Интерактивная диаграмма Ганта для тысяч работ
Всем привет ! Я работаю full-stack разработчиком в одной организации в атомной отрасли. Некоторое время назад потребовалось добавить в одно из наших приложений диаграмму Ганта. В сфере деятельности нашей организации много специфики, и для реализации самой удобной диаграммы именно для наших пользователей не хватило бы библиотечных решений. Поэтому была поставлена задача: реализовать диаграмму Ганта с нуля.

Интерфейс диаграммы
В этой статье будут рассмотрены следующие проблемы:
Наши пользователи хотят отображать на диаграмме 1, 3, 5, а то и 10 тысяч работ.
На диаграмме работы должны быть отсортированы, при этом у некоторых имеются вложенные работы, т.е. у работы с номером '1.' может быть работа с номером '1.1.'. Работа с номером '1.1.' должна идти перед работой с номером '2.', и в то же время работа с номером '11.' должна идти после работы '2'. Лексикографическая сортировка здесь не подходит. Данные в БД изначально не отсортированы (удовлетворяют 1NF).
Пользователи хотят сворачивать вложенные работы. Если есть работа с номером '1.' с 1e3 вложенных работ, и пользователь её скрывает, он должен незамедлительно увидеть сразу после неё работу '2'.
Далее максимум внимания уделен архитектурным и алгоритмическим решениям сначала на фронт-энде, затем на бэк-энде. Мы используем популярное сочетание React + Nest + PostgreSQL, поэтому далее будут небольшие пояснения, как именно они ложатся на этот стэк.
Принцип сортировки работ описан в разделе про бэк-энд.
Также отмечу, что работы («job») и задачи («task») в статье используются синонимично.
Фронт-энд
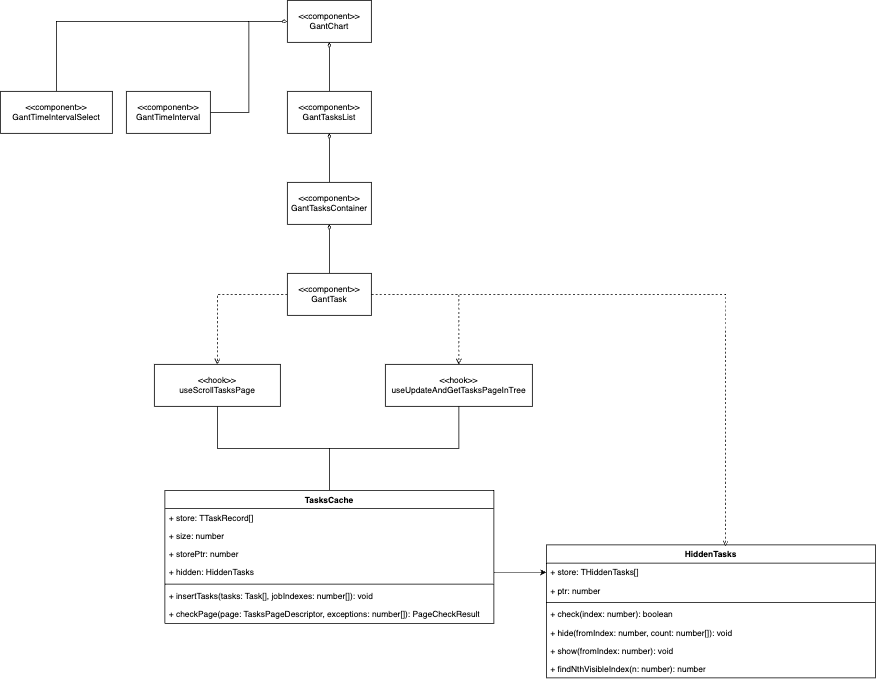
Архитектура фронт-энда
Основные выдержки из описанного далее кода фронт-энда можно увидеть тут.
Чтобы не запрашивать разом тысячи работ пользователя, мы используем пагинацию. В рамках пагинации мы оперируем не отдельными работами, а небольшими подмножествами последовательно идущих работ, называемыми страницами. При каждом пролистывании пользователя одна страница работ загружается в память, а другая её покидает.
Важно учесть: пользователи редко просто листают работы подряд и чаще возвращаются к просмотренным ранее работам. Просто запрашивать при каждом пролистывании нужную в конкретный момент времени страницу работ может быть слишком медленно (особенно при неидеальном сетевом подключении). Поэтому в архитектуру был добавлен важный элемент: кэш работ »TasksCache».
Также заметим тот факт, что пользователь взаимодействует в течение некоторого отрезка времени лишь с небольшим подмножеством работ. Это послужит основной для оптимизированного функционирования архитектуры. Если же случайно пролистывается большое число работ (например, зажатием колесика мыши), срабатывает механизм debounce.
