Infrastructure as Code: как побороть проблемы с помощью XP
Привет, Хабр! Раньше я жаловался на жизнь в парадигме Infrastructure as code и ничего не предлагал для решения сложившейся ситуации. Сегодня я вернулся, чтобы рассказать, какие подходы и практики помогут вырваться из бездны отчаяния и вырулить ситуацию в правильное русло.

В предыдущей статье «Infrastructure as code: первое знакомство» я делился своим впечатлением от этой сферы, пытался размышлять о текущей ситуации в этой области и даже предположил, что стандартные, известные всем разработчикам практики, могут помочь. Могло показаться, что там было много жалоб на жизнь, но не было предложений по выходу из сложившейся ситуации.
Кто мы, где мы и какие у нас проблемы
Сейчас мы находимся в Sre Onboarding Team, которая состоит из шести программистов и трёх инженеров инфраструктуры. Все мы пытаемся писать Infrastructure as code (IaC). Делаем мы это, потому что в принципе умеем писать код и в анамнезе являемся разработчиками уровня «выше среднего».
- У нас есть набор плюсов: определённый бекграунд, знание практик, умение писать код, желание учиться новому.
- И есть провисающая часть, она же минус: недостаток знаний по матчасти инфраструктуры.
- Terraform для создания ресурсов.
- Packer для сборки имиджей. Это Windows, CentOS 7 образы.
- Jsonnet, чтобы делать мощную сборку в drone.io, а также для генерации packer json и наших модулей терраформа.
- Azure.
- Ansible при готовке образов.
- Python для вспомогательных сервисов, а также скриптов провиженинга.
- И всё это в VSCode с плагинами, расшаренными между участниками команды.
Вывод из моей прошлой статьи был такой: я пытался вселить (в первую очередь в себя) оптимизм, хотел сказать, что мы будем пробовать известные нам подходы и практики для того, чтобы бороться с трудностями и сложностями, которые есть в этой сфере.
Сейчас мы боремся с такими проблемами IaC:
- Несовершенство инструментов, средств к разработке кода.
- Медленное развёртывание. Инфраструктура — это часть реального мира, а он может быть небыстрым.
- Нехватка подходов и практик.
- Мы новенькие и многого не знаем.
Экстремальное программирование (XP) спешит на помощь
Всем разработчикам хорошо знакомо экстремальное программирование (XP) и те практики, которые за ним стоят. Многие из нас работали по такому подходу, и он был удачен. Так почему бы не воспользоваться принципами и практиками, заложенными там, чтобы побороть трудности инфраструктуры? Мы решили применить этот подход и посмотреть, что из этого выйдет.
1. Dynamically changing software requirements. Нам было понятно, какова конечная цель. Но в деталях можно варьировать. Мы сами решаем, куда нам надо вырулить, поэтому требования периодически меняются (в основном нами же самими). Если брать команду SRE, которая сама делает автоматизацию, и сама же ограничивает требования и scope работ, то этот пункт ложится хорошо.
2. Risks caused by fixed time projects using new technology. У нас могут возникнуть риски при использовании каких-то неизвестных нам вещей. И это 100% наш случай. Весь наш проект — это использование технологий, с которыми мы не были до конца знакомы. Вообще, это постоянная проблема, т.к. в сфере инфраструктуры постоянно появляется множество новых технологий.
3,4. Small, co-located extended development team. The technology you are using allows for automated unit and functional tests. Эти два пункта не совсем нам подходят. Во-первых, мы не колоцированная команда, во-вторых, нас девять человек, что может считаться большой командой. Хотя, по ряду определений «большой» команды, много — это 14+ человек.
Рассмотрим некоторые практики из XP и то, как они влияют на скорость и качество обратной связи.
Принцип цикла обратной связи в XP
В моём понимании обратная связь — это ответ на вопрос, правильно ли я делаю, туда ли мы идём? В ХР на этот счёт есть божественная схемка: цикл обратной связи по времени. Интересность заключается в том, что чем ниже мы находимся, тем мы быстрее имеем возможность получить ОС, чтобы ответить на необходимые вопросы.
