HighLoad++, Михаил Макуров, Максим Чернецов (Интерсвязь): Zabbix, 100kNVPS на одном сервере
Следующая конференция HighLoad++ пройдет 6 и 7 апреля 2020 года в Санкт-Петербурге Подробности и билеты по ссылке. HighLoad++ Moscow 2018. Зал «Москва». 9 ноября, 15:00. Тезисы и презентация.

* Мониторинг — онлайн и аналитика.
* Основные ограничения платформы ZABBIX.
* Решение для масштабирования хранилища аналитики.
* Оптимизация сервера ZABBIX.
* Оптимизация UI.
* Опыт эксплуатации системы при нагрузках более 40k NVPS.
* Коротко выводы.
Михаил Макуров (далее — ММ): — Всем привет!
Максим Чернецов (далее — МЧ): — Добрый день!
ММ: — Разрешите мне представить Максима. Макс — талантливый инженер, лучший сетевик, которого я знаю. Максим занимается сетями и сервисами, их развитием и эксплуатацией.

МЧ: — А я бы хотел рассказать о Михаиле. Михаил — разработчик на Си. Он написал несколько высоконагруженных решений по обработке трафика для нашей компании. Мы живём и работаем на Урале, в городе суровых мужиков Челябинске, в компании «Интерсвязь». Наша компания — это поставщик услуг интернета и кабельного телевидения для одного миллиона человек в 16 городах.
ММ: — И стоит сказать, что «Интерсвязь» — гораздо больше, чем просто провайдер, это IT-компания. Большинство наших решений сделано силами нашего IT-отдела.
А: от серверов, обрабатывающих трафик, до колл-центра и мобильного приложения. В IT-отделе сейчас около 80 человек с очень и очень разнообразными компетенциями.
О Zabbix и его архитектуре
МЧ: — А теперь я попробую поставить личный рекорд и за одну минуту сказать, что же такое Zabbix (далее — «Заббикс»).
«Заббикс» позиционирует себя как систему мониторинга «из коробки» уровня предприятия. В нём есть много упрощающих жизнь функций: развитые правила эскалации, API для интеграции, группировка и автообнаружение хостов и метрик. В «Заббиксе» есть так называемые средства масштабирования — прокси. «Заббикс» — это система с открытым исходным кодом.
Коротко об архитектуре. Можно сказать, она состоит из трёх компонентов:
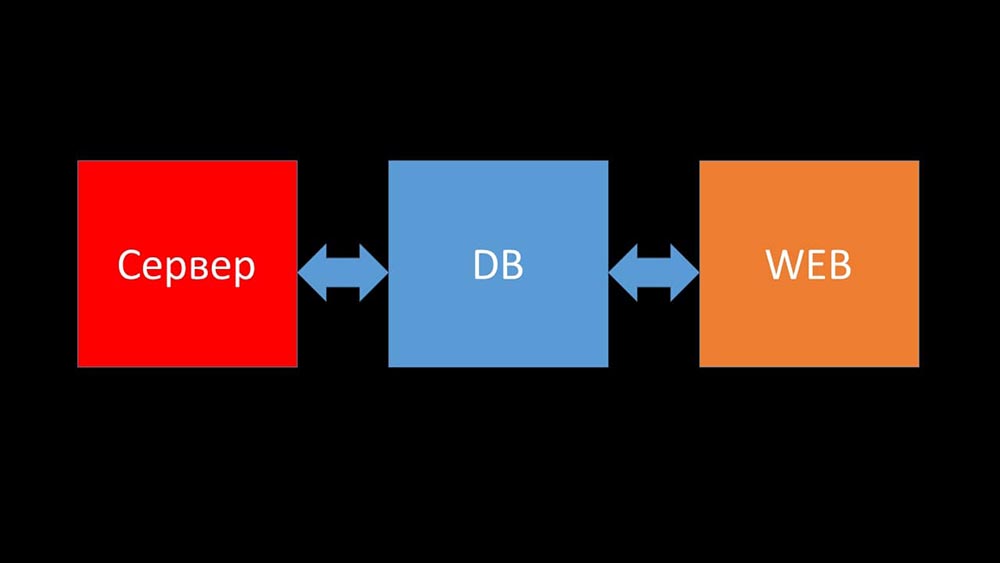
- Сервер. Написан на Си. С достаточно сложной обработкой и передачей информации между потоками. Вся обработка происходит в нём: от получения до сохранения в базу.
- Все данные хранятся в базе. «Заббикс» поддерживает MySQL, PostreSQL и Oracle.
- Веб-интерфейс написан на PHP. В большинстве систем поставляется с сервером Apache, но более эффективно работает в связке nginx + php.
Сегодня мы хотели бы рассказать из жизни нашей компании одну историю, связанную с «Заббикс»…
История из жизни компании «Интерсвязь». Что имеем и что нужно?

5 или 6 месяцев тому назад. Однажды после работы…
МЧ: — Миша, привет! Рад, что успел тебя поймать — есть разговор. У нас снова были проблемы с мониторингом. Во время крупной аварии всё тормозило, и не было никакой информации о состоянии сети. К сожалению, это повторяется уже не в первый раз. Мне нужна твоя помощь. Давай сделаем так, чтобы наш мониторинг работал при любых обстоятельствах!
ММ: — Но давай сначала синхронизируемся. Я не смотрел туда уже пару лет. Насколько я помню, мы отказались Nagios и перешли на «Заббикс» лет 8 назад. И сейчас у нас, кажется, 6 мощных серверов и около десятка прокси. Я ничего не путаю?
МЧ: — Почти. 15 серверов, часть из которых виртуальные машины. Самое главное, что это не спасает нас в тот момент, когда нужно больше всего. Как авария — сервера тормозят и ничего не видно. Мы пробовали оптимизировать конфигурацию, но оптимального прироста производительности это не даёт.
ММ: — Понятно. Что-то смотрели, что-то уже накопали из диагностики?
МЧ: — Первое, с чем приходится иметь дело — это как раз БД. MySQL итак постоянно нагружен, сохраняя новые метрики, а когда «Заббикс» начинает генерировать кучу событий — база уходит в себя буквально на несколько часов. Про оптимизацию конфигурации я тебе уже рассказал, а вот буквально в этом году обновляли железо: на серверах стоит больше сотни гигов памяти и дисковые массивы на SSD RAID-ах — линейно растить его дальне нет смысла. Что будем делать?
ММ: — Понятно. Вообще, MySQL — это LTP-база. Видимо, она больше не подходит для хранения архива метрик нашего размера. Давай разбираться.
МЧ: — Давай!
Интеграция Zabbix и Clickhouse как итог хакатона
Через некоторое время мы получили интересные данные:

Большая часть места в нашей базе была занята архивом метрик и менее 1% использовалось под конфигурацию, шаблоны и настройки. К тому моменту мы уже более года эксплуатировали решение Big data на базе Clickhouse. Направление движения для нас было очевидным. На нашем весеннем «Хакатоне» написал интеграцию «Заббикса» с «Кликхаусом» для сервера и фронтенда. На тот момент в «Заббиксе» уже была поддержка ElasticSearch, и мы решили сравнить их.

Сравнение Clickhouse и Elasticsearch
ММ: — Для сравнения мы генерировали нагрузку такую же, какую обеспечивает «Заббикс»-сервер и смотрели, как себя будут вести системы. Мы писали данные пачками по 1000 строк, использовали CURL. Мы заранее предполагали, что «Кликхаус» будет более эффективным для того профиля нагрузки, которую делает «Заббикс». Результаты даже превзошли наши ожидания:

В одинаковых условиях на тестах «Кликхаус» писал в три раза больше данных. При этом обе системы очень эффективно потребляли (малое количество ресурсов), читая данные. Но «Эластиксу» при записи требовалось большое количество процессора:
Суммарно «Кликхаус» значительно превосходил «Эластикс» по потреблению процессора и по скорости. При этом за счёт сжатия данных «Кликхаус» использует в 11 раз меньше на жёстком диске и делает примерно в 30 раз меньше дисковых операций:
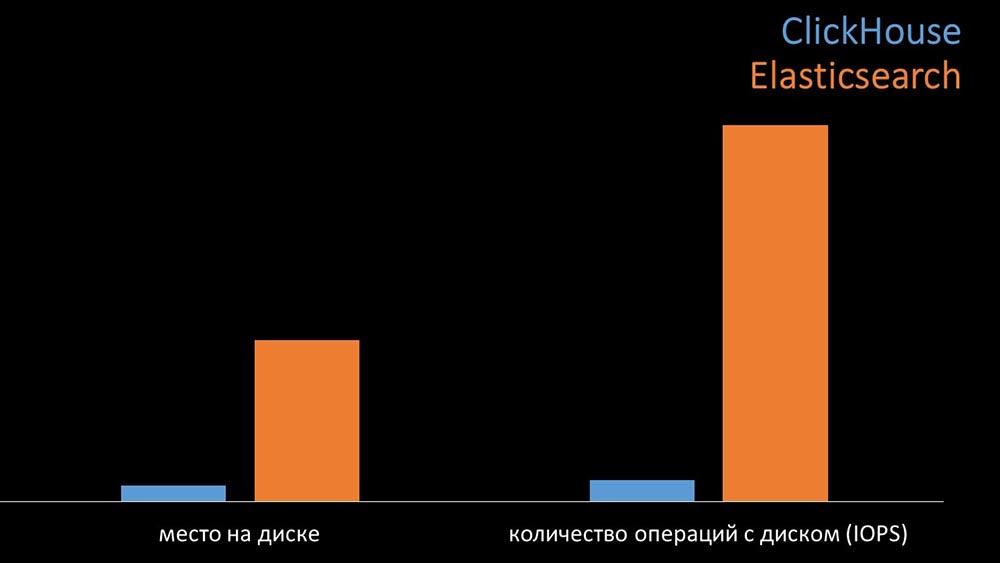
МЧ: — Да, работа с дисковой подсистемой у «Кликхауса» реализована очень эффективно. Под базы можно использовать огромные SATA-диски и получать скорость записи в сотни тысяч строк в секунду. Система «из коробки» поддерживает шардинг, репликацию, весьма проста в настройке. Мы более чем довольны её эксплуатацией в течение года.
Для оптимизации ресурсов можно установить «Кликхаус» рядом с существующей основной базой и тем самым сохранить уйму процессорного времени и дисковых операций. Мы вынесли архив метрик на уже имеющиеся «Кликхаус»-кластеры:
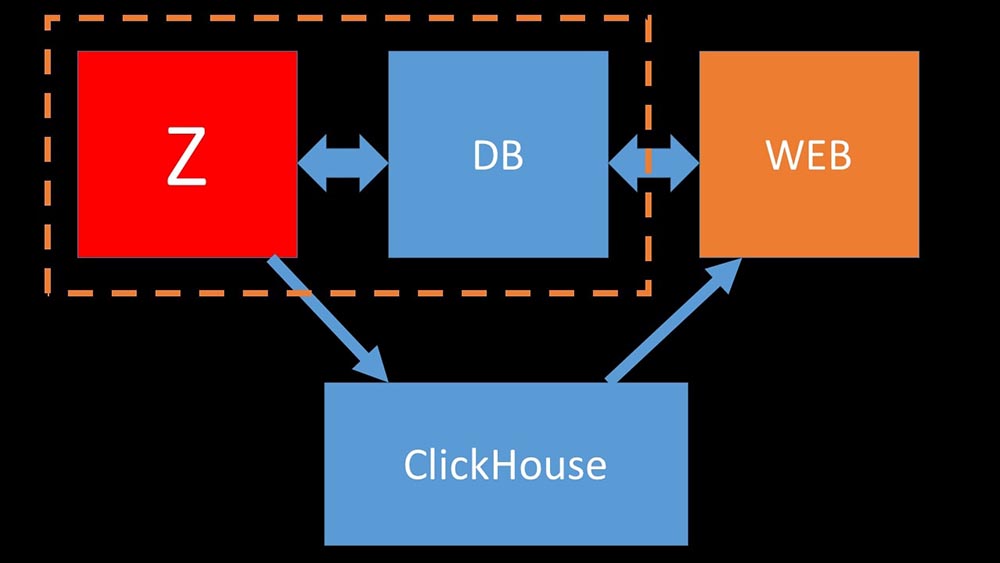
Мы настолько разгрузили основную MySQL-базу, что могли объединить её на одной машине с «Заббикс»-сервером и отказаться от выделенного сервера под MySQL.
Как устроен polling в Zabbix?
4 месяца назад
ММ: — Ну что, о проблемах с базой можно забыть?
МЧ: — Это точно! Другая задача, которую нам нужно решить — это медленный сбор данных. Теперь все наши 15 прокси-серверов перегружены процессами SNMP и поллинга. И нет никаких, кроме как ставить новые и новые серверы.
ММ: — Отлично. Но расскажи сперва, как устроен поллинг в «Заббикс»?
МЧ: — Если коротко, то существует 20 типов метрик и десяток способов их получения. «Заббикс» может собирать данные либо в режиме «запрос — ответ», либо ожидать новые данные через «Интерфейс Траппера».

Стоит заметить, что в оригинальном «Заббиксе» этот способ (Trapper) — самый быстрый.
Существуют прокси-серверы для распределения нагрузки:
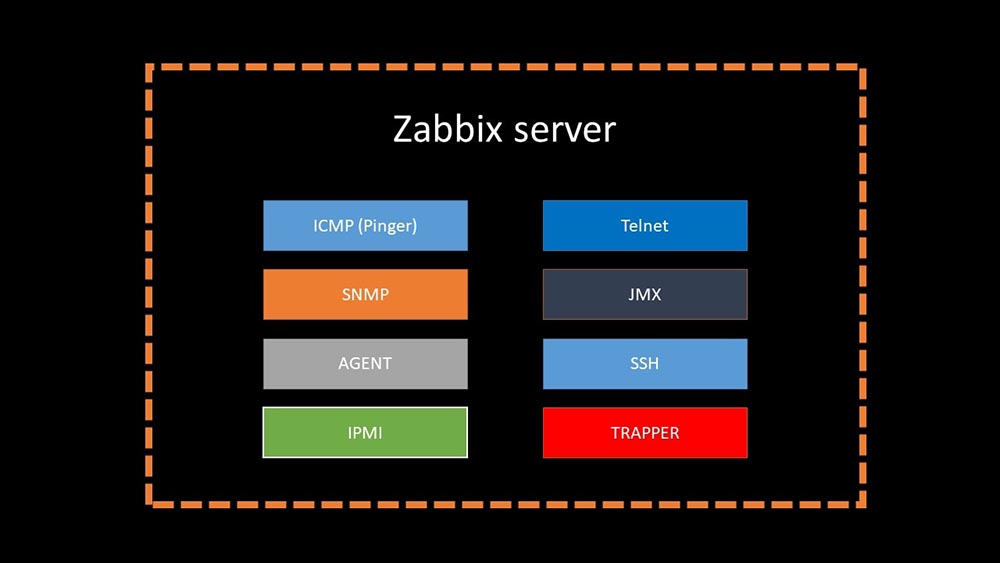
Прокси могут выполнять те же функции сбора, что и «Заббикс»-сервер, получая с него задания и отсылая собранные метрики как раз через Траппер-интерфейс. Это официально рекомендованный способ распределения нагрузки. Также прокси полезны для мониторинга удалённой инфраструктуры, работающей через NAT или медленный канал:

ММ: — С архитектурой всё понятно. Надо смотреть исходники…
Пару дней спустя
Сказ о том, как nmap fping победил
ММ: — Кажется, я что-то накопал.
МЧ: — Рассказывай!
ММ: — Я обнаружил, что при проверках доступности «Заббикс» делает проверку максимум до 128 хостов одновременно. Я попробовал увеличить эту цифру до 500 и убрал межпакетный интервал в их пинге (ping) — это увеличило производительность раза в два. Но хотелось бы больших цифр.
МЧ: — В своей практике мне иногда приходится проверять доступность тысяч хостов, и ничего быстрее nmap я для этого не встречал. Я уверен, что это самый быстрый способ. Давай его попробуем! Нужно значительно увеличить количество хостов за одну итерацию.
ММ: — Проверять больше пятисот? 600?
МЧ: — Как минимум пару тысяч.
ММ: — Окей. Самое главное, что хотел сказать: я нашёл, что большинство поллинга в «Заббиксе» сделано синхронно. Мы обязательно должны его переделать на асинхронный режим. Тогда мы сможем кардинально увеличить количество метрик, собираемых поллерами, особенно если мы увеличим количество метрик за одну итерацию.
МЧ: — Здорово! И когда?
ММ: — Как обычно, вчера.
МЧ: — Мы сравнили обе версии fping и nmap:
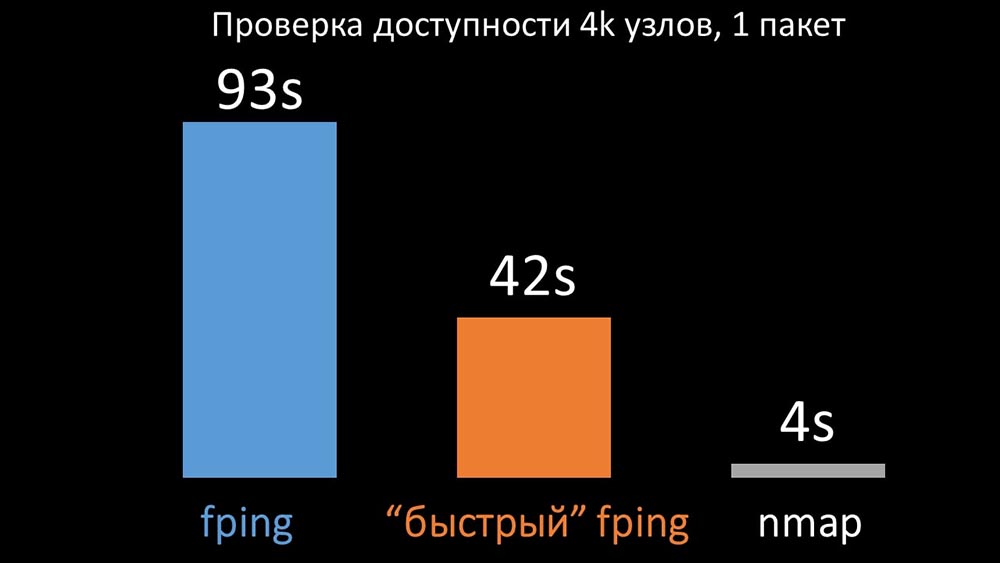
На большом количестве хостов nmap был ожидаемо до пяти раз эффективнее. Так как nmap проверяет только факт доступности и время отклика, подсчёт потерь мы перенесли в триггеры и значительно сократили интервалы проверки доступности. Оптимальным количеством хостов для nmap мы нашли в районе 4 тысяч за одну итерацию. Nmap позволил нам в три раза снизить затраты ЦПУ на проверки доступности и сократить интервал с 120 секунд до 10.
Оптимизация поллинга
ММ: — Затем мы занялись поллерами. В основном нас интересовал съём SNMP и агенты. В «Заббиксе» поллинг сделан синхронно и приняты специальные меры для того, чтобы увеличивать эффективность системы. В синхронном режиме недоступность хостов вызывает значительную деградацию поллинга. Существует целая система состояний, существуют специальные процессы — так называемые unreachable-поллеры, которые работают только с недоступными хостами:
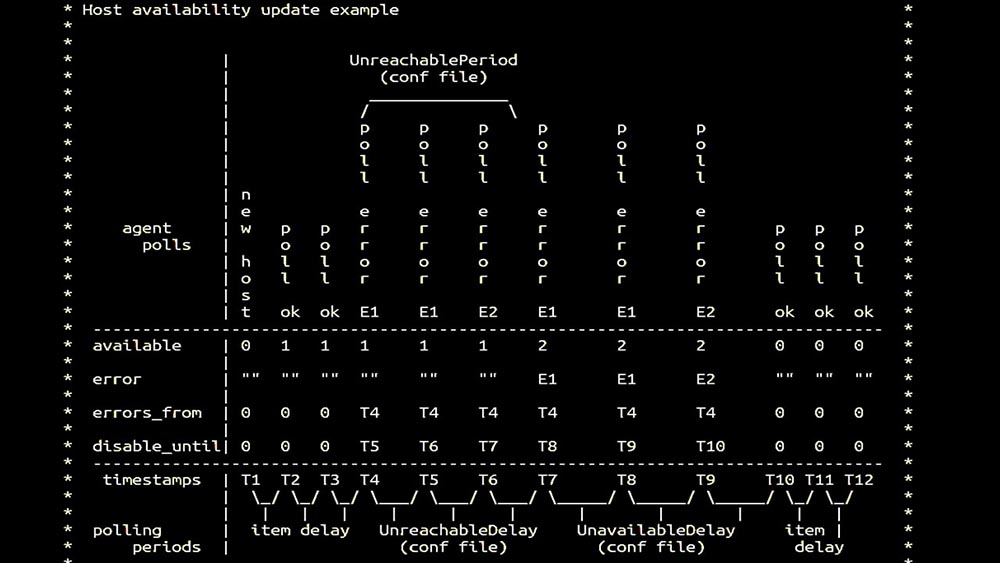
Это комментарий, который демонстрирует матрицу состояний, всю сложность системы переходов, которые требуются для того, чтобы системе оставаться эффективной. Кроме того, сам синхронный поллинг достаточно медленный:
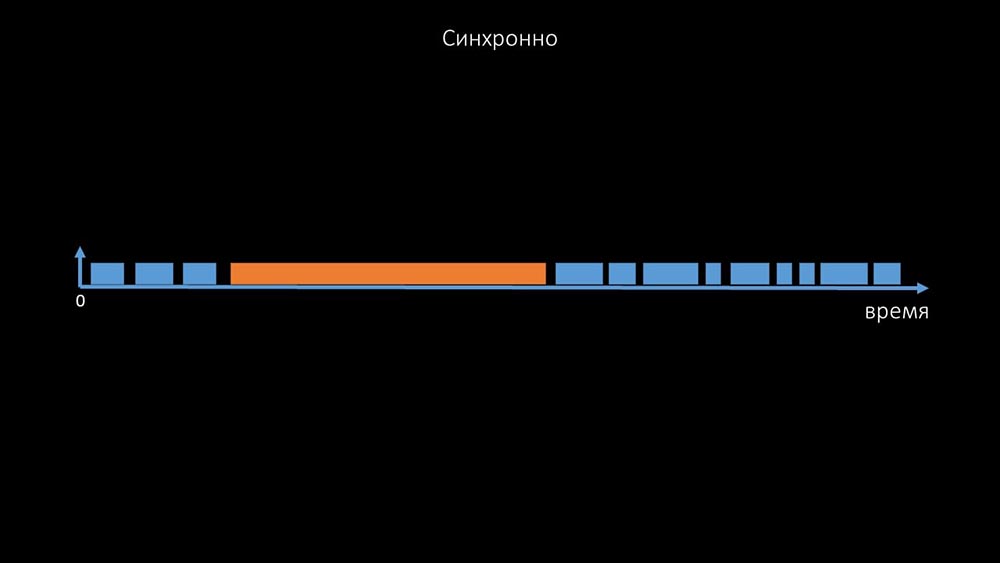
Именно поэтому тысячи потоков поллеров на десятке прокси не могли собрать для нас нужного количества данных. Асинхронная реализация решила не только проблемы с количеством потоков, но и значительно упростила систему состояний недоступных хостов, потому что при любом количестве, проверяемых в одной итерации поллинга, максимальное время ожидания составляло 1 тайм-аут:
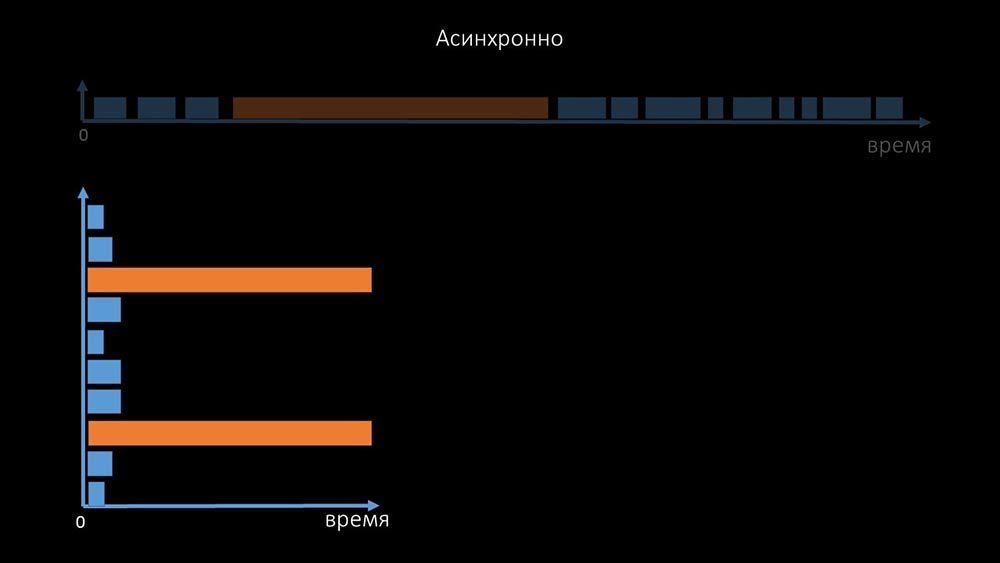
Дополнительно мы модифицировали, доработали систему поллинга для SNMP-запросов. Дело в том, что большинство не могут отвечать на несколько SNMP-запросов одновременно. Поэтому мы сделали гибридный режим, когда SNMP-поллинг одного и того же хоста делает асинхронно:
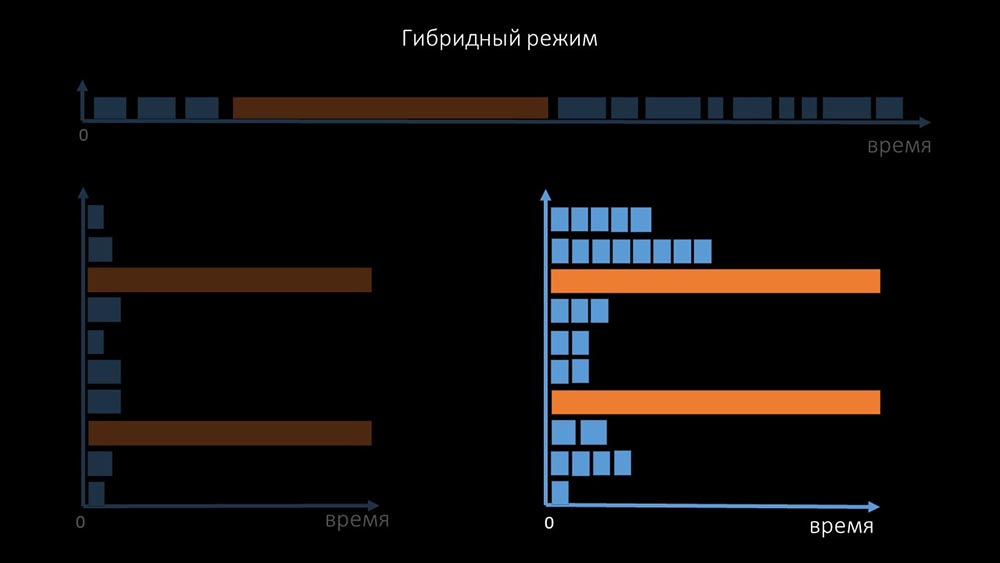
Это делается для всей пачки хостов. Такой режим в итоге не медленнее, чем полностью асинхронный, так как опрос полутора сотен SNMP-значений всё равно гораздо быстрее, чем 1 тайм-аут.
Наши эксперименты показали, что оптимальное количество запросов в одной итерации — примерно 8 тысяч при SNMP-поллинге. Суммарно переход на асинхронный режим позволил ускорить производительность поллинга в 200 раз, в несколько сотен раз.
МЧ: — Полученные оптимизации поллинга показали, что мы не только можем избавиться от всех прокси, но и сократить интервалы по многим проверкам, а прокси станут не нужны как способ разделения нагрузки.
Около трёх месяцев назад
Измени архитектуру — увеличь нагрузку!
ММ: — Ну что, Макс, пора в продуктив? Мне нужен мощный сервер и хороший инженер.
МЧ: — Хорошо, запланируем. Давно пора сдвинуться с мёртвой точки в 5 тысяч метрик в секунду.
Утро после апгрейда
МЧ: — Миша, мы обновились, но к утру откатились обратно… Отгадай, какой скорости удалось достичь?
ММ: — Тысяч 20 максимум.
МЧ: — Ага, 25! К сожалению, мы там же, с чего начали.
ММ: — А что так? Диагностику сняли какую-нибудь?
МЧ: — Да, конечно! Вот, например, интересный top:
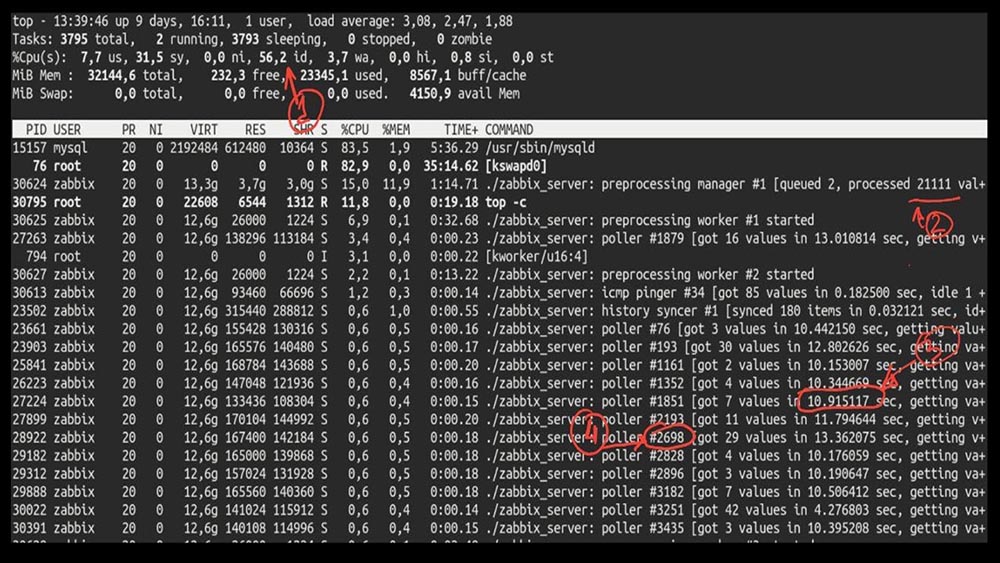
ММ: — Давай посмотрим. Я вижу, что мы пробовали огромное количество потоков поллинга:
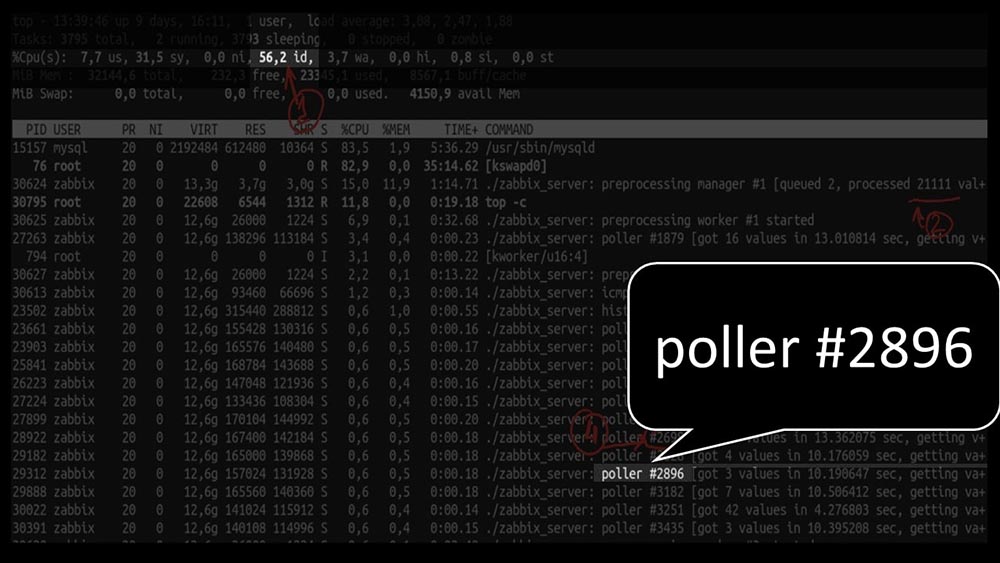
Но при этом не смогли утилизировать систему даже наполовину:
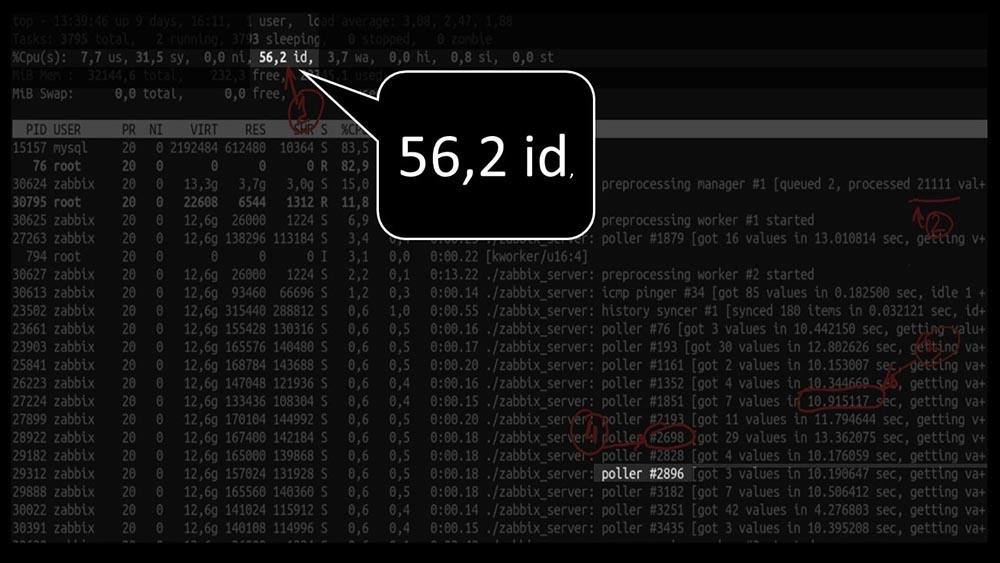
А общая производительность достаточно маленькая, около 4 тысяч метрик в секунду:
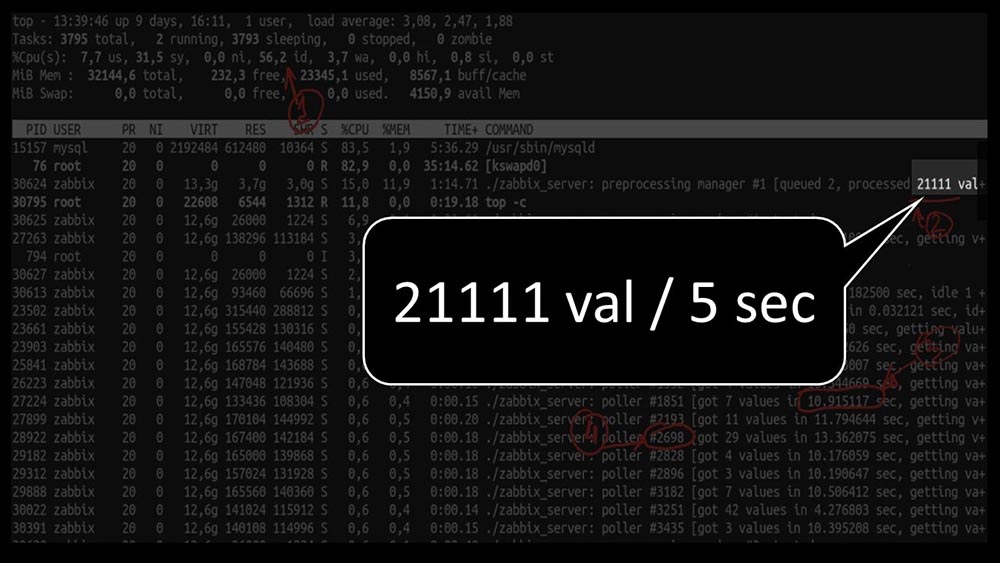
Есть что-нибудь ещё?
МЧ: — Да, strace одного из поллеров:
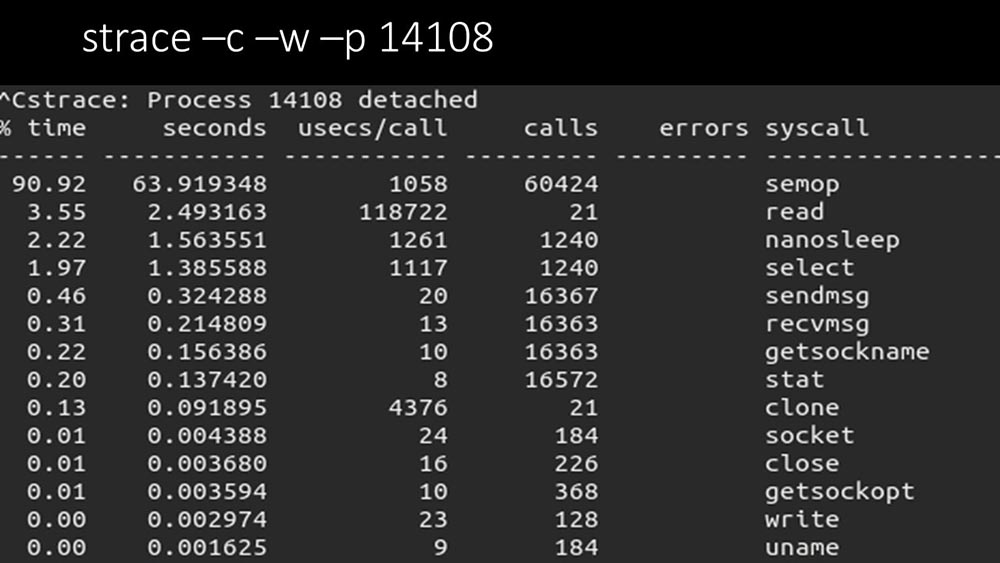
ММ: — Здесь чётко видно, что процесс поллинга ждёт «семафоров». Это блокировки:
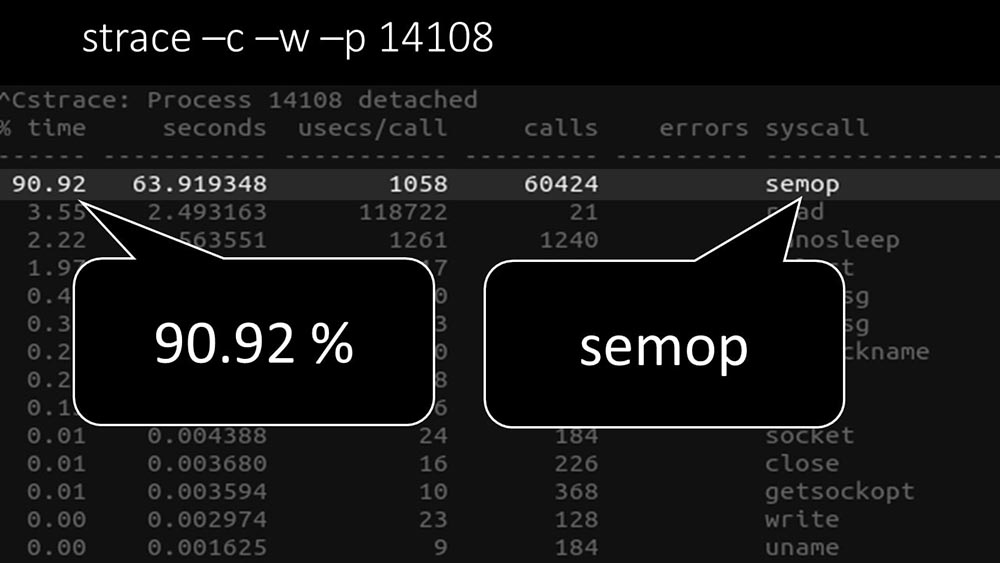
МЧ: — Непонятно.
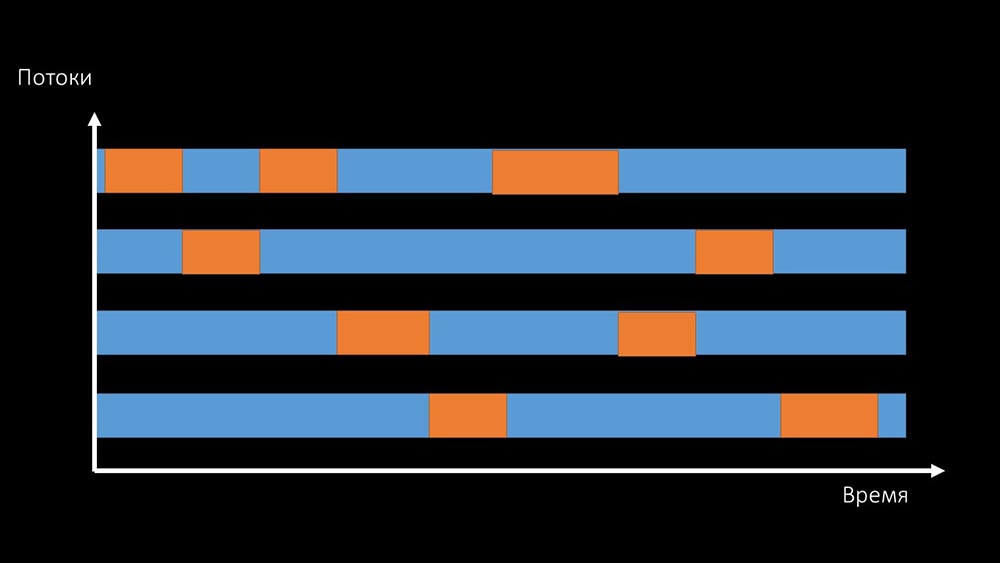
ММ: — Смотри, это похоже на ситуацию, когда куча потоков пытается работать с ресурсов, с которым одновременно можно работать только одному. Тогда всё, что они могут делать — разделять этот ресурс по времени:

И суммарная производительность работы с таким ресурсом ограничивается скоростью одного ядра:
Решить такую проблему можно двумя способами.
Апгредить железо машины, переходить на более быстрые ядра:
Или менять архитектуру и параллельно — нагрузку:
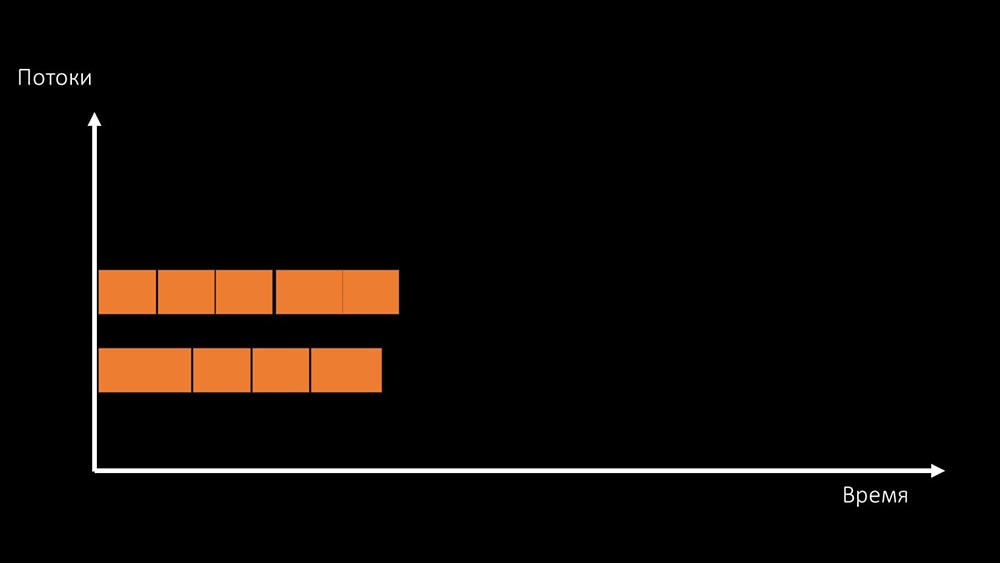
МЧ: — Кстати говоря, на тестовой машине пустим меньшее количество ядер, чем на боевой, но зато они раза в 1,5 быстрее по частоте на ядро!
ММ: — Ясно? Надо смотреть код сервера.
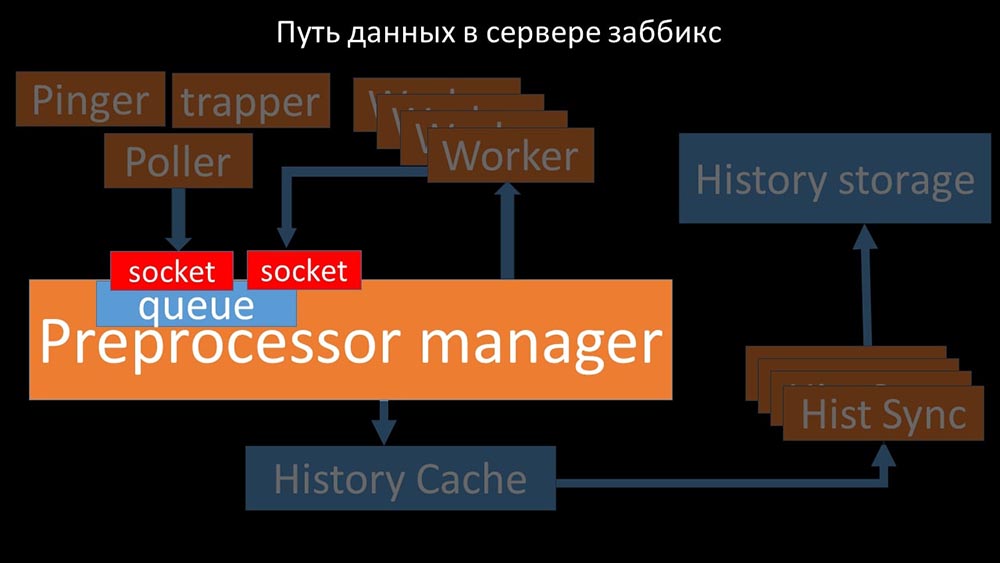
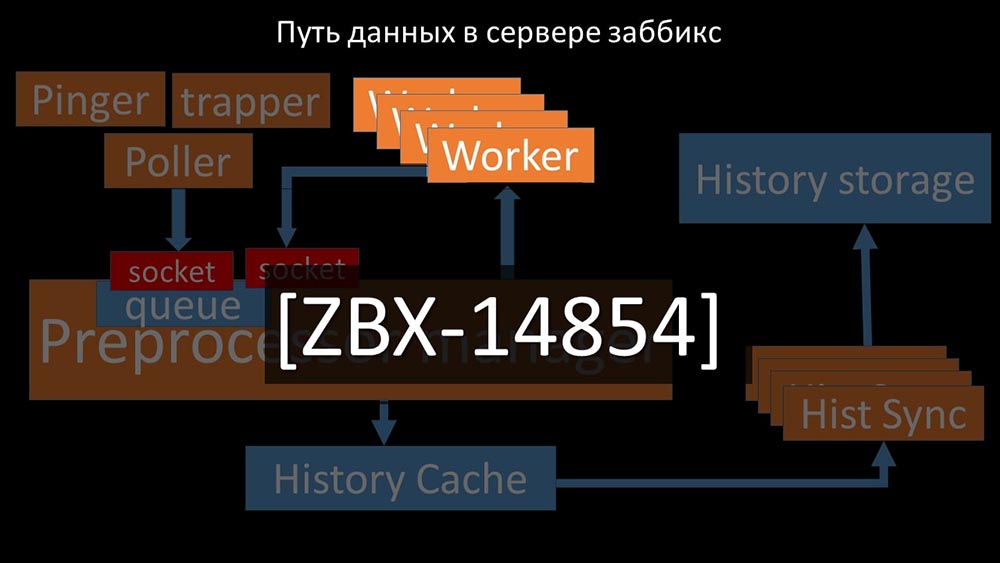
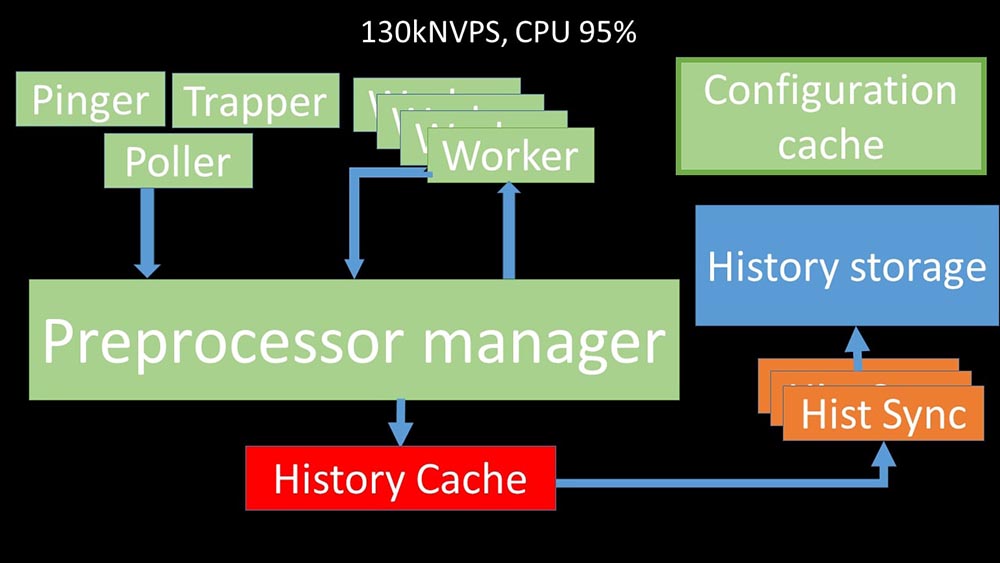
Путь данных в сервере Zabbix
МЧ: — Чтобы разобраться, мы стали анализировать, как данные передаются внутри «Заббикс»-сервера:
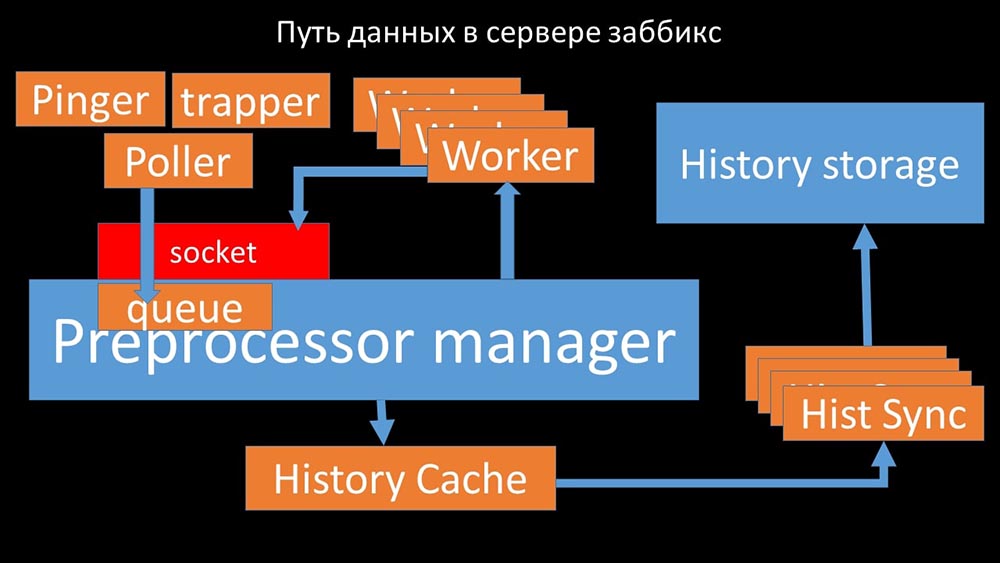
Классная картинка, правда? Давайте пройдёмся по ней шаг за шагом, чтобы более-менее прояснить. Есть потоки и сервисы, ответственные за сбор данных:
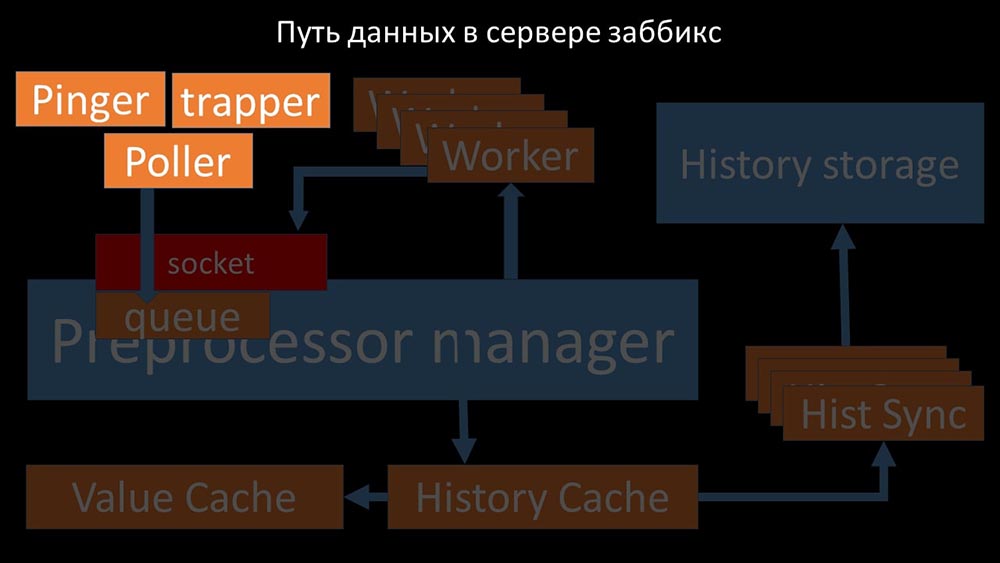
Собранные метрики они передают через сокет в Preprocessor manager, где сохраняются в очередь:
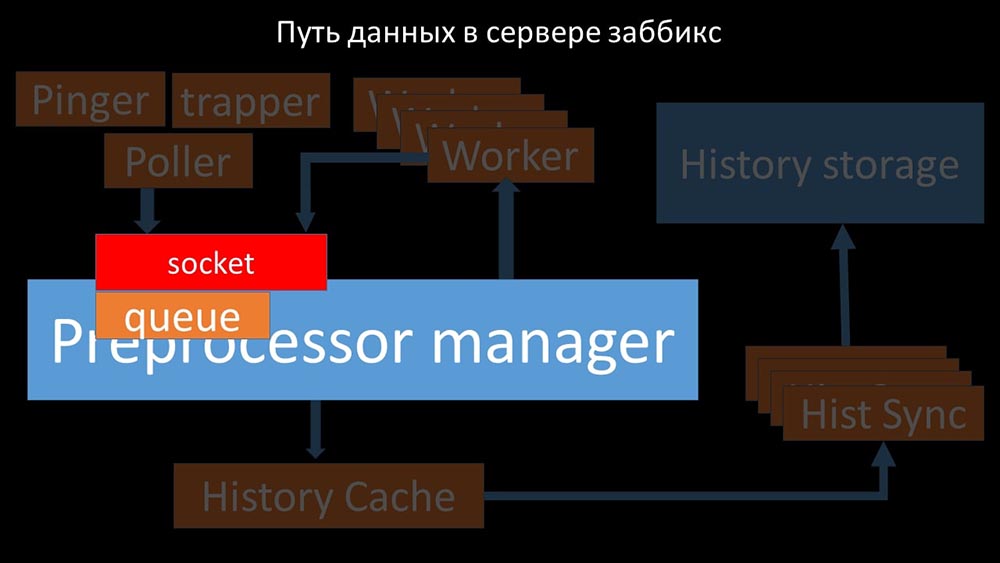
Препроцессор-менеджер» передаёт данные своим воркерам, которые выполняют инструкции предобработки и возвращают их обратно через тот же сокет:
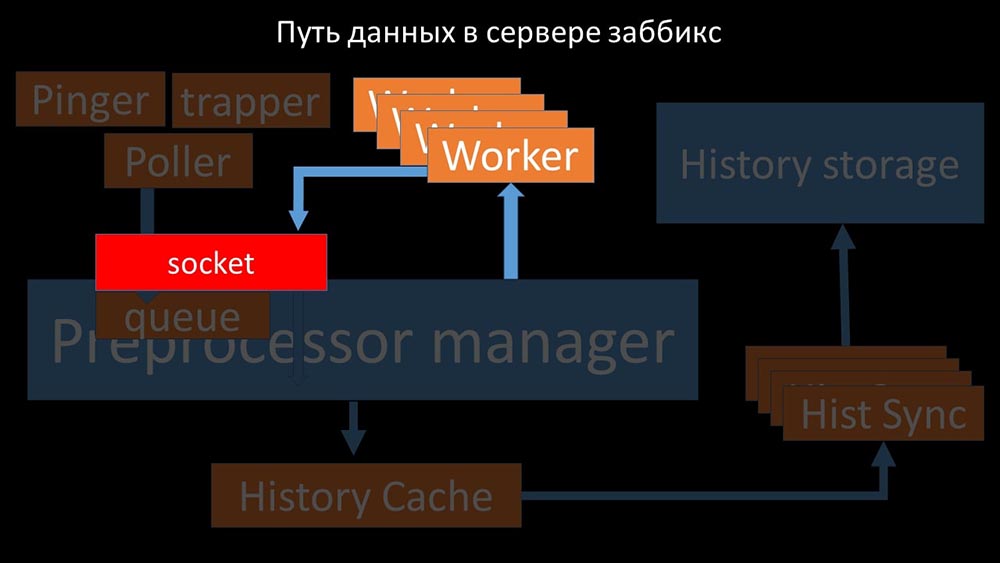
После этого препроцессор-менеджер сохраняет их в кэше истории:
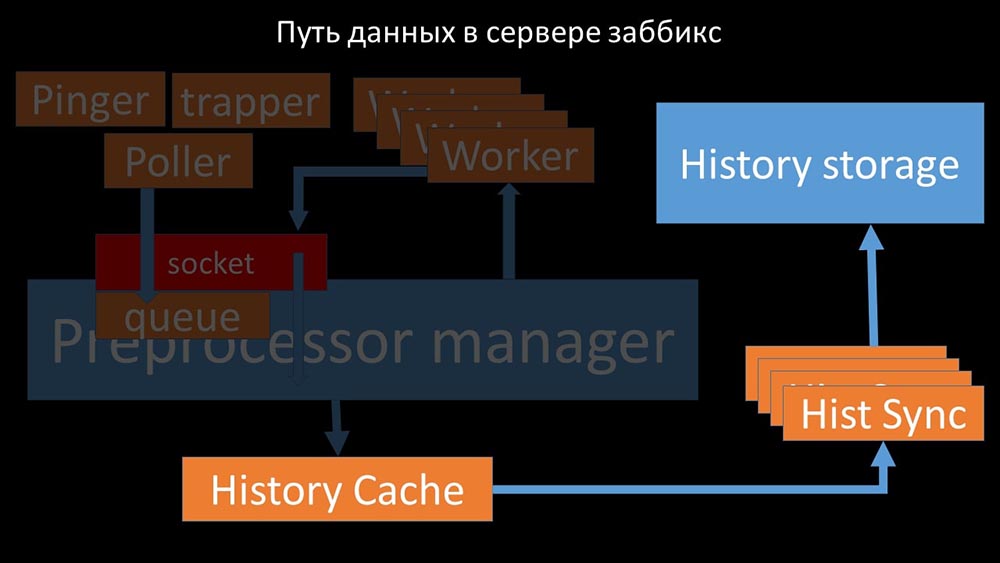
Оттуда их забирают хистори-синкеры, выполняющие достаточно много функций: например, вычисление триггеров, заполнение кэша значений и, самое главное, сохранение метрик в хранилище истории. В общем, процесс сложный и весьма запутанный.

ММ: — Первое, что мы увидели — это то, что большинство потоков конкурирует за так называемый «конфигурационный кэш» (область памяти, где хранятся все конфигурации сервера). Особенно много блокировок делают потоки, ответственные за съём данных:
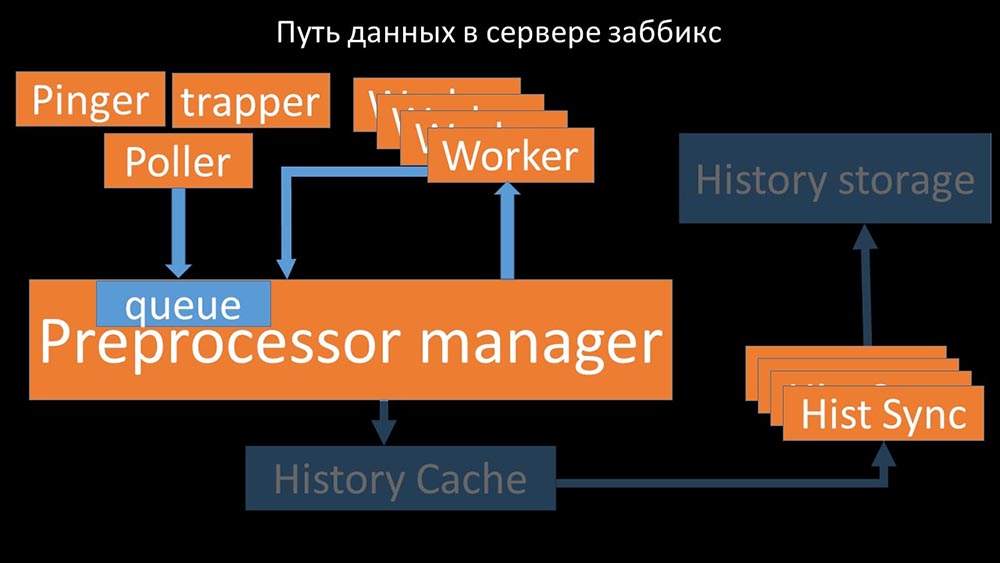
…так как в конфигурации хранятся не только метрики с их параметрами, но и очереди, из которых поллеры берут информацию о том, что им делать дальше. Когда поллеров много, и один блокирует конфигурацию, остальные ждут запросов:

Поллеры не должны конфликтовать
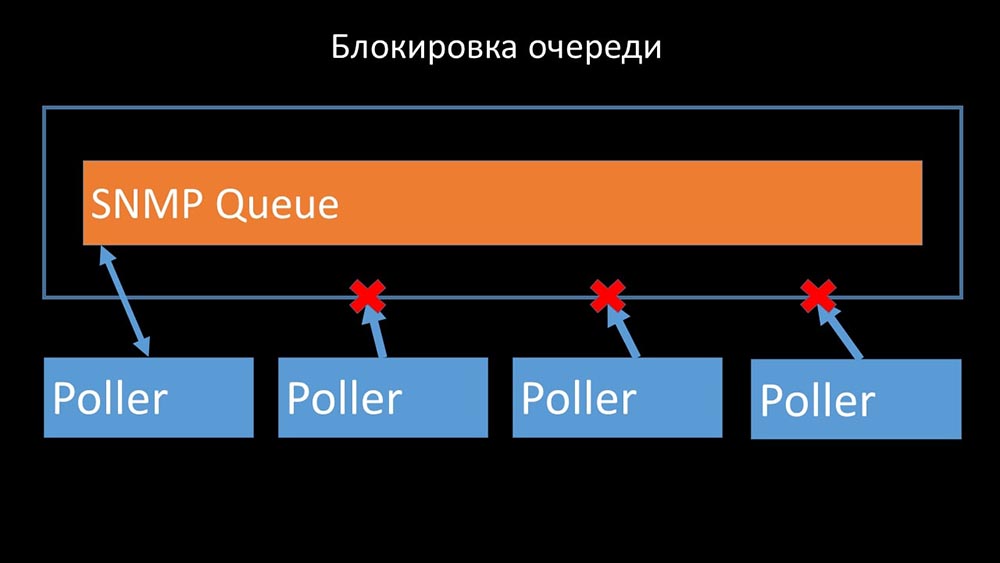
Поэтому первое, что мы сделали — разделили очередь на 4 части и разрешили поллерам в безопасных условиях блокировать эти очереди, эти части одновременно:
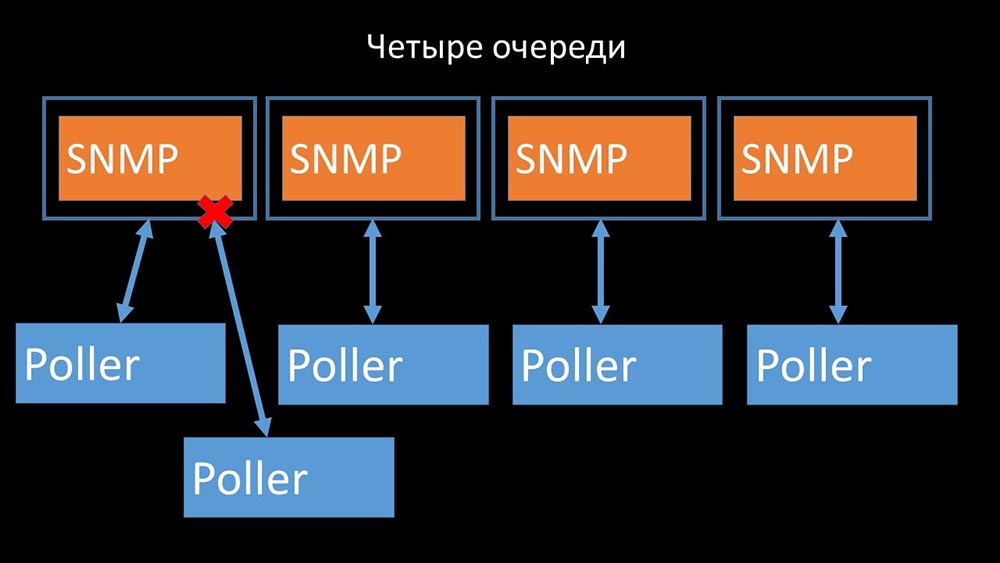
Это убрало конкуренцию за конфигурационный кэш, и скорость работы поллеров значительно выросла. Но затем мы столкнулись с тем, что препроцессор-менеджер начал копить очередь заданий:

Preprocessor manager должен уметь расставить приоритеты
Это происходило в случаях, когда ему не хватало производительности. Тогда всё, что он мог делать — копить запросы от процессов сбора данных и складывать их буфер до тех пор, пока он не съедал всю память и падал:
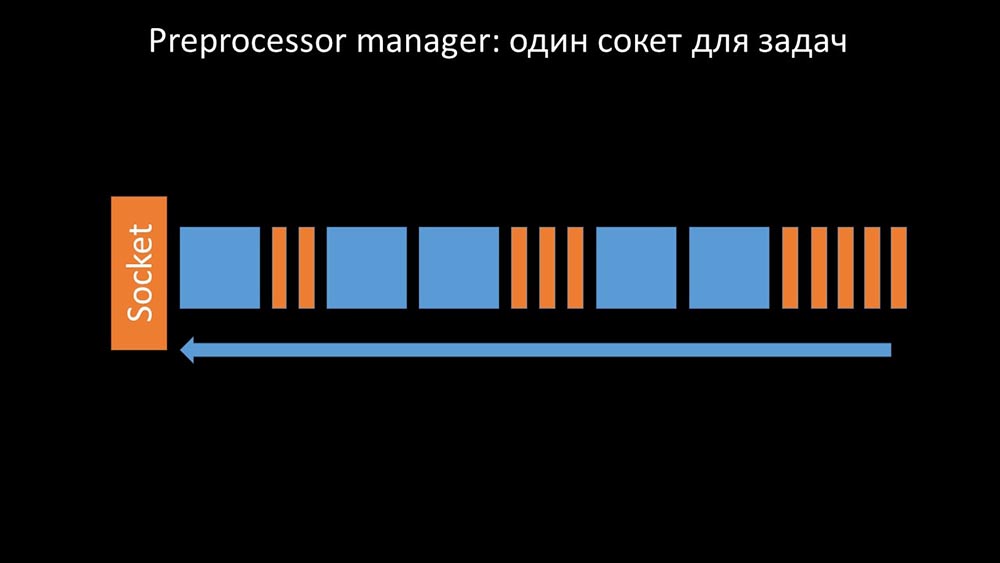
Чтобы решить эту проблему, мы добавили второй сокет, который был выделен специально для воркеров:
Таким образом, препроцессор-менеджер получил возможность приоритизировать свою работу и в случае разрастания буфера задача тормозить съём, давая воркерам возможность этот буфер забрать:
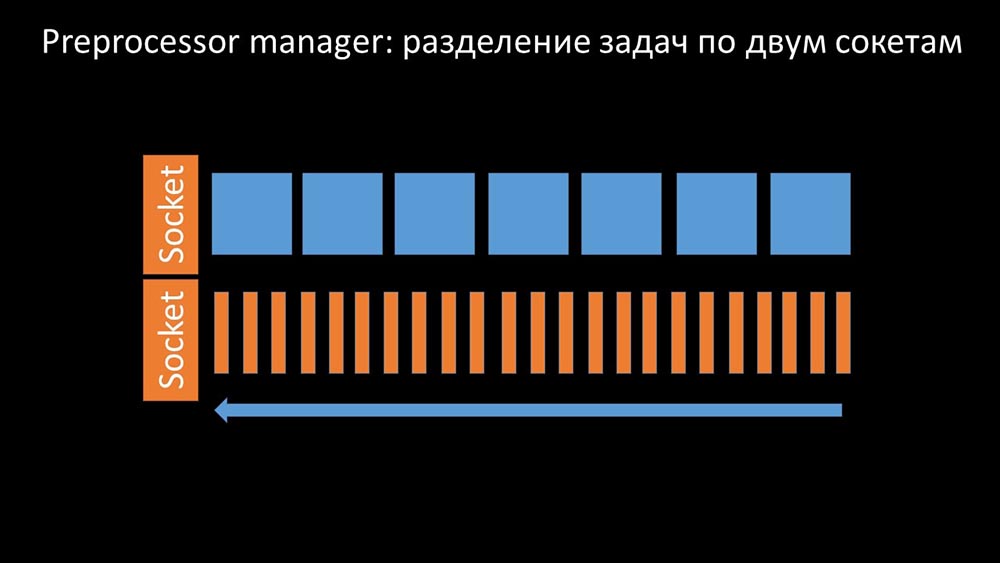
Затем мы обнаружили, что одной из причин торможения были сами воркеры, поскольку они конкурировали за совершенно не важный для их работы ресурс. Эту проблему мы оформили bug-fix«ом, и в новых версиях «Заббикса» она уже решена:
Увеличиваем количество сокетов — получаем результат
Далее сам препроцессор-менеджер стал узким звеном, поскольку это — один поток. Он упирался в скорость ядра, давая максимальную скорость примерно в 70 тысяч метрик в секунду:
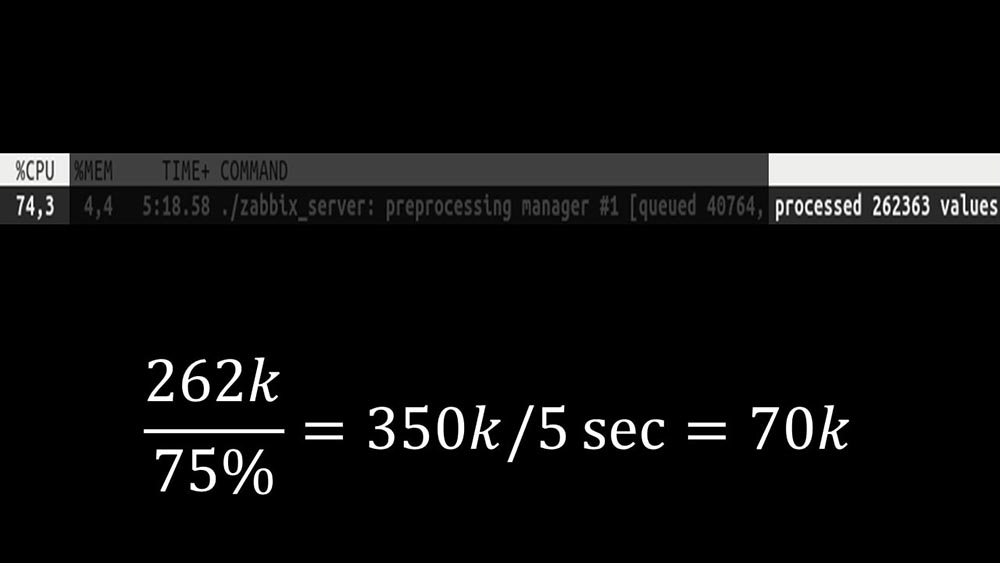
Поэтому мы сделали четыре, с четырьмя наборами сокетов, воркеров:
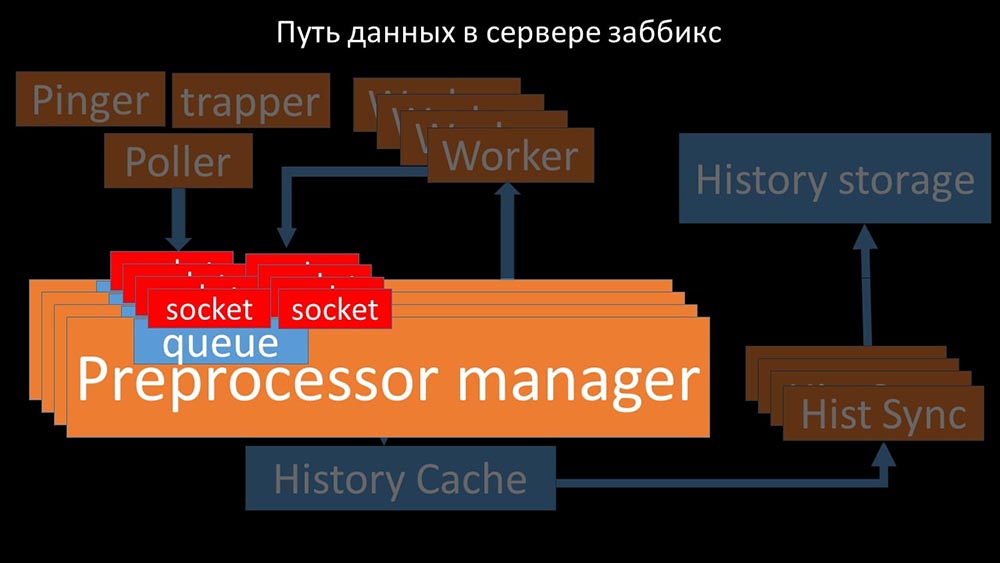
И это позволило увеличить скорость примерно до 130 тысяч метрик:

Нелинейность роста объясняется тем, что появилась конкуренция за кэш истории. За него конкурировали 4 препроцессор-менеджера и хистори-синкеры. К этому моменту мы получали на тестовой машине примерно 130 тысяч метрик в секунду, утилизируя её примерно на 95% по процессору:
Около 2,5 месяцев назад
Отказ от snmp-community увеличил NVPs в полтора раза
ММ: — Макс, мне нужна новая тестовая машина! В текущую мы больше не влезаем.
МЧ: — А что есть сейчас?
ММ: — Сейчас — 130k NVPs и процессор «в полку».
МЧ: — Ух ты! Круто! Погоди, у меня два вопроса. По моим подсчётам, наша потребность — в районе 15–20 тысяч метрик в секунду. Зачем нам больше?
ММ: — Хочется доделать дело до конца. Хочется посмотреть, сколько мы сможем выжать из этой системы.
МЧ: — Но…
ММ: — Но для бизнеса бесполезно.
МЧ: — Понятно. И второй вопрос: то, что есть сейчас, мы сможем поддерживать самостоятельно, без помощи разработчика?
ММ: — Я не думаю. Изменение работы с конфигурационным кэшем — это проблема. Она касается изменений в большинстве потоков и достаточно сложна в поддержке. Скорее всего, поддерживать её будет очень тяжело.
МЧ: — Тогда нужно какую-то альтернативу.
ММ: — Есть такой вариант. Мы можем перейти на быстрые ядра, при этом отказавшись от новой системы блокировки. Мы всё равно получим производительность 60–80 тысяч метрик. При этом мы сможем оставить весь остальной код. «Кликхаус», асинхронный поллинг будут работать. И это будет легко поддерживать.
МЧ: — Замечательно! Предлагаю на этом остановиться.
После оптимизации серверной части мы наконец-то смогли запустить новый код в продуктив. Мы отказались от части изменений в пользу перехода на машину с быстрыми ядрами и минимизации количества изменений в коде. Мы также упростили конфигурацию и по возможности отказались от макросов в элементах данных, поскольку они являются источником дополнительных блокировок.

Например, отказ от часто встречающегося в документации и примерах макроса snmp-community в нашем случае позволил дополнительно ускорить NVPs примерно в 1,5 раза.
После двух дней в продуктиве
Убираем всплывающие окна истории инцидентов
МЧ: — Миша, мы два дня пользуемся системой, и всё работает. Но только тогда, когда всё работает! У нас были плановые работы с переносом достаточно большого сегмента сети, и мы снова руками проверяли, что поднялось, что — нет.
ММ: — Не может быть! Мы 10 раз всё проверили. Сервер обрабатывает даже полную недоступность сети мгновенно.
МЧ: — Да я всё понимаю: сервер, база, top, austat, логи — всё быстро… Но мы смотрим веб-интерфейс, а там — процессор «в полку» на сервере и вот это:

ММ: — Понятно. Давай смотреть вебу. Мы обнаружили, что в ситуации, когда было большое количество активных инцидентов, большинство оперативных виджетов начинало работать очень медленно:
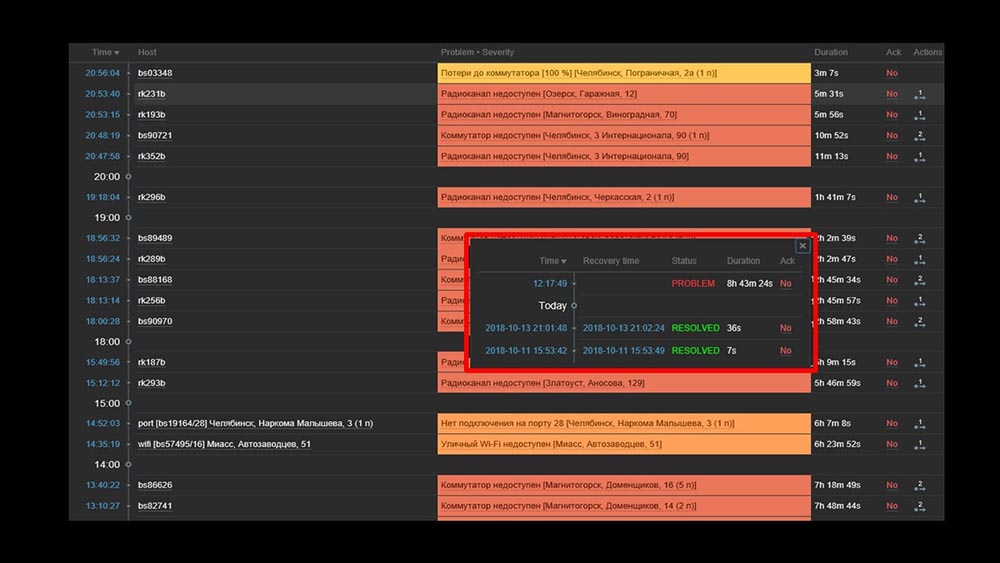
Причиной этому была генерация всплывающих окон с историей инцидентов, которые генерируются для каждого элемента в списке. Поэтому мы отказались от генерации этих окон (закомментировали 5 строчек в коде), и это решило наши проблемы.
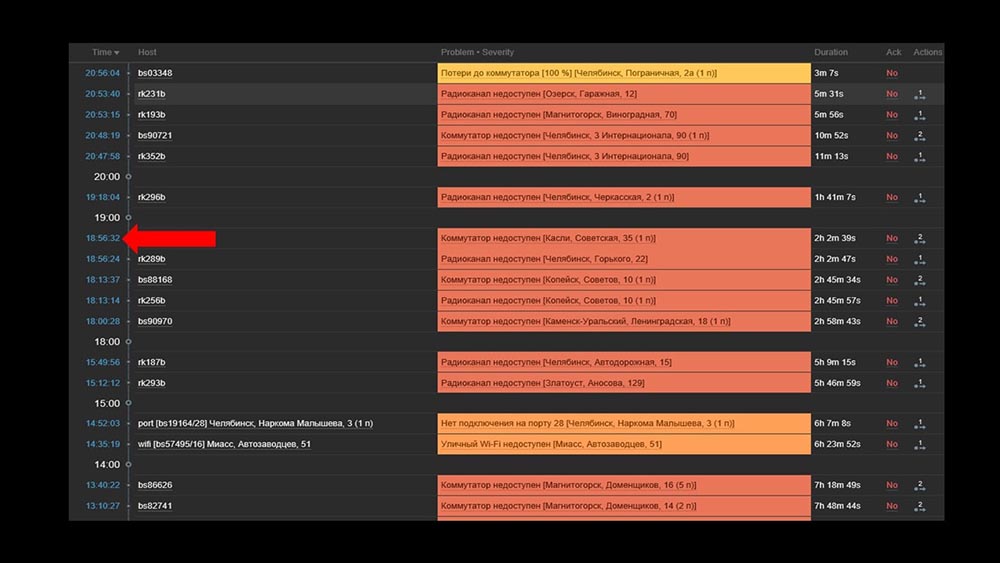
Время загрузки виджетов даже при полной недоступности сократилось с нескольких минут до допустимых для нас 10–15 секунд, а историю по-прежнему можно смотреть щелчком по времени:
После работы. 2 месяца назад
МЧ: — Миша, уходишь? Есть разговор.
ММ: — Не собирался. Опять что-то с «Заббиксом»?
МЧ: — Да не, расслабься! Я просто хотел сказать: всё работает, спасибо! С меня пиво.
Zabbix эффективен
«Заббикс» — достаточно универсальная и богатая система и функция. Его вполне можно использовать для небольших инсталляций «из коробки», но с ростом потребностей его приходится оптимизировать. Для хранения большого архива метрик используйте подходящее хранилище:
- можно воспользоваться встроенными средствами в виде интеграции с «Эластиксёрч» или выгрузкой истории в текстовые файлы (доступно с четвёртой версии);
- можно воспользоваться нашим опытом и интеграцией с «Кликхаус».
Для кардинального увеличения скорости сбора метрик, собирайте их асинхронными методами и передавайте через траппер-интерфейс в «Заббикс»-сервер; либо можно воспользоваться патчем для асинхронности поллеров самого «Заббикса».
«Заббикс» написан на Си и достаточно эффективен. Решение же несколько узких архитектурных мест позволяет дополнительно увеличить его производительность и, по нашему опыту, получать более 100 тысяч метрик на однопроцессорной машине.

Тот самый патч Zabbix
ММ: — Я хочу добавить пару моментов. Весь текущий доклад, все тесты, цифры приведены для той конфигурации, которая используется у нас. С неё мы сейчас снимаем примерно 20 тысяч метрик в секунду. Если вы пытаетесь понять, будет ли это работать у вас — можете сравнить. То, о чём сегодня рассказали, выложено на GitHub в виде патча: github.com/miklert/zabbix

Патч включает:
- полную интеграцию с «Кликхаусом» (как «Заббикс»-сервера, так и фронтенда);
- решение проблем с препроцессор-менеджером;
- асинхронный поллинг.
Патч совместим со всей версией 4, в том числе с lts. Скорее всего, с минимальными изменениями он будет работать на версии 3.4.
Спасибо за внимание.
Вопросы
Вопрос из аудитории (далее — А): — Добрый день! Скажите, пожалуйста, есть ли у вас планы интенсивного взаимодействия с командой Zabbix или у них с вами, чтобы это был не патч, а нормальным поведением «Заббикса»?
ММ: — Да, часть изменений мы обязательно закоммитим. Что-то будет, что-что останется в патче.
А: — Спасибо большое за отличный доклад! Подскажите, пожалуйста, после применения патча поддержка со стороны «Заббикса» останется и как дальше обновляться на более высокие версии? Будет ли возможность обновить «Заббикс» после вашего патча до 4.2, 5.0?
ММ: — О поддержке я не могу сказать. Если б я был техподдержкой «Заббикса», то, видимо, сказал бы нет, потому что это чужой код. Что касается кодовой базы 4.2, то наша позиция такая: «Мы будем идти со временем, и сами будем обновляться на следующей версии». Поэтому какое-то время мы будем выкладывать патч на обновлённые версии. Я уже сказал в докладе: количество изменений с версиями пока достаточно небольшое. Думаю, переход с 3.4 на 4 у нас заняло, кажется, минут 15. Там что-то поменялось, но не сильно важное.
А: — То есть вы планируете поддерживать свой патч и можно смело его ставить на продакшн, в дальнейшем получая обновления каким-то образом?
ММ: — Мы категорически рекомендуем. Нам это решает очень много проблем.
МЧ: — Ещё раз хотелось бы заострить внимание, что изменения, которые не касаются архитектуры и не касаются блокировок, очередей — они модульные, они в отдельных модулях. Даже самостоятельно при незначительных изменениях их можно поддерживать достаточно легко.
ММ: — Если интересны детали, то «Кликхаус» использует так называемую библиотеку истории. Она отвязана — это копия поддержки «Эластикса», то есть она конфигурационно изменяема. Поллинг меняет только поллеры. Мы считаем, что это будет работать долго.
А: — Спасибо большое. А подскажите, есть ли какая-то документация внесённых изменений?

ММ: — Документация — это патч. Очевидно, с введением «Кликхауса», с введением новых типов поллеров возникают новые конфигурационные опции. По ссылке из последнего слайда есть короткое описание, как этим пользоваться.
О замене fping на nmap
А: — Как вы в итоге это реализовали? Можете на конкретных примерах: это у вас страпперы и внешний скрипт? Что в итоге проверяет так быстро такое огромное количество хостов? Как вы добываете эти хосты? Надо nmap«у их как-то скормить, получить откуда-то, положить, что-то запустить?…
ММ: — Круто. Очень правильный вопрос! Суть такая. Мы модифицировали библиотеку (ICMP-пинг, составная часть «Заббикса») для ICMP-проверок, в которых указано количество пакетов — единица (1), а код пытается использовать nmap. То есть это внутренняя работа «Заббикса», стало внутренней работой пингера. Соответственно, никакой синхронизации или использования траппера не требуется. Это было сделано сознательно, чтобы оставить систему целостной и не заниматься синхронизацией двух систем баз: что проверять, заливать через поллер, а не сломалась ли у нас заливка?… Это гораздо проще.
А: — Для прокси тоже работает?
ММ: — Да, но мы не проверяли. Код поллинга и в «Заббиксе», и в сервере единый. Должно работать. Ещё раз акцентирую: производительность системы такая, что нам прокси не нужен.
МЧ: — Правильный ответ на вопрос такой: «А зачем вам при такой системе прокси?» Только из-за NAT«а или мониторить через медленный канал какой-то…
А: — А вы используете «Заббикс» как аллертор, если я правильно понял. Или графики (где архивный слой) у вас уехали в другую систему, типа Grafana? Или вы не используете этот функционал?
ММ: — Я ещё раз подчеркну: мы сделали полную интеграцию. Мы выливаем history в «Кликхаус», но при этом изменили php-фронтенд. Php-фронтенд ходит в «Кликхаус» и все графики делает оттуда. При этом, если честно, у нас есть часть, которая строит из того же «Кликхауса», из тех же данных «Заббикса» данные в других системах графического отображения.
МЧ: — В «Графане» в том числе.
Как принималось решение и о выделении ресурсов?
А: — Поделитесь немного внутренней кухней. Как принималось решение о том, что надо выделить ресурсы на серьёзную переработку продукта? Это, в общем-то, определённые риски. И скажите, пожалуйста, в контексте того, что вы собираетесь поддерживать новые версии: как оправдывается это решение с точки зрения управления?
ММ: — Видимо, драму истории мы не очень хорошо рассказали. Мы оказались в ситуации, когда что-то надо было делать, и пошли по сути двумя параллельными командами:
- Одна занималась запуском системы мониторинга на новых методах: мониторинг как сервис, стандартный набор опенсорсных решений, которые мы комбинируем и потом пытаемся изменить бизнес-процесс для того, чтобы работать с новой системой мониторинга.
- Параллельно у нас был энтузиаст-программист, который этим занимался (о себе). Так получилось, что он победил.
А: — И каков размер команды?
МЧ: — Она перед вами.
А: — То есть как всегда нужен пассионарий?
ММ: — Я не знаю, что такое пассионарий.
А: — В данном случае, видимо, вы. Спасибо большое, вы — крутые.
ММ: — Спасибо.
О патчах для Zabbix
А: — Для системы, которая использует прокси (например, в каких-то распределённых системах), возможно ли ваше решение адаптировать и пропатчить, скажем, поллеры, прокси и частично препроцессор самого «Заббикса»; и их взаимодействие? Возможно ли существующие наработки оптимизировать под систему с несколькими прокси?
ММ: — Я знаю, что «Заббикс»-сервер собирается с помощью прокси (компилируется и получается код). Мы не проверяли это в продуктиве. Я не уверен в этом, но, по-моему, препроцессор-менеджер не используется в прокси. Задача прокси — это взять набор метрик из «Заббикса», споллить их (он ещё записывает конфигурацию, локальную базу) и отдать обратно «Заббикс»-серверу. Делать препроцессинг будет потом сам сервер, когда получит.
Интерес к прокси понятен. Мы проверим это. Это интересная тема.
А: — Идея такая была: если можно патчить поллеры, их можно патчить на прокси и патчить взаимодействие с сервером, а препроцессор под эти цели адаптировать только на сервере.
ММ: — Думаю, всё даже проще. Вы берёте код, накладываете патч, потом конфигурируете так, как вам надо — собираете прокси-серверы (например, с ODBC) и патченный код разносите по системам. Где надо — собираете прокси, где надо — сервер.
А: — Дополнительно патчить передачу прокси к серверу не придётся, скорее всего?
МЧ: — Нет, она стандартная.
ММ: — На самом деле не звучала одна из идей. Мы всегда соблюдали соблюсти баланс между взрывом идей и количеством изменений, лёгкостью поддержки.
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
