Инфраструктура А/Б-экспериментов в большом Поиске. Доклад Яндекса
А/Б-тестирование — мощный способ проверки интерфейсов перед публикацией на всю аудиторию. Я решил рассказать, из чего этот инструмент состоит, какие у него особенности логирования, как составляются метрики и в чем суть экспериментов во фронтенде. Поговорим об их устройстве и сервисах для решения ежедневных аналитических задач. Обсудим несколько путей развития для разработчика, который вроде бы всё уже умеет, но хочет больше.
— Меня зовут Лёша, я работаю в Поиске и разрабатываю самый главный, наверное, продукт Яндекса — поисковую выдачу.
Все вы так или иначе когда-либо пользовались каким-либо из поисков. Пару-тройку терминов. Выдача состоит из различных блоков. Есть простые органические документы, которые мы собираем со всего интернета и каким-то образом умеем представлять, и есть специальные блоки, которые мы отображаем как специальную разметку. Про их содержимое мы знаем очень много данных. Эти блоки называются колдунщиками. Терминология специфическая, принятая в Яндексе и не только.
Я хочу вам сегодня рассказать, как мы проводим эксперименты, какие в этой сфере нашей деятельности есть нюансы, инструменты, и какие замечательные изобретения есть в наших загашниках.
Для чего нужно А/Б-тестирование
С чего бы начать? Для чего Яндексу нужны А/Б-эксперименты?
Хотелось бы начать с лирики. Я не так давно со своей дочерью посмотрел один коротенький научный фильм »4,5 млрд лет за 40 минут. История Земли». Там сплошь и рядом одни А/Б-эксперименты. В том числе эти. Один из самых интересных и забавных я попытался вынести на этот слайд. Это когда у эволюции есть несколько ветвей. Например, есть два семейства: сумчатые и плацентарные. И как мы сейчас видим, плацентарные почему-то побеждают. Побеждают вот почему.

Это уже мозг человека домыслил. Во внутриутробном и дальнейшем развитии у сумчатых черепная коробка быстро твердеет и не дает мозгу развиваться. А у плацентарных все прогрессирует, все мягкое до тех пор, пока мозг не станет складками с бороздами, не нарастит поверхность, сделав неокортекс крутым. В итоге плацентарные победят в эволюции. Какой в этом смысл? У природы эволюция, и ее движущие силы — мутация и естественный отбор, как вы наверняка знаете.

В компании есть аналогия А/Б-экспериментов природы: любой бизнес хочет развиваться стабильно и вкладывает определенные усилия, используя А/Б-эксперименты как способ что-то мутировать, что-то изменить. Всю математическую мощь аналитики компания использует, чтобы отбирать эти самые эксперименты.
А/Б-эксперименты и вся эволюция нацелены на то, чтобы достигать цели, уметь себя наблюдать со стороны, сравнивать с конкурентами, искать определенные новые ниши, гипотезы. Для разработчиков в целом, особенно для фронтендеров, важно проверять новые функциональности на небольшой доле в продакшене.

Короткая история выглядит примерно так. Можно сказать, что 2010 год, когда наши продакт-менеджеры делали первые А/Б-эксперименты, — это такой постпериод после Большого взрыва. Только-только начали зарождаться определенные звездные скопления, понимание того, как нужно проводить А/Б-эксперименты, на что смотреть, как логировать. Нарабатывались первые шишки, первые ошибки.
В течение этого периода с 2010 по 2019 год мы достигли значимых результатов. Сегодня все эти термины касательно логов, экспериментов, метрик, целей, достижений и так далее являются уже базовыми для нас, в частности для вновь приходящих молодых разработчиков. Это наш сленг, наша внутренняя яндексовая ментальность.
Большой Поиск
Переходим непосредственно к мясу, о большом Поиске. Большой Поиск в своей структуре выглядит примерно так. 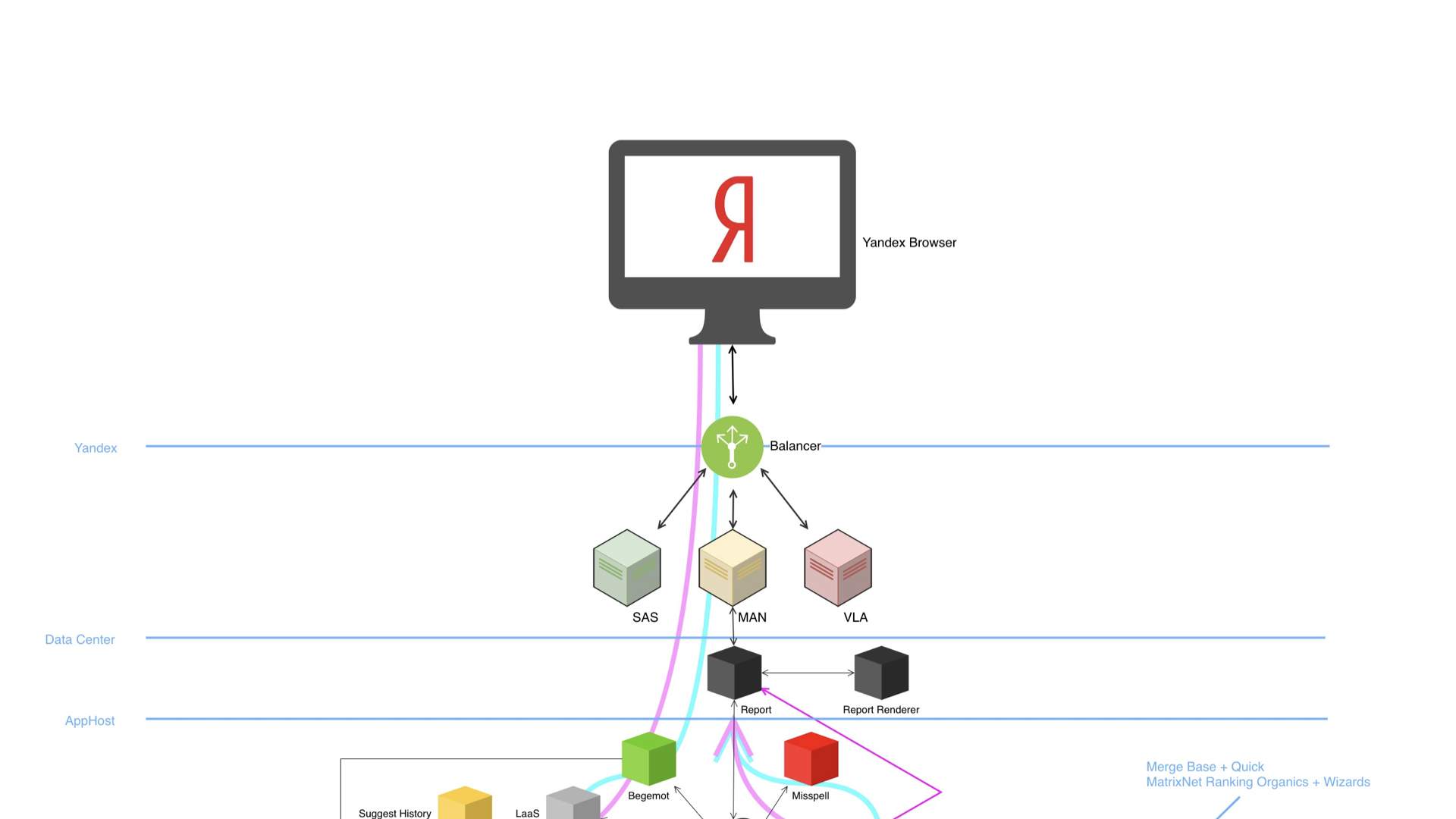
У нас есть браузер, балансер, много дата-центров и огромная богатая инфраструктура под капотом. Схема демонстрирует, что устройство сложное, здесь много компонент. И что самое удивительное, все эти компоненты умеют проводить А/Б-эксперименты и, естественно, пишут и анализируют логи.
Логи

Логи пишут многие-многие компоненты. Нам, конечно, интереснее поговорить в контексте фронтенда. Фронтенд логирует два больших значимых среза. Это сугубо технические логи, связанные с непосредственным измерением каких-то времен, производительности на клиентских устройствах. Real user measurement, RUM-метрики. Здесь и времена до первого байта, до первой отрисовки, до загрузки всего DOM-контента и до интерактивности.
Наряду с этим есть логи, которые пишет и серверная, и клиентская верстка. Это продуктовые логи. В наших реалиях даже тут есть свой термин «баобаб». Почему баобаб? Потому что дерево: дерево компонент, дерево фич, в котором одни из главных логов — логи показов, кликов и прочих технических событий, которые мы регистрируем для последующего анализа.
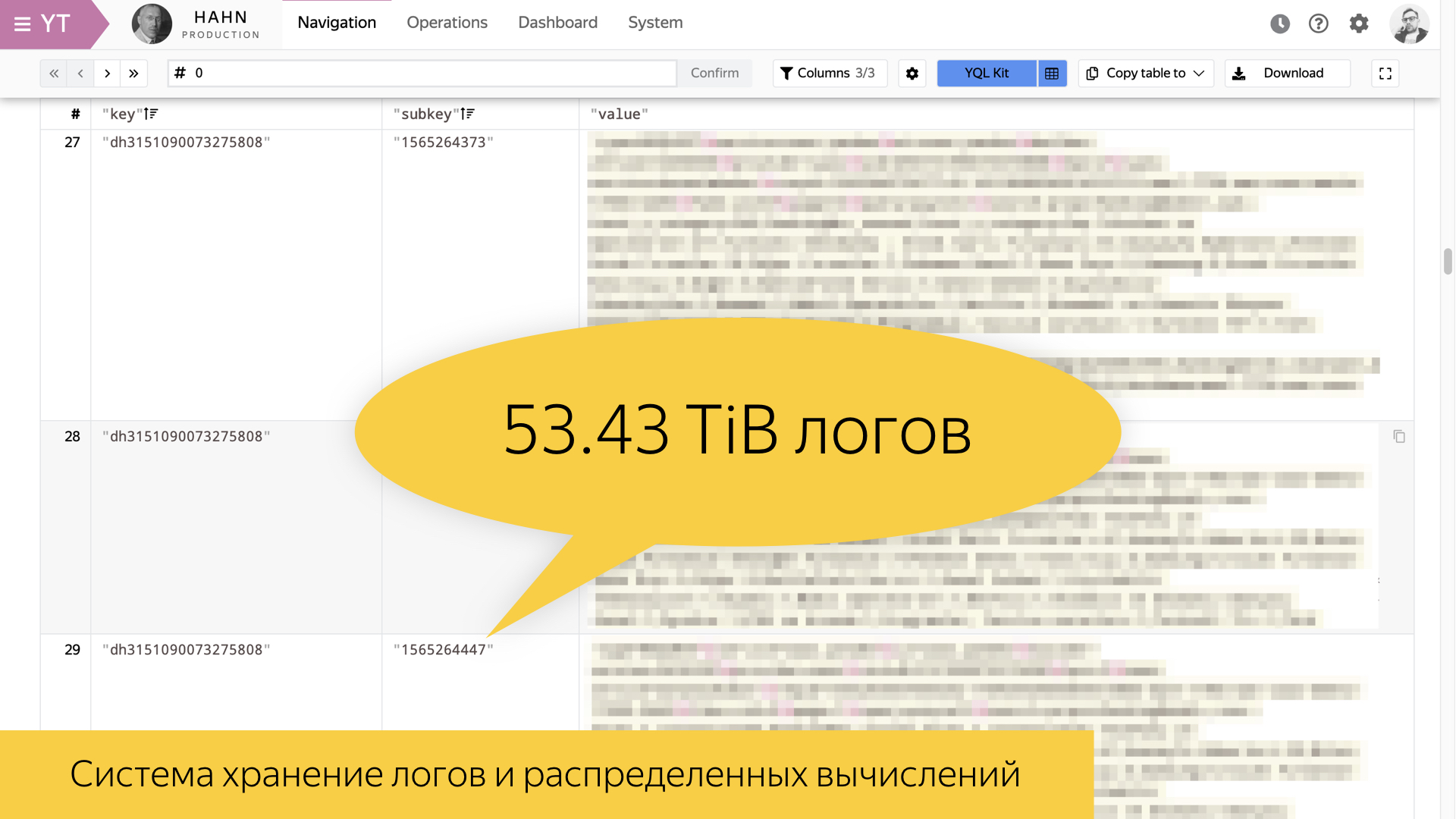
На этом слайде представлен инструмент для хранения логов внутри Яндекса и для распределенных вычислений. Он у нас называется Yandex Tables, YT. Во всем разработанном в Яндексе есть буква Y. Я постарался вспомнить аналог этого инструмента во внешнем мире. По-моему, у Facebook MapReduce-инструмент называется Hadoop. Он позволяет реализовать хранение и вычисление.
На слайде представлена статистика за 8 августа этого года. Один из самых ценных логов поиска, пользовательские сессии, составляет за день в своем виде 54 терабайта. Это огромное количество информации, которое в сыром виде никак не перелопатить. Поэтому надо уметь строить какие-то высокоуровневые истории.
Для работы с логами, в частности, все наши особенно опытные разработчики обязательно овладевают каким-либо аналитическим инструментом.