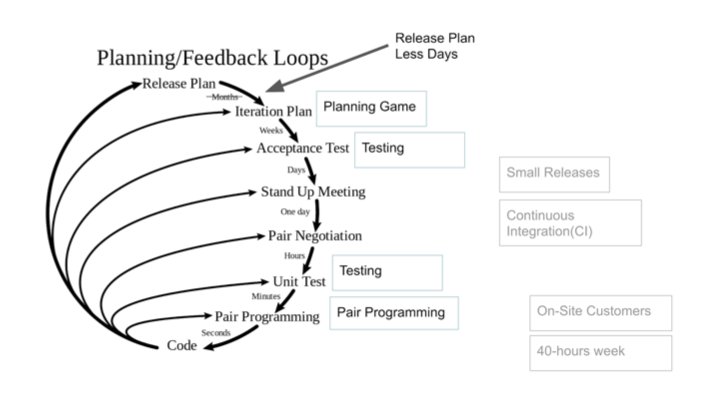
Это довольно интересная тема для обсуждения, что у нас в IT индустрии возможно быстро получить ОС. Представьте, как больно сложно делать какой-нибудь проект полгода и только потом узнать, что в самом начале была заложена ошибка. Такое бывает и в проектировании, и в любом построении сложных систем.
В нашем случае IaC нам помогает обратная связь. Сразу вношу небольшую корректировку в схему выше: релиз-план имеем не месячный цикл, а происходит несколько раз в день. К этому циклу ОС привязаны некоторые практики, которые мы рассмотрим подробнее.
Важно: обратная связь может стать решением для всех заявленных выше проблем. В совокупности с практиками XP, она может вытащить из бездны отчаяния.
Как вытащить себя из бездны отчаяния: три практики
Тесты
Тесты упоминаются дважды в цикле обратной связи XP. Это не просто так. Они крайне важны для всей техники экстремального программирования.
Предполагается, что у тебя есть Unit и Acceptance tests. Одни дают тебе фидбек за сколько-то минут, другие за сколько-то дней, потому они пишутся дольше, а прогоняются реже.
Есть классическая пирамида тестирования, которая показывает, что каких-то тестов должно быть больше.
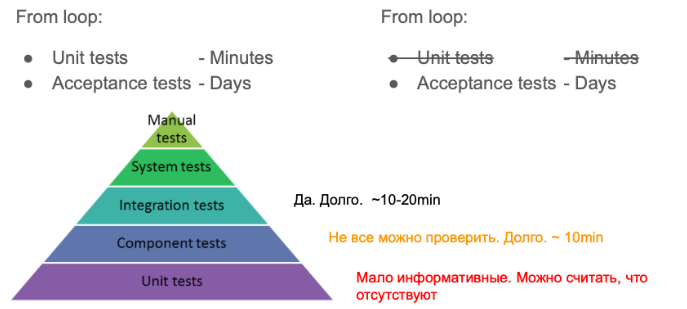
Как это схема применима к нам в проекте IaC? На самом деле… никак.
- Unit-тестов, несмотря на то, что их должно быть очень много, не может быть очень много. Либо они очень косвенно что-то тестируют. Фактически можно сказать, что мы их не пишем вообще. Но вот несколько применений для таких тестов, которые у нас всё-таки получилось сделать:
- Тестирование кода на jsonnet. Это, например, наш пайплайн сборки в drone, который достаточно сложен. Код на jsonnet хорошо покрывается тестами.
Мы используем этот Unit testing framework for Jsonnet. - Тесты на скрипты, которые выполняются при старте ресурса. Скрипты на Python, а значит и тесты на них можно писать.
- Тестирование кода на jsonnet. Это, например, наш пайплайн сборки в drone, который достаточно сложен. Код на jsonnet хорошо покрывается тестами.
- Потенциально возможна проверка конфигурации в тестах, но мы не делаем так. Ещё есть возможность настройки проверки правил конфигурирования ресурсов через tflint. Однако, просто для терраформа там слишком базовые проверки, но много проверочных сценариев написано для AWS. А мы на Azure, так что это снова не подходит.
- Компонентные интеграционные тесты: тут зависит от того, как ты их классифицируешь и куда раскладываешь. Но они в принципе работают.
Вот так выглядят интеграционные тесты.
