Го в Go! Как команда PHP взялась писать микросервисы
Всем привет! Меня зовут Алексей Скоробогатый, я системный архитектор в Lamoda. В феврале 2019 года я выступал на Go Meetup еще на позиции тимлида команды Core. Сегодня хочу представить расшифровку своего доклада, который вы также можете посмотреть.
Наша команда называется Core неспроста: в зону ответственности входит все, что связано с заказами в e-commerce платформе. Команда образовалась из PHP-разработчиков и специалистов по нашему order processing, который на тот момент представлял собой единый монолит. Мы занимались и продолжаем заниматься декомпозицией его на микросервисы.

Оформление заказа в нашей системе состоит из связанных компонентов: есть блок доставки и корзина, блоки скидок и оплаты, — и в самом конце есть кнопка, которая отправляет заказ собираться на склад. Именно в этот момент начинается работа системы order processing, где все данные заказа будут провалидированы, а информация агрегирована.
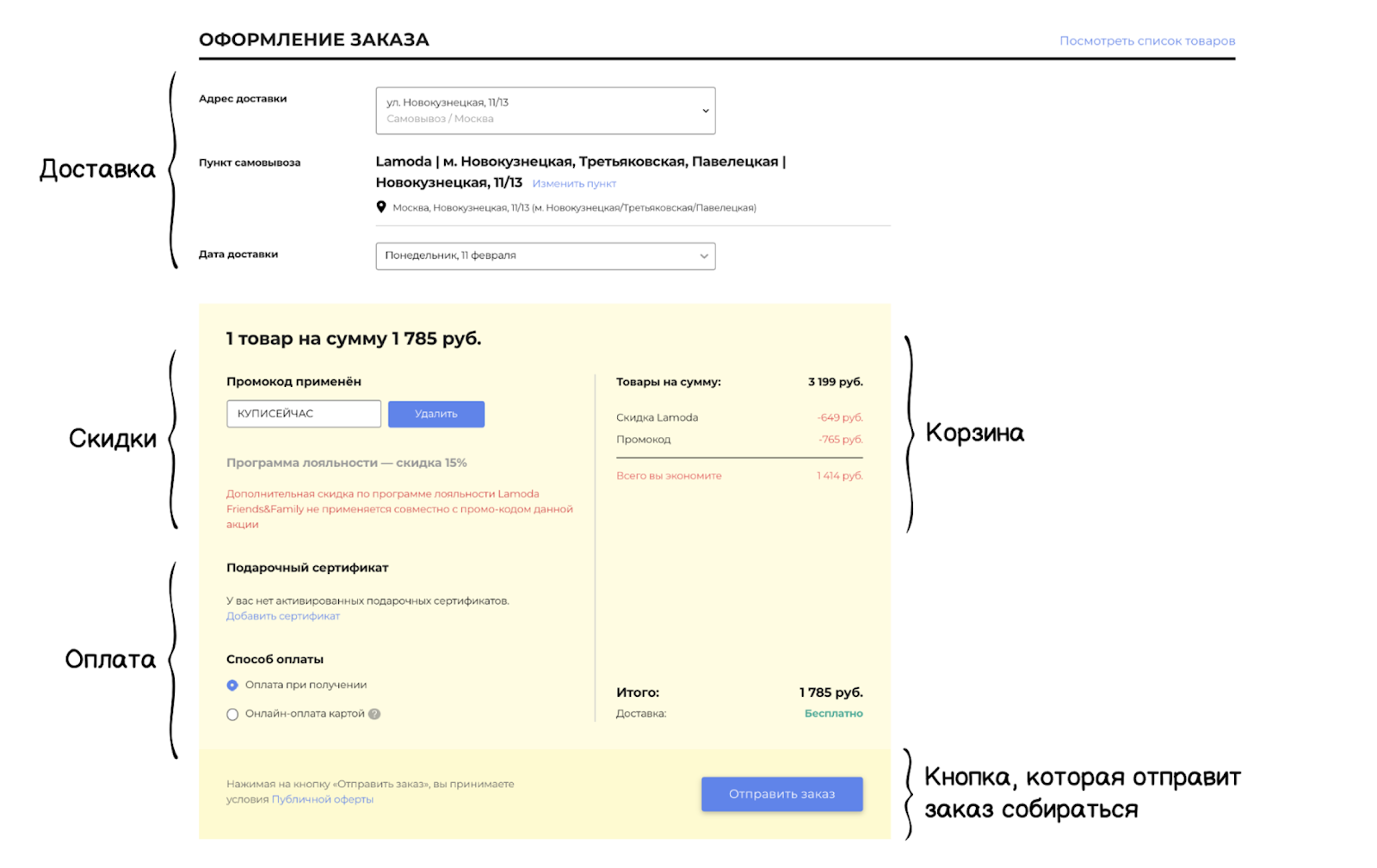
Внутри всего этого — сложная многокритериальная логика. Блоки взаимодействуют между собой и влияют друг на друга. Непрерывные и постоянные изменения от бизнеса еще увеличивают сложность критериев. Кроме того, у нас есть разные платформы, через которые клиенты могут создавать заказы: сайт, приложения, колл-центр, В2В-платформа. А также жесткие критерии SLA/MTTI/MTTR (метрики регистрации и решения инцидента). Все это требует от сервиса высокой гибкости и устойчивости.
