Исследование файловой системы HDD видеорегистратора модели QCM-08DL

Данная статья посвящена изучению файловой структуры жёсткого диска восьмиканального видеорегистратора с целью массового извлечения файлов с видеозаписями. В конце статьи приводится реализация соответствующей программы на языке С.
Видеорегистратор (сокращённо DVR) QCM-08DL применяется в системах видеонаблюдения и позволяет производить восьмиканальную запись видео и аудио. Данная модель, на мой взгляд, одна из самых дешёвых и в тоже время надёжных в эксплуатации. Форматом сжатия видео является популярный формат H264. Для аудио применяется формат сжатия ADPCM. Видео и аудио записываются на стандартный компьютерный SATA жёсткий диск (HDD), установленный внутри DVR. С помощью самого DVR имеется возможность просматривать записи, производя их поиск по дате и времени. Также, имеется возможность извлекать данные в файл на внешний носитель. Во-первых — на USB накопитель, который подключается к USB интерфейсу DVR. Во-вторых — на компьютер через WEB-интерфейс DVR. Имя получающегося файла длинное, и в него входит дата записи, время начала и конца, канал записи и прочая дополнительная информация. Расширение файла — ».264». Исследование содержимого такого файла дало мне понять, что медиа контейнер, в который запакованы аудио и видео потоки, далеко не стандартный. Такой файл можно открыть с помощью плеера, который прилагается вместе с видеорегистратором. Плеер очень неудобный. Но также, можно воспользоваться программой-перепаковщиком в контейнер AVI, которая также прилагается. Данная программа перепаковывает видеопоток, оставляя его в формате H264. А звуковой поток преобразует из ADMCM в PCM, увеличивая его в 4 раза по размеру. В итоге получается .avi файл, воспроизводимый любым стандартным плеером. Отмечу сразу, что данная программа-перепаковщик весьма неудобная. Она позволяет совершать операции только над одним файлом. Для перепаковки множества файлом приходиться открывать их по очереди.
Были поставлены следующие задачи.
- Получить с жёсткого диска видеорегистратора доступ ко всем файлам .264, подключив жёсткий диск к компьютеру.
- Изучить алгоритм, по которому работает штатная программа-перепаковщик 264-avi и создать такую же программу, которая выполняла бы те же операции, но уже не над одним, а над целой группой файлов, причём одним нажатием.
Первая задача, на первый взгляд, может показаться очень простой: нужно просто подключить HDD к компьютеру и открыть разделы в проводнике. Однако здесь имеются свои подводные камни. Данная статья посвящена именно первой задаче.
Я уже заранее знал, что программная оболочка микроконтроллера видеорегистратора основана на операционной системе, подобной Linux. Поэтому, разметка жёсткого диска, вероятнее всего, также будет Linux-подобной. Следовательно, потребуется компьютер с ОС Linux. В моём случае ёмкость HDD — 1TB, компьютер с ОС Xubuntu. Подключив HDD к компьютеру, мне удалось увидеть всего один раздел на несколько гигабайт. Это явно не то, что нужно. Внутри раздела находится множество папок формата имени «YYYY-MM-DD», соответствующие датам записей. Внутри каждой папки — множество файлов, соответствующие записям. Файлы одноимённые с теми, которые получаются при извлечении с DVR. Однако, их размер в разы меньше и расширение не .264, а .nvr. Стоит предположить, что эти самые файлы nvr являются ключами для соответствующих файлов 264 (или их медиа потоков), содержимое которых находится на основном пространстве HDD. Данные папки с файлами я скопировал на отдельный носитель для дальнейшего исследования.
Для исследования использовал множество программных инструментов: дисковый редактор (он же и файловый бинарный редактор) DiskExplorer (WinHex я использовал позже), MS Excel для вспомогательных расчётов и фиксации результатов, среда программирования Dev-C++ для написания вспомогательных и окончательных консольных программ и прочее. В этой статье я попробую рассказать о данной процедуре.
