История архитектуры Dodo IS: путь бэкофиса
Хабр меняет мир. Больше года мы ведём свой блог. Где-то полгода назад нам прилетел вполне логичный фидбэк от хабровчан: «Додо, вот вы везде говорите, что у вас своя система. А что это за система? И зачем она нужна сети пиццерий?».
Мы посидели, подумали и поняли, что вы правы. Мы пробуем объяснить всё на пальцах, но выходит рваными кусками и нигде нет полноценного описания системы. Так начался долгий путь сбора информации, поиска авторов и написания серии статей про Dodo IS. Погнали!
Благодарности: спасибо, что делитесь своим фидбэком с нами. Благодаря ему мы наконец описали систему, составили технорадар и скоро выкатим большое описание наших процессов. Без вас так бы и сидели ещё 5 лет.
Серия статей «Что такое Dodo IS?» расскажет про:
- Ранний монолит в Dodo IS (2011–2015 годы). (In progress…)
- Путь бэкофиса: раздельные базы и шина. (You are here)
- Путь клиентской части: фасад над базой (2016–2017 годы). (In progress…)
- История настоящих микросервисов. (2018–2019 годы). (In progress…)
- Законченный распил монолита и стабилизация архитектуры. (In progress…)
Если интересно узнать что-то ещё — пишите в комментариях.
Традиционно мы смотрим на систему, как на набор компонентов (технических или более высокоуровневых), бизнесовых модулей, взаимодействующих между собой ради достижения какой-либо цели. И если для проектирования такой взгляд оправдан, то для описания и понимания не совсем подходит. Причин тут несколько:
- Реальность отличается от того, что на бумаге. Не всё из задуманного получается. А нам интересно, как на самом деле всё оказалось и работает.
- Последовательное изложение информации. По сути можно пройтись хронологически от начала до текущего состояния.
- От простого к сложному. Не универсально, но в нашем случае именно так. От более простых подходов архитектура переходила к более сложными. Часто через усложнение решались проблемы скорости реализации и стабильности, а также десятки других свойств из списка нефункциональных требований (вот здесь хорошо рассказано про противопоставление сложности остальным требованиям).
В 2011 году архитектура Dodo IS выглядела так:

К 2020 году она немного усложнилась и стала такой:
Как произошла эта эволюция? Зачем нужны разные части системы? Какие архитектурные решения и почему были приняты? Разберёмся в этой серии статей.
Первые проблемы 2016 года: зачем сервисам выходить из монолита
Первые статьи из цикла будут про сервисы, которые первыми отделились от монолита. Чтобы ввести вас в контекст, расскажу, какие проблемы были у нас в системе к началу 2016 года, что нам пришлось заниматься разделением сервисов.
- Единая база MySql, в которую писали свои записи все приложения, существовавшие на тот момент в Dodo IS. Следствия были такие:
- Большая нагрузка (при этом 85% запросов приходилось на чтение).
- База разрасталась. Из-за этого её стоимость и поддержка становились проблемой.
- Единая точка отказа. Если одно приложение, пишущее в базу, внезапно начинало делать это активнее, то другие приложения чувствовали это на себе.
- Неэффективность в хранении и запросах. Часто данные хранились в некоторой структуре, которая была удобна для одних сценариев, но не подходила для других. Индексы ускоряли одни операции, но могли замедлять другие.
- Часть проблем сняли сделанные наспех кэши и read-реплики на базы (об этом будет отдельная статья), но они лишь позволили выиграть время и принципиально проблему не решали.
- Проблемой было наличие самого монолита. Следствия были такие:
- Единые и редкие релизы.
- Сложность в совместной разработке большого числа людей.
- Невозможность привносить новые технологии, новые фреймворки и библиотеки.
Проблемы с базой и монолитом много раз описывались, например, в контексте падений в начале 2018 года (тут, тут и тут), так что особо останавливаться не буду. Скажу только, что нам хотелось дать большую гибкость при разработке сервисов. В первую очередь это касалось тех, которые были самыми нагруженными и корневыми во всей системе — Auth и Трекер.
Путь бэкофиса: раздельные базы и шина
Навигация по главе
- Схема монолита 2016 года
- Начинаем разгружать монолит: отделение Auth и Трекера
- Чем занимается Auth
- Откуда нагрузки?
- Разгружаем Auth
- Чем занимается Трекер
- Откуда нагрузки?
- Разгружаем Трекер
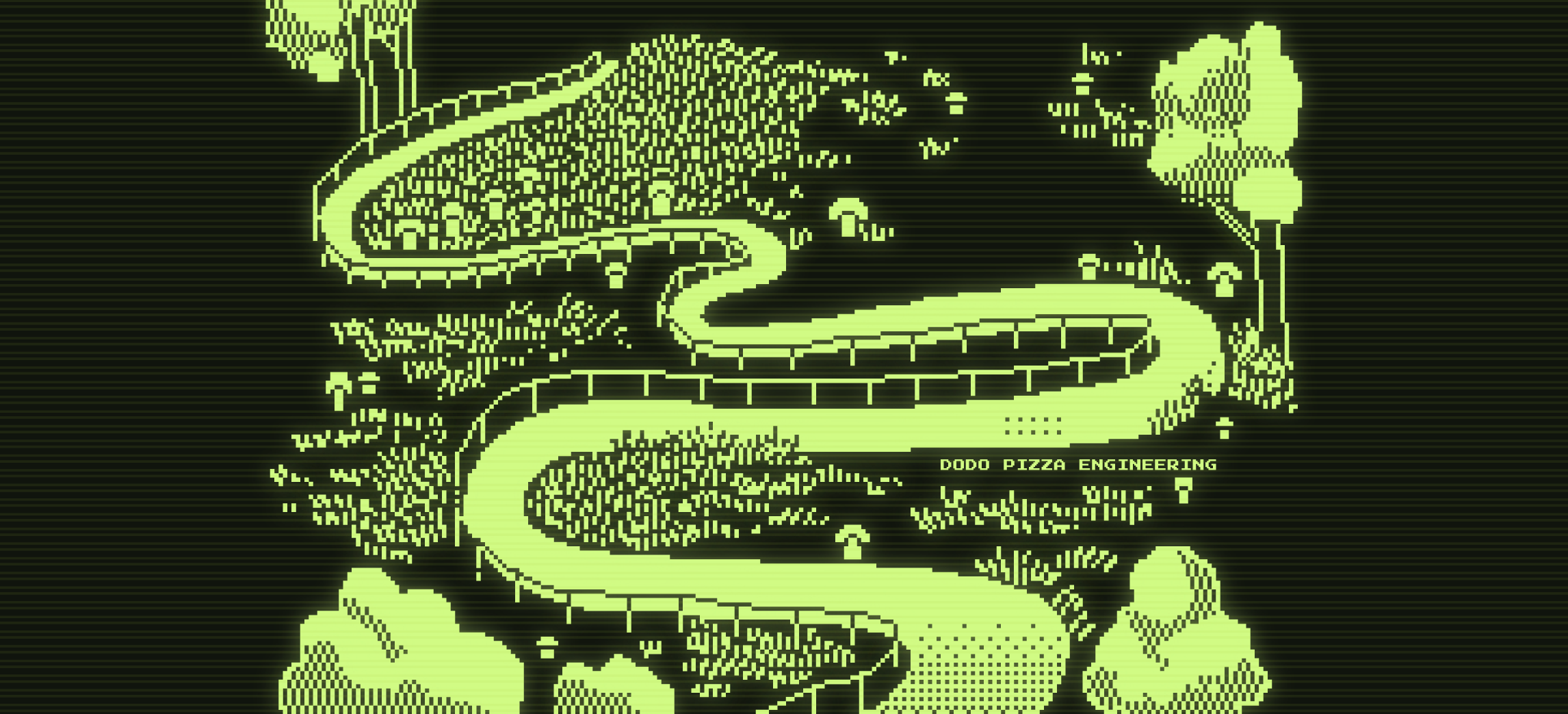
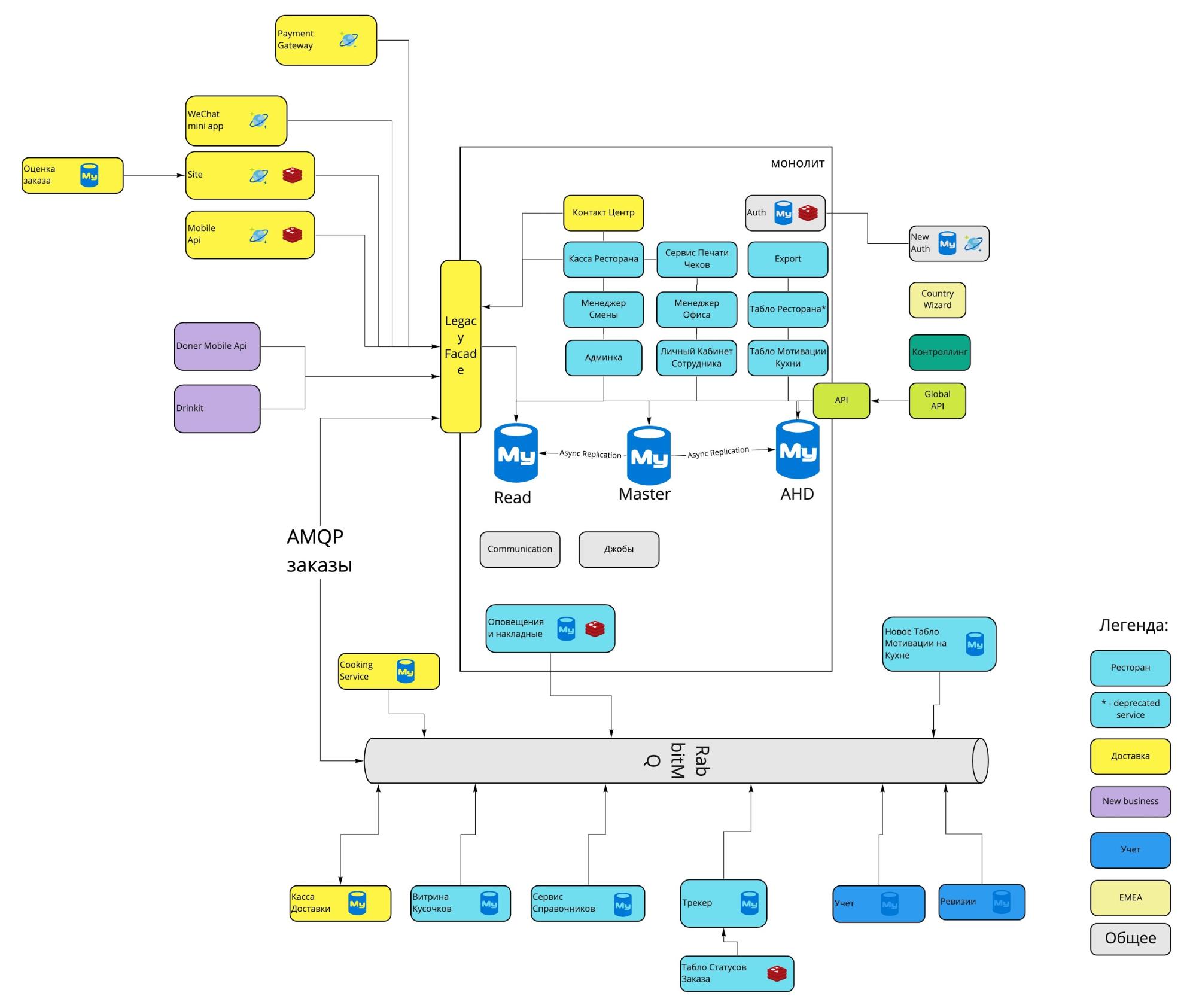
Схема монолита 2016 года
Перед вами основные блоки монолита Dodo IS 2016 года, а чуть ниже расшифровка их основных задач.
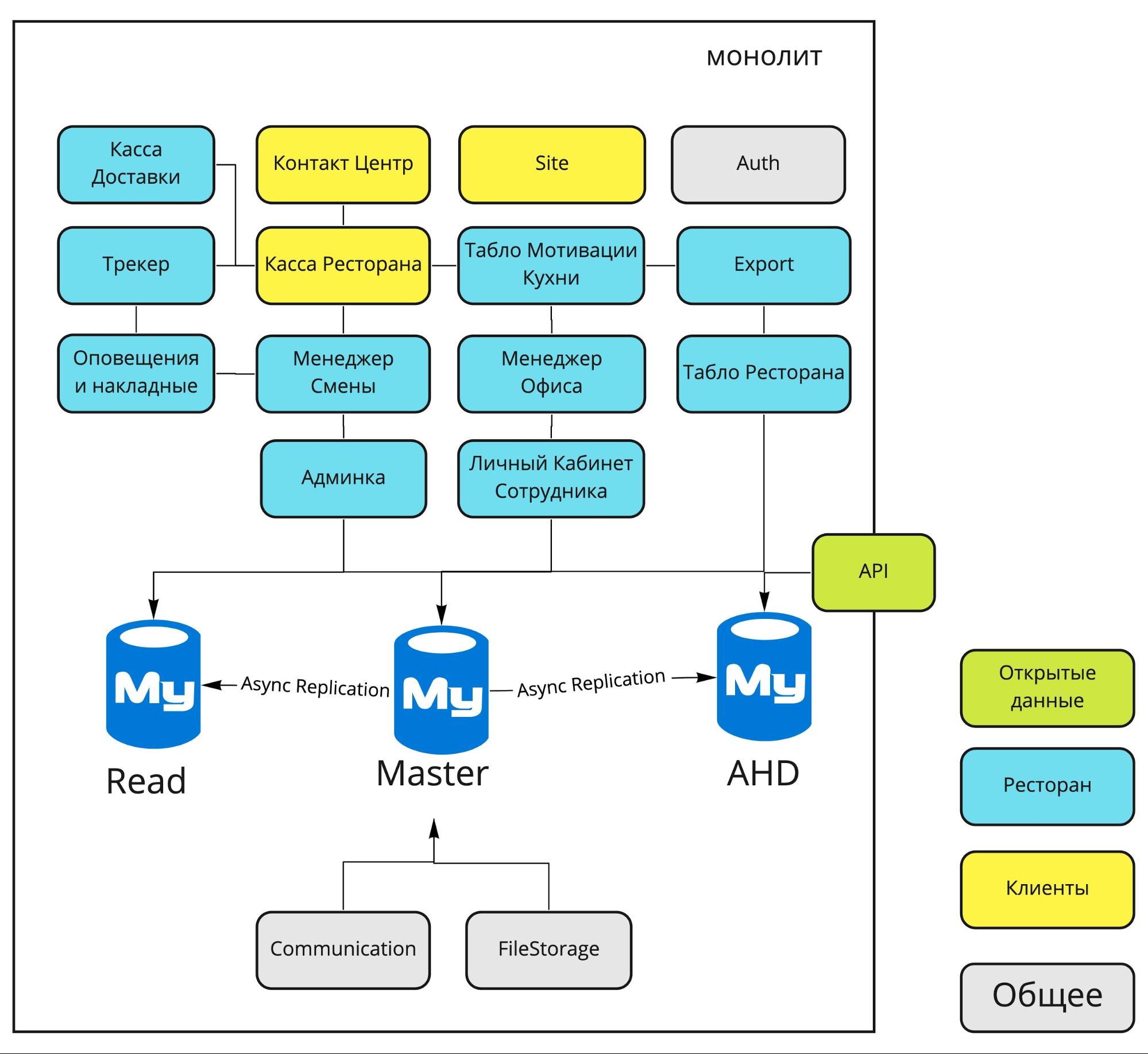
Касса Доставки. Учёт курьеров, выдача заказов курьерам.
Контакт Центр. Приём заказов через оператора.
Site. Наши сайты (dodopizza.ru, dodopizza.co.uk, dodopizza.by и т.д.).
Auth. Сервис авторизации и аутентификации для бэкофиса.
Трекер. Трекер заказов на кухне. Сервис отметки статусов готовности при приготовлении заказа.
Касса Ресторана. Приём заказов в ресторане, интерфейсы кассира.
Export. Выгрузка отчётов в 1C для бухгалтерии.
Оповещения и накладные. Голосовые команды на кухне (например, «Поступила новая пицца») + печать накладных для курьеров.
Менеджер Смены. Интерфейсы для работы менеджера смены: список заказов, графики производительности, вывод на смену сотрудников.
Менеджер Офиса. Интерфейсы для работы франчайзи и управляющего: приём сотрудников, отчёты по работе пиццерии.
Табло Ресторана. Отображение меню на телевизорах в пиццериях.
Админка. Настройки в конкретной пиццерии: меню, цены, учёт, промокоды, акции, баннеры для сайта и т.д.
Личный Кабинет Сотрудника. Графики работы сотрудников, информация о сотрудниках.
Табло Мотивации Кухни. Отдельный экран, который висит на кухне и отображает скорость работы пиццамейкеров.
Communication. Отправка sms и email.
FileStorage. Собственный сервис для приёма и выдачи статических файлов.
Первые попытки решить проблемы помогли нам, но стали лишь временной передышкой. Они не стали системными решениями, поэтому было ясно, что с базами надо что-то сделать. Например, разделить общую базу на несколько более специализированных.
Начинаем разгружать монолит: отделение Auth и Трекера
Основные сервисы, которые тогда больше других записывали и считывали из базы:
- Auth. Сервис авторизации и аутентификации для бэкофиса.
- Трекер. Трекер заказов на кухне. Сервис отметки статусов готовности при приготовлении заказа.
Чем занимается Auth
Auth — это сервис, через который пользователи логинятся в бэкофис (на клиентской части отдельный независимый вход). Также к нему обращаются в запросе, чтобы удостовериться, что есть нужные права на доступ, и что эти права не изменились с последнего входа. Через него же происходит вход устройств в пиццерии.
Например, нам хочется открыть на телевизоре, висящем в зале, табло со статусами готовых заказов. Тогда мы открываем auth.dodopizza.ru, выбираем «Вход как устройство», появляется код, который можно внести в специальной странице на компьютере менеджера смены, указав тип устройства (девайса). Телевизор сам перейдёт на нужный интерфейс своей пиццерии и начнёт отображать там имена клиентов, заказы которых готовы.

Откуда нагрузки?
Каждый залогиненный пользователь бэкофиса на каждый запрос ходит в базу, в таблицу пользователей, через sql-запрос вытаскивает оттуда пользователя и проверяет, есть ли у него нужные доступы и права на эту страницу.
Каждое из устройств делает то же самое только с таблицей устройств, проверяя свою роль и свои доступы. Большое количество запросов в мастер-базу приводит к её загрузке и трате ресурсов общей базы на эти операции.
Разгружаем Auth
У Auth изолированный домен, то есть данные о пользователях, логинах или устройствах поступают в сервис (пока будущий) и там остаются. Если они кому-то понадобятся, то он пойдёт в этот сервис за данными.
