Грехи оптимизации производительности. Александр Валялкин, VictoriaMetrics

Доклад посвящен теме оптимизации производительности, но не совсем оптимизации производительности, а грехам оптимизации производительности (в VictoriaMetrics).
Видео
Что это такое — расскажу попозже. Сначала расскажу немного о себе.

- Я — Александр Валялкин. Мой ник valyala.
- Я автор библиотек на Go таких, как Fasthttp, Fastjson, Quicktemplate. Эти библиотеки оптимизированы по скорости.
- Я увлекаюсь оптимизацией производительности.
- И в данный момент я работаю над собственной timeseries базой данных VictoriaMetrics.

Когда нам нужна оптимизация производительности? Есть несколько кейсов, когда это нужно:
- Когда ваша программа работает медленно.
- Когда ваша программа требует очень много hardware ресурсов, чтобы она нормально работала, и вы хотите уменьшить свои расходы на эти ресурсы.
- И третий кейс — это benchmark games. Мы любим оптимизировать наши программы, чтобы они показывали хорошие результаты в benchmarks. Эти результаты необязательно будут соответствовать хорошим результатам в production.

Понятно, что оптимизация производительности не всегда приводит к общему улучшению вашей программы. Она не всегда бесплатна. И цена может быть слишком высока для того, чтобы продолжать заниматься производительностью.
В этом докладе я покажу примеры из реальных проектов из Fasthttp, fastjson, VictoriaMetrics. Несколько примеров будет из стандартной Go библиотеки. Последний пример вообще не будет касаться Go. Это про процессоры.

Начнем с Fasthttp. Fasthttp — это альтернатива стандартного пакета net/http, которая предоставляет сервер и клиент, и которая оптимизирована по скорости.

В Fasthttp мы рассмотрим такие примеры, как:
- Буферизация ответа.
- Отложенный парсинг HTTP headers.
- Использование slices вместо maps для хранения
key->valueзначений. - Переиспользование объекта
requestCtx. - И кэширование DNS записи.

Начнем c буферизации ответа. Вот так выглядит стандартная обработка HTTP протокола на Go. Это псевдокод.
Мы получаем хэндлер соединения в функцию. Эта функция читает http запрос из этого соединения. Проверяет, закрыто ли соединение или нет. Если закрыто, то входим из функции. Если не закрыто, то обрабатываем полученный запрос и отправляем ответ в соединение. Делаем это в цикле, т. к. соединение у нас может быть keep-alive, к которому может приходить много запросов.
Что в этом коде плохого? То, что он на каждый запрос, на каждый ответ должен читать и писать из/в соединение, т. е. делать системный вызов.

Чтобы это исправить, мы делаем вот так. Это функция, которая оптимизирована для обработки HTTP pipelining запросов.
HTTP pipelining — это когда клиент отправляет в HTTP соединение на сервер несколько запросов, не дожидаясь ответа на предыдущие запросы.
Вот как выглядит оптимизированная функция. Мы заворачиваем соединения в буфера. Это bufio.NewReader и bufio.NewWriter. Затем в цикле читаем запросы из буферизированного соединения. Снова проверяем: если соединение закрыто, то отправляем все, что у нас есть в Write буфере.
Тут тоже самое, что было и на предыдущем слайде. Мы обрабатываем соединение и записываем ответ уже не напрямую в соединение, а в буфер, стоящий перед соединением.
После этого идет оптимизация для pipelining connection. Что она делает? Она проверяет — есть ли у нас еще в буфере на чтение какие-то данные, где у нас запросы приходят. Если этот буфер пустой, значит, надо отправить все ответы, которые накопились в буфере на запись.

