Геоданные без регистрации и СМС

Здравствуй, дорогой читатель.
Спешу поделиться тем, как на самом деле найти геоданные без регистрации и СМС. По чесноку. Без всяких-яких. И даже «подписывайтесь на телеграмм канал» — не будет, у меня его и нет…
И речь пойдёт про инструмент Osmosis.
Побудительный мотив
Сидел я тут намедни, и наткнулся на интереснейшую вещь: почти часовой подкаст на YouTube канале Хабра: Хабр Про. В чём магия геоданных и как их найти без регистрации и СМС. И тема то небезынтересна.
Но в подкасте было всё кроме ответа на главный вопрос: «как же их найти?». И вот сижу я, обманутый, и думаю как восстановить справедливость. Вопрос поставлен, а ответа нет. И решил взять дело в свои руки — написать эту статью. Прошу любить и жаловать.
Зачем?
Не публикация, конечно, «зачем», а: «зачем получать геоданные».
Для исследований:
Кто сказал «урбанистика»?
Если создаёте свое приложение с блэкджеком… с картами:
А иногда просто по фану:
Да много всякого…
Так где?
Вопрос то поставлен ребром: без регистрации и СМС, а значит безвозмездно, то есть даром! Это ограничение оставляет нас, по большому счёту, с единственным известным мне вариантом: OSM.
В OSM прекрасно всё: он сбалансированный как инь и янь. Масштабный, открытый, универсальный, обо всём что может быть на карте, с бардаком, бесконечными спорами как надо и не надо картографировать и перманентно нестабильной документацией (посмотрите для интереса блок тегирование в новостях из мира OpenStreetMap), — всё как мы любим. Т.е. польза и энтропия зашкаливают.
Т.е. в нём есть всё, если нет — значит скоро будет, если ждать невозможно: занесите сами. Но в правилах чёрт ногу сломит. А раз правила гибкие, то и инструменты для работы с этими данными должны быть под стать: либо есть линия партии и «шаг влево, шаг вправо — расстрел», либо «что хочу, то и ворочу». А раз буква O в OSM это Open, то придерживаться будем «что хочу, то и ворочу».
Инструмент подходящий есть — osmosis, и его-то я опишу, но будьте готовы: придётся вникать не только в команды инструмента, но и в правила OSM, примеры приведу, ссылки приложу, но прогулка не будет лёгкой, на блюдечке с голубой каёмочкой вам эти данные не получить: без СМС всё-таки, а значит придётся поработать.
Osmosis это приложение для работы в командной строке. А значит будем преодолевать тяготы и лишения. Но оно того стоит.
Ну и не осмосисом единым, конечно же, есть, например, ещё osmium и д.р. см. Alternatives to osmosis.
Приготовления
Установка osmosis
Инструкции по установке доступны на OpenStreetMap Wiki.
Опишу таки как поставить на Windows:
Для начала нужна Java.
…
Качаем zip архив Osmosis c GitHub.
Извлекаем архив.
По сути вся установка. Запустите командную строку. Перейдите в директорию, куда извлечён архив, найдите папку bin, например, D:\osmosis-0.49.2\bin, и выполните команду osmosis для проверки.
И так, ложка есть — инструмент установлен. Теперь пойдём добывать варенье.
Сырые данные
Данные нам нужны в формате PBF. Я их всегда качаю с geofabrik. Находим нужный регион — качаем. Есть и другие источники подробнее смотрите страницу Planet.osm на OpenStreetMap Wiki.
Данные получены. Осталось разобраться как это есть.
Работа с данными
Инструкцию по всем командам (версия 0.48) можно посмотреть всё там же: на Openstreetmap Wiki.
Важно понимать несколько вещей при работе в командной строке с Osmosis.
Термины
Задачи (Tasks)
В командной строке вы пишите последовательность задач (Tasks). Каждая задача начинается с символов --, например:
osmosis --read-pbf file=myfile.osm.pbf --write-null
Здесь две задачи --read-pbf и --write-null.
У задач есть сокращённая запись:
osmosis --rd file=myfile.osm.pbf --wn
Краткая запись полезна, когда необходимо как-то команду сделать компактнее, порой команды получаются слишком монструозные, тут и многострочный режим пригодится и краткая запись. Я в примерах буду использовать полную запись, для полноты изложения конечно же.
Аргументы (Arguments)
Аргументы относятся к задачам, после которых они следуют, и являются парой ключ-значение.
Некоторые задачи могут принимать безымянные аргументы — аргументы «по умолчанию» — ключ не обязательно указывать. Если не указан ключ, то osmosis будет подставлять тот ключ, который соответствует аргументу «по умолчанию», вот это, одно и то же:
osmosis --read-pbf file=myfile.osm.pbf --write-null
osmosis --read-pbf myfile.osm.pbf --write-null
file — аргумент по-умолчанию для задачи --read-xml.
