Infrastructure as code: первое знакомство
У нас в компании идёт процесс онбординга SRE-команды. Я зашёл во всю эту историю со стороны разработки. В процессе у меня появились мысли и инсайты, которыми я хочу поделиться с другими разработчиками. В этой статье-размышлении я говорю о том, что происходит, как происходит, и как всем дальше с этим жить.
Продолжение серии статей, написанных по мотивам выступлений на нашем внутреннем мероприятии DevForum:1. Кот Шрёдингера без коробки: проблема консенсуса в распределённых системах.
2. Infrastructure as code. (You are here)
3. Генерация Typescript контрактов по c# моделям. (In progress…)
4. Введение в алгоритм консенсуса Raft. (In progress…)
…
Мы решили сделать команду SRE, воплотив идеи google sre. Набрали программистов из своих же разработчиков и отправили их обучаться на несколько месяцев.
Перед командой стояли следующие учебные задачи:
- Описать нашу инфраструктуру, которая по большей части в Microsoft Azure в виде кода (Terraform и все, что около).
- Научить разработчиков работе с инфраструктурой.
- Подготовить разработчиков к дежурствам.
Вводим понятие Infrastructure as code
В обычной модели мира (классическом администрировании) знания об инфраструктуре находятся в двух местах:
- Либо в виде знаний в головах экспертов.

- Либо эти сведения находятся на каких-то машинках, часть из которых знают эксперты. Но не факт, что человек со стороны (в случае, если вся наша команда внезапно умрёт) сможет разобраться, что и как работает. На машине может быть много сведений: аксессы, кронджобы, подмаученный (см. disk mounting) диск и просто бесконечный список того, что может происходить. По ней сложно понять, что в реальности происходит.

В обоих случаях мы оказываемся в ловушке, становясь зависимыми:
- либо от человека, который смертный, подверженный болезням, влюблённостям, перепадам настроения и просто банальным увольнениям;
- либо от физически работающей машины, которая тоже падает, воруется, преподносит неожиданности и неудобства.
Само собой напрашивается решение, что в идеале всё надо перевести в человекочитаемый, поддерживаемый, качественно написанный код.
Таким образом инфраструктура как код (Incfastructure as Code — IaC) — это описание всей имеющейся инфраструктуры в виде кода, а также сопутствующие средства по работе с ним и воплощению из него же реальной инфраструктуры.
Люди — не машины. Они не могут запомнить всё. Реакция у человека и машины разная. Всё автоматизированное потенциально работает быстрее, чем всё, что делает человек. Самое главное — это один источник правды (single source of truth).
Мы много и долго искали их на кадровом рынке за пределами нашей компании. Но вынуждены признать, что не нашли ни одного под наши запросы. Пришлось пошерстить среди своих.
Проблемы Infrastructure as code
Теперь давайте посмотрим примеры того, как инфраструктура может быть зашита в код. Код хорошо написан, качественно, с комментами и отступами.
Пример кода из Terraforma. 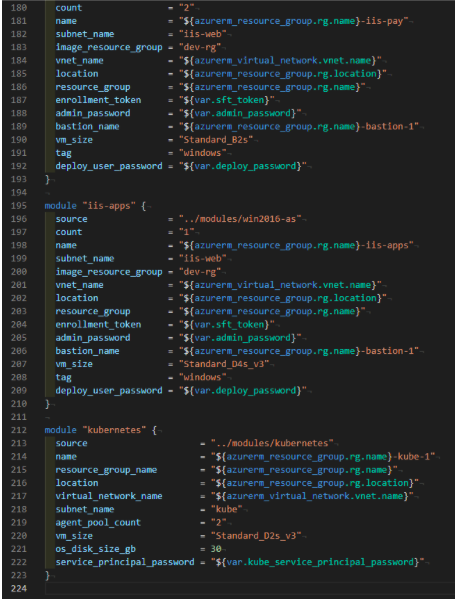
Пример кода из Ansible.
Господа, но если бы всё было так просто! Мы же с вами в реальном мире, а он всегда готов удивить вас, преподнести сюрпризы, проблемы. Не обходится без них и здесь.
1. Первая проблема состоит в том, что в большинстве случаев IaC — это какой-то dsl.
А DSL, в свою очередь, — это описание структуры. Точнее того, что у тебя должно быть: Json, Yaml, модификации от каких-то крупных компаний, которые придумали свой dsl (в терраформе используется HCL).
Беда в том, что в нём может легко не быть таких привычных нам вещей как:
- переменные;
- условия;
- где-то нет комментариев, например, в Json, по дефолту их не предусмотрено;
- функции;
- и это я еще не говорю о таких высокоуровневых вещах, как классы, наследование и всё такое.
2. Вторая проблема такого кода — чаще всего это гетерогенная среда. Обычно вы сидите и работаете с C#, т.е. с одним языком, одним стеком, одной экосистемой. А тут у вас огромное разнообразие технологий.
Вполне реальная ситуация, когда баш с питоном запускает какой-то процесс, в который подсовывается Json. Вы его анализируете, потом еще какой-то генератор выдает ещё 30 файлов. Для всего этого поступают входные переменные из Azure Key Vault, которые стянуты плагином к drone.io, написанным на Go, и переменные эти проходят через yaml, который получился в результате генерации из шаблонизатора jsonnet. Довольно сложно иметь строго хорошо описанный код, когда у вас настолько разнообразная среда.
Традиционная разработка в рамках одной задачи идет с одним языком. Здесь же мы работаем с большим количеством языков.
3. Третья проблема — это тулинг. Мы привыкли к крутом редакторам (Ms Visual Studio, Jetbrains Rider), которые все делают за нас. И даже, если мы затупили, они скажут, что мы не правы. Кажется, что это нормально и естественно.
Но где-то рядышком есть VSCode, в котором есть какие-то плагины, которые как-то ставятся, поддерживаются или не поддерживаются. Вышли новые версии, и их не поддержали. Банальный переход к имплементации функции (даже если она есть) становится сложной и нетривиальной проблемой. Простой ренейм переменной — это реплейс в проекте из десятка файлов. Повезёт, если он то, что надо зареплейсит. Есть, конечно, кое-где подсветка, есть автокомплишн, где-то есть форматинг (правда у меня в терраформе на винде не завелся).
На момент написания статьи vscode-terraform plugin еще не выпустили для поддержки версии 0.12, хотя она зарелижена уже как 3 месяца.
Пришло время забыть о…
- Debugging.
- Refactoring tool.
- Auto completion.
- Обнаружении ошибок при компиляции.
Смешно, но это же увеличивает время на разработку и увеличивает количество ошибок, которые неизбежно происходят.
Самое страшное, что мы вынуждены думать не о том как спроектировать, разложить файлики по папочкам, декомпозировать, сделать поддерживаемым, читаемым и так далее код, а о том, как бы мне корректно написать эту команду, потому что я её как-то неправильно написал.
Как новичок вы пытаетесь познать терраформ, а IDE вам в этом нисколько не помогает. Когда есть документация — зашли, посмотрели. Но если бы вы въезжали в новый язык программирования, то IDE подсказала бы, что есть такой тип, а такого нет. По крайней мере, на уровне int или string. Это часто бывает полезным.
А как же тесты?
Вы спросите: «Как же тесты, господа программисты?» Серьёзные ребята тестируют всё на проде, и это жестко. Вот пример юнитеста для терраформ-модуля с сайта Microsoft.