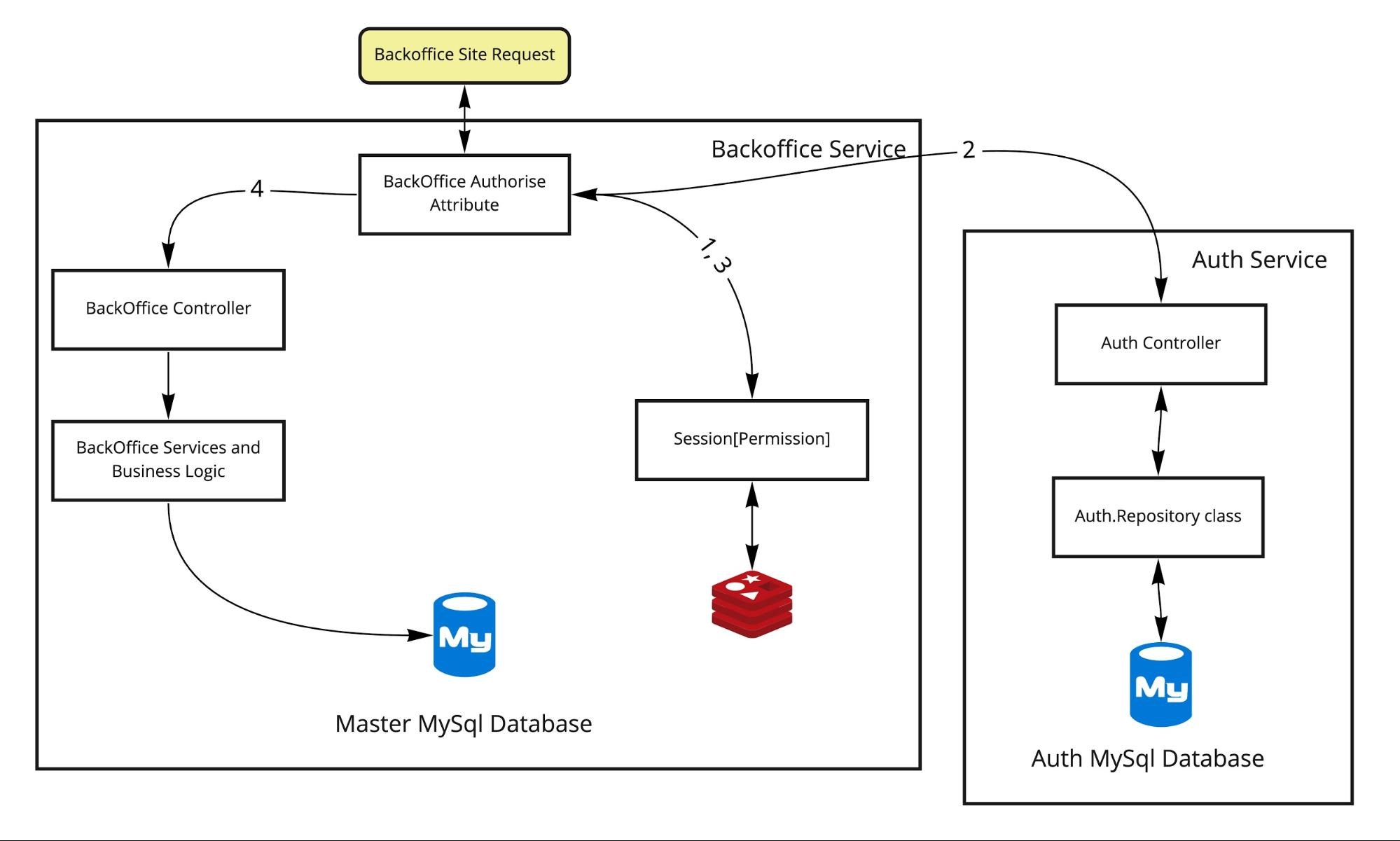
БЫЛО. Схема работы изначально была такой:
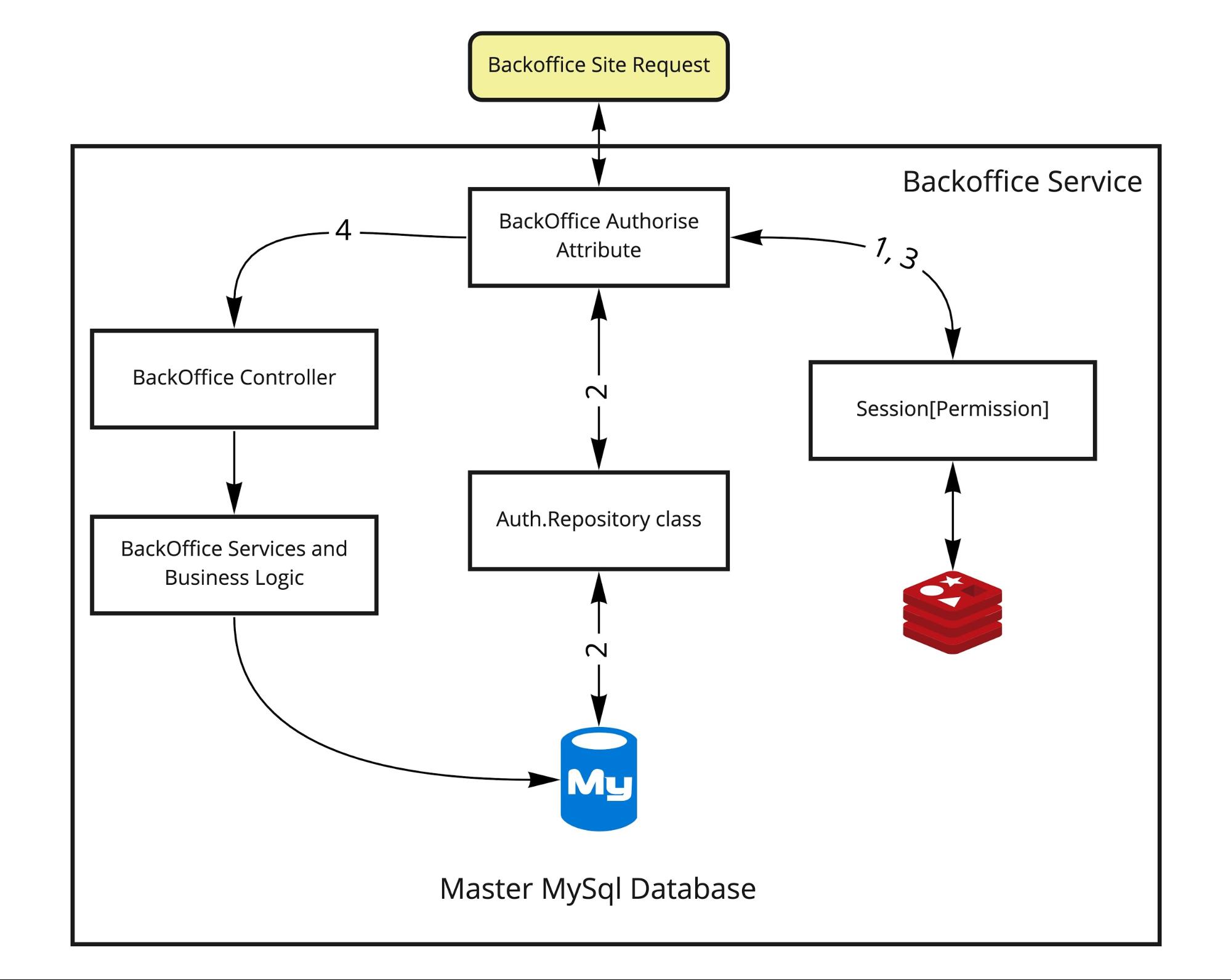
Хочется немного пояснить, как это работало:
- Запрос извне приходит на бэкэнд (там Asp.Net MVC), приносит с собой куку сессии, которая используется для получения сессионных данных из Redis (1). В ней либо есть информация о доступах, и тогда доступ в контроллер открыт (3,4), либо нет.
- Если доступа нет, нужно пройти процедуру авторизации. Здесь для упрощения она показана как часть пути в том же атрибуте, хотя это переход на страницу логина. В случае позитивного сценария мы получим правильно заполненную сессию и перейдём в Backoffice Controller.
- Если данные есть, то нужно проверить их на актуальность в базе пользователя. Не изменилась ли его роль, не надо ли его не пускать теперь на страницу. В этом случае после получения сессии (1) надо напрямую сходить в базу и проверить доступы пользователя с помощью слоя логики аутентификации (2). Далее либо на логин-страницу, либо переход в контроллер. Такая вот простая система, но при этом не совсем стандартная.
- Если все процедуры пройдены, то пропускаем дальше в логике в контроллерах и методах.
Данные пользователей отделены от всех других данных, они хранятся в отдельной таблице membership, функции из слоя логики AuthService вполне могут стать api-методами. Границы домена определены вполне чётко: пользователи, их роли, данные о доступах, выдача и отзыв доступов. Всё выглядит так, что можно вынести в отдельный сервис.
