Инженерный подход к разработке ПО
Как проверить идеи, архитектуру и алгоритмы без написания кода? Как сформулировать и проверить их свойства? Что такое model-checkers и model-finders? Требования и спецификации — пережиток прошлого?
Привет. Меня зовут Васил Дядов, сейчас я работаю программистом в Яндексе, до этого работал в Intel, ещё раньше разрабатывал RTL-код (register transfer level) на Verilog/VHDL для ASIC/FPGA. Давно увлекаюсь темой надёжности софта и аппаратуры, математикой, инструментами и методами, применяемыми для разработки ПО и логики с гарантированными, заранее определёнными свойствами.
Это первая моя статья из цикла, призванного привлечь внимание разработчиков и менеджеров к инженерному подходу к разработке ПО. В последнее время он незаслуженно обойдён вниманием, несмотря на революционные изменения в подходе и инструментах поддержки.
Не буду лукавить: основная задача статьи — возбудить интерес. Так что в ней будет минимум пространных рассуждений и максимум конкретики.

В статье две части. В первой я опишу, что подразумеваю под инженерным подходом, во второй покажу пример использования подхода в рамках простой задачи (близкой к области микросервисной архитертуры).
Я всегда открыт для обсуждения вопросов, связанных с разработкой ПО, и буду рад пообщаться с читателями (координаты для связи есть в моём профиле).
Часть 1. Инженерный подход к разработке
Что это такое? Покажу на примере возведения моста:
- Этап 1 — это сбор требований к мосту: тип моста, грузоподъёмность и т. д.
- Этап 2 — уточнение требований и расчёт конструкций (спецификация).
- Этап 3 — собственно само строительство на основе инженерных расчётов (спецификаций).
Конечно, это упрощённая аналогия. Никто не делает прототипов мостов, чтобы уточнить требования и спеки. В мост нельзя добавить параметризации, чтобы он становился то арочным, то подвесным. Но в целом, думаю, аналогия ясна.
В разработке ПО этапы 1 и 2 часто отсутствуют либо очень слабо выражены. Если требования и зафиксированы, то расплывчато, неполно и неформально. Лишь единицы детализируют требования и разрабатывают чёткие спецификации.
Многие считают, что это трата времени, пережиток прошлого, особенно если выбран agile-подход к разработке (особенно с короткими итерациями). И это большое заблуждение.
Почему?
Для начала разберёмся, что такое требование и спецификация и в чём их существенное отличие, которое даже многим профессионалам не всегда очевидно.
Что такое требования?
Если кратко, требования — это формулирование свойств продукта в терминах предметной области. Например, так: «Все экземпляры программы должны одинаково обрабатывать входные запросы».
В требованиях не используются термины области реализации. Как только в требования просачиваются термины «синхронизация состояний», Raft, Paxos, «логарифмическая сложность по времени» — то начинают смешиваться требования и спецификация.
Важно понимать это и чётко отделять одно от другого.
Почему?
Требования должны быть понятны потребителям ПО, поэтому должны быть из предметной области, для которой разрабатывается ПО (часто к формулировке требований и постановке задачи на разработку ПО приходится привлекать экспертов, далеких от разработки).
Свойства ПО, которые видит потребитель, оцениваются по метрикам предметной области. Нужно разделять требования и спецификации, чтобы иметь возможность 1) выделить основные метрики продукта, по которым потребитель будет оценивать наше ПО, и 2) ясно понимать, какие свойства продукта важны для пользователя, а какие нет.
А иначе может получиться так: разработчики, не укладываясь в срок, пожертвуют важными свойствами и уделят много времени и внимания неважным. Причём то, что кажется важным с точки зрения разработки ПО, может быть неважным с точки зрения для пользователя.
Классический пример такого несоответствия приведён в разнообразной литературе о разработке пользовательского интерфейса и в статьях (например: System Response Time and User Satisfaction: An Experimental Study of Browser-based Applications, Computer latency: 1977–2017). Разработчики обычно стараются оптимизировать время выполнения операции, например поиска информации в базе данных, а для пользователя важно время отклика системы. И если поиск идёт медленно, но пользователь начинает видеть выдаваемые результаты как можно быстрее, то ему кажется, что такое ПО работает лучше, чем то, которое ищет быстро, но сначала аккумулирует результаты и в конце выдаёт их все.
Именно поэтому планировщики ресурсов ОС различаются для серверного и десктопного режимов работы. Для серверного режима важна максимальная пропускная способность системы, т. е. оптимизация времени и памяти, чтобы эффективно использовать сервер. А для пользователя важна задержка отклика системы. Чем быстрее система реагирует на действия, тем более шустрой она кажется, даже если работает медленнее.
И, наконец, самая важная причина:
Если требования и спеки смешиваются — значит, мы не полностью понимаем задачи, для которых разрабатываем ПО. Задачи из предметной области мы начинаем формулировать и решать в области разработки ПО. Поэтому логика предметной области просачивается и запутывает логику кода. В итоге получается сильно связанный код, который тяжело поддерживать.
Об этом хорошо написал Michael Jackson в книге Problem Frames: Analysing & Structuring Software Development Problems. На мой взгляд, это одна из самых полезных книг для разработчиков ПО. Она учит в первую очередь анализировать проблемы пользователей, которые и должно решать хорошее ПО. Супербыстрая программа, которая потребляет мало ресурсов системы, но не решает задач пользователей, — это плохая программа. Крутая, но плохая.
Что есть спецификация?
Спецификация — это формулирование свойств ПО в терминах области разработки ПО. Вот тут появляются понятия сложности, синхронизации и т. д.
Спецификации могут быть организованы иерархически: от абстрактных к конкретным, по которым можно писать код. Такой подход зачастую наиболее эффективен. В абстрактных спецификациях легко отражается архитектура — можно увидеть основные свойства, найти архитектурные ошибки и т. д. Поэтому мы можем отыскать проблемы на ранних стадиях жизненного цикла ПО и существенно уменьшить затраты на исправление ошибок.
Особенно стоить отметить пользу и важность спецификаций на протоколы и интерфейсы между компонентами системы, что позволит избежать вот таких ситуаций: 
В чём отличие от обычного подхода к разработке?
При инженерном подходе мы заранее проектируем ПО с требуемыми характеристиками в соответствии со спецификациями. Спецификации проверяем на нужные свойства, которые идут из требований.
Я сделал сравнение в виде таблички (весьма субъективной):
А не за водопадную ли модель разработки тут идёт агитация?
Инженерия ПО, включая даже формальные спеки и моделирования, отлично сочетается с agile-подходом.
Есть мнение, что инженерный подход к разработке несовместим с быстрой итерационной разработкой ПО (так утверждается во многих статьях, вот пример).
Но это не так. Инженерный подход с успехом применяется во многих проектах, в том числе в проектах с короткими итерациями.
Раньше из-за слабо развитых средств и инструментов поддержки инженерный подход действительно был тесно связан с водопадной моделью.
Но сейчас всё кардинально поменялось.
Благодаря прорывным успехам в области моделирования, SAT/SMT-солверов и др. теперь можно быстро проверять огромные пространства состояний системы на наличие нужных нам свойств и отсутствие ненужных, верифицировать промышленные объёмы кода и т. д.
Появились первоклассные промышленные инструменты типа Alloy, TLA+/TLC, Atelier B, PRISM, которые перевели задачу формализации и проверки спецификаций из академической/математической, требующей высокой квалификации и огромных усилий, в задачу push-button, доступную большинству программистов.
Спецификации сейчас можно разрабатывать итеративно и инкрементально. Модели отлично разрабатываются итерационно, от абстрактных к конкретным. Время моделирования даже крупных систем исчисляется минутами и часами.
Требования легко уточнять итеративно, особенно с современными подходами и инструментами.
И уточнение требований, спецификаций, рефакторинг моделей, написание кода и его рефакторинг легко могут идти параллельно — в рамках одной итерации.
В общем, инженерный подход сейчас совсем не равен водопадной модели, это уже две независимые вещи.
Инженерный подход легко сочетается с любой методологией организации разработки.
В блоге Hillel Wayne показано, как просто работать с формальными спецификациями и моделями. У него есть отличный пример, как за 10 минут формально специфицировать логику пользовательского интерфейса программы и проверить некоторые её свойства.
Не буду вдаваться в детали и переводить статью целиком, просто покажу саму спецификацию на языке Alloy:
open util/ordering[Time]
sig Time {
state: one State
}
abstract sig State {}
abstract sig Login extends State {}
abstract sig Reports extends Login {}
one sig Logout extends State {}
one sig Students, Summary, Standards extends Reports {}
one sig Answers extends Login {}
pred transition[t: Time, start: State, end: State] {
t.state in start
t.next.state in end
}
pred logout[t: Time] { transition[t, Login, Logout] }
pred login[t: Time] { transition[t, Logout, Summary] }
pred students[t: Time] { transition[t, Reports, Students] }
pred summary[t: Time] { transition[t, Reports, Summary] }
pred standards[t: Time] { transition[t, Reports, Standards] }
pred answers[t: Time] { transition[t, Students, Answers] }
pred close_answers[t: Time] { transition[t, Answers, Students] }
fact Trace {
first.state = Summary
all t: Time - last |
logout[t] or
login[t] or
students[t] or
summary[t] or
standards[t] or
answers[t] or
close_answers[t]
}Как видно, спецификация краткая и понятная. Здесь описан небольшой автомат, реализующий абстрактную логику UI в виде состояний и переходов между ними.