Архитектурное наследие
Как я уже говорил, на момент образования нашей команды система order processing представляла собой монолит — почти 100 тысяч строк кода, в которых описывалась непосредственно бизнес-логика. Основная часть была написана в 2011 году, с использованием классической многослойной MVC-архитектуры. В основе был РНР (фреймворк ZF1), который постепенно оброс адаптерами и symfony-компонентами для взаимодействия с различными сервисами. За время существования у системы было более 50 контрибьюторов, и хотя нам удалось сохранить единый стиль написания кода, это тоже наложило свои ограничения. Плюс ко всему возникло большое количество смешанных контекстов — по разным причинам в систему были имплементированы некоторые механизмы, не связанные непосредственно с обработкой заказов. Все это привело к тому, что на настоящий момент мы имеем MySQL базу данных размером более 1 терабайта.
Схематично изначальную архитектуру можно представить так:
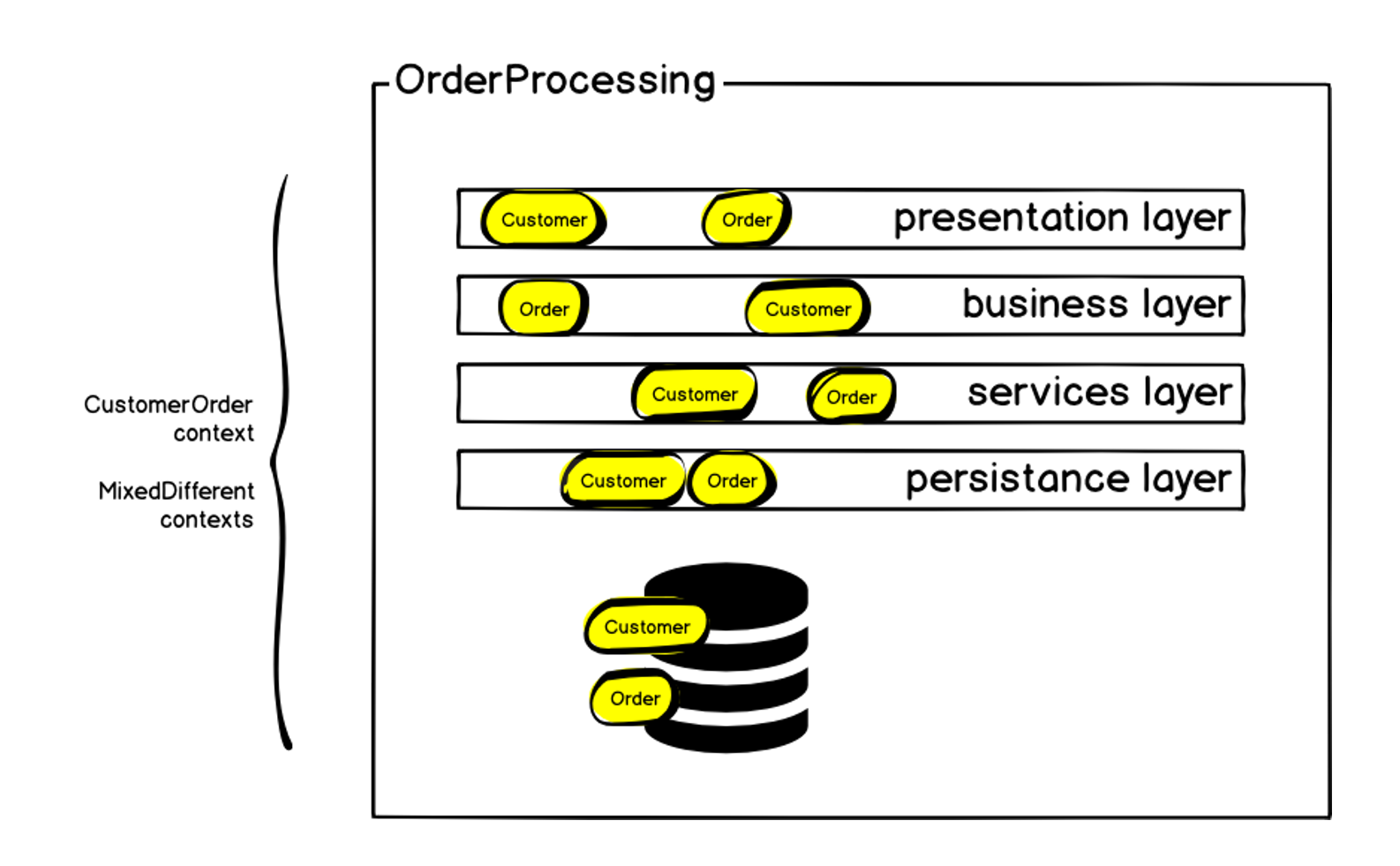
Заказ, конечно, находился на каждом из слоев —, но помимо заказа были и другие контексты. Мы начали с того, что определили bounded context именно заказа и назвали его Customer