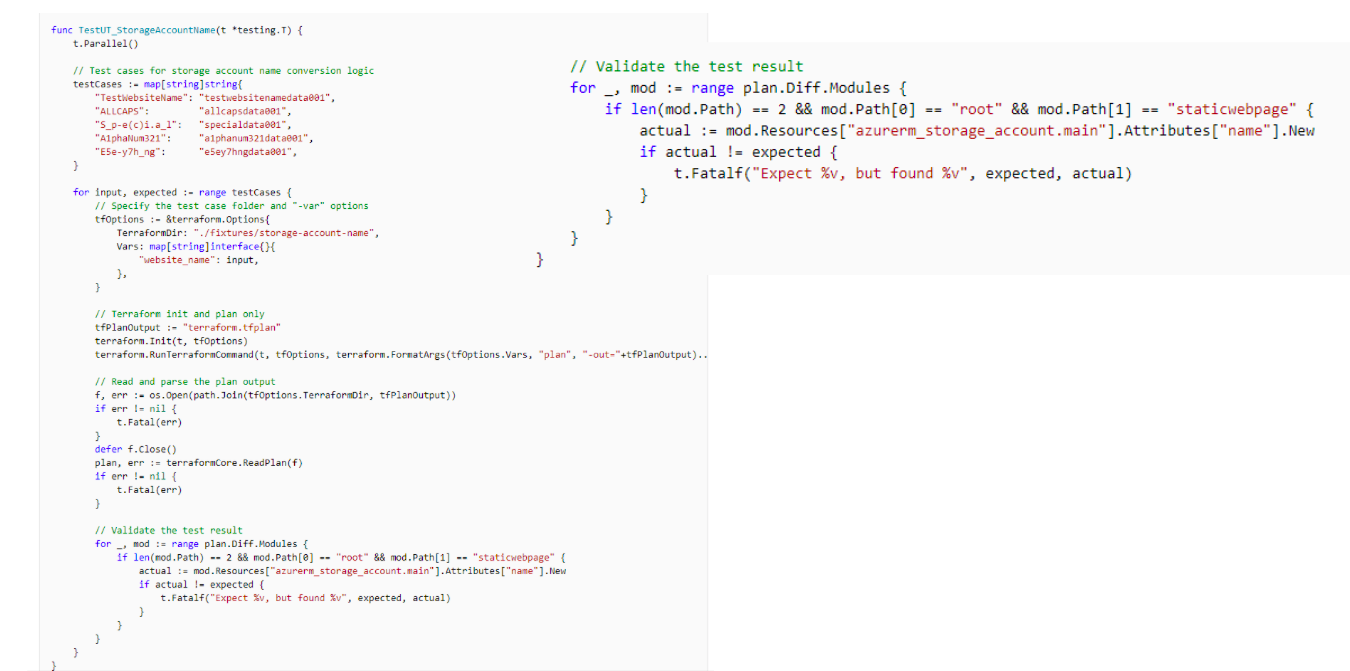
У них хорошая документация. Microsoft мне всегда нравились своим подходом к документации и обучению. Но не нужно быть дядюшкой Бобом, чтобы понять, что здесь не идеальный код. Обратите внимание на валидация, вынесенную вправо.
Проблема unit-теста в том, что мы с вами можем проверить корректность Jsonа на выходе. Я кинул 5 параметров, мне выдалась портянка Json на 2000 строк. Я могу проанализировать, что здесь происходит, validate test result…
Сложно анализировать Json в Go. А надо писать в Go, потому что терраформ на Go — это хорошая практика того, что тестируешь в том языке, в котором ты пишешь. Сама организация кода очень слабая. При этом — это лучшая библиотека для тестирования.
Сам Microsoft пишет свои модули, тестируя их таким способом. Конечно, это Open Source. Всё, о чем я говорю вы можете прийти и починить. Я могу сесть и за недельку всё починить, заопенсорсить плагины VS-кода, терраформ, сделать плагин для райдера. Может быть, написать парочку анализаторов, прикрутить линтеры, законтрибьютить библиотеку для тестирования. Всё могу сделать. Но я не этим должен заниматься.
Лучшие практики Infrastructure as code
Едем дальше. Если в IaC нет тестов, плохо с IDE и тулингом, то должны быть хотя бы лучшие практики. Я просто пошёл в гугл-аналитику и провёл сравнение двух поисковых запросов: Terraform best practices и c# best practices.