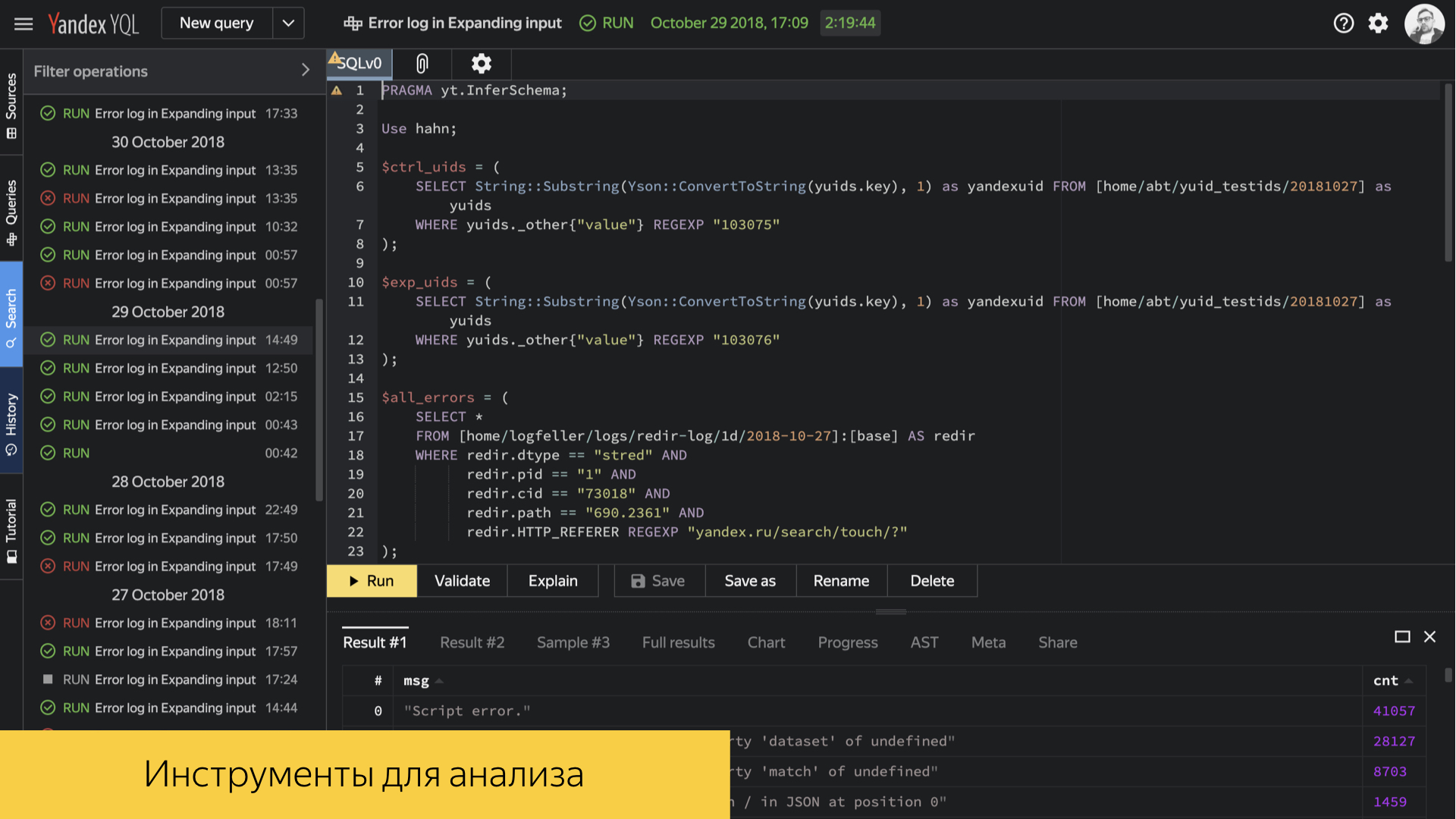
Внутри Яндекса есть инструмент YQL. Это SQL-подобный язык запросов и вычислений над нашими логами, который позволяет строить всевозможные среды, делать именно низкоуровневую аналитику, заглядывать прямо в конкретные числа, средние персентили, и строить отчеты. Инструмент достаточно мощный, у него огромный развесистый API и много возможностей. На его базе выстроено много инфраструктурных процессов.
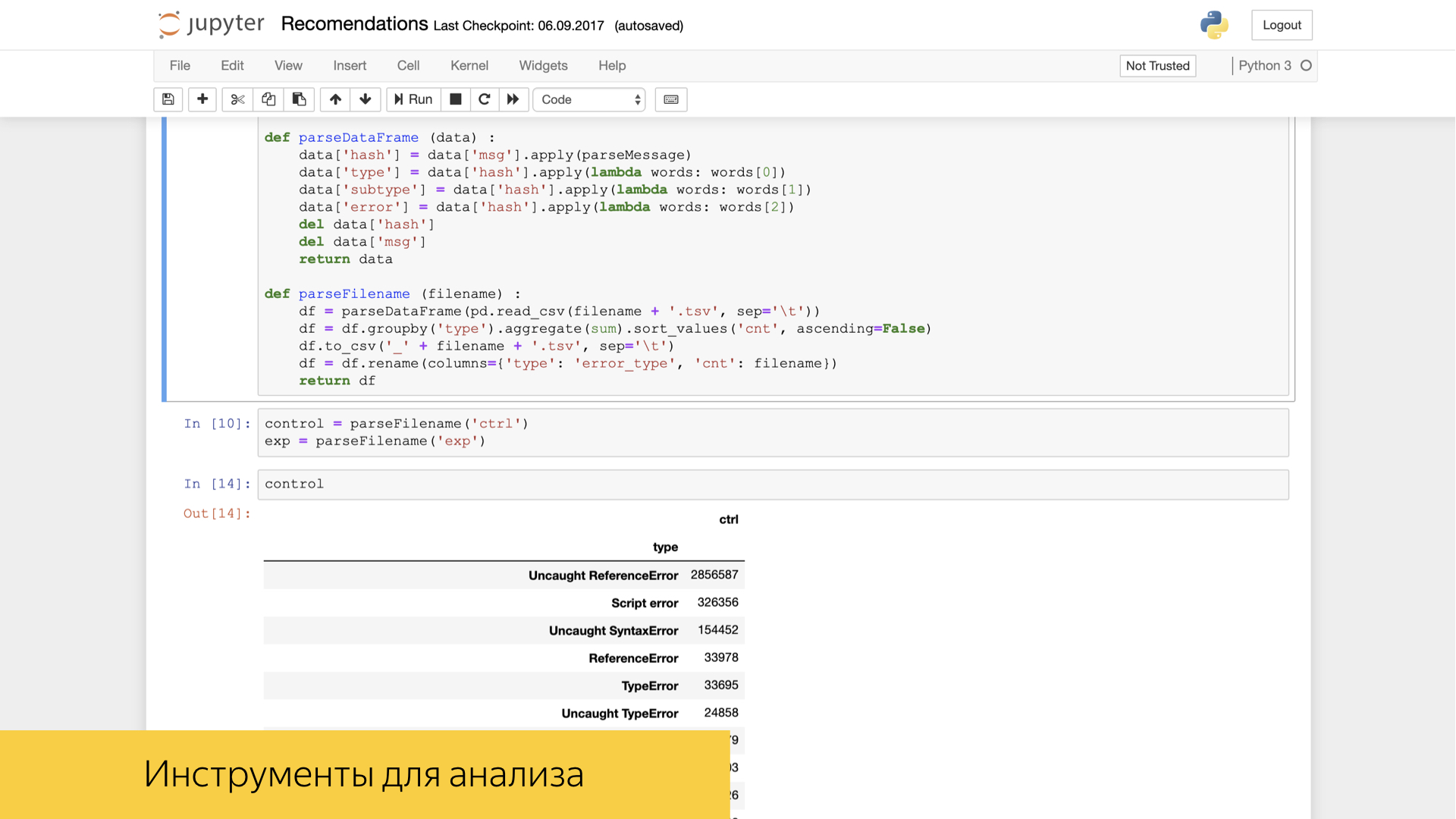
Кроме того, среди наших фронтенд-разработчиков и, в частности, аналитиков пользуется хорошим спросом и популярностью инструмент Jupyter. В нем можно уже с мощью инструментов Numpy и прочих известных вам, например Pandas, делать какие-то преобразования и высокоуровневую аналитику над нашими логами.