Order, так как помимо самого заказа, там есть те самые блоки, которые я упомянул в начале: доставка, оплата и прочее. Внутри монолита всем этим было сложно управлять: любые изменения влекли к увеличению зависимостей, код доставлялся на прод очень долго, всё время увеличивалась вероятность ошибок и отказа системы. А мы ведь говорим про создание заказа, основную метрику интернет-магазина — если заказы не создаются, то остальное уже не так важно. Отказ системы вызывает немедленное падение продаж.
Поэтому мы решили вынести контекст Customer Order из системы Order Processing в отдельный микросервис, который назвали Order Management.
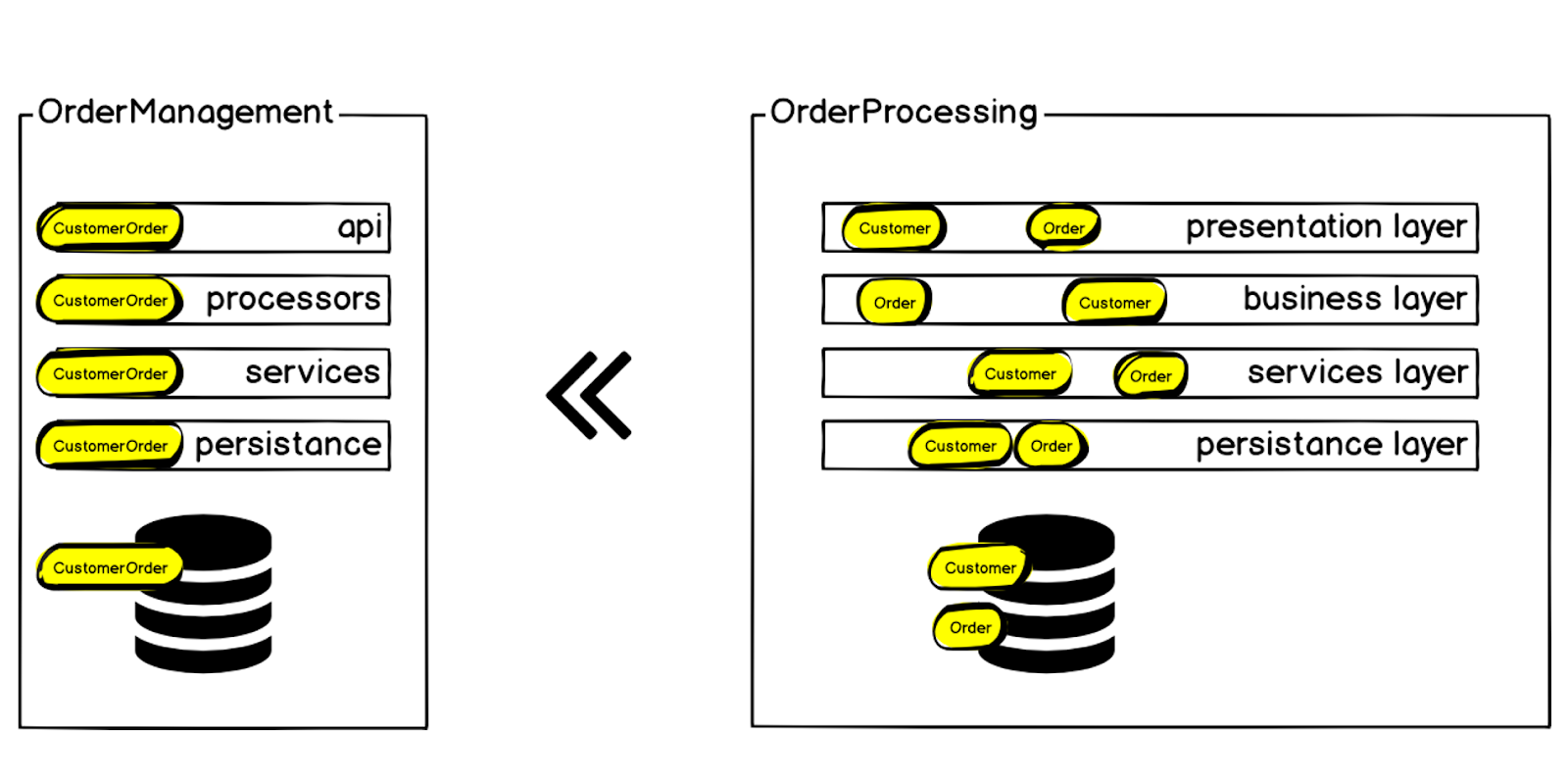
Требования и инструментарий
После определения контекста, который решили вынести из монолита в первую очередь, мы сформировали требования к нашему будущему сервису:
- Производительность
- Консистентность данных
- Устойчивость
- Предсказуемость
- Прозрачность
- Инкрементальность изменений
Мы хотели, чтобы код был максимально понятным и легко редактируемым, чтобы следующие поколения разработчиков могли быстро внести требующиеся для бизнеса изменения.
В итоге мы пришли к определенной структуре, которую используем во всех новых микросервисах:
Bounded Context. Каждый новый микросервис, начиная с Order Management, мы создаем на основе бизнес-требований. Должны существовать конкретные объяснения, какую часть системы и почему требуется вынести в отдельный микросервис.
Существующая инфраструктура и инструментарий. Мы не первая команда в Lamoda, которая начала внедрять Go, до нас были первопроходцы — непосредственно Go-шная команда, которая подготовила инфраструктуру и инструментарий:
- Gogi (swagger) — генератор спецификации по swagger.
- Gonkey (testing) — для функциональных тестов.
- Мы используем Json-rpc и генерим обвязку client/server по swagger. Также все это деплоим в Kubernetes, собираем метрики в Prometheus, для трейсинга используем ELK/Jaeger — все это входит в обвязку, которую создает Gogi для каждого нового микросервиса по спецификации.
Примерно так выглядит наш новый микросервис Order Management:
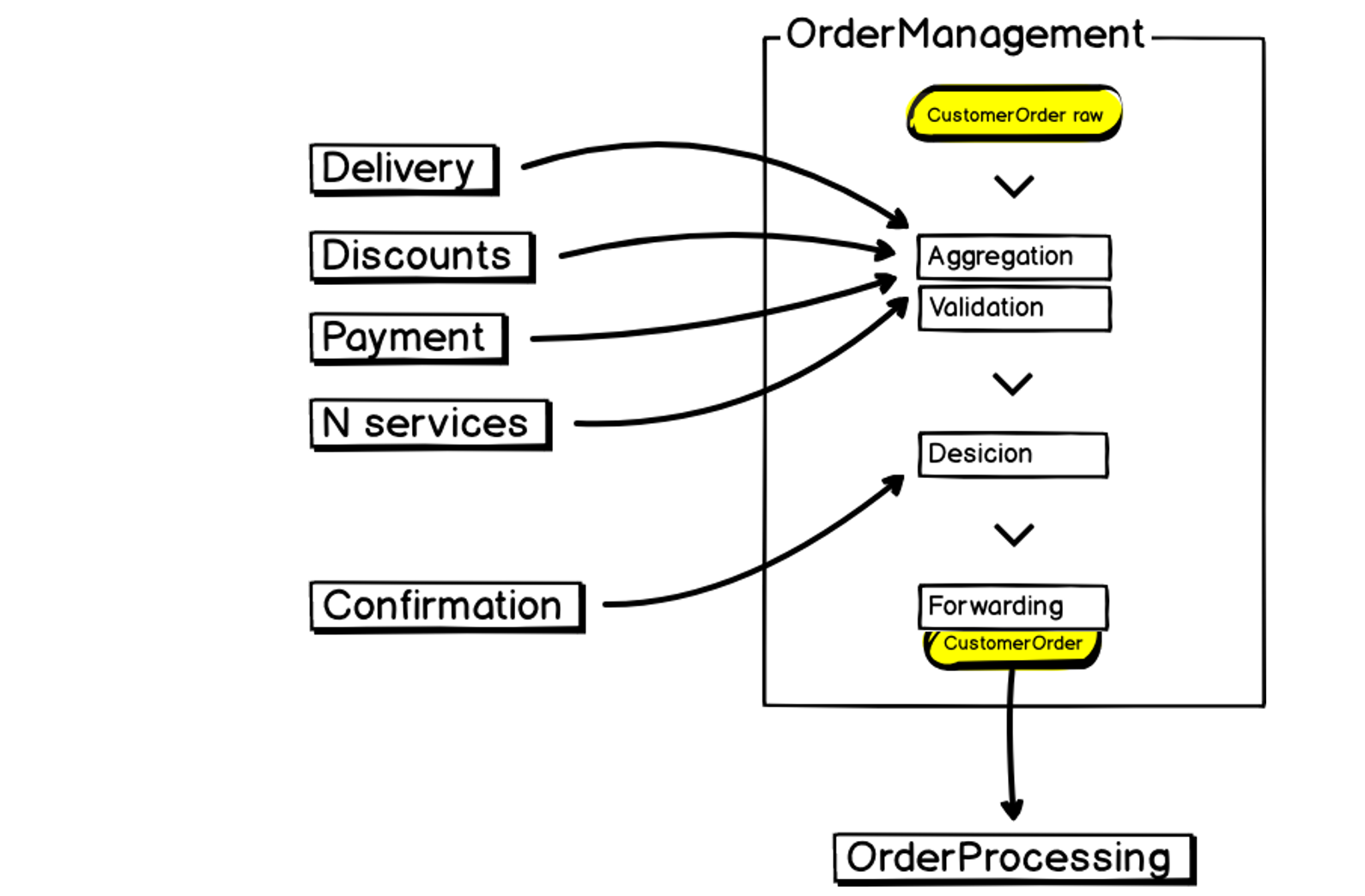
На входе у нас есть данные, мы их агрегируем, валидируем, взаимодействуем со сторонними сервисами, принимаем решения и передаем результаты дальше в Order Processing — тот самый монолит, который большой, неустойчивый и требовательный к ресурсам. Это тоже нужно учитывать при построении микросервиса.
Сдвиг парадигмы
Выбрав Go, мы сразу получили несколько преимуществ:
- Статическая строгая типизация сразу отсекает определенный круг возможных багов.
- Concurrency модель хорошо ложится в наши задачи, так как нам надо ходить и одновременно опрашивать несколько сервисов.
- Композиция и интерфейсы помогают нам также в тестировании.
- «Простота» изучения — как раз здесь обнаружились не только очевидные плюсы, но и проблемы.
Язык Go ограничивает воображение разработчика. Это стало камнем преткновения для нашей команды, привыкшей к РНР, когда мы перешли к разработке на Go. Мы столкнулись с настоящим парадигменным сдвигом. Нам пришлось пройти через несколько стадий и понять некоторые вещи:
- В Go тяжело строить абстракции.
- Go, можно сказать, Object-based, но не Object-oriented язык, так как там нет прямого наследования и некоторых других вещей.
- Go способствует писать явно, а не скрывать объекты за абстракциями.
- Go имеет Pipelining. Это вдохновило нас на построение цепочек обработчиков для работы с данными.
В итоге мы пришли к пониманию, что Go — это процедурный язык программирования.
