Grafana, InfluxDB, два тега и одна сумма. Или как посчитать сумму подгрупп?

Всем привет!
Занимаюсь тестированием производительности. И очень люблю настраивать мониторинг и любоваться метриками в Grafana. А стандартом для хранения метрик в инструментах для подачи нагрузки является InfluxDB. В InfluxDB можно сохранять метрики из таких популярных инструментов, как:
Работая с инструментами по тестированию производительности и их метриками, накопил подборку рецептов программирования для связки Grafana и InfluxDB. Предлагаю рассмотреть интересную задачу, которая возникает там, где есть метрика с двумя и более тегами. Думаю, это не редкость. И в общем случае задача звучит так: подсчёт суммарной метрики по группе, которая делится на подгруппы.
Есть три варианта:
- Просто сумма с группировкой по тегу Type
- Grafana-way. Используем стек значений
- Сумма максимумов с подзапросом
Как всё начиналось
Настраивал мониторинг JVM MBean с помощью Jolokia, Telegraf, InfluxDB и Grafana. И визуализировал метрики по пулам памяти — сколько памяти выделено каждым пулом памяти в HEAP и за её пределами.
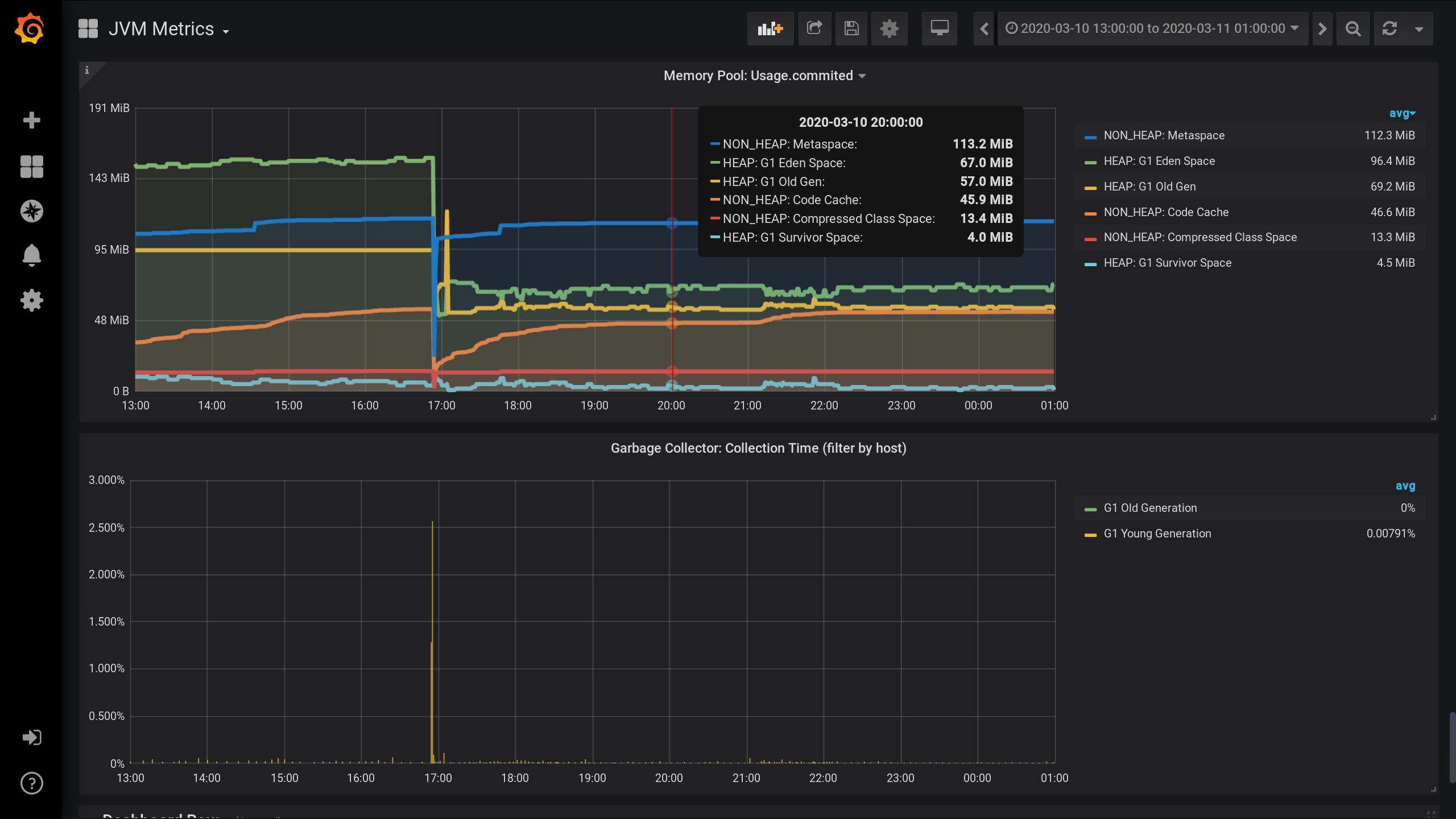
Графики по пулам памяти JVM и активности сборщика мусора с 13:00 предыдущего дня по 01:00 ночи текущего дня (период в 12 часов). Тут видно, что пулы памяти делятся на две группы: HEAP и NON_HEAP. И что примерно в 17:00 была сборка мусора, после чего размер пулов памяти уменьшился:
Для сбора метрик по пулам памяти указал в конфигурационном файле telegraf следующие настройки:
telegraf.conf
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
А в Grafana сконструировал запрос к InfluxDB, чтобы вывести в виде графиков максимальное значение метрики Usage.Committed за период времени с шагом $granularity (1m) и группировкой по двум тегам Type (HEAP или NON_HEAP) и name (Metaspace, G1 Old Gen, …):
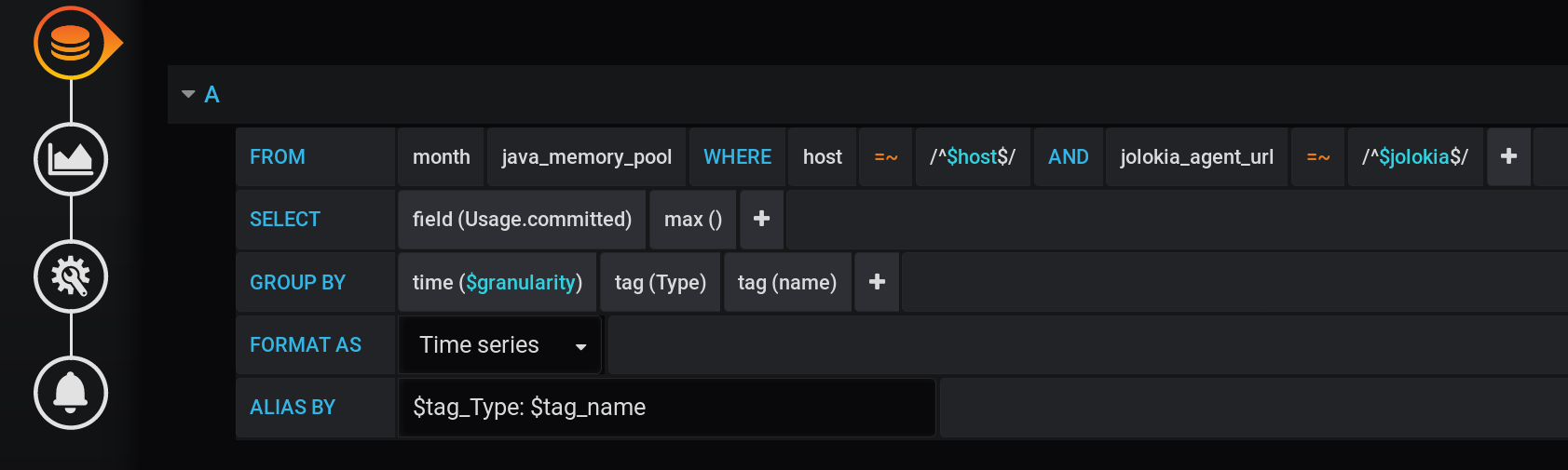
Этот же запрос в текстовом виде, с учетом всех переменных Grafana (обратите внимание на экранирование значений переменных с помощью :regex — это важно для корректной работы запроса):
SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
Этот же запрос в текстовом виде, с учетом конкретных значений переменных Grafana:
SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Группировка по времени GROUP BY time($granularity) или GROUP BY time(1m) используется, чтобы сократить количество точек на графике. Для периода времени 12 часов и шага группировки 1 минута получаем: 12×60 = 720 отрезков времени или 721 точку (последняя точка со значением null).
