Intel® Parallel Studio XE 2016 Beta – что нового?
Большое обновление пакета Intel® Parallel Studio XE вышло на этой неделе. Версия 2016 включает три совершенно новых продукта: Intel® Data Analytics Acceleration Library (Intel® DAAL) — C++ и Java решение для аналитики данных (статистика, машинное обучение и другое).
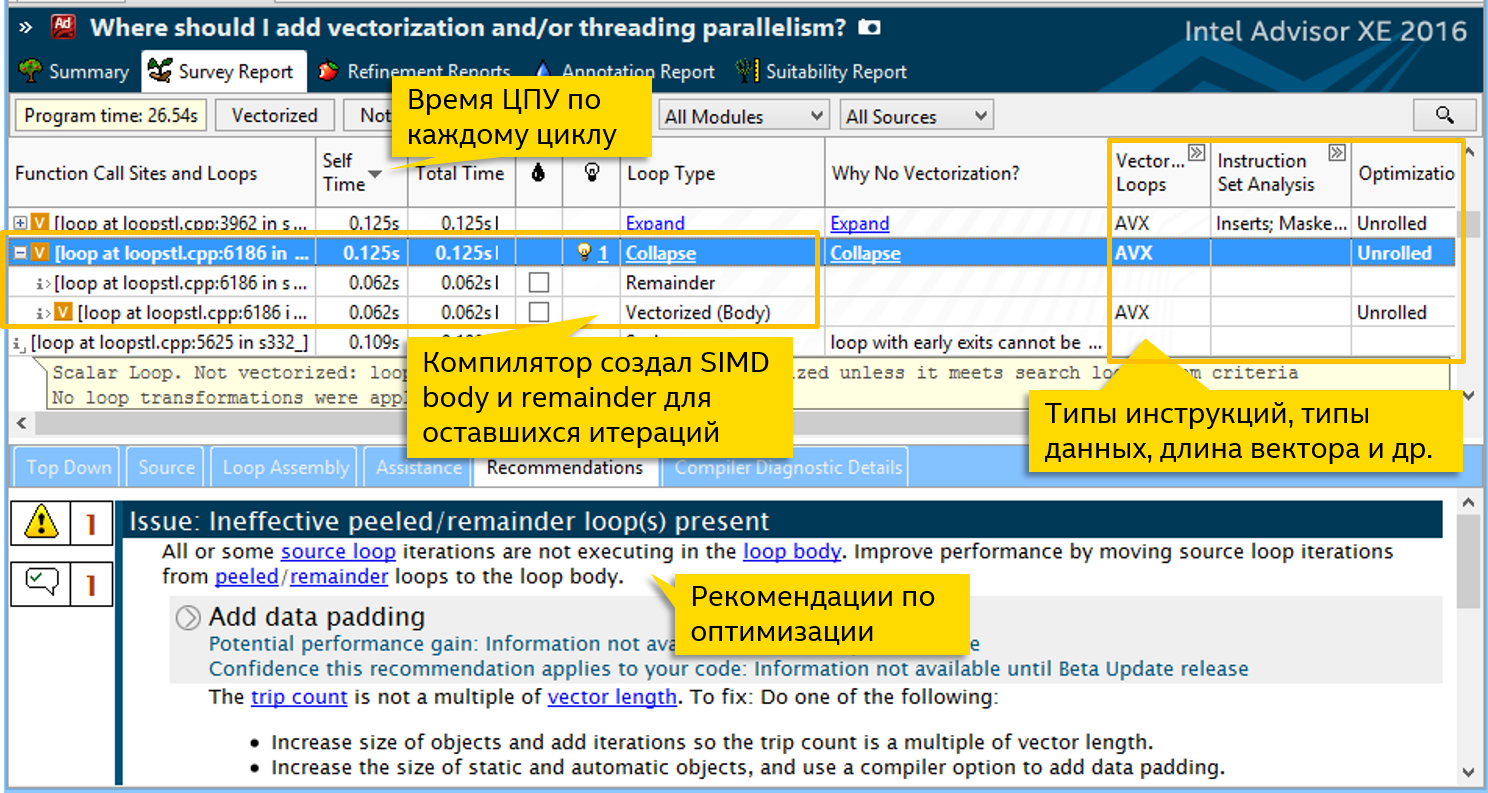
Новый Vectorization Advisor в составе Intel® Advisor XE 2016 Beta для оптимизации кода под SIMD инструкции, т.е. векторизации.
MPI Performance Snapshot для быстрой общей оценки производительности MPI программ.