Data first
Я думал, как визуализировать проблему, с которой мы столкнулись, и наткнулся на эту картинку:
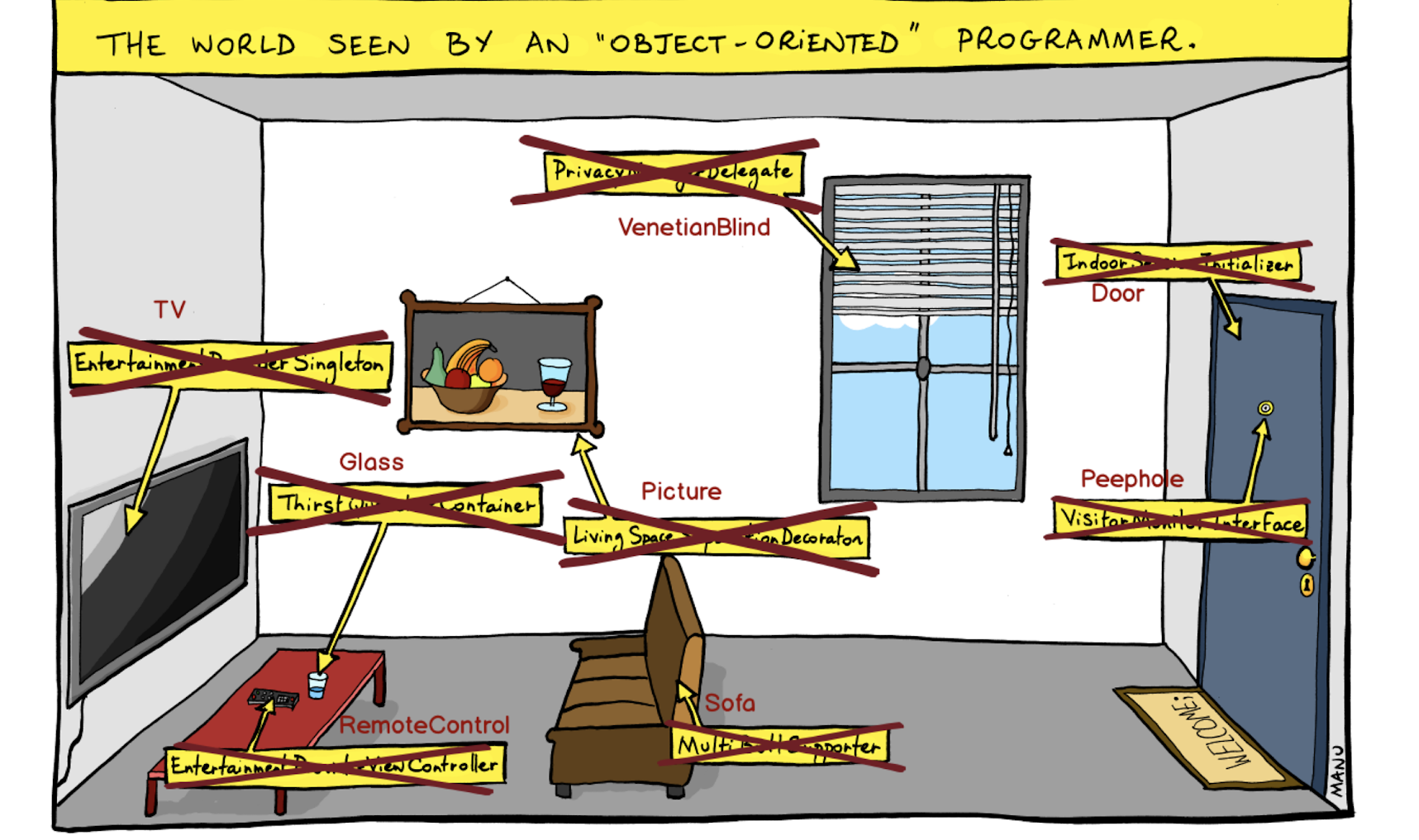
Здесь изображен «объектно-ориентированный» взгляд на мир, где мы строим абстракции и закрываем за ними объекты. Например, тут не просто дверь, а Indoor Session Initialiser. Не зрачок, а Visitor Monitor Interface — и так далее.
Мы отказались от такого подхода, и на первое место поставили сущности, не став их скрывать за абстракциями.
Рассуждая таким образом, мы поставили на первое место данные, и получили такой Pipelining в сервисе:

Изначально мы определяем модель данных, которые поступают в конвейер обработчиков. Данные являются изменяемыми, причем изменения могут происходить как последовательно, так и конкурентно (concurrency). С помощью этого мы выигрываем в скорости.
