Исключения C++ через призму компиляторных оптимизаций

На дворе 21-й век, непроизводительная реализация обработки C++ исключений на основе setjmp/longjmp уже в прошлом. Современные компиляторы, такие как gcc и clang, используют продвинутую реализацию C++ исключений, называемую zero-cost exception handling. Но насколько действительно это zero-cost?
На конференции C++ Russia 2019 Piter Роман Русяев рассказал, каким образом С++ исключения оказывают влияние на компиляторные оптимизации: какие оптимизации не могут быть применены в случае, если функция может бросить исключения, а какие оптимизации становится труднее применять.
Роман — разработчик компиляторов C/C++ и компиляторов нейронных сетей для специализированных платформ, таких как Neural Processing Unit, работает в Samsung.
Под катом текстовая расшифровка и видео доклада.
В посте Роман расскажет:
Далее — повествование от лица спикера.
Как исключения C++ влияют на производительность ваших приложений? Рассмотрим этот вопрос под другим углом, чем обычно привыкли думать о производительности.
Не будет каких-то чисел, показывающих увеличение размера бинарного файла или времени исполнения программы. Ни для кого не секрет, что компилятор помещает специальную информацию, которая используется stack unwinder-ом в процессе обработки исключения, за счёт чего ваш бинарный файл увеличивается.
У меня есть статья, где я описываю два разных подхода к реализации исключений и показываю замеры производительности. Давайте поговорим о том, как исключения влияют на middle-end компилятора, то есть на ту часть, которая ответственна за оптимизацию ваших приложений, для того, чтобы они работали быстрее. Посмотрим, соблюдается ли один важнейших принципов C++: вы не платите за то, что не используете. У вас есть какие-то функции, не бросающие исключения, но вы не пометили их noexcept-ом, либо не подали какой-то специальный флажок при сборке, например, -fno-exceptions: будете ли вы платить за то, что компилятор там нагенерирует какой-то дополнительный код в плане производительности своих приложений?
Цель доклада
Как оптимизирующий компилятор работает с исключениями С++, и как это может отразиться на производительности ваших приложений:
- насколько дороги исключения, даже если они не выбрасываются?
- когда лучше исключения не использовать;
- noexcept везде, где можно.
Допустим, я покажу, что платить мы будем. Но что с этим делать? Самый очевидный вывод — не использовать исключения. Но не все приложения могут это делать. Кому-то удобно обрабатывать ошибки своих приложений через механизм исключений. Так или иначе, большинство нашего кода все-таки исключения не бросает, и каким-то образом мы можем на это повлиять. Один из основных моих тезисов — использовать noexcept везде, где это возможно. Если ваша функция не бросает исключения, ставьте «noexcept». Почему так? Рассмотрим чуть позднее.
Сначала рассмотрим противоположный лагерь, тех людей, которые считают иначе. Есть точка зрения — используйте const повсюду. Если у вас значения неизменяемые, логично помечать const-ом. Этот лагерь считает, что нужно ставить везде const: на локальные переменные, на параметры функции, которые передаются по значению, на возвращаемые значения, но не всегда возможно гарантировать соблюдение этого правила, используя различные средства, такие как статанализ. В процессе код ревью какое-то из этих мест вы можете пропустить. У вас появится неконсистентность в коде: где-то будет const, где-то не будет, удлинение строчек из-за этого скажется на читаемости, а с move-семантикой всё стало еще забавнее. В каких-то местах, где должен вызываться конструктор перемещений, будет вызываться конструктор копирования. Есть такой лагерь, у него есть свои аргументы. А что с noexcept-ом?
Есть лагерь людей, которые считают, что может появиться неконсистентность — кто-то забудет поставить noexcept. При начальном дизайне функции мы должны решить, будет она бросать исключения или не будет. Если мы навесим noexcept, а потом его придется убирать (а это уже часть интерфейса), пользовательский код может заложиться на это. Есть сторонники, которые говорят: «Зачем нам вообще noexcept, что он даёт?» Я попробую продемонстрировать, какой профит можно получить с noexcept.
Введение в реализацию исключений
Составим общее понимание о том, каким образом исключения реализованы, что сделано в компиляторе, что необходимо в runtime.
Реализация исключений это достаточно платформоспецифичная штука, поэтому я взял наиболее распространенный сиплюсплюсный ABI, который в настоящий момент есть, это Itanium CXX ABI (спецификация описана в Itanium C++ ABI).
Zero-Cost Exception Handling (0eh)
Термин Zero-Cost Exception Handling был введен Hewlett-Packard-ом при реализации исключений. Что он означает? Если вы не бросаете исключения, у вас не будет выполняться дополнительного кода. Как и все zero-cost абстракции в C++, он декларирует, что вы не исполняете каких-то дополнительных динамических инструкций, если не бросаете исключения. Помимо динамического исполнения есть ещё статический код, с которым работает компилятор. Компилятор не может понять, будет ли этот код исполнен или нет, горячий он или холодный. Есть определенные эвристики, есть профилирование и так далее. Так или иначе компилятор видит только статистический код, но не динамическое исполнение. И вот zero-cost для компилятора уже не совсем zero-cost.
Немного о терминологии, которую будем использовать. Будем говорить только про noexcept. Мы можем навесить noexcept на функцию, таким образом декларируя, что она не будет бросать исключения.
Необходимые термины:
- Stack unwinding — осуществляет вызов деструкторов локальных объектов каждого стекового фрейма, пока не будет найден фрейм с обработчиком исключения, соответствующим объекту брошенного исключения. Состоит из двух фаз. В Itanium ABI это фаза поиска обработчика и фаза cleanup.
- Cleanup выполняет вызовы деструкторов локальных объектов в процессе stack unwinding.
- Обработчик исключения — это код, который в конечном итоге выполнится. Обработчик исключения есть всегда: даже если вы не поставили catch, у вас вызовется terminate.
std::terminate
Есть много случаев, в которых вызывается terminate. Первый, который мы рассмотрим — случай, если нарушена спецификация исключений. Из функции, помеченной noexcept бросается исключение. Если исключение бросается из cleanup-ов, тоже вызывается terminate.