Что нам такой код дает? Как я уже говорил, он уменьшает количество системных вызовов, необходимых на чтение и запись данных. Буфер по умолчанию равен 4 килобайта. Т. е. при первом чтении из соединения, которое завернуто в bufio.Reader, reader пытается считать до 4-х килобайт данных и поместить их в буфер.
В 4 килобайтах данных может находиться не один запрос, а много запросов. Таким образом, мы с помощью одного системного вызова получаем сразу много запросов и обрабатываем в этом цикле.
То же самое касается записи ответов. При записи в буферизованное соединение данные записываются в буфер до 4 килобайт прежде, чем попасть в нижележащее соединение. Для того, чтобы данные отправились дальше клиенту, нужно явно вызывать функцию «flush». Вот она здесь. Таким образом мы экономим количество системных вызовов, необходимых на отправку ответа клиенту. Это преимущество данной штуки.
https://en.wikipedia.org/wiki/HTTP_pipelining#Implementation_status
https://github.com/TechEmpower/FrameworkBenchmarks/issues/4410
Но в ней есть и недостатки.
Первый грех в том, что HTTP pipelining подвержен head of line blocking. По-русски это означает, что, если мы отправили несколько запросов в HTTP connection и если первый запрос требует много времени на выполнение, то все остальные запросы после него будут ждать выполнения первого запроса, даже если все остальные запросы могут выполниться намного быстрее. Таким образом, это увеличивает время ответа на последующие запросы.
Второй недостаток. На самом деле случаев применения HTTP pipelining в реальной жизни мало. Например, все современные браузеры, хотя и поддерживают HTTP pipelining, но он у них всегда отключен. Почему? Потому что большинство серверов HTTP, которые были популярны в начале и в середине 2000-ых годов, не поддерживали HTTP pipelining, либо имели ошибки в реализации HTTP pipelining. Поэтому исторически сложилось, что все браузеры поотключали HTTP pipelining. Сейчас вышел HTTP 2.0 протокол. И вместо того, чтобы возобновить HTTP pipelineing, все браузеры просто включили HTTP 2.0.
И самый главный недостаток оптимизации под HTTP pipelining — это то, что я его сделал для того, чтобы увеличить производительность в Techempower benchmarks в два раза. Techempower benchmark — это бенчмарк, который проверяет скорость разных HTTP серверов на разных типах запросов. Там есть один тип запросов, который называется plaintext. Это когда отправляется 16 pipelining requests и ожидаются ответы от сервера. Для данного теста HTTP pipelining оптимизация позволила увеличить скорость fasthttp сервера в 2 раза.
Недавно эту штуку поломали. Пришлось заводить баг. Можете потом по нему пройтись, посмотреть, почитать, как ее потом починили.

Следующий пример — это отложенный парсинг HTTP headers.
Fasthttp не парсит сразу HTTP headers в запросах. Он ищет маркер окончания HTTP headers. Это два перевода каретки. И складывает нераспарсенный headers в byte slice локально. Этот byte slice парсится только при первом обращении к HTTP headers.

Вот пример кода на Fasthttp, при котором HTTP header вообще не будет распарсен. Этот код пишет: «Hello, world!» в http ответе и не читает http headers.

А вот код, который читает http headers. Соответственно, на этой строчке при чтении header «X-Forwarded-For», Fasthttp сервер на этой строчке парсит HTTP header.

Какие преимущества от такой оптимизации? Понятно, что HTTP сервер будет работать быстро, когда нет обращений к HTTP headers каждого запроса.
Недостатки этой схемы — это то, что в реальной жизни http сервера обычно читают эти заголовки. Эта оптимизация показывает свое преимущество в том же бенчмарке, где код выглядит вот так, как здесь. Просто отправляется ответ и все.

Использование slices вместо maps. Fasthttp использует slices вида key->value вместо стандартных go«шных map’ов для того, чтобы хранить список аргументов, т. е. список заголовков, query args, список cookies.

Рассмотрим, как это выглядит. Вот у нас есть структура key->value с двумя полями byte slices.

Вот так выглядит добавление элемента в slice map.
Что мы здесь делаем? Мы помним, что slice map — это у нас byte slice. Поэтому мы сохраняем его во временную переменную kvs и проверяем — есть ли в этом byte slice еще место для дополнительной записи. А если capacity выше, чем его длина, то значит, место еще есть. Мы увеличиваем длину на единичку. На этой строчке мы экономим выделение памяти. Если у нас нет дополнительного элемента в slice, то мы его добавляем. И потом обращаемся к этому элементу. В этом элементе записываем ключ-значение. И тут используем такую запись — [:0], что означает, что мы переиспользуем память, которая уже выделена под эти kv.value, если они раньше были где-то выделены.
Такой код позволяет переиспользовать как элементы slice map, так и kv.value byte slice в каждом slice map. И, соответственно, это позволяет экономить выделение памяти.

Вот так реализовано чтение данных из slice map. Мы тут просто проходимся по всем элементам slice map«а и сверяем ключ. И если ключ совпадает с нужным нам, то возвращаем значение. Ничего сложного.

Какие преимущества у этого метода? В обычных условиях те элементы, в которых используются slice maps, это заголовки, query args и cookies, содержат небольшое количество элементов — не более пары десятков. Для такого количества slice maps работают быстрее, чем стандартная map в Go.
Также, как я показал на предыдущем слайде, slice maps позволяют переиспользовать память в отличии от обычных maps. Т. е. мы можем переиспользовать те же самые slice maps много раз и таким образом экономить на выделении памяти.
И еще одна фича, которая бывает иногда необходима — это сохранение исходного порядка элементов, которые были у нас получены в запросах. Т. е. если у нас были получены query args в определенном порядке, то в slice map они будут храниться в этом же порядке, в отличии от map, где этот порядок будет случайным при чтении из этой map.

Но у этого метода есть недостатки. Если у вас количество этих query args или заголовков слишком большое, то, как вы видели из предыдущего слайда, чтение данных из slice map — это O(N) операция, т. е. для того чтобы прочитать все данные, необходимо пройтись по всем элементам slice. Это может быть очень медленно, если вы читаете из slice map, который содержит тысячу или миллион элементов.
Второй недостаток — в том, что slice map подвержен фрагментации. Это означает, что если в slice map сохраните какое-то большое значение, например, мегабайт, то после этого этот slice map всегда будет занимать этот мегабайт, даже если вы будете в него записывать маленькие значения.
И последний недостаток — в том, что значение, которое возвращается из slice map, принадлежит этому slice map. Поэтому оно становится невалидным после того, как этот slice map будет переиспользован. И про это нужно помнить.

Следующий пример — это переиспользование RequestCtx объекта. RequestCtx — это основной объект, который заменяет стандартный http.ResponseWriter и http.Request. Это единственный объект, который передается в ваш RequestHandler. И этот объект переиспользуется HTTP сервером.
Вот как это выглядит. Это тоже псевдокод. Мы получаем из пула наш RequestCtx. Затем в цикле читаем запрос. Он помещается в ctx.Request. Вызываем ваш RequestHandler с вашим RequestCtx и потом записываем response в connection. И это делается в цикле. Т. е. ваш RequestHandler будет переиспользовать этот RequestCtx объект, и все, что в нем находится, при каждом вызове вашего RequestHandler.

Какие в этом преимущества? Преимущества в том, что мы переиспользуем этот RequestCtx. Соответственно, уменьшается количество выделений памяти, увеличивается локальность данных. И увеличивается скорость работы.

О недостатках, я думаю, вы уже догадались. Такой API легко неправильно использовать. Самый распространенный кейс, когда вы берете какой-то объект из этого RequestCtx в вашем RequestHandler и сохраняете где-нибудь по ссылке, либо передаете в горутину, которая параллельно исполняется. Эта ссылка остается жить после возвращения из RequestHandler. Соответственно, в данном месте вы сразу получаете неправильную работу Fasthttp, т. к. по этой ссылке при последующем переиспользовании этого RequestCtx объекта, будет хранится мусор, а не то, что вы ожидали.
И есть еще проблема, как в предыдущем примере — это фрагментация памяти. Если у вас в RequestCtx поместится какой-нибудь большой request response body, либо какой-то большой объект. Большой объект при последующем переиспользовании RequestCtx объекта будет занимать память, даже если этот объект уже удалили. Про это нужно помнить.

Следующий пример — это кэширование DNS. В Fasthttp кроме сервера есть еще и клиент. Для клиента используется resolve DNS имя. В Fasthttp реализовано DNS кэширование, т. е. для ускорения этого resolving. Fasthttp кэширует mapping между name и ip в течение минуты.
Вот псевдокод, как это выглядит. Вот resolveHost. Здесь у нас dnsCache map«a. Мы проверяем есть ли там запись. Если она есть, и если время добавления ее туда не превышает одной минуты, то мы возвращаем эту запись. Это псевдокод, тут не хватает locks. Он специально так сделан, чтобы упростить слайды. На самом деле там все сложнее, но выглядит примерно так.

Какие преимущества? Мы ускоряем DNS resolving.
Недостатки — это то, что такое кэширование ломает ваши HTTP клиенты в окружениях, где часто меняется DNS записи. Типичный пример такого окружения — это Kubernetes, который может при перезагрузке pods, перемещать их между вашими нодами с разными IP-адресами. И, соответственно, у вас после такой перезагрузки Fasthttp клиент будет пытаться подключиться к предыдущей ноде, на которой уже этого pod«а нет. И нужно ждать минуту, пока этот кэш не протухнет.

С Fasthttp закончили. Теперь пару примеров будет из Fastjson библиотеки.
Fastjson библиотека — это замена стандартной библиотеки encoding/json. Она работает быстрее, но не всегда лучше. Сейчас расскажу, почему.

Рассмотрим три «недостатка» fastjson:
Переиспользование памяти.
Быстрый парсинг строк.
И кастомный парсер для integers и floats.

Начнем с переиспльзования памяти. Fastjson содержит объект Parser, который используется для парсинга JSON. Все данные, которые вы парсите с помощью этого объекта, принадлежат ему.
Вот у нас пример. Мы вызываем Parser.Parse. Получаем value. Этот value принадлежит парсеру. Т. е. value хранится в объекте Parser. Потом мы читаем строку foo. Помещаем ее в b. Эта строка b также рекурсивно принадлежит этому парсеру.
На этой строчке парсим с помощью этого объекта другой JSON. После этой строчки у нас v и b, и все другие объекты, которые получены через v и через p, становятся невалидными. Т. е. у нас возвращается vv, который содержит уже распарсенную структуру, а все остальное становится уже невалидным.

Какие преимущества этой штуки? Понятно, что переиспользование памяти позволяет экономить выделение памяти и ускорять парсинг JSON.

Недостатки — это то, что API легко неправильно использовать. Если вы будете сохранять ссылки на объекты, полученные из парсера, после того, как этот парсер использован для другого JSON«а, то эти ссылки становятся невалидными и в них будет содержаться мусор.
Второй недостаток — это то, что этот парсер может с течением времени вырасти в размерах занимаемой памяти по тем же причинам, о которых рассказывал раньше. Т. е. если у вас парсятся JSON объекты разной конфигурации, где, например, вначале первый элемент занимает один мегабайт, второй 1 байт, а после этого с помощью парсера распарсился JSON, в котором элементы поменялись местами, то у вас парсер уже выделит 2 мегабайта, даже если потом вы будете парсить с помощью него маленькие элементы. Т. е. парсер будет продолжать занимать 2 мегабайта.

Следующий пример — это быстрый unescaping строк. В Fastjson он работает так. Мы ищем escape символ в строке. Если escape символов в строке нет, то мы просто возвращаем эту строку. Там нечего парсить. Если хотя бы один escape символ найден, то мы вызываем функцию, которая проходит по всем байтам этой строки и правильно анескэйпит каждый элемент этой строки.

Преимущества такого подхода в том, что строки, не содержащие escape символов, парсятся очень быстро. Потому что функция strings.IndexByte — это стандартная go«шная функция. Она оптимизирована по скорости.

Недостаток такого метода — это то, что строки с escape символами будут парситься медленно.
Второй недостаток — это то, что парсинге смешанных строк, где есть часть строк с escape символами, а часть — без, вы получите смешанную производительность, которая может быть иногда быстрой, а иногда медленной. И это не всегда приемлемо.

Следующий пример — это кастомный парсер для floats и integer в Fastjson.

Преимущества этого кастомного парсера в том, что он быстрее, чем стандартная функция из пакета strconv.

Какие недостатки? Сразу возникает вопрос: «Почему стандартные функции из пакета strconv не оптимизированы по скорости максимально?». Потому что они могут обрабатывать граничные случаи, которые кастомный парсер не может обрабатывать. На обработку граничных случаев обычно расходуется много ресурсов. Примеры edge cases. Это большие числа. Мой парсер умеет работать только с маленькими числами. А если видит большое число, то он просто вызывает strconv функцию для парсинга этих чисел. И, соответственно, на больших числах он будет работать медленней, чем стандартный strconv.
Второй недостаток — это то, что он возвращает 0, если получено неправильное число.
И третий недостаток — это то, что он может работать неправильно на каких-то граничных случаях, которые я не предусмотрел.

Теперь рассмотрим пример из VictoriaMetrics для временных рядов.

Пример интересный. VictoriaMetrics умеет принимать данные из Prometheus по remote write API протоколу. И для этого используются protobufs.

Изначально мы использовали стандартный protobuf парсер, полученный в результате кодогенерации из пакета Prometheus. Но, как выяснилось, стандартная реализация выделяет очень много памяти. Пришлось этот код оптимизировать вручную.
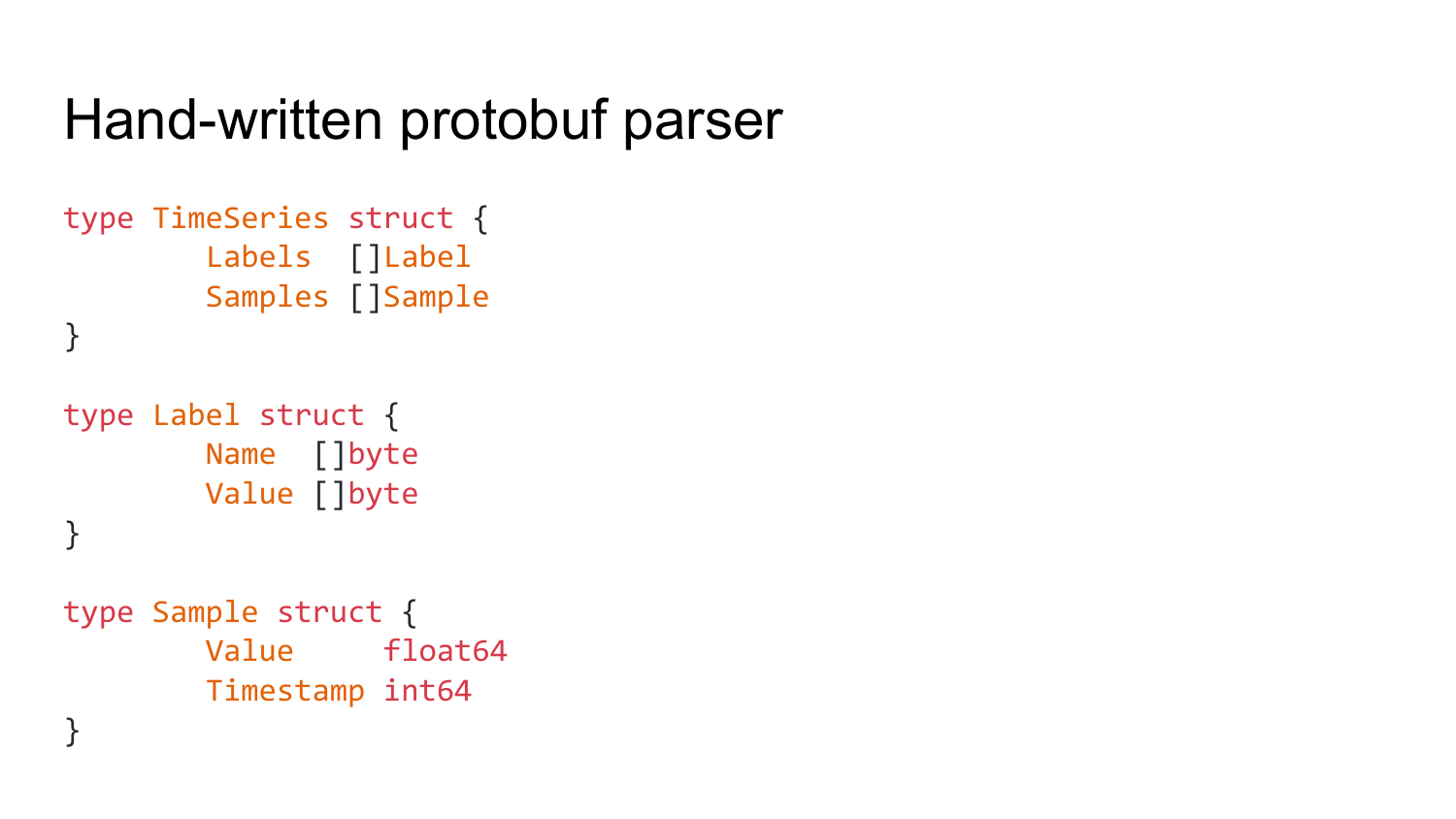
Вот пара примеров модификации. Вот как выглядит структура данных из этого protobuf. Есть timeseries, который хранит в себе набор labels и набор samples. Каждый label содержит в себе name и value. Sample, соответственно, значение и timestamp.

Пример модификации. Вначале у нас в labels тип name был string. Я его поменял на byte slice. И, соответственно, изменил в коде вот эту строчку, куда вписывается name. В этой строчке происходило копирование byte slice data в новую выделенную память в string. Соответственно, в этой строчке у нас было раньше выделение памяти. Я заменил на такую строчку. Убрал string отсюда. Я думаю, многие поняли, какой есть недостаток в этой строчке. Чуть позже расскажу.

Второй пример модификации. У нас был slice labels, т. е. slice указатель на labels. Я убрал указатели. И поменял добавление нового элемента в label в эту строчку, которая выделяет новый элемент в памяти и добавляет его в label массив на уже знакомый нам код, который проверяет размерность label. Если его capacity позволяет, то он не выделяет память, а увеличивает длину массива и переиспользует элемент.

Преимущество такого подхода в том, что мне удалось убрать все выделения памяти за счет переиспользования памяти. И, соответственно, удалось увеличить производительность парсинга protobuf.

А недостаток такого метода в том, что этот вручную написанный код сложно поддерживать. Если вспомните пример, где я заменил string на byte slice, там byte slice должен оставаться валидным до тех пор, пока мы используем этот name. Как только мы переиспользуем byte slice, из которого мы парсим protobuf, он становится невалидным, соответственно, у нас name становится невалидным, в нем начинается храниться мусор.

Тут рассмотрим два примера. Первый пример — это использование пула строк для маленьких чисел.

И второй пример — расскажу про sync.Pool.

Первый пример выглядит так. Функция strconv.FormatInt из стандартного пакета Go выглядит примерно так. Идет проверка числа Int, что оно не превышает nSmalls, который равен 99 или 100. И что base (это система счисления, в которую надо вернуть результат) равна 10. В этом случае вызывается функция small, которая возвращает строку из глобальной области видимости без выделения памяти.

Какое преимущество у этого кода? Преимущество в том, что он быстро работает при преобразовании чисел в строку, которые не превышают 100, потому что пропускается выделение памяти и пропускается парсинг этих чисел.

Недостаток в том, что этот код работает неожиданно при парсинге смешанных чисел, как больших, так и маленьких. Т. е. вы профилируете вашу программу и видите, что в ней нет выделения памяти, а потом вдруг началось выделение памяти, потому что вы там начали парсить большие числа.

Основное преимущество sync.Pool — он позволяет переиспользовать объекты без необходимости выделять под них память и инициализировать их снова.
Основной недостаток — фрагментация памяти. Например, если в sync.Pool положить большой byte slice, то он продолжит занимать память даже если после этого программа будет использовать только маленькие byte slice’ы.

Последний пример — про CPUs. Современные процессоры выполняют инструкции в многоуровневом конвейере (pipeline). Этот pipeline прерывается, как только процессор находит инструкцию условного перехода, потому что процессоры при нахождении этой инструкции дальше не знают, по какому из двух путей пойти. И это замедляет выполнение вашей программы, т. к. процессору приходится настраивать pipeline заново.
Разработчики процессоров нашли выход из этой ситуации с помощью предсказаний ветвлений и спекулятивного выполнения кода. Но, как оказалось в прошлом году — такая оптимизация производительности не совсем бесплатная. И это тоже недостаток, потому что благодаря ей, мы теперь имеем такие уязвимости как Meltdown и Spectre, из-за которых теперь приходится замедлять работу процессора.

Подведем итоги. Оптимизация производительности требует нахождения компоромиссов. Например, что лучше — скорость или читаемость кода? Или скорость или удобное API. Скорость или правильная обработка граничных случаев. И т.д.

Про Fasthttp было понятно, зачем это делаете. Т. е. для того чтобы обмануть benchmarks. А остальное? Какие-то метрики повысились на 10%, т. е. вы душу продали ради повышения производительности на 10% или на 200%?
Это зависит от задач. Но обычно производительность повышается минимум на десятки процентов. Если она повышается меньше, чем на 10%, то такие оптимизации я обычно не применяю. И в Fasthttp я привел примеры, которые позволяют улучшить результаты в TechEmpower benchmarks. Но есть куча других примеров c Fasthttp, которые дают реальный выигрыш в производительности по сравнению со стандартным пакетом net/http.
