Использование машинного обучения в статическом анализе исходного кода программ
Машинное обучение плотно укоренилось в различных сферах деятельности людей: от распознавания речи до медицинской диагностики. Популярность этого подхода столь велика, что его пытаются использовать везде, где только можно. Некоторые попытки заменить классические подходы нейросетями оканчиваются не столь уж успешно. Давайте взглянем на машинное обучение с точки зрения задач создания эффективных статических анализаторов кода для поиска ошибок и потенциальных уязвимостей.
Команду PVS-Studio часто спрашивают, не хотим ли мы начать использовать машинное обучение для нахождения ошибок в исходном коде программ. Короткий ответ: да, но очень ограничено. Мы считаем, с применением машинного обучения в задачах анализа кода скрывается много подводных камней. Во второй части статьи мы расскажем про них. А начнём с обзора новых решений и идей.
Новые подходы
В настоящее время существует уже множество реализаций статических анализаторов, основанных на или использующих машинное обучение, в том числе — глубокое обучение и NLP для обнаружения ошибок. На потенциал машинного обучения при поиске ошибок обратили внимание не только энтузиасты, но и крупные компании, например, Facebook, Amazon или Mozilla. Некоторые проекты не являются полноценными статическими анализаторами, а лишь промежуточно находят некоторые определенные ошибки при коммитах.
Интересно, что почти все позиционируются как game-changer продукты, которые с помощью искусственного интеллекта изменят процесс разработки.

Рассмотрим некоторые известные примеры:
- DeepCode
- Infer, Sapienz, SapFix
- Embold
- Source{d}
- Clever-Commit, Commit Assistant
- CodeGuru
DeepCode
Deep Code — инструмент поиска уязвимостей в коде программ, написанных на Java, JavaScript, TypeScript и Python, в котором машинное обучение присутствует в качестве компонента. По заявлению Бориса Паскалева, уже работает более 250 тысяч правил. Этот инструмент обучается на основе изменений, вносимых разработчиками в исходный код открытых проектов (миллион репозиториев). Сама компания говорит, что их проект — это Grammarly для разработчиков.

По сути этот анализатор сравнивает ваше решение со своей базой проектов и предлагает вам предполагаемое наилучшее решение из опыта других разработчиков.
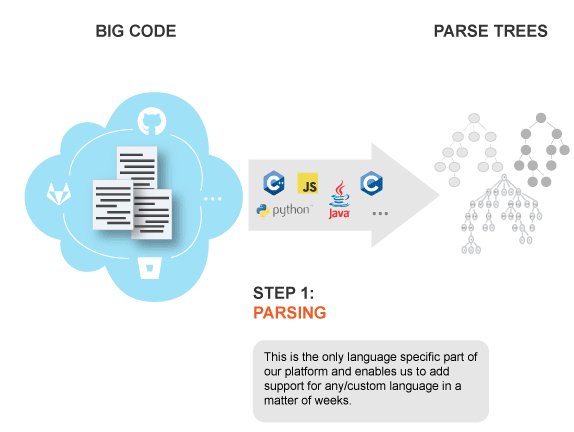
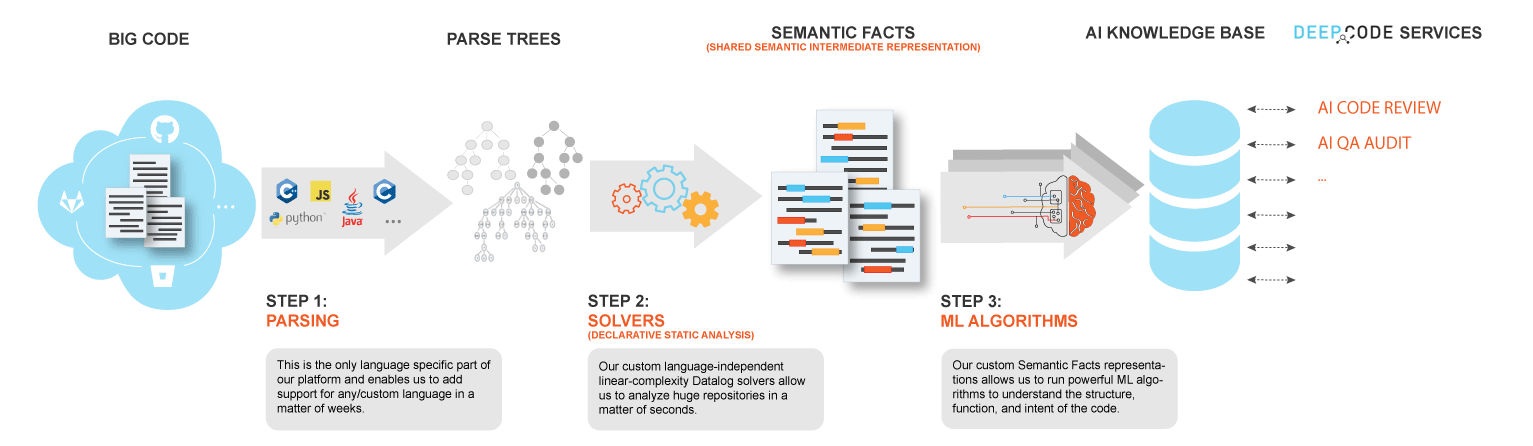
В мае 2018 года разработчики писали, что готовится поддержка языка C++, однако до сих пор этот язык не поддерживается. Хотя на самом сайте и указано, что добавление нового языка можно произвести за считанные недели, благодаря тому, что от языка зависим лишь один этап — парсинг.
Также на сайте опубликована группа публикаций о методах, на которых основан анализатор.
Infer
Фейсбук достаточно широко старается внедрить новые подходы в своих продуктах. Не обошли они своим вниманием и машинное обучение. В 2013 году они купили стартап, который разрабатывал статический анализатор, основанный на машинном обучении. А в 2015 году исходный код проекта стал открытым.
Infer — статический анализатор для проектов, написанных на языках Java, C, C++, и Objective-C, разрабатываемый Фейсбуком. Согласно сайту, он также используется в Amazon Web Services, Oculus, Uber и других популярных проектах.
В настоящее время Infer способен находить ошибки, связанные с разыменовыванием нулевого указателя, утечками памяти. Infer основан на логике Хоара, separation logic и bi-abduction, а также на теории абстрактной интерпретации (abstract interpretation). Использование этих подходов позволяет анализатору разбивать программу на малые блоки (chunks) и анализировать их независимо друг от друга.
Вы можете попробовать использовать Infer и на своих проектах, однако разработчики предупреждают, что, хотя на проектах Facebook полезные срабатывания составляют 80% результатов, на других проектах низкое число ложных срабатываний не гарантируется. Некоторые из ошибок, которые Infer пока что не может находить, но разработчики работают над введением таких срабатываний:
- выход за пределы массива;
- исключения приведения типов;
- утечки непроверенных данных;
- состояние гонки потоков.
SapFix
SapFix является автоматизированным инструментом внесения правок. Он получает информацию от Sapienz, инструмента для автоматизации тестирования, и статического анализатора Infer, и на основании последних внесенных изменений и сообщениях Infer выбирает одну из нескольких стратегий для исправления ошибок.
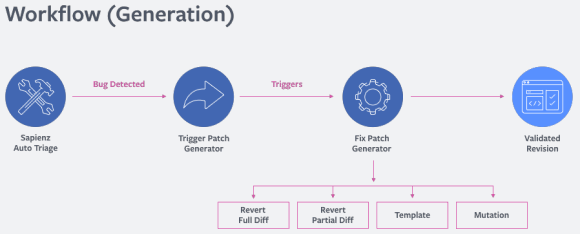
В части случаев SapFix откатывает все изменения или их часть. В других случаях он пытается разрешить проблему, генерируя патч из своего набора шаблонов фиксов. Этот набор формируется из шаблонов правок, собранных самими программистами из набора уже произведенных когда-то правок. Если такой шаблон не исправит ошибку, SapFix пытается подстроить шаблон под ситуацию, производя малые модификации в абстрактном синтаксическом дереве, пока потенциальное решение не будет найдено.
Но одного потенциального решения недостаточно, поэтому SapFix собирает несколько решений, которые отбираются на основе трех вопросов: есть ли ошибки компиляции, остается ли падение, не вносит ли правка новых падений. После того, как правки будут полностью протестированы, патчи отправляются на ревью программисту, который примет решение, какая из правок наилучшим образом разрешает проблему.
Embold
Embold — стартап-платформа для статического анализа исходного кода программ, которая до переименования носила имя Gamma. Статический анализ производится на основе собственных диагностик, а также на базе встроенных анализаторов, таких как Cppсheck, SpotBugs, SQL Check и других.
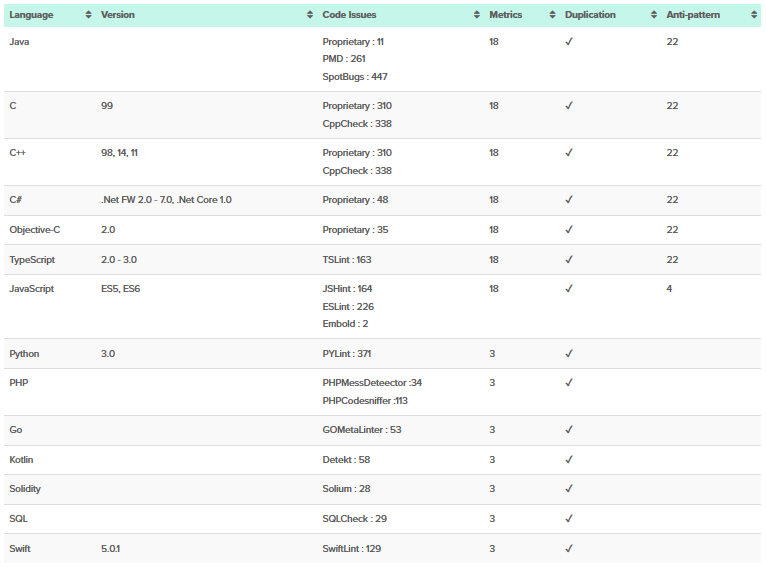
Кроме самих диагностик акцент делается на возможности наглядного отображения инфографики по нагруженности кодовой базы и удобного просмотра найденных ошибок, а также поиска возможности рефакторинга. Кроме того, в этом анализаторе есть набор анти-паттернов, который позволяет обнаруживать проблемы в структуре кода на уровне классов и методов, и различные метрики для расчета качества системы.

Одним из основных преимуществ заявляется интеллектуальная система предложения решений и правок, которая, в дополнение к обычным диагностикам, проверяет правки на основе информации о предыдущих изменениях.

С помощью NLP Embold разбивает код на части и ищет между ними взаимосвязи и зависимости между функциями и методами, что позволяет сэкономить время рефакторинга.
Таким образом, Embold в основном предлагает удобную визуализацию результатов анализа вашего исходного кода различными анализаторами, а также собственными диагностиками, часть которых основана на машинном обучении.
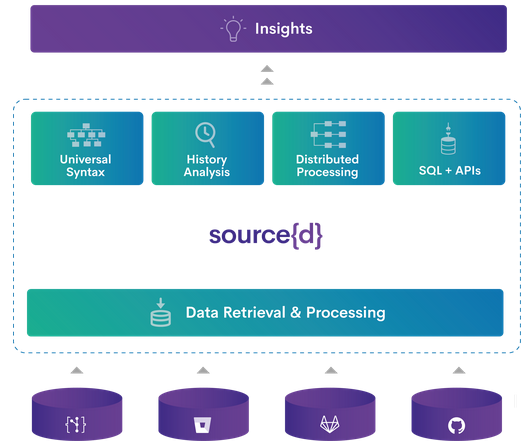
Source{d}
Source{d} является наиболее открытым в плане способов своей реализации из рассмотренных нами анализаторов. Также он является решением с открытым исходным кодом. На их сайте можно (в обмен на адрес своей почты) заполучить буклетик с описанием используемых ими технологий. Кроме того, в нём есть ссылка на собранную ими базу публикаций, связанную с использованием машинного обучения для анализа кода, а также репозиторий с датасетом для обучения на коде. Сам продукт представляет собой целую платформу анализа исходного кода и программного продукта, и ориентируется, скорее, не на разработчиков, а на звено менеджеров. Среди его возможностей присутствует функционал для выявления объема технического долга, бутылочных горлышек в процессе разработки и другой глобальной статистики по проекту.
Свой подход к анализу кода с помощью машинного обучения они основывают на Natural Hypothesis, сформулированной в статье «On the Naturalness of Software».
«Языки программирования, в теории, являются сложными гибкими и мощными, но программы, которые на самом деле пишут реальные люди, в большинстве своем простые и достаточно повторяющиеся, и, следовательно, в них присутствуют полезные и предсказуемые статистические свойства, которые можно выразить в статистических языковых моделях и использовать для задач разработки программного обеспечения.»
Исходя из этой гипотезы, чем больше кодовая база для обучения анализатора, тем сильнее выделяются статистические свойства и тем точнее будут достигнутые через обучение метрики.
Для анализа кода в source{d} используется сервис Babelfish, который может распарсить файл с кодом на любом из доступных языков, получить абстрактное синтаксическое дерево и преобразовать его в универсальное синтаксическое дерево.
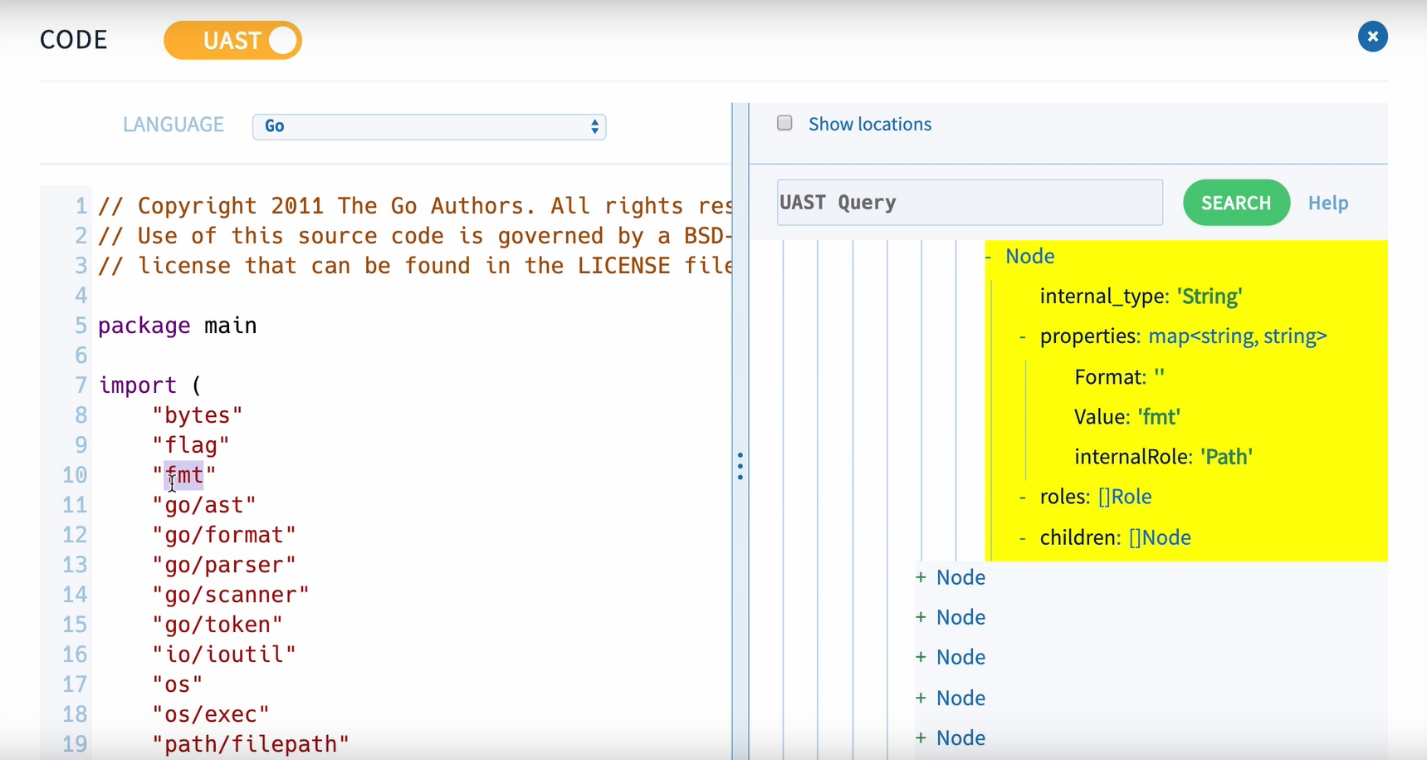
Однако source{d} не занимается поиском ошибок в коде. На основе дерева с помощью машинного обучения на базе всего проекта, source{d} выявляет то, как код отформатирован, какой стиль кодирования применяется в проекте и при коммите, а если новый код не соответствует код-стайлу проекта — вносит соответствующие правки.


Обучение ориентируется на несколько основных элементов: пробелы, табуляция, переносы строки и т.д.

Подробнее можно почитать об этом в их публикации: «STYLE-ANALYZER: fixing code style inconsistencies with interpretable unsupervised algorithms».
В целом, source{d} представляет собой широкую платформу для сбора самой разнообразной статистики по исходному коду и процессу разработки проекта, от расчета эффективности разработчиков до выявления временных затрат на код-ревью.
Clever-Commit
Clever-Commit — анализатор, созданный Mozilla в сотрудничестве с Ubisoft. Он основан на исследовании CLEVER (Combining Levels of Bug Prevention and Resolution Techniques), проведенном Ubisoft, и основанном на нем продукте Commit Assistant, который выявляет подозрительные коммиты, скорее всего содержащие ошибку. Благодаря тому, что CLEVER основан на сравнении кода, он не только указывает на опасный код, но и делает предложения о возможных правках. Согласно описанию, в 60–70% случаев Clever-Commit находит проблемные места и с той же частотой предлагает для них верные правки. В целом, информации об этом проекте и об ошибках, которые он способен находить, немного.
CodeGuru
А ещё совсем недавно список анализаторов, использующих машинное обучение, пополнился продуктом от Amazon под названием CodeGuru. Это сервис, основанный на машинном обучении, который позволяет находить ошибки в коде, а также выявлять в нем затратные участки. Пока что анализ есть только для Java кода, но пишут о поддержке и других языков в будущем. Хотя он и был анонсирован совсем недавно, СЕО AWS (Amazon Web Services) Энди Джасси говорит, что он уже долгое время используется в самом Амазоне.
На сайте сказано, что обучение проводилось на кодовой базе самого Амазона, а также на более чем 10 000 проектах с открытым исходным кодом.
По сути сервис разделен на две части: CodeGuru Reviewer, обученный с помощью поиска ассоциативных правил и ищущий ошибки в коде, и CodeGuru Profiler, занимающийся мониторингом производительности приложений.
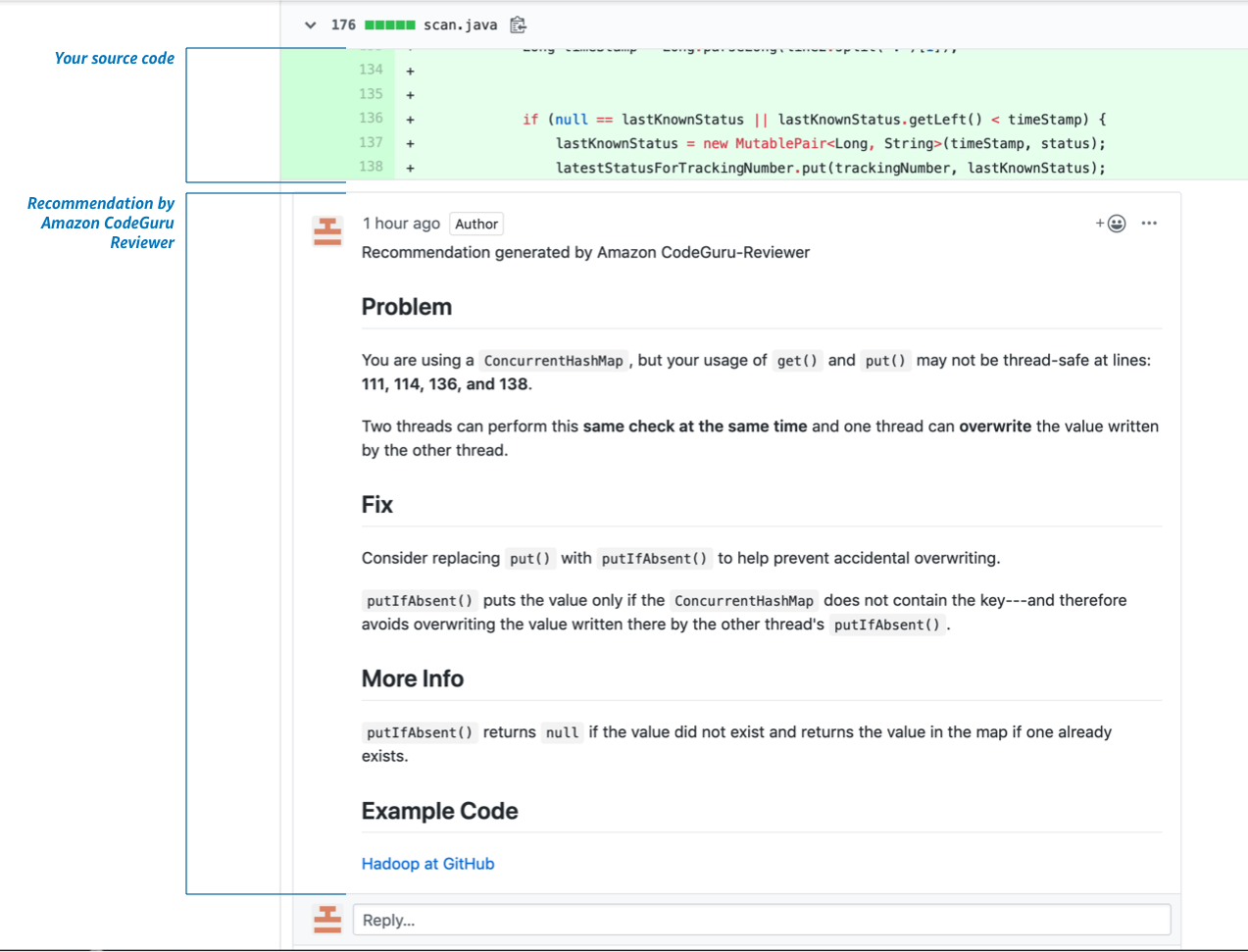
В целом, информации об этом проекте опубликовано не так уж и много. На сайте сказано, что чтобы обучиться ловить отклонения от «лучших практик», Reviewer анализирует кодовые базы Амазона и ищет в них пулл-реквесты, содержащие вызовы API AWS. Далее он просматривает внесенные изменения и сравнивает их с данными из документации, которая анализируется параллельно. В результате получается модель «лучших практик».
Также сказано, что рекомендации для пользовательского кода улучшаются после получения фидбэка по рекомендациям.
Список ошибок, на которые реагирует Reviewer, достаточно размыт, так как конкретной документации по ошибкам не опубликовано:
- «Лучшие практики» AWS
- Параллелизм
- Утечки ресурсов
- Утечка конфиденциальной информации
- Общие «лучшие практики» кодирования
Наш скептицизм
Теперь давайте посмотрим на задачу поиска ошибок глазами нашей команды, которая занимается разработкой статических анализаторов много лет. Мы видим ряд высокоуровневых проблем применения обучения, о которых и хотим рассказать. Но в начале грубо разделим все ML подходы на два типа:
- Вручную обучить статический анализатор искать различные проблемы, используя синтетические и реальные примеры кода;
- Обучить алгоритмы на большом количестве открытого исходного кода (GitHub) и истории изменений, после чего анализатор сам начнёт выявлять ошибки и даже предлагать правки.
О каждом направлении мы поговорим отдельно, так как им будут присущи различные недостатки. После чего, думаю, читателям станет понятно, почему мы не отрицаем возможности машинного обучения, но и не разделяем энтузиазм.
Примечание. Мы смотрим с позиции разработки универсального статического анализатора общего назначения. Мы нацелены на разработку анализатора, ориентированного не на конкретную кодовую базу, а который может использовать любая команда в любом проекте.
Обучение статического анализатора «вручную»
Допустим, мы хотим использовать ML для того, чтобы анализатор начал искать в коде аномалии следующего вида:
if (A == A)
Странно сравнивать переменную саму с собой. Мы можем написать множество примеров корректного и некорректного кода и обучить анализатор искать такие ошибки. Дополнительно, можно добавить в тесты реальные примеры уже найденных ошибок. Вопрос, конечно, где эти примеры взять. Но будем считать, что это возможно. Например, у нас накопилось некоторое количество примеров таких ошибок: V501, V3001, V6001.
Итак, можно ли искать такие дефекты в коде, используя алгоритмы машинного обучения? Можно. Только непонятно, зачем это делать!
Смотрите, чтобы обучить анализатор нам потребуется потратить много сил на подготовку примеров для обучения. Или размечать код реальных приложений, указывая, где надо ругаться, а где нет. В любом случае потребуется проделать очень большую работу, так как примеров для обучения должны быть тысячи. Или десятки тысяч.
Ведь мы хотим искать не только случаи (A == A), но и:
- if (X && A == A)
- if (A + 1 == A + 1)
- if (A[i] == A[i])
- if ((A) == (A))
- и так далее.

А теперь давайте посмотрим, как была бы реализована такая простейшая диагностика в PVS-Studio:
void RulePrototype_V501(VivaWalker &walker,
const Ptree *left, const Ptree *right, const Ptree *operation)
{
if (SafeEq(operation, "==") && SafeEqual(left, right))
{
walker.AddError("Ой беда, беда!", left, 501, Level_1, "CWE-571");
}
}
И всё. Не нужно никакой базы примеров для обучения!
В дальнейшем диагностику следует научить учитывать ряд исключений и понимать, что надо ругаться на (A[0] == A[1–1]). Однако всё это очень легко программируется. А вот как раз с базой примеров для обучения всё будет обстоять плохо.
Отметим, что в обоих случаях ещё потребуется система тестов, написание документации и так далее. Однако трудозатраты по созданию новой диагностики явно на стороне классического подхода, где правило просто жёстко программируется в коде.
Давайте рассмотрим теперь какое-то другое правило. Например, что результат некоторых функций обязательно должен использоваться. Нет смысла их вызывать и при этом не использовать их результат. Вот некоторые такие функции:
- malloc
- memcmp
- string: empty
В общем, это то, что делает реализованная в PVS-Studio диагностика V530.
Итак, мы хотим искать вызовы таких функций, где результат их работы не используется. Для этого можно сгенерировать множество тестов. И думаем, всё будет хорошо работать. Вот только опять непонятно, зачем это нужно.
Реализация диагностики V530 со всеми исключениями в анализаторе PVS-Studio составляет 258 строк кода, из которых 64 строки являются комментариями. Плюс есть таблица с аннотациями функций, где отмечено, что их результат должен использоваться. Пополнять эту таблицу намного проще, чем создавать синтетические примеры.
Ещё хуже дело будет обстоять с диагностиками, в которых используется анализ потока данных. Например, анализатор PVS-Studio умеет отслеживать значение указателей, что позволяет найти вот такую утечку памяти:
uint32_t* BnNew() {
uint32_t* result = new uint32_t[kBigIntSize];
memset(result, 0, kBigIntSize * sizeof(uint32_t));
return result;
}
std::string AndroidRSAPublicKey(crypto::RSAPrivateKey* key) {
....
uint32_t* n = BnNew();
....
RSAPublicKey pkey;
pkey.len = kRSANumWords;
pkey.exponent = 65537; // Fixed public exponent
pkey.n0inv = 0 - ModInverse(n0, 0x100000000LL);
if (pkey.n0inv == 0)
return kDummyRSAPublicKey; // <=
....
}
Пример взят из статьи «Chromium: утечки памяти». Если выполнится условие (pkey.n0inv == 0), то происходит выход из функции без освобождения буфера, указатель на который хранится в переменной n.
С точки зрения PVS-Studio здесь нет ничего сложного. Анализатор изучил функцию BnNew и запомнил, что она возвращает указатель на блок выделенной памяти. В другой функции он заметил, что возможна ситуация, когда буфер не освобождается, а указатель на него теряется в момент выхода из функции.
Работает общий алгоритм отслеживания значений. Не важно, как написан код. Не важно, что ещё есть в функции, не относящееся к работе с указателями. Алгоритм универсален и диагностика V773 находит массу ошибок в различных проектах. Посмотрите сколь различны фрагменты кода, где выявлены ошибки!
Мы не являемся знатоками машинного обучения, но, кажется, здесь будут большие проблемы. Есть невероятное количество способов, как можно написать код с утечками памяти. Даже если машина будет обучена отслеживать значение переменных, потребуется обучить её понимать, что бывают вызовы функций.
Есть подозрение, что потребуется столь большое количество примеров для обучения, что задача становится грандиозной. Мы не говорим, что она нереализуема. Мы сомневаемся, что затраты на создание анализатора окупят себя.
Аналогия. На ум приходит аналогия с калькулятором, где вместо диагностик надо программировать арифметические действия. Уверены, можно научить калькулятор на базе ML хорошо складывать числа, введя в него базу знаний про результат операций 1+1=2, 1+2=3, 2+1=3, 100+200=300 и так далее. Как вы понимаете, целесообразность разработки такого калькулятора под большим вопросом (если под это не выделен грант :). Намного более простой, быстрый, точный и надёжный калькулятор можно написать, используя в коде обыкновенную операцию »+».
Вывод. Способ будет работать. Но использовать его, на наш взгляд, не имеет практического смысла. Разработка будет более трудоёмкой, а результат менее надёжен и точен, особенно если речь пойдёт о реализации сложных диагностик, основанных на анализе потока данных.
Обучение на большом количестве открытого исходного кода
Хорошо, с ручными синтетическими примерами мы разобрались, но ведь есть GitHub. Можно отследить историю коммитов и вывести закономерности изменения/исправления кода. Тогда можно указать не только на участки подозрительного кода, но даже, возможно, предложить способ его исправления.
Если остановиться на этом уровне детализации, то всё выглядит хорошо. Дьявол же, как всегда, кроется в деталях. Давайте как раз и поговорим про эти детали.
Первый нюанс. Источник данных.
Правки на GitHub достаточно хаотичны и разнообразны. Люди часто ленятся делать атомарные коммиты и вносят в код одновременно сразу несколько правок. Сами знаете, как это бывает: поправили ошибку, а заодно и порефакторили немножко («А вот тут ещё заодно добавлю обработку такого случая…»). Даже человеку потом может быть непонятно, связаны эти правки между собой, или нет.
Встаёт задача, как отличить собственно ошибки от добавления новой функциональности или чего-то ещё. Можно, конечно, посадить 1000 человек вручную размечать коммиты. Люди должны будут указать, что вот здесь ошибку поправили, здесь рефакторинг, здесь новая функциональность, здесь требования поменялись и так далее.
Возможна такая разметка? Возможна. Но обратите внимание, как быстро происходит подмена. Вместо «алгоритм научится сам на базе GitHub» мы уже обсуждаем как озадачить сотни человек на продолжительное время. Трудозатраты и стоимость создания инструмента резко возрастают.
Можно попытаться выявить автоматически, где именно исправлялись ошибки. Для этого следует анализировать комментарии к коммитам, обращать внимание на небольшие локальные правки, которые, скорее всего, являются именно правкой ошибки. Затрудняюсь сказать, насколько хорошо можно автоматически искать правки ошибок. В любом случае, это большая задача, требующая отдельного исследования и программирования.
Итак, мы ещё не добрались до обучения, а уже есть нюансы :).
Второй нюанс. Отставание в развитии.
Анализаторы, которые будут обучаться на основании таких баз, как GitHub, всегда будут подвержены такому синдрому, как «задержка психического развития». Это связано с тем, что языки программирования изменяются со временем.
В C# 8.0 появились Nullable Reference типы, помогающие бороться с Null Reference Exception’ами (NRE). В JDK 12 появился новый оператор switch (JEP 325). В C++17 появилась возможность выполнять условные конструкции на этапе компиляции (constexpr if). И так далее.
Языки программирования развиваются. Причем такие, как C++, очень быстро и активно. В них появляются новые конструкции, добавляются новые стандартные функции и так далее. Вместе с новыми возможностями появляются и новые паттерны ошибок, которые тоже хотелось бы выявлять с помощью статического анализа кода.
И здесь у рассматриваемого метода обучения проблема: паттерн ошибки может быть уже известен, есть желание его выявлять, но учить ещё не на чем.
Давайте рассмотрим эту проблему на каком-то конкретном примере. В C++11 появился Range-based for loop. И можно написать следующий код, перебирающий все элементы в контейнере:
std::vector numbers;
....
for (int num : numbers)
foo(num);
Новый цикл принёс с собой и новый паттерн ошибки. Если внутри цикла изменить контейнер, то это приведёт к инвалидации «теневых» итераторов.
Рассмотрим следующий некорректный код:
for (int num : numbers)
{
numbers.push_back(num * 2);
}
Компилятор превратит его в нечто подобное:
for (auto __begin = begin(numbers), __end = end(numbers);
__begin != __end; ++__begin) {
int num = *__begin;
numbers.push_back(num * 2);
}
При операции push_back может произойти инвалидация итераторов __begin и __end, если произойдёт реаллокация памяти внутри вектора. Результатом будет неопределённое поведение программы.
Итак, паттерн ошибки давно известен и описан в литературе. Анализатор PVS-Studio диагностирует его с помощью диагностики V789 и уже находил реальные ошибки в открытых проектах.
Как скоро на GitHub наберётся достаточно нового кода, чтобы заметить такую закономерность? Хороший вопрос… Надо понимать, что если появился range-based for loop, это не означает, что все программисты сразу начали его массово использовать. Могут пройти годы, прежде чем появится много кода, использующего новый цикл. Более того, должно быть совершено множество ошибок, а потом они должны быть поправлены, чтобы алгоритм смог заметить закономерность в правках.
Сколько должно пройти лет? Пять? Десять?
Десять — это слишком много, и мы пессимисты? Отнюдь. К моменту написания статьи прошло уже восемь лет, как в C++11 появился range-based for loop. Но пока в нашей базе выписано только три случая такой ошибки. Три ошибки — это не много и не мало. Из их количества не следует делать какой-то вывод. Главное, можно подтвердить, что такой паттерн ошибки реален и есть смысл его обнаруживать.
Теперь сравним это количество, например, вот с этим паттерном ошибки: указатель разыменовывается до проверки. Всего при проверке open-source проектов мы уже выявили 1716 подобных случаев.
Возможно, вообще не стоит искать ошибки range-based for loop? Нет. Просто программисты инерционны, и этот оператор очень неспеша приобретает популярность. Постепенно кода с его участием станет много, и ошибок, соответственно, тоже станет больше.
Произойдёт это, по всей видимости, лишь спустя 10–15 лет с момента появления C++11. И теперь философский вопрос. Уже зная паттерн ошибки, мы будем просто ждать многие годы, пока накопится много ошибок в открытых проектах?
Если ответ — «да», то тогда можно заранее обоснованно поставить всем анализаторам на базе ML диагноз «задержка психического развития».
Если ответ — «нет», то как быть? Примеров нет. Писать их вручную? Но тогда мы возвращается к предыдущей главе, где мы рассматривали написание человеком множества примеров для обучения.
Такое можно сделать, но вновь встаёт вопрос целесообразности. Реализация диагностики V789 со всеми исключениями в анализаторе PVS-Studio составляет всего 118 строк кода, из которых 13 строк являются комментариями. Т.е. это очень простая диагностика, которую можно легко взять и запрограммировать классическим способом.
Аналогичная ситуация будет с любыми другими нововведениями, появляющимися в любых других языках. Как говорится, есть над чем подумать.
Третий нюанс. Документация.
Важной составляющей любого статического анализатора является документация, описывающая каждую диагностику. Без неё использовать анализатор будет крайне сложно или вообще невозможно. В документации к PVS-Studio у нас есть описание каждой диагностики, где приводится пример ошибочного кода и как его исправить. Также приводится ссылка на CWE, где можно прочитать альтернативное описание проблемы. И всё равно, иногда пользователям бывает что-то непонятно, и они задают нам уточняющие вопросы.
В случае статических анализаторов, которые строятся на алгоритмах машинного обучения, вопрос документации как-то замалчивается. Предполагается, что анализатор просто укажет на место, которое кажется ему подозрительным и, возможно, даже предложит как его исправить. Решение вносить правку или нет остаётся за человеком. И во тут… кхм… Непросто принять решение, не имея возможности прочитать, на основании чего анализатору кажется подозрительным то или иное место в коде.
Конечно, в ряде случаев всё будет очевидно. Предположим, анализатор укажет вот на этот код:
char *p = (char *)malloc(strlen(src + 1));
strcpy(p, src);
И предложит заменить его на:
char *p = (char *)malloc(strlen(src) + 1);
strcpy(p, src);
Сразу понятно, что программист опечатался и прибавил 1 не туда, куда надо. В результате чего памяти будет выделено меньше необходимого.
Тут и без документации всё понятно. Однако так будет далеко не всегда.
Представьте, что анализатор «молча» указывает на этот код:
char check(const uint8 *hash_stage2) {
....
return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE);
}
И предлагает изменить тип возвращаемого значения с сhar на int:
int check(const uint8 *hash_stage2) {
....
return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE);
}
Документации для предупреждения нет. Да и видимо самого текста у предупреждения, как мы понимаем, тоже не будет, если мы говорим про полностью самостоятельный анализатор.
Что делать? В чём разница? Стоит ли делать такую замену?
В принципе, здесь можно будет рискнуть и согласиться исправить код. Хотя соглашаться на правки без их понимания, это так себе практика… :) Можно заглянуть в описание функции memcmp и прочитать, что функция действительно возвращает значения типа int: 0, больше нуля и меньше нуля. Но всё равно может быть непонятно, зачем вносить правки, если код сейчас и без того успешно работает.
Теперь, если вы не знаете, в чём смысл такой правки, ознакомьтесь с описанием диагностики V642. Сразу становится понятным, что это самая настоящая ошибка. Более того, она может стать причиной уязвимости.
Возможно, пример показался неубедительным. Ведь анализатор предложил код, который, скорее всего, будет лучше. Ok. Давайте рассмотрим другой пример псевдокода, на этот раз, для разнообразия, на языке Java.
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
obj.state = 200;
out.writeObject(obj);
out.close();
Есть какой-то объект. Он сериализуется. Затем состояние объекта меняется, и он вновь сериализуется. Вроде всё хорошо. Теперь представим, что анализатору, вдруг, этот код не нравится, и он предлагает заменить его на:
ObjectOutputStream out = new ObjectOutputStream(....);
SerializedObject obj = new SerializedObject();
obj.state = 100;
out.writeObject(obj);
obj = new SerializedObject(); // Добавилась эта строка
obj.state = 200;
out.writeObject(obj);
out.close();
Вместо изменения объекта и его повторной записи, создаётся новый объект и уже он сериалиузется.
Описания проблемы нет. Документации нет. Код стал длиннее. Зачем-то добавлено создание нового объекта. Вы готовы сделать в своём коде такую правку?
Вы скажете, что непонятно. Действительно, непонятно. И так будет непонятно постоянно. Работа с таким «молчаливым» анализатором станет бесконечным исследованием в попытке понять, почему анализатору что-то не нравится.
Если же есть документация, то всё становится прозрачно. Класс java.io.ObjectOuputStream, который используется для сериализации, кэширует записываемые объекты. Это означает, что один и тот же объект не будет сериализован дважды. Один раз класс сериализует объект, а во второй раз просто запишет в поток ссылку на тот же самый первый объект. Подробнее: V6076 — Recurrent serialization will use cached object state from first serialization.
Надеемся, нам удалось объяснить важность наличия документации. А теперь вопрос. Как появится документация для анализатора, построенного на базе ML?
Когда разрабатывается классический анализатор кода, то здесь всё просто и понятно. Есть некий паттерн ошибок. Мы его описываем в документации и реализуем диагностику.
В случае ML всё наоборот. Да, анализатор может заметить аномалию в коде и указать на неё. Но он ничего не знает о сути дефекта. Он не понимает и не расскажет, почему же так нельзя писать код. Это слишком высокоуровневые абстракции. Тогда уж анализатору надо заодно научиться читать и понимать документацию для функций.
Как я уже сказал, поскольку тема документации обходится в статьях по машинному обучению, мы не готовы рассуждать дальше. Просто ещё один большой нюанс, который мы вынесли на обозрение.
Примечание. Можно возразить, что документация не обязательна. Анализатор может привести отсылки к множеству примеров исправления на GitHub и человек, просматривая коммиты и комментарии к ним, разберётся что к чему. Да, это так. Но идея не выглядит привлекательной. Анализатор по-прежнему вместо помощника выступает в качестве инструмента, который ещё больше будет озадачивать программиста.
Четвёртый нюанс. Узкоспециализированные языки.
Описываемый подход не применим для узкоспециализированных языков, для которых статический анализ также может быть крайне полезен. Причина в том, что на GitHub и других источниках просто не наберётся достаточно большой базы исходных кодов, чтобы проводить эффективное обучение.
Рассмотрим это на конкретном примере. Для начала зайдём на GitHub и выполним поиск репозиториев для популярного языка Java.
Результат: language: «Java»: 3,128,884 available repository results
Теперь возьмём специализированный язык »1C Enterprise», используемый в бухгалтерских приложениях, выпускаемых российской компанией 1C.
Результат: language:»1C Enterprise»: 551 available repository results
Быть может анализаторы для этого языка не нужны? Нужны. Имеется практическая потребность в анализе таких программ и уже существуют соответствующие анализаторы. Например, существует SonarQube 1C (BSL) Plugin, выпускаемый компанией «Серебряная Пуля».
Думаю, каких-то специальных пояснений не требуется, почему подход с машинным обучением будет затруднителен для специализированных языков.
Пятый нюанс. C, C++, #include.
Статьи, посвящённые исследованиям в области статического анализа кода на базе ML, тяготеют к таким языкам, как Java, JavaScript, Python. Объясняют это их крайней популярностью. А вот языки C и C++ как-то обходят стороной, хотя их точно нельзя назвать непопулярными.
У нас есть гипотеза, что дело не в популярности/перспективности, а в том, что с языками C и C++ есть проблемы. И сейчас мы «вытащим» одну неудобную проблему на обозрение.
Абстрактный c/cpp-файл бывает очень непросто скомпилировать. По крайней мере, не получится выкачать проект с GitHub, выбрать какой-то cpp-файл и просто его скомпилировать. Сейчас мы поясним, какое отношение всё это имеет к ML.
Итак, мы хотим обучать анализатор. Мы скачали с GitHub проект. Мы знаем патч и предполагаем, что он исправляет ошибку. Мы хотим, чтобы эта правка стала одним из примеров для обучения. Другим словами, у нас есть .cpp-файл до правки и после правки.
Вот здесь и начинается проблема. Недостаточно просто изучить исправления. Необходимо иметь полный контекст. Необходимо знать описание используемых классов, необходимо знать прототипы используемых функций, нужно знать как раскрываются макросы и так далее. А для этого нужно выполнить полноценное препроцессирование файла.
Рассмотрим пример. Вначале код выглядел так:
bool Class::IsMagicWord()
{
return m_name == "ML";
}
Его исправили так:
bool Class::IsMagicWord()
{
return strcmp(m_name, "ML") == 0;
}
Следует ли на основании этого случая начинать учиться, чтобы в дальнейшем пр