Свойства для проверки тоже легко задаются:
check {all t: Time | t.state = Answers implies
t.prev.state = Students} for 7Спецификация похожа на небольшую программу.
К её разработке, уточнению и рефакторингу можно применять те же подходы, что и к разработке программ на любых языках программирования.
С такими спецификациями можно легко работать в стиле agile.
Зачем нужны такие спецификации и что с ними делать — покажу далее.
Формализация спецификаций
Как вы уже догадались, вышеприведённая спецификация является формальной, так как выполнена в рамках формализма — языка Alloy, который позволяет описывать объекты и взаимосвязи между ними в рамках реляционной логики первого порядка.
Если грамотно подходить к разработке, то на этапе формализации, отладки и моделирования спецификаций можно выявить и исправить наиболее критичные и дорогие (при обнаружении на заключительных этапах) ошибки и проблемы в ПО.
Отладка спецификаций позволяет выявить и исправить основные (или даже все) архитектурные проблемы ПО на ранних этапах, зачастую даже до кодирования.
Чтобы не утомлять читателя лишними словами, перейдём к простому примеру.
Часть 2. Пример использования Alloy
Чтобы показать возможности Alloy, я приведу пример создания и отладки спецификации вычислительных графов: структуры, описывающей один из способов обработки данных в системах, основанных на микросервисах и др.
Пример можно рассматривать как начало разработки архитектуры верхнего уровня для вычислительной системы для обработки больших потоков данных на основе микросервисов, где каждый микросервис — это узел в сети, который принимает данные, выполняет над ними какую-то операцию и передаёт их дальше.
Представленный подход к обработке данных на основе вычислительных графов применим для широкого класса задач.
Тут мы проанализируем основные свойства, которыми должны обладать вычислительные графы, чтобы на основе графов можно было делать работоспособные системы.
Отношения
Традиционно в математике бинарным отношением называется множество пар  , где
, где  и
и  .
.
В Alloy принята такая запись: X->Y.
Описание отношений и их свойств поместим в отдельный модуль (который очень близок к стандартному util/relation):
module relation
-- Мультипликаторы:
-- set A - множество элементов из A, может быть пустым
-- one A - множество ровно из одного элемента из A
-- lone A - один элемент из A или пустое множество
-- some A - один и больше элементов из A
-- Универсумы:
-- univ - множество всех элементов во всех множествах модели,
-- можно считать объединением всех сигнатур
-- iden - множество пар {A0, A0}, где первый и второй элемент
-- пары один и тот же и из univ
-- iden = {a : univ, b: univ | a=b}
-- то есть это отношение идентичности
-- none - пустое множество
-- Операции:
-- логические: and, or, => (импликация), != (не равно), not
-- над множествами:
-- & - пересечение
-- A->B - множество кортежей с элементами из соотв.
-- множеств
-- X<:Y - выбор из кортежей в Y тех, которые начинаются с
-- кортежей из X
-- A in B - множество A содержится в B
-- ~A - перевернуть все кортежи в A
-- A + B - объединение
-- no A - A пустое, эквивалент A = none
-- ^A - транзитивное замыкание бинарного отношения A,
-- минимальное бинарное отношение B такое, что:
-- A in B,
-- {E0, E1}, {E1, E2} in B => {E0, E2} in B
-- A.B - оператор JOIN, работает след. образом:
-- {A0, B0} in A, {B0, C0, D0} in B, тогда
-- {A0, C0, D0} in A.B
-- Кванторы:
-- all X : Y | .... - всеобщности
-- some X : Y | .... - существования
-- применение предикатов:
-- pred[a: A, b:B] {...} есть две синтаксические формы
-- применения: pred[a, b] и a.pred[b]
-- вторая форма сделана для мимикрии под некоторые
-- ООП-языки, где методы определяются как
-- method(self : Object, args ...)
