GitFlow в его простоте от dev до prod
В какой ветке вести разработку? Из какой ветки деплоить на PROD? В какой ветке чинить багу, выявленную на IFT? Многие команды закрыли для себя этот вопрос, но для многих он остаётся открытым.
Этот пост не будет содержать каких-то особых ноу-хау и киллер-фич. В нём я расскажу наиболее простую и понятную (лично мне) практику релизных циклов на основе git flow. И постараюсь объяснить каждое своё решение и каждый подход.
Итак, поехали.
Сколько понадобится стендов?
В идеале, в дополнение к проду, хорошо иметь ещё два стенда: интеграционно-функциональный (далее — IFT) и, конечно, DEV. Опишем каждый стенд, его задачи и назначение более подробно:

Основной минимум стендов
DEV. Стенд для разработки. Все новые фичи и починенные баги в рамках спринта в первую очередь выкатываются на этот стенд. Активное тестирование фич и исправленных багов происходит тут. Деплоит на него в основном команда разработки. Содержит синтезированные данные.
IFT. Стенд для интеграционно-функционального тестирования. На этапе отладки фичи и исправленные баги тестируются на нём. Как правило, размещается в тестовом окружении заказчика и содержит реальные обезличенные данные. Если у Вас проект чуть сложнее CRUD, а стенда IFT у Вас нет, разрабатывать будет больно.
PROD. Продуктивный стенд, с реальными посетителями. Вершина иерархии окружения. Деплоем на такие стенды занимается специальная команда внедрения. Лучше, если у разработчиков вообще не будет к нему доступа.
Как управлять разработкой для этого минимума стендов, мы и поговорим в этом посте.
Как мы поделим спринт?
Спринт мы поделим на две неравные части: разработка и отладка.
Активная разработка — это бо́льшая часть спринта, во время которой реализуются фичи, заявленные в спринте и исправляются баги, найденные на DEV-стенде.
Отладка — это вторая часть спринта, которая наступает после реализации фич спринта, а тестирование переносится на IFT-стенд.
Какие основные ветки потребуются для разработки?
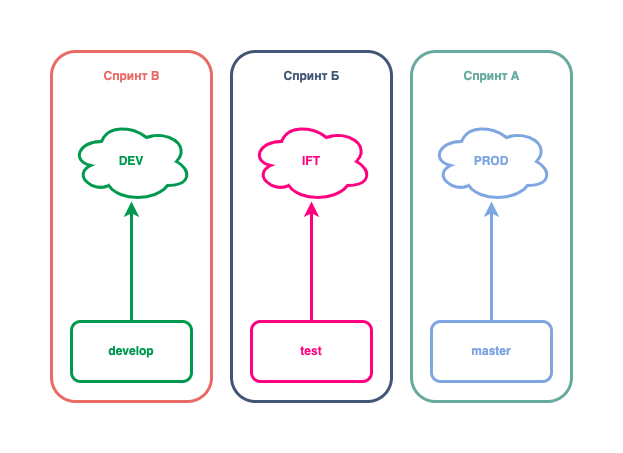
Итак, у нас 3 стенда. Для каждого из них лучше создать свою ветку, назвав её соответствующим образом: prod/master, ift/test, dev/develop — как угодно, главное, чтобы по названиям было понятно их назначение или они хотя бы были в понятийной среде разработки. В нашем примере, ветки будут master, test и develop.
Правило первое. Каждый стенд имеет свою одну-единственную мастер-ветку. Разворачивание приложения на стенд происходит только из неё.
Выглядеть это будет следующим образом:

Правило деплоя на стенды.
Этот контракт необходимо поддерживать всеми силами.
Этап активной разработки.
Активная разработка ведётся только из ветки develop. Реализуете фичу — ответвляете ветку feature/XXX от develop. Исправляете баг — пожалуйста, bug/XXX. По окончании разработки, ветка вливается обратно в develop, а оттуда уже изменения попадают на DEV-стенд.

Активная разработка.
Правило второе. Вся активная разработка ведётся в ветках, образованных от ветки
develop, которые по окончании разработки в них вливаются обратно вdevelop.
На DEV-стенде размещено приложение в состоянии, соответствующем текущему спринту; на IFT и PROD — предыдущему. Выглядит это так:

Версии приложения во время активной разработки
Как видно из картинки, на IFT и PROD код ещё в версии спринта А, тогда как на DEV-стенде уже в версии спринта Б.
Этап отладки.
По окончании активной разработки, весь код из ветки develop вливается в ветку test. Тестирование на DEV-стенде прекращается и переносится на IFT-стенд. Этот процесс можно назвать code freeze в рамках спринта.
С этого момента, разработчик уже может брать задачи следующего спринта и продолжать реализовывать обычным способом, в ветках от develop, по окончании реализации которых он в обычном режиме деплоится на DEV-стенд. Происходит разделение стендов на уровне спринтов: IFT-стенд принадлежит текущему спринту, тогда как DEV-стенд — будущему.
С момента отладки уже можно проводить планирование следующего спринта, чтобы определить scope задач, которые разработчик уже может брать в работу.
Таким образом, на этапе отладки каждый стенд находится в версии своего спринта: тогда как PROD всё ещё в версии предыдущего спринта, то IFT уже в версии нынешнего, а DEV — в версии спринта будущего.
Версии приложения на время отладки
Таким образом, разработчик не простаивает на время отладки и уже может сделать часть работы, намеченной на следующий спринт.
Этап отладки: что, если был найден баг на стенде IFT?
Интеграционно-функциональный стенд имеет несколько важных отличий от стенда разработки: а) он находится в окружении заказчика, что позволяет отладить взаимодействие с этим окружением, и б) он наполнен не синтезированным мусором, а обезличенными данными с PROD. Это позволяет тестировщику провести тестирование фич на уровне, наиболее близком к продуктивному.
Конечно, целью такого тестирования является обнаружение новых багов.
Итак, тестировщик нашёл новый баг. Как мы помним, IFT находится в состоянии текущего спринта, а DEV — будущего. Если мы для устранения бага создадим ветку от develop, то к тому моменту в develop уже могут оказаться фичи следующего релиза, которые не были ещё протестированы и не должны попасть в текущий релиз. Тогда, после устранения бага, нам придётся черри-пикать изменения из develop в test и держать потом эти черри-пики в уме, но это плохой выход из ситуации (в целом, практика черри-пиков является костылём и в разработке может применяться только от безысходности).
Отсюда вытекает правило третье:
Правило третье: мы помним правило Первое, согласно которому, изменения на стенд деплоятся только из своей мастер-ветки. Стало быть, если на каком-то конкретном стенде были найдены причины для изменения кода, то и разработка в рамках этих изменений ведётся из мастер-ветки этого стенда.
Иными словами, если на IFT был найден баг, для его устранения мы образуем ветку из test. После исправления бага, ветка вливается обратно в test, происходит деплой на IFT, баг тестируется повторно, и если всё ок, ветка test вливается в develop.

Исправление багов IFT
При таком подходе, сохраняется следующая взаимосвязь: ветка test содержит в себе версию кода, актуальную по текущий релиз; ветка develop содержит в себе версию кода, актуальную по текущий релиз + изменения в рамках следующего релиза.
Окончание этапа отладки и заход на новый спринт.
Единственное назначение стенда IFT — это тестирование приложения «как бы на проде». Окружение и наполнение IFT-стенда не должно кардинально отличаться от прода и как можно чаще обогащаться оттуда обезличенными данными. Если у Вас не так — будете тестировать на проде, что уж.
После окончания этапа отладки изменения из ветки test переносятся в ветку master и деплоятся на PROD. Версионность стендов возвращается к состоянию активной разработки (в следующей итерации), начинается новый спринт, с его победами и поражениями.

Начало нового спринта
Как будет выглядеть полный релизный цикл?
В соответствии с вышеописанным, полный релизный цикл будет выглядеть так:

Полный релизный цикл
Вместо заключения: что делать, если баг найден на проде?
Мы приложили все усилия для того, чтобы это не произошло. Но мы точно знаем, что это произойдёт. Что делать?
В первую очередь, попробуйте воспроизвести баг на стенде IFT. Если вы держите IFT в состоянии, актуальном PROD, он в очень высокой долей вероятности воспроизведётся. Если воспроизвёлся, переходим к разделу »Этап отладки: что, если был найден баг на стенде IFT? », правилу 3 и далее вниз по посту: исправили на IFT, влились из IFT в develop, влились в master, зарелизились на PROD повторно.
Если баг не воспроизвёлся на IFT, значит, это проблема чисто PROD и применяем правило 3 уже к нему: бранчуемся из master, исправляем проблему, далее переливаем изменения из master → test → develop.