Бета-версия доступна публично и бесплатно, программа длится до 23 июня, но лицензии будут работать вплоть до 25 сентября 2015 г. Для получения Бета-версии нужно зарегистрироваться здесь.Эта статья посвящена обзору нового функционала, более детально отдельные продукты постараемся осветить в последующих блогах — пишите в комментариях, к чему есть интерес.Intel® Advisor XE традиционно был инструментом прототипирования параллелизма на потоках. В версии 2016 Beta он фактически разделяется на два больших продукта: Threading assistant — всё, что было в Intel Advisor раньше, с несколькими улучшениями.
Vectorization Advisor — совершенно новый инструмент анализа SIMD программ.
Основные возможности Vectorization Advisor: Вся информация о векторизации циклов собрана в одном месте: время ЦПУ, диагностики от компилятора, анализ использованных инструкций и типов данных и т.д. Это позволяет сфокусироваться на важном — оптимизировать самые горячие циклы.
Подсчёт количества итераций (trip counts) и вызовов (call counts) циклов.
Поиск итерационных зависимостей
Анализ шаблона доступа к памяти
Рекомендации по оптимизации, основанные на собранных данных.
 Мы ещё напишем подробнее о Vectorization Advisor в следующих блогах.
Мы ещё напишем подробнее о Vectorization Advisor в следующих блогах.
Оптимизированная библиотека для работы с «большими данными» на разных стадиях: получение данных от источника, предварительная обработка, трансформация, интеллектуальный анализ данных, моделирование, валидация и принятие решений.Интеллектуальный анализ данных (data mining) — вычисление подобия данных, факторизация матриц (SVD, QR, Cholesky), статистические моменты, вариационные и ковариационные матрицы, нахождение одномерных и многомерных выбросов и ассоциативные правила. Методы машинного обучения с учителем и без: линейная регрессия, наивный классификатор Байеса, алгоритмы бустинга (AdaBoost, LogitBoost, BrownBoost), метод опорных векторов, кластеризация методом k-средних, функция правдоподобия и т.д. Поддержка локальных и распределённых источников данных, включая СSV в файлах и в памяти, MySQL, HDFS, и Resilient Distributed Dataset (RDD) объекты из Apache Spark*. Сжатие и распаковка данных — утилиты Intel DAAL предоставляют эффективные реализации ZLIB, LZO, RLE, и BZIP2. Сериализация и десериализация данных для эффективных коммуникаций. Официальное название — Intel® Parallel Studio XE 2016 Beta, Composer Edition. Продукт объединяет в себе компилятор и библиотеки. Компилятор Intel расширяет набор поддерживаемых стандартов: OpenMP* 4.0:
simdlen and safelen для циклов,
array reductions (Fortran),
User-defined reductions (C/C++),
опция collapse (N) для omp simd.
OpenMP* 4.1 TR 3: Non-structured data allocation with omp target [enter | exit ] data
Асинхронный оффлоад с nowait опцией для omp task
Оффлоад с зависимостями с опцией depend для omp task
Модификаторы always и delete для map
С/С++ стандарты: C11: поддержка Unicode strings, C11 anonymous unions, ключевые слова _Alignas, _Alighof, _Static_assert, _Thread_local, _Noreturn, и _Generic.
C++14: generic lambdas, generalized lambda captures, digit separators, [[deprecated]] attribute, дедукция типа возвращаемого значения функции, и инициализация членов.
Fortran компилятор стал поддерживать подмодули (submodules), улучшена рантайм проверка неинициализированных переменных (опция [Q]init), добавлена поддержка IMPURE ELEMENTAL (F2008) и улучшена C Interoperability (F2015).
В новой версии VTune™ Amplifier XE расширен функционал профилировки OpenMP и MPI приложений. Для OpenMP инструмент выдаёт статистику по параллельным регионам и подсвечивает те из них, где есть наибольший потенциал для оптимизации. VTune Amplifier распознаёт основные причины неэффективности OpenMP — дисбаланс нагрузки, накладные расходы, синхронизацию и др. Подробно об OpenMP анализе уже писалось. VTune Amplifier сильно расширил возможности профилировки MPI-приложений, а самое интересное — гибридных, MPI+OpenMP.Т. е. вы можете одновременно анализировать дисбалансы OpenMP и MPI коммуникацию.
VTune Amplifier сильно расширил возможности профилировки MPI-приложений, а самое интересное — гибридных, MPI+OpenMP.Т. е. вы можете одновременно анализировать дисбалансы OpenMP и MPI коммуникацию. В таблице Bottom-up можно группироваться по MPI процессу и OpenMP регионам внутри него, а также по отдельным барьерам (например, у циклов) внутри региона:
В таблице Bottom-up можно группироваться по MPI процессу и OpenMP регионам внутри него, а также по отдельным барьерам (например, у циклов) внутри региона:  Анализ производительности OpenCL программ, выполняющихся на Intel® HD Graphics, становится удобнее с новой «диаграммой архитектуры», где можно наглядно видеть аппаратные блоки GPU и их загрузку — занятость вычислительных ядер и трафик данных:
Анализ производительности OpenCL программ, выполняющихся на Intel® HD Graphics, становится удобнее с новой «диаграммой архитектуры», где можно наглядно видеть аппаратные блоки GPU и их загрузку — занятость вычислительных ядер и трафик данных:  Другие изменения в VTune Amplifier XE: Обновлён анализ General Exploration с оценкой надёжности статистики сэмплирования.
