История машинного перевода: долгий путь от мейнфреймов до мобильных устройств
Сегодня в App Store вышло обновленное приложение Яндекс.Перевода для iOS. Теперь в нем есть возможность полнотекстового перевода в офлайн-режиме. Машинный перевод прошел путь от мейнфреймов, занимавших целые комнаты и этажи, до мобильных устройств, помещающихся в карман. Сегодня полнотекстовый статистический машинный перевод, требовавший ранее огромных ресурсов, стал доступен любому пользователю мобильного устройства — даже без подключения к сети. Люди давно мечтают о «вавилонской рыбке» — универсальном компактном переводчике, который всегда можно взять с собой. И, кажется, мечта эта постепенно начинает сбываться. Мы решили, воспользовавшись подходящим случаем, подготовить небольшой экскурс в историю машинного перевода и рассказать о том, как развивалась эта интереснейшая область на стыке лингвистики, математики и информатики.«Это все делает машина», «Электронный мозг переводит с русского на английский», «Робот-билингва» — такие газетные заголовки увидели читатели ликующей прессы 8 января 1954 года. А днем ранее, 7 января, научный компьютер IBM 701 принял участие в знаменитом Джорджтаунском эксперименте, переведя около шестидесяти русских фраз на английский. «Семьсот-первый» использовал словарь из 250 слов и шесть синтаксических правил. И, конечно же, очень тщательно подобранный набор предложений, на которых проводилось тестирование. Вышло настолько убедительно, что восторженные журналисты со ссылками на ученых заявляли о том, что через несколько лет машинный перевод почти полностью заменит классический «ручной».

Джорджтаунский эксперимент был одним из первых шагов в развитии машинного перевода (и одним из первых применений ЭВМ для работы с естественным языком). Тогда многие проблемы из тех, с которыми предстояло столкнуться в будущем, были еще не так очевидны. Однако главной проблемой, по иронии, стало то, что как раз таки было очевидно с самого начала — компьютеру труднее всего давалась работа с многозначными словами. На более-менее естественных предложениях система практически полностью переставала справляться с задачей. Сложная многокомпонентная структура таких систем также создавала проблемы: например, синтаксический анализ не всегда срабатывал верно, и составное слово guitar pick (медиатор) могло быть переведено как «выбор гитары». Также плохо переводились многозначные слова, смысл которых зависел от контекста. Например, текст «Little John was looking for his toy box. Finally he found it. The box was in the pen» вызывал (и продолжает вызывать) очень много сложностей — как словосочетание «toy box», переводившееся как «игрушечная коробка», а не «коробка для игрушек», так и «in the pen», которое переводилось как «в ручке», а не «в детском манеже». Сложности были огромными, и в итоге за 12 лет сдвинуться с мертвой точки почти не получилось. В 1966 году разгромный доклад ALPAC (Automatic Language Processing Advisory Committee) положил конец исследованиям в области машинного перевода на следующие десять лет. Пока же настроения после Джорджтаунского эксперимента были еще весьма радужными и машинному переводу предрекалось большое будущее, американцы начали всерьез задумываться об использовании новой технологии в стратегических целях. Что в полной мере осознавали и в СССР. В начале 1955 года Академией Наук СССР были созданы две исследовательские группы — в Математическом Институте имени В.А. Стеклова (руководителем группы стал выдающийся математик и кибернетик Алексей Ляпунов) и в Институте точной механики и вычислительной техники AН СССР (её возглавил математик Д.Ю. Панов). Обе группы начали с детального изучения Джорджтаунского эксперимента, а уже в 1956 году Панов опубликовал брошюру, в которой излагал результаты первых экспериментов по машинному переводу, проведенных на компьютере БЭСМ. В том же 1956 последовала публикация об аналогичных изысканиях в институте им. Стеклова за авторством Ольги Кулагиной и Игоря Мельчука, которая вышла в сентябрьском номере журнала «Вопросы языкознания». Эта публикация сопровождалась различными вводными статьями, и вот тут-то было обнаружено кое-что интересное: оказалось, что в 1933 году в АН СССР обратился некий Пётр Петрович Троянский, эсперантист и один из соавторов БСЭ, с проектом машинного переводчика и просьбой обсудить этот вопрос с лингвистами Академии. Ученые отнеслись к идее скептически: дискуссии вокруг проекта продолжались одиннадцать лет, после чего связь с Троянским была внезапно потеряна, а сам он предположительно уехал из Москвы.
