидационный набор и текущий батч). Это позволяет шарахнуть 5 экспериментов разом эффективно использовать вычислительные ресурсы сервера.
В целом, хотелось бы отметить важность правильной аугментации — благодаря данной технике можно обучить более сложную и умную сеть с одной стороны, а с другой — избежать переобучения и быть уверенным, что на тестовой выборке качество работы сети будет не хуже чем при обучении и валидации. Некоторые специалисты, по непонятным причинам, пренебрегают работой с данными и ищут способ улучшить работу системы только за счёт изменения архитектуры сетей. С нашей точки зрения, работа с данными не менее, а чаще — более важна, чем вдумчивый подбор параметров архитектуры сети.
Повышение качества
Процесс повышения качества решения происходил итеративно. В основном работа шла по трём направлениям:
- Анализ ошибок сети и работа с данными.
- Доработка архитектуры сети, настройка гиперпараметров слоёв и механизмов регуляризации.
- Построение ансамбля на основе нейросетевых и обычных методов.
Работа с данными происходила следующими циклами:
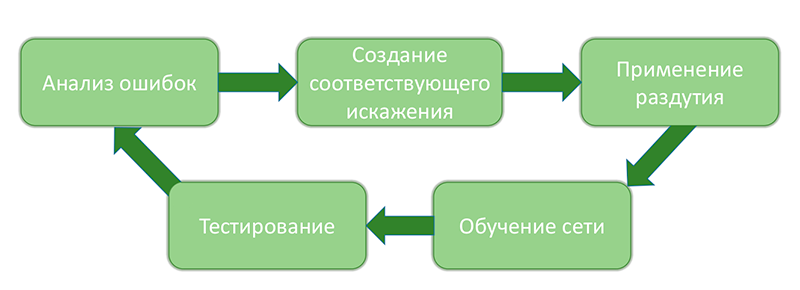
Процесс анализа ошибок системы их устранение
Подробно работу с данными можно описать так: после каждого значительного этапа изменения системы (с улучшением качества, как мы каждый раз надеялись) подсчитывались различные метрики и статистики путём кросс-валидации. Отписывалось порядка 2000 «окон» (но не больше 50 окон с одного изображения), на которых ошибка достигала максимальной величины согласно квадратичной метрике и изображения из которых эти окна были вырезаны. Затем проводился анализ этих изображений и их классификация по типу ошибки. Результат выглядел примерно вот так:
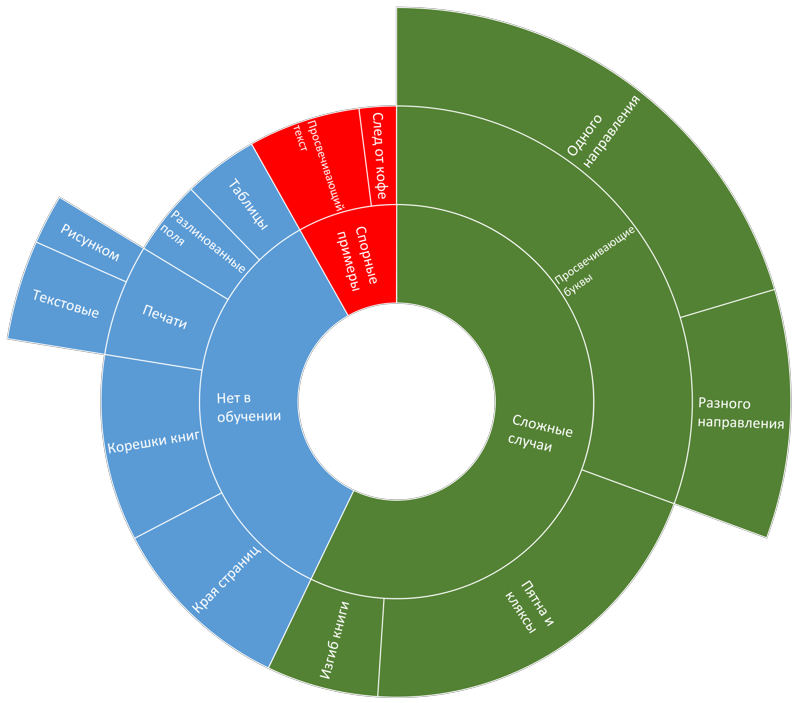
Пример диаграммы распределения ошибок
Далее выбирается самый распространённый тип ошибок. Создаётся искажение, которое имитирует изображения с этим типом ошибок. Проверяется, что текущая версия системы действительно ошибается на искаженном изображении и ошибка возникает вследствии добавленного искажения. Затем, созданная процедура аугментации добавляется к набору уже существующих и применяется в процессе обучения. После обучения новой сети и обновления подстроечных параметров системы, происходит новый анализ и классификация ошибок. Как финальный этап цикла — проверяем, что качество растёт и число ошибок конкретного типа сильно уменьшилось. Естественно, здесь описан весьма «идеалистичный» ход развития событий =). Например для некоторых типов ошибок крайне сложно создать подходящие искажения или при добавлении искаженных изображений один тип ошибок может исчезать, а три других проявляться. Тем не менее подобная методология позволяет нивелировать 80% ошибок, возникающих на разных этапах построения системы.
