«Герои Меча и Магии» в браузере: долго, сложно и невыносимо интересно
Рисуем текстуру объектаПри необходимости рисуем флаг игрока
И это все при том, что количество объектов может достигать over 9000! Что делать, как рисовать это в рантайме? Я думаю, что лучше не рисовать это в рантайме, и сейчас расскажу, как.

Для начала, я нашел такой алгоритм рисования, как renderTree. Он используется, например, в браузере чтобы отрисовать DOM-элементы, которые висят друг над другом с Z-индексом. И каждая ветвь, которая есть в этом дереве — это ось Y, по которой объекты отсортированы. В свою очередь, на каждой ветви все объекты отсортированы по оси X.
Что мы с этого получаем? Мы получаем более дешевую итерацию, потому что мы сразу можем отсекать ветви, не попадающие на экран. А при каждой итерации на ветви, мы будем смотреть на X объекта, и как только мы натолкнемся на объект, который точно не поместится в карту, перестаем итерироваться по этому объекту. Таким образом затрагивается меньше объектов, чем если бы мы просто пробегались по массиву. Также нам сразу дается корректное перекрытие объектов, потому что они уже отсортированы. Таким образом получается грамотное хранение данных.
Далее я пошел в функцию рисования:
01. const object = getObject(id)
02. const {x, y} = getAnimationFrame(object)
03. const offsetleft = getMapLeft()
04. const offsetTop = getMapTop()
05.
06. context.drawImage(object.texture, x - offsetleft, …
Видим, что каждая функция состоит из того, что я определяю конечное смещение объекта, его фрейм для анимации, и, самое главное — функция drawImage. Все сводилось к этой функции, и нужно было как-то это оптимизировать.
Я понял, что я просто могу создать эту функцию через bind с нужными параметрами и сохранить прямо в renderTree. То есть я перестал хранить там объекты, и стал хранить только функции рисования. Больше там не нужно ничего, поэтому я получил отличный прирост производительности.

Но дело не только в объектах, дело еще в том, что игра не должна тормозить с точки зрения анимации. Коняшка должна бегать по экрану идеально, иначе у вас создастся впечатление, что с игрой что-то не так.
Давайте немножко окунемся в геометрию, чтобы понять, через что пришлось пройти. Там, когда вы прокладываете отрезок на определенное расстояние в любую сторону — хоть по горизонтали, хоть по диагонали — они равны.

Но это геометрия. А у нас «героеметрия». Там проблема в том, что это игра на сетке, где диагональное и горизонтальное перемещение по факту не равны, но игра считает, что это равно, и все нормально.

Как с этим жить? Если посчитать, то для горизонтального движения мы делаем четыре шага анимации, для диагонального — примерно шесть. Я начал искать решение, как сделать эту анимацию действительно плавной.
Проблема с JavaScript в том, что он однопоточный и оперирует задачами. Каждый setTimeout, который мы ставим, создает отдельную задачу, она конкурирует с другими задачами, которые у нас есть, например, с другими setTimeout. И в этом плане нас не спасет ничто.
Я пытался делать через setTimeout, через setInterval, через requestAnimationFrame — все создает задачи, которые друг с другом конкурируют.
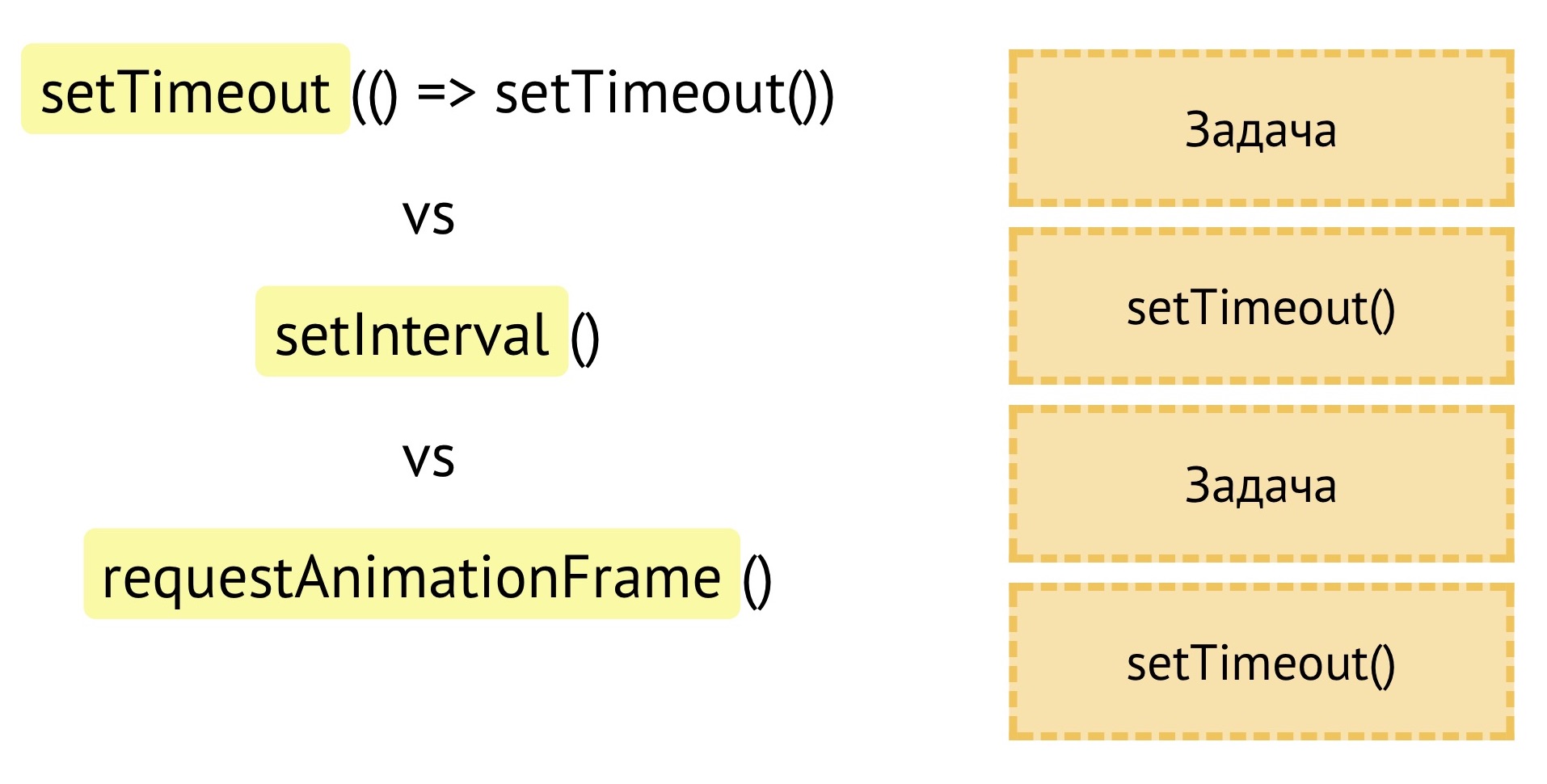
И при большом количестве обсчетов при движении игрока, конкурирующие задачи портили мне всю анимацию.
Я пошел искать дальше и нашел, что в JavaScript, оказывается, есть микрозадачи, которые являются частью задач. Они нужны в тех случаях, когда callback, который вы передаете, допустим, в Promise, единственный объект, который делает микрозадачу6 может совершиться сразу, либо асинхронно. Поэтому, на всякий случай, реализовали микрозадачу, которая имеет приоритет выше, чем у задачи.
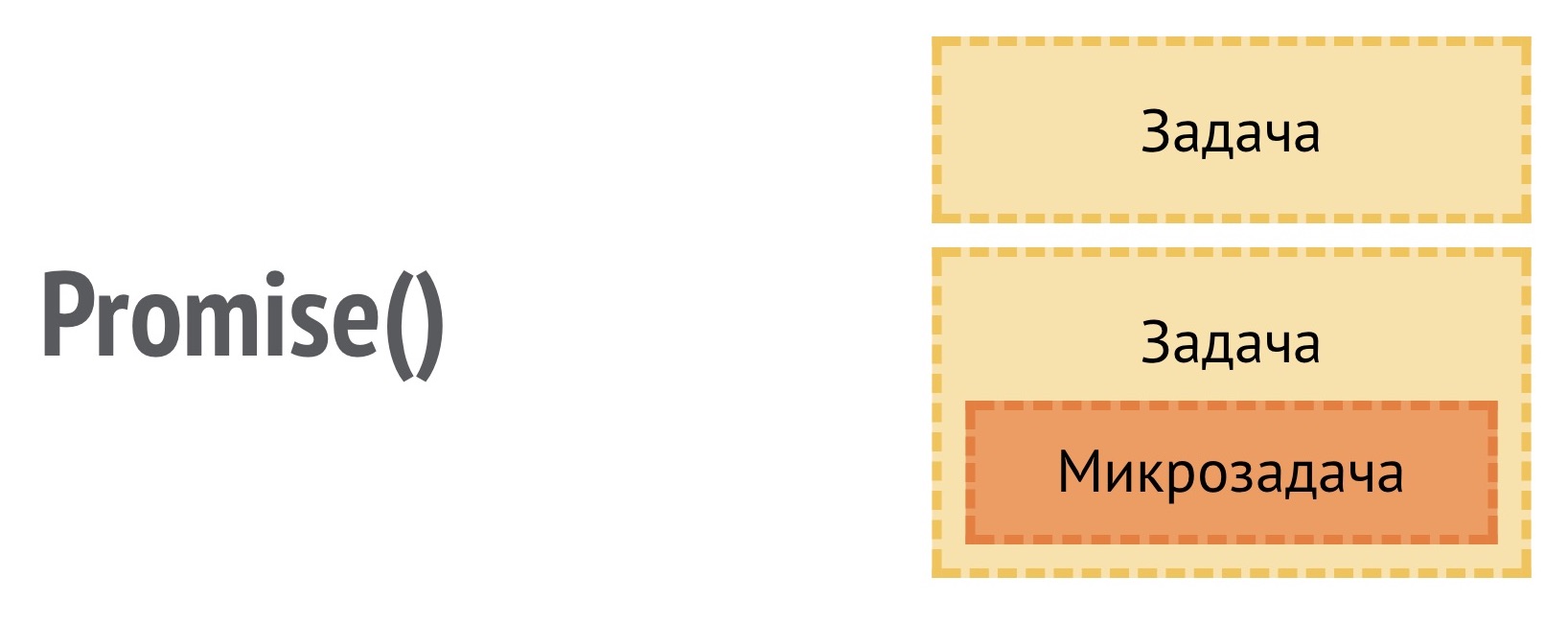
По факту, мы получаем неблокирующий цикл, который можно использовать для анимации. Подробнее об этом можно почитать в статье Джейка Арчибальда.