Пока же настроения после Джорджтаунского эксперимента были еще весьма радужными и машинному переводу предрекалось большое будущее, американцы начали всерьез задумываться об использовании новой технологии в стратегических целях. Что в полной мере осознавали и в СССР. В начале 1955 года Академией Наук СССР были созданы две исследовательские группы — в Математическом Институте имени В.А. Стеклова (руководителем группы стал выдающийся математик и кибернетик Алексей Ляпунов) и в Институте точной механики и вычислительной техники AН СССР (её возглавил математик Д.Ю. Панов). Обе группы начали с детального изучения Джорджтаунского эксперимента, а уже в 1956 году Панов опубликовал брошюру, в которой излагал результаты первых экспериментов по машинному переводу, проведенных на компьютере БЭСМ. В том же 1956 последовала публикация об аналогичных изысканиях в институте им. Стеклова за авторством Ольги Кулагиной и Игоря Мельчука, которая вышла в сентябрьском номере журнала «Вопросы языкознания». Эта публикация сопровождалась различными вводными статьями, и вот тут-то было обнаружено кое-что интересное: оказалось, что в 1933 году в АН СССР обратился некий Пётр Петрович Троянский, эсперантист и один из соавторов БСЭ, с проектом машинного переводчика и просьбой обсудить этот вопрос с лингвистами Академии. Ученые отнеслись к идее скептически: дискуссии вокруг проекта продолжались одиннадцать лет, после чего связь с Троянским была внезапно потеряна, а сам он предположительно уехал из Москвы.
Эта историческая находка удивила исследователей; начались изыскания. Удалось найти авторское свидетельство Троянского на «механизированный словарь», позволяющий быстро переводить тексты одновременно на несколько языков. После очередного пленарного заседания, на котором Ляпунов прочитал доклад об этом изобретении, Академией Наук был создан специальный комитет по изучению вклада Троянского. Прошло несколько лет и, наконец, в 1959 году была опубликована статья «Перeводная машина П.П. Троянского: сборник материалов о машине для перевода с одного языка на другие, предложенной П.П. Троянским в 1933 г.» за авторством И.К. Бельской и Д.Ю. Панова. Вскоре было опубликовано и авторское свидетельство, из которого было видно весьма оригинальное технологическое решение устройства.

В проекте машина Троянского представляла собой стол с наклонной поверхностью, перед которым была закреплена фотокамера, совмещенная с печатной машинкой. Клавиатура печатной машинки состояла из обычных клавиш, которые позволяли кодировать морфологическую и грамматическую информацию. Лента печатной машинки и плёнка камеры должны были быть соединены вместе и подаваться синхронно. На самой же поверхности стола должно было быть расположено так называемое «глоссарное поле» — свободно двигающаяся пластина с напечатанными на ней словами. Каждое из слов сопровождалось переводами на трех, четырех и более языках. Все слова должны были быть даны в начальной форме и расположены на доске таким образом, чтобы наиболее часто используемые слова были ближе к центру — как буквы на клавиатуре. Оператор машины должен был сдвинуть глоссарное поле и сделать фотоснимок слова и его переводов, одновременно набрав на печатной машинке относящуюся к слову грамматическую и морфологическую информацию. В итоге получалось две ленты: одна со словами сразу на нескольких языках, а вторая — с грамматическими пояснениями к ним. Когда весь исходный текст был набран таким образом, материал уходил носителям языка — ревизорам, которые должны были сверить две ленты и составить по ним тексты на своих языках. Далее материалы должны были быть переданы редакторам, знающим оба языка. Их задачей было довести текст до литературного вида.