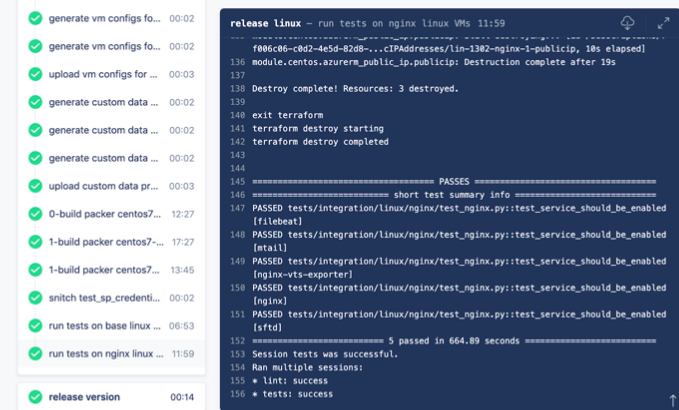
Это пример при сборке образов в Drone CI. Чтобы до них дойти, надо 30 минут ждать, пока соберётся имидж Packer, потом ещё минут 15 ждать, пока они пройдут. Но они есть!
Алгоритм проверки образов- Сначала Packer должен приготовить образ полностью.
- Рядом с тестом есть терраформ с локальным стейтом, которым мы этот образ разворачиваем.
- При разворачивании используется небольшой модуль, лежащий рядом, чтобы проще было работать с образом.
- Когда из образа развернута VM, можно начать проверки. В основном, проверки осуществляются на машине. Проверяется, как отработали скрипты при старте, как работают демоны. Для этого через ssh или winrm мы заходим на только что поднятую машину и проверяем состояние конфигурации или поднялись ли сервисы.
- Похожая ситуация с интеграционными тестами и в модулях для терраформа. Вот краткая таблица, поясняющая особенности таких тестов.
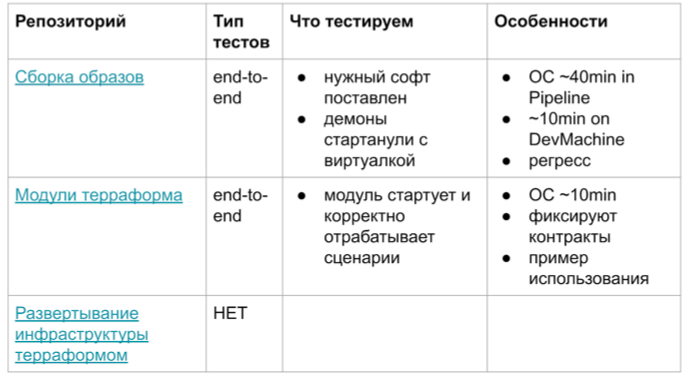
Обратная связь на пайплайне в районе 40 минут. Всё происходит очень долго. Можно использовать для регресса, но для новой разработки вообще нереально. Если очень-очень к этому подготовиться, подготовить running, скрипты, то можно сократить до 10 минут. Но это всё равно не Unit-тесты, которые за 5 секунд 100 штук.
Отсутствие Unit-тестов при сборке образов или модулей терраформа сподвигает перекладывать работу на отдельные сервисы, которые просто можно дёрнуть по REST, или на Python-скрипты.
Например, нам нужно было сделать так, чтобы при старте виртуальной машины она регистрировала себя в сервисе ScaleFT, а при уничтожении виртуалки удаляла себя.
Так как ScaleFT у нас как сервис, мы вынуждены работать с ним через API. Tам была написана обёртка, которую можно дёрнуть и сказать: «Зайди и удали то-то, то-то». Она хранит все необходимые настройки и доступы.
На это уже можем писать нормальные тесты, так как это никак не отличается от обычного софта: мокается какая-то апиха, ты дёргаешь, и смотрим, что происходит.
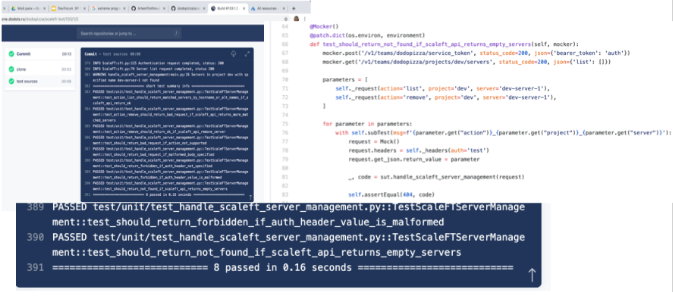
Итоги по тестам: Unit-тестирование, которое должно давать ОС за минуту, не даёт его. А более высокие по пирамиде виды тестирования дают эффект, но закрывают лишь часть проблем.