Для начала я взял все и обернул в Promise:
01. new Promise(resolve => {
02. setTimeout(() => {
03. // расчеты для анимации
04. requestAnimationFrame(() => /* рисование */)
05. resolve()
06. })
07. })
Мне все равно нужен был setTimeout, чтобы делать анимацию, но он был уже в Promise. Я делал расчеты для анимации и скармливал в функцию requestAnimationFrame то, что мне нужно было рисовать по итогу этих расчетов, чтобы расчеты не блокировали рисование, и оно шло тогда, когда это действительно нужно.
Таким образом, я смог построить целую последовательность из шагов анимации:
01. startAnimation()
02. .then(step)
03. .then(step)
04. .then(step)
05. .then(step)
06. .then(doAction)
07. .then(endAnimation)
Но я понял, что этот объект не очень сильно конфигурируем и не сильно отражает то, что я хочу. И я придумал хранить анимации в объекте, который назвал AsyncSequence:
01. AsyncSequence([
02. startAnimation, [
03. step
04. step
05. ...],
06. doAction,
07. endAnimation
08. ])
По сути, это некий reduce, который проходится по Promise и вызывает их последовательно. Но он не так прост, как кажется, дело в том, что в нем есть еще и вложенные циклы анимации. То есть я мог после startAnimation засунуть массив из одних step. Допустим, их тут семь или восемь штук, сколько нужно максимально для диагональной анимации героя.
Как только герой доходит до определенной точки, в этой анимации выходит куоусе, анимация прекращается, и AsyncSequence понимает, что нужно перейти на родительскую ветвь, а там уже вызывается doAction и endAnimation. Очень удобно делать сложную анимацию декларативно, как мне показалось.
Хранение данных
Но не только благодаря рендеру мы сможем увеличить нашу производительность. Оказалось, что больше всего тормозит хранение данных, что явилось для меня наибольшим сюрпризом в JavaScript.
Для начала найдем данные, которые больше всего тормозят, а это карта. Вся карта — это сетка, она состоит из тайлов. Тайлы — это какие-то условные квадратики в сетке, которые имеют свою текстуру, свой набор данных, и позволяют нам строить карту из ограниченного количества текстур, как делали все старые игры.
Этот набор данных содержит в себе:
- Тип тайла (вода, земля, дерево)
- Проходимость/стоимость перемещения по тайлу
- Наличие события
- Флаг «Кем занят»
- Другие поля, зависящие от реализации вашего движка
В коде это можно представить в виде сетки:
01.const map = [
02. [{...}, {...}, {...}, {...}, {...}, {...}],
03. [{...}, {...}, {...}, {...}, {...}, {...}],
04. [{...}, {...}, {...}, {...}, {...}, {...}],
05. ...
06. ]
07.const tile = map[1][3]
Такая же визуальная конструкция, как тайловая сетка. Массив массивов, в каждом массиве у нас объекты, которые содержат что-то для тайла. Получить конкретный тайл мы можем по смещению X и Y. Этот код работает, и он, вроде, норм.
Но. У нас есть алгоритм поиска пути, который сам по себе довольно дорогой, ему приходится учитывать массу деталей, которые есть не только в тайлах, но и в объектах. А когда мы перемещаем мышку, курсор меняется в зависимости от того, можем ли мы дойти до этой точки, находится ли в этой точке противник или какое-то действие.
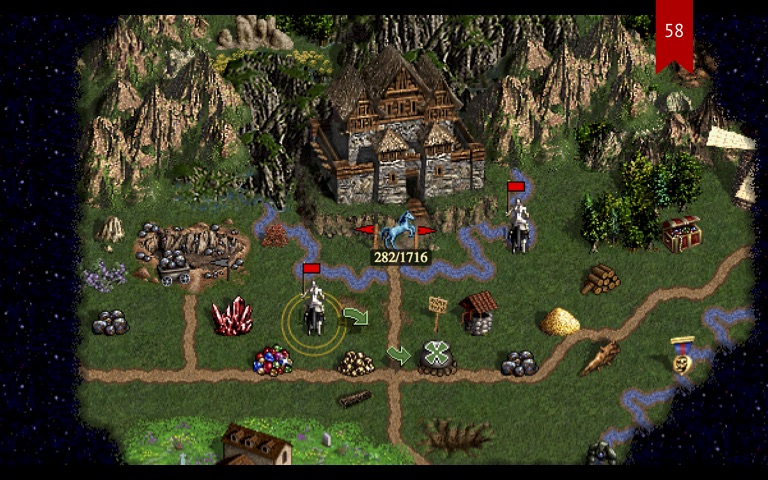
Например, навели на дерево — появился обычный курсор, потому что на эту точку нельзя пройти. А еще нам нужно показывать количество дней, которое требуется чтобы дойти до точки. То есть по факту мы гоняем алгоритм поиска пути постоянно, и та самая сетка работает очень медленно.
Чтобы получить свойство тайла, мне нужно было:
- Запросить массив тайлов
- Запросить массив массива для строки
- Запросить объект тайла
- Запросить свойство объекта
Четыре вызова кучи, как оказалось — это очень медленно, когда нам нужно очень много раз запросить карту для алгоритма поиска пути.
И что можно с этим сделать? Вначале я глянул данные:
01. const tile = {
02. // данные для отрисовки
03. render: {...},
04. // данные для поиска пути
05. passability: {...},
06. // данные которые нужны значительно реже
07. otherStuff: {...},
08. }
Я увидел, что каждый объект тайла состоит из того, что нужно для рендера, из того, что нужно для алгоритма поиска пути, и других данных, которые нужны значительно реже. Они каждый раз вызывались, при том, что были не нужны. Надо было откинуть эти данные и придумать, каким образом их хранить.
И я обнаружил, что быстрее всего читать эти данные из массива.

Ведь объект тайла можно разделить на массивы. Конечно, если вы будете писать так бизнес-код на работе, к вам будут вопросы. Но мы говорим о производительности, и тут все средства хороши. Мы просто берем отдельный массив, где храним тип объекта в тайле, или что тайл пустой, а вместе с ним массив цифр для алгоритма поиска пути, который простое единицей/нулем «проходима клетка или нет».
Но для алгоритма поиска пути нужно не просто узнать, есть объект или нет, и поставить единичку или нолик. Разные типы почвы имеют разную проходимость, разные герои по-разному ходят, все это нужно считать.

Этот простой массив считается по сложным алгоритмам из двух больших массивов: с тайлами и с объектами. Таким образом, мы получаем уже посчитанные цифры, которые можно быстро использовать в алгоритме поиска пути. Считаем заранее, когда объект обновляется, обновляем и значения.
В итоге у нас есть много массивов, которые что-то кэшируют и что-то связывают:
- Массив функций отрисовки для цикла отрисовки
- Массив чисел для поиска пути
- Массив строк для ассоциации объектов к тайлам
- Массив чисел для дополнительных свойств тайлов
- Map объектов с их ID для игровой логики
Остается только своевременное обновление данных из медленных хранилищ в более быстрые.
Конечно, назрел вопрос, каким образом можно уйти от массива массивов, который работает куда медленнее обычного массива.