Рассмотрим пример, из которого видно, что происходит при бросании исключений. У вас есть функция. Есть ваш код — user code, и C++ runtime code — это библиотеки поддержки C++, в которых реализованы всякие unwinding-и. Бросается исключение. По красной стрелке переходим в C++ runtime. Происходит фаза поиска.
Если обработчик не найден, вызываем terminate. В противном случае переходим на вторую стадию, стадию cleanup.
Из неё переходим на код, который выполняет собственно cleanup. Этот код в вашем приложении строит компилятор. Он содержит вызовы деструкторы локальных объектов, могут быть какие-то дополнительные действия. Либо это обработчик. Например, catch, который вы написали.
Есть несколько путей развития:
- из catch вы выходите по нормальному потоку и все — вы остаетесь в своем коде.
- из cleanup компилятор строит вызов специальной функции, которая возвращает вас на вторую стадию cleanup.
- третий вариант платформоспецифичный. В LLVM: если функция с noexcept-ом нарушает свою спецификацию (из этой функции выбрасывается исключение), вызывается terminate. Этот terminate строится в пользовательском коде. По стандарту это implementation-defined, то есть вы можете раскручивать стек полностью или частично, либо вообще не раскручивать стек, сразу вызывать terminate.
Рассмотрим, что сделано в middle-end.
Введение в LLVM IR
Intermediate Representation — промежуточное представление, некая структура данных или язык, которым оперирует компилятор, получаемый в результате работы фронтенда, который генерирует IR из AST. С IR на middle-end работают все оптимизации, анализы, трансформации для того, чтобы ускорять ваш код. Будем использовать немножко урезанный вариант LLVM, но не в ущерб корректности, чтобы было более понятно. В любой момент можно взять этот IR и достроить его до полного представления.
Пример инструкций на LLVM IR псевдокоде
- %val — объявление локальной переменной либо метки.
- alloca — выделение на стеке памяти для объекта типа type.
- call — инструкция вызова функции с именем func_name.
Важный момент — call имеет специальный признак. Это бинарный признак, который говорит, может ли из этого call-а вылететь исключение или нет. Этот признак очень часто используется оптимизацией. Также инструкция return — возврат из функции.

Вся ваша программа в middle-end компилятора представлена в виде Control Flow Graph — граф потока управления. Специальный граф, узлами которого являются пачка инструкций. Этот узел называется Basic Block (базовый блок). Пачка инструкций, которая находится в базовом блоке обладает определенным свойством — переходя в этот базовый блок, мы либо выполним все инструкции в нем, либо вообще туда не попадем.
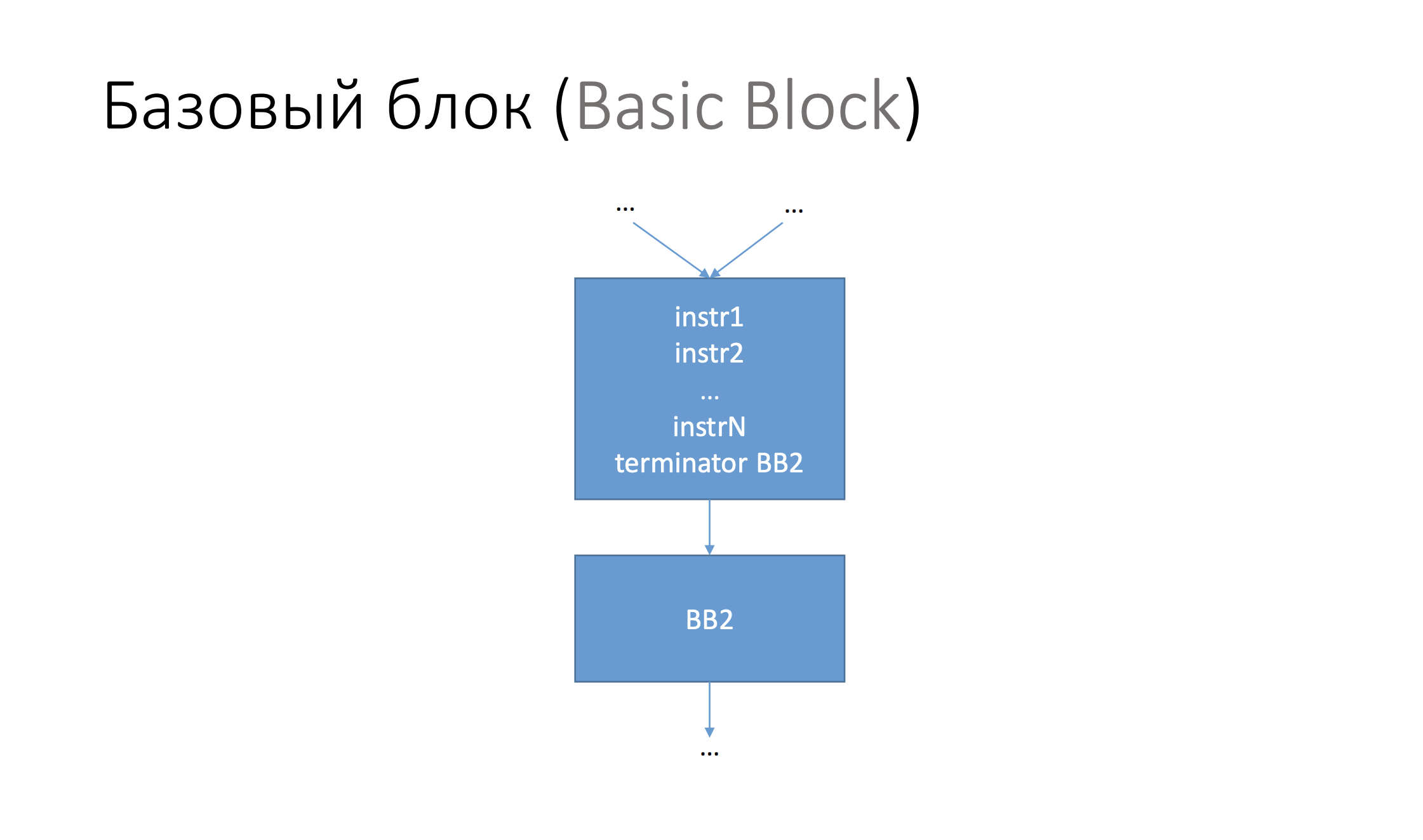
Базовый блок оканчивается специальной инструкцией, которая называется terminator. Это может быть либо какой-то бранч (переход, условный либо безусловный), либо это инструкция возврата из функции, либо специальная инструкция, которая называется invoke.
Поддержка исключений в LLVM: invoke, landing pad, resume
- вызов функции с неявным переходом на участок кода, если бросили исключение
invoke foo() to label %1 unwind label %2 - участок кода, ответственный за обработку исключения
landingpad - инструкция, продолжающая раскрутку стека
resume
Invoke — терминальная инструкция. Она оканчивает базовый блок, обладает семантикой двух операций. Первая — это семантика вызова функции, аналогично инструкции call, но в случае успешного выполнения вызываемой функции (если exception не был брошен), управление передается на блок с меткой %1. Если исключение из функции было брошено, управление передается на базовый блок %2. Этот блок начинается со специальной инструкции landingpad, и содержит код обработчика исключения и/или cleanup'ы (вызовы деструкторов локальных объектов).
Если нам нужно продолжать раскрутку стека, то строится специальная инструкция resume, после которой управление не возвращается в эту функцию. Resume преобразуется в вызов специальной функции, определяемой ABI, которая возвращает нас на вторую стадию cleanup. Invoke — это превдоинструкция, необходимая оптимизатору для отображения неявного потока управления. В ассемблере она будет представлена обычной инструкцией вызова функции.
Влияние исключений на компиляторные оптимизации
Два ключевых момента. Есть инструкция call с признаком «может бросать исключения или нет», есть инструкция invoke, которая делает то же что и call — вызывает функцию, — но обладает дополнительной семантикой условного перехода. Условный переход — неявный, если exception выбросился, мы переходим на специальный участок кода, который генерирует компилятор. Invoke — это терминальная инструкция, на ней базовый блок заканчивается.
Перейдем к тому, как вообще всё это переваривают оптимизации.
Накладные расходы (с точки зрения оптимизатора)
За счет чего мы получаем накладные расходы? Важный момент — накладные расходы именно с точки зрения middle-end, потому что там есть дополнительные накладные расходы со стороны runtime и за счет увеличения размера бинарного файла. Первый момент — это увеличение размера функции, потому что компилятор строит landingpad-ы, invoke-и, в этих landingpad-ах создается код cleanup-ов, то есть вызов деструкторов.
Второй момент — это усложнение потока управления за счет инструкции invoke. Call — это обычная инструкция, она может быть в начале базового блока, в конце, в середине — в любом месте. В случае invoke-ов, базовые блоки будут резаться по ним, появится больше базовых блоков. Поток управления усложняется, потому что появляются условные переходы, и те оптимизации, которые работают в пределах базового блока (peephole-оптимизации), будут иметь меньше контекста для применения. Они видят меньше инструкций, чем могли бы видеть, если бы у нас были не invoke-и, а call-ы. Современные компиляторы — хорошие. Clang активно развивается, есть определенные оптимизации, которые позволяют устранить этот оверхед.
Накладные расходы — как побороть?
Первая оптимизация — PruneEH. Она преобразует invoke-и в call-ы и ставит признак — nounwind для функций, которые не бросают exception.

