Habra Analytics Tools: сравниваем хабы
Если вы не читаете хабр по выходным, то скорее всего пропустили запуск мини-проекта Habra Analytics Tools. Цель проста — предоставить авторам Хабрахабра инструментарий для анализа статей и хабов. Первые инструменты посвящены анализу и сравнению хабов, и прежде всего они полезны для оценки аудитории статей. Например, график справа показывает, какие хабы также читают подписчики хаба «Google» (высота столбики — процент подписчиков, который так же читает указанные хабы), а слева визуальную диспозицию относительно двух других хабов («Искусственный интеллект» и «Linux»).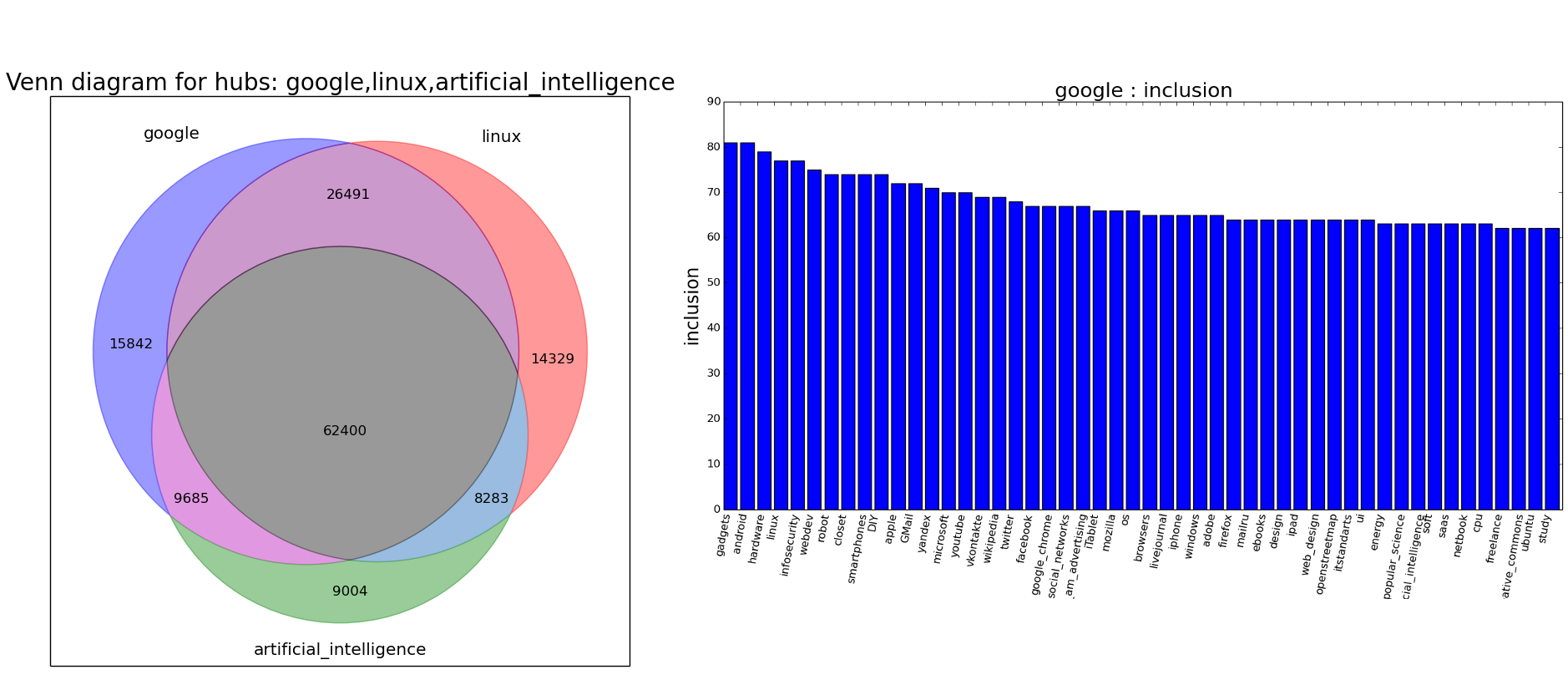 Построение диаграмм Венна мы обсудили ранее вот в этой статье, исходники доступны на github (или готовые исполняемые файлы под Windows, Linux и Mac OS) — вам так же нужно будет скачать и распаковать data.7z (также необходим для данной статьи).
Построение диаграмм Венна мы обсудили ранее вот в этой статье, исходники доступны на github (или готовые исполняемые файлы под Windows, Linux и Mac OS) — вам так же нужно будет скачать и распаковать data.7z (также необходим для данной статьи).
Здесь же мы поговорим о предпочтениях читателей определенного хаба по отношению сразу ко всем остальным хабам Хабрахабра.Исходные данные тула под названием hubs доступны на github, там же доступны исполняемые файлы для Windows и Linux.
Зачем это нужно?
Самое очевидное применение инструмента hubs — это анализ предпочтений целевой аудитории. Представим, что мы пишем для корпоративного блога и хотим узнать, что же еще читают наши подписчики. Какие темы их интересуют? Рассмотрим в качестве примера корпоративный блог Яндекса:  Для сравнения приведем хаб Яндекса (не корпоративный блог):
Для сравнения приведем хаб Яндекса (не корпоративный блог): 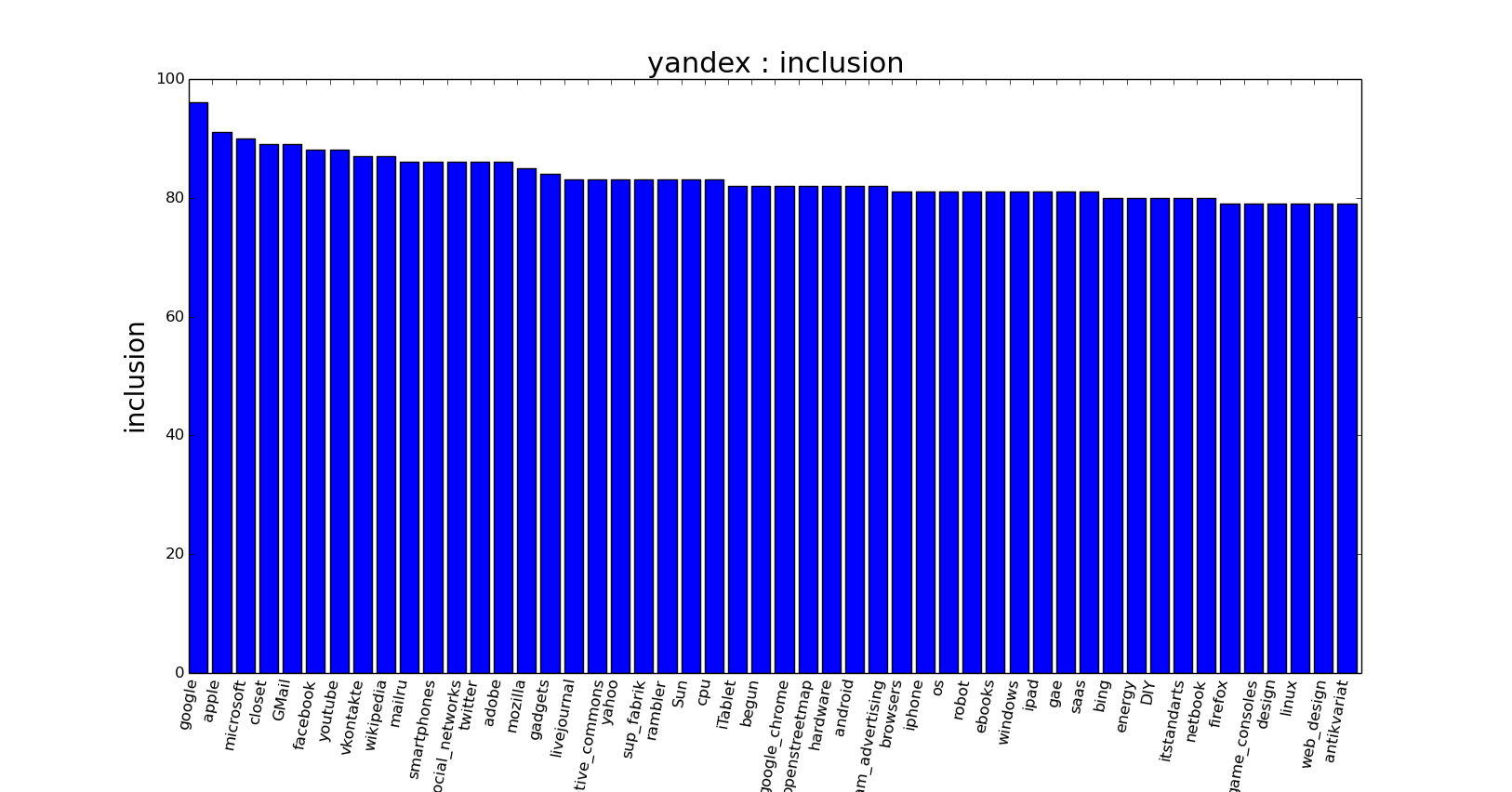 Из двух графиков мы видим, что предпочтения существенно отличаются (хотя их и объединяют некоторая любовь к Гуглу).Столь существенная разница возникает прежде всего из-за существенной разницы в аудитории блога и хаба:
Из двух графиков мы видим, что предпочтения существенно отличаются (хотя их и объединяют некоторая любовь к Гуглу).Столь существенная разница возникает прежде всего из-за существенной разницы в аудитории блога и хаба: 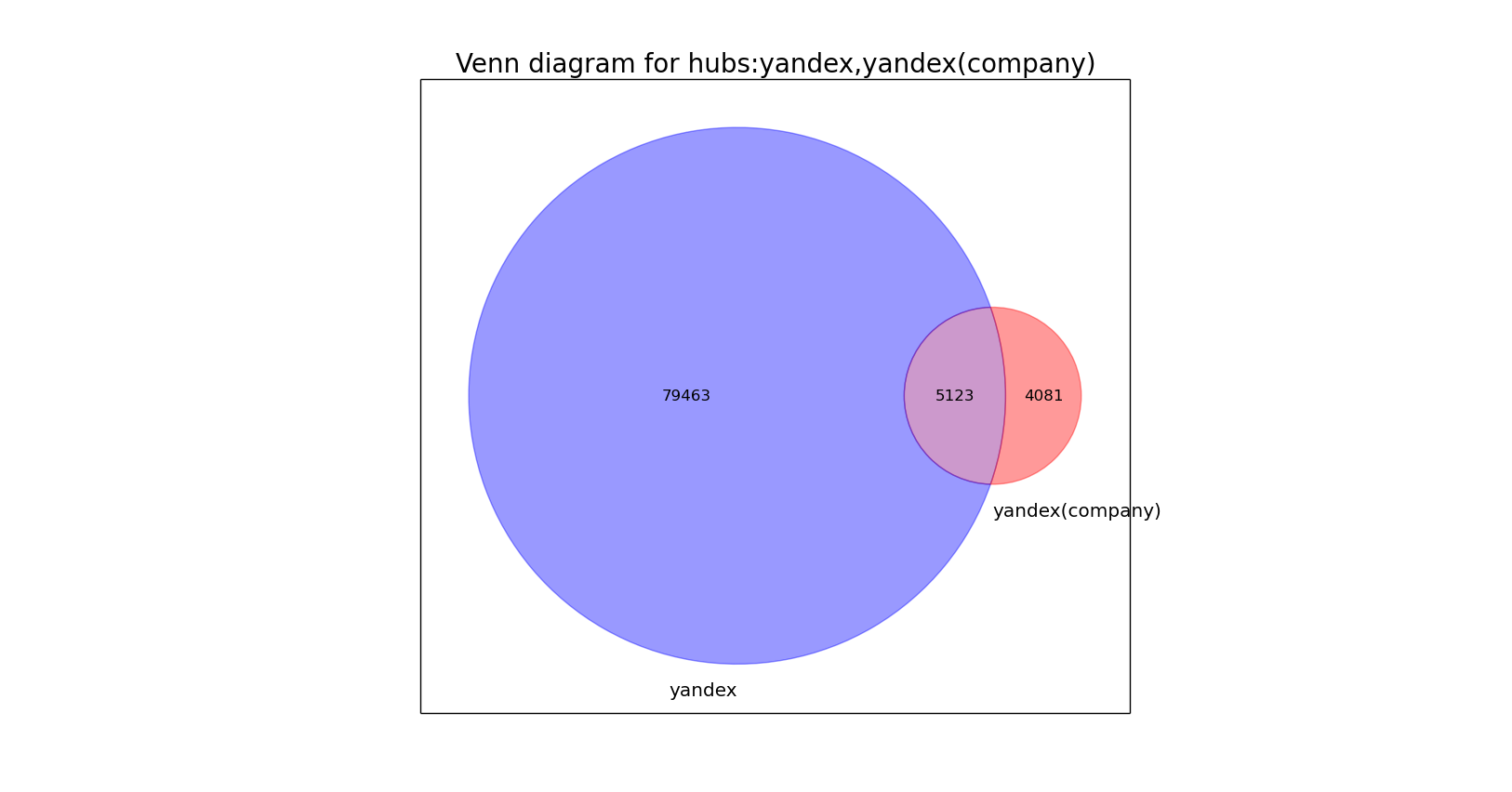
Таким образом диаграмма Венна говорит нам о том, что аудитория существенно отличается, а две гистограммы сверху показывают как именно отличаются вкусы читателей. А значит решение о том, в какой хаб писать — в корпоративный блог и/или в обычный хаб, можно принять во внимание тему статьи и её соответствие предпочтениям пользователей из гистограмм выше.
Похожие хабы Если диаграмма Венна подсказывает взаимное расположении аудиторий двух хабов и отвечает на вопрос: «Как вырастет аудитория хаба X, если мы добавим Y», то гистограмма хабов отвечает на вопрос какие хабы Z1, Z2, … Zn похожи на хаб X? Здесь мы предоставляем две метрики для сравнения хабов:
Если z% читателей хаба Х читают Y, то X ~ Y = z, пример, если 10% читателей хаба Космонавтика подписаны на хаб C++, то 10 — степень схожести хабов Космонавтика на C++ (данное отношение не симметрично)
Коэффициент_Жаккара: 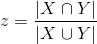 Первая метрика подходит лучше всего для естественной интерпретации предпочтений читателей хаба, а вторая может быть полезна для автоматической кластеризации хабов в каталог. Приведем пример с оценкой предпочтений читателей хаба:
Первая метрика подходит лучше всего для естественной интерпретации предпочтений читателей хаба, а вторая может быть полезна для автоматической кластеризации хабов в каталог. Приведем пример с оценкой предпочтений читателей хаба: 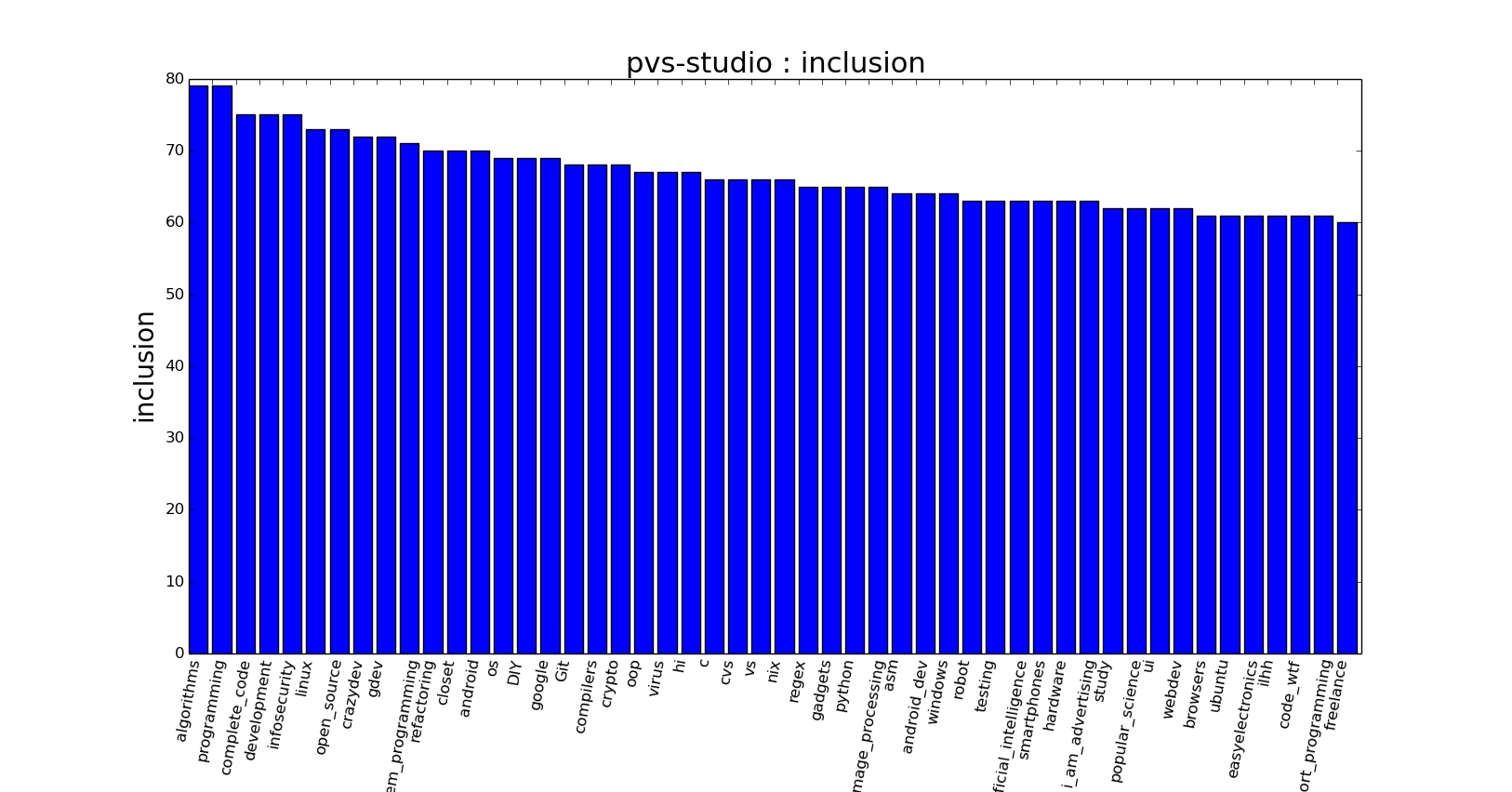 На данной гистограмме мы видим, что у корпоративного хаба есть несколько основных групп читателей, условно назовем их «разработка» — алгоритмы, программирование etc, «безопасность», «Open source», «рефакторинг» и «операционные системы». Данный фактор может быть учтен при написании статей, например, подчеркнув определенные аспекты интересные одной из групп читателей.
На данной гистограмме мы видим, что у корпоративного хаба есть несколько основных групп читателей, условно назовем их «разработка» — алгоритмы, программирование etc, «безопасность», «Open source», «рефакторинг» и «операционные системы». Данный фактор может быть учтен при написании статей, например, подчеркнув определенные аспекты интересные одной из групп читателей.
Код, документация и примеры
Для установки необходимо скачать либо: Также необходимо скачать архив data.7z (~15МБ, unzipped ~ 200МБ) и распаковать его в той же директории, что и скрипт. Далее в зависимости от скаченной версии необходимо вызывать python hubs.py, либо ./hubs.efl, либо hubs.exe. Будем придерживаться первой версии.Основные команды
Скрипт является консольным, поэтому его важнейшей командой является help, доступный через флаги -h, --help: python hubs.py -hпример вывода на экран: 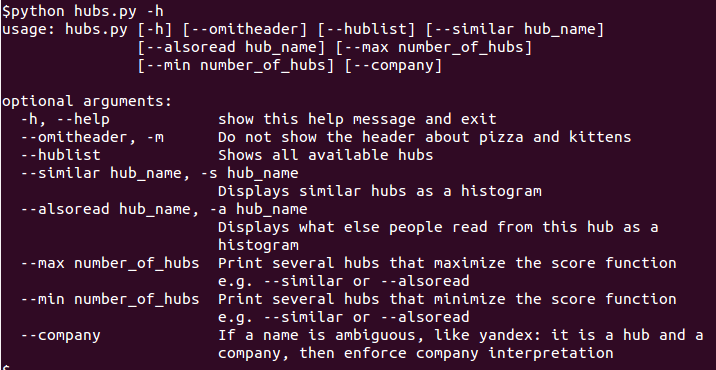 Основная команда для вывода гистограммы «что еще читают подписчики хаба»: python hubs.py --alsoread spaceпример вывода:
Основная команда для вывода гистограммы «что еще читают подписчики хаба»: python hubs.py --alsoread spaceпример вывода: 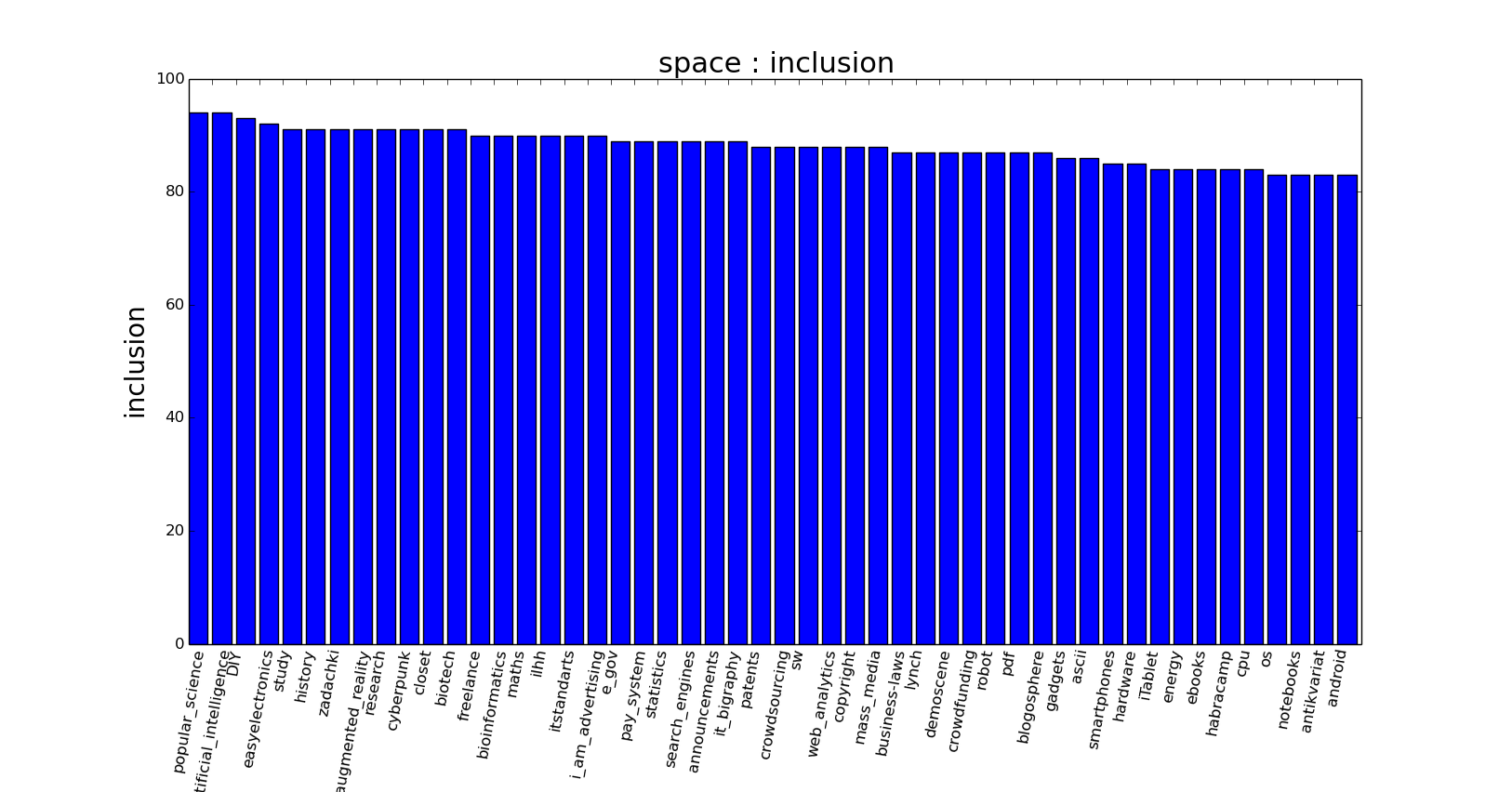
Для каждого хаба в программе используется соответствующее имя из ссылки на этот хаб habrahabr.ru/hub/space — для хаба Космонавтика, space — это имя в программе. Вывод доступных имен хабов и их полные названия, все операции производятся по коротким латинским именам из списка (они же используются в url на хабре)python hubs.py --hublistВ идеале используется вместе с командой grep: 
Как уже было отмечено ранее, yandex — это корпоративный блог и хаб, чтобы устранить неоднозначность используется ключ:--company. Поэтому, чтобы создать диаграмму для корпоративного блога Яндекса необходимо вызвать: python hubs.py --alsoread yandex --company.
Для создания гистограммы на основе коэффициента Жаккара используется ключ --similar: python hubs.py --similar space
Для вывода максимальных (минимальных) значений до N хабов по включению или коэффициенту Жаккара без самой гистограммы, необходимо вызвать ключ --max (--min): 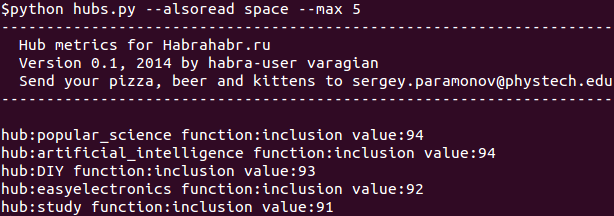
Идеи для следующих tools Монитор статей: после написания статьи нужно будет вызвать тул monitor $article_id и она будет записывать и рисовать изменение просмотров (плюсов, etc) во времени, а так же shares and likes в социальных сетях и возможно комментарии читателей.Веб интерфейс: все тоже самое, но доступное через веб.
Идеи, комментарии, помощь зала и предложения особенно приветствуются.
