Хранение, резервное копирование и каталогизация фотографий
Тут периодически пишут посты про то, как хранят и бэкапят свои фотографии — ну и просто файлы. В последнем таком посте написал достаточно длинный комментарий, немного подумал и решил всё же развернуть его в пост. Тем более, что несколько поменял метод бэкапа в облако, может будет полезно кому.
Домашний сервер, где происходит многое из описанного ниже:

Что надо сохранять?
Самое важное и объёмное у меня — фотографии. Изредка видео, но очень изредка — оно слишком много места занимает и слишком много времени отнимает, потому я его не слишком люблю, снимаю только короткие ролики, которые валяются в той же куче, где и фотографии. На текущий момент фотоархив у меня занимает примерно 1,6 терабайта и растёт где-то на 200 гигабайт в год. Другие важные вещи гораздо менее объёмны и с ними меньше вопросов в плане хранения и бэкапа, десяток-другой гигабайт можно распихать по куче бесплатных или очень дешевых мест, начиная от ДВД и заканчивая флэшками и облаками.
Как оно хранится и бэкапится?
Весь мой фотоархив занимает порядка 1,6 терабайта на текущий момент. Мастер-копия хранится на двухтерабайтном SSD в домашнем компьютере. На картах памяти я стараюсь не держать фотографии дольше необходимого, при первой возможности сливаю десктоп или ноутбук (когда в дороге). Хотя с флэшки при этом не удаляю, если ещё место есть. Лишняя копия никогда не помешает. С ноута по приезду домой тоже всё скидывается на десктоп.

Ежедневно делается копия папки с фотографиями на домашний сервер (с типа зеркалом на базе Drivepool, где настроено дублирование важных папок). Кстати, Drivepool по прежнему рекомендую — за все годы использования ни одного глюка. Просто работает. Не надо только смотреть на его русский интерфейс, я отправил разработчикам более пристойный перевод, но не знаю, когда его внедрят. А пока что на русском языке это программа для управления бассейном (manage pool).
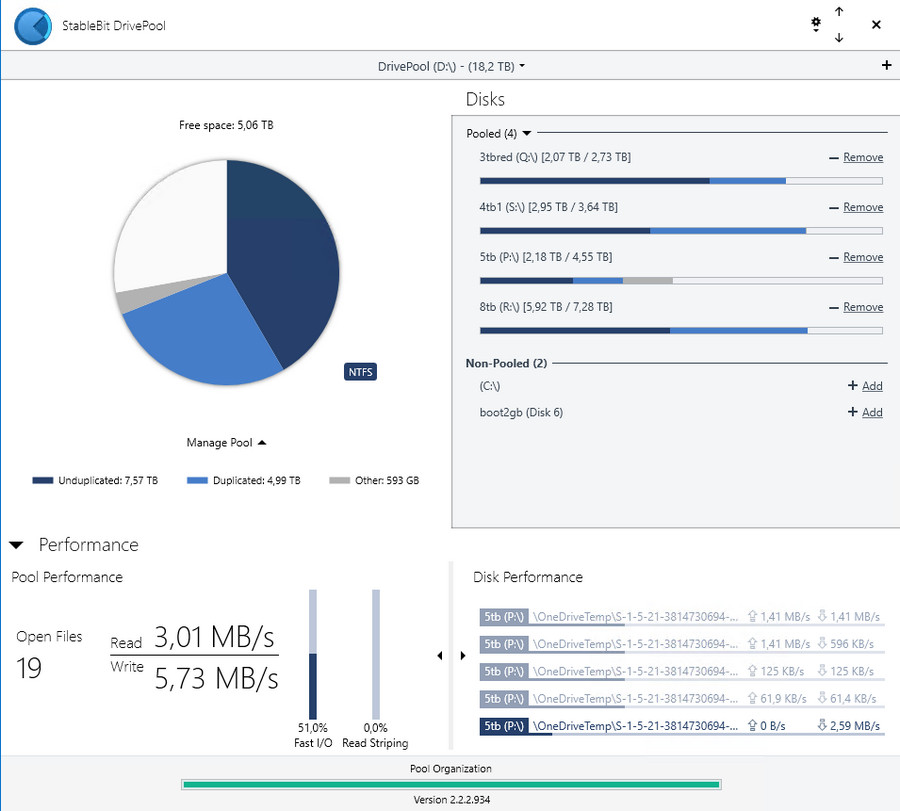
Можно, конечно, копии делать и чаще, если за день много работы сделано, то могу принудительно задание запускать. Хотя сейчас всё же думаю о том, чтобы запускать копирование по изменению файлов, хочу перестать десктоп держать включенным круглосуточно, пусть сервер больше работает. Программа — GoodSync.