Сначала посмотрим на самый первый сектор HDD (один сектор (1 LBA) занимает 512 Байт). Данный сектор, как правило, содержит MBR структуру. В неё входит загрузчик и базовое оглавление разделов. Структура этого сектора, а также, структура описания раздела, приведены ниже (взято из Википедии).

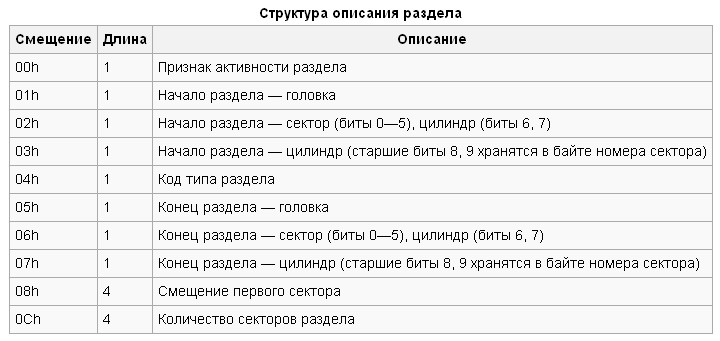
В случае с исследуемым HDD имеем следующее. Глядя на рисунок ниже и руководствуясь таблицами выше, мы видим, что загрузчик отсутствует. Но нас интересует больше таблица разделов. Она выделена в красную рамку. Последние два байта (синяя заливка) — сигнатура MBR. Из таблицы разделов видно, диск поделён на два раздела. Код типа первого раздела (жёлтая заливка) — 0×0B. Это раздел FAT32. Код типа второго (оранжевая заливка) — 0×83. Это один из разделов Linux (в смысле, EXT). Байты кода типа раздела обведены в синюю рамку.
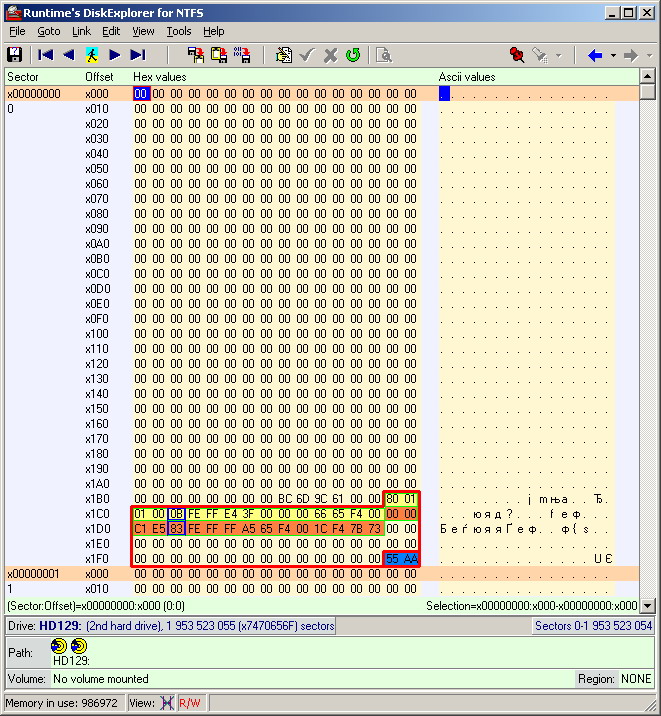
Полная расшифровка сектора MBR с таблицей разделов и их параметрами приведена ниже.
Обращая внимание на размеры разделов (пересчитывая число секторов в гигабайты), несложно догадаться, что на компьютере с ОС Xubuntu отображался именно первый раздел, занимающий незначительную часть дискового пространства. Кстати говоря, в Windows XP также отобразился только первый раздел, но из проводника не открылся. А почему же тогда второй раздел Linux не отобразился в ОС Xubuntu?
Изучив предварительно структуру и организацию линуксовой файловой системы на примере EXT2, я приступил к исследованию второго раздела.
Как видно из таблицы разделов, второй раздел начинается с сектора 16016805. Руководство по файловой системе EXT2 свидетельствует о наличии так называемого суперблока, который располагается в 1024 байтах от начала раздела (то есть в двух секторах от начала). Однако сектор 16016805+2=16016807 оказался пустым. Зато первый сектор 16016805 по своей структуре напоминал суперблок. Но его содержимое полностью не соответствовало описанию содержимого суперблока из руководства. Суперблок — это основной блок, в котором содержится своеобразная таблица различных констант и параметров для функционирования файловой системы: адреса положений и размеры других необходимых блоков, в частности, заголовков файловых записей и директорий. Дальнейшие исследования этого раздела привели меня только к одному выводу: DVR использует свою уникальную файловую систему.
В дальнейшем решил взглянуть на первый сектор первого раздела (сектор 63) и пролистать вниз. Было обнаружено на секторе 65 (двумя секторами ниже) содержимое, полностью похожее на содержимое суперблока ФС EXT2, которое описано в руководстве. Дальнейшие исследования привели к выводу, что первым разделом HDD DVR является раздел EXT2, который и отображался в ОС Xubuntu, невзирая на метку 0×08 (не EXT) в оглавлении раздела! Таким образом, первый раздел жёсткого диска видеорегистратора — раздел EXT2, на котором записаны файлы nvr, являющиеся ключами к требуемым видеозаписям.
Напишу кратко о структуре файлов .264, которые я также предварительно исследовал. Данная информация в дальнейшем будет необходима для исследования второго раздела HDD. Как и в любом медиа контейнере, в »264» присутствует заголовок со служебной информацией и медиа тегами, а также потоки аудио и видео, которые следуют небольшими блоками один за другим. По смещению 0×84 байта от начала файла прописано ключевое слово «MDVR96NT_2_R». Перед этим словом расположены байты, относящиеся к дате и времени записи. Но эта информация содержится в имени файла, поэтому, особого внимания она здесь не заслуживает. После идёт множество байтов нулей. Основная информация с аудио и видео потоками берёт начало по смещению 65536 байт. Блоки видеопотока начинаются с 8-байтового заголовка »01dcH264» (встречается также »00dcH264»). Следующие за ним 4 байта описывают размер текущего блока видеопотока в байтах. Через 4 байта нулей (00 00 00 00) начинается сам блок видеопотока. Блоки аудиопотоков имеют заголовок »03wb» (хотя, по моим наблюдениям, первый символ заголовка в некоторых случаях был необязательно »0»). После — 12 байт информации, которую я пока не разгадал. А начиная с 17-ого байта — аудиопоток фиксированной длины 160 байт. Какие-либо метки в конце файла отсутствуют.
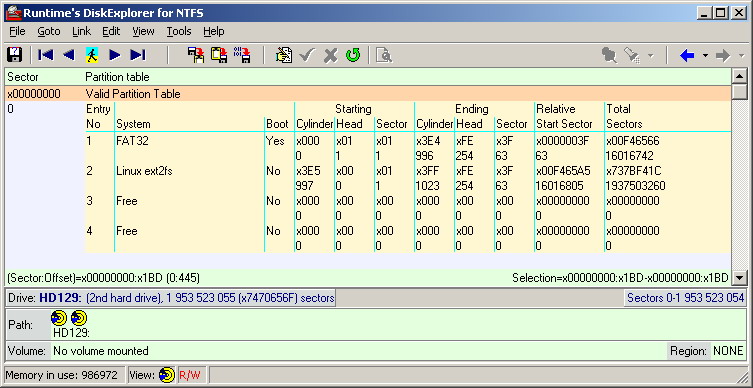
Приступим к исследованию структуры файлов и каталогов, расположенных на первом разделе HDD. Как уже говорилось выше, содержимое раздела было скопировано на отдельный носитель через обычный проводник в ОС Xununtu. В каждом каталоге (директории), помимо файлов nvr содержится один бинарный файл с именем «file_list». Судя по имени, в нём содержится информация о списке файлов в текущем каталоге. Откроем этот файл в бинарном редакторе (см. рис. ниже). Я исследовал структуру данного файла, и здесь нет в принципе ничего интересного. Файл не имеет никакой информации, касающейся расположения искомых медиа потоков. Тем не менее, кратко напишу о данной структуре. Первые 32 байта — заголовок с какими-то константами. Следующие 16 байт имеют отношение к дате и времени и количеству файлов в текущем каталоге. Далее следуют 48 байт констант. Далее — 8 байт констант, свидетельствующих о начале файловой записи. Далее — 96 байт, указывающие полный путь к файлу nvr, включая его имя. Далее — 24 байта, относящиеся к времени (число секунд, прошедших от начала суток, начала и конца видеозаписи) и прочим атрибутам видеозаписи. И так далее, по аналогии, для всех файлов nvr в текущем каталоге. Их число равняется числу видеозаписей за текущие сутки, на которые указывает имя текущего каталога. Для чего нужен этот файл? Видимо, для ускорения поиска видеозаписи внутри интерфейса DVR.