Архитектура работает следующим образом:
Кэш
TasksCacheхранит некоторое число работ в кольцевом буфере. В буфере резервируется место под несколько страниц работ. По мере пролистывания новые нужные пользователю работы записываются в память на места самых старых и давно не использованных работ. Если же пользователь возвращается к работам, которые он просматривал не так давно, указатель буфера перемещается назад к ним.TasksCacheпредоставляет следующие методы:insertTasksзаписывает свежий массив работ в буфер. Асимптотика — O (Sp), где Sp — размер страницы работ.checkPageпроверяет, есть ли желаемая страница работ в памяти, и если не находит её, возвращает массив номеров недостающих работ. Благодаря использованию кольцевого буфера, в среднем случае достигается асимптотика O (Sp). В худшем случае (если пользователь резко пролистал к тем работам, с которыми раньше не взаимодействовал) получается асимптотика O (Sb), где Sb — размер буфера.
Класс
HiddenTasksхранит в себе отрезки свёрнутых работ. Отрезкок работ — это множество работ, имеющее общую родительскую работу. Отрезки хранятся в массиве, отсортированные по началу отрезков. В примере ниже хранится следующий массив: [{ from: 2, to: 3 }, { from: 6, to: 9 }, { from: 9, to: 9}]. Это позволяет предоставлять следующие эффективные методы:checkпроверяет, скрыта ли работа с указанным индексом. Для этого линейно просматриваются все отрезки, и проверяется, попадает ли указанный индекс в какой-либо из них. Класс хранит в себе указатель ptr на отрезок, в котором в последний раз была найдена некоторая работа. Линейный просмотр отрезков начинается с этого указателя и проходит в массиве по кругу. Учитывая, что зачастую данный метод вызывается с соседними индексами работ, данная оптимизация позволяет в большинстве случаев получить асимптотику O (1); в худшем случае асимптотика O (Sh), где Sh — кол-во отрезков.hideскрывает указанный отрезок. Асимптотика O (Sh) (линейно находится место для вставки нового отрезка)show раскрывает указанный отрезок. Асимптотика также O (Sh).
findNthVisibleнаходит n-ную по счету не скрытую работу. В примере ниже для n = 3 данный метод вернул бы 5. Метод линейно проходит по отрезкам и останавливается тогда, когда число не скрытых работ между ранее пройденными отрезками = n. Именно для работы данного массив отрезков поддерживается отсортированным. Асимптотика O (Sh).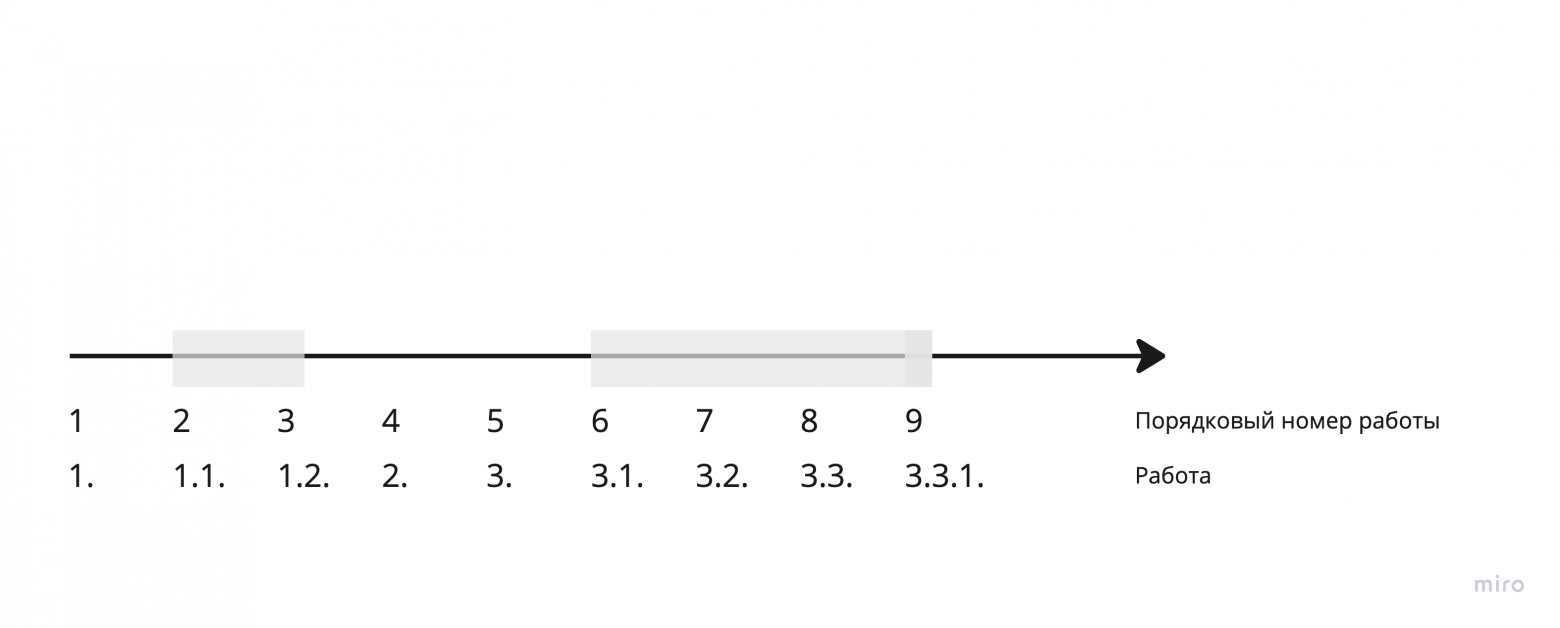
Пример отрезков скрытых работ
Хук
useScrollTasksPageотслеживает, пролистал ли пользователь очередные несколько работ и реализует технику debounce. Какие по счету задачи требуется показать пользователю вычисляется по высоте прокрутки, исходя из высоты одной работы (такой расчёт позволяет пользователю прокручивать с любой скоростью в отличие от использования IntersectionObserver).Хук
useUpdateAndGetTasksPageInTreeзагружает новую страницу работ. Для этого он:Вызывает у