Потоки (Pipeline)
Задачи воспринимают данные как поток. Визуально это можно представить в виде пазлов:

В документации к osmosis описан такой таблицей:
Pipe | Description |
|---|---|
outPipe.0 | Produces an entity stream. |
команды которые принимают поток на вход, обрабатывают его, и возвращают результат в виде потока, в другие команды;

В документации к osmosis таблица будет выглядеть так:
Pipe | Description |
|---|---|
inPipe.0 | Consumes an entity stream. |
outPipe.0 | Produces an entity stream. |

В документации к osmosis:
Pipe | Description |
|---|---|
inPipe.0 | Consumes an entity stream. |
Я вместо таблиц буду иллюстрировать пазлами, очень уж они мне нравятся.
Таким образом у вас должны быть задачи создания потоков, возможно обработки потоков, возможно манипуляции потоками, и завершения потоков. И они должны выстраиваться в некую цепочку, как конвейер.
Задачи в последовательности можно ставить как угодно, — ошибки не будет, главное чтобы входящие потоки «следующей» задачи соотносились с исходящими потоками «предыдущей».
Однако это «как угодно» будет, давать разные результаты. Последовательность задач имеет значение.
Это особенности работы с инструментом, — его философия. Понимание этих простых вещей сделает вашу работу с инструментом более осмысленной.
А теперь к задачам.
Задачи чтения
Начнём, конечно же с задач чтения, полагаем что дамп данных мы скачали таки в формате pbf.
--read-pbf (--rb)
Всё прозаично, — ничего не делает кроме как создаёт поток для чтения данных из файла, вся работа по обработке: правила выборки, сохранение — потом.
Имеет один параметр file, в котором указывается путь к файлу.
Ну и пример мы уже видели, посмотрим ещё раз:
osmosis --read-pbf file=myfile.osm.pbf --write-null
--read-xml (--rx)
Читает данные из файла структуры OSM XML.
Задачи записи
--write-xml (--wx)--write-pbf (--wb)
Записывает поток, соответственно либо в OSM XML либо в PBF. В качестве аргумента принимает как минимум имя файла.
XML хотя бы человекочитаема, в большинстве примеров будем её использовать, чтобы можно было открыть и глазками посмотреть что там происходит.
Но погодите что-то куда-то записывать. Мало ли что за pbf файл вы добыли, просто прочитать его и сохранить — задача сомнительной полезности. Попробуем его сначала как-то урезать. С файлом поменьше и работать будет попроще.
Задачи фильтрации по области
--bounding-box (--bb)
Извлекает данные в пределах определённой ограничивающей рамки, задаваемой координатами широты и долготы.
И так, я скачал pbf со всем Уральским Федеральным Округом, а поскольку всё подряд мне не надо, — выберу один город, и сохраню его в отдельный pbf-файл.
osmosis \
--read-pbf file=myfile.osm.pbf \
--bounding-box top=57.2456 left=65.4316 bottom=57.0719 right=65.6945 \
--write-pbf file=tyumen.osm.pbf
Координаты ставил на глаз, по гугл картам, всё что попало в этот прямоугольник, должно попасть и в итоговый pbf.
--bounding-polygon (--bp)
А эта для тех кто хочет заморочиться. Если прямоугольник по каким-то причинам не устраивает, то можно задать полигон произвольной формы. Задаётся прямоугольник серией координат широта/долгота, в отдельном файле, подробнее смотреть: Polygon Filter File Format.
Есть в интернетах уже готовые полигоны смотрите http://download.openstreetmap.fr/polygons/ например.
В целом с пространственными ограничениями — всё.
И про это уже писали на Хабре: Как вырезать сабсет города (любого отношения) из OSM данных.
Задачи фильтрации данных по атрибутам
По сути самый важный раздел — для него всё и затевалось, остальные задачи, — это так, вспомогательные.
Для этого раздела уже понадобится понимание структуры и правил OSM.
Важно знать что элементы в OSM трёх типов:
узлы (node), они же точки
пути (way), они же линии
отношения (relation), они же отношения (sic!)
Все задачи фильтрации оперируют этими тремя категориями.
Помимо этого у элементов OSM есть ещё такое понятие как теги. Теги описывают конкретные особенности элементов карты, это единственный способ как-то обозначить к чему относятся данные, см. Скованные одним слоем. Т.е. данные в OSM бесконечно расширяемые и неделимы (на слои) — собственно по этой причине и написана данная статья, было бы всё по слоям — писать было бы не о чем.