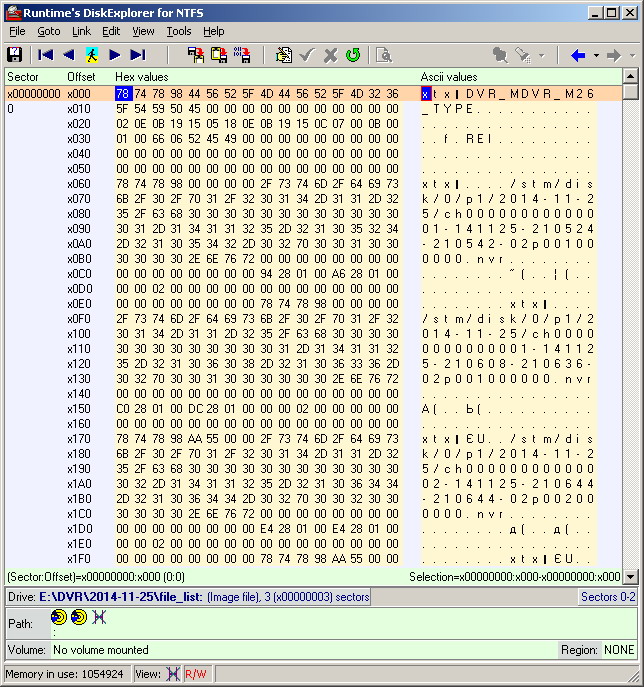
Перейдём к изучению структуры самих файлов nvr. Вид одного такого файла в бинарном (точнее, в 16-ричном) редакторе приведён на рисунке ниже. Не вдаваясь в подробности описания структуры содержимого (часть которой так и осталась для меня загадкой), я выделил самые основные параметры, которые и являются искомым ключом. Это 32-битные (4-байтные) значения, располагающиеся через каждые 32 байта, начиная с байта по смещению 40. На рисунке они выделены красным прямоугольником. В дальнейшем я убедился, что этого вполне достаточно для ключа к видеозаписям. Напоминаю, что 4 байта значения этого ключевого параметра располагаются от младшего к старшему, но не наоборот! Такая нотация обусловлена архитектурой процессора ПК. В приведённом на рисунке примере изображён первый nvr файл первого каталога. Он соответствует первой видеозаписи, сделанной видеорегистратором. Очевидно, что значения параметров, которые я назвал ключевыми, в приведённом примере образуют последовательность целых чисел, начиная с нуля и идущие по порядку по возрастанию. Исследуя другие nvr файлы, и просматривая в них именно эти указанные байты, были также замечены целые числа, идущие по возрастанию. Но данная последовательность начиналась естественно уже не с нуля, и в некоторых случаях местами наблюдались пропуски по одному или два числа. Например (числа от балды): 435, 436, 438, 439, 442, …(или в 16-ричном виде: B3010000, B4010000, B6010000, B7010000, BA010000, …).