Запомним, что 721 — ожидаемое количество точек в ответе на запросы к InfluxDB при текущих настройках интервала времени (12 часов) и шага группировки (1 минута).
Пул памяти NON_HEAP: Metaspace (синий) в лидерах потребления памяти на момент 20:00. А по HEAP: G1 Old Gen (желтый) был небольшой локальный всплеск в 17:03. И на момент 20:00 в сумме на все NON_HEAP-пулы ушло 172.5 MiB (113.2 + 45.9 + 13.4), а на HEAP-пулы 128 MiB (67 + 57 + 4).

Запомним значения для 20:00: NON_HEAP-пулы 172.5 MiB, и HEAP-пулы 128 MiB. Будем ориентироваться на эти значения в будущем.
В разрезе Type: name значение метрики мы получили легко.
В разрезе только тега name значение метрики получить тоже легко, так как все имена пулов памяти уникальны, и достаточно оставить группировку результатов только по name.
Остается вопрос: как получить, какой размер выделен под все HEAP-пулы и все NON_HEAP-пулы в сумме?
1. Просто сумма с группировкой по тегу Type
1.1. Сумма с группировкой по тегу
Первое решение, которое может придти на ум — сгруппировать значения по тегу Type и вычислить сумму значений в каждой группе. Такой запрос будет выглядеть так:
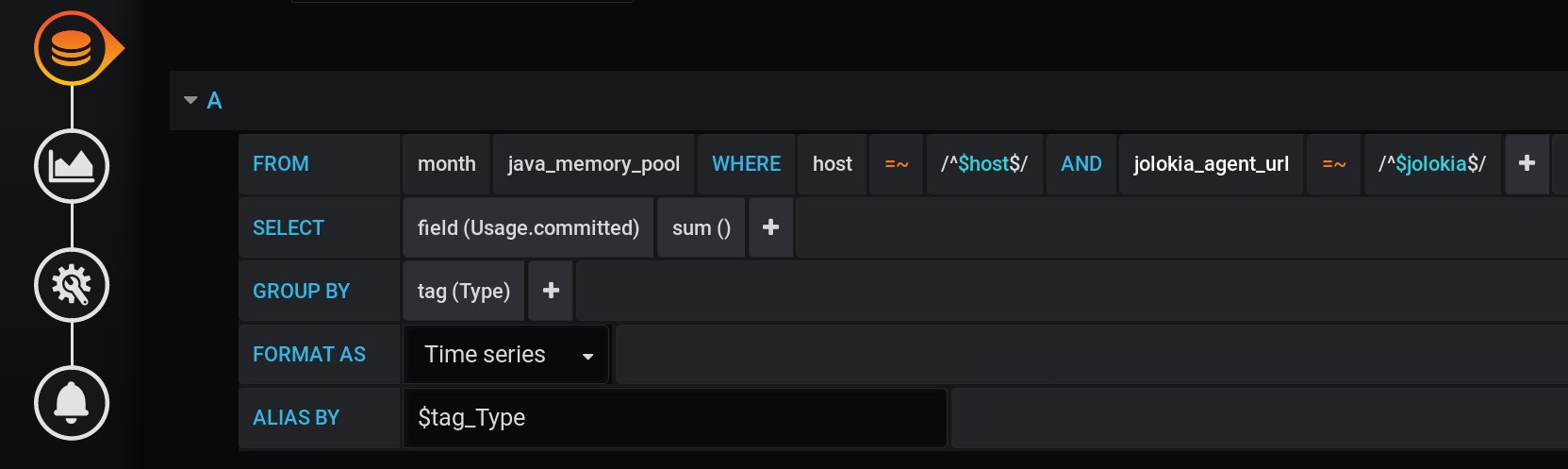
Текстовое представление запроса вычисления суммы с группировкой по тегу Type со всеми переменными Grafana:
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Это валидный запрос, но он вернёт всего две точки: сумма вычислится с группировкой лишь по тегу Type с двумя значениями (HEAP и NON_HEAP). Мы даже график не увидим. Будут две отдельностоящие точки с огромной суммой в значениях (более 3-х TiB):

Такая сумма не годится, нужна разбивка на интервалы времени.
1.2. Сумма с группировкой по тегу за минуту
В исходном запросе мы группировали метрики по настраиваемому интервалу $granularity. Сделаем и сейчас группировку по настраиваемому интервалу.
