Haxe 4: Что нового?
Предлагаю вашему вниманию перевод доклада Александра Кузьменко (с апреля этого года он официально работает в качестве разработчика компилятора Haxe) об изменениях в языке Haxe, произошедших с релиза Haxe 3.4.

С момента выпуска Haxe 3.4 прошло более чем два с половиной года. За это время вышло 7 патч-релизов, 5 превью-релизов Haxe 4 и 2 релиз-кандидата Haxe 4. Это был долгий путь к новой версии и она почти готова (остается решить около 20 задач).

Александр поблагодарил сообщество Haxe за отчеты о багах, за желание участвовать в развитии языка. Благодаря проекту haxe-evolution в Haxe 4 появятся такие вещи как:

Также в рамках данного проекта ведутся обсуждения таких возможных нововведений как: Promises, полиморфный this и типы по-умолчанию (default type parameters).
Далее Александр рассказал об изменениях в синтаксисе языка.

Первое — это новый синтаксис для описания типов функций (function type syntax). Старый синтаксис был немного странным.
Haxe — мультипарадигменный язык программирования, в нем всегда была поддержка функций первого класса, но синтаксис для описания типов функций был унаследован от функционального языка (и отличается от принятого в других парадигмах). И программисты, знакомые с функциональным программированием, ожидают, что функции с таким синтаксисом поддерживают автоматическое каррирование. Но в Haxe это не так.
Основным недостатком старого синтаксиса, по мнению Александра, является отсутствие возможности определить имена аргументов, из-за чего приходится писать длинные комментарии-аннотации с описанием аргументов.
Но теперь у нас есть новый синтаксис для описания типов функций (который, кстати, был добавлен в язык в рамках инициативы haxe-evolution), где такая возможность есть (хотя делать это необязательно, но рекомендуется). Новый синтаксис легче читается и его даже можно считать частью документации к коду.
Еще одним недостатком старого синтаксиса описания типов функций была его некоторая нелогичность — необходимость задавать тип аргументов функции даже в том случае, когда функция не принимает никаких аргументов: Void->Void (данная функция не принимает аргументов и ничего не возвращает).
В новом синтаксисе это реализовано элегантнее: ()->Void

Второе — это стрелочные функции или лямбда-выражения — краткая форма описания анонимных функций. Сообщество долгое время просило добавить их в язык, и, наконец, это свершилось!
В таких функциях вместо ключевого слова return используется последовательность символов -> (отсюда и название синтаксиса «стрелочная функция»).
В новом синтаксисе осталась возможность задавать типы аргументов (так как система автовыведения типов не всегда может сделать это так, как этого желает программист, например, компилятор может решить использовать Float вместо Int).
Единственным ограничением нового синтаксиса является отсутствие возможности явно задать возвращаемый тип. Если это необходимо, то у вас есть выбор либо использовать старый синтаксис, либо использовать check-type синтаксис в теле функции, который подскажет компилятору возвращаемый тип.
У стрелочных функций нет специального представления в синтаксическом дереве, они обрабатываются также как и обычные анонимные функции. Последовательность -> заменяется ключевым словом return.

Третье изменение — final теперь стал ключевым словом (в Haxe 3 final был одним из встроенных в компилятор мета-тэгов).
Если применить его к классу, то это запретит наследование от него, то же самое относится к интерфейсам. А применение спецификатора final к методу класса запретит его переопределение в дочерних классах.
Однако в Haxe остался способ обойти ограничения, накладываемые ключевым словом final — для этого можно использовать мета-тэг @:hack (но все же делать это следует только в случае крайней необходимости).
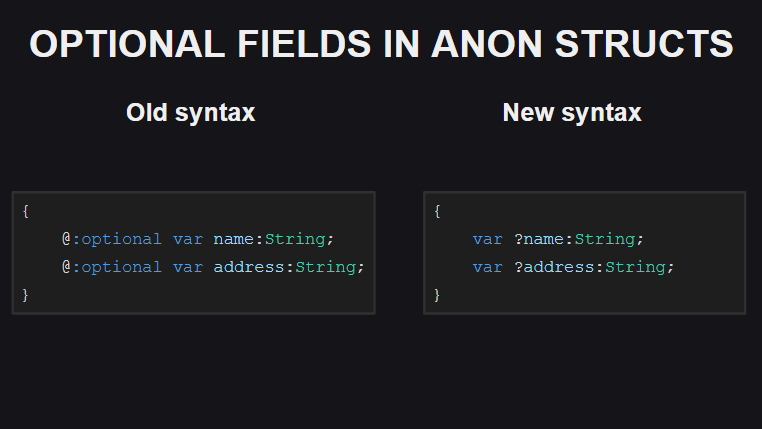
Четвертое изменение — это способ объявления необязательных полей в анонимных структурах. Ранее для этого использовался мета-тэг @:optional, теперь достаточно добавить перед именем поля вопросительный знак.

Пятое — абстрактные перечисления стали полноценным членом в семействе типов в Haxe, и вместо мета-тэга @:enum теперь для их объявления используется ключевое слово enum.
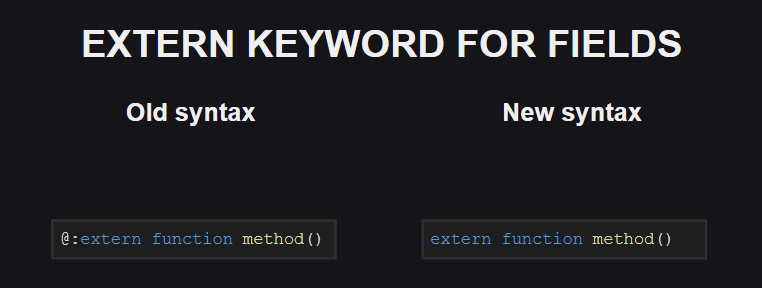
Аналогичное изменение коснулось и мета-тэга @:extern.

Седьмое — новый синтаксис для объединения типов (type intersection), который лучше отражает суть расширения структур.
Такой же новый синтаксис используется для ограничения типов параметров (type parameters constraints), он точнее передает ограничения, накладываемые на тип. Для человека, незнакомого с Haxe, старый синтаксис MyClass мог восприниматься как требование к типу параметра T быть либо типом Type1, либо Type2. Новый синтаксис явно говорит нам, что T должен быть одновременно и Type1 и Type2.
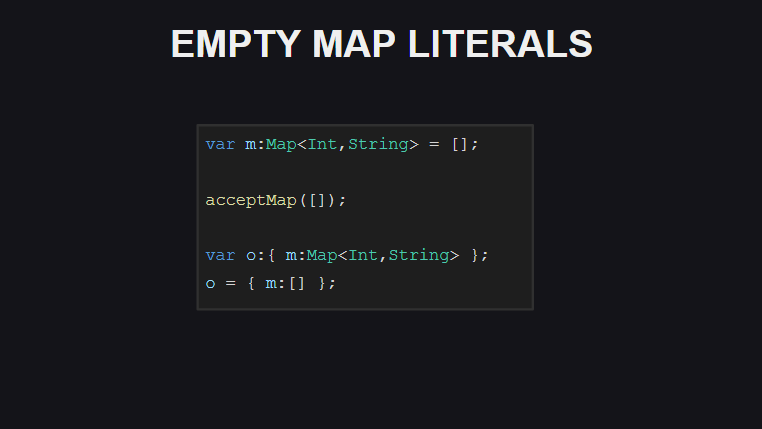
Восьмое — это возможность использовать [] для объявления пустого Map-контейнера (однако, если тип переменной явно не указать, то компилятор выведет для данного случая тип как массив).
Рассказав об изменениях в синтаксисе, перейдем к описанию новых функций в языке.
Начнем с новых итераторов «ключ-значение»
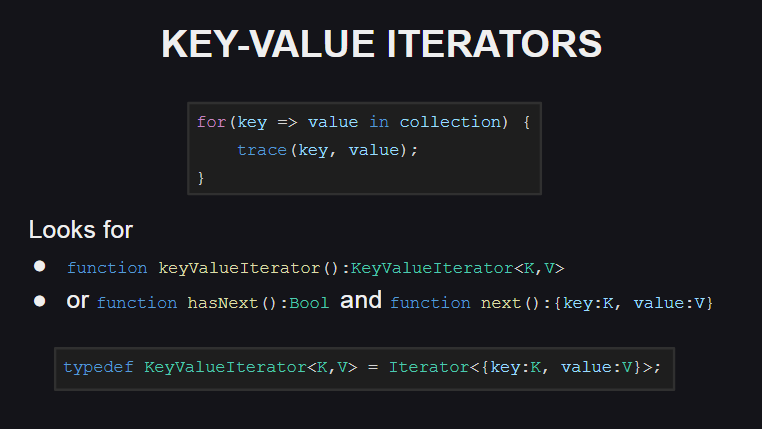
Для их использования добавлен новый синтаксис.
Для поддержки таких итераторов в типе должен быть реализован либо метод keyValueIterator():KeyValueIterator, либо методы hasNext():Bool и next():{key:K, value:V}. При этом тип KeyValueIterator является синонимом для обычного итератора по анонимной структуре Iterator<{key:K, value:V}>.
Итераторы ключ-значения реализованы для некоторых типов из стандартной библиотеки Haxe (String, Map, DynamicAccess), также ведется работа по их реализации для массивов.
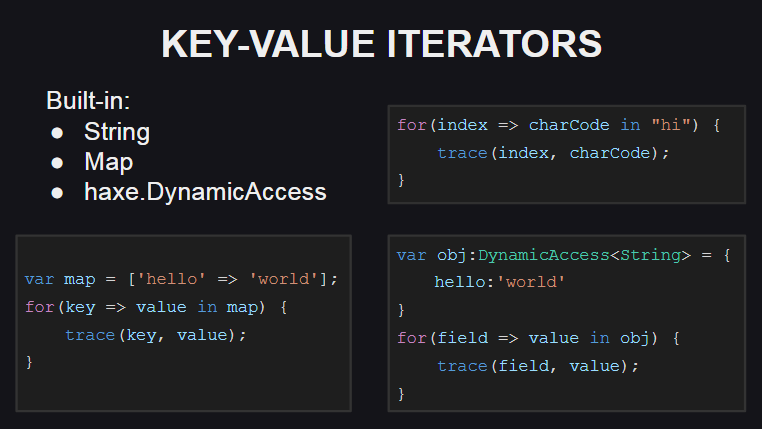
Для строк в качестве ключа используется индекс символа в строке, а в качестве значения — код символа по данному индексу (если нужен сам символ, то можно использовать метод String.fromCharCode()).
Для контейнера Map новый итератор работает также как и старый способ итерации, то есть получает массив ключей в контейнере и проходит по нему, запрашивая значения для каждого из ключей.
Для DynamicAccess (обертка для анонимных объектов) итератор работает с использованием рефлексии (для получения списка полей объекта с помощью метода Reflect.fields() и для получения значений полей по их именам с помощью метода Reflect.field()).

В Haxe 4 используется совершенно новый интерпретатор макросов «eval». Саймон Кражевски, автор интерпретатора, довольно подробно описал его в официальном блоге Haxe, а также в своем прошлогоднем отчете о проделанной работе.
Основные изменения в работе интерпретатора:
- он в несколько раз быстрее старого интерпретатора макросов (в среднем в 4 раза)
- поддерживает интерактивную отладку (раньше для макросов мог использоваться только вывод в консоль)
- он используется для работы компилятора в режиме интерпретатора (ранее для этого использовался neko. Кстати eval также превосходит neko по скорости работы).

Поддержка юникод для всех платформ (за исключением neko) является одним из крупнейших изменений в Haxe 4. Саймон подробно рассказал об этом в прошлом году. Но вот краткий обзор текущего состояния поддержки юникод-строк в Haxe:
- для Lua, PHP, Python и eval (интерпретатор макросов) реализована полная поддержка юникод (кодировка UTF8)
- для остальных платформ (JavaScript, C#, Java, Flash, HashLink и C++) используется кодировка UTF16.
Таким образом, строки в Haxe работают одинаково для символов, входящих в основную многоязычную плоскость, но для символов за пределами данной плоскости (например, для эмодзи) код для работы со строками может выдавать разный результат в зависимости от платформы (но это все равно лучше, чем ситуация, которую мы имеем в Haxe 3, когда на каждой платформе было свое поведение).

Для строк в юникод-кодировке (как в UTF8, так и UTF16) в стандартную библиотеку Haxe добавлены специальные итераторы, одинаково работающие на ВСЕХ платформах для всех символов (как в пределах основной многоязычной плоскости, так и за ее пределами):
haxe.iterators.StringIteratorUnicode
haxe.iterators.StringKeyValueIteratorUnicode
Вследствие того, что реализация строк разнится от платформы к платформе, необходимо иметь в виду некоторые нюансы их работы. В UTF16 каждый символ занимает 2 байта, благодаря этому доступ к символу в строке по индексу работает быстро, но только в пределах основной многоязычной плоскости. С другой стороны, в UTF8 поддерживаются все символы, но достигается это ценой замедленного поиска символа в строке (так как символы могут занимать в памяти разное количество байт, то доступ к символу по индексу требует каждый раз проходить по строке с самого ее начала). Поэтому в случае работы с крупными строками в Lua и PHP нужно иметь в виду, что доступ к произвольному символу работает довольно медленно (также на данных платформах длина строки вычисляется каждый раз заново).
Однако, хотя для Python заявлена полная поддержка юникод, на него данное ограничение не распространяется благодаря тому, что строки в нем реализованы несколько иначе: для символов в пределах основной многоязычной плоскости в нем используется кодировка UTF16, а для более «широких» символов (3 и более байт) Python использует UTF32.
Для интерпретатора макросов eval реализованы дополнительные оптимизации: строка «знает» о том, есть ли в ней юникод-символы. В том случае, если в ней нет таких символов, строка интерпретируется как состоящая из ASCII-символов (где каждый символ занимает 1 байт). Последовательный доступ по индексу в eval также оптимизирован: в строке кэшируется позиция последнего символа, к которому осуществлялся доступ. Так если сначала обратиться к 10-му символу в строке, то при последующем обращении к 20-му символу eval будет искать его не с самого начала строки, а начиная с 10-го. Кроме того, длина строки в eval кэшируется, то есть вычисляется только при первом запросе.
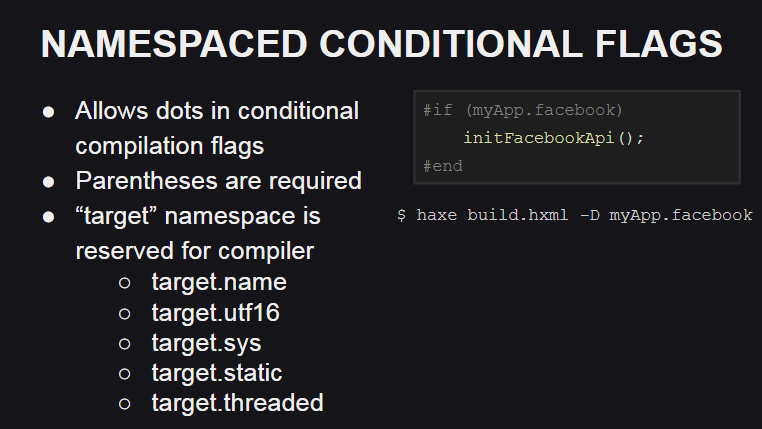
В Haxe 4 появилась поддержка пространств имен для флагов компиляции, которая может пригодиться, например, для организации кода при написании пользовательских библиотек.
Также появилось зарезервированное пространство имен для флагов компиляции — target, которое используется компилятором для описания целевой платформы и особенностей ее поведения:
target.name— имя платформы (js, cpp, php и т.д.)target.utf16— говорит о том, что поддержка юникода осуществляется с помощью UTF16target.sys— говорит о том, доступны ли классы из пакета sys (например, для работы с файловой системой)target.static— говорит о том, является ли платформа статической (на статических платформах базовые типыInt,FloatиBoolне могут иметь в качестве значенияnull)target.threaded— говорит о том, поддерживается ли платформой многопоточность
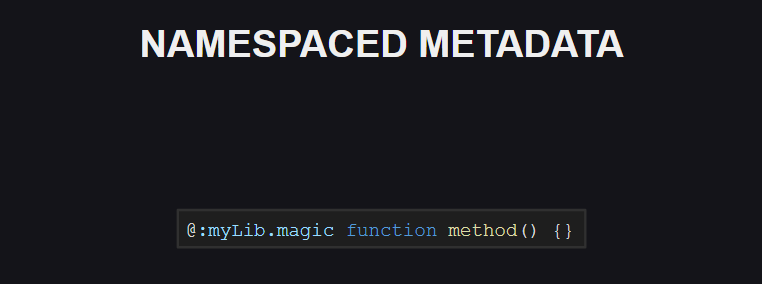
Аналогично появилась поддержка пространств имен для мета-тэгов. Пока что зарезервированных пространств имен для мета-тэгов в языке нет, но в будущем ситуация может измениться.

В стандартную библиотеку Haxe добавлен тип ReadOnlyArray — абстракт над обычным массивом, в котором доступны методы только для чтения данных из массива.

Еще одно нововведение в языке — финальные поля и локальные переменные.
Если при объявлении поля класса или локальной переменной вместо ключевого слова var использовать final, то это будет означать, что данному полю или переменной нельзя переназначить значение (при попытке сделать это компилятор выдаст ошибку). Но в то же время его состояние можно изменить, таким образом финальное поле или переменная не является константой.
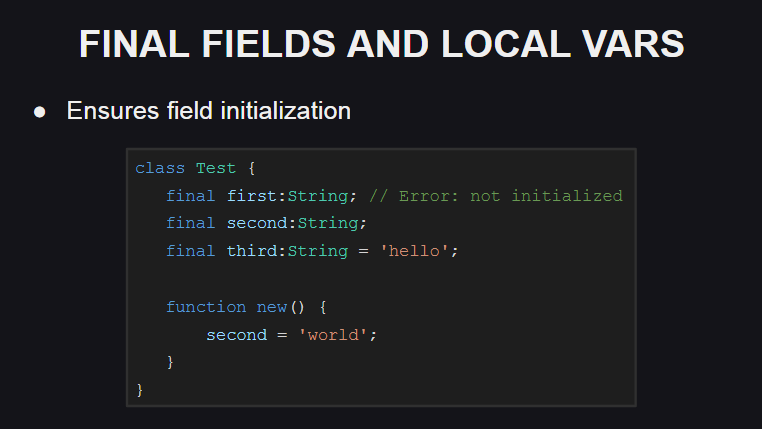
Значения финальных полей должны инициализироваться либо при их объявлении, либо в конструкторе, в противном случае компилятор выдаст ошибку.

HashLink — новая платформа с собственной виртуальной машиной, созданная специально для Haxe. HashLink поддерживает так называемую «двойную компиляцию» (Dual compilation) — код может компилироваться либо в байткод (что очень быстро, ускоряет процесс отладки разрабатываемых приложений), либо в C-код (который отличается повышенной производительностью). Николас посвятил HashLink несколько постов в блоге Haxe, а также рассказывал о нем на прошлогодней конференции в Сиэтле. Технология HashLink используется в таких популярных играх как Dead Cells и Northgard.

Еще одной новой интересной особенностью Haxe 4 является Null-безопасность (Null safety), которая пока находится в экспериментальной стадии (из-за ложных срабатываний и недостаточных проверках на безопасность кода).
Что такое Null-безопасность? Если ваша функция явно не объявляет, что она может принимать null в качестве значений параметров, то при попытке передать в нее null, компилятор выдаст соответствующую ошибку. Кроме того, для параметров функций, которые могут принимать null в качестве значения, компилятор потребует от вас написать дополнительный код для проверки и обработки таких случаев.
Данная функциональность выключена по-умолчанию, но она не влияет на скорость исполнения кода (если ее все же включить), так как описанные проверки выполняются только на этапе компиляции. Ее можно включить как для всего кода, так и постепенно включать для отдельных полей, классов и пакетов (обеспечивая таким образом постепенный переход к более безопасному коду). Для этого можно использовать специальные мета-тэги и макросы.
Режимы, в которых может работать Null-безопасность: Strict (наиболее строгий), Loose (режим по-умолчанию) и Off (используется для того, чтобы отключить проверки для отдельных пакетов и типов).

Для приведенной на слайде функции включена проверка на Null-безопасность. Мы видим, что данная функция имеет необязательный параметр s, то есть мы можем передать в нее null в качестве значения параметра. При попытке скомпилировать код с такой функцией компилятор выдаст ряд ошибок:
- при попытке обратиться к какому-либо полю объекта
s(т.к. он может бытьnull) - при попытке присвоить переменной str, которая как мы видим не должна принимать значение
null(иначе мы должны были объявить ее не какString, а какNull) - при попытке вернуть из функции объект
s(т.к. функция не должна возвращатьnull)
Как исправить эти ошибки?
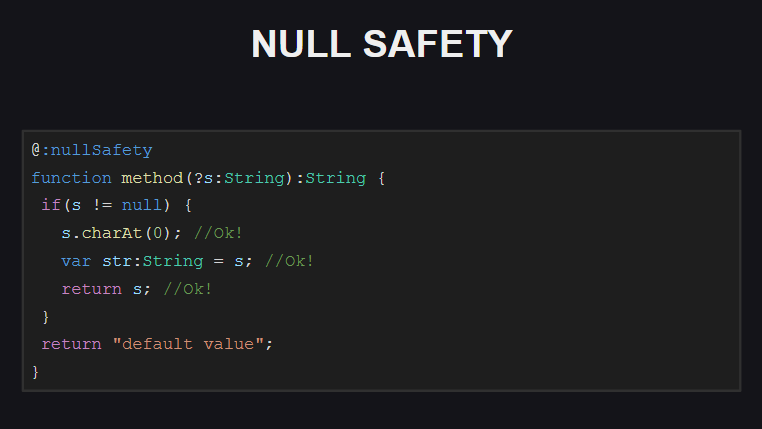
Мы просто должны добавить в код проверку на null (внутри блока с проверкой на null компилятор «знает», что s не может быть null и с ним можно безопасно работать), а также удостовериться, что функция не возвращает null!

Кроме того, при осуществлении проверок на Null-безопасность компилятор принимает во внимание порядок выполнения программ. Например, если после проверки значения параметра s на null завершить выполнение функции (или бросить исключение), то компилятор будет «знать», что после такой проверки параметр s уже не может быть null, и что с ним можно безопасно работать.

Если для компилятора включить Strict-режим проверок на Null-безопасность, то он будет требовать дополнительных проверок на null в тех случаях, когда между первоначальной проверкой значения на null и попыткой обратиться к полю объекта исполнялся какой-либо код, который мог установить его в null.
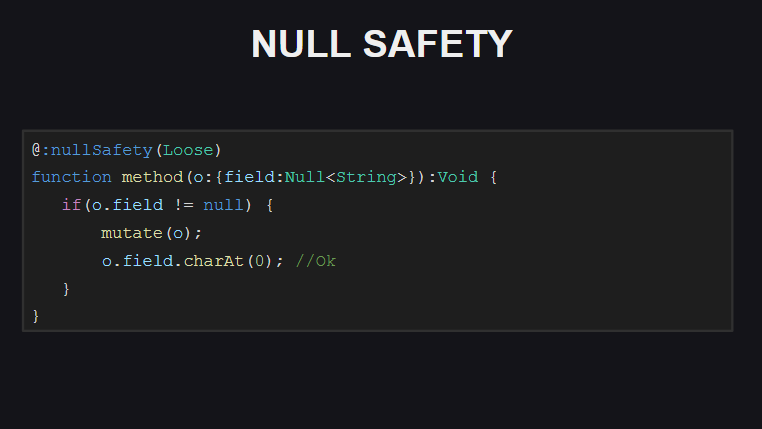
В Loose-режиме (используется по-умолчанию) таких проверок компилятор не потребует (кстати, такое поведение также используется по-умолчанию в TypeScript).

Также при включенных проверках на Null-безопасность компилятор проверяет инициализируются ли поля в классах (непосредственно при их объявлении или в конструкторе). В противном случае компилятор будет выдавать ошибки при попытке передать объект такого класса, а также при попытках вызова методов у таких объектов, до тех пор, пока все поля объекта не будут инициализированы. Такие проверки можно отключать для отдельных полей класса, пометив их мета-тэгом @:nullSafety(Off)
Более подробно о Null-безопасности в Haxe Александр рассказывал в прошлом октябре.

В Haxe 4 появилась возможность генерировать ES6 классы для JavaScript, включается она с помощью флага компиляции js-es=6.
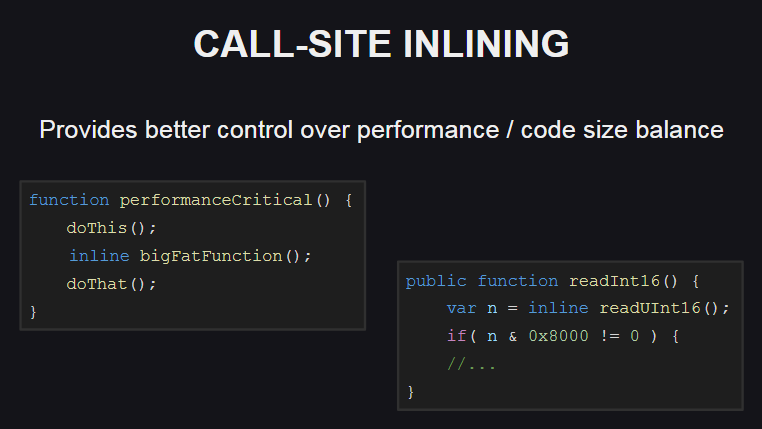
Встраивание функций по месту вызова (call-site inlining) предоставляет больше возможностей для контроля баланса между производительностью кода и его размером. Данная функциональность используется и в стандартной библиотеке Haxe.
Что она собой представляет? Она позволяет встраивать тело функции (с помощью ключевого слова inline) только в тех местах, где это требуется для обеспечения высокой производительности (например, при необходимости вызывать в цикле достаточно объемный метод), при этом в остальных местах тело функции не встраивается. В результате размер сгенерированного кода будет незначительно увеличен.
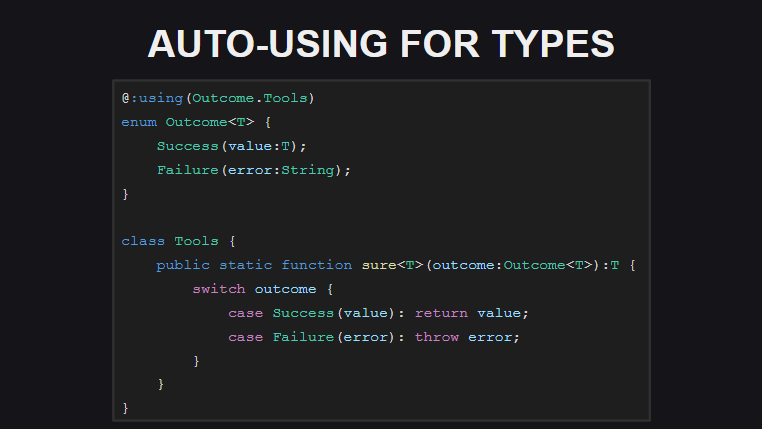
Auto-using (автоматические расширения для типов) означает, что теперь для типов можно объявлять статические расширения по месту объявления типа. При этом отпадает необходимость каждый раз использовать конструкцию using type; в каждом модуле, где используется тип и методы расширения. На данный момент такой тип расширений реализован только для перечислений, но в финальном релизе (и в ночных сборках) его можно будет использовать не только для перечислений.

В Haxe 4 появится возможность переопределять для абстрактных типов оператор доступа к полям объекта (только для несуществующих в типе полей). Для этого используются методы, помеченные мета-тэгом @:op(a.b).

Встроенная разметка — еще одна экспериментальная функция в Haxe. Код встроенной разметки обрабатывается компилятором не как xml-документ — компилятор видит ее как строку, обернутую в мета-тэг @:markup. Код разметки должен быть обязательно обернут в открывающий и закрывающий тэги.
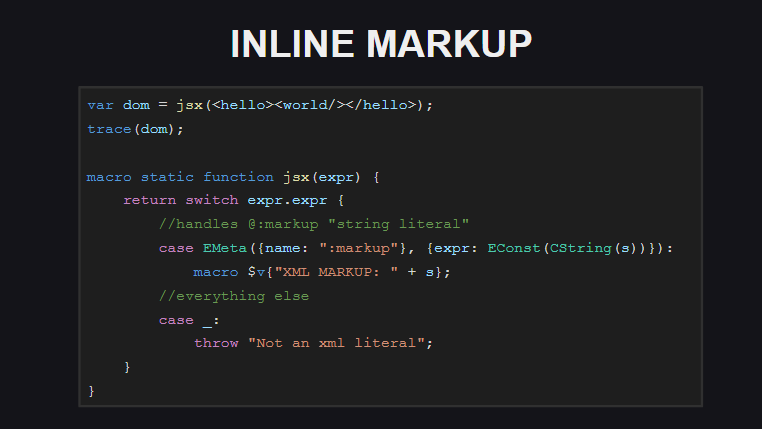
Здесь приведен пример макро-функции, которая ищет мета-тэг @:markup и строку литерала разметки, и затем возвращает некоторый результат.

Также встроенную разметку можно использовать как замену для вставок кода на языке целевой платформы (замена для untyped). При этом механизм макросов позволяет реализовать подсветку кода из таких вставок. Так, в показанном примере, макрос Js.build() ищет в дереве выражений мета-тэг @:markup и следующую за ней строку, и если найденная строка обернута в теги

В Haxe 4 появилась возможность задавать значения по-умолчанию для перечислений-аргументов функций, но с ограничением — можно использовать только конструкторы перечислений без аргументов.

Для абстрактных перечислений теперь автоматически генерируются значения. Таким образом, отпадает необходимость вручную задавать их для каждого конструктора. Для абстрактных перечислений, созданных поверх Int, значения создаются по тем же правилам, что в языке C.
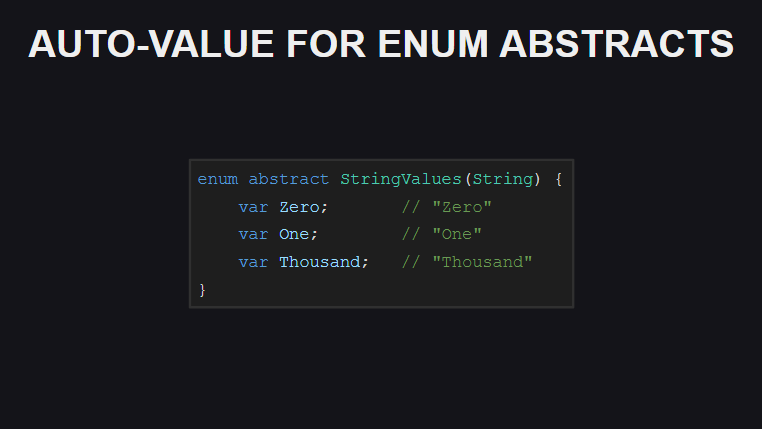
Генерация значений работает и для строковых абстрактных перечислений — сгенерированное значение будет совпадать с именем конструктора.
В следующих релизах планируются следующие изменения:

Появится возможность генерации JVM-байткода без использования JDK, при этом компиляция непосредственно в байткод осуществляется значительно быстрее компиляции в Java-код. Полученный байткод работает быстрее. Также рассматривается возможность реализации интерактивной отладки для нового таргета.

В следующих версиях запланирована поддержка корутин, но без ключевых слов async/await и yield. Корутины будут работать в одном потоке (в отличие от C#, где они могут исполняться в разных потоках). С черновиком предложения по реализации корутин в Haxe можно ознакомиться на github.

В Haxe появятся функции, доступные на уровне модуля. Для объявления таких функций (и переменных) не нужно создавать отдельный класс. Для работы с такими функциями достаточно импортировать модуль, в котором они определены.

Еще одним следующим нововведением будет асинхронное API для работы с системными ресурсами. Пока никаких подробностей не раскрывается, за исключением того, что возможно новое API будет основано на промисах.
Такое будущее нас ждет в Haxe 4 и далее!