Пример: на некоторых изображениях присутствует шум от неоднородного фона, клякс и, в частности, зернистость пергамента. Ошибки, проявляющиеся на подобных примерах, можно подавить с помощью дополнительного зашумления исходного изображения.

Пример имитации «зернистого пергамента» с помощью искажения
Процесс оптимизации архитектуры нейронной сети и гиперпараметров слоёв осуществлялся в нескольких направлениях:
- Вариация текущей архитектуры сети по глубине / количеству слоёв / числу фильтров и т.д.
- Проверка других архитектур для решения нашей задачи (VGG, Resnet и т.д.). Для проверки возможности использования уже обученных нейронных сетей были исследованы сети архитектур VGG и Resnet. Использовалось два подхода:
- С выходов различных слоёв каждой из сетей отписывались вектор признаки, которые использовались как вход полносвязной нейронной сети, обучаемой решать задачу классификации. При этом обучалась только «финальная» полносвязная нейронная сеть, а сети, поставляющие признаки, оставались неизменны. Для уменьшения размерности входного пространства полносвязной сети применялось сингулярное разложение.
- Второй подход заключался в том, что мы заменяли последнии N слоёв одной из сетей (например VGG) полносвязными и дообучали всю сеть целиком. Т.е. просто использовали готовые веса в качестве первоначальной инициализации.
В целом нужно сказать, что оба подхода дали некоторые результаты, но по качеству и надёжности уступали подходу обучения U-net сети «с нуля».
Процесс ensembling
Следующий этап создания финального решения — построение ансамбля из нескольких решений. Для построения ансамбля мы использовали 3 U-net сети, различной архитектуры, обученных на разных наборах данных и один необучаемый метод бинаризации, который применялся только на краях изображения (для отсечения краёв страниц).
Мы пробовали строить ансамбль двумя различными способами:
- Усреднением ответов.
- Взвешенной суммой ответов. Вклад в финальный ответ определялся качеством работы на валидационной выборке.
В процессе работы над ансамблем нам удалось достичь улучшения качества по сравнению c одной U-net сетью. Однако, улучшение было очень незначительным, а время работы ансамбля, состоящего из нескольких сетей было крайне велико. Даже несмотря на то, что в данном соревновании не было ограничения по времени работы алгоритма, совесть не позволила нам коммитить подобное решение.
Выбор финального решения
По мере продвижения к финальной версии алгоритма, каждый из этапов (добавление доразмеченных данных, вариация структуры, раздутия и т.д.) подвергался процессу кросс-валидации, для понимания того всё ли мы делаем правильно.
Финальное решение было выбрано основываясь на этой статистике. Им стало ровно одна U-net сеть, хорошо обученная с применение всего описанного выше + отсечение по порогу.
Одним из возможных способов предоставления решения организаторам, было создание докер контейнера с образом решения. К сожалению не было возможности использовать контейнер с поддержкой gpu (требование организаторов), и финальный расчёт шёл только на cpu. В связи с этим так же были убраны некоторые хитрые трюки, позволяющее немного повысить качество. Например первоначально, каждое изображение мы прогоняли через сетку несколько раз:
- обычное изображение
- зеркально отраженное
- перевернутое
- немного уменьшенное
- немного увеличенное
Затем полученные результаты усреднялись.