Получится такой запрос, в нём добавилось GROUP BY time($granularity):

Получаем завышенные значения, вместо 172.5 MiB по NON_HEAP видим, 4.88 GiB:
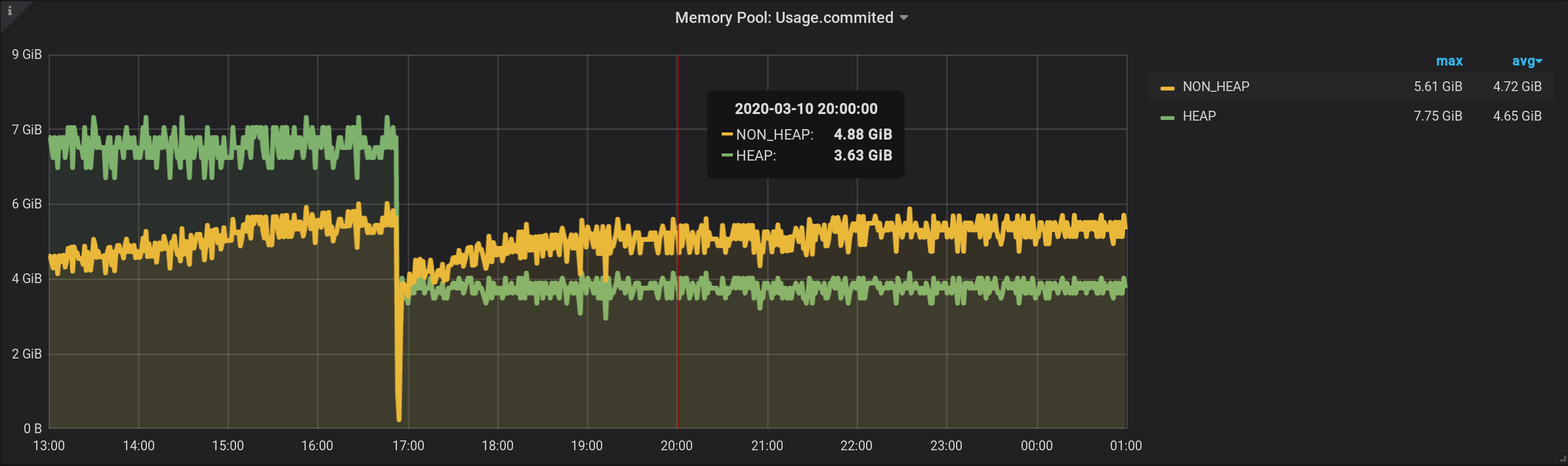
Так как метрики отправляются в InfluxDB раз в 2 секунды (смотри telegraf.conf выше), то сумма показаний за одну минуту, даст сумму не в моменте, а сумму тридцати таких сумм.
Поделить результат на константу 30 мы тоже не можем. Так как $granularity — параметр, его можно задать как равным 1 минуте, так и 10-ти минутам. И значение суммы будет меняться.
1.3. Сумма с группировкой по тегу за секунду
Чтобы верно получить значение метрики для текущей интенсивности сбора метрик (2 секунды), нужно считать сумму за фиксированный интервал, не превышающий интенсивность сбора метрик.
Попробуем выводить статистику с группировкой по секундам. Добавим в GROUP BY группировку time(1s):
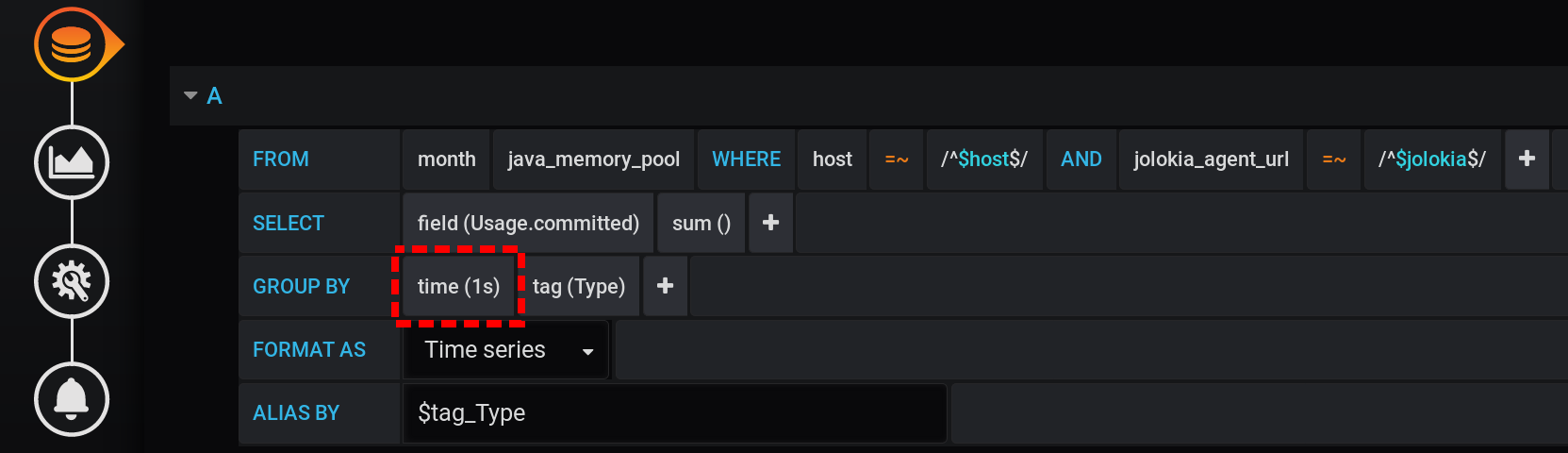
При такой малой гранулярности получаем для нашего интервала времени в 12 часов огромное количество точек (12 часов * 60 минут * 60 секунд = 43 200 интервалов, 43 201 точка на линию, последняя из которых со значением null):
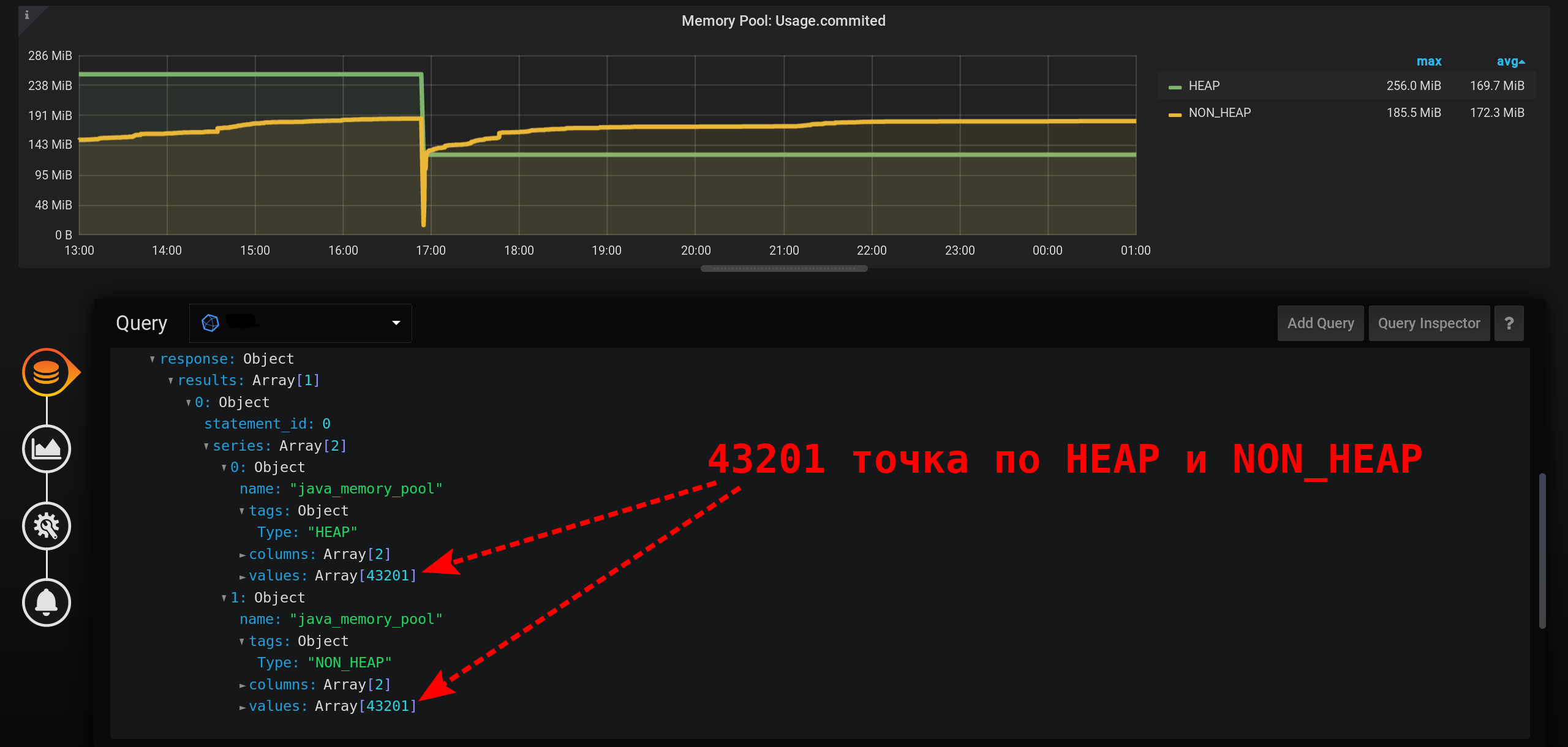
43 201 точка в каждой линии графика. Точек так много, что InfluxDB будет долго формировать ответ, Grafana будет дольше принимать ответ, а потом браузер будет долго отрисовывать такое огромное количество точек.