Парное программирование
Тесты — это, конечно, хорошо. Их можно писать много, они могут быть разных видов. Они будут работать на своих уровнях и давать нам обратную связь. Но проблема с плохими Unit-тестами, которые дают самую быструю ОС, остаётся. При этом продолжает хотеться быстрой ОС, с ней легко и приятно работать. Не говоря уже о качестве получаемого решения. К счастью, есть техники, позволяющие дать ещё более быстрый feedback, чем модульные тесты. Это парное программирование.
При написании кода хочется получить обратную связь о его качестве как можно быстрее. Да, можно написать всё в фича-ветке (чтобы не поломать ничего никому), сделать pull request в гитхабе, назначить на кого-то, чьё мнение имеет вес, и ждать ответа.
Но ждать можно долго. Люди все занятые, а ответ, даже если и будет, может быть не самым высоким по качеству. Предположим, что ответ пришёл сразу, ревьювер моментально понял весь замысел, но ответ всё равно приходит с запозданием, постфактум. А хочется-то раньше. Вот парное программирование и нацелено на это — чтобы сразу, в момент написания.
Далее привожу стили парного программирования и их применимость в работе над IaC:
1. Classic, Опытный+опытный, смена по таймеру. Две роли — driver and navigator. Два человека. Они работают над одним кодом и меняются ролями через определенный заранее обозначенный промежуток времени.
Рассмотрим сочетаемость наших проблем со стилем:
- Проблема: несовершенство инструментов, средств к разработке кода.
Негативное влияние: дольше разрабатывать, мы замедляемся, сбивается темп/ритм работы.
Как боремся: применяем другой тулинг, общими IDE и выучиванием шорткатов. - Проблема: медленное развертывание.
Негативное влияние: увеличивает время на создание работающего куска кода. Скучаем во время ожидания, руки тянутся заняться чем-то другим, пока ждешь.
Как боремся: не побороли. - Проблема: недостаток подходов и практик.
Негативное влияние: нет знания, как делать хорошо, а как плохо. Удлиняет получение обратной связи.
Как боремся: взаимообмен мнений и практик в парной работе почти решает проблему.
Главная проблема применения этого стиля в IaC в неровном темпе работы. В традиционной разработке ПО у тебя очень равномерное движение. Ты можешь потратить пять минут и написать N. Потратить 10 минут и написать 2N, 15 минут — 3N. Здесь же можно потратить пять минут и написать N, а потом потратить еще 30 минут и написать десятую часть от N. Здесь ты ничего не знаешь, у тебя затык, тупняк. Разбирательство занимает время и отвлекает от непосредственно программирования.
Вывод: в чистом виде нам не подходит.
2. Ping-pong. Это подход предполагает, что один участник пишет тест, а другой делает для него реализацию. С учетом того, что с Unit-тестами всё сложно, и приходится писать долгий по времени программирования интеграционный тест, вся легкость ping-pong«а уходит.
Могу сказать, что мы пробовали разделение обязанностей по проектированию сценария теста и реализации кода под него. Один участник придумывал сценарий, в этой части работы он был ответственным, за ним было последнее слово. А другой был ответственен за реализацию. Это получалось хорошо. Качество сценария при таком подходе увеличивается.
Вывод: увы, темп работы не позволяет использовать ping-pong, как практику парного программирования в IaC.
3. Strong Style.Сложная практика. Идея в том, что один участник становится директивным навигатором, а второй берёт роль исполняющего драйвера. При этом право решений исключительно за навигатором. Драйвер лишь печатает и словом может повлиять на происходящее. Роли не меняются долгое время.
Хорошо подходит для обучения, но требует сильных soft skills. На этом мы и запнулись. Техника шла сложно. И дело тут даже не в инфраструктуре.
Вывод: потенциально может применяться, мы не оставляем попытки.
4. Mobbing, swarming и все известные, но не перечисленные тут стили не рассматриваем, т.к. не пробовали и сказать про это в контексте нашей работы не получится.