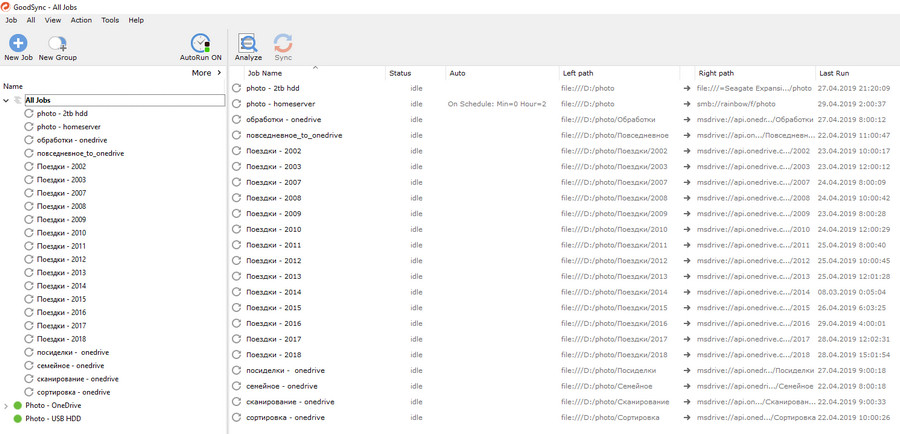
До недавнего времени с того же десктопа тем же GoodSync файлы загружались в облако Onedrive. Большая часть файлов у меня не персональные, потому закачивал как есть, без шифрования. Что было персональным — закачивалось отдельным заданием, с шифрованием.
Onedrive был выбран из-за того, что подписка Office 365 Home Premium за 2000 в год давала пять (а сейчас уже шесть) терабайт в облаке. Пусть и кусочками по терабайту. Сейчас, правда, халява несколько подорожала, но несколько недель назад были ещё вариант за 2600–2700 в год (надо искать искать у розничных продавцов). Я это предвидел, когда в прошлом году MS задрал цены, да ещё и прекратил на сайте подписку продавать, потому активировал подписку на пять лет вперёд пока ещё были в продаже по 1800–2000 коробки (можно, конечно, было ещё и несколько коробок про запас взять, но настолько я загадывать не решился).

Скорость закачки — максимальная для моего тарифа, 4–5 мегабайт/сек., по ночам до 10. В своё время смотрел на crashplan — там хорошо если мегабайт в секунду грузился.
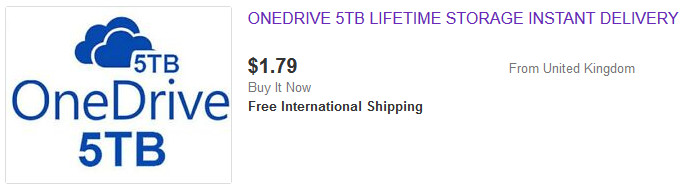
Пожизненные 5ТБ за 2–3$ c ebay — штука очень рэндомная. Ибо срок жизни может оказаться очень коротким, пока что три месяца рекорд. Не дело это — бэкапиться в то место, которое может накрыться в любой момент. Пусть и за копейки.
Но сейчас же, в силу того, что решил перетащить часть задач с десктопа на сервер, копирование в Onedrive перевёл на Duplicati. Пусть оно и бета, но пользуюсь уже несколько месяцев и пока что работает вполне стабильно. Поскольку Duplicati всё равно хранит свои бэкапы в архивах, а не россыпью, то решил уж всё загружаемое шифровать встроенными средствами. Всё равно восстанавливать, если что, через Duplicati же придётся. Так что пусть всё шифрует.
Учитывая то, что терабайты у меня кусочками, бэкап в облако состоит из нескольких заданий. Тут как раз идёт перезаливка бэкапа в облако. 2019 залился быстро — там за пару дней полсотни фото, я мало пока что ездил, а 2018 потихоньку льётся. Текущая скорость закачки не максимальная — день, каналы загружены и всё такое.
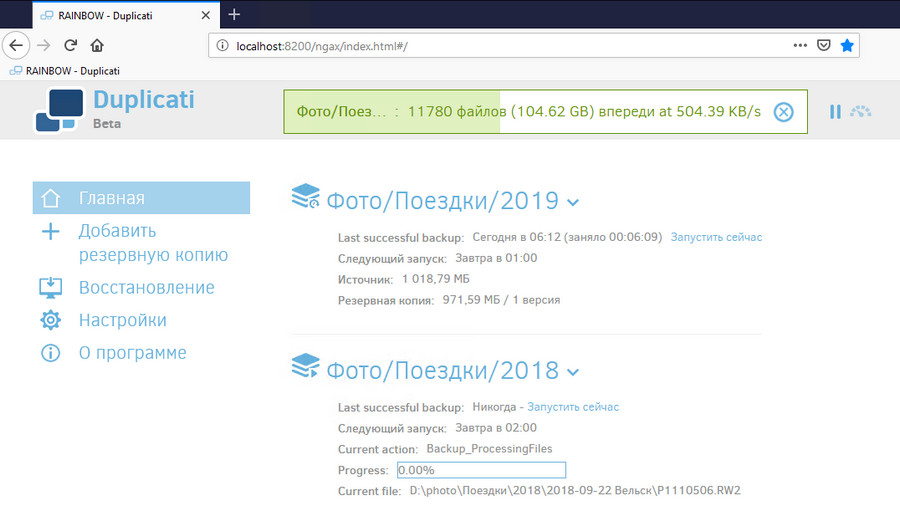
В облаке папка с бэкапом выглядит так — много zip-архивов, размер архива настраивается при создании задания:
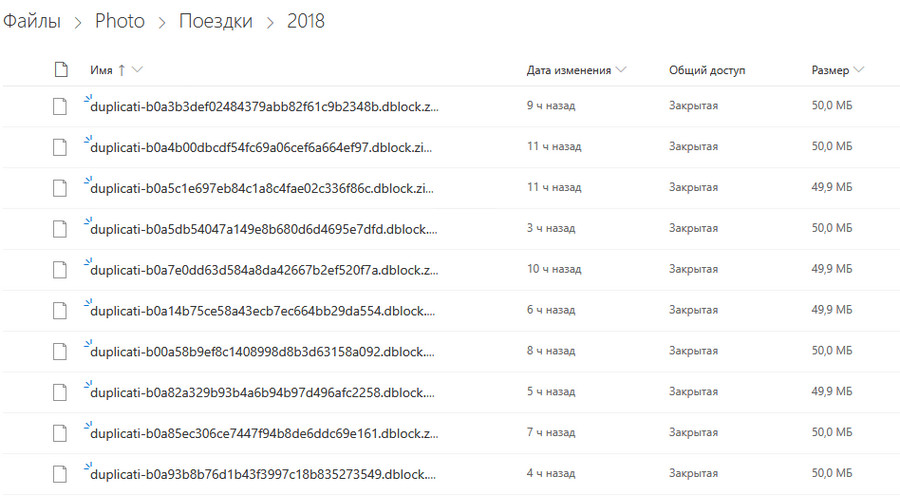
Примерно раз в месяц делаю копию на внешнем диске, который хранится в шкафу. Подключаю и руками запускаю задание с том же GoodSync. Хотя, конечно, можно и запуск по факту подключения диска настроить —, но мне далеко не всегда нужно сделать копию, когда подключаю диск.
По хорошему нужно бы ещё одно удалённое место хранения — своё и не сильно облачное. На моём сервере, который стоит на провайдерской площадке, у меня давно уже подготовлен диск под это дело, но всё руки не доходят. Но раз уж взялся за перетаскивание всего под duplicati, то, думаю, и это сделаю сейчас, после того, как перезалью всё в onedrive.
Как оно каталогизируется?
Тут вопрос разделяется на два — уровень файловой системы, где каталогизация идёт на уровне папок и логическая каталогизация по большему количеству параметров, потому что дерево папок всё же ограничено в возможностях.
Да, фотографирую я в равы. Потому что из raw в любой момент можно сделать jpg, но не наоборот. Когда-то снимал в raw+jpg, чтобы была возможность быстро перекинуть фото на телефон и отправить в интернет (raw на телефон передать было сложно). jpg потом стирал при копировании на десктоп. Но сейчас телефон меня стал устраивать по качеству фото (для выкладывания в интернет), потому от jpg на фотоаппаратах полностью отказался. Остались либо с тех времён, когда у меня не было беззеркалки, либо приходят с телефона.
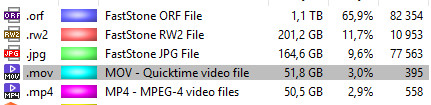
На уровне файловой системы выглядит как-то так: на верхнем уровне папок — источник. Имена фотографов обычно.
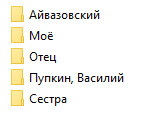
Уровнем ниже — темы. У всех более-менее одинаковые, могут быть персональные темы (к примеру «Собаки», каких-то тем может не быть.
Дальше — года. Внутри года папки по дням. В папке могут быть отдельные фотосессии, если фотографии за день бьются по темам.
В итоге путь к файлу может выглядеть примерно так: Моё\Поездки\2018\2018–04–11 Берлин\Французский вокзал\P4110029.ORF
Фотографирую я на два фотоаппарата, обычно по очереди, но изредка беру с собой оба — тогда фотографии с них сваливаю в одну папку. Главное — чтобы время было синхронизировано, иначе потом приходится высчитывать разницу и корректировать дату съёмки у всех файлов (в лайтруме это просто, но нудновато считать разницу во времени).
Для фото с телефона есть отдельная папка на втором уровне, но при необходимости фотография может быть отправлена в тематическую папку.
Логическая каталогизация поверх папок — Adobe Lightroom. Конечно, программ для каталогизации и обработки достаточно много, но лайтрум меня устраивает, вполне подъёмно стоит (и даже фотошоп в комплекте дают), а за последние пару лет ещё и тормозить меньше стал. Хотя, конечно, тут ещё и полный переход на SSD помог.
Все фотографии живут в одном каталоге. Базово используется структура папок из предыдущего пункта, поверх неё — информация EXIF, геометки, теги и цветовые отметки. Ещё можно распознавание лиц включить, но я им не пользуюсь.
На основе всего вышеперечисленного можно создавать «умные коллекции» — динамические выборки по определённым свойствам файла — от параметров съёмки до текста в комментариях.
Все теги хранятся в файлах, история редактирования — в XMP-файлах рядом с равами. Каталог лайтрума бэкапится средствами самого же лайтрума раз в неделю в определённую папку, откуда потом закидывается на onedrive. Ну и плюсом через veeam agent системный диск десктопа каждый день заливается на сервер —, а каталог как раз на системном диске хранится.
А что всё про фото? Что, других типов файлов нет?
Есть, почему нету. Методы бэкапа не отличаются (если вообще надо бэкапить), а методы каталогизации от типа контента зависят.
В основном хватает сортировки на уровне папок, теги не нужны. Только для фильмов и сериалов отдельный каталогизатор используется. — Plex Media Server. Он же и медиасервер, как следует из названия. Но там конь не валялся, нормально отсортирована хорошо если четверть фильмотеки, а остальное валяется в папке »! to sort».