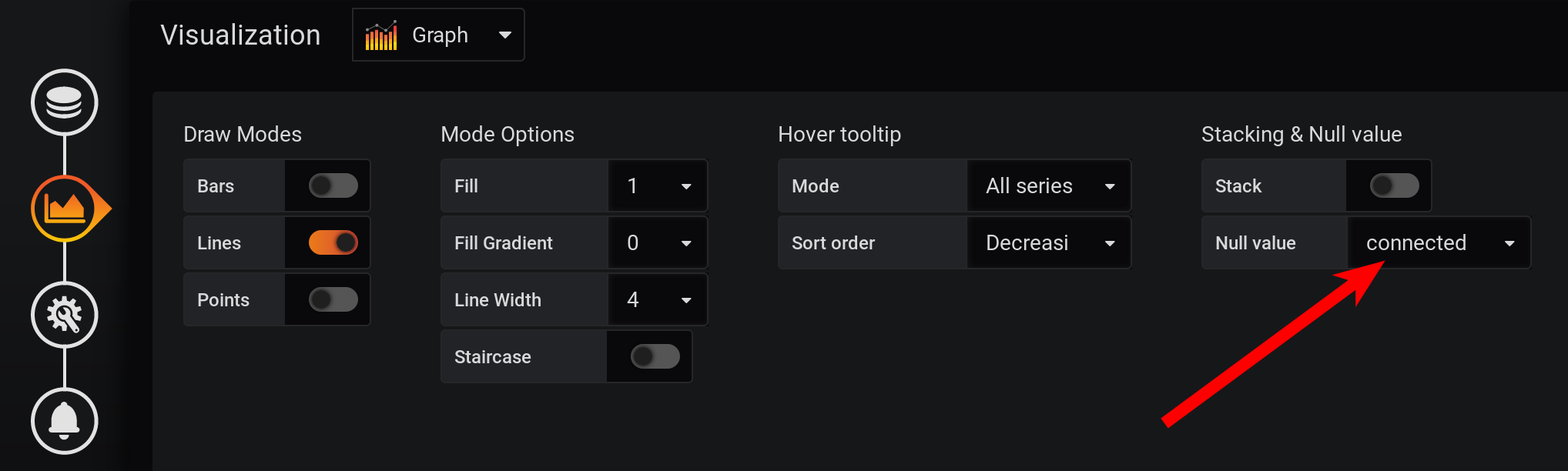
И не в каждой секунде есть точки: метрики собирались раз в 2 секунды, а группировка по каждой секунде, значит, каждая вторая точка будет со значением null. Чтобы увидеть плавную линию, настроим соединение непустых значений. Иначе графиков мы не увидим:
Раньше Grafana была такой, что браузер зависал во время отрисовки большого количества точек. Сейчас версия Grafana имеет возможность отрисовать несколько десятков тысяч точек: браузер просто пропускает часть из них, рисует график по прореженным данным. Но график сглаживается. Максимумы отображаются, как средние максимумы.
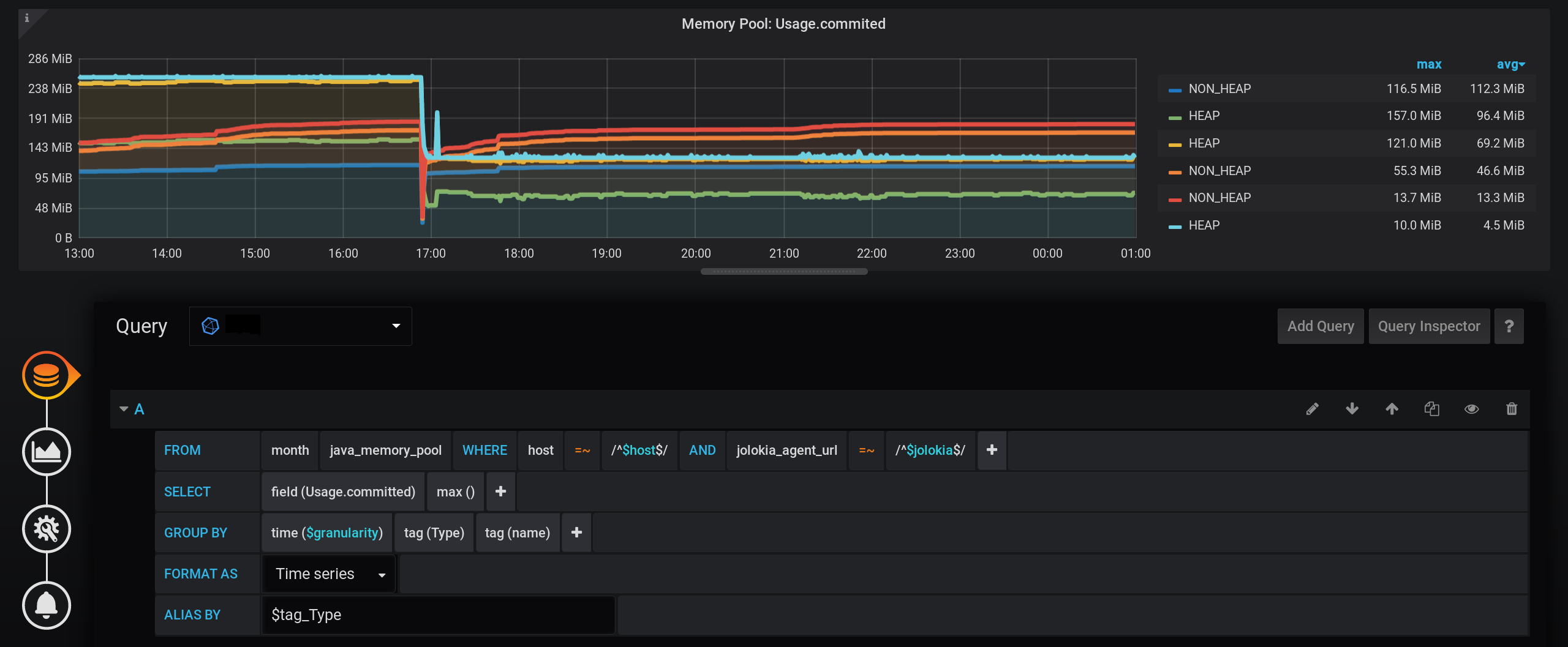
В результате график есть, отображается точно, метрики в 20:00 посчитаны верно, метрики в легенде графика посчитаны верно. Но график сглаженный: на на нём не видны всплески с точностью до 1 сек. В частности всплеск по HEAP в 17:03 пропал с графика, график HEAP очень гладкий:

Минус в производительности отчетливо проявится на большем интервале времени. Если попытаться построить график за месяц (720 часов), а не за 12 часов, то всё зависнет при такой малой гранулярности (1 секунда), точек будет слишком много. И есть минус в отсутствии пиков, парадокс — из-за высокой точности получения метрик, мы получаем низкую точность их отображения.