СТАЛО. Так и сделали:
У такого подхода есть ряд проблем. Например, вызов метода внутри процесса — не то же самое, что вызов по http внешнего сервиса. Латенси, надёжность, поддерживаемость, прозрачность операции совершенно другие. Подробнее именно о таких проблемах рассказывал Андрей Моревский в своем докладе »50 оттенков микросервисов».
Сервис аутентификации и с ним сервис устройств используются для бэкофиса, то есть для сервисов и интерфейсов, используемых на производстве. Аутентификация для клиентских сервисов (вроде сайта или мобильного приложения) происходит отдельно без использования Auth. Отделение заняло около года, а сейчас мы опять занимаемся этой темой, переводя систему уже на новые сервисы аутентификации (со стандартными протоколами).
- Нам хотелось перевести данные о пользователях, устройствах и аутентификации из баз по стране в одну. Для этого пришлось переводить все таблицы и использование с идентификатора int на глобальный идентификатор UUId (недавно перерабатывали этот код Роман Букин «Uuid — большая история маленькой структуры» и open-source проект Primitives). Хранение данных по пользователям (так как это персональная информация) имеет свои ограничения и для некоторых стран надо хранить их отдельно. Но глобальный идентификатор пользователя должен быть.
- Много таблиц в базе имеет аудит информацию о том пользователе, который совершил операцию. Это потребовало дополнительного механизма, чтобы была консистентность.
- После создания api-сервисов был долгий и постепенный период перевода на другую систему. Переключения должны были происходить бесшовно для пользователей и требовали ручной работы.
Схема регистрации устройства в пиццерии:
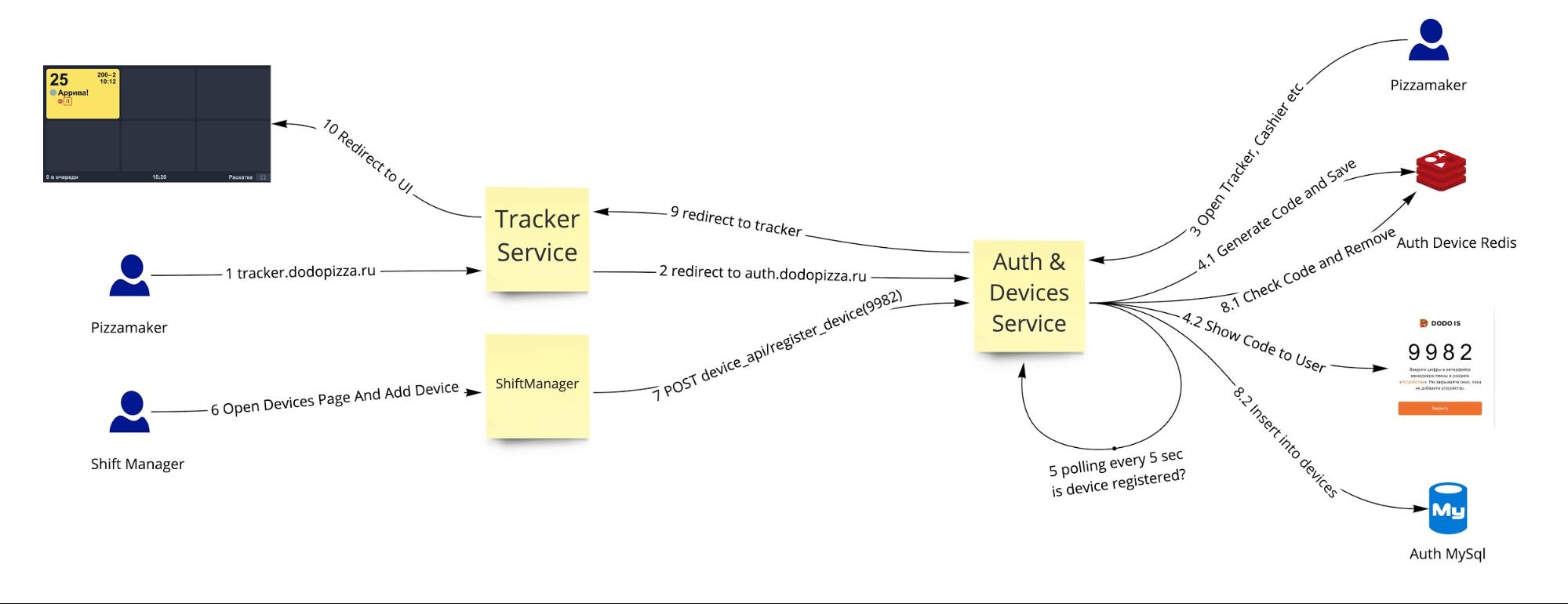
Общая архитектура после выделения Auth и Devices-сервиса:

Чем занимается Трекер
Теперь про второй из нагруженных сервисов. Трекер выполняет двойственную роль:
- С одной стороны, его задача — показывать сотрудникам на кухне, какие заказы сейчас в работе, какие продукты сейчас нужно готовить.
- С другой стороны — оцифровывать все процессы на кухне.

Когда в заказе появляется новый продукт (например, пицца), он попадает на станцию трекера «Раскатка». На этой станции стоит пиццамейкер, который берёт плюшку нужного размера и раскатывает её, после чего отмечает на планшете трекера, что выполнил свою задачу и передаёт раскатанную основу теста на следующую станцию — «Начинение».
Там следующий пиццамейкер начинает пиццу, затем отмечает на планшете, что выполнил свою задачу и ставит пиццу в печь (это тоже отдельная станция, которую нужно отметить на планшете). Такая система была с самого начала в Додо и самого начала существования Dodo IS. Она позволяет полностью отслеживать и оцифровывать все операции. Кроме того трекер подсказывает, как готовить тот или иной продукт, проводит каждый вид продукта по своим схемам изготовления, хранит оптимальное время приготовления продукта и трекает все операции над продуктом.

Так выглядит экран планшета на станции трекера «Раскатка»
Откуда нагрузки?
В каждой из пиццерий примерно по пять планшетов с трекером. В 2016 году у нас было больше 100 пиццерий (а сейчас более 600). Каждый из планшетов делает раз в 10 секунд запрос на бэкэнд и выгребает данные из таблицы заказа (связка с клиентом и адресом), состава заказа (связка с продуктом и указание количества), таблицы учёта мотивации (в ней трекается время нажатия). Когда пиццамейкер нажимает на продукт на трекере, происходит обновление записей во всех этих таблицах. Таблица заказа общая, в неё же одновременно идут вставки при принятии заказа, обновления от других частей системы и многочисленные считывания, например, на телевизоре, который висит в пиццерии и показывает готовые заказы клиентам.
В период борьбы с нагрузками, когда всё и вся кэшировалось и переводилось на асинхронную реплику базы, эти операции с трекером продолжили ходить в мастер-базу. Тут не должно быть никакого отставания, данные должны быть актуальными, рассинхрон недопустим.