Новая вкладка «Platform» вместо «Tasks and Frames»
Сбор аппаратных событий без драйвера на Linux
Поддержка основного функционала стандарта MPI v3.0.
Появилась поддержка Intel® True Scale Fabric.
Опция -use-app-topology позволяет Hydra подстраивать расстановку MPI процессов, основываясь на ранее собранной статистике и известной топологии кластера.
Опция --fast для mpitune позволяет ускорить автоматическую настройку благодаря использованию результатов предыдущего запуска.
Опция --rank-placement для mpitune оптимизирует настройку MPI под конкретную топологию кластера, основываясь на шаблонах коммуникации.
Новая опция -gtool позволяет удобно запускать инструмент-анализатор для вашего MPI приложения. Например, Vectorization Advisor для анализа векторизации: mpirun -n 4 -gtool «advixe-cl -collect survey:2,3» ./your_app
Другие изменения в VTune Amplifier XE: Обновлён анализ General Exploration с оценкой надёжности статистики сэмплирования.
Новая вкладка «Platform» вместо «Tasks and Frames»
Сбор аппаратных событий без драйвера на Linux
Поддержка основного функционала стандарта MPI v3.0.
Появилась поддержка Intel® True Scale Fabric.
Опция -use-app-topology позволяет Hydra подстраивать расстановку MPI процессов, основываясь на ранее собранной статистике и известной топологии кластера.
Опция --fast для mpitune позволяет ускорить автоматическую настройку благодаря использованию результатов предыдущего запуска.
Опция --rank-placement для mpitune оптимизирует настройку MPI под конкретную топологию кластера, основываясь на шаблонах коммуникации.
Новая опция -gtool позволяет удобно запускать инструмент-анализатор для вашего MPI приложения. Например, Vectorization Advisor для анализа векторизации: mpirun -n 4 -gtool «advixe-cl -collect survey:2,3» ./your_app
Или VTune Amplifier, для анализа производительности отдельных ранков:
mpirun -n 4 -gtool «amplxe-cl -collect hostpots:2,3» ./your_app
Обратите внимание, в примере анализ запускается лишь на ранках 2 и 3 из четырёх запущенных. Т.е. вы можете выборочно профилировать отдельные процессы.
Главным нововведением является MPI Performance Snapshot. Инструмент используется для быстрой верхнеуровневой оценки производительности — как приложение масштабируется, каков баланс загрузки MPI, OpenMP и вычислений. Улучшен анализ гибридных приложений: Intel® Trace Analyzer позволяет выбрать MPI ранки и сгенерировать для них командную строку VTune™ Amplifier с помощью новой опции
Улучшен анализ гибридных приложений: Intel® Trace Analyzer позволяет выбрать MPI ранки и сгенерировать для них командную строку VTune™ Amplifier с помощью новой опции  Intel® Parallel Studio 2016 Beta несёт серьёзный набор нового функционала по целому ряду направлений: Векторизация, оптимизация использования SIMD инструкций (Intel Advisor XE)
Анализ больших данных (Intel® DAAL)
Единый анализ гибридных HPC приложений на MPI и OpenMP (Intel Trace Analyzer and Collector, VTune Amplifier XE)
GPU анализ (VTune Amplifier XE)
Новые стандарты (Intel® Compiler, Intel® MPI)
Часть из этого есть развитие традиционного набора для HPC разработчика, но многое расширяется и на другие сферы, такие как мультимедиа и анализ данных.Это был краткий обзор, в следующих постах напишем подробнее — дайте знать, что интересно в первую очередь.Зарегистрироваться на Intel® Parallel Studio XE 2016 Beta.
Intel® Parallel Studio 2016 Beta несёт серьёзный набор нового функционала по целому ряду направлений: Векторизация, оптимизация использования SIMD инструкций (Intel Advisor XE)
Анализ больших данных (Intel® DAAL)
Единый анализ гибридных HPC приложений на MPI и OpenMP (Intel Trace Analyzer and Collector, VTune Amplifier XE)
GPU анализ (VTune Amplifier XE)
Новые стандарты (Intel® Compiler, Intel® MPI)
Часть из этого есть развитие традиционного набора для HPC разработчика, но многое расширяется и на другие сферы, такие как мультимедиа и анализ данных.Это был краткий обзор, в следующих постах напишем подробнее — дайте знать, что интересно в первую очередь.Зарегистрироваться на Intel® Parallel Studio XE 2016 Beta.