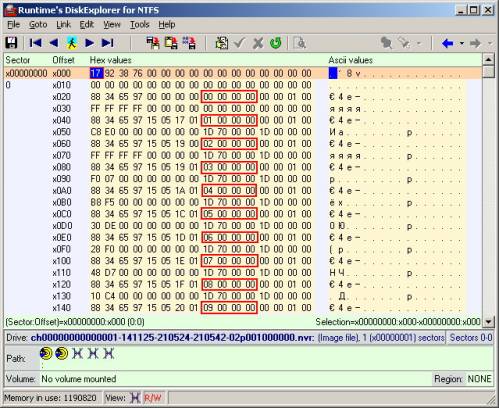
Такая последовательность с пропусками приходилась на nvr файлы, соответствующие видеозаписям, которые DVR записывал одновременно с двух и более каналов. То есть, например, если последовательность »435, 436, 438, 439, 442, …» относится к видеозаписи с одного канала, то пропущенные значения (437, 440, 441) будут относиться к видеозаписи с другого канала, которая осуществлялась в тот же момент времени. В этом я сам убедился, просмотрев и сравнив соответствующие nvr файлы, опираясь на их имя. Не остаётся и сомнений, что приведённые выше числа образуют номера каких-то частей, имеющих отношение к видеозаписям. Остаётся только разгадать связь между этими числами и координатами дискового пространства, на котором размещены данные.
Также, предстояло выяснить, какие именно данные делятся на вышесказанные нумерованные сегменты? Первое предположение — данными являются потоки аудио и видео, которые в контейнере 264 представлены короткими блоками, причём, как было сказано, блоки видеопотока имеют разный размер. При этом DVR на этапе извлечения видеозаписи на внешний носитель собирает эти потоки и упаковывает в контейнер 264. Второе предположение — потоки аудио и видео DVR упаковывает в контейнер 264 в начале и во время видеозахвата. И при этом на HDD записываются уже сформированные данные файла .264, который бы получился в результате его извлечения на внешний носитель. Исследуя пространство HDD где-то в середине второго раздела, наряду с байтами потоков аудио и видео и их заголовками того же вида, что и в контейнере 264, мне также попадались и заголовки самого контейнера: MDVR96NT_2_R. После данного заголовка также присутствовало множество байтов нулей. В целом, исследование показало, что имеет место второй вариант из двух вышеприведённых. Поэтому, для получения нужного файла .264, вероятнее всего, нужно просто соединить вместе все сегменты, номера которых содержатся в соответствующем файле nvr.
Приступим к поиску зависимости между номером сегмента и координатами на HDD.
Начало данных контейнера 264, соответствующего самой первой видеозаписи (там, где нумерация сегментов начинается с нуля) инструментами поиска я нашёл на секторе 16046629 (29824 сектора от начала раздела). Можно сделать предположение о параметре т.н. начального смещения, который будет участвовать в формуле, описывающей искомую зависимость.
Возьмём два nvr файла, соответствующие видеозаписям с разных каналов, которые DVR захватывал одновременно. Для этого взглянем на имена файлов. Например, видеозаписи, на которые указывают файлы «ch00000000000001–150330–160937–161035–02p101000000.nvr» и «ch00000000000004–150330–160000–163000–00p004000000.nvr» велись одновременно. Первая запись — запись с 1-ого канала с 16:09:37 по 16:10:35 времени. Вторая запись — запись с 4-ого канала с 16:00:00 по 16:30:00 времени. Обе записи сделаны 30.03.2015 г. На временной шкале, очевидно, временной интервал первой записи является подмножеством временного интервала второй записи. Принимаю во внимание также тот факт, что в меньшем интервале времени (в пересечении двух интервалов) DVR не осуществлял видеозахват ни с одного из остальных 6-ти каналов. Просмотрим содержимое этих nvr файлов. Убедимся, что отсутствующие те самые числа (номера сегментов) во втором длинном файле обязательно присутствуют в первом коротком файле, целиком и полностью. С помощью DVR обычным способом требуется заранее извлечь хотя бы один из файлов .264, на которые ссылаются исследуемые файлы nvr. Допустим, извлекли «ch00000000000001–150330–160937–161035–02p101000000.264». Откроем его в бинарном редакторе. Как уже было сказано, в начале данного файла до ключевого слова «MDVR96NT_2_R» присутствуют уникальные байты, соответствующие дате и времени видеозаписи, содержащейся в данном файле. Списываем все эти байты, начиная от ненулевого и кончая заголовком (чем короче цепочка байт, уникальная для данной видеозаписи, тем лучше). Также, записываем смещение этой цепочки байт от начала файла. Следует обратить особое внимание, что в начале извлечённого файла .264 присутствуют лишние 4 байта нулей. Это стало заметно, сравнивая первые 512 байт файла .264 и сектор дискового пространства, с которого начинаются данные содержимого одного из файлов .264 (файл практически любой ФС всегда начинается в начале сектора, мало того, — кластера). То есть, информация в файле .264 сдвинута заранее на 4 байта вправо. Размер (в байтах) любого файла .264 кратен 512 только после предварительного вычитания числа 4 из размера. Приступим к поиску сектора, с которого начинается исследуемый файл .264. В дисковом редакторе запускаем функцию поиска. В поле искомого значения вписываем уникальную цепочку байт, списанную заранее. Для ускорения поиска вписываем в поле «искать по смещению» значение смещения, предварительно вычитая 4. Запускаем поиск. Через несколько часов поиск завершился удачно. Записываем номер сектора, в котором найден уникальный заголовок. Пусть это будет значение s. Смотрим содержимое файла nvr для этой видеозаписи. Списываем номер первого сегмента (4 байта по смещению 40). Пусть это будет значение b. Итого, пока у нас известны номер сектора диска (16046629) для нулевого номера сегмента (в самой первой видеозаписи) и номер найденного сектора диска s для только что списанного номера сегмента b. Можно вычислить предполагаемый размер сегмента: (s-16046629)/(b-0). Вычислив, получил значение 128. Таким образом, размер сегмента равен 128 дисковым секторам (LBA), или 128×512=65536 байт!
Я провёл ещё один дополнительный интересный эксперимент, чтобы окончательно развеять все сомнения. Он описан ниже.
От начала сектора s выделим область на диске, размером, сравнимым с размером файла .264, который начинается с данного сектора. Если мои догадки верные, то в выделенную область попадут сегменты другого файла .264, который захватывался на HDD одновременно с первым. Сохраним эту область в файл (создадим образ). Порежем получившийся образ на файлы по 65536 байт (размер сегмента). Это можно сделать с помощью функции «Разбить файл» в Total Commander. Пусть это будут куски M1, M2, M3, …. Точно также порежем исследуемый файл .264 (который был по-юзерски извлечён с DVR), но убрав предварительно 4 байта нулей вначале. Пусть это будут куски K1, K2, K3, …. С помощью функции «Сравнить по содержимому» в Total Commander сравним по очереди куски образа и куски от файла .264. (M1 с K1, M2 с K2 и т.д.), руководствуясь номерами сегментов из соответствующего файла nvr. При этом получается следующее. Допустим (числа от балды), цепочка чисел в nvr следующая: 435, 436, 438, 439, 442, … При таком раскладе M1=K1, M2=K2, M4=K3, M5=K4, M8=K5, …. То есть, кусочки, на которые разбивался файл-образ и файл .264 оказываются равными между собой, учитывая соответствующее опережение по номерам кусков файла-образа, согласно пропускам чисел в последовательности. Вот так вот!
Итого, мы получили предполагаемую зависимость: S=16046629+128*d, где d — номер сегмента в файле nvr, а S — номер сектора на HDD, начиная от самого начала диска, с которого начинаются данные содержимого сегмента. Размер сегмента — 128 секторов. Приведённая выше формула не берёт во внимание существование второго раздела. Зависимость найдена только для конкретного примера с HDD на 1TB. Возможно, если поставить в DVR HDD другой ёмкости, константы примут иной вид.
Чтобы убедиться в справедливости формулы, вычислим позицию первого сегмента какого-либо другого произвольного файла .264, руководствуясь соответствующим файлом nvr. Обращая внимание на дату и время в имени файла, сравним их с первыми байтами в заголовке .264, находящемся на вычисленном секторе. Байты, кодирующие по отдельности число, месяц, год, часы, минуты, секунды, соответствуют временным данным в названии файла. Следовательно, «попали в точку»! Подсчитаем в файле nvr, соответствующем извлечённому заранее файлу .264, количество сегментов cs. Вообще, их число равно cs = sf/32–1, где sf — размер файла nvr. Если файл .264 состоит из cs сегментов, то его размер должен быть равен cs*65536+4 (число сегментов, умноженное на размер сегмента в байтах, плюс 4 тех самых байта нулей). И это действительно так!
Всё-таки, попытаемся исследовать второй раздел. Как уже отмечалось ранее, нечто похожее на суперблок находится прямо в первом секторе раздела (16016805). А его точная копия была обнаружена семью секторами ниже (16016812). Очевидно, ненулевая основная информация находится в первом секторе суперблока. Его вид в дисковом редакторе приведён на рисунке ниже.
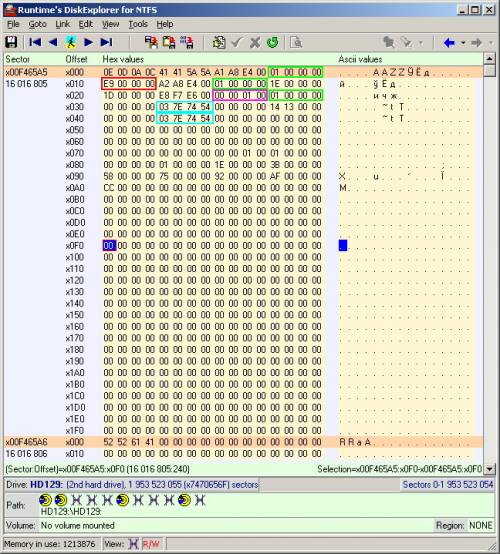
Часть 4-байтных параметров я сумел расшифровать. Голубым цветом выделены дата и время монтирования раздела. Дата и время представлены в специальной нотации «Unix time» (число секунд, прошедших с полуночи 1 января 1970 года). В приведённом примере »03 7E 74 54» (десятичное значение 1416920579) соответствует «Tue, 25 Nov 2014 13:02:59 GMT». Для перевода значений я пользовался специальным онлайн калькулятором. В фиолетовой рамке обведено значение 65536. Возможно, именно на эту позицию суперблока ссылается интерпретатор файловой системы внутри программы DVR, когда считывается размер блока (в предыдущем контексте я называл блоки сегментами). В зелёную рамку выделены значения 1. Одно из них наверняка обозначает положение начала т.н. битовой карты (в количествах блоков от начала раздела). Действительно, заранее было обнаружено начало информации нечто похожей на битовую карту на секторе 16016933 (16016805+128×1). В красную рамку выделено значение 233. Это как раз и есть позиция начала данных видеозаписей .264 от начала раздела: 16016805+128×233=16046629.
То есть, второй раздел можно назвать урезанным и немного видоизменённым разделом EXT2. В нём есть суперблок, его копия, битовая карта. Но отсутствуют т. н. информационные узлы, соответствующие файловым записям. Раздел содержит данные файлов .264 (аудио и видео потоки), но информационные узлы (скажем так) для этих данных размещены в nvr файлах на первом разделе. Может быть, существует более грамотная формулировка? Но мне это уже не столь важно.
Напишем простую программу для массового извлечения файлов .264. Сразу говорю, что большого опыта в программировании по Windows у меня нет. Программа сканирует все файлы nvr, скопированные заранее на раздел 1TB нового HDD. Анализируя их, программа создаёт файл .264 с тем же именем в том же каталоге, используя обращение к секторам оригинального HDD. Предварительно в пустом разделе нового HDD создана папка с именем «DVR», в которую помещены папки по датам, что скопированы «обычным способом» в Линуксе. Можно было в данную программу включить алгоритм работы с первым линуксовым разделом для доступа к файлам nvr, чтобы не прибегать к их предварительному копированию. А ещё можно было добавить другие удобные фишки. Да, можно было, но мне на тот момент хотелось сделать всё как можно быстрее.
Для сканирования директорий я не использовал рекурсию, принимая во внимание, что формат директорий фиксирован и имеет два уровня вложения. Соответственно, я применил два цикла: пробег по папкам, пока они не закончатся, и пробег по файлам в каждой папке с тем же условием. Для чтения файлов я применил сишную функцию fopen. Для работы с секторами HDD я использовал функционал WinAPI по аналогии работы с файлами. Перейдём к коду программы.