Рассмотрим код: слева — C++, с другой стороны — LLVM. Bar будет вызывать функцию extF. Почему не invoke? Потому что в bar нет никаких локальных объектов, не нужно делать никаких дополнительных действий. В foo, которая вызывает bar, объявлен локальный объект, для которого нужно вызвать деструктор, поэтому функция bar будет вызываться по invoke.
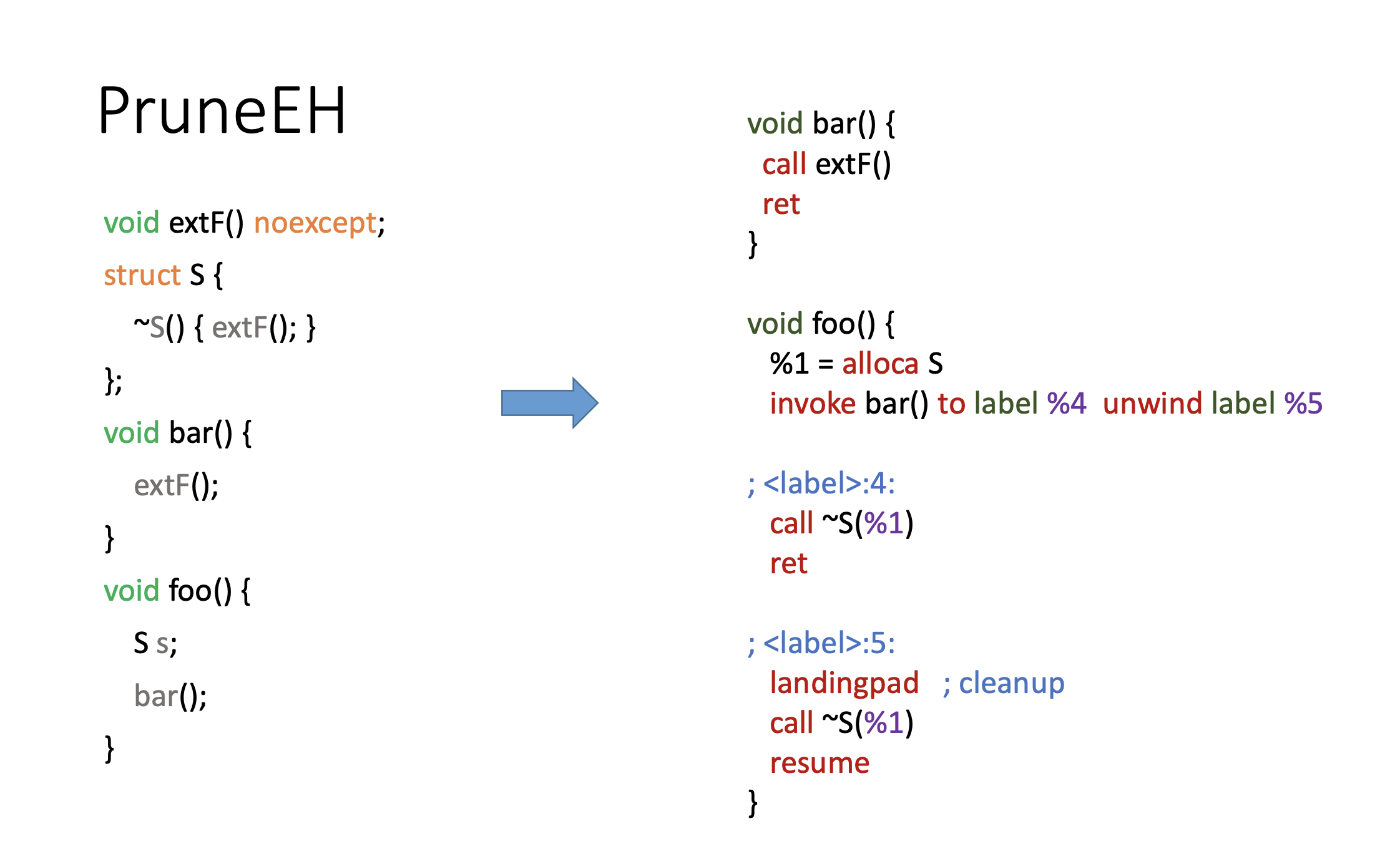
В случае normal попадаем на метку «4», просто уничтожаем этот объект, выходим из функции. В случае если исключение было брошено, попадаем на метку «5», вызываем там деструктор и продолжаем раскрутку стека. Что делает PruneEH?