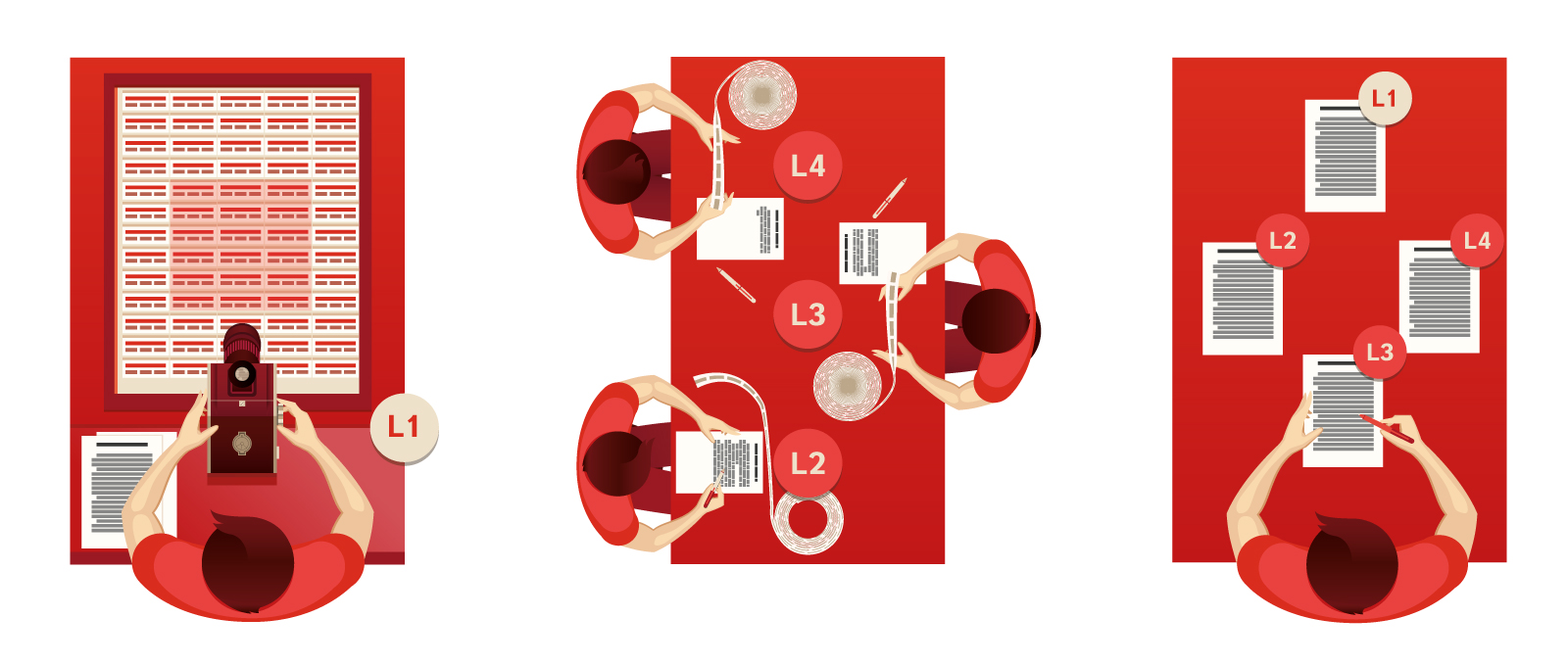
Главная идея изобретения — разделение процесса перевода на три основных этапа (кстати, первый и последний в современной терминологии назывались бы «pre-editing» и «post-editing»). Что интересно, самые затратные по времени процессы (кодирование исходного текста и синтез из этой информации текстов на других языках) требуют от операторов всего лишь знания родного языка.
Таким образом, перевод осуществлялся сначала между естественным языком и его логической формой, затем между логическими формами двух языков, а после этого текст в логической форме целевого языка выверялся и приводился к естественной форме. Троянский, как историк науки, несомненно знал о теориях Лейбница и Декарта о создании универсального языка и переводе через интерлингву. В предложенной им технологии прослеживается влияние этих теорий. Более того, Троянский был эсперантистом, и построил систему кодирования грамматической информации на основе грамматики Эсперанто (от чего позже по политическим соображениям был вынужден отказаться).
Что особенно интересно, уже в сороковые годы Троянский рассматривал перспективы создания «мощного переводного устройства на базе современных технологий связи». Однако при жизни идеи изобретателя были встречены академическим обществом с огромным скепсисом и впоследствии преданы забвению. Троянский умер в 1950, не дожив совсем немного до начала работы над машинным переводом в Советском Союзе. Английский исследователь машинного перевода Джон Хатчинс считает, что если вклад Троянского не был бы забыт, принципы его переводной машины легли бы в основу первых экспериментов на БЭСМе, и это бы поставило изобретателя в ряды «отцов» машинного перевода наряду с Уорреном Уивером. Но, к сожалению, история не имеет сослагательного наклонения.
Перенесемся на сорок лет вперед, в восьмидесятые. После ALPAC«а ни у кого, кроме самых отчаянных энтузиастов, не было серьезного желания заниматься машинным переводом. Однако, как это часто бывает, двигателем прогресса стал бизнес. В конце шестидесятых курс на глобализацию мира был уже очевиден. Перед международными компаниями встала острая необходимость поддерживать тесные торговые контакты в нескольких странах одновременно. В 1980-е годы запрос бизнеса на технологию быстрого перевода документов и новостей возрос: и тут «расчехлили» машинный перевод. Не отставало и Европейское экономическое сообщество — будущий Евросоюз — в 1976 в этой организации стал активно использоваться SYSTRAN — первый в истории коммерческий машинный переводчик. В дальнейшем эта система стала почти обязательным приобретением любой уважающей себя международной компании: General Motors, Dornier и Aerospatiale. Не оставалась в стороне и Япония: все увеличивающиеся объемы работы с Западом вынуждали крупные японские корпорации вести свои разработки в этой области. Правда, в большинстве случаев они (как и «Систран») так или иначе были вариациями правиловых (rule-based) систем, с их известными «родовыми» травмами — неумением корректно работать с многозначными словами, омонимами и идиоматическими выражениями. Такие системы также отличались большой дороговизной, поскольку для создания словарей требовался труд большого штата профессиональных лингвистов, а также негибкостью — довольно затратным делом была адаптация для нужной предметной области, не говоря уже о новом языке. Исследователи по-прежнему предпочитали концентрироваться на системах, использовавших правила, а также семантический, синтаксический и морфологический анализ.
 По-настоящему новая эра машинного перевода началась в 1990-х годах. Исследователи поняли, что естественный язык очень сложно описать формально, и еще сложнее применить формальные описания к живому тексту. Это было слишком тяжелой и ресурсоемкой задачей. Нужно было искать другие пути.
По-настоящему новая эра машинного перевода началась в 1990-х годах. Исследователи поняли, что естественный язык очень сложно описать формально, и еще сложнее применить формальные описания к живому тексту. Это было слишком тяжелой и ресурсоемкой задачей. Нужно было искать другие пути.
Как обычно, когда проблема кажется практически неразрешимой, полезно сменить перспективу. На сцене снова появилась компания IBM, одна из исследовательских групп которой разработала систему статистического машинного перевода, названную Candide. Специалисты подошли к задаче машинного перевода с точки зрения теории информации. Ключевой идеей стала концепция так называемого канала с ошибками (noisy channel). Модель канала с ошибками рассматривает текст на языке A как зашифрованный текст на любом другом языке B. И задача переводчика — дешифровать этот текст.
Прибегнем к забавной иллюстрации. Представьте себе англичанина, который изучает французский язык и с целью попрактиковаться в нем приехал во Францию. Поезд прибыл в Париж, и нашему герою нужно найти камеру хранения на вокзале Гар-дю-Нор. После безуспешных поисков он наконец обращается к случайному прохожему и, заранее обдумав фразу на английском, спрашивает его по-французски, не знает ли тот, где можно найти камеру хранения. Задуманная английская фраза как бы «искажается» и превращается во фразу на французском языке. На беду, прохожий оказывается англичанином, и знает французский довольно плохо. Смысл фразы он восстанавливает, пытаясь восстановить с помощью своих познаний во французском и примерного представления того, что вероятнее всего имел ввиду его собеседник — то есть, говоря проще, пытается угадать, какую английскую фразу тот задумал.
IBM«овцы работали как раз с французским и английским: в руках исследовательской группы было огромное количество параллельных документов из оборота канадского правительства. Исследователи построили свои переводные модели следующим образом: собрали вероятности для всех сочетаний слов определенной длины на двух языках и вероятности для соответствия каждого из таких сочетаний сочетанию на другом языке.
Далее самый вероятный перевод e, допустим, на английский, для, например, французской фразы f может быть определен так:

где E — это все английские фразы в модели. Как англичанин пытался угадать мысли своего соотечественника, алгоритм пытается найти самую частотную фразу на английском, которая имела бы хоть какое-то отношение к тому, что потенциально могло быть задумано, когда произносилась французская фраза.
Такой простой подход оказался самым действенным. IBM«овцы не применяли никаких лингвистических правил, и, на самом деле, в группе практически никто не знал французского языка. Несмотря на это, Candide работал, и более того — работал довольно хорошо! Результаты исследования и общий успех системы стали настоящим прорывом в области машинного перевода. И самое главное, опыт Candide доказал, что не обязательно иметь дорогостоящий штат первоклассных лингвистов для составления правил перевода. Развитие же интернета дало доступ к огромному количеству данных, необходимых для создания больших моделей перевода и языка. Исследователи сконцентрировали усилия на разработке алгоритмов перевода, сборе корпусов параллельных текстов и выравнивании предложений и слов на разных языках.