Библиотеки нужны такие.
#include
#include
#include
А эти функции я полностью скопировал с какого-то форума.
HANDLE openDevice(int device) {
HANDLE handle = INVALID_HANDLE_VALUE;
if (device <0 || device >99)
return INVALID_HANDLE_VALUE;
char _devicename[20];
sprintf(_devicename, "\\\\.\\PhysicalDrive%d", device);
// Creating a handle to disk drive using CreateFile () function ..
handle = CreateFile(_devicename,
GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE,
NULL, OPEN_EXISTING, 0, NULL);
return handle;
}
HANDLE openOutputFile(const char * filename) {
return CreateFile ( filename, // Open Two.txt.
GENERIC_WRITE, // Open for writing
0, // Do not share
NULL, // No security
OPEN_ALWAYS, // Open or create
FILE_ATTRIBUTE_NORMAL, // Normal file
NULL); // No template file
}
В функцию копирования заключена формула линейной зависимости, которая фигурировала в теории выше.
void copy(HANDLE device, HANDLE file, unsigned long int s){
LONG HPos;
LONG LPos;
__int64 sector;
sector = 16046629+128*s;
HPos = (sector*512)>>32;
LPos = (sector*512);
SetFilePointer (device, LPos, &HPos, FILE_BEGIN);
DWORD dwBytesRead;
DWORD dwBytesWritten;
unsigned char buf[65536];
ReadFile(device, buf, 65536, &dwBytesRead, NULL);
WriteFile(file, buf, dwBytesRead, &dwBytesWritten, NULL);
}
Основная функция также довольно простая.
int main(){
HANDLE hdd = openDevice(1); //Здесь надо указать номер HDD от DVR, который прописался в системе;
SetFilePointer (hdd, 0, NULL, FILE_BEGIN);
DWORD dwBytesRead;
char name[100];
unsigned int bl; //Пробег по блокам;
unsigned int N; //Число блоков;
unsigned long int pt; //Указатель на блок;
WIN32_FIND_DATA fld,fld1; //Структура с файлом nvr или с папкой;
HANDLE hf,hf1;
hf=FindFirstFile("E:\\DVR\\*",&fld);
FindNextFile(hf,&fld);//Пропускаем ".";
FindNextFile(hf,&fld);//Пропускаем "..";
do{
char *str = new char;
sprintf(str,"%s%s%s","E:\\DVR\\",fld.cFileName,"\\*.nvr");
printf("\n\nFOLDER: %s\n\n",str);
hf1=FindFirstFile(str,&fld1);
do{
FILE *nvr;
sprintf(name,"%s%s%s%s","E:\\DVR\\",fld.cFileName,"\\",fld1.cFileName);
nvr=fopen(name,"rb");
name[strlen(name)-3]='2'; //Путь и имя сохраняем, но
name[strlen(name)-2]='6'; //корректируем разширение;
name[strlen(name)-1]='4';
HANDLE out = openOutputFile(name);
SetFilePointer(out, 4, NULL, FILE_BEGIN); //Как в "оригинале", оставляем 4 нулевых байта в выходном файле (для полного соответствия);
bl=0;
N=fld1.nFileSizeLow/32-1; //Расчёт количества блоков (кусков);
printf("\t%s\n\t%i Blocks\n\n",fld1.cFileName,N);
for(bl=0;bl
На старом компьютере с процессором Pentium 4 и PCI контроллером SATA программа успешно переложила до конца заполненный HDD несколькими тысячами файлов .264 в среднем за 7 часов. На новом компьютере — раза в три быстрее. Как я уже отметил, программа не универсальная, все константы и переменные подстроены под мой конкретный случай с HDD на 1TB. Однако, можно ещё немного поработать и сделать её универсальной, нарисовать к ней графический интерфейс.
Во второй части статьи я напишу, как «своими руками» осуществить перепаковку из контейнера »264» в стандартный контейнер «avi».