Посмотрите на разницу: так было, а так стало. Так как функция extF помечена noexcept-ом. Оптимизация работает следующим образом: она анализирует call граф, ходит по call графу снизу вверх и пропагирует признак noexcept, если такой встречается по ходу, преобразуя инструкции invoke в инструкции call. Мы видим результат её работы. Удалось определить, что та функция не бросает исключение, значит, этот признак можно спропагировать и преобразовать в call.
Остальные оптимизации
Есть также ещё ряд оптимизаций, например, Simplify the CFG. В общем случае на каждый invoke строится свой landingpad, но landingpad-ы могут быть одинаковыми. Simplify the CFG объединяет эти landingpad-ы, минимизируя размер кода функции, убирая лишние инструкции, что благоприятно сказывается на других оптимизациях. GVO делает похожую вещь, что и PruneEH. Instruction combining — это та разновидность peephole-оптимизаций, которая работает на базовом блоке. Она помечает инструкции call, вызывающие noexcept функции как noexcept, что также будет полезно для последующих оптимизаций.
Где не удается побороть накладные расходы?
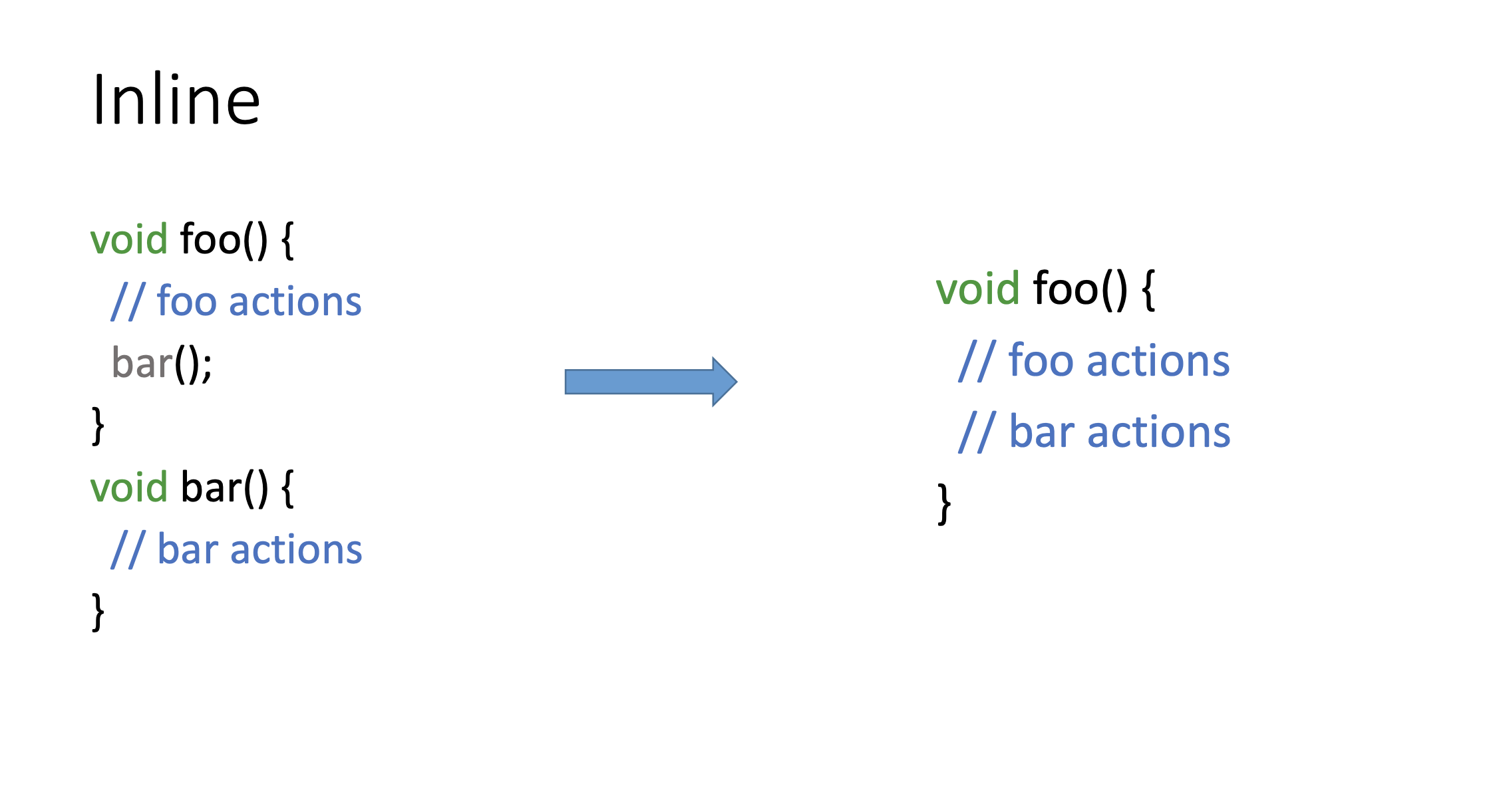
Больше всех страдает Inline. Inline — концептуально простая оптимизация, подставляет тело вызываемой функции в вызывающую. Всё. Но с точки зрения реализации, это одна из самых сложных оптимизаций. Она использует cost-модели, различные эвристики, по которым она понимает, нужно ли инлайнить эту функцию или нет.
Inline: эвристики
CallAnalyzer::analyzeBlock(…) {
…
addCost(…); // for each instruction add cost …
}
Одна из самых ключевых эвристик — это количество инструкций в текущей функции, куда мы инлайним. Если у нас уже инструкций очень много, то вероятность инлайна туда очередной функции уменьшается. За счет invoke-ов компилятор генерирует дополнительный код, где вызывает деструкторы, статический размер кода увеличивается, inline начинает работать хуже.