pred valid [rel : univ->univ, dom : set univ, cod : set univ] {
rel.univ in dom and rel.univ in cod
}
fun domain [rel : univ->univ] : set (rel.univ) { rel.univ }
fun codomain [rel : univ->univ] : set (univ.rel) { univ.rel }
pred total [rel: univ->univ, dom: set univ] {
all x: dom | some x.rel
}
pred partial [rel: univ->univ, dom: set univ] {
all x: dom | lone x.rel
}
pred functional [rel: univ->univ, dom: set univ] {
all x: dom | one x.rel
}
pred surjective [rel: univ->univ, cod: set univ] {
all x: cod | some rel.x
}
pred injective [rel: univ->univ, cod: set univ] {
all x: cod | lone rel.x
}
pred bijective [rel: univ->univ, cod: set univ] {
all x: cod | one rel.x
}
pred bijection [rel: univ->univ, dom, cod: set univ] {
rel.functional[dom] and rel.bijective[cod]
}
pred reflexive [rel: univ->univ, s: set univ] {
s<:iden in rel
}
pred irreflexive [rel: univ->univ] {no iden & rel}
pred symmetric [rel: univ->univ] {~rel in rel}
pred antisymmetric [rel: univ->univ] {~rel & rel in iden}
pred transitive [rel: univ->univ] {rel.rel in rel}
pred acyclic [rel: univ->univ, s: set univ] {
all x: s | x not in x.^rel
}
pred complete[rel: univ->univ, s: univ] {
all x,y:s | (x!=y => x->y in (rel + ~rel))
}
pred preorder [rel: univ->univ, s: set univ] {
rel.reflexive[s] and rel.transitive
}
pred equality [rel: univ->univ, s: set univ] {
rel.preorder[s] and rel.symmetric
}
pred partial_order [rel: univ->univ, s: set univ] {
rel.preorder[s] and rel.antisymmetric
}
pred total_order [rel: univ->univ, s: set univ] {
rel.partial_order[s] and rel.complete[s]
}Многое из этого модуля нам не понадобится, оно приведено в качестве примера того, как можно даже сложные свойства отношений легко и лаконично выражать Alloy.
Графы
Теперь на основе отношений определим основные свойства графов.
Модуль для описания графов близок к стандартному utils/graph, но, в отличие от модуля отношений, в данный модуль вошли только необходимые нам предикаты и функции:
module graph[node]
open relation
-- функция получения всех узлов графа
fun nodes[r: node->node]: set node {
r.domain+ r.codomain
}
-- граф связан, то есть из любой вершины
-- можно добраться до любой другой по рёбрам
-- без учёта направленности
pred connected[r: node->node] {
all n1,n2 : r.nodes | n1 in n2.*(r + ~r)
}
-- граф ацикличный и направленный
pred dag [r: node->node] {
r.acyclic[r.nodes]
}
-- получить все корневые вершины
-- корневая вершина та, в которую нет
-- никаких входящих путей
fun roots [r: node->node] : set node {
let ns = r.nodes | -- ns - все узлы графа
ns - ns.^r -- из всех узлов убираем те,
-- в которые есть какой-либо
-- входящий путь
}
-- получить все листья
-- лист - конечный узел, из которого
-- нет исходящих путей
fun leaves [r: node->node] : set node {
let ns = r.nodes | -- ns - все узлы графа
ns - ns.^~r -- из всех узлов убираем те,
-- из которых есть какой-либо
-- исходящий путь
}Вычислительный граф
Вычислительный граф — это абстракция, описывающая вычисления в системе в виде графа.
Основные характеристики:
- (1) есть исток — узел, куда передаются входные данные, над которыми и выполняются вычисления;
- (2) есть сток — узел, куда поступает результат вычислений, который отправляется дальше вовне;
- (3) есть вычислительные узлы — они принимают данные, вычисляют и передают данные дальше;
- (4) сток один, исток — тоже;
- (5) у вычислительного узла может быть множество входящих и исходящих дуг. Типы данных и синхронизацию пока не рассматриваем. Для простоты считаем, что данные, пришедшие по входящей дуге, обрабатываются и передаются на все исходящие дуги;
- (6) граф направленный, между любой парой узлов — максимум одна дуга, двух дуг в противоположных направлениях быть не может.
На данном этапе мы рассматриваем в основном топологию.