2. Grafana-way. Используем стек значений
Сделать простое и производительное решение с InfluxDB и конструктором запросов Grafana не получилось. Попробуем лишь средствами Grafana просуммировать метрики, выдаваемые в исходном графике. И да, такое возможно!
2.1. Просто сделаем Hover tooltip / Stacked value: cummulative
Запрос выбора метрик оставим без изменений, такой же как в разделе «Как всё начиналось»:
Метрики будут группироваться по Type и name. Но в названия графиков будем выводить только тег Type:
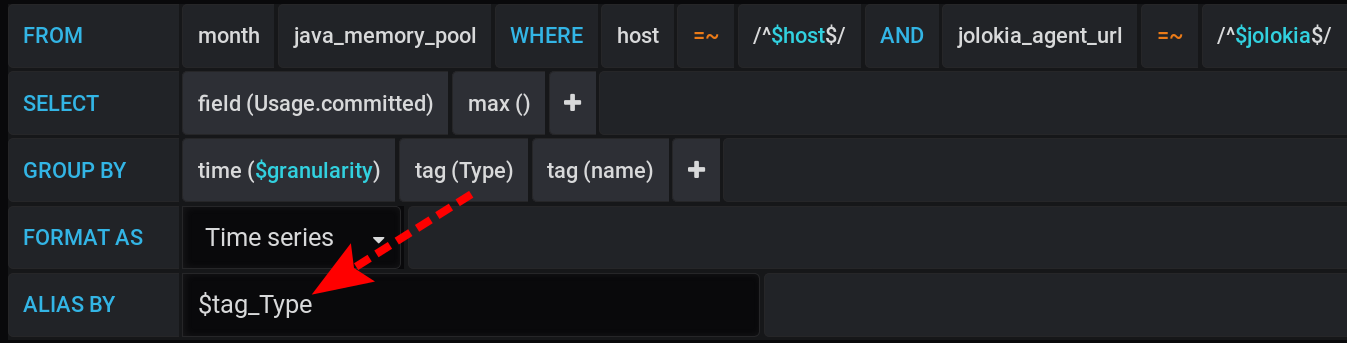
А в настройках визуализации сделаем группировку метрик по стекам Grafana:
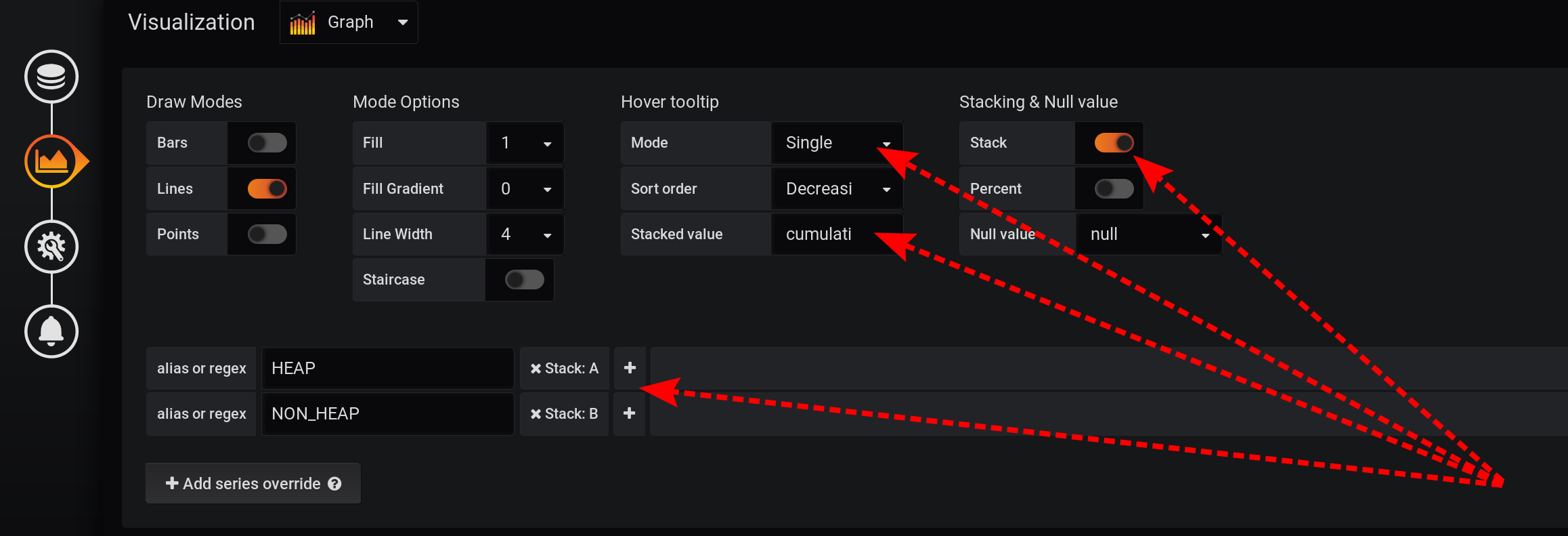
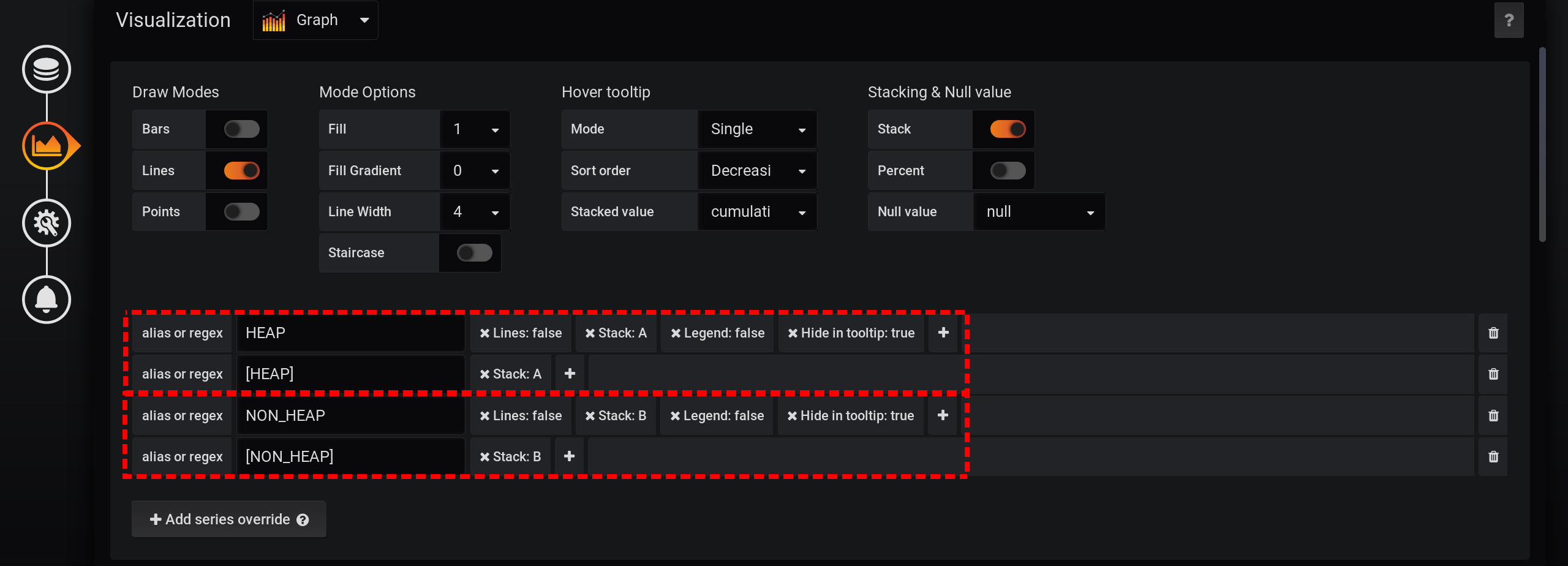
Сначала добавим разделение двух тегов на два разных стека A и B, чтобы их значения не пересекались:
- Add series override / HEAP / Stack: A
- Add series override / NON_HEAP / Stack: B
Затем настроим визуализацию метрик на отображение суммарных значений во всплывающей подсказке с графикам:
- Stacking & Null value / Stack: On
- Hover tooltip / Stacked value: cummulative
- Hover tooltip / Mode: Single
Из-за разных особенностей Grafana нужно выполнять действия именно в таком порядке. Если изменить порядок действий или оставить некоторые поля с настройками по умолчанию, то что-нибудь не сработает:
- если разделить метрики на Stack A и B уже после активации Stacking & Null value / Stack: On, то метрики не разделятся;
- если оставить Hover tooltip / Mode со значением по умолчанию, не перевести в Single, то Hover tooltip не будет отображаться вообще.
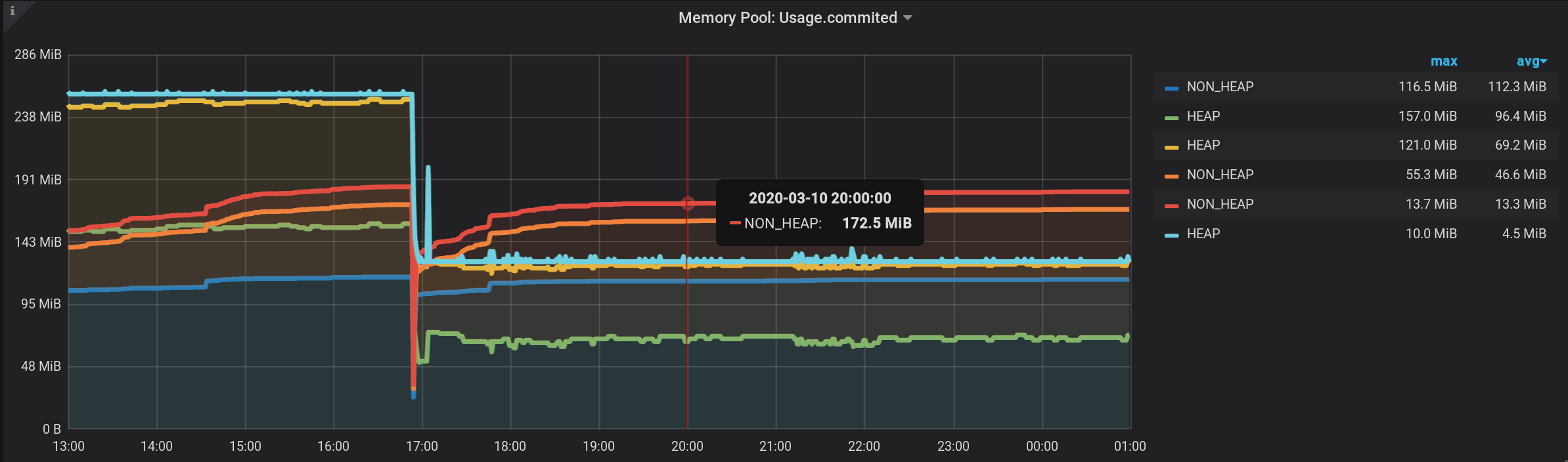
А теперь так — видим множество линий, такое себе. Но! Если навести указатель на самый верхний NON_HEAP, то во всплывающей подсказке будет видна сумма значений всех NON_HEAP. Сумма считается верно, уже средствами Grafana:
А если навести курсор на самый верхний график с именем HEAP, то увидим сумму по HEAP. График отображается верно. Даже всплекск по HEAP в 17:03 виден:
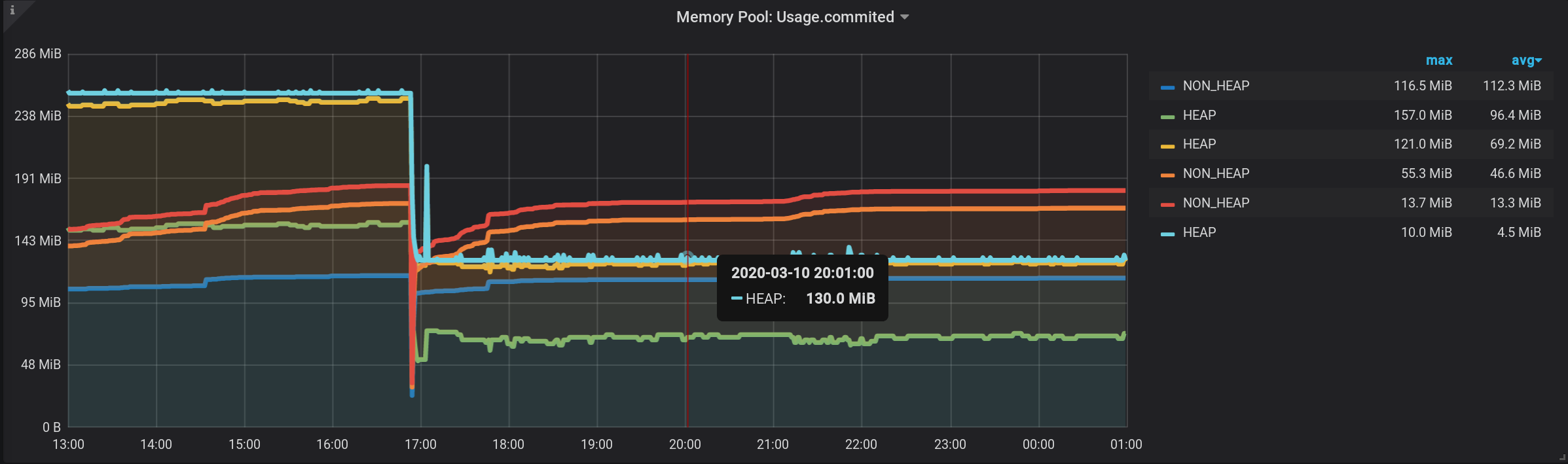
Формально, задача выполнена.
Но есть минусы — отображается много лишних графиков. Нужно попасть курсором в самый верхний из них. И в легенде к графику отображается не кумулятивные, а отдельные значения, поэтому легенда стала бесполезной.
2.2. Stacked value: cummulative со скрытием промежуточных линий
Поправим первый минус предыдущего решения: сделаем так, чтобы лишние графики не отображались.
Для этого:
- Добавим в результаты новые метрики с другим именем и значением 0.
- Новые метрики добавим в Stack A и Stack B, на вершину стека.
- Скроем из отображения — оригинальные линии HEAP и NON_HEAP.
Добавим после основного запроса два новых: запрос B на получение серии со значениями 0 и именем [NON_HEAP] и запрос C на получение серии со значениями 0 и именем [HEAP]. Чтобы получить 0, берем в каждой временной группе первое значение поля «Usage.committed» и вычитаем его же: first («Usage.committed»)-first («Usage.committed») — получим стабильный 0. Названия графиков изменены без потери смысла за счёт квадраных скобок: [NON_HEAP] и [HEAP]:
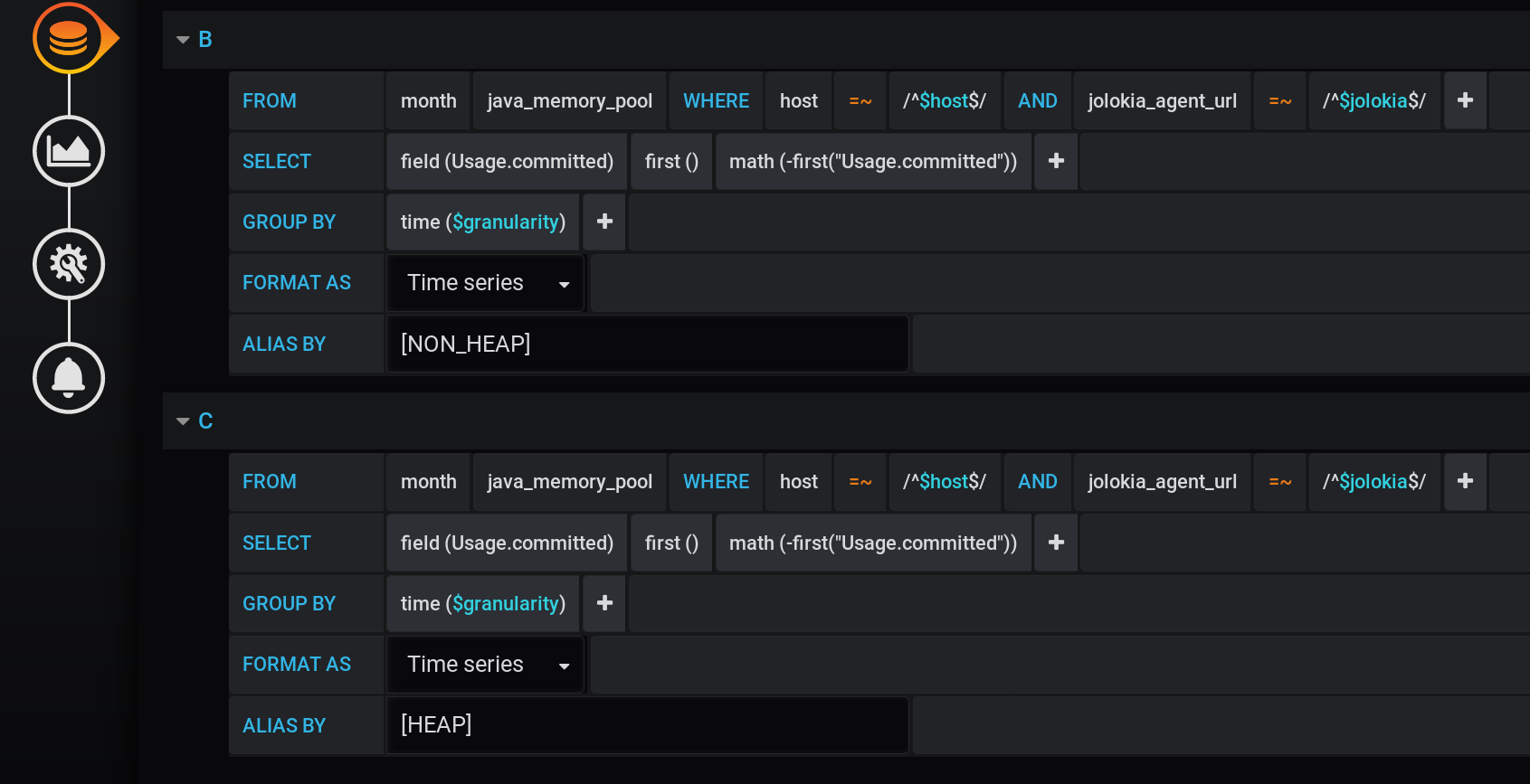
[HEAP] и HEAP объединены в Stack A, а ещё скроем все HEAP. [NON_HEAP] и NON_HEAP объединим в Stack B и скроем NON_HEAP:
Получаем корректную сумму по [NON_HEAP] в Tooltip при наведении на график:

Получаем корректную сумму по [HEAP] в Tooltip при наведении на график. И даже видны все всплески:

И график формируется быстро. Но в легенде отображается всегда 0, легенда стала бесполезной.
Всё получилось! Правда в обход — через стеки Grafana. Именно из-за этого статья добавлена в категорию Ненормальное программирование.
3. Сумма максимумов с подзапросом
Раз мы уже ступили на путь ненормального программирования на связке Grafana и InfluxDB, давайте продолжим. Сделаем так, чтобы InfluxDB вернул небольшое количество точек и чтобы легенда отображалась.
3.1 Сумма приращений кумулятивной суммы максимумов
Углубимся в возможности InfluxDB. Раньше меня часто выручало взятие производной от кумулятивной суммы, поэтому попробуем применить этот подход и сейчас. Перейдем в режим ручного редактирования запросов:

Составим такой запрос:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Тут берётся максимальное значение метрики в группе по времени и считается сумма таких значений с момента начала отсчёта с группировкой по тегам Type и name. В результате в каждый момент времени будет сумма всех показаний по типу (HEAP или NON_HEAP) с разделением по имени пула, но просуммируется не 30 значений, как было в варианте 1.2, а только одно — максимальное.
