История о жрущем память API-сервере Kubernetes

Наша команда занимается сопровождением кластеров Kubernetes внутри компании. Мы стараемся построить модель предоставления кластера как услуги, насколько это возможно в наших реалиях. Несколько месяцев назад коллеги, работающие с одним из кластеров Kubernetes в dev-окружении, обратились с проблемой недоступности API-сервера Kubernetes (далее kube-api). Dev-среды обычно не подключены к дежурной смене, и решением проблем занимаются владельцы или, если проблемы нестандартные, обращаются к профильным специалистам. В ходе диагностики оказалось, что kube-api стал потреблять значительно больше памяти. Это приводило к возникновению ошибки с OOM.
Давайте будем честными — если бы это произошло в production-окружении, мы, скорее всего, закинули бы больше памяти и успешно бы забыли про проблему. Но dev-стенд не имеет жёстких SLA с финансовой ответственностью, и это дало нам возможность и время разобраться с прожорливым kube-api.
Всех, кому интересно, что из этого вышло, прошу под капот.
Оглавление
Немного слов о нашей инфраструктуре
О kube-api
Попытка № 1: А что там на проде?
Попытка № 2: Кто жрёт?
Результаты
Немного слов о нашей инфраструктуре
В нашей инфраструктуре используем ванильный Kubernetes в on-premise-окружении. Для установки мы используем кастомизированный Kubespray и приватный сontainer registry.
Типовое развёртывание кластера следующее: три VM для Control-Plane с etcd и три worker-ноды, которыми могут быть как VM, так и сервера на Bare Metal. Из-за особенностей контрактной деятельности и требований по обеспечению информационной безопасности у нас более 50 k8s кластеров.
Мы стараемся разворачивать кластеры в пределах информационной системы от dev до prod в функционально одинаковой конфигурации: идентичные версии ПО и, насколько возможно, одинаковые параметры настройки системных и инфраструктурных компонентов кластера. При этом допускаем и необходимые различия, к примеру, в dev храним данные внутри кластера Kubernetes, в prod — на выделенных серверах.
О kube-api
Кто знаком с организацией Kubernetes, может пропустить этот раздел.
Kube-api — центральный элемент кластера Kubernetes, отвечающий за настройку и взаимодействие остальных компонентов. Для хранения конфигурационных данных и сведений о состоянии кластера он использует хранилище etcd. Kube-api является stateless-приложением, с которым общаются все потребители кластера: системные компоненты, kubelet, пользователи, приложения и т.д. Ни один из потребителей не может обращаться за данными в хранилище etcd напрямую. Таким образом, весь рабочий трафик kubernetes проходит через kube-api. Это означает, что основная нагрузка и потребление памяти приходятся именно на kube-api.

Схема организации запросов к kube-api
Попытка № 1: А что там на проде?
OOM на kube-api dev случался один-два раза в день, обычно во второй половине дня, когда разработчики начинали тестировать свои утренние или вчерашние изменения.
Ввиду того, что функционально тестовые и продуктовые среды у нас в целом одинаковые, т.к. периодичность релизов в общем-то не превышает спринта разработки, мы решили сравнить кластеры dev и prod по объёму потребляемой памяти и заодно проверить, как себя чувствует prod, нет ли на нём сейчас похожих проблем.
На prod уже были случаи с одним из кластеров, когда он действительно разрастался и возникал OOM. Тогда вопрос решался увеличением ресурсов или простым удалением неактуальных объектов.
Сравнив, мы увидели следующее потребление памяти за сутки:
kube-api dev: 21—30 Gb RAM
kube-api prod: 8—11 Gb RAM
Нас удивило, что kube-api dev потребляет в два с лишним раза больше памяти, чем kube-api prod. Использование одинаковых технических стеков для dev и prod исключало возможность некорректной настройки или утечки памяти kube-api.
В ходе выдвижения рабочей гипотезы предположили, что количество объектов в dev гораздо больше, и для проверки сравнили их количество в кластерах dev и prod:
Объект сравнения | Итог сравнения количества объектов |
Node | На prod узлов немного больше, но они значительно мощнее по аппаратным характеристикам |
Pod | Соизмерим, разница не более 10% в пользу prod. Но Limit и Request значительно больше для prod |
Deployment DaemonSet StatefulSet | В dev примерно в 3 раза больше |
Configmap | В dev примерно в 3 раза больше |
Secrets | В dev в разы больше |
Размер etcd | В dev — 1,1 Гб, prod — 0,5 Гб |
Действительно, обнаружили, что на dev, например, значительно больше высокоуровневых объектов, таких как Deployments, DaemonSets, StatefulSets, а также Configmaps.
Пообщавшись с коллегами, отвечающими за работу приложений, выяснили, что в кластере dev размещается сразу несколько стендов, т.е. часто создаются отдельные окружения — каждое под свои задачи.
После этого стала понятна разница в количестве объектов. Однако несмотря на то, что в dev высокоуровневых объектов много, они на самом деле состоят из гораздо меньшего числа Pods, чем в prod. Таким образом, общее число активных Pods в dev и prod оказывается соизмеримо. Проверив, нет ли среди объектов в dev каких-то неактуальных, мы не нашли их в настолько значимом количестве, которое могло повлиять на возникновение OOM.
На высокое потребление памяти kube-api в dev дополнительно влияет тот момент, что к нему обращается несколько сотен сотрудников. В prod — всего лишь несколько десятков. Это объясняется тем, что в prod мы не даём доступ в kube-api: за необходимыми данными о состоянии приложений пользователи обращаются в системы логирования или мониторинга. Для dev таких требований нет, и там разработчики могут просто пойти через Lens смотреть за ресурсами.
А вот значительная разница в объеме Secrets и размере etcd нам показалась гораздо критичнее.
Проведя анализ секретов и пообщавшись с командой dev-кластера, было выявлено большое количество неактуальных секретов, которые остаются после работы Helm. Это оказались секреты, в которых хранится история релизов, что позволяет разработчикам откатываться на предыдущие версии приложений, т.е. прошлые релизы, и сравнивать отличия.
Учитывая, что всё деплоится через связку Git — Helm — Jenkins, было решено удалить все секреты Helm для проверки теории, что причина ООМ — именно в неактуальных Secrets. Дополнительно решили явно задать параметры requests.memory и limits.memory для kube-api.
Тут нужно сделать отступление: лучшие практики всегда советуют устанавливать requests и limits, но в нашем случае на Control Plane запускается заранее определённый и проверенный в работе набор приложений. Мы руководствовались тем, что лучше предоставить всю память сервера системным компонентам Kubernetes, чем их как-то ограничивать в работе. По прошествии пары лет с такими параметрами проблем не возникало. В данной ситуации решили попробовать явно ограничить потребление ресурсов, чтобы заставить kube-api активнее освобождать память.
Итак, после применения получили следующие результаты, имея на сервере 32 Гб RAM, согласно графику потребления памяти kube-api ниже:
Отметка »1» — установка лимитов. По графикам стало лучше, на практике — нет.
Отметка »2» — удаление секретов и ограничение размера истории релизов Helm. Вроде как стало действительно лучше.