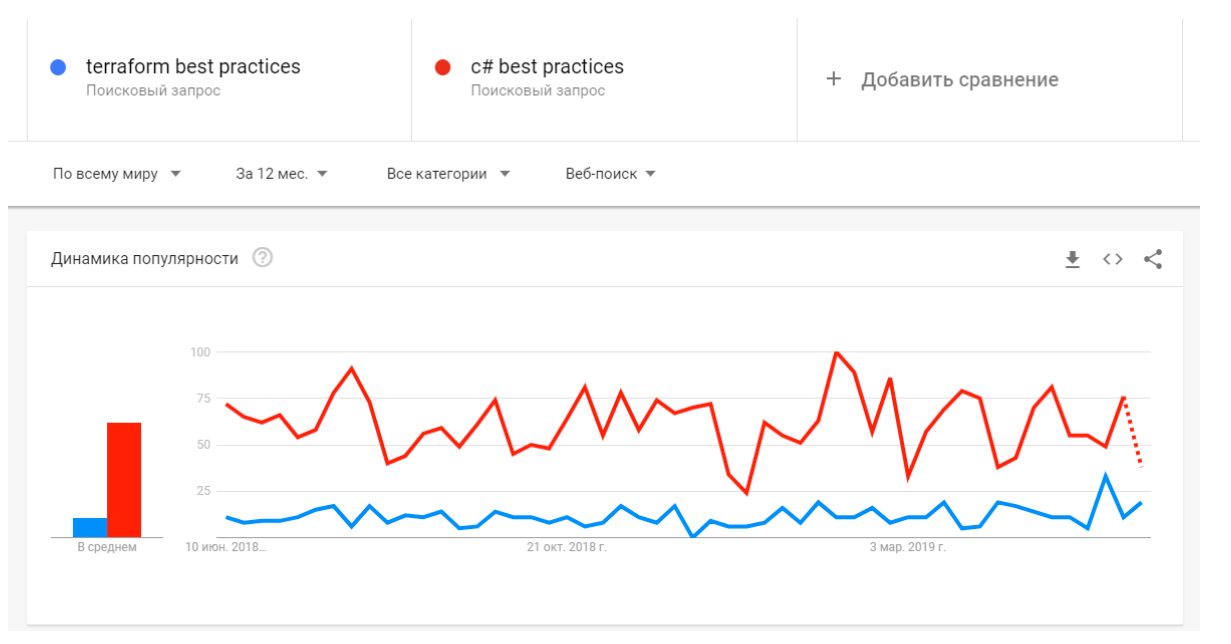
Что мы видим? Беспощадную статистику не в нашу пользу. По количеству материала — то же самое. В C# разработке мы просто купаемся в материалах, у нас есть сверхлучшие практики, есть книги написанные экспертами, и также книжки, написанные на книжки другими экспертами, которые критикуют те книжки. Море официальной документации, статей, обучающих курсов, сейчас еще и open source разработка.
Что касается запроса по IaC: здесь вы по крупицам пытаетесь собрать инфу с докладов хайлоада или HashiConf, с официальной документации и многочисленных issue на гитхабе. Как вообще эти модули раскидывать, что с ними делать? Кажется, что это реальная проблема… Есть же комьюнити, господа, где на любой вопрос тебе дадут 10 комментов на гитхабе. Но это не точно.
К сожалению, в данный момент времени эксперты только начинают появляться. Пока их слишком мало. А само комьюнити болтается на уровне зачатков.
Куда всё это движется и что делать
Можно всё бросить и пойти обратно на C#, в мир райдера. Но нет. Зачем вы вообще стали бы этим заниматься, если не найти решение. Далее я привожу свои субъективные выводы. Можете поспорить со мной в комментариях, будет интересно.
Лично я ставлю на несколько вещей:
- Развитие в данной сфере происходит очень быстро. Привожу график запросов по DevOps.