Назад в будущее
Неожиданно, разрабатывая микросервисы, мы пришли к модели программирования 70-х годов. После 70-х возникли большие enterprise-монолиты, где появилось объектно-ориентированное программирование, функциональное программирование — большие абстракции, которые позволяли удерживать код в этих монолитах. В микросервисах нам все это не нужно, и мы можем использовать отличную модель CSP (communicating sequential processes), идею которой выдвинул как раз в 70-х Чарльз Хор.
Также мы используем Sequence/Selection/Interation — парадигму структурного программирования, согласно которой весь код программы можно составить из соответствующих управляющих конструкций.
Ну и процедурное программирование, которое в 70-х годах было мейнстримом :)
Структура проекта

Как я уже говорил, на первое место мы поставили данные. Кроме того, построение проекта «от инфраструктуры» мы заменили на бизнес-ориентированное. Чтобы разработчик, заходя в код проекта, сразу видел, чем занимается сервис — это и есть та самая прозрачность, которую мы определили как одно из основных требований к структуре наших микросервисов.
В результате мы имеем плоскую архитектуру: небольшой слой API плюс модели данных. А вся логика (которая ограничена у нас контекстом бизнес требования от микросервиса), хранится в процессорах (обработчиках).
Мы стараемся не создавать новые отдельные микросервисы без однозначного запроса от бизнеса — так мы контролируем гранулярность всей системы. Если есть логика, которая близко связана с существующим микросервисом, но по сути относится к другому контексту — мы вначале заключаем ее в так называемых сервисах. И только при возникновении постоянной бизнес-потребности мы выносим ее в отдельный микросервис, к которому далее обращаемся при помощи rpc-вызова.
Чтобы контролировать гранулярность и не плодить микросервисы необдуманно, логику, которая не относится непосредственно к этому контексту, но близко связана с данным микросервисом, мы заключаем в слое services. А потом, если есть бизнес-потребность, мы выносим ее в отдельный микросервис — и далее с помощью rpc-вызова обращаемся к нему.
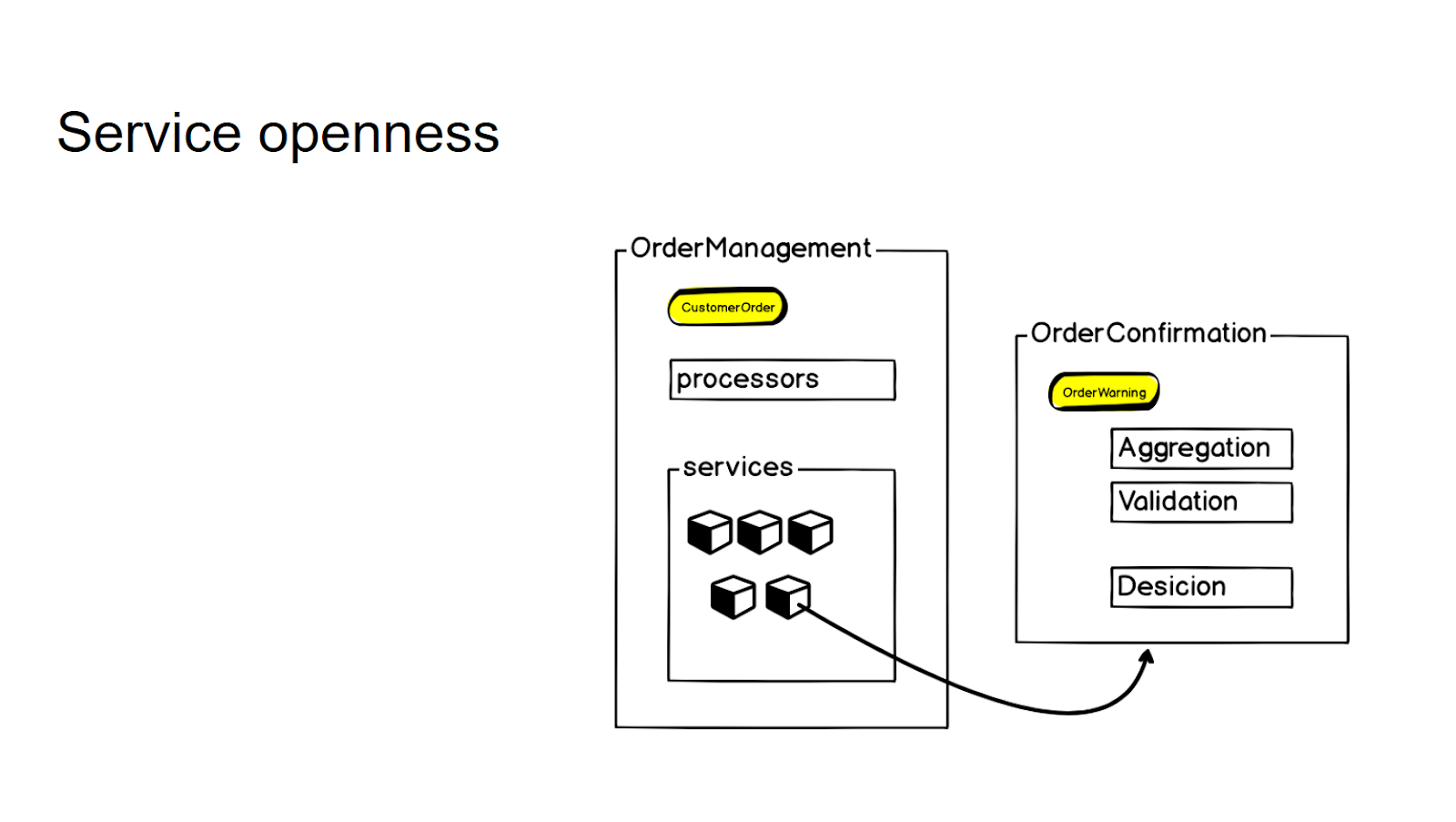
Таким образом, для внутреннего API в процессорах у сервиса взаимодействие никак не меняется.
Устойчивость
Мы решили не брать заранее какие-то сторонние библиотеки, так как данные, с которыми мы работаем, достаточно чувствительные. Поэтому мы немного повелосипедили :) Например, сами реализовали некоторые классические механизмы — для Idempotency, Queue-worker, Fault Tolerance, Compensating transactions. Наш следующий шаг — постараться это переиспользовать. Завернуть в библиотеки, может быть side-car контейнеры в Pod’ах Kubernetes. Но уже сейчас мы можем эти паттерны применять.
Мы реализуем в своих системах паттерн, который называется graceful degradation: сервис должен продолжать работать, независимо от внешних вызовов, в которых мы агрегируем информацию. На примере создания заказа: если запрос попал в сервис, мы в любом случае заказ создадим. Даже если упадет соседний сервис, отвечающий за какую-то часть той информации, которую мы должны сагрегировать или провалидировать. Более того — мы не потеряем заказ, даже если мы не сможем в краткосрочном отказе процессинга заказа, куда мы должны передать. Это тоже один из критериев, по которым мы принимаем решение, выносить ли логику в отдельный сервис. Если сервис не может обеспечить свою работу при недоступности следующих сервисов в сети, то либо нужно его перепроектировать, либо подумать о том, стоит ли его вообще выносить из монолита.
Го в Go!
Когда приходишь писать бизнес-ориентированные продуктовые микросервисы из классической сервис-ориентированной архитектуры, в частности РНР, то сталкиваешься с некоторым парадигменным сдвигом. И его обязательно нужно пройти, иначе можно наступать на грабли бесконечно. Бизнес-ориентированная структура проекта позволяет нам не усложнять лишний раз код и контролировать гранулярность сервиса.
Одной из основных наших задач было повышение устойчивости сервиса. Конечно, Go не дает повышения устойчивости просто «из коробки». Но, по моему ощущению, в экосистеме Go оказалось проще создать весь необходимый Reliability kit даже своими руками, не прибегая к сторонним библиотекам.
Другой важной задачей было увеличить гибкость системы. И тут я однозначно могу сказать, что скорость внесения требуемых бизнесом изменений сильно выросла. Благодаря архитектуре новых микросервисов разработчик остается один на один с бизнес-фичей, ему не нужно думать о том, чтобы строить клиенты, слать мониторинги, пробрасывать трейсинги, и настраивать логирование. Мы оставляем для разработчика именно прослойку написания бизнес-логики, позволяя ему не задумываться обо всей инфраструктурной обвязке.
Собираемся ли мы полностью переписать все на Go и отказаться от РНР?
Нет, так как мы идем от бизнес-потребностей, и есть некоторые контексты, в которых РНР очень хорошо ложится — там не нужна такая скорость и весь Go-шный набор инструментов. Вся автоматизация операций по доставке заказов и управлению фотостудией сделана на PHP. Но, например, в e-commerce платформе в customer side мы почти все переписываем на Go, так как там это оправданно.