Как показали последующие результаты, даже без подобных ухищрений качества работы сети хватило с запасом, чтобы занять первое место на обоих тестовых датасетах =)
Результаты
В текущем году в соревновании приняли участие 18 коллективов со всего мира. Были участники из США, Китая, Индии, Европы, стран Ближнего Востока и даже из Австралии. Было предложено множество решений, использующих нейросетевые модели, модификации классических адаптивных методов, теорию игр и комбинации различных подходов. При этом наблюдалась большая вариативность в типах архитектур используемых нейросетей. Использовались как полносвязные, свёрточные, так и реккурентные варианты с LSTM слоями. В качестве этапа предобработки использовась например фильтрация и морфологию. В оригинальной статье, кратко описаны все методы, которые применяли участники — часто они настолько разные, что остаётся только удивляться, как они показывают похожий результат.
Нашему решению удалось занять первое место как на рукописных документах, так и на печатных. Далее приведены финальные результаты замеров решений. С описанием метрик можно ознакомиться в работах организаторов конкурса опубликованных в предыдущие года. Мы кратко опишем только топ 5 результатов, остальные можно будет прочитать в оригинальной статье (ссылка на неё должна скоро появиться на официальном сайте соревнования). В качестве ориентира организаторами приводятся замеры для классического ноль-параметрического глобального метода Отсу и локального малопараметрического авторства Сауволы (к сожалению, точные значения настроечных коэффициентов неизвестны).
| № | Краткое описание метода | Score | FM | Fps | PSNR | DRD |
|---|---|---|---|---|---|---|
| 1 | Наш метод (U-net сеть) | 309 | 91.01 | 92.86 | 18.28 | 3.40 |
| 2 | FCN (VGG подобная архитектура) + постфильрация |
455 | 89.67 | 91.03 | 17.58 | 4.35 |
| 3 | Ансамбль из 3-х DSN, с 3-х уровневым выходом, работающие на патчах разных маштабов |
481 | 89.42 | 91.52 | 17.61 | 3.56 |
| 4 | Ансамбль из 5-ти FCN — вход: патчи разных маштабов + бинаризованные методом Howe + RD признаки. |
529 | 86.05 | 90.25 | 17.53 | 4.52 |
| 5 | Схож с предыдущим методом, , но добавлен CRF построцессинг |
566 | 83.76 | 90.35 | 17.07 | 4.33 |
| … | … | … | … | … | … | … |
| 7 | Морфология + Howe + постобработка | 635 | 89.17 | 89.88 | 17.85 | 5.66 |
| Otsu | 77.73 | 77.89 | 13.85 | 15.5 | ||
| Sauvola | 77.11 | 84.1 | 14.25 | 8.85 |
Лучший метод, не использующий никаким образом нейронные сетки занял 7-ое место.
Ниже демонстрируется работа нашего алгоритма на ряде тестовых изображений.
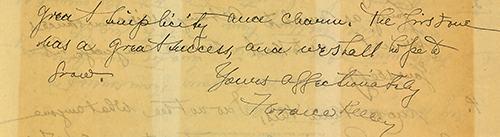
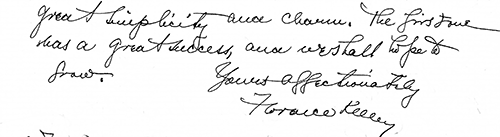





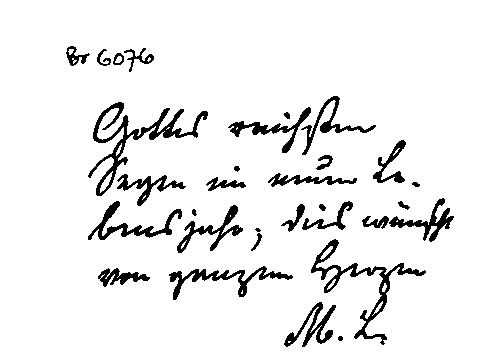
Ну и свидетельство, которое нам вручали на конференции ICDAR 2017 в Японии:

