Hydrosphere — управляем ML как сервисом

Подобно тому, как в мире разработки многокомпонентных систем применяются подходы для управления и мониторинга микросервисами на основе инструментов DevOps (для запуска и восстановления сервисов, передачи данных, наблюдения за распределенными операциями, выполнение замеров и получение операционных метрик), так же и для моделей машинного обучения становится важным обеспечить возможность их развертывания, обновления и наблюдения за метриками (точность модели, время выполнения прямого прохождения нейронной сети и другими). В обобщенном виде такие решения получили названия MLOps и в этой статье мы рассмотрим возможности платформы Hydrosphere 3.0.
Hydrosphere поддерживает разные фреймворки для описания нейронных сетей (в том числе, Tensorflow/Keras, PyTorch, fastai и другие) и обеспечивает полный цикл управления моделью, включая контроль обучения, версионирование, развертывание и наблюдение за операционными метриками, а также позволяет обнаруживать деградацию сети и потерю производительности и точности (из-за переобучения или некачественных данных, выбранных для обучения) на ранних этапах. Hydrosphere также предоставляет возможность интерпретации процесса вывода результата и визуализации работы модели машинного обучения для определения причины неправильного вывода.
Hydrosphere использует для развертывания моделей Kubeflow (исполнение моделей машинного обучения в подах Kubernetes) или Apache AirFlow (инструмент для управления любыми конвейнерными операциями). Для управления Hydrosphere используется веб-интерфейс, а также API (REST или gRPC) для внешних приложений. Для развертывания моделей используются OCI-контейнеры с gRPC-интерфейсом, который оборачивает реальный код исполнения модели (на любом языке программирования) и позволяет обобщить способ передачи входного вектора в модель и получения результата исполнения модели. Модели могут версионироваться (каждая версия — отдельный образ контейнера) и объединяться в конвейеры обработки в концепции приложения (Application), при этом на каждой стадии конвейера может использоваться одна или несколько версий модели, выводы которых объединяются с учетом весов. Модель и конвейер описываются в виде yaml-файлов, которые описывают входы и выходы модели (тип и размерность массива или категоризированные значения, также поддерживаются типы для текстов, изображений, звука и видео), при развертывании модели сохраняются во внутреннем реестре.
Hydrosphere выполняет функции маршрутизации внешних запросов (Gateway), управления запущенными моделями (Manager), получения операционных метрик (Sonar, также может отправлять метрики в Prometheus) и автоматического обнаружения выбросов (Auto OD) и создания отчетов о статистическом распределении в обучающем наборе и реальных данных (Drift Report). Также Hydrosphere содержит два компонента для объяснения выводов модели (Explanation) и визуализации выводов на многомерных массивах (Data Projection).
Для установки Hydrosphere можно использовать готовый стек на Docker Compose или Kubernetes (через Helm) и утилиту командной строки (pip install hs), которая позволяет управлять приложениями и моделями, а также конфигурировать кластер Hydrosphere. В нашем примере будем использовать Docker Compose (про установку в Kubernetes можно почитать на этой странице):
export HYDROSPHERE_RELEASE=3.0.0
wget -O hydro-serving-${HYDROSPHERE_RELEASE}.tar.gz https://github.com/Hydrospheredata/hydro-serving/archive/${HYDROSPHERE_RELEASE}.tar.gz
tar -xvf hydro-serving-${HYDROSPHERE_RELEASE}.tar.gz
cd hydro-serving-${HYDROSPHERE_RELEASE}
docker-compose up -dПосле запуска мы можем увидеть контейнеры для всех подсистем Hydrosphere (ui, visualization, gateway, auto-od, sonar, serving-manager), дополнительные контейнера для хранения данных (mongodb, postgres, minio), alertmanager для оповещения о деградации моделей. Веб-интерфейс публикуется на порт 80. Для внешнего доступа (через Python SDK) будет использовать gRPC-интерфейс на порте 9090.
Для развертывания модели прежде всего необходимо сконфигурировать новый кластер:
pip install hs
hs cluster add --name=demo --server=http://localhost/
hs cluster use demo
git clone https://github.com/Hydrospheredata/hydro-serving-example.git
cd hydro-serving-example/examples/custom_metrics/census/models/model
hs apply -f serving.yamlПри выполнении apply будет выполнена сборка контейнера для поддержки модели и его развертывание в кластер. Рассмотрим более подробно структуру проекта с моделью ML и yaml-файл для описания развертывания:
kind: Model
name: "census"
payload:
- "src/"
- "requirements.txt"
- "model.joblib"
- "encoders.joblib"
runtime: "hydrosphere/serving-runtime-python-3.7:3.0.0-alpha.1"
install-command: "pip install -r requirements.txt"
training-data: "../../data/train.csv"
metadata:
documentation: "https://docs.hydrosphere.io/quickstart/tutorials/train-and-deploy-census-income-classification-model"
contract:
name: "predict"
inputs:
age:
shape: scalar
type: int64
profile: numerical
hours-per-week:
shape: scalar
type: int64
profile: categorical
//...другие поля...
native-country:
shape: scalar
type: string
profile: categorical
outputs:
income:
shape: scalar
type: string
profile: categoricalМодель определяет правила сборки контейнера — базовый образ (runtime), расположение тестовых данных в проекте, список дополнительных файлов для добавления в контейнер — payload, название модели, команда для конфигурирования собираемого контейнера (здесь используется установка зависимостей из requirements.txt, но может быть выполнен запуск сценария, но нужно при этом не забыть добавить его через payload). Взаимодействие с моделью описывается через contract, который содержит набор входов (inputs) и выходов (модели), каждый из которых определяется формой матрицы (может быть в формате массива размерностей или scalar для скалярных величин), типом значения (int64, float, string и другие, подробно список типов можно посмотреть здесь), профилем значения (numerical, categorical, image, text).
На текущий момент доступны две среды исполнения — hydrosphere/serving-runtime-python-3.7 и hydrosphere/serving-runtime-python-3.8, но может использовать любой образ, который создает совместимый grpc-сервис.
Сам проект должен включать в себя необходимые для запуска модели зависимости (устанавливаются через install-command), описание конвейеров или обученные веса для нейронных сетей (также должны добавлять в payload), а также код с экспортируемой функцией predict или любую другую, название указывается в описании модели в contract.name (принимает входные значения как **kwargs) и возвращает dict с выходными значениями. При запуске код должен создать необходимые объекты для представления ML-модели, загрузить веса или описания конвейеров, выполнить все необходимые операции для дальнейшего использования модели.
Для развертывания приложения используются другой тип yaml-файлов (kind: Application), в которых перечисляются стадии исполнения в pipeline, при этом внутри стадии может использоваться одна или несколько моделей (при указании модели дополнительно можно уточнять номер версии):
kind: Application
name: demo
pipeline:
- - model: "census:1"
weight: 100Для установки приложения также используется hs apply application.yaml. Также приложение может быть создано через веб-интерфейс. Перейдем на страницу http://localhost/applications/demo и попробуем проверить исполнение приложения (кнопка Test):
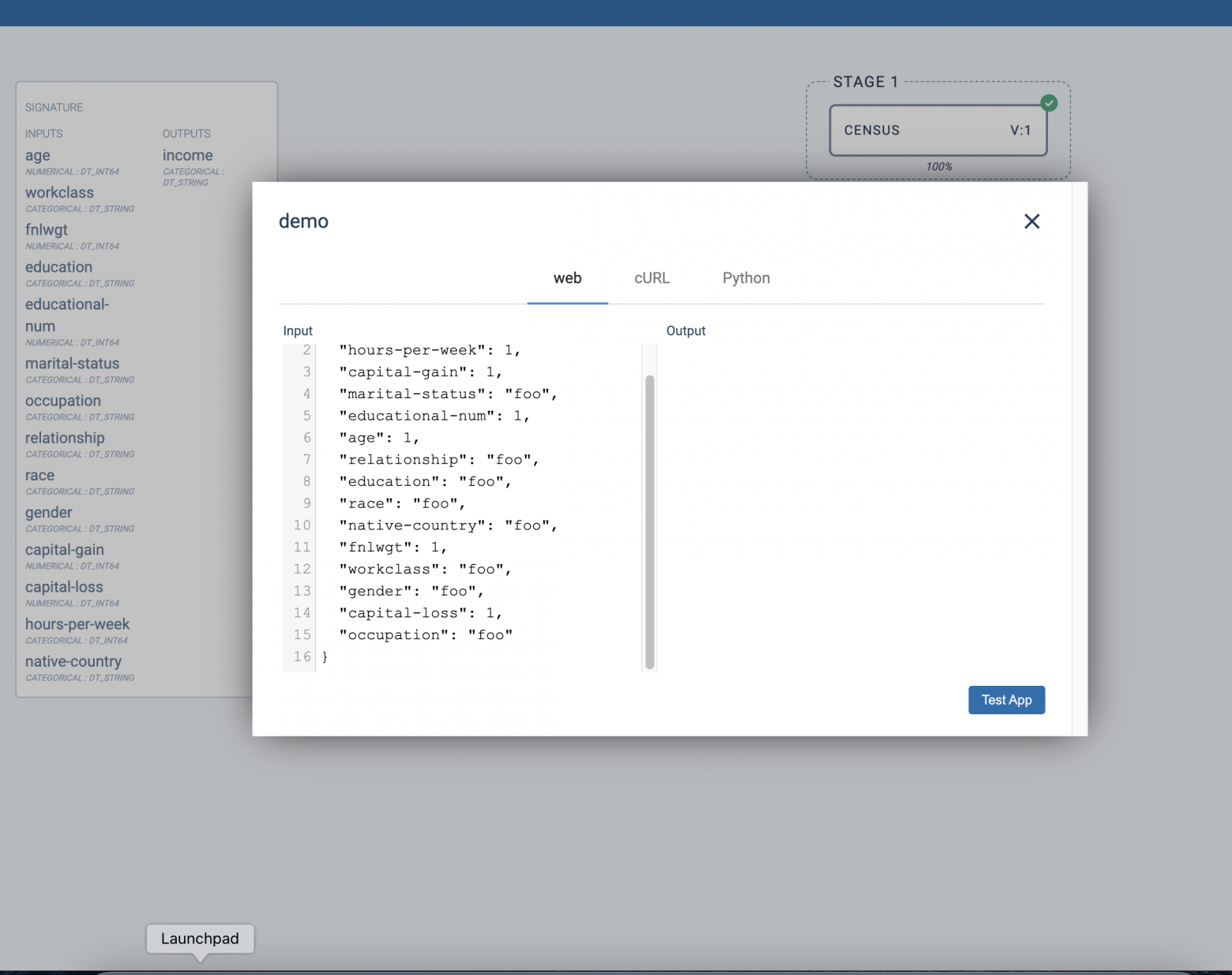
Здесь необходимо заполнить категориальные данные корректными значениями, либо обратиться к кластеру программно и передать данные, загруженные из тестового набора:
from hydrosdk import Cluster, Application
cluster = Cluster("http://localhost", grpc_address="localhost:9090")
app = Application.find(cluster, "demo")
predictor = app.predictor()