Также отсутствие собственных таблиц и индексов на них не позволяло написать более специфичные запросы, заточенные под своё использование. Для примера, трекеру может быть эффективно иметь индекс на пиццерию на таблице заказов. Мы всегда выгребаем из базы трекера заказы по пиццерии. При этом для приёма заказа не так важно, в какую пиццерию он падает, важнее, какой клиент сделал этот заказ. А значит там нужен индекс по клиенту. Ещё для трекера в таблице заказа не обязательно хранить id напечатанного чека или связанные с заказом бонусные акции. Эта информация наш сервис трекера не интересует. В общей монолитной базе таблицы могли быть только компромиссным вариантом между всеми пользователями. Это было одной из изначальных проблем.
БЫЛО. Изначально архитектура была такая:
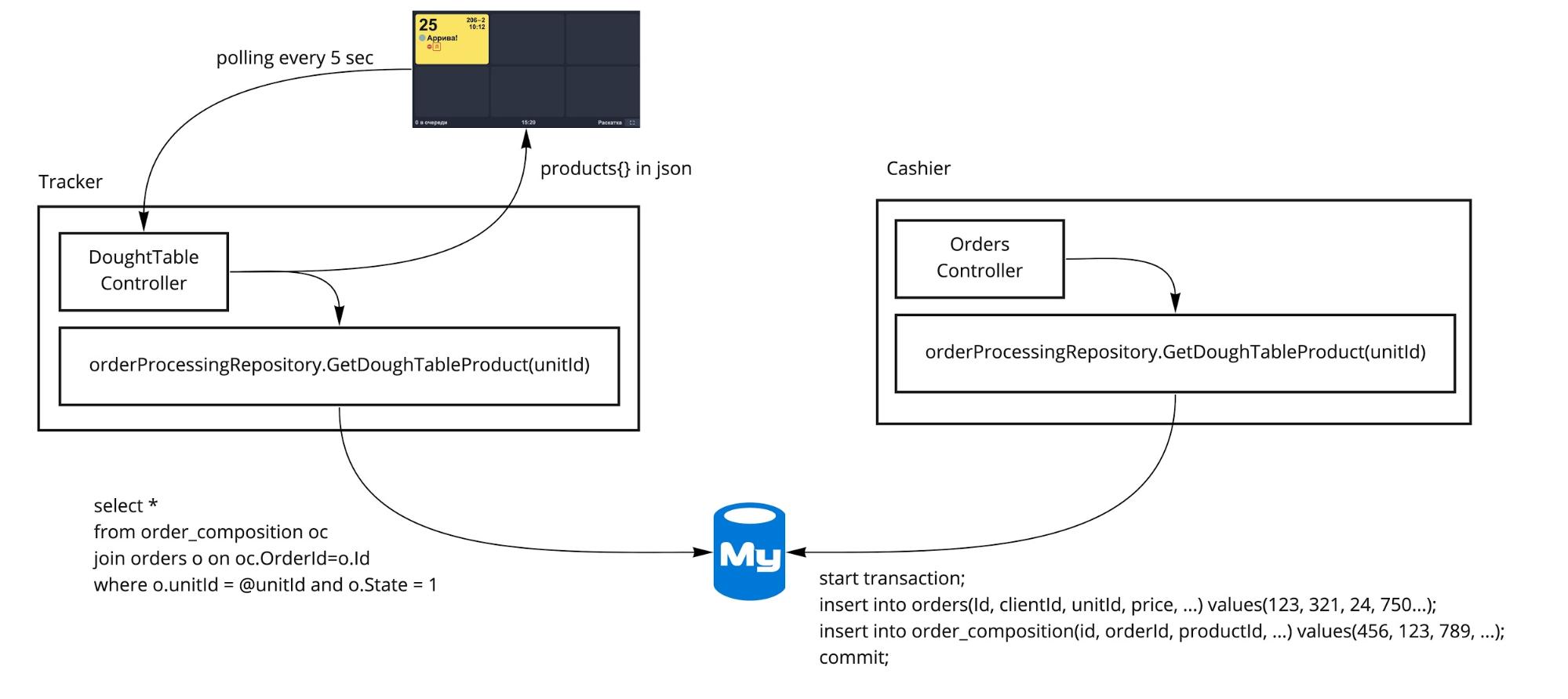
Даже после выделения в отдельные процессы большая часть кодовой базы оставалась общей для разных сервисов. Всё, что ниже контроллеров, было единым и жило в одном репозитории. Использовались общие методы сервисов, репозиториев, общая база, в которой лежали общие таблицы.
Разгружаем Трекер
Главная проблема с трекером в том, что данные должны синхронизироваться между различными базами. Это же и главное его отличие от разделения Auth-сервиса, заказ и его статус могут изменяться и должны отображаться в различных сервисах.
Мы принимаем заказ на Кассе Ресторана (это сервис), он сохраняется в базе в статусе «Принят». После этого он должен попасть на трекер, где ещё несколько раз изменит свой статус: от «Кухня» до «Упакован». При этом с заказом могут происходить какие-то внешние воздействия от Кассы или интерфейса Менеджера смены. Приведу в таблице статусы заказа с их описанием:
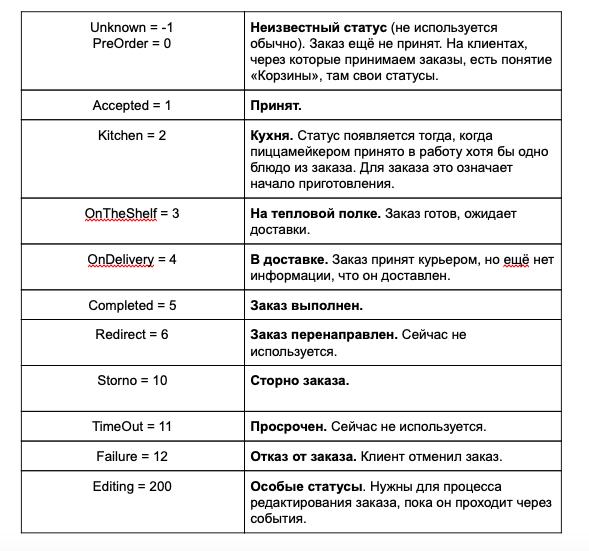
Схема изменения статусов заказа выглядит так:
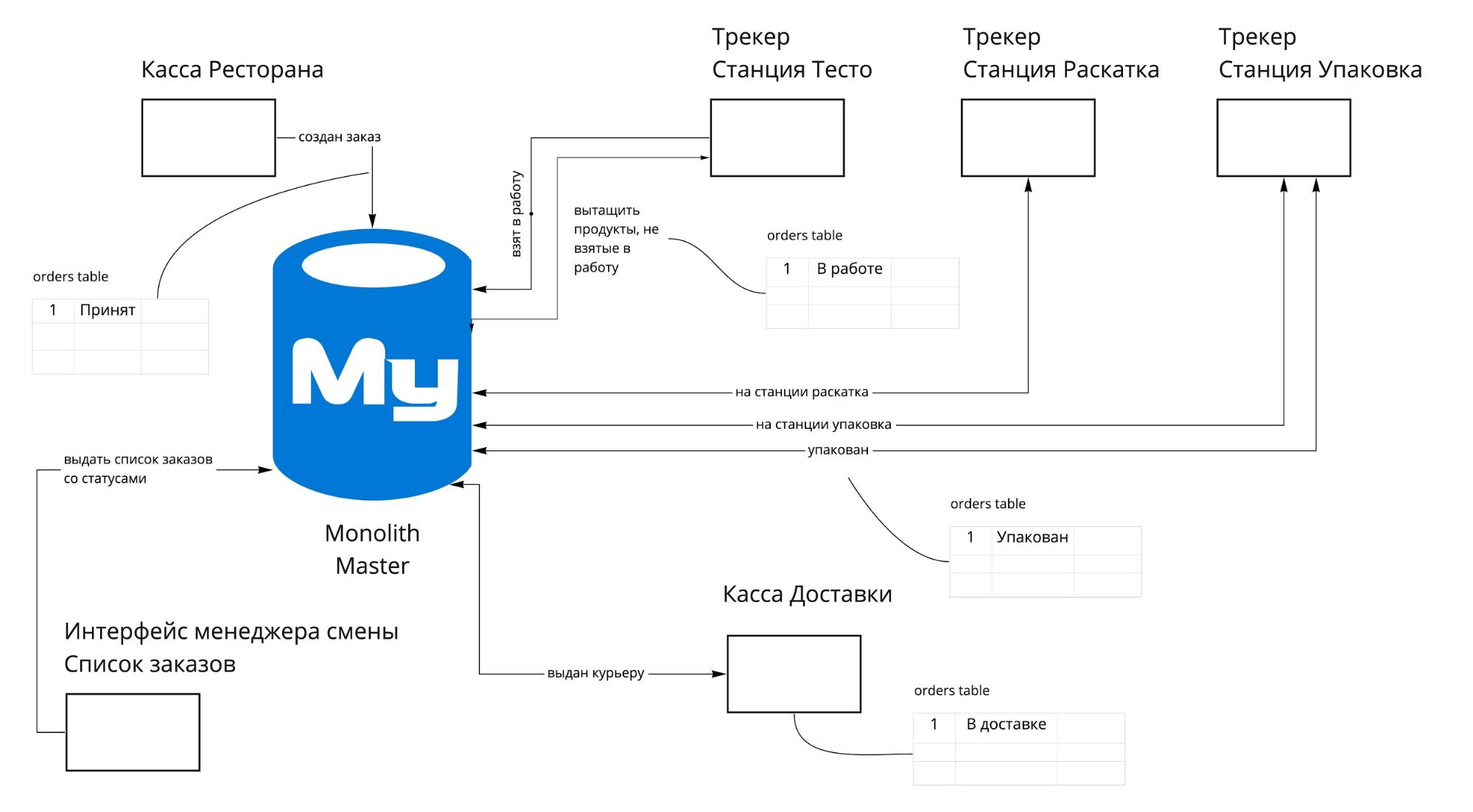
Статусы меняются между разными системами. И здесь трекер не является конечной системой, в которой замыкаются данные. Мы видели несколько возможных подходов для разделения в таком случае:
- Концентрируем все действия заказа в одном сервисе. В нашем случае этот вариант требует слишком большого сервиса по работе с заказом. Если бы мы остановились на нём, то получился бы второй монолит. Проблемы бы мы не решили.
- Одна система делает вызов в другую. Второй вариант уже интереснее. Но при нём возможны цепочки вызовов (каскадные сбои), связность компонентов выше, управлять этим сложнее.
- Организуем события, и каждый сервис обменивается с другим через эти события. В итоге был выбран именно третий вариант, по которому все сервисы начинают обмениваться событиями друг с другом.
То, что мы выбрали третий вариант значило, что для трекера будет своя база, а на каждое изменение заказа он будет посылать событие об этом, на которое подписываются другие сервисы и которое в том числе попадает в мастер-базу. Для этого нам нужен был некоторый сервис, который обеспечит доставку сообщений между сервисами.
К тому времени у нас в стеке уже был RabbitMQ, отсюда и итоговое решение использовать его как брокер сообщений. На схеме показан переход заказа от Кассы Ресторана через Трекер, где он меняет свои статусы и отображение его на интерфейсе Заказы менеджера. СТАЛО:

- На Кассе полностью готов заказ, и его пора отправить на трекер. Бросается событие, на которое подписан трекер.
- Трекер, принимая себе заказ, сохраняет его в свою собственную базу, делая при этом событие «ЗаказПринятТрекером» и посылая его в RMQ.
- В шине событий на заказ уже подписаны несколько обработчиков. Для нас важен тот, который делает синхронизацию с монолитной базой.
- Обработчик принимает событие, выбирает из него значимые для него данные: в нашем случае это статус заказа «ПринятТрекером» и обновляет свою сущность заказа в основной базе.
Если кому-то нужен заказ именно из монолитной таблицы orders, то можно считать его и оттуда. Например, такое нужно интерфейсу Заказы в Менеджере Смены:
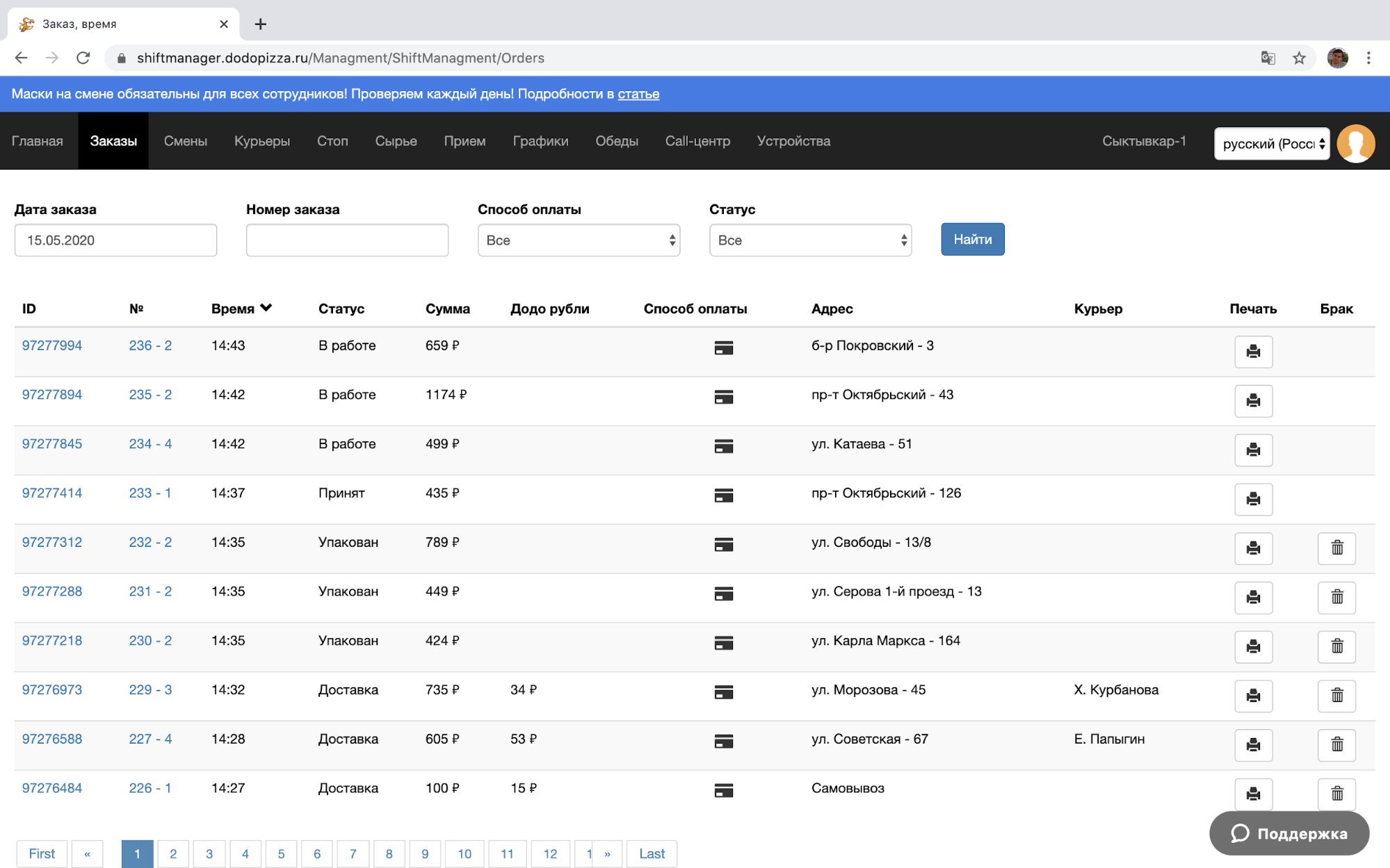
Все другие сервисы тоже могут подписаться на события заказа из трекера, чтобы использовать их для себя.
