GO Scheduler: теперь не кооперативный?
Если вы читали release notes для версии GO 1.14, то возможно заметили несколько довольно интересных изменений в рантайме языка. Вот и меня очень заинтересовал пункт: «Goroutines are now asynchronously preemptible». Выходит что GO scheduler (планировщик) теперь не кооперативный? Что же, после прочтения по диагонали соответствующего proposal любопытство было удовлетворено.
Тем не менее, через некоторое время я решил более подробно исследовать нововведения. Результатами этих исследований и хотелось бы поделиться.
System Requirements.
Описанные ниже вещи требуют от читателя помимо знания языка GO дополнительных познаний, а именно:
- понимание принципов работы планировщика (хотя я и попытаюсь объяснить ниже, «на пальцах»)
- понимание принципов работы сборщика мусора
- понимание что такое GO assembler
В конце я оставлю пару ссылок которые по моему мнению хорошо раскрывают данные темы.
Кратко о планировщике.
Для начала напомню, что такое кооперативная и не кооперативная многозадачность.
С не кооперативной (вытесняющей) многозадачностью мы все с вами прекрасно знакомы на примере планировщика ОС. Данный планировщик работает в фоне, выгружает потоки на основании различных эвристик, а вместо выгруженных процессорное время начинают получать другие потоки.
Для кооперативного планировщика характерно другое поведение — он спит пока одна из горутин явно не разбудит его с намеком о готовности отдать свое место другой. Планировщик далее сам решит, надо ли убирать из контекста текущую горутину, и если да, кого поставить на ее место. Примерно так и работал планировщик GO.
Кроме того рассмотрим краеугольные сущности, которыми оперирует планировщик это:
- P — логические процессоры (их количество мы можем поменять функцией runtime.GOMAXPROCS), на каждом логическом процессоре в один момент времени может независимо выполняться одна горутина.
- M — потоки ОС. Каждый P работает на потоке из М. Заметьте, что P не всегда равно M, например, поток может быть заблокирован syscall'ом и тогда для его P будет выделен другой поток. А еще есть CGO и прочие и прочие нюансы.
- G — горутины. Ну тут понятно, на каждом P должна выполняться G и scheduler за этим следит.
И последний момент, который нужно знать, а когда же собственно горутина вызывает планировщик? Все просто, обычно инструкции для вызова вставляются компилятором в начало тела (пролог) функции (чуть позже мы поговорим об этом подробнее).
А в чем собственно проблема?

Из начала статьи Вы уже поняли, что в GO изменился принцип работы планировщика, рассмотрим причины по которым эти изменения были сделаны. Взгляните на код:
func main() {
runtime.GOMAXPROCS(1)
go func() {
var u int
for {
u -= 2
if u == 1 {
break
}
}
}()
<-time.After(time.Millisecond * 5) // в этом месте main горутина разбудит планировщик, а он в свою очередь запустит горутину с циклом
fmt.Println("go 1.13 has never been here")
}
Если скомпилировать его с версией GO
Это только один из примеров, когда горутина захватывает P и подолгу не дает другим горутинам выполниться на этом P. Больше вариантов, когда такое поведение вызывает проблемы, вы можете найти прочитав proposal.
Разбираем proposal.
Решение данной проблемы довольно простое. Давайте сделаем так же как и в планировщике ОС! Просто позволим рантайму GO вытеснить горутину из P и положить туда другую, а для этого воспользуемся средствами ОС.
Окей, как это реализовать? Мы позволим рантайму отправлять сигнал потоку на котором работает горутина. Обработчик этого сигнала зарегистрируем на каждом потоке из M, задача обработчика — определить можно ли вытеснить текущую горутину. Если да — сохраним ее текущее состояние (регистры и стак поинтер) и дадим ресурсы другой, иначе — продолжим выполнение текущей горутины. Стоит заметить, что, концепция с сигналом — это решение для UNIX-base систем, в то время как например для Windows реализация вытеснения все еще в разработке. Кстати, сигналом для отправки был выбран SIGURG.
Наиболее сложная часть данной реализации состоит в определении — может ли горутина быть вытеснена. Дело в том, что некоторые места в нашем коде должны быть атомарными, с точки зрения garbage collector'а. Назовем такие места unsafe-point'ами. Если мы вытесним горутину в момент выполнения кода из unsafe-point'а, а затем запустится GC, то он застанет состояние нашей горутины, снятое в unsafe-point'e, и может натворить дел. Давайте рассмотрим концепцию safe/unsafe подробнее.
А туда ли ты зашел, GC?
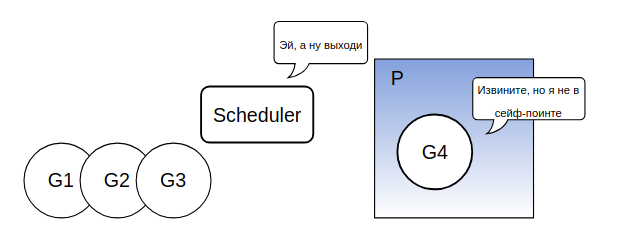
В версии до 1.12 runtime Gosched использовал safe-points места, где точно можно вызвать планировщик без боязни, что мы попадем в атомарную для GC секцию кода. Как мы уже говорили, данные safe-points располагаются в прологе функции (но далеко не каждой функции, заметьте). Если вы разбирали go-шный ассемблер, то могли бы возразить — никаких очевидных вызовов планировщика там не видно. Да это так, но вы можете найти там инструкцию вызова runtime.morestack, а если заглянуть внутрь этой функции то обнаружится вызов планировщика. Под спойлером я спрячу комментарий из исходников GO, либо вы можете найти ассемблер для morestack сами.
Synchronous safe-points are implemented by overloading the stack bound check in function prologues. To preempt a goroutine at the next synchronous safe-point, the runtime poisons the goroutine's stack bound to a value that will cause the next stack bound check to fail and enter the stack growth implementation, which will detect that it was actually a preemption and redirect to preemption handling.
Очевидно, что при переходе на вытесняющую концепцию сигнал о вытеснении может застать нашу горутину в любом месте. Но авторы GO решили не уходить от safe-points, а объявить safe-points everywhere! Ну конечно, есть подвох, almost averywhere на самом то деле. Как говорилось выше, есть некоторые unsafe-points, где вытеснять мы никого не будем. Давайте напишем простой unsafe-point.
j := &someStruct{}
p := unsafe.Pointer(j)
// unsafe-point start
u := uintptr(p)
//do some stuff here
p = unsafe.Pointer(u)
// unsafe-point end
Чтобы понять, в чем же тут проблема, примерим на себя шкуру сборщика мусора. Каждый раз когда мы выходим на работу надо узнать корневые узлы (указатели на стеке и в регистрах), с которых мы начнем маркировку. Так как в рантайме нельзя сказать, являются 64 байта в памяти указателем или просто числом, обратимся к картам стека и регистров (некоторому кэшу с мета информацией), любезно предоставленным нам компилятором GO. Информация в этих картах позволяет нам найти указатели. Итак, нас разбудили и отправили работать, когда GO исполнял строчку No4. Придя на место и заглянув в карты, мы
обнаружили, что там пусто (и это действительно так, ведь uintptr с точки зрения GC — число а не указатель). Что же, вчера мы слышали о выделение памяти под j, раз до этой памяти теперь не добраться — надо бы ее подчистить, и удалив память отправляемся спать. Что дальше? Ну, разбудило начальство, ночью, криками, ну вы и сами поняли.
С теорией на этом все, предлагаю рассмотреть на практике, как работают все эти сигналы, unsafe-point'ы и карты регистров да стеков.
Перейдем к практике.
Я дважды прогнал (go 1.14 и go 1.13) пример из начала статьи профайлером perf, дабы посмотреть какие системные вызовы происходят и сравнить их. Нужный syscall в 14й версии нашелся довольно быстро:
15.652 ( 0.003 ms): main/29614 tgkill(tgid: 29613 (main), pid: 29613 (main), sig: URG ) = 0
Отлично, очевидно рантайм послал SIGURG в тред на котором крутится горутина. Взяв это знание за отправную точку, я пошел смотреть коммиты в GO, чтобы найти, где и по какой причине этот сигнал посылается, а также найти место, где устанавливается обработчик данного сигнала. Начнем с посылки, функцию отправки сигнала мы найдем в runtime/os_linux.go
func signalM(mp *m, sig int) {
tgkill(getpid(), int(mp.procid), sig)
}
Теперь найдем места в коде рантайма, откуда мы отправляем сигнал:
- при suspend'е горутины, если она находится в состоянии «running». Запрос на suspend исходит от сборщика мусора. Тут пожалуй я не буду добавлять код, но его можно найти в файле runtime/preempt.go (suspendG)
- если планировщик решает, что горутина работает слишком долго, runtime/proc.go (retake)
if pd.schedwhen+forcePreemptNS <= now { signalM(_p_) }
forcePreemptNS — константа равная 10мс, pd.schedwhen — время когда крайний раз вызывался планировщик для потока pd - а так же всем потокам посылается данный сигнал при панике, StopTheWorld (GC) и еще нескольких случаях (которые я вынужден обойти стороной, ибо размер статьи совсем уже выйдет за рамки)
С тем, как и когда рантайм шлет сигнал в M мы разобрались. Теперь давайте найдем обработчик данного сигнала и посмотрим, что делает поток при его приеме.
func doSigPreempt(gp *g, ctxt *sigctxt) {
if wantAsyncPreempt(gp) && isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()) {
// Inject a call to asyncPreempt.
ctxt.pushCall(funcPC(asyncPreempt))
}
}
Из этой функции видно, что бы «заприемтиться» надо пройти 2 проверки:
- wantAsyncPreempt — проверяем «хочет ли» G вытесняться, тут, например, проверится валидность текущего статуса горутины.
- isAsyncSafePoint — проверяем, можно ли вытеснить прямо сейчас. Самая интересная из проверок здесь — находится ли G в safe или unsafe point'е. Кроме того, мы должны быть уверены, что поток, на котором выполняется G, так же готов к вытеснению G.
Если обе проверки пройдены — из исполняемого кода будет совершен вызов инструкций, которые сохранят состояние G и вызовут планировщик.
И еще об unsafe.
Предлагаю разобрать новый пример, он проиллюстрирует еще один кейс с unsafe-point:
//go:nosplit
func infiniteLoop() {
var u int
for {
u -= 2
if u == 1 {
break
}
}
}
func main() {
runtime.GOMAXPROCS(1)
go infiniteLoop()
<-time.After(time.Millisecond * 5)
fmt.Println("go 1.13 and 1.14 has never been here")
}
Как вы могли бы догадаться, надпись «go 1.13 and 1.14 never been here» мы не увидим и в GO 1.14. Это происходит потому, что мы явно запретили прерывать функцию infiniteLoop (go:nosplit). Реализован такой запрет как раз с помощью unsafe-point, которой является все тело функции. Посмотрим, что сгенерировал компилятор для функции infiniteLoop.
0x0000 00000 (main.go:10) TEXT "".infiniteLoop(SB), NOSPLIT|ABIInternal, $0-0
0x0000 00000 (main.go:10) PCDATA $0, $-2
0x0000 00000 (main.go:10) PCDATA $1, $-2
0x0000 00000 (main.go:10) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) FUNCDATA $2, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (main.go:10) XORL AX, AX
0x0002 00002 (main.go:12) JMP 8
0x0004 00004 (main.go:13) ADDQ $-2, AX
0x0008 00008 (main.go:14) CMPQ AX, $3
0x000c 00012 (main.go:14) JNE 4
0x000e 00014 (main.go:15) PCDATA $0, $-1
0x000e 00014 (main.go:15) PCDATA $1, $-1
0x000e 00014 (main.go:15) RET
В нашем случае интерес представляет инструкция PCDATA. Когда линковщик видит эту инструкцию, он не преобразует ее в «реальный» ассемблер. Вместо этого в карту регистров или стека (определяется 1м аргументом) будет помещено значение 2го аргумента с ключом равным соответствующему programm counter (число которое можно наблюдать слева от имени функции+строка).
Как мы видим на строках 10 и 15 мы кладем в мапы $0 и $1 значения -2 и -1 соответственно. Запомним этот момент и заглянем внутрь функции isAsyncSafePoint, на которую я уже обращал ваше внимание. Там мы увидим следующие строки:
smi := pcdatavalue(f, _PCDATA_RegMapIndex, pc, nil)
if smi == -2 {
return false
}
Именно в этом месте мы и проверяем, находится ли горутина в настоящий момент в safe-point'е. Мы обращаемся к карте регистров (_PCDATA_RegMapIndex = 0), и передав ей текущий pc проверяем значение, если -2 то G не в safe-point'e, а значит не может быть вытеснена.
Заключение.
На этом я остановил свои «изыскания», надеюсь статья была полезна и для вас.
Размещаю обещанные ссылки, но прошу быть внимательнее, ведь некоторая информация в данных статьях могла устареть.
GO scheduler — раз и два.
Assembler GO.