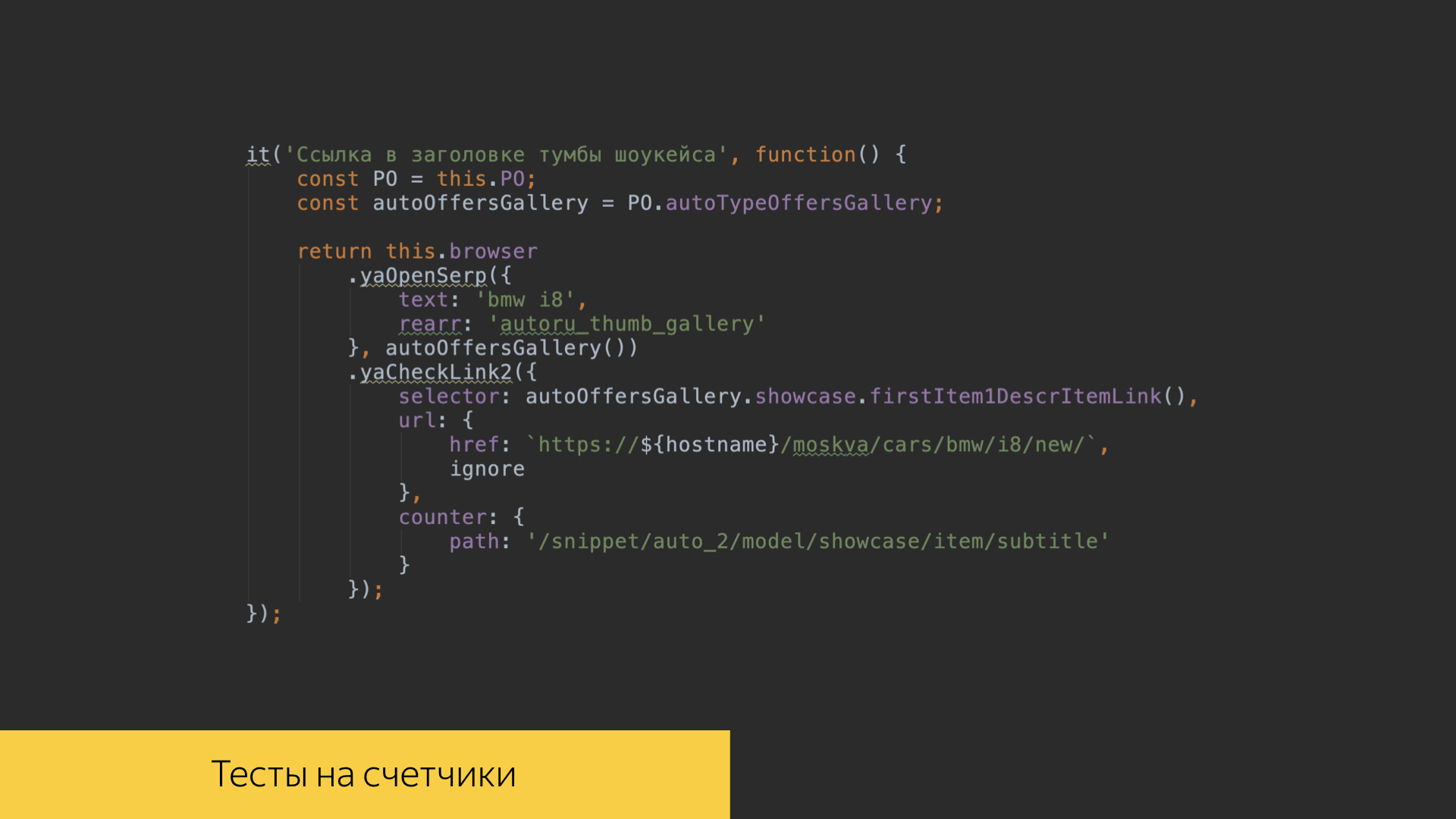
Мы очень дорожим логами, буквально боремся за каждую запись. Для этого в репозитории нашего поискового проекта в коде фронтенда есть тесты, которые позволяют проверять, что все события правильно записываются. Мы пишем тесты на каждую нашу фичу, можем проверить определенный сценарий, прокликать определенные ссылки, кнопочки, проскроллить определенные галереи в нашем интерфейсе и посмотреть, что записалось ровно то количество логов ровно с такими значениями, которые мы ожидаем, которые мы зафиксировали, для которых сделали какие-то эталоны. И потом в эти эталонные значения ассёртимся.
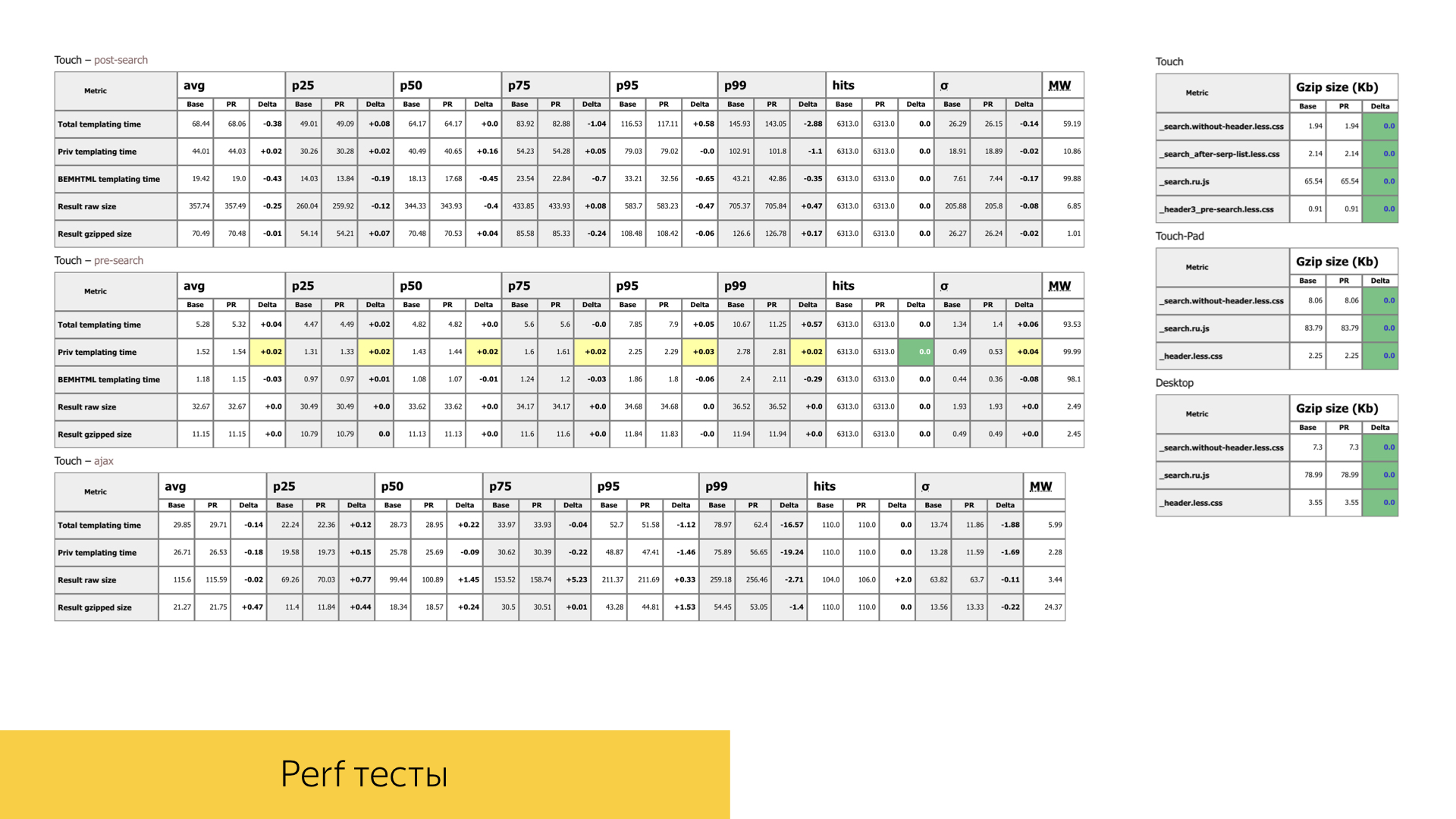
Также мы уделяем огромное внимание производительности наших интерфейсов. Во всяком пул-реквесте с новой функциональностью или рефакторингом уже имеющейся функциональности мы огромное внимание уделяем временам, объемам, количеству вызовов тех или иных функций. На слайде — один из отчетов совершенно случайного пул-реквеста. У нас две стадии поиска, одна разновидность аяксовая: сначала мы загружаем шапку на странице с поисковой стрелкой, а когда отработают все поисковые источники, мы еще можем померить именно времена шаблонизации и все производительности уже при рендеринге основной части выдачи.