Если через некоторое время заказ берётся в работу, то его статус сначала изменяется в своей базе (базе Трекера), а потом сразу генерируется событие «ЗаказВРаботе». Оно также попадает в RMQ, откуда синхронизируется в монолитной базе и доставляется другим сервисам. На этом пути могут быть разные проблемы, подробнее о них можно посмотреть в докладе Жени Пешкова про детали реализации Eventual Consistency в Трекере.
Итоговая архитектура после изменений в Auth и Трекере
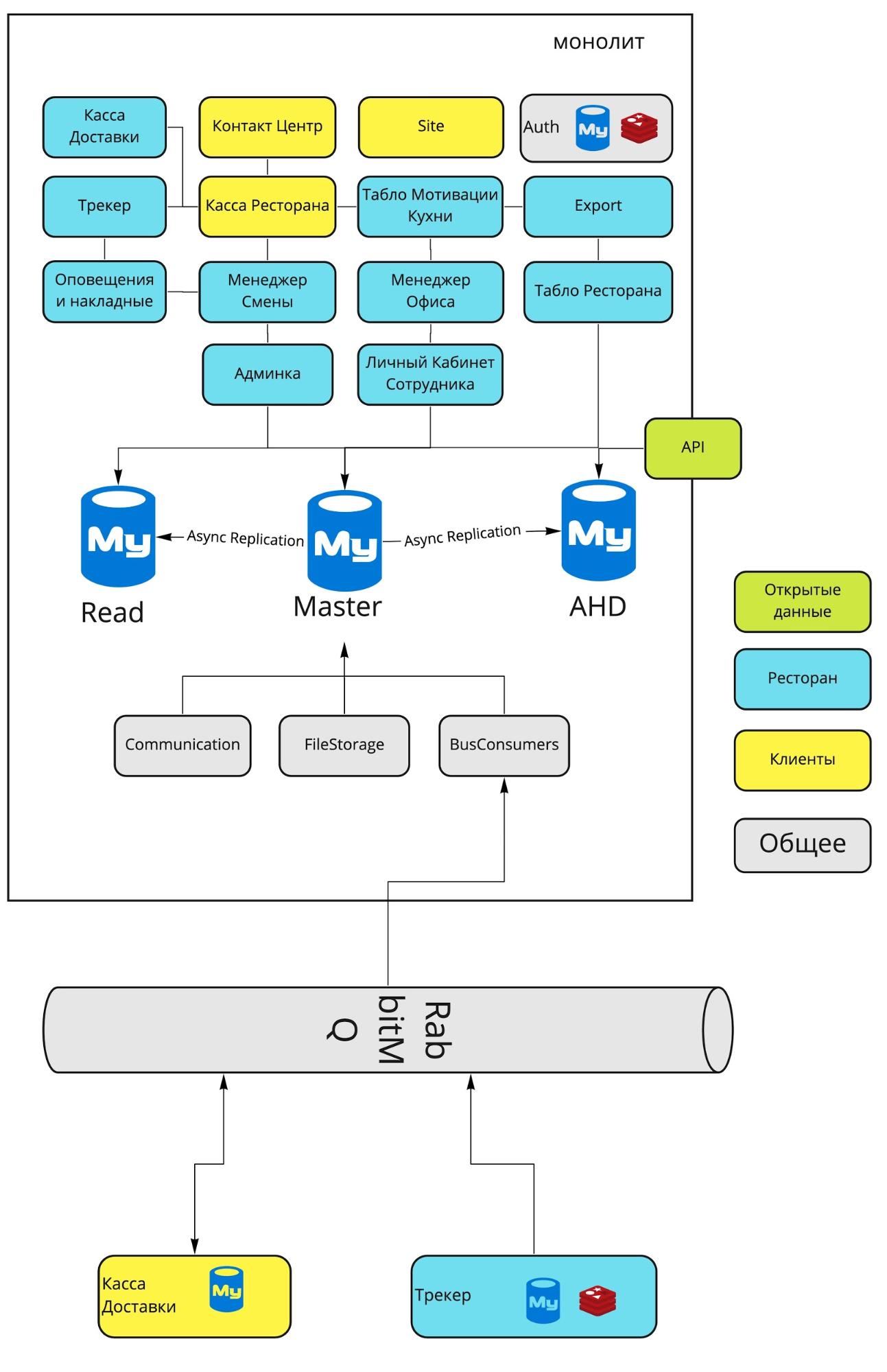
Подводя промежуточный итог: изначально у меня была мысль упаковать девятилетнюю историю системы Dodo IS в одну статью. Хотелось быстро и просто рассказать об этапах эволюции. Однако сев за материал, я понял, что всё гораздо сложнее и интереснее, чем кажется.
Размышляя над пользой (или её отсутствием) от такого материала, я пришёл к выводу, что непрерывное развитие невозможно без полноценных летописей событий, развёрнутых ретроспектив и анализа своих прошлых решений.
Надеюсь, что вам было полезно и интересно узнать про наш путь. Сейчас я стою перед выбором, какую часть систему Dodo IS описать в следующей статье: пишите в комментариях или голосуйте.