Теперь опишем вычислительный граф, который удовлетворяет вышеприведённым свойствам, на Alloy:
module compgraph[node]
open graph[node]
open relation
pred valid [edges: node->node,
source : one node, -- свойство 1
drain : one node -- свойство 2
] {
edges.antisymmetric and edges.irreflexive -- свойство 6
graph/roots[edges] = source -- свойство 1 и 4
graph/leaves[edges] = drain -- свойство 2 и 4
}Посмотрим на пару примеров вычислительных графов:
open compgraph[node] as cg -- cg - это псевдоним
enum node {n0, n1, n2, n3, n4}
-- зададим узлы как перечисление, чтобы было более наглядно
run cg/valid -- ещё дополнительно указываем модуль cg, так как
-- предикат valid есть в двух модулях: relation и compgraphПримеры графов можно увидеть на следующем рисунке:

Можем заметить, что некоторые графы не совсем подходят для вычислений (есть подозрительные циклы).
Подумав над свойствами вычислительных графов по отношению к обрабатываемым данным, мы придём к идее консистентности.
Консистентность вычислительного графа
Под консистентностью тут понимаются свойства графа по отношению к потоку данных, которые обрабатываются в графе.
Результаты обработки данных не должны теряться. Это фундаментальное свойство вычислительного графа по отношению к абстрактным данным. То есть все результаты должны попадать либо в сток, либо в другие вычислительные узлы.
Понятно, что потерять данные можно только после получения. Мы можем классифицировать узлы по возможности потери данных:
- активный узел — до него есть путь от истока, т. е. сюда могут прийти данные для вычислений;
- неактивный узел — до него нет пути от истока;
- безопасный узел — от него все пути ведут в сток, т. е. нет опасности подключения к узлу исходящего ребра от активного узла, переданные в него данные не потеряются.
Граф консистентен, если в нём не теряются результаты вычислений и все вычислительные процессы конечны, т. е. мы получим результат за конечное время (все вычисления в графе останавливаются за конечное время, и мы можем считать результат из стока).
Консистентности можно достичь, добавив ещё несколько свойств к свойствам вычислительного графа:
- (7) нет циклов (для простоты описания). В реальных графах могут быть циклы при условиях, которые исключают бесконечную циркуляцию данных по путям цикла, но тут считаем граф ациклическим;
- (8) все пути из активных узлов должны вести к стоку, т. е. нет потерь данных.
И можно ослабить свойство единственности корня и равенства его истоку, так как мы ввели понятие неактивного узла.
То есть все узлы, которые являются корнями, кроме истока, это просто неактивные узлы.
- (9) могут быть дополнительные корневые узлы, являющиеся неактивными узлами.
И (правда, избыточное, оно следует из других) свойство:
- (10) все активные узлы безопасны.
Теперь уточним спецификацию вычислительного графа:
module compgraph[node]
open graph[node]
pred active[edges : node->node,
source: node,
n : node
] {
-- n находится в множестве узлов,
-- достижимых от истока
n in source.^edges
}
pred safe[edges : node->node,
drain : node,
n : node
] {
-- если есть ещё листья, кроме drain,
-- то не один путь из n
-- не должен вести в эти узлы
-- и n не должно быть одним из
-- этих узлов
no n.*edges & (leaves[edges] - drain)
-- одно из свойств безопасных узлов, что
-- можно подать туда данные из активных узлов
-- и данные не будут теряться,
-- таким образом, должен быть путь до drain
drain in n.*edges
}
pred valid [edges: node->node,
source : one node, -- свойство 1
drain : one node -- свойство 2
] {
edges.connected -- так как мы ослабили ограничения
-- на корни и вершины (теперь и
-- тех и тех может быть не по одной),
-- то граф может быть не графом, а
-- лесом, поэтому нужно дополнительное
-- условие connected
edges.dag -- свойство 6 и 8
source in edges.roots -- свойство 1, 4 и 9
drain in edges.leaves -- свойство 2, 4 и 8
all n : edges.roots - source |
not active[edges, source, n] -- свойство 9
all n : edges.nodes | -- 10 свойство
active[edges, source, n] => safe[edges, drain, n]
}Для экономии времени и места картинки с уточнёнными вычислительными графами приводить не буду.
Операции над вычислительным графом
Для работы с вычислительными графами нам нужны операции.
Сначала подумаем, как граф будет жить в системе и что из этого может следовать.
В простейшем случае жизнь графа состоит из шести этапов:
- создание графа;
- проверка валидности графа;
- запуск данных в граф;
- работа графа;
- прекращение подачи данных;
- уничтожение графа.
Изменение работающего графа не подразумевается. Сценарий простой и для большинства задач подойдёт. Не надо заботиться о консистентности графа по отношению к данным во время работы: после создания граф валидируется и далее не меняется.
А если нам нужен сервис, который будет работать долго и сумеет адаптироваться к меняющейся нагрузке? А если мы хотим менять функциональность сервиса во время работы?
Это серьёзно усложняет задачу.