По факту, я перешел к обычному массиву, просто развернув массив массивов, это работает на 50% быстрее:
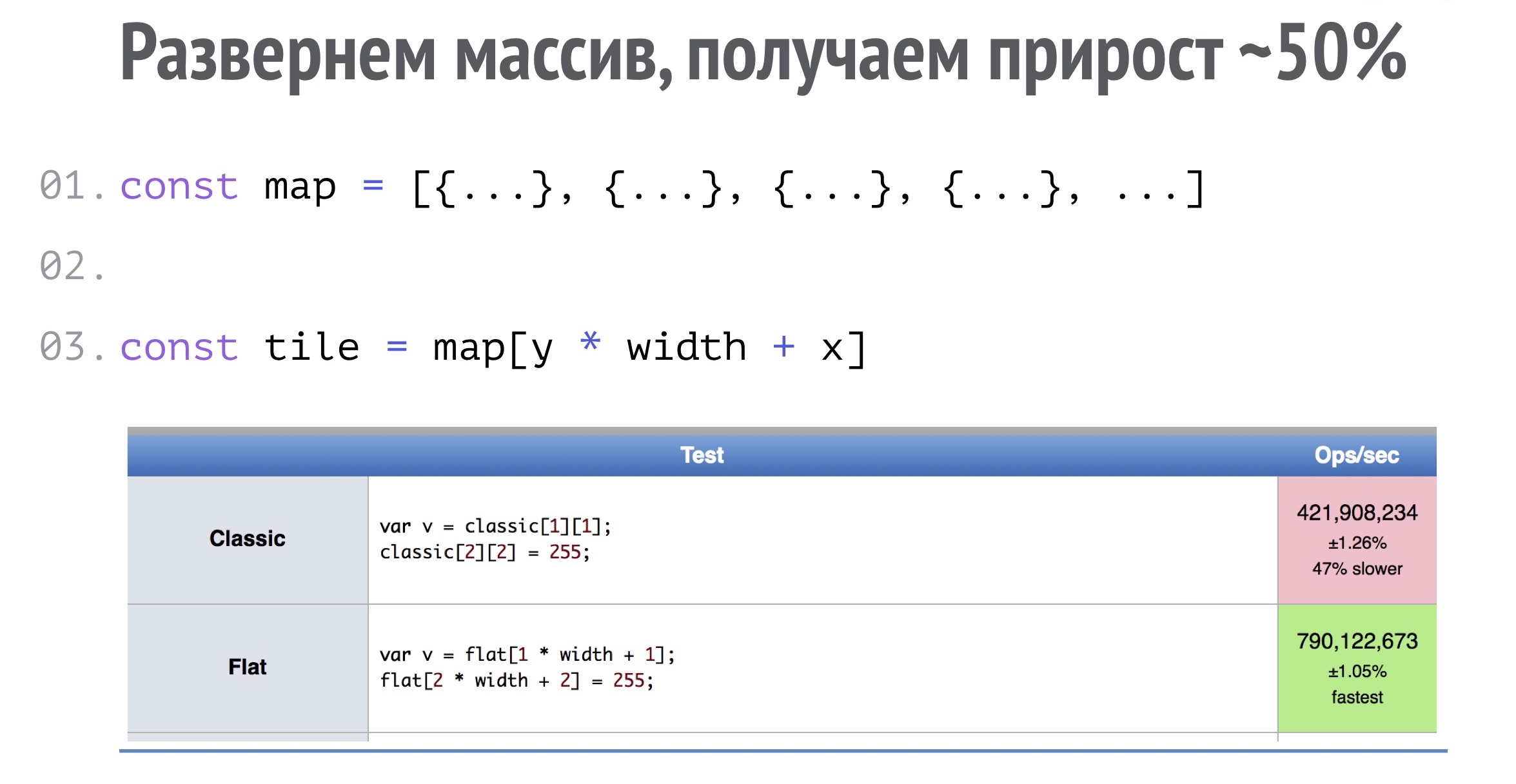
Получать смещение данных в массиве просто. Нам всего лишь надо знать Y, ширину этого квадрата, который мы храним в этом массиве, и X.
Дальше — больше. Я смотрел и понимал, что при каждой итерации мне нужно из индекса в массиве высчитывать X и Y объекта. Каждую итерацию нужно было что-то делать, и, в зависимости от X и Y, принимать какое-то решение:
01. const map = [{...}, {...}, {...}, {...}, ...]
02.
03. const tile = map[y * width + x]
04. map.forEach((value, index) => {
05. const y = Math.floor(index / width)
06. const x = index - (y * width)
07. })
Тут есть дорогие операции, такие как умножение, округление и деление. Пожалуй, самым дорогим здесь было деление, и я начал искать, что же с этим делать.
Тут я познакомился с силой двойки:

Я не зря назвал этот слайд «Power of 2», потому что это переводится одновременно как «сила двойки» и «степень двойки», то есть, сила двойки в ее степени. И если вы научитесь работать с битовыми сдвигами, которые я выделил желтым, то вы можете увеличить производительность.
Проблема в том, что если это встретится в вашем бизнес-коде, вас, скорее всего, тоже будут ругать, потому что это непонятный код. А найти применение этой силе двойки можно только если вы сможете понять, каким образом с этими формулами работать.
Хотя сдвиг влево, который равен умножению, не даст вам особого роста производительности, зато сдвиг вправо, который сравним с делением, дает довольно большой рост, а в сочетании с тем, что мы делим только на двойку, и числа у нас предсказуемые, без дробей, производительность увеличивается еще сильнее.
Таким образом, я дошел до того, что мы можем посчитать ближайшую степень двойки большую, чем нам нужно, чтобы заранее сделать больший массив, но квадратный, со стороной-степенью двойки, который покрывает все наши нужды по хранению.
01. const map = [{...}, {...}, {...}, {...}, ...]
02. const powerOfTwo = Math.ceil(Math.log2(width))
03.
04. const tile = map[y << powerOfTwo + x]
05. map.forEach((value, index) => {
06. const y = index >> powerOfTwo
07. const x = index - (y << powerOfTwo)
08. })
Допустим, карта 50×50, мы находим ближайшую степень двойки больше 50 и используем ее для дальнейших расчетов (при получении X и Y, а также сдвига в массиве для получения тайла).
Как ни странно, такие же оптимизации присутствуют в видеокарте:

Видеокарта раскладывает каждую текстуру, для которой предусмотрен так называемый MIP-маппинг, на квадраты-степени двойки, которые рисуются в зависимости от удаленности объекта. Это дает нам очень дешевое сглаживание и очень быструю отрисовку, потому что все, что является степенью двойки, очень быстро считается процессорами.
Так у меня получился Grid. Grid — это очень удобный для меня тип хранения данных, который позволяет итерироваться, получая сразу X и Y каждого объекта, и, наоборот, получать объект по X и Y.
01. const grid = new Grid(32)
02.
03. const tile = grid.get(x, y)
04. grid.forEach((value, x, y) => {})
Проблема в том, что таким образом можно хранить только квадратные сетки, но я там храню и прямоугольные, просто потому что это быстро. И минус грида в том, что он неэффективен для сеток со стороной больше, чем 256: если это перемножить, становится понятно, насколько много в массиве данных. А такие массивы тормозят всегда и везде, и ничего для них не придумано. Но мне это не нужно, потому что нет карт больше 256×256, везде все довольно красиво.
UI на Canvas
Дальше я начал разрабатывать UI на Canvas. Я посмотрел разные игрушки, и, в основном, в игрушках UI делался на HTML. Он накладывался сверху, таким образом его было проще разрабатывать, проще делать адаптивным. Но я хотел упороться по полной и сделать рисование.
Сначала я стала создавать обычные объекты, передавая в них какие-то данные, вешая на них eventListener. И это работало, пока я имел две-три кнопки.
01. const okButton = new Buttton(0, 10, 'Ok')
02. okButton.addEventListener('click', () => { ... })
03. const cancellButton = new Buttton(0, 10, 'Cancel')
04.cancellButton.addEventListener('click', () => { ... })
Потом я понял, что количество данных у меня растет и растет, и начал передавать там объекты. Там же и «биндил» события, потому что это было удобно.
01. const okButton = new Buttton({
02. left: 0,
03. top: 10,
04. onClick: () => { ... }
05. })
06. const cancellButton = new Buttton({...})
Потом выросло количество объектов, и я вспомнил, что есть JSON.
01. [
02. {
03. id: 'okButton',
04. options: {
05. left: 0,
06. top: 10,
07. onClick: () => { ... }
08. },
09. },
Далее я начал грустить, потому что не мог представить, как он будет выглядеть. Когда вы пишете код, вы немного предвыполняете его у себя в голове. Когда вы верстаете, вы немного визуализируете. И я, пытаясь верстать, пытался и визуализировать, и это было очень сложно.
Тут я вспомнил, что есть XML. XML — это то же самое, что и HTML, это для меня понятно и просто, а при сборке он генерирует тот самый JSON, который понятен машине, но плохо понятен мне.
01.
По факту, я сделал удобство для себя и более выразительную верстку. Я даже придумал вычисляемое условие, которое срабатывает при нужном событии.
Таким образом, мои интерфейсы стали куда сложнее, и я начал оперировать группами элементов, которые двигал относительно друг друга, начал делать сложные компоненты. Абстракции только улучшили мой код, они позволили мне думать совершенно на другом уровне сложности.
01.
02.
03.
06.
07.
10.
Как оказалось, не я первый, кто это придумал — делать из XML что-то на Canvas. Есть такая библиотека — react-canvas, и я был очень рад, когда узнал, что мои мысли тоже кому-то знакомы, и я додумался до чего-то полезного, что может пригодиться и в других отраслях.
Как это все работает
Мы рассмотрели по отдельности рендер, производительность, чтение данных, их хранение… Пожалуй, у вас возник вопрос:, а как все это вместе работает? А вот как-то так:
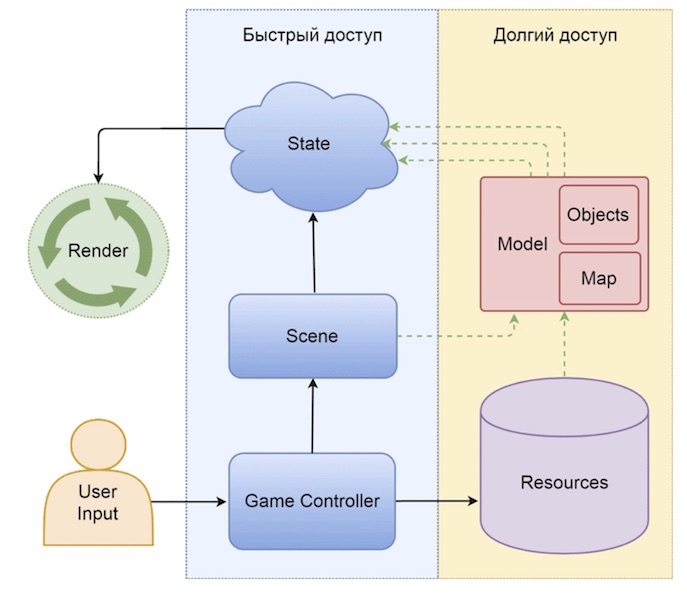
Я нарисовал схему, по которой видно, что у меня есть зона быстрого доступа к данным, которая, получая какой-то ивент от пользователя, может быстро изменить что-то в рендере, а есть зона долгого доступа — это модель для хранения большого количества объектов. То есть всё хранится в долгом доступе, где-то в моделях, и асинхронно приходит в рендер.
Пунктирные стрелочки представляют собой асинхронное взаимодействие. Ресурсы — это то, что мы загружаем с сервера. Когда нам нужно подгрузить картинку, она, естественно, придет к нам асинхронно. Мы не загружаем все картинки, потому что, переходя по экрану, стараемся грузить только необходимое. Надеюсь, вы на сайтах делаете так же.
Я бы хотел рассмотреть, как это все работает, на примере сбора ресурсов. Мы видим какой-то ресурс, бежим к нему и собираем. Как в этом случае работает игра?
Сначала включается поиск пути:

Я использую алгоритм A*. Этот алгоритм позволяет искать пути по графам. Граф — это то, что можно представить в виде сетки, либо квадратной, либо гексагональной, как в боевке. По факту, на экране боя и экране карты используется одинаковый алгоритм поиска пути — алгоритм переиспользуемый, и это большой плюс. Он учитывает «вес» перемещения по каждой клетке (на картинке слева можно заметить, что герой пойдет не прямо, а по дороге, потому что это банально дешевле, потратит меньше шагов хода).
Далее, во время движения персонажа, выполняется его анимация. Во время анимации мне нужно обновлять героя в дереве отрисовки. Зачем это нужно? Дело в том, что, так как объекты рисуются друг над другом, когда герой находится за мельницей, она его перекрывает, и наоборот:

Чтобы достичь такого эффекта в нужный момент времени, мне надо делать перенос героя по ветвям дерева отрисовки каждый раз, когда он проходит тайл.
Затем мне нужно сделать проверки в конечной точке, то есть, когда герою остался буквально один шаг, начинаются проверки:
- Делаем запрос к карте и получаем ID объектов в этой точке
- Они отсортированы как: действия, проходимые и непроходимые
- Берем первый объект по ID
- Проверяем, можно ли заходить на объект для активации действия
Для того, чтобы совершить действие с объектом, у меня в каждом из них реализован PubSub в объекте events:
01. const objectInAction = Objects.get(ID)
02.const hero = Player.activeHero
03. objectInAction.events.dispatch('action', hero)
04. ...
05. this.events.on('action', hero => {
06. hero.owner.resources.set('gems', this.value)
07. this.remove()
08. })
Так я могу диспатчить события и уже внутри объекта, начиная с пятой строки, я могу повесить callback на это действие (в данном случае я кидаю действие «action» и единственный атрибут, который его вызвал — это герой. В объекте я получаю этого героя, перечисляю ему нужные ресурсы и самоудаляюсь).
Кстати, с удалением объекта не все так просто, пожалуй, тут это самая сложная операция, потому что мне нужно обновлять много связанных массивов:
- Удаляем отрисовку из рендера
- Удаляем из массивов поиска пути
- Удаляем из ассоциативного массива с координатами
- Удаляем обработчики событий
- Удаляем из массива объектов
- Обновляем мини-карту, уже без этого объекта
- Рассылаем событие об удалении этого объекта из текущего стейта (для того, чтобы делать save/load, я храню данные в стейте, это отдельный интересный челлендж)
Со временем я задумался, как обновлять все эти массивы быстрее. Оказалось, что доля динамических объектов, которые могут удаляться или перемещаться — всего около 10%, и это, пожалуй, максимум. Таким образом, у нас есть балласт из 90% объектов, которые мы каждый раз итерируем, когда нам нужно что-то обновить в этих массивах. И я сильно сэкономил на расчетах, делая две сетки, которые потом мерджу, когда мне это действительно нужно.
У меня есть базовая сетка со статичными объектами и сетка с динамическими объектами, потому что чаще всего мне мне приходится обновлять и проверять только динамические объекты. Если же я не нахожу объект в динамической сетке, я лезу в более большую и дорогую статическую сетку, которая содержит больше, и там уже точно будет найдено то, что мне нужно. Таким образом я увеличиваю производительность при чтении данных. Советую вам всегда смотреть на данные, действительно ли они все нужны сейчас? Можно ли разделить их так, чтобы читать их побыстрее, а какие-то долгие, большие данные хранить отдельно и читать только при необходимости?
