Исследование: ИИ плохо предсказывает баллы на экзамене, выселение, увольнения и материальные трудности

112 исследователей из 160 групп по данным и общественным наукам провели совместную работу и обнаружили, что ИИ и статистические модели, используемые для прогнозирования шести результатов для детей, родителей и домохозяйств, были не очень точными даже при обучении на 13 000 единиц данных из более 4000 семей. Они считают, что эти наработки помогут предупредить провалы при использовании прогностического моделирования, особенно в системе уголовного правосудия и программах социальной поддержки.
Соавтор исследования Мэтт Салганик, профессор социологии в Принстоне и временный директор Центра политики в области информационных технологий в Школе общественных и международных отношений им. Вудро Вильсона, говорит: «Эти результаты показывают, что машинное обучение — не волшебство. Очевидно, что существуют и другие факторы, влияющие на прогнозирование жизненного пути».
Исследование, которое было опубликовано в журнале Proceedings Национальной академии наук, является результатом многолетнего сотрудничества в рамках Fragile Families Challenge. На участие подали заявки более 457 групп, из которых 160 были отобраны, а их прогнозы были оценены с помощью метрики ошибок.
Основу для работы заложило более раннее исследование «Хрупкие семьи», которое проводилось в Принстоне, Колумбийском университете и Университете Мичигана. В ходе него изучали данные около 5000 детей, родившихся между 1998 и 2000 годами в 20 крупных американских городах. Целью исследования было ответить на вопросы: каковы условия жизни и возможности неженатых родителей, каков характер отношений между неженатыми родителями, как живут дети, рожденные в этих семьях, а также как политика и условия окружающей среды влияют на семью и детей.
Набор данных этого исследования состоит из модулей, каждый из которых включает примерно 10 разделов с вопросами по теме, задаваемыми родителям, опекунам, учителям и самим детям. Например, у матери, которая недавно родила, могут спросить об отношениях с родственниками, государственных программах и отношениях в браке, а у 9-летнего ребенка — о родительском надзоре, отношениях с братьями и сестрами и школе. В дополнение к опросам массив данных содержит результаты домашних оценок, включая психометрическое тестирование, биометрические измерения и наблюдения за окрестностями и самими домами семей.
Целью нового исследования было предсказать социальные результаты этих детей в возрасте 15 лет с учетом 1617 переменных. Из переменных шесть были выбраны в качестве основных: средний балл на выпускном экзамене, характер (эмоциональность и настойчивость), опасность выселения, материальные трудности, первое увольнение по собственному желанию.
Исследователям были предоставлены анонимные исходные данные из 4242 семей и 12 942 переменных по каждой, а также данные обучения, включающие шесть результатов для половины из этих семей.
В итоге даже лучшая из более чем 3000 представленных моделей, которые часто использовали сложные методы ИИ и имели доступ к тысячам переменных-предикторов, была лишь незначительно впереди линейной регрессии и логистической регрессии, которые не связаны с машинным обучением.
«Либо удача играет важную роль в жизни людей, либо наши теории, если социологи упускают какую-то важную переменную», — отмечают авторы работы.
Так, материальные трудности у родителей 15-летних детей удалось предсказать в 23% случаев. Точность прогноза оценки выпускного балла составила 19%, характера —6%, выселения — 5%, увольнения — 3%.