# load data and call predictor.predict(data), where data is a dictionaryПопробуем создать простую модель на основе keras для детектирования цифр (обучена на наборе данных MNIST. Создадим новый пустой каталог и внутри него, в src/train.py сохраним сценарий для обучения нейронной сети на наборе данных MNIST. Результат обучения сохраним в файл .h5 (HDF5):
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utils
nb_classes = 10
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(X_train, Y_train,
batch_size=128, epochs=4,
validation_data=(X_test, Y_test))
model.save('trained.h5')Запустим обучение:
python3 src/train.pyТеперь создадим реализацию модели для использования в hydrosphere:
import tensorflow as tf
import numpy as np
model = tf.keras.models.load_model('trained.h5')
def predict(data):
predictions = model.predict(data['image'])
return {'result':np.argmax(predictions)}
# simulate digit "1"
digit_one = [1.0 if d%28==14 else 0.0 for d in range(0,28*28)]
data = {'image': np.array(digit_one, dtype=np.float32).reshape([1,-1])}
assert predict(data)['result']==1Здесь в модели добавлен тест, который симулирует изображение цифры »1» (вертикальная черта) и проверяет вывод сети на корректность.
Для публикации модели необходимо создать файл с определением контракта и метаданных:
kind: Model
name: "digit"
payload:
- "src/model.py"
- "trained.h5"
runtime: "hydrosphere/serving-runtime-python-3.7:3.0.0-alpha.1"
install-command: "pip install tensorflow keras numpy"
contract:
name: "predict"
inputs:
image:
shape: [1,784]
type: float32
profile: numerical
outputs:
result:
shape: scalar
type: int32
profile: categoricalИ также подготовим развертывание приложения:
kind: Application
name: digits
pipeline:
- - model: digit:1Установим модель и приложение в Hydrosphere:
hs apply -f model.yaml
hs apply -f application.yamlИ подключимся к нему из внешнего приложения:
from hydrosdk import Cluster, Application
cluster = Cluster("http://localhost", grpc_address="localhost:9090")
app = Application.find(cluster, "digits")
predictor = app.predictor()
digit_one = [1.0 if d%28==14 else 0.0 for d in range(0,28*28)]
print(predictor.predict(digit_one))Аналогично может быть сделана сложная обработка с объединением нескольких моделей, в этом случае вывод предыдущей модели будет передаваться на ввод моделей следующей стадии.
Таким образом, использование Hydrosphere позволяет интегрировать управление моделями и ML-приложениями в CI/CD-конвейер доставки других компонентов системы, а также обеспечивает механизм обнаружения и исполнения ML-приложений и мониторинга их функционирования.
В заключение приглашаю всех на бесплатный урок по теме: «MLFlow и переобучение ML-моделей». Зарегистрироваться на урок можно по ссылке ниже.