Общие итоги по использованию pair programming:
- Имеем неравномерный темп работы, который сбивает.
- Мы упёрлись в недостаточно хорошие soft skills. А предметная область не способствует преодолению этих наших недостатков.
- Долгие тесты, проблемы с инструментами делают парную разработку вязкой.
5. Несмотря на это, были и успехи. Мы придумали собственный метод «Схождение — расхождение». Кратенько опишу, как он работает.
У нас есть постоянные партнеры на несколько дней (меньше недели). Мы делаем одну задачу вместе. Какое-то время мы сидим вместе: один пишет, второй сидит и наблюдает, как саппорт тим. Потом мы расходимся на какое-то время, каждый делает какие-то независимые вещи, потом опять сходимся, синхронизируемся очень быстро, делаем что-то вместе и опять расходимся.
Планирование и общение
Последний блок практик, через которые решаются проблемы ОС — это организация работ с самими задачами. Сюда же входит и обмен опытом, который находится вне парной работы. Рассмотрим три практики:
1. Задачи через дерево целей. Общее ведение проекта мы организовали через дерево, бесконечно уходящее в будущее. Технически ведение делается в Miro. Есть одна задача — она промежуточная цель. От неё идут либо более мелкие цели, либо группы задач. От них уже сами задачи. Все задачи создаются и ведутся на этой доске.
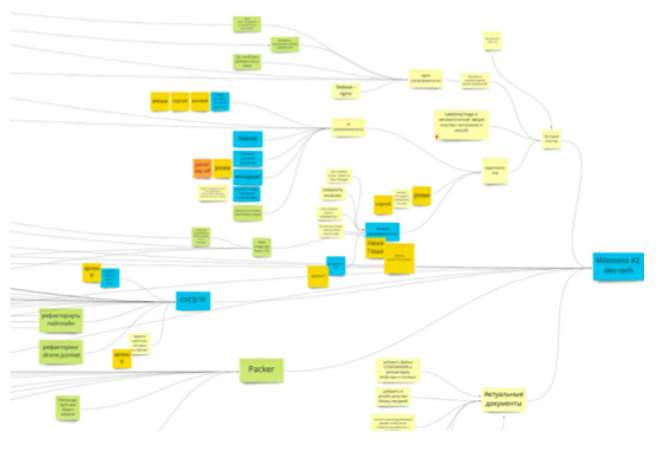
Эта схема тоже дает обратную связь, которая происходит один раз в день, когда мы синхронизируемся на митингах. Наличие перед всеми общего плана, при этом структурированного и полностью открытого, позволяет каждому быть в курсе происходящего и того, как далеко мы продвинулись по прогрессу.
Преимущества визуального видения задач:
- Причинность. Каждая задача ведёт к какой-то глобальной цели. Задачи группируются по более мелким целям. Домен инфраструктуры сам по себе довольно техничен. Не всегда сразу понятно, какое конкретно влияние на бизнес оказывает, например, написание ранбука по миграции на другой nginx. Наличие рядом целевой карточки делает это более понятным.
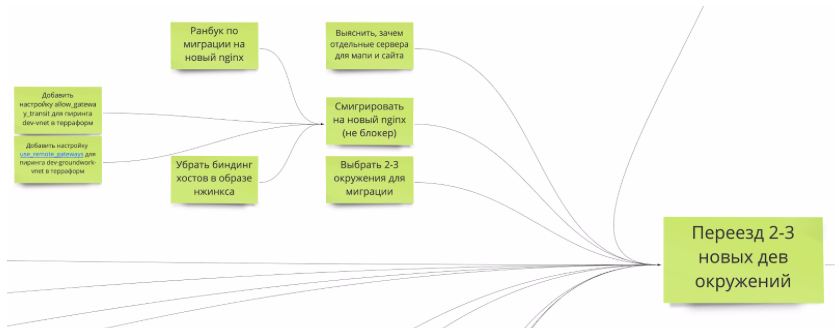
Причинность — важное свойство задач. Оно непосредственно отвечает на вопрос: «А то ли я делаю?» - Параллельность. Нас девять человек, и набрасываться всем на одну задачу невозможно просто физически. Задач из одной области тоже не всегда может хватить. Мы вынужденно параллелим работу между мелкими рабочими группами. При этом группы некоторое время сидят на своей задаче, их могут усилить кем-то еще. От этой рабочей группы иногда отваливаются люди. Кто-то уходит в отпуск, кто-то делает доклад для конференции DevOps conf, кто-то пишет статью на Хабр. Знать, какие цели и задачи могут делаться параллельно становится очень важно.