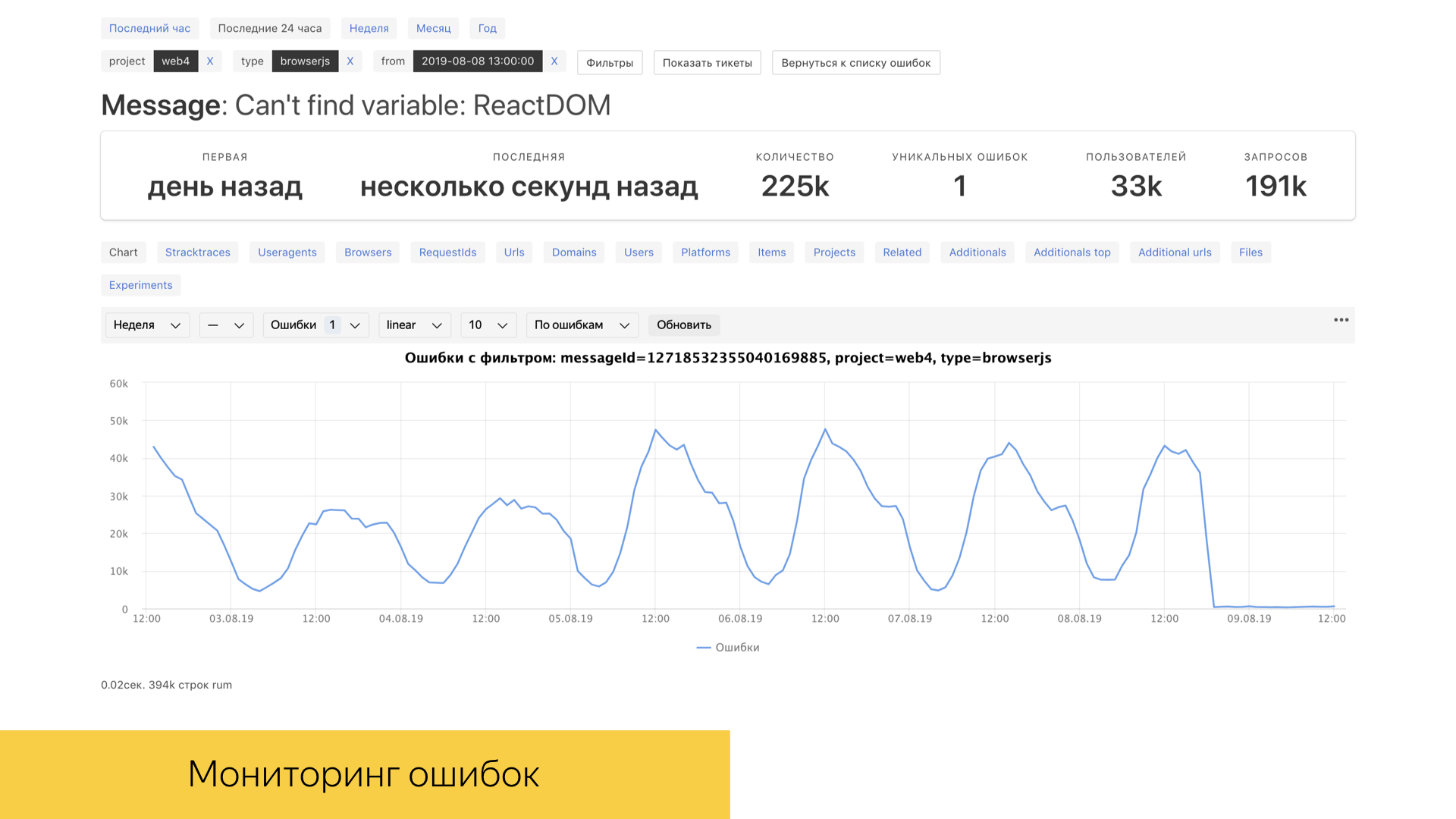
Для нас, как, конечно, и для любого другого субъекта в IT, очень важны ошибки в продакшене, в специальных окружениях. У нас есть инструмент под названием error booster, который позволяет в реальном времени с достаточно хорошей временной рамкой смотреть на реальные ошибки в продакшене. Под капотом у этого инструмента используется база данных ClickHouse, запросы в которой достаточно быстро отрабатываются, и сама база рассчитана на аналитическую работу. Бо́льшая часть взаимодействий реализована именно с ClickHouse.
Поговорили о логах, об их разновидностях. Их очень много. Чтобы двигать эксперименты и что-либо анализировать, принимать на чем-то решения, у нас есть большое количество метрик. Это некоторые свертки над большими объемами сырых данных.
Метрики
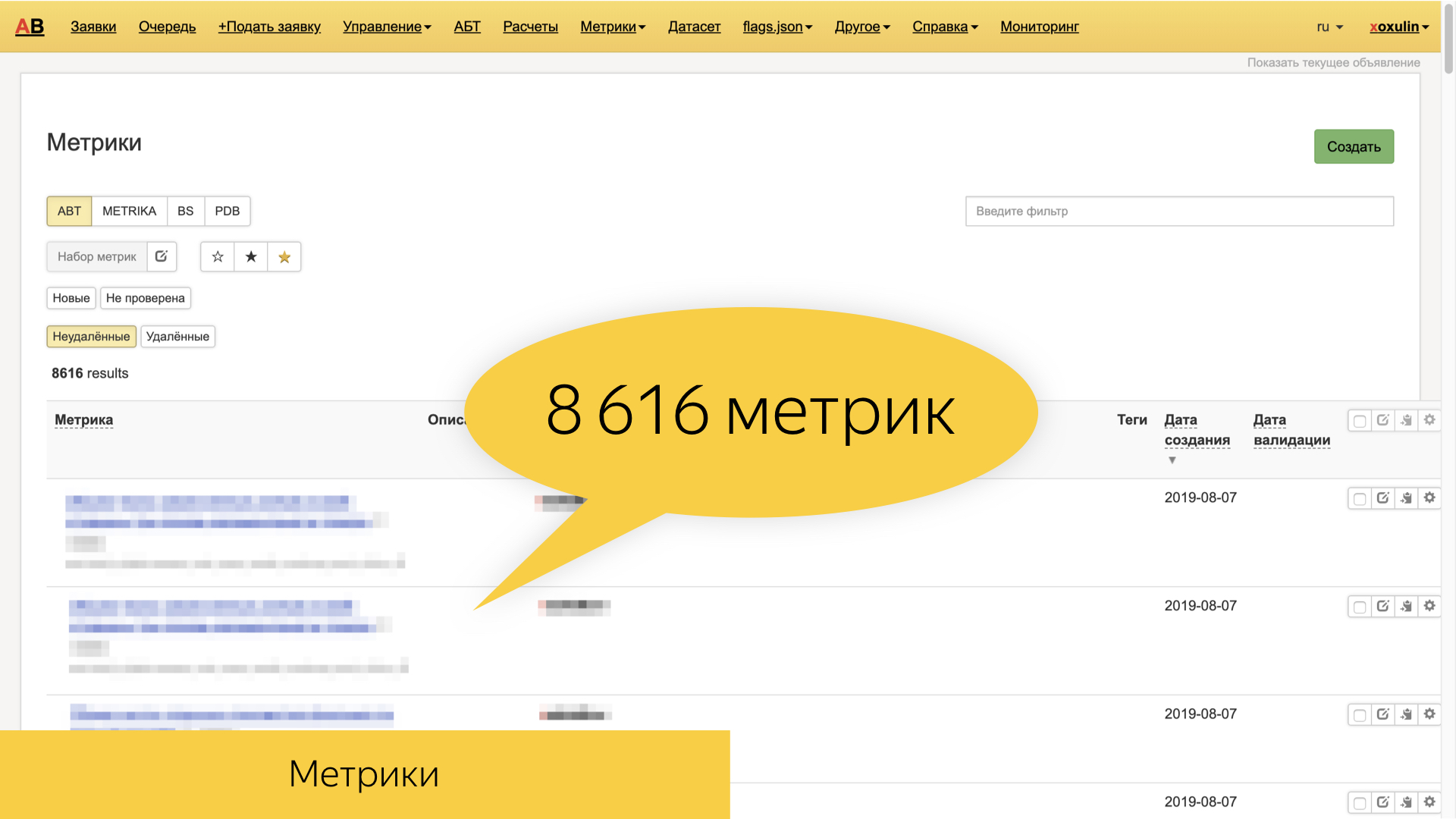
В Яндексе сейчас порядка 8,6 тыс. всевозможных метрик, которые базируются на тех самых сырых логах — и более высокоуровневых, таких как поисковые и пользовательские сессии. Они очень разнообразные, и зачастую именно фича-ориентированные. То есть это метрики, специфические определенному колдунщику, определенному блоку, срезу запросов, типу документов, который мы отображаем.