А пока статистический машинный перевод находился в стадии промышленной разработки и медленно добирался до пользователей сети Интернет, на рынке онлайн-перевода господствовали rule-based системы. Здесь надо заметить, что — rule-based перевод появился задолго до интернета и начал продвижение в широкие массы с программ для десктопных компьютеров, и, чуть позже, переносных (palm-size и handheld) устройств. Версии для онлайн-пользователей появились только в середине 90-х годов и наибольшее распространение получил уже знакомый нам «Систран». В 1996 году он стал доступен пользователям интернета — система позволяла переводить небольшие тексты онлайн. Вскоре после этого разработки «Систрана» стал использовать поисковик AltaVista, запустив сервис BabelFish, благополучно доживший в составе Yahoo до 2012 года. Появившийся в виде веб-приложения в 1998 году и быстро ставший популярным в рунете PROMT-онлайн использовал собственные технологии, но работал также в парадигме rule-based machine translation.
Первопроходец статистического онлайн Google запустил первую версию сервиса Translate только в 2007 году, но очень быстро завоевал всеобщую популярность. Сейчас сервис предлагает не только перевод для более чем 70 языков, но и много полезных инструментов вроде исправления ошибок, озвучивания и т.п… По его следу идет не такой популярный, но довольно мощный и активно развивающийся онлайновый переводчик компании Майкрософт, предлагающий перевод для более чем 50 языков. В 2011 году появился Яндекс.Перевод, который сейчас поддерживает более 40 языков и предлагает разнообразные средства упрощения набора текста и улучшения качества перевода.
 История появления Яндекс.Перевода началась летом 2009 года, когда Яндекс занялся исследованиями в области статистического машинного перевода. Все началось с экспериментов с открытыми системами статистического перевода, с разработки технологий поиска параллельных документов и создания систем тестирования и оценки качества перевода. В 2010 году приступили к работе над высокоэффективными алгоритмами перевода и программами для построения переводных моделей. 16 марта 2011 года была запущена публичная бета-версия сервиса Яндекс.Перевод с двумя языковыми парами: англо-русской и украино-русской. В декабре 2012 года появилось мобильное приложение для iPhone, через полгода версия для Android, а еще через полгода версия для Windows Phone.
История появления Яндекс.Перевода началась летом 2009 года, когда Яндекс занялся исследованиями в области статистического машинного перевода. Все началось с экспериментов с открытыми системами статистического перевода, с разработки технологий поиска параллельных документов и создания систем тестирования и оценки качества перевода. В 2010 году приступили к работе над высокоэффективными алгоритмами перевода и программами для построения переводных моделей. 16 марта 2011 года была запущена публичная бета-версия сервиса Яндекс.Перевод с двумя языковыми парами: англо-русской и украино-русской. В декабре 2012 года появилось мобильное приложение для iPhone, через полгода версия для Android, а еще через полгода версия для Windows Phone.
Здесь мы возвращаемся к исходной точке рассказа — появлению офлайнового перевода. Напомним, что статистический машинный перевод изначально разрабатывался для работы на мощных серверных платформах с неограниченными ресурсами оперативной памяти. Но не так давно началось движение в обратном направлении — переработка мощных серверных приложений в компактные приложения для смартфонов. Год назад компания Гугл запустила полнотекстовый офлайн-перевод на платформе Андроид. Яндекс тоже работал в этом направлении и вот в мобильном приложении Яндекс.Перевод для iOS появилась возможность пользоваться в офлайн-режиме сначала словарем, а теперь уже и полнотекстовым переводом. То, для чего раньше требовался этаж с мейнфрейм-системой, а затем мощный сервер с десятками гигабайт ОЗУ, теперь помещается в кармане или дамской сумочке и работает автономно — без обращений к удаленному серверу. Такой переводчик будет работать там, где еще нет интернета — высоко над облаками, в десяти тысячах лье под водой и даже в космосе.
Подводя итоги, можно сказать, что в области машинного перевода за последние десятилетия был достигнут огромный прогресс. И, хотя до мгновенного и незаметного для пользователя перевода с любого языка галактики пока еще очень далеко, но тот факт, что за последние несколько десятилетий в этой области совершен огромный скачок, не вызывает никаких сомнений, хочется надеяться, что новые поколения систем машинного перевода будут неуклонно к нему стремиться.