И если взять приращение non_negative_difference такой накопительной суммы за последний шаг, то мы получим значение суммы всех пулов данных с группировкой по тегам Type и name на момент начала интервала времени.
Теперь, чтобы получить сумму только по тегу Type, без группировки по тегу name, надо сделать запрос верхнего уровня, с похожими параметрами группировки, но без группировки по name.
В результате выполнения такого сложного запроса получим сумму по всем типам.
Идеальный график. Сумма максимумов посчитана верно. Есть легенда с корректными значениями, ненулевыми. Во всплывающей подсказке можно отразить все метрики, а не только Single. Отображаются даже всплески по HEAP:

Одно, но — запрос получился непростым: сумма приращения кумулятивной суммы максимумов со сменой уровня группировки.
3.2 Сумма максимумов со сменой уровня группировки
Может можно сделать что-то попроще, чем в варианте 3.1? Ящик Пандоры уже открыт, мы перешли в режим ручного редактирования запросов.
Есть подозрение, что получение приращения от кумулятивной суммы приводит к нулевому эффекту — одно гасит другое. Избавимся от non_negative_difference (cumulative_sum (…)).
Упростим запрос.
Оставим просто сумму максимумов, с уменьшением уровня группировки:
SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Это быстрый простой запрос, который возвращает всего 721 точку на серию за 12 часов, при группировке по минутам: 12 (часов) * 60 (минут) = 720 интервалов, 721 точка (последняя пустая). Обратите внимание, что фильтр по времени дублируется. Он есть в подзапросе и в группирующем запросе:
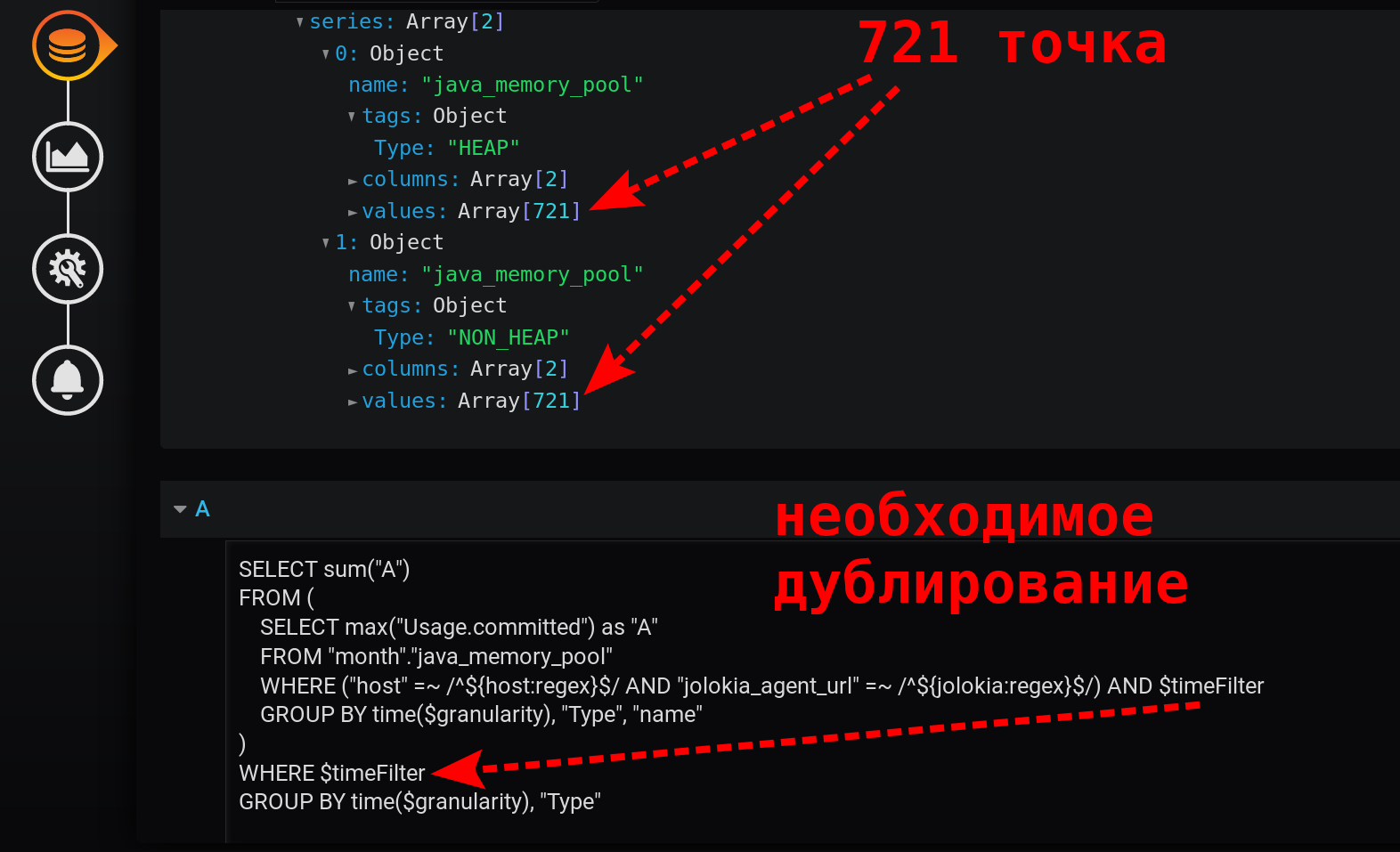
Без $timeFilter во внешнем группирующем запросе количество возвращённых точек будет не 721 за 12 часов, а больше. Так как загруппировка подзапроса выполняется для интервала from… to, а группировка внешнего запроса без фильтра будет для интервала from… now. И если в Grafana будет выбран интервал времени не последние X-часов (не такой, что to = now), а за интервал из прошлого (to < now), то появятся пустые точки со значением null в конце выборки.
Результирующий график получился простым, быстрым, корректным. С легендой, в которой отображаются суммарные метрики. С tooltip для нескольких линий сразу. А также с отображением всех всплесков значений:
Результат достигнут!
Ссылки (вместо списка литературы)
Дистрибутивы используемых в статье инструментов:
Документация о возможностях инструментов, используемых в статье:
Итоги
Связку Grafana и InfluxDB нужно хорошо знать инженерам по тестированию производительности. И в этой связке многие простые задачи являются очень интересными, и их не всегда можно решить методами нормального программирования.
Иногда могут понадобиться навыки ненормального программирования с помощью особенностей Grafana и тонкостей языка запросов InfluxDB.
В статье по шагам разобрали четыре варианта реализации суммирования метрики с группировкой по одному тегу, но у которой есть несколько тегов. Задача получилась интересной. И таких задач много.
Готовлю доклад на тему тонкостей программирования с Grafana и InfluxDB. Буду периодически публиковать материалы на эту тему. А пока буду рад вашим вопросам по текущей статье.