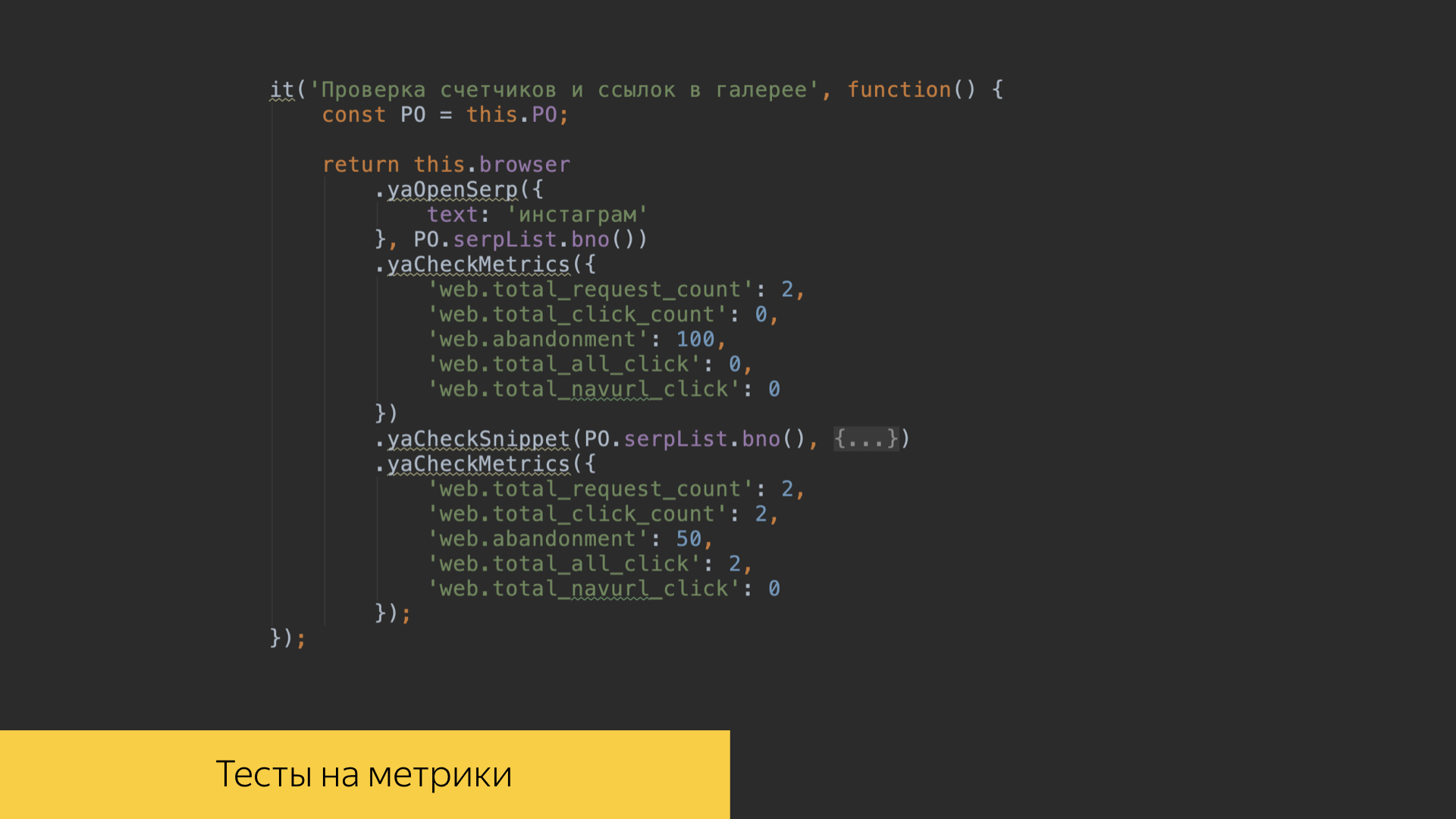
В наших тестовых сценариях есть возможность проверять значение метрик в наших же интерфейсах. Когда мы проиграли определенные сценарии, мы можем посмотреть результаты вычислений над логами и заассёртить определенные значения метрик.
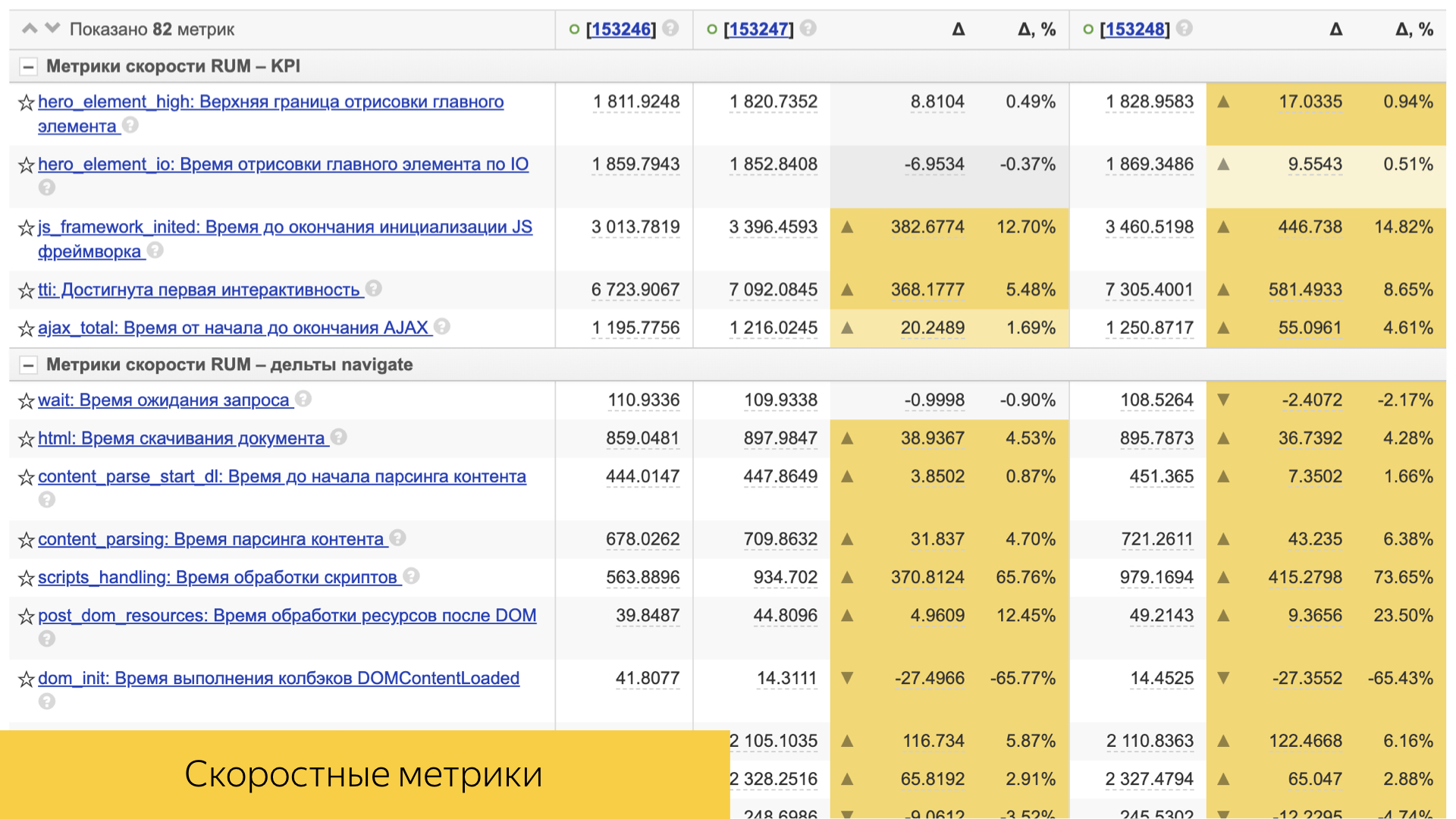
Немаловажную роль играют и скоростные метрики. Все они достаточно просто устроены. Это обычно либо какая-то персентиль, либо средняя величина и ее отклонение и статистическая значимость.
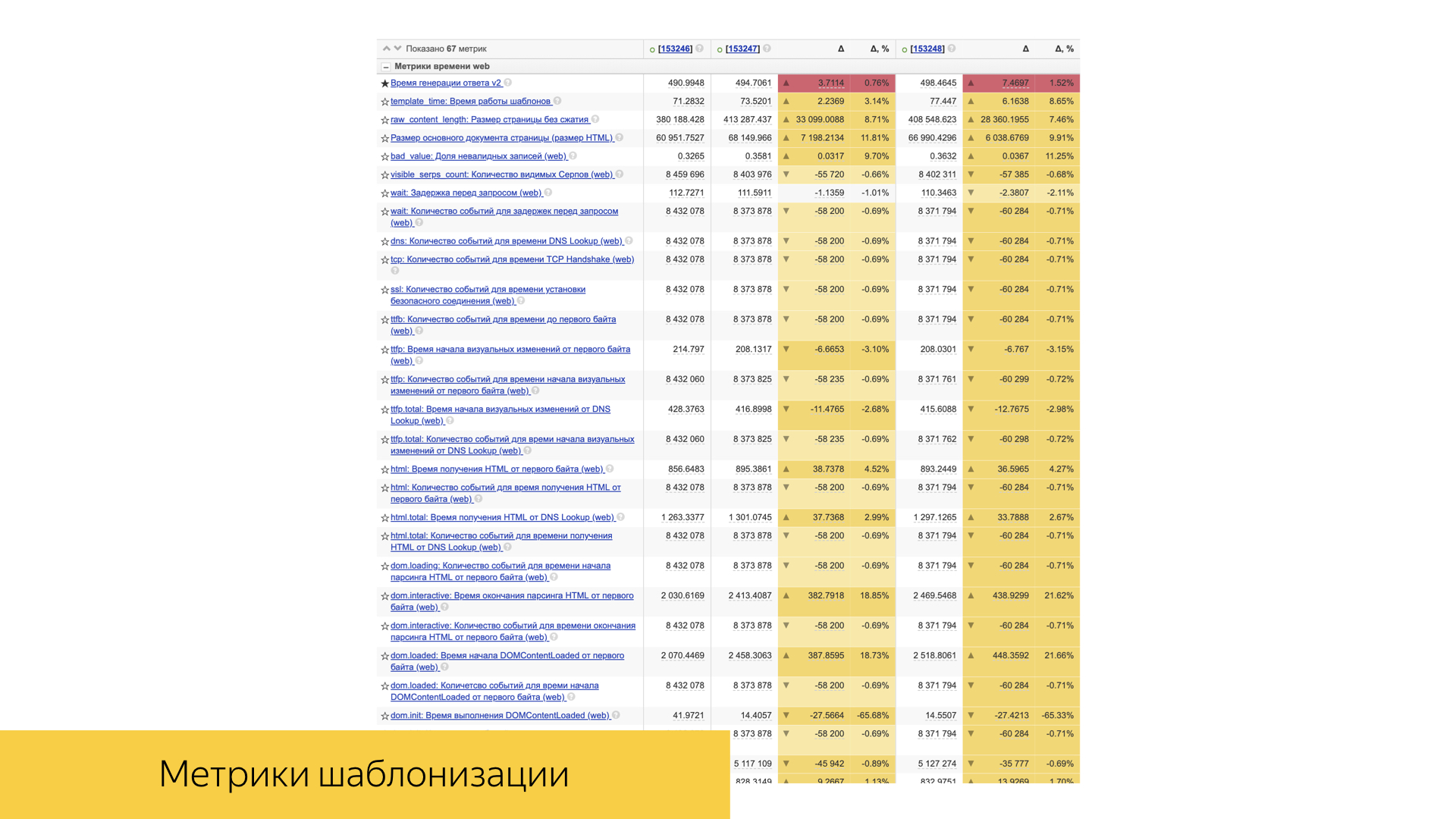
Их достаточно много, они учитывают и время шаблонизации, и время доставки контента на устройство пользователя.
