Intel Nervana NNP-T и NNP-I — специализированные чипы для AI

Осознавая важность работ в области искусственного разума, Intel делает еще один шаг в этом направлении. Месяц назад на конференции Hot Chips 2019 компания официально представила два специализированных чипа, предназначенных для тренировки и инференса нейронных сетей. Чипы получили наименования соответственно Intel Nervana NNP-T (Neural Network Processor) и Intel Nervana NNP-I. Под катом вы найдете характеристики и схемы новых продуктов.
Intel Nervana NNP-T (Spring Crest)
Время тренировки нейронной сети, наряду с энергоэффективностью — один из ключевых параметров AI системы, определяющий область ее применения. Вычислительная мощность, используемая в крупнейших моделях и тренировочных наборах удваивается каждые три месяца. При этом в нейронных сетях используется ограниченный набор вычислений, преимущественно свертки и перемножение матриц, что открывает большой простор для оптимизаций. В идеале нужное нам устройство должно быть сбалансированным с точки зрения потребления, коммуникаций, вычислительной мощности и масштабируемости.
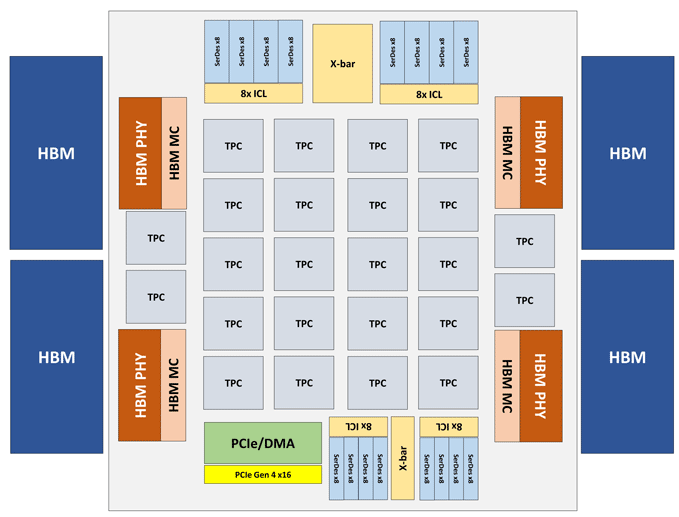
Модуль Intel Nervana NNP-T выполнен в виде карты PCIe 4.0×16 либо OAM. Основной вычислительный элемент NNP-T — Tensor Processing Cluster (TPC) в количестве 24 штук, обеспечивающий производительность до 119 TOPS. Через 4 порта HBM подключено суммарно 32 Тб памяти HBM2–2400. На борту также имеется блок сериализации/десериализации на 64 линии общей пропускной способностью до 3.5 Тб/с, интерфейсы SPI, I2C, GPIO. Объем распределенной памяти на чипе составляет 60 Мб (по 2.5 Мб на ТРС).
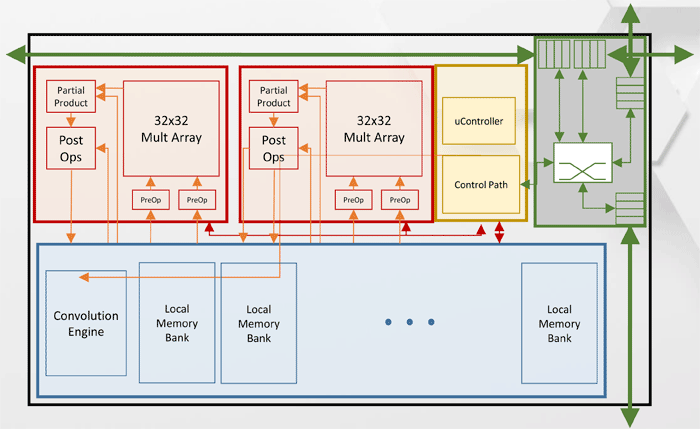
Архитектура Tensor Processing Cluster (TPC)
Прочие эксплуатационные характеристики Intel Nervana NNP-T.
Как видно из схемы, каждый TPC имеет два ядра перемножения матриц 32×32 с поддержкой BFloat16. Прочие операции выполняются в формате BFloat16, либо FP32. Всего на одном хосте может быть установлено до 8 карт, максимальная масштабируемость — до 1024 нод.
Intel Nervana NNP-I (Spring Hill)
При проектировании Intel Nervana NNP-I преследовалась цель обеспечить максимальную энергоэффективность при инференсе в масштабах больших дата центров — порядка 5 TOP/Вт.
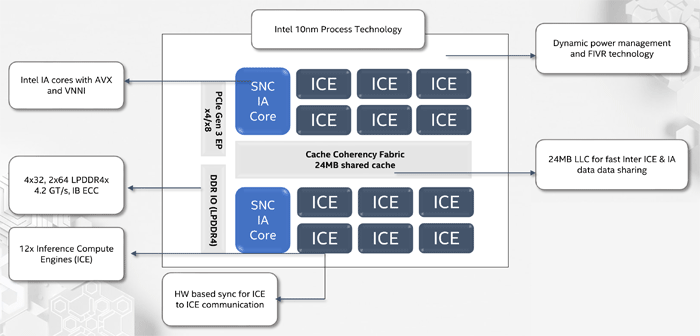
NNP-I представляет собой SoC, выполненный по 10-нм техпроцессу и включающий в себя два стандартных ядра х86 с поддержкой AVX и VNNI, а также 12 специализированных ядер Inference Compute Engine (ICE). Максимальная производительность составляет 92 ТОРS, TDP — 50 Вт. Объем внутренней памяти равен 75 Мб. Конструктивно устройство выполнено в виде карты расширения М.2.
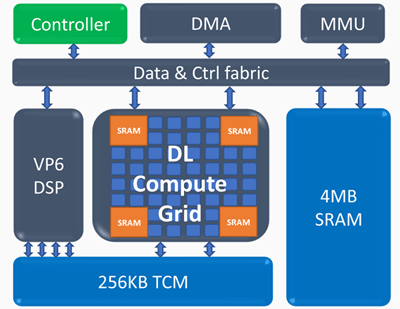
Архитектура Inference Compute Engine (ICE)
Основные элементы Inference Compute Engine:
Вычислительная решетка Deep Learning (Deep Learning compute grid)
- 4k MAC (int8) за цикл
- масштабируемая поддержка FP16, INT8, INT 4/2/1
- большой объем встроенной памяти
- нелинейные операции и пулинг
Программируемый векторный процессор (Programmable vector processor)
- высокая производительность — 5 VLIW 512 b
- расширенная поддержка NN — FP16/16b/8b
Получены следующие показатели производительности Intel Nervana NNP-I: на 50-слойной сети ResNet достигнута скорость 3600 инференсов в секунду при энергопотреблении 10 Вт, то есть энергоэффективность составляет 360 изображений в секунду в пересчете на Ватт.