Как устроены объекты? Так как это игра, на нее отлично ложится ООП:
01. // Объект содержит гарнизон и может быть атакован
02. @Mixin(Attacable)
03. class TownObject extends OwnershipObject {...}
04. // Содержит все для отрисовки флажка, его смены и т.п.
05. class OwnershipObject extends MapObject {...}
06. // Содержит все базовые поля для объекта карты 07.class MapObject {...}
Одни объекты экстендят другие, таким образом получая какие-то свойства от своих родителей. Также я очень люблю миксины, которые позволяют мне добавлять какое-то поведение. Например, TownObject, который является объектом города, также является Attacable, потому что его можно атаковать. Это значит, что у него есть свой гарнизон, там находятся функции для работы с этим гарнизоном, там же есть функции коллбэков, которые говорят, что делать, если на город напали (если есть гарнизон, то вступать в бой, если нет, то просто сдаваться).
Сам по себе TownObject наследуется от OwnershipObject, который содержит все, что нужно объектам, которые можно захватить и поставить флажок. Там есть все функции для постановки флажка, для его отрисовки, для событий, которые нужны, когда объект захватывает какой-то другой герой. И все это, в свою очередь, наследуется от базового MapObject, где хранятся все данные для базовых объектов, имеющихся у нас.
Выводы
Какие выводы я могу из всего этого сделать? Это была очень большая борьба с нечистью. Нечисть была в том, что было много багов, я много раз унывал, я бросал проект (бывало, на месяцы). Это, кстати, полезно делать в рамках вашего домашнего проекта. Конечно, в рамках рабочего проекта вы вряд ли сможете так сделать, но домашний проект позволяет вам быть немножко ленивым и отдохнуть, чтобы придумать что-то красивее, чем у вас есть сейчас.
Многие спрашивают:, а зачем ты это делал? Я делал это на протяжении двух лет. Спрашивается, зачем ты делаешь что-то большое и никому не показываешь? Я показываю это на большом экране, пожалуй, второй раз, и были разные советы, вроде: «почему ты не сделаешь плагин для webpack или какую-нибудь маленькую библиотеку и не нахватаешь звезд, и все у тебя в шоколаде». Но я продолжал это делать, я продолжал никому ничего не показывать, кроме нескольких друзей, которым иногда кидал ссылки. Спасибо моей жене, которая долго это терпела!
Что мне это дало:
- Я очень сильно саморазвился
- Я выходил за рамки привычных рабочих задач. Дело в том, что, когда я начинал делать эту игру, я работал в обычной web-студии, делал сайты, рамки рабочих задач были строго ограничены тем, что нужно для сайта, а это, обычно, повторяющиеся задачи.
- Я сильно расширил кругозор, занимаясь игровыми задачами, занимаясь игровой логикой.
- Также я узнал много фанатиков, которые тоже что-то делают для «Героев». Многие из них делали это далеко не два года, а пять-десять лет. Кто-то делает свой конвертер, кто-то за пять лет делает крутую карту. То есть, фанатиков много, они не очень себя пиарят, они вдохновляли меня на то, чтобы двигаться дальше и не останавливаться. Знакомство с фанатиками очень окрыляет.
Зачем делать игры:
- На мой взгляд, это куда интереснее, чем делать сайтики, потому что вы решаете такие задачи, которые обычно не решаете
- Это большое количество новых для вас алгоритмов, с которыми вы не сталкиваетесь. Например, я изобретал новые способы хранения данных, или, допустим, написал алгоритм поиска пути, который банально был в составе, но для того, чтобы сделать его быстрее, мне пришлось в нем разобраться и немножко дописать.
- Это очень красиво. Советую вам наполнять мир красотой, потому что я всегда к ней стремился, и мне нравилось делать интерфейсы.
На мой взгляд, степень мастерства прямо пропорциональна времени, которое можно потратить на работу вглубь. Когда я учился рисовать, нам рассказывали, что, когда вы рисуете голову, вы должны поступать как скульптор. Скульптор сначала берет параллелепипед камня и отсекает от него грани, делая его отдаленно похожим на голову. Потом он начинает искать все новые и новые грани, он находит форму носа, находит форму брови и под конец он находит 50, или даже больше, граней в веке.
И работа вглубь заключается в том, насколько долго можно углублять свое детище, насколько долго над ним можно работать. И если вы видите свое детище, и не представляется никаких вариантов, что еще можно сделать, то что-то не так со степенью мастерства. Советую почитать и расширить свой кругозор, отдохнуть и вернуться снова. Таким образом вы будете только улучшаться и делать себя бо́льшим мастером.
Тут я оставил полезные ссылки, которые отчасти мне помогли:
И, конечно же, демка, куда ж без нее. Работает и на телефонах.
Минутка рекламы. Если вам понравился этот доклад с предыдущей HolyJS, обратите внимание: уже 19–20 мая пройдёт HolyJS 2018 Piter. И на сайте конференции уже опубликована её программа, так что смотрите, что на новой конференции будет интересным для вас.