2. Сменные ведущие утренних митингов. На стендапах получилась такая проблема — много задач люди делают параллельно. Иногда задачи слабо связаны и нет понимания, кто что делает. А мнение ещё одного члена команды очень важно. Это дополнительная информация, которая способна изменить ход решения задачи. Конечно, обычно с тобой в паре кто-то есть, но консультация и подсказки всегда не лишние.
Чтобы эту ситуацию улучшить, мы применили технику «Смена ведущего стендпапа». Теперь они ротируются по определенному списку, и это имеет свой эффект. Когда до тебя доходит очередь, ты вынужден погрузиться и понять что происходит, чтобы хорошо провести скрам-митинг.

3. Внутреннее демо. Помощь в решении задачи от парного программирования, визуализация на дереве задач и помощь на скрам-митингах по утрам — хорошо, но не идеально. В паре вы ограничены лишь своими знаниями. Дерево задач помогает глобально понять, кто и что делает. А ведущий и коллеги на утренней встрече не погрузятся глубоко в твои проблемы. Уж точно могут что-то и пропустить.
Решение было найдено в демонстрировании сделанных работ друг другу и последующем обсуждении их. Мы собираемся раз в неделю на час и показываем детали решений по задачам, которые делали за последнюю неделю.
В процессе демонстрации надо раскрыть детали задачи и обязательно продемонстрировать её работу.
2. Как решалась задача до этого? Например, требовалось массовое мышекликанье, или же вообще было невозможно что-то сделать.
3. Как мы улучшаем это. Например: «Смотрите, теперь есть скриптосик, вот ридми».
4. Покажите, как это работает. Желательно прямо осуществить какой-либо сценарий пользователя. Хочу X, делаю Y, вижу Й (или Z). Например, деплою NGINX, курлю url, получаю 200 OK. Если действие долгое, подготовьте заранее, чтобы потом показать. Желательно за час до демо уже не разламывать особо, если хрупкое.
5. Объясните, насколько удачно решена проблема, какие трудности остались, что не доделано, какие усовершенствования возможны в дальнейшем. Например, сейчас cli, потом будет полная автоматика в CI.
Желательно каждому спикеру уложиться в 5–10 минут. Если ваше выступление заведомо важное и займет больше времени, заранее согласуйте это в канале sre-takeover.
После очной части обязательно идет обсуждение в треде. Вот тут-то и появляется та необходимая нам обратная связь по своим задачам.

По итогу проводится опрос для выявления полезности происходящего. Это уже обратная связь по сути выступления и важности задачи.

Длинные выводы и что дальше
Может показаться, что тон статьи несколько пессимистичный. Это не так. Два низовых уровня получения обратной связи, а именно тесты и парное программирование, работают. Не так совершенно, как в традиционной разработке, но позитивный эффект от этого есть.
Тесты, в текущем их виде, дают лишь частичное покрытие кода. Много функций конфигурации оказываются не протестированными. Влияние их на непосредственную работу при написании кода низкое. Однако эффект от интеграционных тестов есть, и именно они позволяют безбоязненно проводить рефакторинги. Это большое достижение. Также с переносом фокуса на разработку в высокоуровневых языках (у нас python, go) проблема уходит. А на «клей» много проверок и не надо, достаточно общей интеграционной.
Работа в паре больше зависит от конкретных людей. Есть фактор задачи и наши soft skills. С кем-то получается очень хорошо, с кем-то хуже. Польза от этого точно есть. Ясно, что даже при недостаточном соблюдении правил парной работы, сам факт совместного выполнения задач положительно влияет на качество результата. Лично мне в паре работается проще и приятнее.
Более высокоуровневые способы влияние на ОС — планирование и работа с задачами точно дают эффекты: качественный обмен знаний и улучшение качества разработки.
Короткие выводы одной строкой
- Практики ХР работают в IaC, но с меньшим КПД.
- Усиливайте то, что работает.
- Придумывайте свои компенсаторные механизмы и практики.