Потребление памяти kube-api
Однако это помогло решить проблему с OOM на сутки. Потом размер etcd вырос, так как количество секретов, которые создаются после работы Helm, увеличилось. И OOM вернулся в нелёгкую жизнь kube-api. На графике видно, как увеличился размер etcd только за счёт новых секретов Helm:
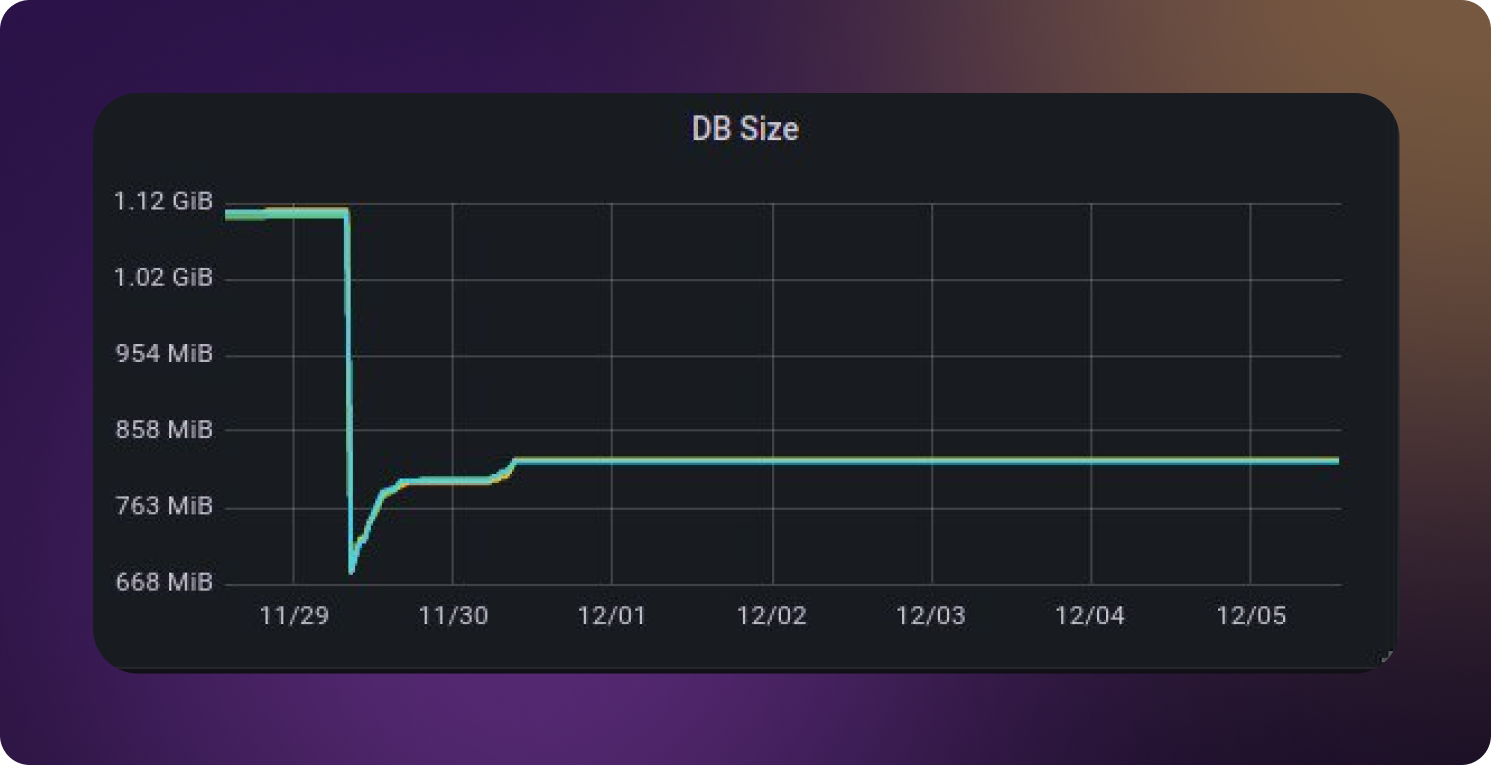
Размер БД etcd после удаления secret и их увеличения
Попытка № 2: Кто жрёт?
Мы уже было подумали, что вся нагрузка легитимная и надо увеличивать ресурсы для kube-api. Но ведь лучше попробовать и не получить результата, чем отказаться от интересного эксперимента.
И всё равно не верилось в такую большую разницу в потреблении памяти между dev и prod. Мы прошерстили интернет на предмет рекомендаций по оптимизации памяти и ресурсов, попробовали пару теорий, но они не принесли результатов. Пришли к тому, что в dev-кластере или приложения, или сотрудники неправильно работают с kube-api, вызывая аномальное потребление ресурсов.
Поняв, что с ходу проблему не решить, мы вооружились знаниями о профилировщике Go — на этом языке написан kube-api. И решили снять параметры потребляемой памяти с kube-api.
Для этого:
Проверили, что kube-api запущен с параметром --profiling=True (значение по умолчанию).
Пробросили порт kube-api на свою машину с заранее установленным Go.
$ kubectl proxy &
Сгенерировали отчёт потребляемой памяти в виде графа в формате svg
$ go tool pprof -svg http://127.0.0.1:8001/debug/pprof/heap > kube-api.svg
В ходе анализа нас больше всего смутили два момента из графа:

Часть вывода графа потребляемой памяти kube-api: операция encoding base64

Часть вывода графа потребляемой памяти kube-api: десериализация json с Secrets
Указанные моменты навели нас на предположение, что большую часть памяти kube-api тратит на десериализацию и отслеживание секретов. Это подтверждалось тем, что OOM стал повторно происходить при увеличении количества секретов, как мы выяснили в ходе первой попытки.
Но просто так kube-api не будет тратить ресурсы на работу с секретами, значит, кто-то просит его об этом. Кто-то, у кого есть необходимые права. Учитывая масштабы трагедии, у этого кого-то есть права на просмотр всех секретов, а точнее, на операции watch и get на весь кластер Kubernetes. Это значит, что в первую очередь надо смотреть ClusterRoleBinding и ClusterRole.
С помощью плагина https://github.com/aquasecurity/kubectl-who-can были выявлены потенциальные обжоры:
$ kubectl who-can watch secrets
CLUSTERROLEBINDING | SUBJECT | TYPE | SA-NAMESPACE |
cert-manager-cainjector | cert-manager-cainjector | ServiceAccount | infra-cert-manager |
cert-manager-controller-certificates | cert-manager | ServiceAccount | infra-cert-manager |
cert-manager-controller-challenges | cert-manager | ServiceAccount | infra-cert-manager |
cert-manager-controller-clusterissuers | cert-manager | ServiceAccount | infra-cert-manager |
cert-manager-controller-issuers | cert-manager | ServiceAccount | infra-cert-manager |
cert-manager-controller-orders | cert-manager | ServiceAccount | infra-cert-manager |
cluster-admin | system: masters | Group | |
kube-prometheus-stack-grafana-clusterrolebinding | kube-prometheus-stack-grafana | ServiceAccount | monitoring |
kube-prometheus-stack-kube-state-metrics | kube-prometheus-stack-kube-state-metrics | ServiceAccount | monitoring |
kube-prometheus-stack-operator | kube-prometheus-stack-operator | ServiceAccount | monitoring |
kubespray: system: node | system: nodes | Group | |
system: controller: generic-garbage-collector | generic-garbage-collector | ServiceAccount | kube-system |
system: controller: resourcequota-controller | resourcequota-controller | ServiceAccount | kube-system |
system: kube-controller-manager | system: kube-controller-manager | User |
Объекты kubernetes, имеющие права watch на все секреты кластера
Благодаря тому, что мы стараемся аккуратно использовать RBAC, их оказалось немного. Часть вывода, например с пользователями и группами OIDC, здесь опущена как несущественная для нашей задачи: с ними и со своими приложениями ушли разбираться владельцы кластера, а мы занялись инфраструктурными компонентами.
По запросу «имя_обжоры secret high memory usage» быстро нашли потенциальное решение.
Изучив issue и немного поковырявшись в коде, выяснили, что prometheus-operator отслеживает все секреты, до которых может дотянуться, в отличие от того же cert-manager, который следит только за «своими» секретами. Prometheus-operator устанавливается в кластер как часть решения kube-prometheus-stack. Посмотрев версию установленного чарта, было принято решение изменить значение secretFieldSelector:
prometheusOperator:
secretFieldSelector: "type!=kubernetes.io/dockercfg,type!=kubernetes.io/service-account-token,type!=helm.sh/release.v1"которое в итоге используется как параметр запуска prometheus-operator:
--secret-field-selector=type!=kubernetes.io/dockercfg,type!=kubernetes.io/service-account-token,type!=helm.sh/release.v1Таким образом, мы запретили prometheus-operator отслеживать большую часть секретов, неактуальных для его работы.
Потребление памяти prometheus-operator после правки параметра:

Потребление памяти prometheus-operator
И аналогично у kube-api:

Потребление памяти kube-api
Время на графиках не совпадает, т.к. перезапуск kube-api не хотелось проводить в рабочие часы и мы надеялись, что он сам снизит потребление памяти. Этого не произошло, и после рабочего дня мы перезапустили kube-api.
Результаты
Прошло несколько месяцев, и, несмотря на то, что в dev-кластере приложений стало немного больше, kube-api не потребляет больше памяти:

Потребление памяти kube-api
Анализ работы kube-api с детальным распутыванием цепочки происходящих внутри него событий с помощью профилировщика Go показал, что виновником проблем оказался prometheus-operator. Перенастроив его, а также выполнив ряд дополнительных конфигурационных корректировок, мы таки достигли оптимальной работы кластера.
Что было сделано по итогу:
Удалили неактуальные объекты из кластера
Уменьшили Helm history до трёх ревизий — для dev-контура этого достаточно
Установили лимиты для kube-api и других системных компонент
Поправили настройки prometheus-operator
Получили практический опыт работы с pprof*
*
Тут буду признателен, если сообщество подскажет более подходящий инструмент отслеживания обращений к kube-api. К примеру, показывающий сколько памяти потребляет тот или иной пользователь или SA своими обращениями.
Проанализировали политики RBAC на предмет минимизации привилегий
Как я говорил, у нас много Kuberenetes и везде развёрнут kube-prometheus-stack с prometheus-operator. Настройка параметров работы prometheus-operator позволила в сумме сократить потребление RAM более чем на 80 Гб на всех проектах нашей компании.
Прошу прощения, что не везде приводил точные цифры — это обусловлено наличием NDA, и за некачественные скрины — когда разбирали инцидент, не думал, что буду писать на Habr: по факту все фото из рабочих переписок.
Мотивацией написать статью послужил факт отсутствия в kube-prometheus-stack разумных значений для secretFieldSelector на момент написания. В исходниках и параметрах работы по умолчанию для prometheus-operator исключений на отслеживание секретов тоже не обнаружил.
Надеюсь, было полезно и вы узнали что-то новое для себя! :)