Рассмотрим пример. Имеется функция bar, которую мы вызываем из foo по invoke-у, если исключение бросили — идем на landingpad вызываем там деструкторы. Это синтетический пример, совершенно тривиальный, он ничего не делает, но уже на нем мы видим увеличение размера кода функции.
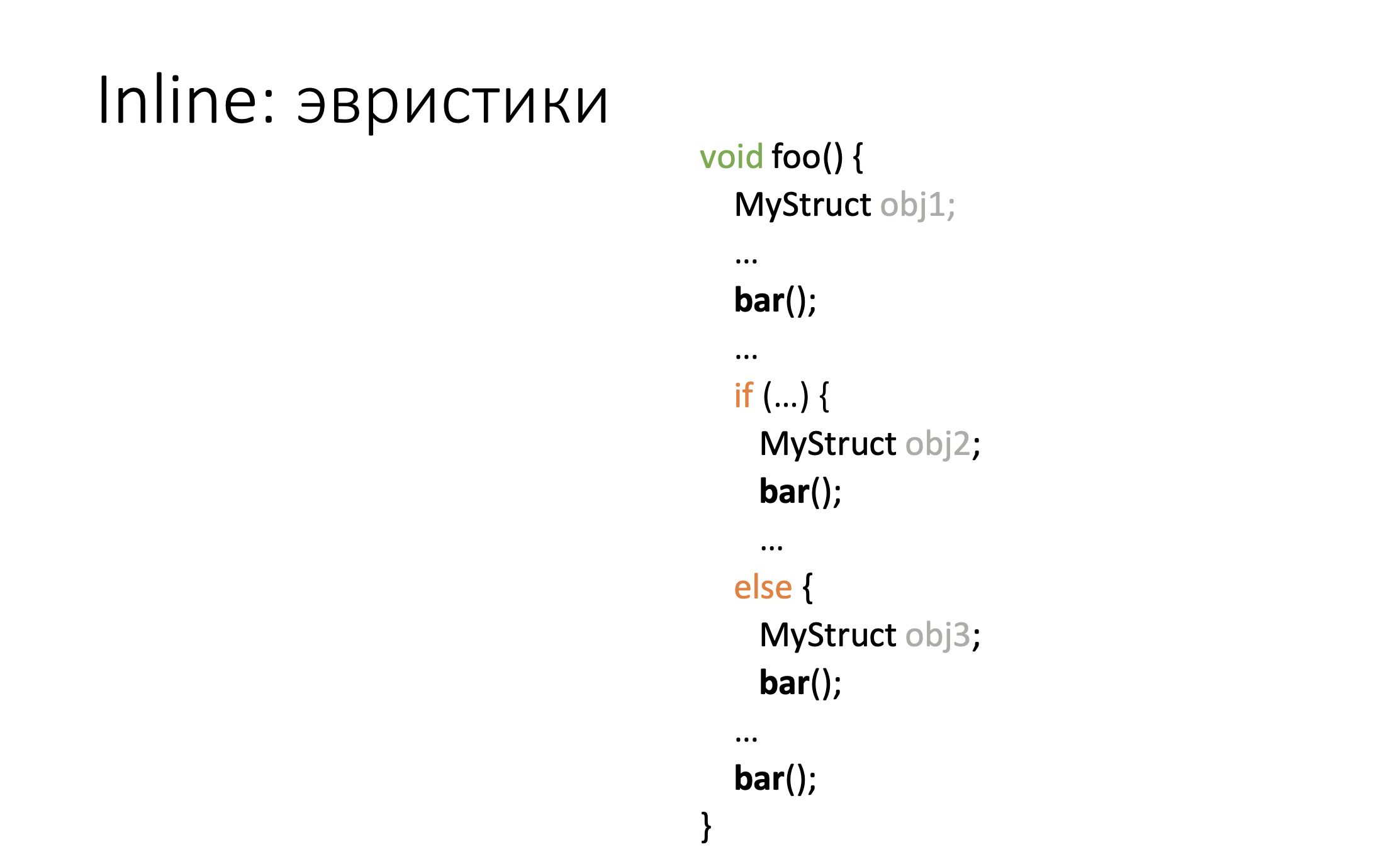
Пример выше демонстрирует, что при наличии инструкций управления, мы создаем локальные объекты, код разбухает за счет invoke-ов и вероятность инлайна уменьшается.

