Google рассказала о работе кластеров Borg впервые с 2011 года
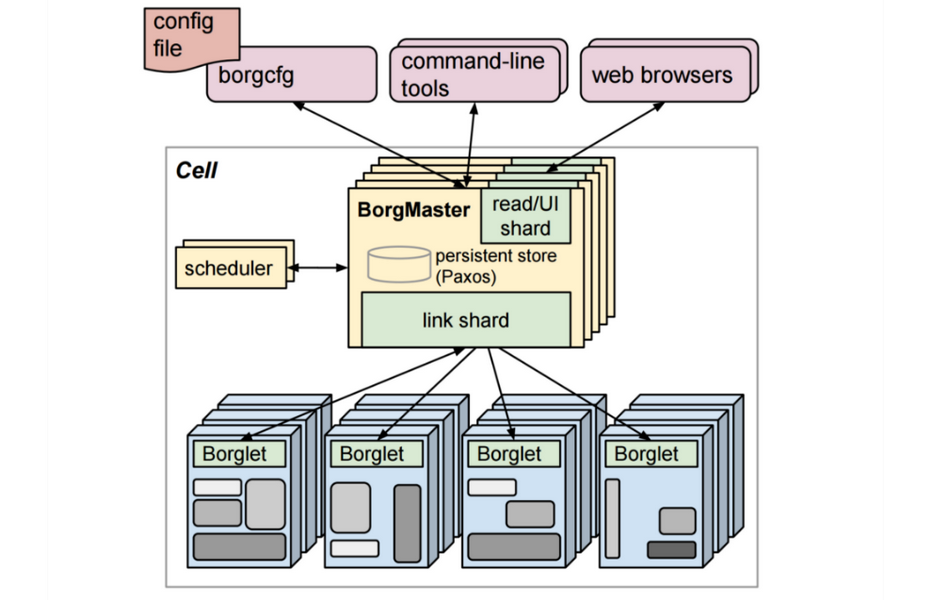
Google опубликовала несколько материалов, где описывается производительность менеджера кластеров Borg, предшественника Kubernetes Kubernetes — открытого ПО для автоматизации развертывания, масштабирования контейнеризированных приложений и управления ими.
В последний раз подобная информация публиковалась в 2011 году.
Google раскрывает данные, сгенерированные восемью кластерами в течение мая 2019 года,
вместе с информацией об использовании ЦП с пятиминутными интервалами, резервировании общих ресурсов и информацией об авторах заданий. В результате дамп содержит 350 гигабайт данных из каждого кластера. Для сравнения — в 2011 году этот показатель был на уровне 40 гигабайтов для одного кластера.
В отдельной статье речь идет о работе нового инструмента масштабирования под названием «Автопилот».
В материале сообщается, что вычислительная инфраструктура Google состоит из множества кластеров, расположенных в разных географических точках. Средний кластер имеет около 10 000 физических машин и одновременно выполняет множество различных видов рабочих нагрузок. Одна физическая машина может одновременно производить пакетные вычисления с интенсивным использованием памяти и ЦП, хранить и обслуживать запросы для фрагмента резидентной базы данных, а также обслуживать запросы конечных пользователей, чувствительные к задержке.
Однако в Google отмечают, что «Автопилот» редко использует более 50% памяти в кластере, в то время как у конкурента Alibaba показатель достигает 80% использования.

Анализ трассировки показывает, что Borg теперь поддерживает несколько планировщиков, в том числе планировщик пакетных операций. Он управляет совокупной рабочей нагрузкой пакетных заданий для повышения пропускной способности, ставя задания в очередь, пока ячейка не сможет их обработать. После этого задание передается обычному планировщику Borg.
Роль «Автопилота» состоит в том, что он «снимает бремя определения требований к ресурсам работы». Это может быть сложной задачей, потому что запрос слишком малого количества ресурсов может привести к катастрофическим последствиям: задание может не соответствовать срокам обслуживания пользователей или даже зависать.
«Это напрямую влияет на повышение эффективности и снижение затрат, позволяя выполнять больше работы в системе. Autopilot использует исторические данные из предыдущих запусков тех же или аналогичных заданий для настройки начального запроса ресурса, а затем постоянно корректирует ограничения ресурсов по мере выполнения задания, чтобы минимизировать возможность провала», — пояснили в Google.
Но даже при использовании «Автопилота» загрузка кластеров Borg остается довольно низкой: приведенные ниже графики показывают, что использование памяти и ЦП редко достигает более 60%.
Другое наблюдение состоит в том, что 1% ресурсоемких приложений потребляет 99% используемых ресурсов. В документе это описывается как проблема, потому что более мелким задачам в конце очереди приходится бороться за ресурсы.
«Большая часть рабочей нагрузки перешла со свободного уровня (с низким приоритетом) на пакетный уровень с наилучшими усилиями (задания, управляемые пакетным планировщиком в очереди), в то время как общее использование для рабочих заданий производственного уровня (с высоким приоритетом) оставалось примерно постоянным», — так описана проблема шаблонов использования.
«Мы обнаружили, что, хотя размеры ячеек кластера относительно не изменены, рабочая нагрузка существенно возросла как в абсолютном смысле, так и с точки зрения загрузки планировщика», — делает выводы компания. В Google отметили, что современные алгоритмы прогнозирования ресурсов кажутся более эффективными, чем процесс, когда пользователи вручную определяют свои требования к ресурсам.
На GitHub есть репозиторий, где содержатся 2,8 ГБ данных трассировки.
Все документы были подготовлены к 15-й Конференции по компьютерным системам или EuroSys '20. Мероприятие должно было состояться на этой неделе в греческом Ираклионе, но прошло в онлайне.
См. также:
