gRPC на практике: особенности, преимущества и недостатки

Разрабатывая экосистему для «Метр квадратный», мы со старта проекта планировали большую линейку продуктов. Поэтому подбирали стек, который поможет реализовать максимум идей. В итоге мы пришли к протоколу gRPC.
В этом материале я расскажу:
о преимуществах gRPC;
об особенностях работы с протоколом, и о том, как с ними жить;
о тех проблемах, с которыми мы столкнулись;
и о том, как их решить.
С подобной темой я выступал в сентября 2021 года на техническом митапе АльфаБанк & m² «MeetUp Backend Stories». Если любите смотреть видео, а не читать, запись тут.
Почему выбрали gRPC ― преимущества протокола
Можно выделить 5 преимуществ, которые определили наш выбор. Первое из них очевидно для всех, кто сталкивался с gRPC на практике. Речь про скорость работы.
1. Скорость работы
Здесь используется бинарная сериализация Protocol Buffers ― protobuf. По некоторым подсчетам, она в семь раз быстрее, чем сериализация в JSON. Мы не проводили собственные замеры, но в сети много тестов, которые это доказывают, например, статьи Дэвида Чао и Рувана Фернандо.
Еще немного скорости добавляет HTTP/2 благодаря постоянному соединению. Это удобно, так как в одном канале может быть замультиплексировано несколько запросов, идущих фреймами. Благодаря HTTP/2, не нужно заново устанавливать соединение под каждый запрос.
2. Спецификация
Проблемы с разработкой спецификации ощущаются, например, в REST. Там для описания используют OpenAPI, Swagger и множество других менее популярных инструментов. Однако, разработка спецификации оторвана реализации. Конечно средства кодогенерации существуют, но они не обязательны, к тому же многие предпочитают практику Code First.Так что, проходит время, и реализация уже не соответствует документации.
В gRPC эта проблема стоит не так остро. Разработка начинается строго с контракта: необходимо сначала описать proto-файлы и затем преобразовать контракт в заглушки для реализации клиента.
Для этого существует множество плагинов кодогенерации, написанных Google. В том числе для java, C++, Python.
На старте мы использовали java, потому что этот язык подходит и для десктопных, и для мобильных клиентов. А когда в работу включились аналитики, без проблем сгенерировали для них Python-клиент.
3. Обратная совместимость
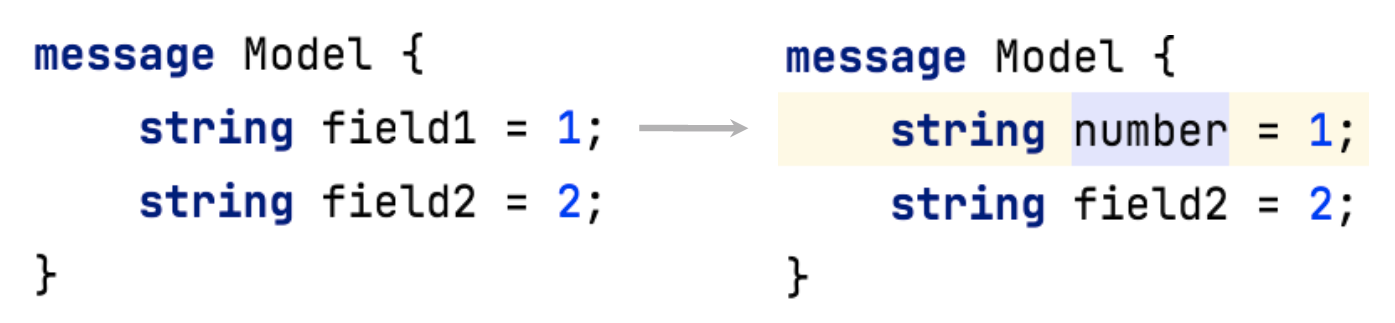
Благодаря особенностям сериализации, gRPC удобно изменять по мере развития API.
Например, поддерживается переименование полей без изменения номера, без изменения ключа. Есть возможность безболезненно изменять простое поле в массив repeated.
4. Переиспользование контракта и обратная совместимость
gRPC позволяет переиспользовать описание сообщений, которые мы посылаем в Kafka.
Так как протокол может похвастаться хорошей обратной совместимостью, он позволяет долго хранить данные, и не бояться, что однажды мы не можем их прочитать. Это заметный плюс для топиков с большим retention. А использование бинарных данных экономит место.
5. Deadlines
Пятое преимущество лучше показать на конкретном примере.
Представьте себе сервис, связанный с несколькими микросервисами внутри вашего контура. Они используют базу данных и некую внешнюю систему.

Клиент делает запрос к сервису, один из связанных микросервисов зависает, но, в случае с gRPC, таймаут останавливает распространение запроса по сети.
Да, в HTTP/1.1 появилась возможность отслеживать разрывы соединений, но в gRPC это реализовано более нативно. Главное, не забывать выставлять deadlines, потому что по умолчанию задается достаточно большое время ожидания запроса клиентом.
Особенности gRPC
При всех преимуществах, у gRPC есть особенности, которые приходится учитывать в работе.
Значения по умолчанию
Так, JSON позволяет контролировать процесс передачи пустых полей. В зависимости от сериализатора поле передается либо как null, либо пропадает вовсе.
В gRPC иначе. Если сообщение не содержит какого-то поля, оно парсится в значение по умолчанию. Для примитивных типов это стандартные значения: ноль для числовых типов, пустые строки для других сообщений.
У вложенных объектов значение зависит от реализации. Например, клиент для Java предоставляет значения по умолчанию с полностью пустыми полями.
Это мешает некоторым клиентам. Они получают объекты, поля которых заполнены значениями по умолчанию, но не могут проверить, что там находилось до передачи ― пустое поле или реальное значение.
Для сравнения, в протоколе protobuf 2.0, можно отметить поля required и optional, а в protobuf 3.0. предусмотрены объекты-обертки для примитивных типов.
Невозможность пересечения по именам enum
Кроме того, стоит учитывать, что в gRPC нельзя объявить в одном контексте два одинаковых значения для разных enum. Это связано с кодогенерацией в C++ и с одним из его стандартов.

Чтобы справиться с этой особенностью, приходится менять наименование константы. Необходимо либо объявить enum внутри сообщения, либо использовать префиксы. А еще нельзя использовать enum в качестве ключа для типа данных map. Нельзя и объявлять map как repeated.
Возможно, это несущественные особенности, но они влияют на читаемость протокола.
Vendor Lock
Еще один спорный момент, это vendor lock. Де-факто Google является основным драйвером и определяет направление развития протокола. И не всегда оптимальным образом.
Приведу в качестве примера различия протоколов protobuf v1 и v2. Между ними нельзя мигрировать один в один ― мешают обязательные и необязательные поля, возможность расширения месседжа во второй версии, но отсутствие этой возможности в третьей, и так далее.
С какими проблемами при использовании gRPC мы столкнулись?
Мы учитывали вышесказанное еще на стадии разработки MVP, но были и неожиданные сложности.
Интеграция с браузером
Сперва мы решили использовать для интеграции с фронтендом BFF ― Backend-for-Frontend паттерн. То есть, применить адаптер, преобразующий gRPC API в независимое API, которое можно адаптировать под запросы фронтенда.

Со временем ситуация сложилась так, что драйвером для развития API выступили сервисы, а BFF занимались маппингом полей из gRPC в REST. Там небольшие различия, так что это достаточно тривиальная задача.
При этом адаптер требовал дополнительных ресурсов для развертывания, поддержки и мониторинга. Да и на ведение документации сил не хватало.
Получился REST, описания которого никто толком не знал. Постоянно приходилось заглядывать в код. В результате, чтобы упростить взаимодействие с фронтендом, мы перешли на gRPC-web.
gRPC-web
В этой реализации у нас есть клиент в виде браузера и есть прокси — Envoy, которое фактически преобразует запросы из HTTP/1.1 в HTTP/2.0. При этом мы получаем бинарные сообщения протокола protobuf.

Это дает ряд преимуществ:
мы используем исходные описания протокола. Не нужно ничего дополнительно описывать, мы знаем, какие поля ожидать, и как все это будет выглядеть;
кодогенерация поможет сделать javascript клиент.
Но есть и недостатки:
толстый бандл мешает дальнейшей оптимизации работы на фронтенде;
бинарный обмен сообщениями усложняет отладку.
gRPC-transcoding
В gRPC с помощью специальных опций можно определить, как будет выглядеть транскодированный REST API: как будут выглядеть методы, из чего будет состоять json, тело запроса.
Для этого также требуется промежуточное звено в виде прокси-сервера, который будет выполнять преобразование. Мы использовали envoy.

Так мы получим понятное описание API, которое можно посмотреть в proto-файлах и распространять между разработчиками. При этом пропадает необходимость в BFF: мы получаем понятный, привычный json на фронте.
Но у такого решения есть и спорные моменты:
то, что является переносимыми изменениями в protobuf, в json становится непереносимыми изменениями. Например, к этому чувствительны переименование полей и множественные поля. При преобразовании json это придется учитывать.
мы убрали BFF, но добавили новый узел в виде envoy, так как он необходим для транскодирования.
Существует еще один путь. В gRPC экосистеме предусмотрен gRPC-gateway, который выполняет аналогичные функции. Он генерируется с помощью плагина protoc. Но мы не стали его использовать по нескольким причинам.
На начальном этапе мы планировали использовать service mesh системы и смотрели в сторону istio. А Istio использует envoy в качестве сайдкар контейнеров. Было бы здорово отработать транскодинг уже с тем сервисом, который будет использовать сервис mesh.
Код на GO. Это дополнительный язык, который нуждается в поддержке, а нам не хотелось заводить зоопарк.
Также из неудобного стоит отметить:
кривой swagger на выходе с транскодинга;
партнеры, с которыми мы интегрируемся по АПИ, часто не понимают, что такое gRPC и, вероятно, не захотят работать с этим протоколом. Следовательно им все равно нужен REST.
Еще из спорных моментов можно выделить то, что ошибки передаются в заголовках. Это неудобно. В целом к маппингу возникает много вопросов: он прописан в рекомендациях gRPC, но многие отмечают его неоднозначность.
Балансировка запросов
При использовании микросервисного подхода возникает необходимость в масштабировании сервисов.
Когда создается несколько экземпляров сервиса запросы клиентов обычно балансируются при помощи промежуточного звена, например, nginx. Мы используем Kubernetes и соответственно в нашем случае балансировка будет происходить с помощью стандартного сервиса Kubernetes.
Схематично это выглядит так: клиент делает запрос, который направляется на один из серверов. Далее для нового запроса выбирается уже следующий экземпляр.
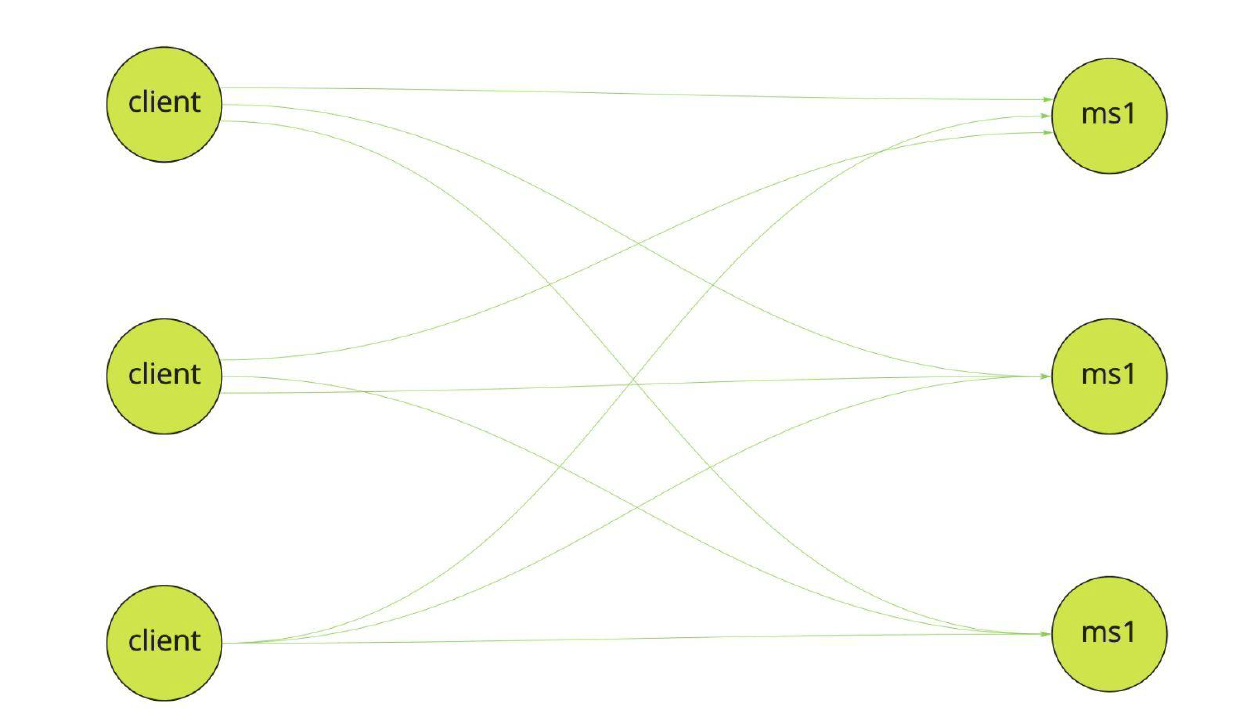
gRPC работает по другой схеме. Так как устанавливается постоянное соединение, в худшем случае все соединения устанавливаются с одним сервисом, неважно, сколько экземпляров запущено.

Чтобы этого избежать, можно использовать отдельный прокси-балансировщик, например, Envoy. Он поставляется в Istio. Это service-mesh система которая занимается честной балансировкой.
Еще один путь ― сбор адресов всех экземпляров сервиса и балансировка на клиенте.
В случае прокси-балансировщика остается бутылочное горлышко, куда будут направлены все запросы, и балансировщик будет вынужден их распределять.
Балансировка на клиенте позволяет обойтись без дополнительного узла, но вся сложность балансировки находится на клиенте. Приходится эту сложность распространять на каждого клиента, и если пропустить одного, балансировки не будет.
На данный момент мы выбрали балансировку на клиенте, которую предоставляет стандартная библиотека gRPC, а занимается ей DNSNameResolver, основывающийся на адресах, которые возвращает DNS. Чтобы получить эти адреса, мы используем headless-сервисы Kubernetes. Они выступают в роли аналога DNS.
var channel: ManagedChannel = ManagedChannelBuilder
. for Target («dns:///service-headless:9090»)
.defaultLoadBalancingPolicy («round_robin»)
. build ();
Конфигурация канала нашего gRPC клиента
У этого варианта лишь один серьезный минус. Изменения конфигурации, добавление сервисов и другие изменения в настройки «из коробки» не всегда доносятся до клиентов. Возможны проблемы с подключением к отдельным клиентам, рассинхрон. Так что в дополнение к DNSNameResolver рекомендуют использовать внешние discovery-системы и look-aside балансировщики .
Нерешенные проблемы
Экосистема spring
Для стабильной работы системы необходимо, чтобы протокол поддерживался со стороны фреймворка. Мы используем для разработки микросервисов экосистему spring. Однако, два года назад, на момент старта проекта, spring не поддерживал gRPC.
Поэтому мы встали перед выбором: либо писать все самостоятельно, используя библиотеку, которую предоставляет gRPC, либо искать сторонние стартеры.
Мы остановились на стартере от LogNet, и пользуемся им до сих пор. Он позволил нам включить gRPC-сервис в контекст spring, но некоторые вещи все равно пришлось делать самостоятельно, например, авторизацию.
Это небольшой объем кода, и все же, это написание собственного интерцептора, парсинг токенов, ручная аутентификация в Authentication Manager.
В результате получилась однобокая реализация под текущие нужды: мы не знаем, что будет дальше, но нам придется как-то поддерживать этот код.
Трассировка запросов
В gRPC не поддерживается трассировка запросов. В spring есть spring sleuth, но там нет трассировки gRPC.
На практике мы используем библиотеку Brave ― просто сконфигурировали этот код и вставили трассировку в нужное место цепочки вызова.
Интеграция с sentry
Мы используем Sentry для регистрации инцидентов, в частности, исключений, которые происходят внутри наших сервисов, и для этого также используем самописный стартер.
vat attributes = call.attributes
//since there were no point in visibility-restriction attributes content
//but for some reason they still deprecate this method
for (key in attributes.keys ()) { record (key.toStringO, attributes[key])
}
При этом пришлось использовать deprecated API библиотеки gRPC для того, чтобы получить все необходимые данные из запроса. Этот метод уже давно обещают удалить из библиотеки. Пока этого не случилось, но скоро придется искать другие способы добычи атрибутов запроса.
Все это уже написали!
Самое забавное, теперь мы понимаем, что изначально поставили не на ту лошадку. За время разработки хорошее развитие получил другой Spring Boot стартер. В аналогичном проекте стартера появилось все, что нам нужно: метрики, различные конфигурации авторизации, трейсинг.
Заранее не угадаешь, что будут поддерживать, а что нет. Это основной минус выбора стороннего решения. Всегда остается вероятность, что развитие и поддержка прекратятся, и придется заниматься этим самостоятельно, вкладывать силы и время.
Подведем итоги
При построении с нуля системы на gRPC стоит учитывать, что это протокол, который поддерживается Google, а политика Google может измениться в любой момент.
Необходимо понимать, понимать какой объем инфраструктурного кода придется написать для поддержки gRPC (условно говоря ― какие будут запросы).
Важно заранее определиться с областью использования. У нас не возникало сложностей в использовании gRPC внутри системы. Однако, стоит выйти за ее пределы, появляются разнообразные вопросы и сложные моменты.