С точки зрения эвристик, здесь мы поделать ничего не можем, кода становится больше, вероятность инлайна — меньше. Еще есть технические сложности, которые достаточно тяжело преодолеть. Есть функция f1, из которой вызывается функция f2, а в функции f1 есть локальные объекты, которые, если исключение выбросится, нужно уничтожить, вызвать для них деструкторы. Функция f2, которую мы хотим проинлайнить в f1, вызывает обычным call-ом какую-то другую функцию, f3. Если мы проинлайним f2 в f1, что мы должны сделать с f3? Мы должны её вызывать через invoke. До inline мы вызвали f1, вызвали f2, в процессе вызова f3 из f3 бросили исключение, разворачиваем стек, должны выполнить landingpad, который находится в f1 — сделать cleanup-ы, вызвать деструкторы локальных объектов. Если мы проинлайним f2, оставим call f3, то в landingpad мы уже не попадем. У оптимизатора не будет возможности увидеть, что здесь есть какой-то код, который мы должны выполнить, если исключение было брошено. После инлайна f2 все функции, которые вызывались из нее через call, теперь должны быть вызваны через invoke. После инлайна f2, все функции, вызывавшиеся из нее через call, стали вызываться через invoke, то есть поток управления ещё сильнее усложнился, появились лишние условные переходы.

У нас был bar, который вызвал extF, в данном примере видно, что теперь мы после inline вызываем extF через invoke, хотя он вызывался в bar через call.

Resume — это инструкция, которая продолжает размотку стека, то есть передает управление в код runtime C++. Пример:

Модифицируем его, добавляем локальный объект в bar, чтобы теперь extF у нас вызывался через invoke.

Те же f1, f2, f3, только теперь f3 вызывается не по call-у, а по invoke-у. Мы должны убрать resume. Потому что если мы оставим resume, то мы не выполним landingpad1, который должен быть выполнен после инлайна. Мы убираем resume и перенаправляем поток управления на landingpad1.

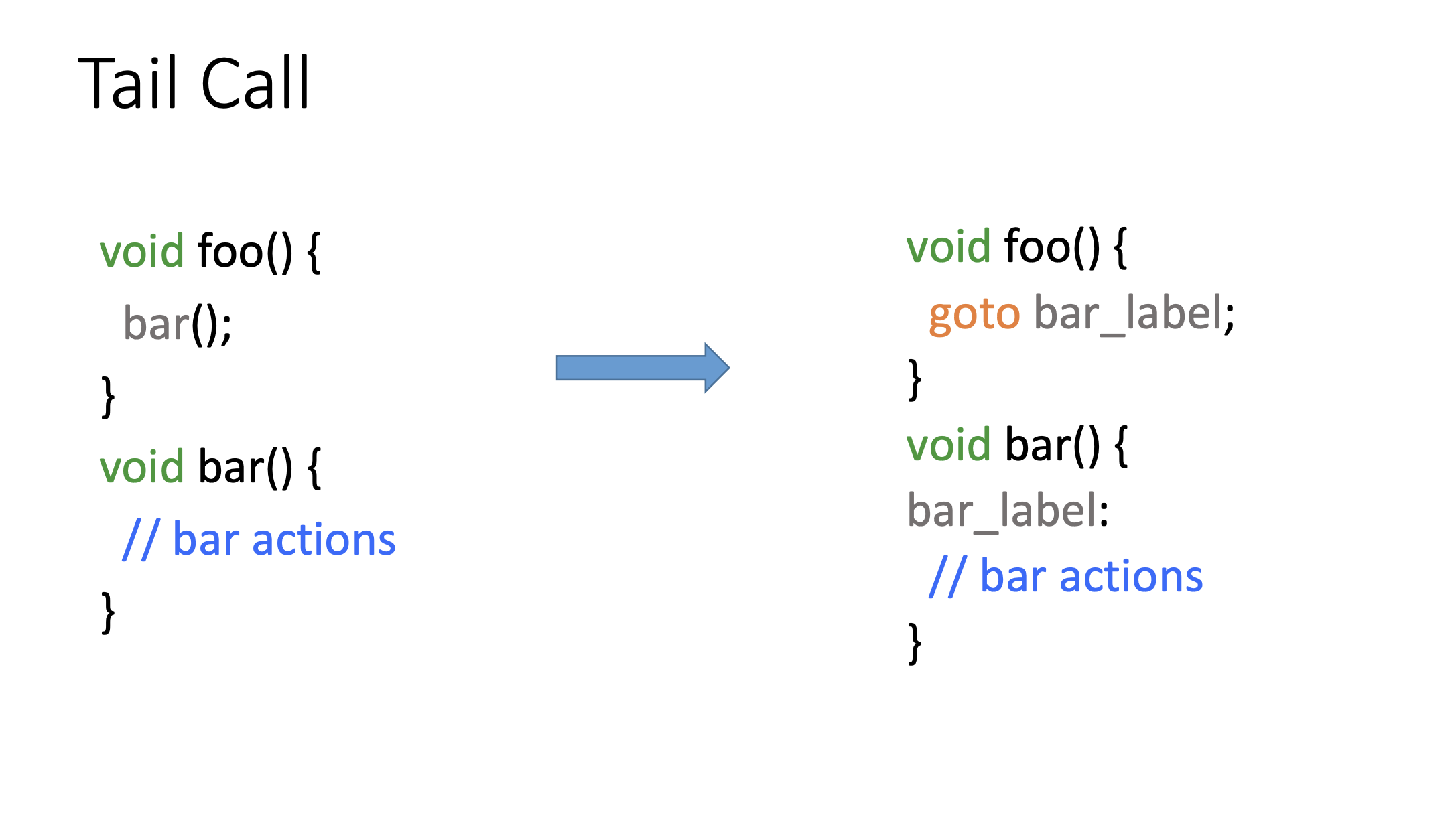
Tail Call тоже классическая оптимизация: минимизирует оверхед, который создается за счет создания стекового фрейма; преобразует call, который находится в конце функции, просто в инструкцию jump, то есть в передачу управления на следующую функцию. Оптимизация выполняется в бэкенде, потому что не для всех архитектур её возможно выполнить. Есть архитектуры, где адрес передачи управления инструкции jump кодируется в меньшее количество бит, чем call, и не все адреса в jump удается представить.
Tail Call не применима к инструкциям invoke
Если call-ы мы можем представить в виде jump-ов, то есть делать переходы вместо вызовов функции, то invoke нет. Мы уже не возвращаемся в вызывающую функцию и не выполним код в landingpad, который должны были выполнить. Tail Call просто не применима к invoke-ам.

Loop Fusion — тоже классика — объединение смежных циклов — уменьшает оверхед на цикл, то есть вместо двух мы выполняем один. Эта оптимизация также является вспомогательной для других оптимизаций, таких как peephole, векторизации и так далее.
Если в цикле есть call с тем признаком, что он может бросать исключения, оптимизация просто не рассматривает этот цикл как кандидата, потому что она считает, что эта функция с побочным эффектом. Объединять такие циклы она не умеет.

LICM (Loop Invariant Code Motion) выносит инварианты из цикла вверх-вниз (предцикл/постцикл), растаскивает load и store и так далее.
Она может выносить call-ы, если определит, что они инварианты относительно цикла, но для invoke-ов и call-ов, которые потенциально могут бросить исключение не применяется.

ADCE — наиболее агрессивная версия удалителя мертвого кода. Часто применяется после других различных оптимизаций, которые создают для неё контекст. Положительно сказывается на многих дальнейших оптимизациях, например, на распределителе регистров, потому что инструкций становится меньше, регистров нужно использовать меньше, давление на регистр снижается. Для инлайна то же самое — минимизируем размер кода — больше вероятность того, что проинлайним.
Агрессивная версия работает следующим образом. Она считает исходно, что все инструкции в функции мертвые, и начинает доказывать обратное. Если для конкретной инструкции оптимизация определила, что эта инструкция живая, то происходит пропагация «живости» на всех предшественников данной инструкции, которые связаны с ней потоком данных.

Существует функция isAlwaysLive, которая проверяет всегда ли жива данная инструкция. И для landingpad-ов она говорит «да, всегда», без всяких дополнительных проверок, а также для всех терминальных инструкций. Invoke — это терминальная инструкция. Следствием из этого является, что в случае «мертвого» call-а оптимизация сможет его удалить, но в случае invoke-а (из-за того, что это терминальная инструкция), оптимизация его не удалит, как и его предшественников по потоку данных.
О терминологии
Есть удаление мертвого кода, а есть удаление недостижимого кода — это разные вещи, часто их путают. Недостижимый код — это код, который мы не достигаем, мы туда вообще не попадем. После безусловного return у нас есть какой-то код. А мертвый код — это код, который выполняется, но не несет в себе никакой полезной нагрузки, то есть если мы его выкинем, в результате программа никаким образом не поменяется.
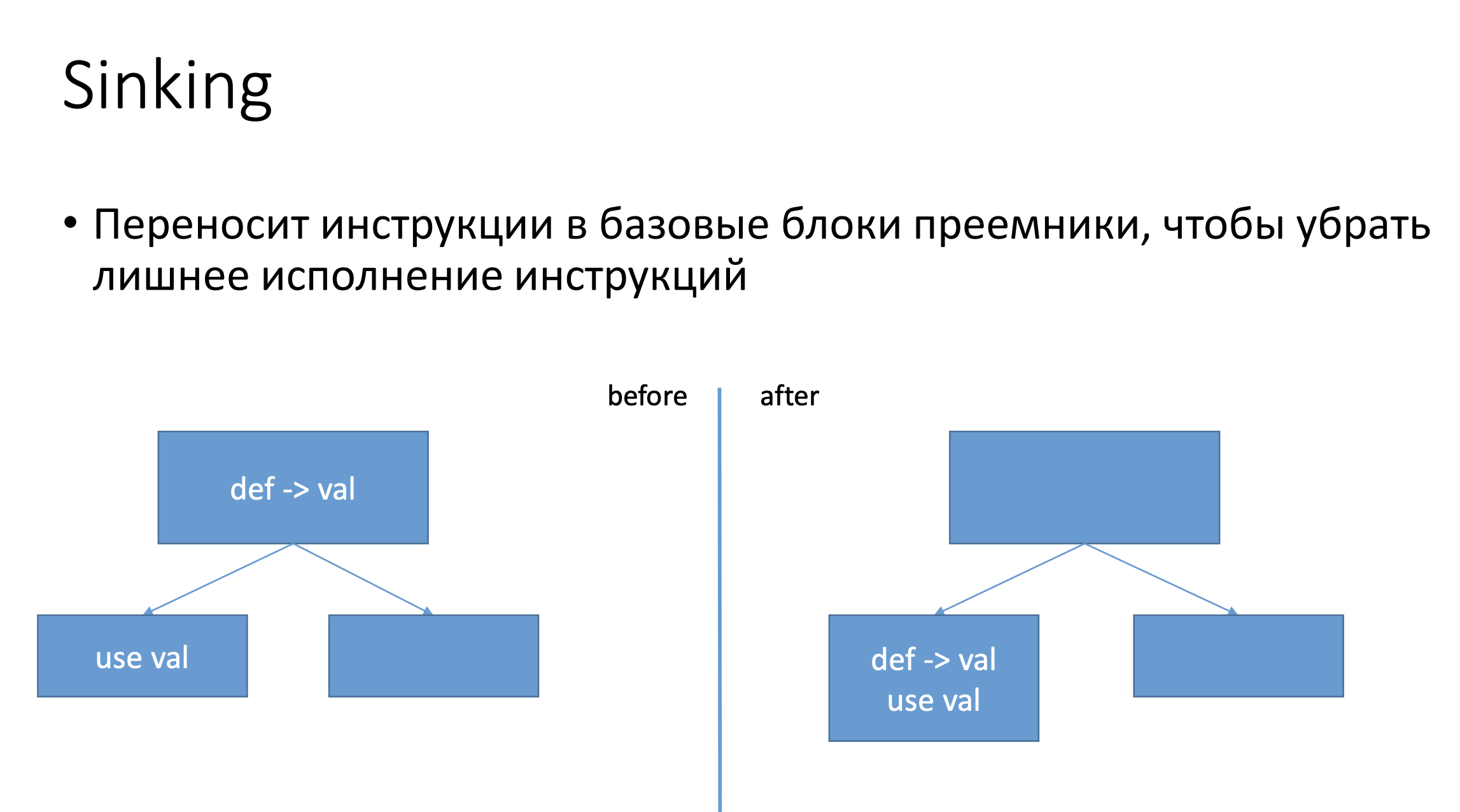
Sinking переносит все инструкции, которые определяют какое-то значение, ближе к их преемникам, таким образом уменьшает количество динамически выполняемых инструкций. Пример: у нас был какой-то def какого-то значения val, потом был use в другом базовом блоке, оптимизация переносит этот def в тот же базовый блок, где расположен use. Если другой базовый блок, который не содержал использования val, был горячим (т.е. передача управления на него переходит часто), то, мы просто не будем выполнять лишние инструкции, и это положительно скажется на производительности.