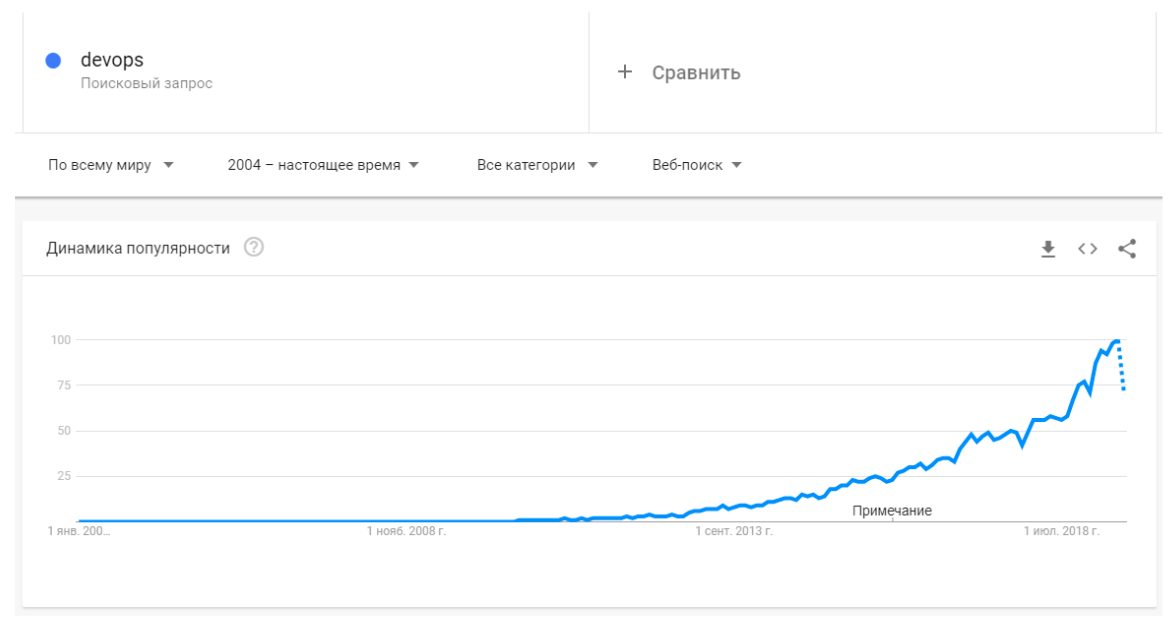
Может быть тема хайповая, но сам факт того, что сфера растёт, вселяет некоторую надежду.Если что-то растет настолько быстро, то обязательно появятся умные люди, которые скажут как надо делать, а как не надо. Увеличение популярности ведет к тому, что может у кого-то будет время дописать наконец плагин к jsonnet для vscode, который позволит переходить к имплементации функции, а не искать ее через ctrl+shift+f. Когда всё развивается, появляется больше материалов. Тот же выход книги от гугла про SRE отличный тому пример.
- Есть разработанные методики и практики в обычной разработке, которые мы можем успешно применять здесь. Да, есть нюансы с тестированием и гетерогенной средой, недостаточный тулинг, но накоплено громадное число практик, которые могут пригодиться и помочь.
Банальный пример: совместная работа через pair programming. Он сильно помогает разобраться. Когда у тебя есть рядом сосед, который тоже что-то пытается понять, вместе вы поймёте лучше.
Понимание о том, как делается рефакторинг помогает даже в такой ситуации производить его. То есть, ты можешь поменять не всё сразу, а поменять нейминг, потом поменять расположение, потом может выделить какую-то часть, ой, а здесь не хватает комментариев.
Заключение
Несмотря на то, что мои рассуждения могут показаться пессимистичным, я с надеждой смотрю в будущее и искренне надеюсь, что у нас (и у вас) всё получится.
Следом готовится вторая часть статьи. В ней я расскажу о том, как мы попробовали применять практики гибкой разработки, чтобы улучшить наш процесс обучения и работу с инфраструктурой.