Подумаем о том, как менять граф во время работы, чтобы изменения не нарушали его консистентность.
Предположим, у нас уже есть валидный и работающий граф.
Сначала подумаем, какие операции нам минимально необходимы:
- добавление нового узла и дуги (граф задаётся дугами, поэтому добавить новый узел без связей не получится);
- добавление дуги;
- удаление дуги;
- удаление узла и связанных с ним дуг.
Новый узел при добавлении очевидно считается неактивным.
Основные свойства определяются дугами, поэтому рассмотрим добавление дуги между узлами.
Соединять узлы мы можем несколькими вариантами:
- неактивный → неактивный;
- неактивный → активный;
- активный → неактивный;
- активный → активный.
Первый и последний вариант тривиальны, а второй и третий уже интереснее.
Очевидно, что при подключении неактивного узла к активному ничего плохого не произойдёт: активные узлы безопасны относительно данных, циклов не получится. Ведь в противном случае должна быть дуга к какому-то неактивному узлу, а оттуда — путь к данному неактивному, а это противоречит определению активного/неактивного узла.
Остался самый интересный вариант, третий: активный → неактивный.
Такое подключение будет безопасным, только если:
- неактивный узел безопасен;
- не образуется циклов.
Опишем операции в виде предикатов над графами, которые связывают граф до и после операции.
Можно попробовать описать в виде функций, но в Alloy тяжело задавать функции по созданию сложных структур данных, так как язык чисто декларативный. Если читатель знаком с Прологом, то вот в Alloy примерно так же идёт работа с данными.
pred connect[
old_edges : node->node,
new_edges : node->node,
source : one node,
drain : one node,
from : one node,
to : one node
] {
-- ребра ещё не было
from->to not in old_edges
-- from недостижим из to,
-- чтобы не возникло цикла
from not in to.*old_edges
-- to должен быть узлом графа,
-- иначе граф может стать
-- лесом
to in (old_edges.nodes - source)
-- подключение к to должно быть
-- безопасно, то есть передаваемые
-- данные в to не потеряются
safe[old_edges, drain, to]
-- новый граф определяется рёбрами,
-- берём все старые рёбра и добавляем
-- новое ребро
new_edges = old_edges + from->to
}Предикат connect покрывает все случаи добавления узла с ребром или только ребра к графу.
Давайте проверим, что connect сохраняет валидность графа:
open compgraph[node] as cg
sig node {}
check {
-- для всех возможных наборов рёбер r1, r2
all r1, r2 : node->node |
-- для всех возможных узлов source, drain, from, to
all source, drain, from, to : node {
-- r1 является валидным вычислительным графом с
-- source/drain истоком/стоком
-- и r2 является графом r1 с добавленным операцией
-- connect ребром from->to
(cg/valid[r1, source, drain] and
connect[r1, r2, source, drain, from, to])
-- это влечёт то, что r2 + source/drain
-- также является валидным вычислительным
-- графом
implies cg/valid[r2, source, drain]
-- то есть операция connect сохраняет валидность
-- вычислительного графа
}
} for 8Executing "Check check$1 for 8"
Sig this/node scope <= 8
Sig this/node in [[node$0], [node$1], [node$2], [node$3],
[node$4], [node$5], [node$6], [node$7]]
Generating facts...
Simplifying the bounds...
Solver=sat4j Bitwidth=4 MaxSeq=7 SkolemDepth=4 Symmetry=20
Generating CNF...
Generating the solution...
8374 vars. 168 primary vars. 22725 clauses. 108ms.
No counterexample found. Assertion may be valid. 26904msAlloy не смог найти контрпример во всём пространстве конфигураций графов с количеством узлов до восьми включительно. Это большое пространство,»168 primary vars» говорит о том, что оно размером  возможных значений основных переменных. И это заняло на среднем ноутбуке меньше 30 секунд!
возможных значений основных переменных. И это заняло на среднем ноутбуке меньше 30 секунд!
То есть мы можем быть вполне уверены, что операция connect сохраняет валидность любых вычислительных графов.
Теперь обратная операция, удаление дуги:
pred disconnect[
old_edges : node->node,
new_edges : node->node,
source : one node,
drain : one node,
from : one node,
to : one node
] {
-- рёбра есть в старом графе
from->to in old_edges
-- при удалении ребра from
-- должен остаться безопасным
safe[new_edges, drain, from]
-- граф должен оставаться связанным
new_edges.connected
-- удаляем ребро
new_edges = old_edges - from->to
}Пробуем:
open compgraph[node] as cg
sig node {}
check {
all r1, r2 : node->node |
all source, drain, from, to : node {
(cg/valid[r1, source, drain] and
disconnect[r1, r2, source, drain, from, to])
implies cg/valid[r2, source, drain]
}
} for 8Ого! Найдены контрпримеры! Парочку из них можно увидеть на следующем рисунке:
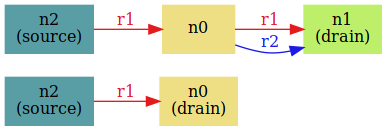
Дуги, помеченные как r1, — это дуги графа до операции disconnect, r2 — после неё. Там, где есть r1, но нет параллельной ей r2, эта r2 и была удалена операцией.
Видно, что причина контрпримеров — это удаление единственной дуги from→to, в случае когда source (он же from) перестаёт быть связанной вершиной графа.
Поправляем операцию disconnect:
pred disconnect[
old_edges : node->node,
new_edges : node->node,
source : one node,
drain : one node,
from : one node,
to : one node
] {
from->to in old_edges
( safe[new_edges, drain, from] or
(from not in new_edges.nodes and
from != source))
new_edges.connected
new_edges = old_edges - from >to
}Executing "Check check$2 for 8"
Sig this/node scope <= 8
Sig this/node in [[node$0], [node$1], [node$2], [node$3], [node$4], [node$5], [node$6], [node$7]]
Generating facts...
Simplifying the bounds...
Solver=sat4j Bitwidth=4 MaxSeq=7 SkolemDepth=4 Symmetry=20
Generating CNF...
Generating the solution...
8505 vars. 168 primary vars. 24808 clauses. 207ms.
No counterexample found. Assertion may be valid. 18369ms.Таким образом мы определили две основные операции, которые сохраняют свойства валидности вычислительного графа.
Полнота операций
У нас есть множество валидных графов, а достаточны ли наши операции для построения любого валидного графа из любого валидного?
Не окажется ли так, что мы не сможем поменять топологию работающей системы нужным образом? И она окажется в тупике и придётся останавливать и перезапускать всю систему?
Давайте проверим:
-- для любых двух валидных графов
-- есть последовательность промежуточных валидных графов,
-- такая, что два следующих друг за другом графа
-- приводятся друг к другу за одну операцию
check {
all r1,r2: node->node | all source,drain: node |
some intermediate : seq node->node {
cg/valid[r1, source, drain] and cg/valid[r2, source, drain]
=>
intermediate.first = r1 and
intermediate.last = r2 and
all i : intermediate.inds - intermediate.lastIdx {
let from = intermediate[i] |
let to = intermediate[i+1] |
some n1, n2 : node |
connect[from,to, source, drain, n1, n2]
or
disconnect[from, to, source, drain, n1, n2]
}
}
} for 3И вот тут мы получаем:
Executing "Check check$3"
Sig this/node scope <= 3
Sig this/node in [[node$0], [node$1], [node$2]]
Generating facts...
Simplifying the bounds...
Solver=sat4j Bitwidth=4 MaxSeq=4 SkolemDepth=4 Symmetry=20
Generating CNF...
Generating the solution...
A type error has occured: (see the stacktrace)
Analysis cannot be performed since it requires higher-order
quantification that could not be skolemized.Что это значит?
Мы столкнулись с ограничением Alloy: квантификация может быть только первого порядка либо должна сводиться к первому порядку.
А здесь не получилось сделать сколемизацию квантора «some intermediate…», так как подкванторная переменная должна пробегать по структуре высшего порядка — последовательности графов.
И к первому порядку такую конструкцию не свести.
Иногда (но не так часто, как хотелось бы) можно переформулировать предикат так, чтобы он свёлся к первому порядку.
Хотя уже есть higher-order Alloy, но он пока экспериментальный, квантификация высших порядков у него имеет существенные ограничения по размеру моделей. Она катастрофически замедляет моделирование, так как идёт через CEGIS — counter-example guided inductive synthesis.
В данном случае нам придётся придумать альтернативный способ проверки, возможно ли достичь всех валидных графов.
Если ослабить условие и проверять не достижимость любого валидного из любого валидного, а возможность сделать шаг между двумя валидными, которые отличаются на одно ребро, то получим:
check {
all edges, edges1 : node->node |
all source,drain, from, to : node {
(cg/valid[edges, source, drain] and
cg/valid[edges1, source, drain] and
edges1 = edges + from->to and
edges1 != edges)
=>
some n1, n2: node | connect[edges, edges1, source, drain, n1, n2]
}
} for 7Эта проверка уже работает, и мы видим результат:
Executing "Check check$3 for 7"
Sig this/node scope <= 7
Sig this/node in [[node$0], [node$1], [node$2], [node$3],
[node$4], [node$5], [node$6]]
Generating facts...