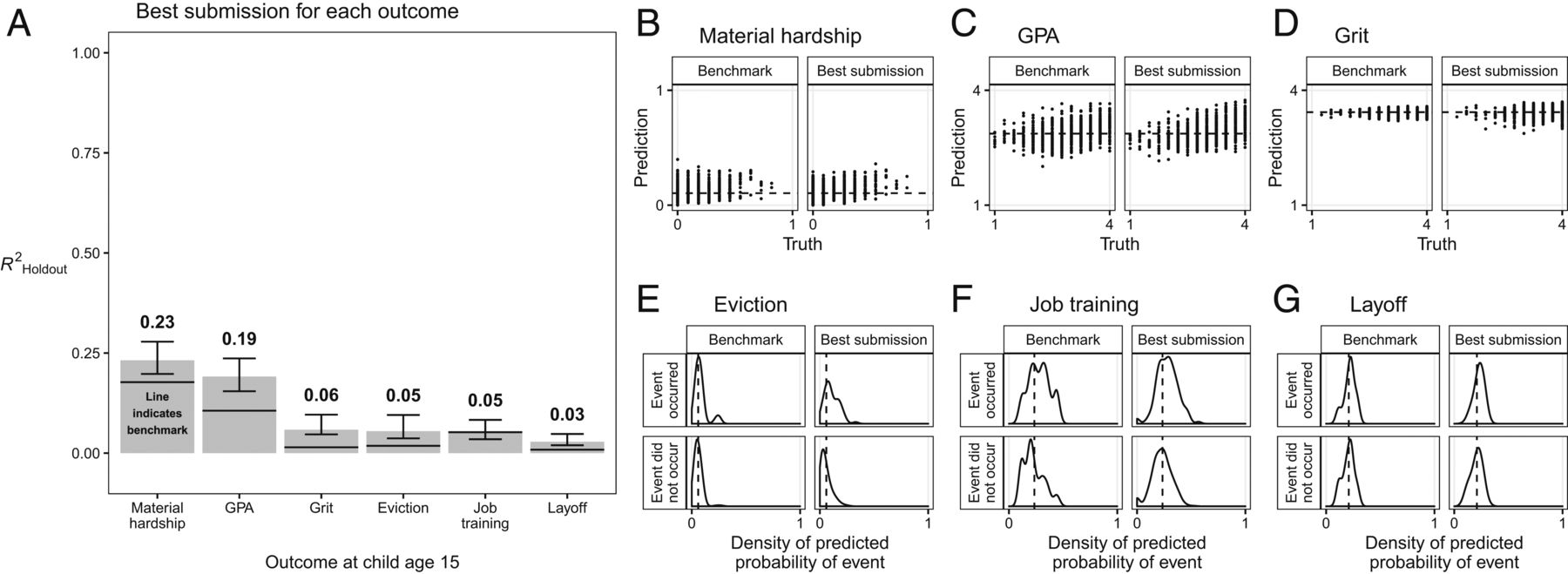
«Результаты поднимают вопросы об относительной производительности сложных моделей машинного обучения по сравнению с простыми эталонными моделями», — заключили соавторы исследования. — «Поэтому, прежде чем использовать сложные прогностические модели, мы рекомендуем лицам, определяющим политику, выяснить, подходит ли достижимый уровень точности прогнозирования для условий, в которых будут использоваться прогнозы, являются ли сложные модели более точными, чем простые модели или эксперты в своей области, и стоит ли возможное улучшение прогнозирующей производительности дополнительных затрат на создание, тестирование и понимание более сложной модели».
Пользователи Reddit вступили в дискуссию с медиа, которые опубликовали материал о данном исследовании. По мнению некоторых из них, исследователи заявили не о неудовлетворительной работе ИИ, а, скорее, о том, что система могла быть «слишком умной» в ситуации с предсказуемыми результатами. Еще один вывод пользователей — в данном конкретном случае результаты были плохими, но это говорит лишь о том, что не нужно применять в широкой практике неэффективные модели.
Между тем The Venture Beat приводит в пример отчет Партнерства по ИИ, некоммерческой коалиции, приверженной ответственному использованию ИИ, которое ранее сделало вывод о том, что алгоритмы не подходят для автоматизации процесса предварительного освобождения под залог или для обозначения некоторых людей как лиц с высоким риском и их последующего задержания. Эксперты опирались на данные о том, что использование алгоритмов при принятии решений для судей приводит к несправедливым результатам на расовой почве, которые с большей вероятностью обозначают заключенных афроамериканцев как подверженных риску рецидивизма.
Также СМИ напоминает о проблеме смещения у ИИ. Например, встраивание слов, общая методика алгоритмического обучения, которая включает в себя связь слов с векторами, неизбежно обнаруживает — и в худшем случае усиливает — предрассудки, скрытые в исходном тексте и диалоге. Так, недавнее исследование, проведенное Национальным институтом стандартов и технологий (NIST), показало, что многие системы распознавания лиц ошибочно распознают людей другого цвета чаще, чем кавказского типа. А внутренний инструмент найма Amazon, который был обучен на резюме, представленных в течение 10-летнего периода — был, по сообщениям, отменен, поскольку демонстрировал предвзятость в отношении женщин.
В июне 2019 года, работая со специалистами по справедливости ИИ, Microsoft пересмотрела и расширила наборы данных, которые она использует для обучения Face API, API Microsoft Azure, предоставляющий алгоритмы для обнаружения, распознавания и анализа человеческих лиц на изображениях. В мае прошлого года Facebook анонсировал Fairness Flow, который автоматически отправляет предупреждение, если алгоритм делает несправедливое суждение о человеке на основании его расы, пола или возраста. Google недавно выпустила What-If Tool, функцию обнаружения смещения веб-панели TensorBoard для своей системы машинного обучения TensorFlow. Чтобы не отставать, IBM осенью прошлого года выпустила AI Fairness 360, облачный, полностью автоматизированный пакет, который «постоянно предоставляет понимание» того, как системы ИИ принимают свои решения, и рекомендует корректировки, такие как алгоритмические настройки или уравновешивание данных, которые может уменьшить влияние предубеждений.
См. также:
