Использование FPGA и языка DSL для ускорения HFT-торговли

Исследователи из немецкого Гейдельбергского университета опубликовали рассказ об использовании предметно-ориентированного языка DSL и FPGA для создания скоростной торговой системы. Мы представляем вашему вниманию главные мысли этой работы.
На современных финансовых рынках значительно число всех операций приходится на автоматизированные торговые системы — уже в 2010 году более половины всех сделок на американских биржах совершались с помощью алгоритмов. Среди них есть такие, которые показывают положительные финансовые результаты в том случае, если целевые действия совершаются быстрее других трейдеров — тогда системе удается заработать, если же аналогичный алгоритм опередит ее, то получить прибыль не удастся. Такая торговля получила название высокочастотной (High Frequency Trading, HFT).
Для передачи финансовой информации о котировках акций и текущих заявках на покупку и продажу используются специальные протоколы передачи финансовых данных (о них мы писали цикл статей). Часто для этих целей используются международные протоколы FIX и FAST. Соответственно, для повышения производительности HFT-системы разработчику необходимо оптимизировать процесс декодирования рыночных данных FAST, а также протоколов нижнего уровня.
Для решения этой задачи часто используются специальные ускорители (accelerators), которые позволяют передавать задачи по обработки Ethernet, UDP и IP-информации от софта железу — это приводит к серьезному повышению продуктивности. В этом материале будет рассмотрен процесс создания такого движка-ускорителя с помощью предметно-ориентированного языка DSL (Domain-specific language).
Инфраструктура трейдинга
Как правило, в процессе онлайн-трейдинга задействованы три главные сущности — это непосредственно биржа, инструменты для обработки потоков данных с нее и участники рынка, то есть трейдеры. Биржа получает приказы на покупку или продажу через так называемые шлюзовые серверы. Затем торговый движок биржи пытается «свести» покупателей и продавцов. Если сделка успешно состоялась, участники получают оповещение об этом. Если же сделка еще не прошла и приказ находится в очереди, его еще можно отменить.
Обработчики потоков данных получают информацию о текущих ценах акций и очереди заявок на покупку или продажу. Эта информация передается биржей и должна быть транслирована заинтересованным участникам торгов как можно быстрее. Для транспортировки данных часто используется протокол FAST. Представим описанную выше торговую инфраструктуру в виде схемы:
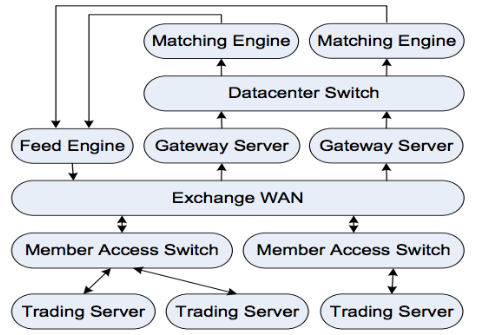
Стек протоколов
В современных реализациях систем для электронной торговли используются протоколы нескольких уровней.TCP/IP, UDP и Ethernet
Базовый коммуникационный протокол, который используют биржи и другие участники рынка. Некритическая информация вроде данных о ценах акций передается по UDP для увеличения скорости, критическая информация о торговых приказах передается по TCP/IP. Соответственно, любая торговая система должна уметь эффективно работать с этими протоколами. В текущей реализации эта задача обработки UDP передана непосредственно железу.FAST
Для передачи больших объёмов финансовых данных без увеличения задержек был разработан протокол FAST. Сообщения FAST состоят из различных полей и операторов. Протокол работает поверх UDP — для снижения задержек несколько сообщений помещаются в один UDP-фрейм. В сообщениях FAST не содержится информации о размере и не устанавливаются параметры разбиения на фреймы. Вместо этого, каждое сообщение определяется шаблоном, которые должен быть известен заранее — только так можно расшифровать поток данных.

UDP-фрейм с несколькими FAST-сообщениями
Каждое сообщение начинается с «карты присутствия» (PMAP) и идентификатора шаблона (TID). PMAP — это маска, которая используется для того, чтобы указать, какое из определенных полей, последовательностей или групп, относится к текущему потоку. TID используется для определения шаблона, который необходим для декодирования сообщения. Шаблоны описываются с помощью XML, как на примере ниже:
Здесь TID равняется 1, шаблон состоит из двух полей и одной группы. Поле может быть строкой, целым числом, со знаком или без, 32, 64-битным или десятичным.
Сжатие данных реализуется с помощью удаления лидирующих нулей внутри каждого слова данных. Для декодирования сжатых данных используются стоп-биты. Для кодирования данных используются первые семь бит каждого байта. Восьмой бит используется в качестве стоп-бита для разделения полей. Для декомпрессии, этот стоп-бит нужно удалить, а оставшиеся 7 бит нужно сдвинуть и осуществить конкатенацию во всех случаях, когда поле больше чем один байт.
Если есть следующий двоичный входящий поток:
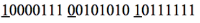
Эти три байта представляют два поля, о чем говорят подчеркнутые стоп-биты. Чтобы узнать реальное значение первого поля, предполагая, что оно является целым числом, достаточно заменить восьмой бит нулем. Результат будет следующим (двоичное и шестнадцатеричное значение):

Второе поле охватывает два байта. Чтобы узнать его реальное значение, для первых семи битов каждого из байтов нужно выполнить конкатенацию и дополнить двумя нулевыми битами. Двоичный и шестнадцатеричный результат будет выглядеть так:
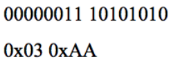
Принятие решений
Одним из важнейших аспектов деятельности алгоритмической торговой системы является принятие решений о совершении финансовых операций. Для того, чтобы решить, покупать или продавать акцию, может требоваться большое количество данных и ресурсов для их обработки. Система может учитывать множество параметров и переменных, которые сравниваются с использованием инструментов математики и статистики.
В этой статье мы не будем подробно рассматривать процесс принятия решения, скажем только, что из-за своей сложности он никогда не выносится напрямую на железо, и остается прерогативой софта.
Базовая реализация
Для создания современных систем онлайн-трейдинга часто используются FPGA. Этому железу передаются задачи по обработке соединений Ethernet, IP, UDP и декодирования протокола FAST. Параллелизм FPGA позволяет добиться серьезного прироста в скорости работы в сравнении с исключительно программными инструментами. Архитектура описываемой в данной работе ситемы выглядит так:
IP, UDP и ETH декодирования на железе
Для снижения задержек при обработке рыночных данных, работа со стеком IP, UDP и Ethernet вынесена полностью на железо. В данном случае используется FPGA Xilinx Virtex-6, которая обладает высокоскоростными серийными трансиверами, кроторые могут рабоать в качестве PHY для прямого доступа к сетевому коммутатору 10Gbit Ethernet.
Работа с Ethernet MAC и протоколами других уровней осуществляется внутренними модулями. Все элементы реализованы на RTL-уровне (Register Transfer Level) с использованием конечных автоматов. Железо работает на частоте 165 МГц и обеспечивает 64-битную шину данных, что позволяет добиться «процессорной» полосы пропускания в размере 1,25 ГБ/с, что соответствует входящему потоку 10 Гбит/с.
Декодирование FAST на железе
Чтобы добиться еще большего быстродействия торговой системы, в железную часть выносится и декодирование протокола FAST. Однако, этот процесс сложнее, чем работа с обычным UDP, которая почти не отличается для различных приложений. FAST же является куда более оригинальным и гибким протоколом — каждый обработчик может определять собственные шаблону и карты присутствия, что делает реализацию с использованием конечных автоматов невозможной.
Поэтому на стороне железа был создан модуль для работы с микрокодами, который может декодироват любую реализацию FAST. Чтобы добить поддержку новой реализации протокола, необходимо создать лишь микрокод-инструкцию. При этом не нужно вносить никаких модификаций в само железо.
Микрокод выделяется из спецификации, написанной на предметно-ориентированном языке DSL. Использование модуля микрокодов вместо обычного процессора позволяет добиться большей скорости работы. Из-за ограниченного набора используемых инструкций, скорость обработки данных возрастает на несколько порядков.
На рисунке ниже представлена реализация FAST-декодера. Каждая стадия использует FIFO-буферы. Каждая из трех стадий работает на частоте 200 МГц и использует 64-битный путь данных. Потребление ресурсов при обработке FAST составляет 5630 LUT (Lookup Tables).
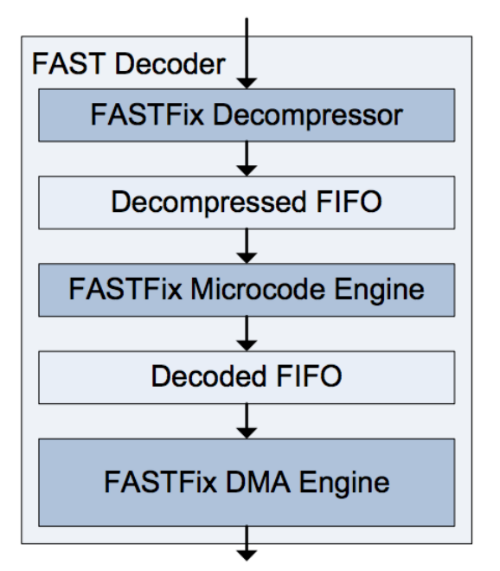
Кратко пройдемся по другим модулям системы:
- Декомпрессор FAST — обнаруживает стоп-биты и выравнивает входящие поля.
- Модуль микрокодов FAST — запускает программу, которая загружается в FPGA при запуске и устанавливает маршрут для каждого шаблона.
- Движок прямого доступа FAST — чтобы передать торговому софту декодированный поток FAST, был создан специальный движок прямого доступа. Он передает полученные данные напрямую в буфер, к которому получает доступ софт, минуя уровень операционной системы.
- Предметно-ориентированный язык
Двоичный код для модуля микрокодов создается ассемблером с помощью разработанной специально для этого проекта реализации DSL. Ассемблер-код для шаблона, представленного выше, могли бы выглядеть примерно так:
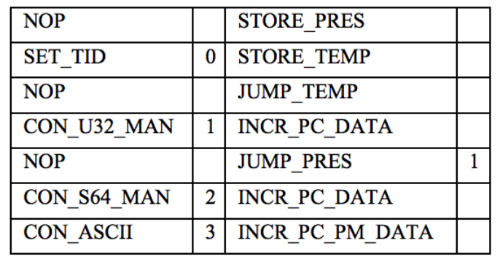
Анализ протокола FAST
Для того, чтобы создать систему, которая могла бы эффективно работать во всех рыночных условиях, даже в моменты высокой волатильности и активности торгов, необходим глубокий анализ данных FAST. Прежде всего, необходимо определить, насколько быстрым может быть обновление данных в реальной торговой системе. Для этого была разработана теоретическая модель, описывающая верхнюю границу скорости обновления информации и принимающая в расчет различные механизмы сжатия данных.
На следующем шаге была выработана более реалистичная модель, основанная на цифрах, полученных в ходе реальных торгов.
Формула ниже показывает скорость передачи данных, которая обеспечивается механизмами трансляции дата-фидов:
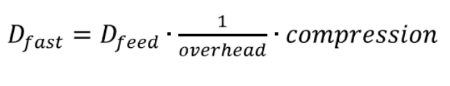
Здесь compression — это фактор компрессии протокола FAST, а overhead — оверхед Ethernet и UDP протокола. Максимальную скорость разработки данных, которую может поддерживать торговый акселератор, можно обоначить как:
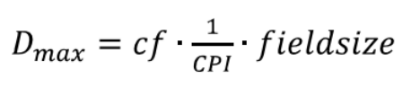
где cf — тактовая частота, CPI означает число циклов на инструкцию, а fieldsize представлет число битов на поле/инструкцию.
Вычислить верхнюю границу Dfast можно выбрать теоретический максимум для Dfeed, который равняется 10 Гбит/с, и степени сжатия (compression), которая равняется 8 (64 бита можно сжать до размера байта). Для получения реалистичной оценки оверхеда осуществлялся анализ нескольких гигабайтов рыночных данных. Оверхед UDP и Ethernet зависит от размера пакетов и множества други факторов, но исследователям удалось определить медианный оверхед для фреймов Ethernet, IP и UDP — он составил 10%.
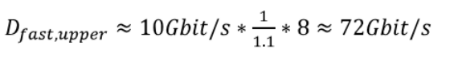
Таким же образом можно вычислить стабильную скорость передачи данных Dmax, которую может «переварить» торговый акселератор. Размер поля составляет 64 бита, а cf равняется 200 МГц. Что касается параметра CPI, то анализ показывает, что в текущей реализации системы для обработки поля требуется 2,66 циклов, что приводит к получению максимальной скорости обрбаотки данных процессором FAST в 4,8 Гбит/с:
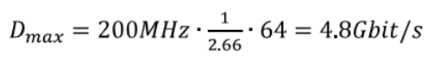
Поскольку Dmax < Dfast, то очевидно, что в моменты всплесков рыночной активности, система просто не справится с возросшими объёмами данных. Единственный параметр, который можно как-то улучшить — это CPI. И сделать это можно с помощью трех техник.
Сегменты «кастомных» инструкций
Декодирование сообщений FAST осуществляется по определенным правилам, которые задаются с помощью TID и PMAP. Для каждого входящего сообщения, модуль микрокодов выполняет анализ TID, чтобы найти код инструкции, которую необходимо исполнить для этого 9шаблона. Внутри потока инструкции, дальнейшие ветви, которые нужно обработать, указываются PMAP. Очевидное решение, которое значительно снижает число используемых ветвей, заключается в том, чтобы использовать дискретные сегменты микрокодов не только для каждого шаблона, но и для каждой последовательности {TID, PMAP}, поскольку именно эта пара предопределяеет все ветви сообщения.
Минусом этого метода является увеличение оверхеда выполнения. Также серьезно растет размер инструкции. Тем не менее, анализ больших объёмов FAST-данных, приводит к интересным выводам. Наблюдения показывают, что для пяти последовательностей {TID, PMAP} вероятность их возникновения составляет 92%. Поэтому может иметь смысл реализация сегментов микрокодов конкретно для этих пар. Реализация этого подхода позволяет значительно снизить CPI — в ходе тестов показатель удалось уменьшить с 2,66 до 2,35 — то есть улучшение составило 13%.
Предварительное вычисление ветвей
Каждая ветвь инструкций требует на выполнение трех тактовых циклов и использования двух инструкций NOP в входе выполнения. В данной реализации существует два типа branch-инструкций. Первый использует TID для поиска сегмента указателя инструкции, а вторая инструкция используется для ветвления внутри сегмента микрокода. Задержку просмотра сегмента шаблона можно исключить с помощью предварительного просмотра входящих полей и перенаправления этой информации в память. Поскольку UDP-фреймы содержат большое количество шаблонов, поиск TID осуществляется часто, а значит открывается простор для оптимизации.
Обработка полей переменной длины
Еще одним источником ветвей инструкций может быть обработка полей переменной длины. Из-за стоп-битов значения в схеме компрессии внутри потока FAST могут иметь размер от 8 до 72 бит (64 бита + 8 стоп-битов). Поскольку путь данных составляет лишь 64 бита, то обработка растягивается на дополнительный один или два цикла. Это также приводит к возникновению дополнительных NOP-циклов.
Исправить ситуацию можно, увеличив путь данных до 72 бит и декомпрессии полей в качестве целого числа. В случае, когда поле представляет собой число, его можно обработать напрямую. В остальных случаях дополнительные 8 бит просто игнорируются. Этот подход позволяет избежать появления ветвей инструкций, реализация полей переменной длины позволило снизить CPI с 2,1 до 1,7.
Оценка
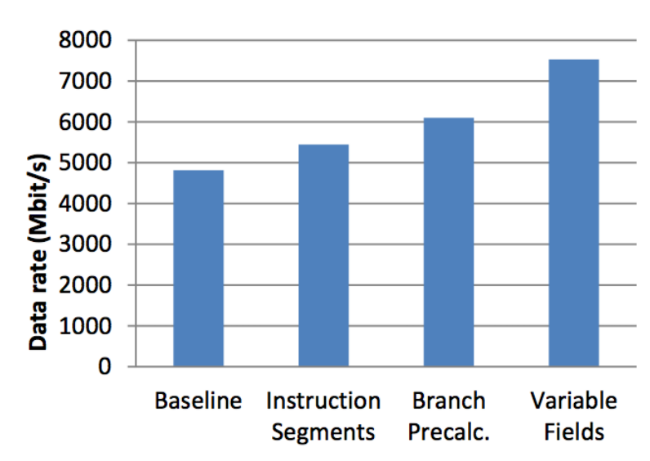
Для оценки производительности системы с применением различных техник оптимизации результаты ее работы были сравнены с базовой реализацией. На рисунке ниже представлены результаты работы применения техник оптимизации для увеличения объёма обрабатываемых данных:
Также FPGA-реализация сравнивалась с софтом, запущенным на обычном железе (Intel Xeon 5472 и IBM Power6). Ниже представлено сравнение производительности в этих случаях:
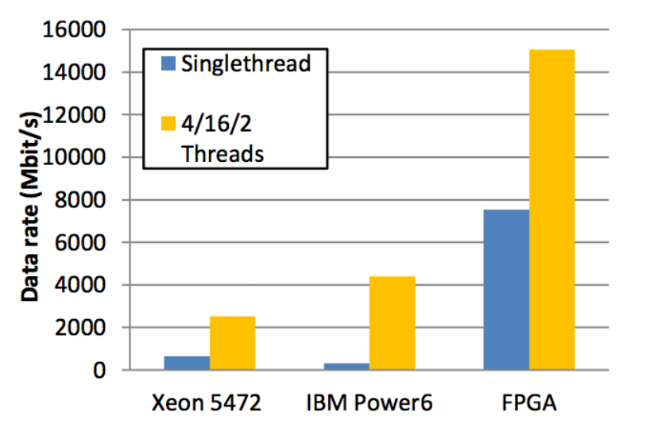
Скорость обработки FAST-сообщений также серьезно отличается. Для того, чтобы декодировать FAST сообщение длиной 21 байт, реализации на Intel Xeon потребовалось 261 нс, у IBM Power6 ушло 476 нс, а у FPGA-реализации всего 40 нс.