Simplifying the bounds...
Solver=sat4j Bitwidth=4 MaxSeq=7 SkolemDepth=4 Symmetry=20
Generating CNF...
Generating the solution...
6471 vars. 133 primary vars. 16634 clauses. 200ms.
Counterexample found. Assertion is invalid. 116ms.Найден контрпример!
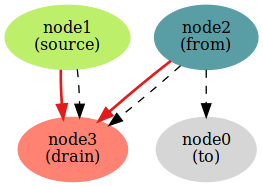
Красные дуги — это дуги графа до шага, чёрные пунктирные — после шага. На этом шаге добавляется дуга from→to.
Тут мы видим, что операция connect не позволяет добавить дугу от неактивной вершины к небезопасной (и, соответственно, неактивной).
Поправляем connect:
pred connect[
old_edges : node->node,
new_edges : node->node,
source : one node,
drain : one node,
from : one node,
to : one node
] {
from->to not in old_edges
from not in to.*old_edges
to in (old_edges.nodes - source)
-- вот тут поправили
active[old_edges, source, from] => safe[old_edges, drain, to]
-- учитываем безопасность to только для активной from,
-- и, так как to теперь может быть отдельной вершиной,
-- как и from, то нужно добавить условие
-- сохранения связанности графа
new_edges.connected
-- это стало очевидным, так как старая проверка
-- стала давать контрпримеры :)
new_edges = old_edges + from -> to
}Проверяем снова:
Executing "Check check$3 for 7"
Sig this/node scope <= 7
Sig this/node in [[node$0], [node$1], [node$2], [node$3],
[node$4], [node$5], [node$6]]
Generating facts...
Simplifying the bounds...
Solver=sat4j Bitwidth=4 MaxSeq=7 SkolemDepth=4 Symmetry=20
Generating CNF...
Generating the solution...
6513 vars. 133 primary vars. 16837 clauses. 125ms.
No counterexample found. Assertion may be valid. 291ms.Теперь всё нормально.
Точно так же проверяем обратный шаг для операции disconnect. Там тоже будет контрпример, придётся внести правки:
pred disconnect[
old_edges : node->node,
new_edges : node->node,
source : one node,
drain : one node,
from : one node,
to : one node
] {
from->to in old_edges
-- если удаляем исходящее ребро из активной вершины,
-- то она должна оставаться безопасной
active[old_edges, source, from] => safe[new_edges, drain, from]
-- заметьте, что теперь не нужно анализировать на
-- то, что вершина вышла из графа:
-- (from not in new_edges.nodes and
-- from != source)
new_edges.connected
new_edges = old_edges - from->to
}Таким образом, мы доказали, что если один валидный граф достижим из другого валидного за конечное число шагов добавления/удаления по одной дуге, то мы всегда можем прийти с помощью наших операций от одного графа к другому.
Это означает, что, начав с минимального работающего валидного графа (например, source→drain), мы можем дойти до больших валидных графов с помощью операций connect/disconnect и всегда вернуться к начальному графу.
Этого свойства хватит для построения широкого класса вычислительных графов (есть основание предполагать, что всех интересных на практике вычислительных графов или же вообще всех, но это требует более серьёзного доказательства).
Что дальше?
Дальше можно развивать идею в направлении локальности операций, например.
В большой распределённой системе может быть очень неудобно при операциях над графом требовать наличия в узлах, которые участвуют в операции, знаний обо всём графе, чтобы определить отсутствие циклов и т. д.
То есть хорошо бы разработать операции со свойством локальности: им понадобится знание только об узлах, что участвуют в операции (признаки safe/active и пр.).
При небольших ограничениях на возможные топологии графа эта задача решаема.
Далее, хорошо бы проводить множество параллельных операций над графом одновременно.
Если мы локализовали операции, то распараллеливание — задача тоже вполне решаемая с помощью механизмов транзакций, локальных блокировок и т. д.
Либо можно изначально проектировать систему таким образом, чтобы операции были локальные и параллельные.
Ещё хорошо бы ввести типы входных и выходных из узлов данных, чтобы конструировать графы с учётом специфики узлов обработки.
В результате на выходе мы получим уже не игрушечную, а реальную рабочую спецификацию вычислительных графов и операций над ними, по которой можно разрабатывать реальную систему с нужными нам (заложенными в спецификации) свойствами.