HiddenTasksметодfindNthVisible, чтобы загрузить страницу со сдвигом на кол-во скрытых перед ней работ.Вызывает у
TasksCacheметодcheckPage, чтобы понять, каких именно работ не достает в памяти.Запрашивает недостающие работы и добавляет их в
TasksCacheвызовом методаinsertTasks. Благодаря использованию буфера вставка работает за O (P).
Важным моментом является то, что фронт-энд не знает, какие именно работы (с какими конкретно id в БД) нужно загрузить следующими. В каждый момент времени он запрашивает работы по их порядковым номерам в сортировке по номеру работы (о ней будет сказано далее). Это позволяет системе быть крайне гибкой и предоставлять возможность удаления/добавления работ.

Возможный порядковый номер работы
Бэк-энд
Бэк-энд предоставляет эндпоинт, в который передаётся массив порядковых номеров работ. Для того, чтобы получить данные из базы по порядковым номерам, для каждой работы вводится специальное число k, по которому работы можно сортировать.
В нашем случае максимально есть 4 уровня вложенности (т.е. может быть работа '1.2.3.4'., но не может быть работы '1.2.3.4.5.'). Также на каждом уровне может быть не более 10 тыс. вложенных работ (т.е может быть работ '1.2.9999.1'., но не может быть работы 1.2.12345.1.). Тогда в качестве k для номера работы = a.b.c.d. выбирается число из 16 разрядов, в котором первые 4 разряда будут отведены под d, следующие 4 разряда под c, ещё 4 под b и последние 4 разряда под a.
Например, для работы »1.10.2.9999.» вот так будут заполнены разряды числа:

Т.е. для каждой работы k = d + 1e4 * c + 1e8 * b + 1e12 * a
С использованием числа k можно запрашивать корректно отсортированные работы следующим образом:
select
order by
(
(cast(coalesce(nullif(split_part(job, '.', 1), ''), '0') as bigint) * 1e12) +
(cast(coalesce(nullif(split_part(job, '.', 2), ''), '0') as bigint) * 1e8) +
(cast(coalesce(nullif(split_part(job, '.', 3), ''), '0') as bigint) * 1e4) +
cast(coalesce(nullif(split_part(job, '.', 4), ''), '0') as bigint)
)
offset
limit
И с PostgreSQL, можно использовать индекс:
create INDEX
(cast(coalesce(nullif(split_part(job, '.', 1), ''), '0') as bigint) * 1e12) +
(cast(coalesce(nullif(split_part(job, '.', 2), ''), '0') as bigint) * 1e8) +
(cast(coalesce(nullif(split_part(job, '.', 3), ''), '0') as bigint) * 1e4) +
cast(coalesce(nullif(split_part(job, '.', 4), ''), '0') as bigint)
))
При использовании индекса на 20 тыс. задач получается приблизительно следующая производительность:

explain analyze в PostgreSQL
При развёртывании на локали на устройстве с Intel Core i5 1.3 Ghz и 16gb DDR4 среднее время ответа на запрос бэк-энда на Nest.js составило 11.4 мс. С максимальной возможной (до включения debounce) скоростью прокрутки на протяжении 15 секунд в Chrome 121 у фронт-энда на React отрисовка заняла ~400 мс, отображение — 200, выполнение скриптов — 2500. То есть производительности данного решения будет более чем достаточно для пользователей.
Благодарю за внимание! :-)