Функция isSafeToMove проверяет можно ли переместить инструкцию. Если call бросает исключение — то, оптимизация не применяется.
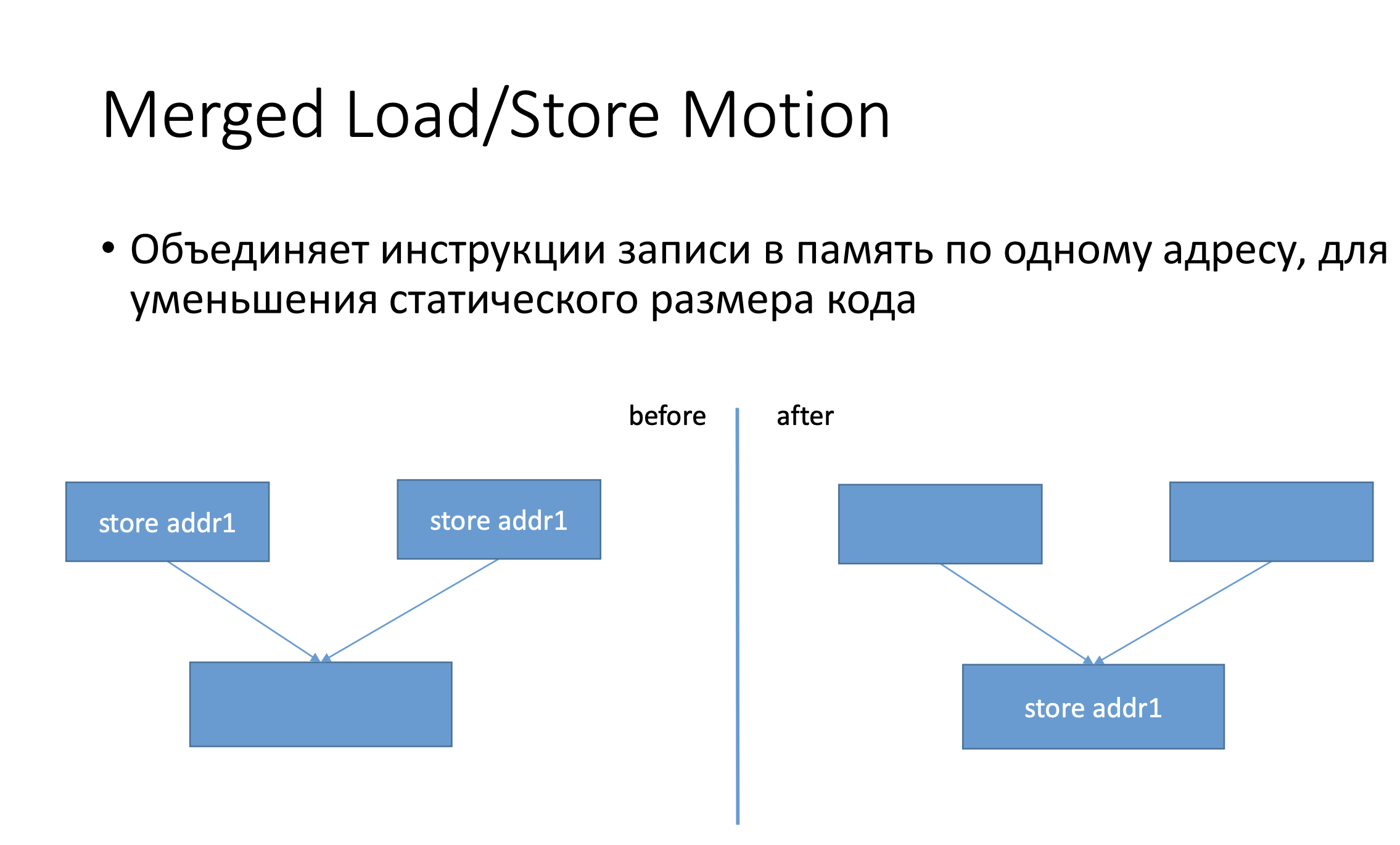
Merged Load/Store объединяет store-ы в один, минимизируя количество статических инструкций в коде.

Функция isStoreSinkBarrierInRange проверяет, можно ли вытащить инструкцию, находящуюся между инструкциями Start и End. Если между этими инструкциями есть какой-то call, который бросает exception, мы не можем этого сделать.
Остальные оптимизации:
- mayHaveSideEffects;
- mayThrow;
- doesNotThrow.
Вышеуказанные функции проверяют, бросает ли функция исключения и есть ли побочные эффекты у инструкции.
Выводы
Как мы продемонстрировали на ряде классических оптимизаций zero-cost далеко не нулевой с точки зрения оптимизатора.
Есть ряд оптимизаций, которые минимизируют этот оверхед, но они рассчитывают, что каким-то образом удастся доказать, что функция не бросает исключения. Это означает, что если функция внешняя (т.е. компилятор не видит ее определения), вы должны её пометить noexcept-ом.
Если вы разрабатываете какую-то библиотеку, то имеет смысл посмотреть, кто будут ваши пользователи — потому что вы можете сократить количество пользователей, если они собирают свои приложения без исключений.
Главный вывод — ставьте noexcept везде. Это просто одно слово, написание которого ничего не стоит, но при этом вы получаете потенциальный выигрыш с точки зрения производительности ваших приложений.
Скоро Роман Русяев выступит на на онлайновой С++ Russia 2020 Moscow вместе с Антоном Полухиным: там они поговорят о настоящем и будущем copy elision. А еще на конференции выступят Герб Саттер (председатель комитета по стандартизации С++) и сам создатель языка Бьярне Страуструп! Полная программа конференции — на сайте.А те, кто хочет не ограничиваться C++, могут проапгрейдить свой билет до абонемента на 8 конференций сразу, чтобы этим летом узнать больше о тестировании, DevOps и других вещах.
