Использование нейросетей в современной биологии

С каждым годом меняется наука, методы анализа и направления исследований. И если в самом начале развития биологии ставка была на макроуровень, то с течением времени уровень «уменьшился» до молекулярного. И вместе с уменьшением уровня увеличился поток получаемых данных — на учёных буквально обрушилась целая лавина. Естественно, необходимо вычленять важную новую информацию из всего этого потока данных. Причем самостоятельно исследователю это сделать без техники невозможно, да и с техникой порой бывают трудности. И тут в биологию приходит Big Data.
Для тех, кому дальше читать интересно, стоит пояснить, что статья написана в соавторстве с Анастасией Новосадской, anastasiamrr — специалистом по молекулярной биологии и применению в этой области нейросетей — и Владиславом Светлаковым svetlakoff, специалистом по нейросетям.
В далёком-далёком прошлом наших предков интересовала биология на макроуровне: это было изучение всего живого, что можно увидеть вокруг невооруженным глазом — птицы, насекомые, растения и прочее, прочее. Это было время описательной биологии. Люди описывали буквально все, что видели: лист зеленый, на нем есть жилки, тут он овальный, тут какой-то пальчатый…
Затем, с течением времени, у людей появлялись новые знания, они наслаивались друг на друга, да и технический прогресс не стоял на месте. Люди постепенно стали отходить от макроуровня, переходя на более «маленькие» уровни, которые уже нельзя изучить, имея в наличии только хорошее зрение. Кох, Пастер, Виноградский, и многие другие привнесли в мир знания о микроорганизмах, и изучение биологии перешло на клеточный уровень. Людей все больше интересовали источники болезней, брожение, возможности использования микроскопических организмов, особенности клеток своего организма. После Уотсоном и Криком Франклин была открыта структура ДНК, что стало фурором и настоящим прорывом для науки. Это был своеобразный скачок от клеточного уровня к молекулярному. И в настоящее время биология совсем не такая, как была в самом начале, и даже не такая, какой была лет 30–40 назад. В разы усложнилось оборудование, усовершенствовались инструменты и методы исследования, зачастую необходимо обладать компетенциями в нескольких областях, чтобы провести действительно качественный эксперимент. Вдобавок ко всему, вместе с «миниатюризацией» биологии, данных с одного исследования становится все больше — это и расшифровка последовательности генов и их функций, оценка уровня экспрессии и многое другое. И их настолько много, что исследователь не может провести анализ самостоятельно, без помощи техники. И вот, биологию приходит айтишный термин «Big Data».
До сих пор нет конкретных рамок, показывающих переход от «просто данных» к «большим». Можно только отметить, что данные являются разнородными, причем часть из них может быть некорректна, часть являться неполной, а многие из них просто напросто повторяться. И такие массивы данных необходимо эффективно и быстро обрабатывать. Под обработкой имеется в виду получение новой информации, новых знаний. Одним из самых простых и ярких примеров Big Data может являться секвенированный (расшифрованный) геном человека. Для сравнения: число пользователей телеграмма составляет 700 миллионов, в то время как число пар нуклеотидов в человеке составляет порядка 3 миллиардов.
Накопление таких больших массивов данных ставит перед современной биологией задачу эффективной обработки цифровой информации с максимальной автоматизацией и оптимизацией, и тем самым уменьшение влияния человеческого фактора. Вдобавок, по сравнению с прошлым веком, сейчас каждый год идет не плавное накопление новой биологической информации, а целый ее наплыв стремительными темпами. Получается своеобразная лавина, которая попросту не успевает преобразовываться в новые знания. Последние двадцать-тридцать лет развиваются методы искусственного интеллекта (ИИ), особенно на слуху машинное обучение и одно из его направлений — искусственные нейронные сети.
Однако никто не забывал и о математических методах анализа. Имеется в виду математический и статистический анализ с помощью языков программирования. В биологии популярны R и Питон, т.к. они достаточно просты в освоении и для них написано большое количество библиотек для статистического анализа и визуализации. И тут стоит понять следующее: для одних опытов (да, с большим массивом данных) приемлемее и выгоднее использовать математические методы, для других — удобнее и быстрее использовать компьютерное зрение.
В частности, когда невозможно оценить все корреляции ввиду их огромного количества, когда процесс слишком трудоёмок или же когда данные не поддаются нормальной аппроксимации — выгоднее использовать машинное обучение. Просто потому, что человек не всегда может оценить и заметить мельчайшие взаимосвязи и детали эксперимента. Или может, но к этому придется идти путем огромного количества проб и ошибок, что неудобно и невыгодно. Очевидно, что в некоторых ситуациях нет принципиальности в выборе метода и все будет упираться только в желание и знания исследователя (ей).
Никто не отменял также анализ той или иной информации при помощи вручную задаваемыми исследователями правил. Например, программа не самостоятельно сделала вывод о комплементарности нуклеотидов (взаимном соответствии молекул в ДНК/РНК), это правило задал человек. Появилась возможность подсчитать результаты транскрипции или репликации с помощью компьютерных вычислительных ресурсов, смоделировать результат трансляции белка и так далее (иными словами получить информацию из анализа молекулярных данных, которая в дальнейшем может обрабатываться еще детальнее).
Естественно, такие правила могут вырастать в целые деревья, и они могут ложиться в основу классификации (например, как в случае решающих деревьев), однако, как показывает практика, правила придуманные человеком, ограничены его собственной фантазией. В свою очередь подходы Deep Learning не имеют такого недостатка, из-за чего они и нашли настолько глубокое применение практически во всех сферах нашей жизни, в том числе и в экспериментальной биологии.
В биологии нейросети применяются достаточно обширно, наравне со с компьютерным статистическим анализом и анализом с помощью условий. Например, для глубоко анализа изображений и физиологических закономерностей при цифровом фенотипировании (определении особенностей внешних характеристик), для исследования геномов и траскриптомов (результатов перевода генома в РНК), изучении структуры белков, липидов и других органических молекул клеток, предсказании поведения молекул при адресной доставке лекарств, эффективность таргетной терапии и многое другое.
Например, мобильное приложение Flora incognita, построено на нейросети и позволяет по фотографии идентифицировать вид растения. Фактически как поиск по фото Яндекса или Гугла, только точнее. Вдобавок, в приложении есть дополнительная информация по каждому из идентифицированных видов. Удобно, быстро. И помогло далеко не одному поколению биологов на практике по ботанике.
Или же приложение AlphaFold2, позволяющее предсказывать трехмерную структуру белка (фолдинг). Предсказание свертки белка в определённую конформацию важно для объяснения и понимания функционала белка, способов взаимодействия и многого другого. В статье «AlphaFold2: глубокий разум и его правильное применение» можно посмотреть, почему это так важно и почему само приложение вызвало бурю эмоций в научном сообществе.
Интересный пример: разработка нейросети учеными университета Нью-Йорка для определения структуры ДНК организма. Она сумела вычленять основные последовательности генома, которые отвечают за жизненный цикл и внешний облик (фенотип). И именно благодаря такой нейросети сейчас становится гораздо проще совершенствовать сельскохозяйственные растения и животных и, как следствие, пищевую и другие отрасли.
Вся прелесть нейросетей
Искусственная нейронная сеть — математическая модель, и, в том числе, ее программная или аппаратная реализация, которая была создана по примеру работы биологических нейронных сетей. В биологической нейронной сети каждый нейрон соединен функционально с другими такими же нейронами и передает и принимает различные дискретные сигналы. Искусственная нейронная сеть по факту имитирует работу естественной биологической нейронной сети — анализирует и в некоторых случаях запоминает информацию. Но мы ни в коем случае не ставим знак равенства между нейросетями биологическими и искусственными, т.к. биологическая нейронная сеть имеет гораздо более сложную архитектуру (как и в принципе практически все биологические структуры более сложны нежели компьютерные), сами связи между нейронами достаточно сложны из-за наличия множества нейромедиаторов и электрических узлов разрыва. Вдобавок, в биологической нейросети работает принцип суммирования сигналов.
Ключевая особенность, которая обеспечивает нейронным сетям возможность воспроизводить практически любые зависимости и корреляции (они, как упомянуто выше, являются одной из главных составляющих биологических данных) — их многослойная структура. Один нейрон не в состоянии восстановить сложные зависимости, ввиду ограниченности его функций, однако объединение таких нейронов в группы, которые называются слоями, позволяет расширить предсказательную способность в разы. К слову, у человеческой сетчатки (орган, отвечающий за восприятие информации и преобразования ее в нервные импульсы) имеется также многослойная структура. Различают 10 микроскопических слоев, которые, работая слаженно, позволяют человеку, например, читать такие посты на Хабре.
Для создания качественной нейронной сети необходима функция активации. Без функции активации нейрон можно сравнить с линейной регрессией, которая успешно справляется с созданием линейных разделяющих плоскостей, либо выделением линейных зависимостей. При добавлении функции активации у нейрона появляется возможность создавать разделяющую плоскость, которая в свою очередь будет нелинейной. Комбинация таких нелинейных разделяющих плоскостей позволяет создавать любые разделяющие гиперплоскости, что позволит восстанавливать сложные, нелинейные зависимости, которые абсолютно необходимы для экспериментальной и предсказательной биологии.
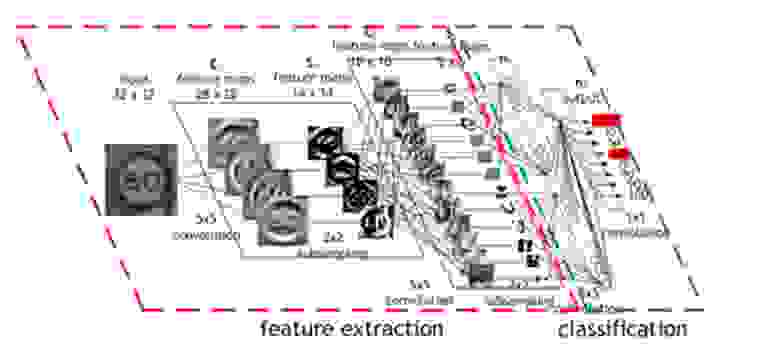
Схема разделяющих плоскостей и классификации
Как говорилось ранее, биологические данные имеют сложную внутреннюю структуру, массивность самих данных и сложные зависимости, и как раз такие задачи нам и позволяют решать нейронные сети. От исследователя требуется обеспечить достаточный объем входных (обучающих) данных (что в биологическом исследовании как правило не проблема), после чего нейросеть, в процессе обучения, сможет найти то самое зерно, которое позволит там делать правильные предсказания. Но для этого нам необходимо применять более высокоуровневые «модули» нейронной сети, например свёртки. А некоторые биологические данные есть смысл анализировать при помощи рекуррентных нейронных сетей или автоэнкодеров.
Успешное применение искусственных нейронных сетей требует наличия аннотированных наборов данных, то есть данных, для которых известны детектируемые параметры. Например, для анализа физиологического состояния растения по фотографии необходим набор данных как с фотографиями, так и с оценкой жизнеспособности растения для каждой фотографии. Для распознавания объектов, например, растений или людей, необходимо представить нейронной сети информации о нахождении данных объектов на фотографиях тренировочной выборки, а для сегментации изображений — указание сегментированой области, на которой находится интересующих объект. Существуют публичные наборы данных, на которых можно успешно тренировать собственные нейронные сети. К такому набору относится, например, PlantVillage.
Интересный факт: для тестирования выполнения тех или иных подходов компьютерного зрения в качестве классического тестового изображения используют фото Лены Сёдерберг. Это изображение шведской фотомодели с фрагмента обложки журнала Playboy 1972 года.
Использовать такие наборы можно в связке с собственными аннотированными изображениями, например, используя их вместе со своими данными для тренировки, так и пользуясь трансферным обучением нейронной сети. Такой подход основан на особенности архитектур современных нейронных сетей. Известно, что ключевую роль в итоговой классификации играют самые нижние слои нейронной сети, которые обрабатывают низкоуровневую информацию. Преобразования, которые происходят не верхних слоях нейронной сети, позволяют получить абстрактную информацию, которая передается на вход низкоуровневым классификаторам. По этим причинам, достаточно эффективным является тренировка нейронной сети на одном, максимально общем наборе данных, а затем ее дообучение, чаще всего с заморозкой верхних слоев, на более «узких» (narrow) данных. Данный подход позволяет провести эффективную тренировку нейронной сети в случаях малого количества изначальных данных. И такая возможность обучения для нейронной сети является настоящим ее преимуществом, т. к. в этом процессе выявляются сложные зависимости и выполняется обобщение.
Когда нейросеть «обучена», она начинает помогать ученому в его исследованиях. Достаточно лишь загрузить входные данные. А зачем это биологам? Как минимум, чтобы снизить затраты на эксперименты. Но есть кое-что еще, более важное. Это корреляции и зачастую достаточно большая амплитуда и разброс данных. Невозможно одной математической формулой оценить все тонкости внешних и внутренних влияний на молекулы. Даже при наличии нормализации, предсказание, например, дальнейшей терапии для группы пациентов, очень затруднено. Что уже тут говорить о батч-эффекте. Качественные искусственные нейросети помогают снизить риски и предотвратить последствия, если у ученого была выстроена неправильная логическая цепочка и выдвинута неправильная гипотеза.
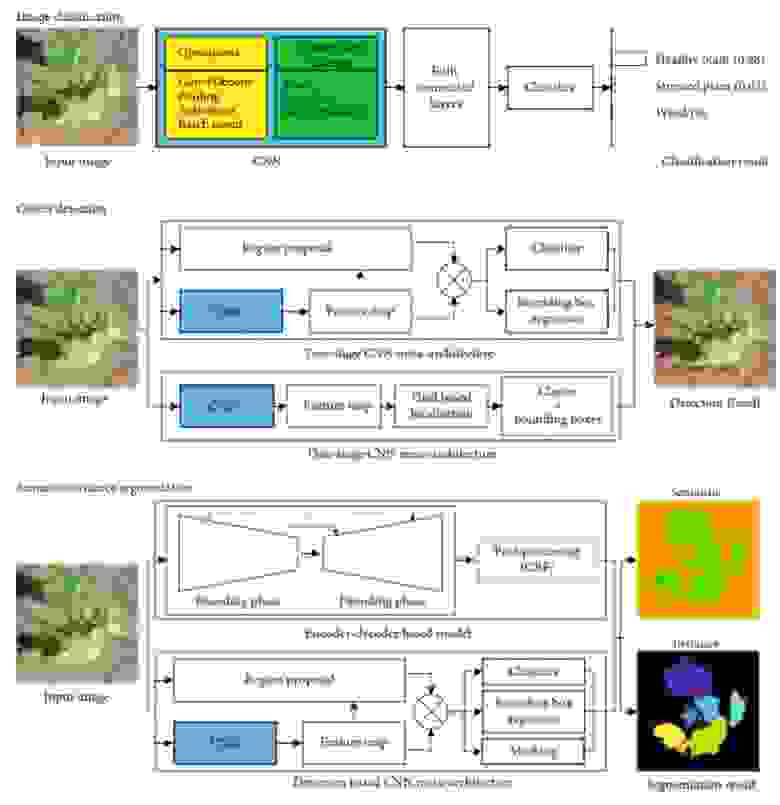
Схема классификации болезней растений по фотографиям
Ещё одним из важных преимуществ использования искусственных нейросетей, да и в принципе компьютерных методов анализа является скорость выполнения. Производительность современных компьютеров позволяет выполнять анализ во много раз быстрее человека, причем не только с сохранением изначального уровня точности, но с его увеличением. Искусственные нейронные сети успешно справляются с самыми разными задачами. Например, получены результаты, показывающие эффективность применения нейронных сетей для классификации болезней растений. В исследовании на рисунке выше были классифицированы 38 категорий болезней по фотографиям. Более того, есть возможность не только определять болезнь или состояние объекта, но и его вид (вспомним Flora incognita).
Как итог, хотелось бы еще раз повторить, что без помощи таких дисциплин, как машинное обучение, вычислительная биология, биоинформатика, невозможно было бы то развитие, которое мы имеем в прикладной науке сейчас. Никогда не стоит забывать, какое сильное влияние оказывает человеческий фактор. Мы живем в удивительное время, когда автоматизированные системы способны справляться с привычной для человека работой, причем в некоторых случаях в разы превосходя его в этом. Поскольку эта тенденция не обошла стороной научное сообщество, у нас появляется возможность не только увеличить объем получаемых данных, но и вывести их анализ на принципиально новый, глубокий уровень.