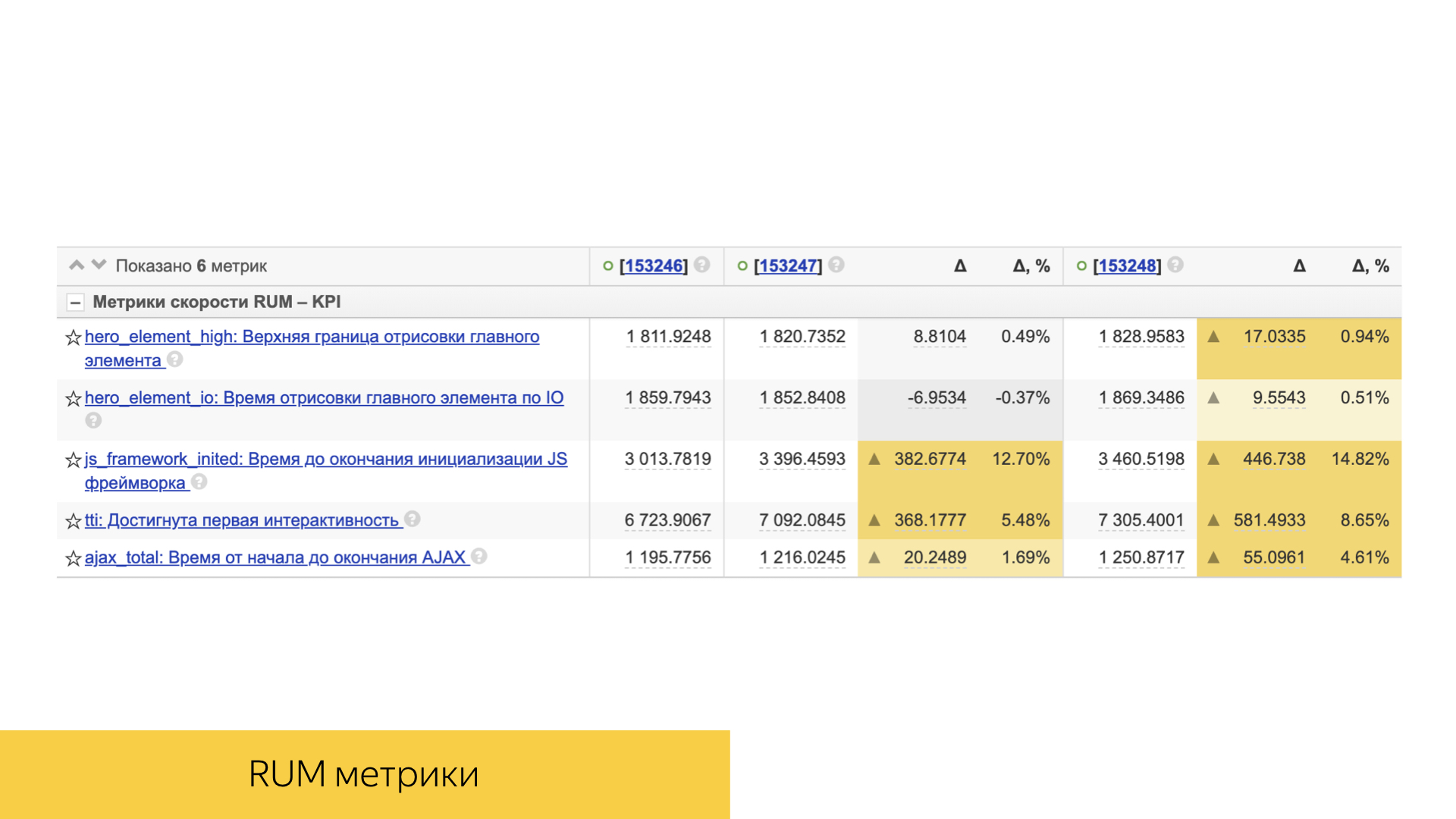
Учитывается и непосредственно клиентская производительность: время отрисовки, время интерактивности и другие.
Эксперименты

Как же все-таки мы проводим эксперименты? Например, есть два пользователя, которые вдруг решили воспользоваться поиском Яндекса. Договорились друг с другом — идем сегодня, например, в Старбакс, и ищут его при помощи нашего поиска. Их запросы, попадая в инфраструктуру наших поисковых источников, помечаются определенными маркерами. По маркерам эти пользователи попадают в различные корзины экспериментов. В каждой из корзин определенный набор флагов, которые активируют эксперименты в каждом из поисковых источников. Например, эти двое пользователей зашли на поисковую выдачу и воспользовались поисковыми подсказками. Первый вводит «Старбакс», видит какие-то пословные подсказки в виде слов. Когда он попадает, в конце концов, на поиск, то видит блок про эту организацию, говорит — да, я нашел, иду туда. А второй пользователь обнаруживает навигационную подсказку уже в интерфейсе поисковых подсказок, быстро переходит на организацию и получает ответ быстрее.
За все это многообразие изменений, разниц в интерфейсе, в определенной функциональности, отвечает инструмент БЭМ. Это не просто фреймворк, а целая методология декларации визуальных компонент, их модификаций. Даже здесь в фоне представлены те самые ДНК-хромосомы, которые будто мутируются через bem. По сути, bem — это ДНК Яндекса, ДНК экспериментов именно во фронтенде.

В методологии есть несколько реализаций. Одна из них — на уже устоявшемся стеке i-bem, который где-то под капотом связан с jQuery. Это уже достаточно зрелая технология. На таком стеке мы умеем решать очень много задач. Сегодня получает большой буст и развитие технология bem-react, которая реализована уже на фреймворке React и языке TypeScript. Все перечисленные инструменты позволяют строить эксперименты и проповедуют главную идею — возможность декларировать как визуальные компоненты, так и их модификации. У нас в репозитории есть целый отдельный уровень с декларациями тех самых экспериментов. Но примерно в 2015-м осознали, что размазывать наши экспериментальные флаги по всему коду фронтенда экономически нерентабельно. Дело в том, что до реального продакшена доезжают единицы экспериментов, а все, что не используется, очень тяжело потом выпиливать из кода. Поэтому мы их выселили на отдельный уровень определения. И здесь снова спасибо bem-методологии, которая дала нам возможность использовать уровни переопределения. На них мы наши эксперименты и декларируем.

Это один из отчетов проведенных экспериментов. Две колонки: контроль и эксперимент. Перед вам даже не всё, что есть в отчете. Почему он такой длинный? В первую очередь, вы видели, какое у нас количество метрик — 8,6 тыс.

Но основную роль играют на самом деле только те метрики, которые различаются. И мы умеем проводить наши эксперименты одновременно, то есть на одном пользователе у нас одномоментно может быть порядка 20 экспериментов. Они друг с другом никак не конфликтуют и при этом во всех наших экспериментах прокрашиваются только свои сугубо продуктовые метрики, не влияя друг на друга. Сейчас в продакшене порядка 800 экспериментов: не только поисковые, но и от очень многих сервисов. Инструмент называется АБ, что неудивительно. Сервисы заводят в нем эксперименты, декларируют определенные выборки и по ним потом смотрят различия между метриками, которые через какой-то период начинают отличаться в эксперименте и контроле.
Смежные роли разработчика
Как следствие такого многообразия в работе фронтенд-разработчиков, среди них есть даже роли. Есть эксперты по экспериментам, и за это мы официально в рамках внутренней сети Яндекса даем ачивки, люди реально сдают экзамены. Они анализируют эксперименты, валидируют свои результаты об знатоков и получают паспорт, что «Я аналитик, я умею анализировать эксперименты». И в целом вся работа с экспериментами, с нашими метриками, ориентирована в первую очередь на улучшение самого продукта. Я один из представителей, я очень мотивирован разрабатывать именно продукт, а не только код и не технологии. И меня сильно драйвит, когда я прихожу в команду и делаю продукт.

Что в сухом остатке? У нас есть большое количество логов, ежедневно пишущихся в наши системы хранения. Есть и большое количество метрик, которые мы вычисляем, проводим над ними эксперименты. Очень большая инфраструктура. Топовый современный инструмент, позволяющий реализовывать огромное количество инструментов, это пакет bem-react. Огромное внимание уделяем показателям скорости и качества, стабильности продукта. И в целом растим в наших разработчиках всё новые и новые роли, смежные основной специальности — фронтенду. У меня всё. Спасибо за внимание.