Ну, а чтобы ответить на вопрос, какие теги бывают, можете заглянуть на страницу Category: Keys и оценить насколько глубока кроличья нора. И важно понимать что список не окончательный, — модель же бесконечно расширяема.
Ладно, переходим к задачам.
--node-key (--nk)--way-key (--wk)
Фильтры по OSM тегам.
Учитывая список ключевых тегов (теги указываются в параметре keyList, через запятую), эти фильтры пропускают только те узлы или линии, соответственно, у которых установлен хотя бы один из этих тегов.
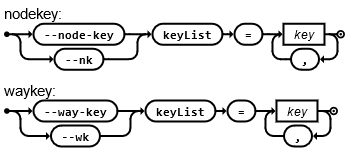
EBNF грамматика
Например попробуем получить всё линии дорог. Для обозначения дорог в OSM используется тег highway:
osmosis \
--read-pbf tyumen.osm.pbf \
--way-key keyList=highway \
--write-xml roads-way.osm.xml
Обратите внимание, что эти фильтры --node-key работает только с узлами, и ВЫБРАСЫВАЕТ все пути и отношения, а фильтр --way-key фильтрует только линии, но ОСТАВЛЯЕТ в потоке и узлы и отношения — никак их не фильтруя.
Можете попробовать сделать ещё аналогичный фильтр по узлам и сравнить результаты:
osmosis \
--read-pbf tyumen.osm.pbf \
--node-key keyList=highway \
--write-xml roads-node.osm.xml
В итоге файл roads-way.osm.xml — распух от несвязанных с дорожной инфраструктурой данных, а roads-node.osm.xml,… ну он получился предсказуемым.
Это в целом немного странно, что поведение отличается для схожих функций. К тому же сами по себе эти две задачи бестолковые, только в комбинации с другими задачами фильтрации им можно найти применение. Полагаю что это и было причиной почему поведение отличается, — задачи воспринимались как вспомогательные для уже отфильтрованных данных.
--node-key-value (--nkv)--way-key-value (--wkv)
Работают аналогично предыдущим, но помимо тегов, которые являются ключами можно добавить ещё и значения ключей, которые вас интересуют, в формате key.value. Всё что не соответствует: либо нет тегов, либо есть теги, но значения не те — будет отброшено.
В качестве аргумента keyValueList в котором и указывается список желаемых комбинаций key.value.
Давайте для примера запросим все точки, которыми отмечены камеры контроля скорости:
osmosis \
--read-pbf tyumen.osm.pbf \
--node-key-value keyValueList=highway.speed_camera \
--write-xml radar.osm.xml
При необходимости в keyValueList можно передавать несколько пар key.value, через запятую, тогда они будут восприниматься как логическое ИЛИ, т.е. в итоговый поток попадут те элементы которые соответствуют или одному фильтру, или другому, или третьему и т.д. сколько бы фильтров ни было.
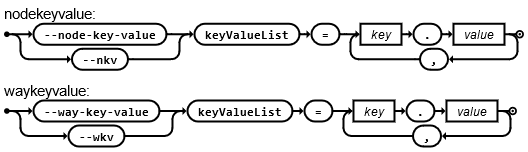
EBNF грамматика
Для примера можем получить камеры и лежачие полицейские:
osmosis \
--read-pbf tyumen.osm.pbf \
--node-key-value keyValueList=highway.speed_camera,traffic_calming.bump \
--write-xml road.osm
Ну, а если мы хотим получить логическое И, скажем не просто получить камеры контроля скорости, а с ограничением скорости на 40 км/ч, (это в отдельном теге хранится), то нужно применить две задачи последовательно:
osmosis \
--read-pbf tyumen.osm.pbf \
--node-key-value keyValueList=highway.speed_camera \
--node-key-value keyValueList=maxspeed.40 \
--write-xml radar.osm.xml
Вот и результат:
Собственно немного в Тюмени таких камер (но надо иметь в виду что OSM не гарантирует полноту и корректность данных), находится на пересечении улиц Щербакова и Мелиораторов, пользуясь случаем передаю всем привет — предупреждён, значит вооружён.
Можно комбинировать задачи разных типов, например если хотим просто получить камеры для которых в OSM указано хоть какое-то ограничение на скорость:
osmosis \
--read-pbf tyumen.osm.pbf \
--node-key-value keyValueList=highway.speed_camera \
--node-key keyList=maxspeed \
--write-xml radar.osm.xml
В качестве примера для линий получим все автомагистрали:
osmosis \
--read-pbf tyumen.osm.pbf \
--way-key-value keyValueList=highway.motorway \
--write-xml road.osm.xml
--tag-filter (--tf)
Самая полезная задача для выбора данных.
Более гибкий аналог предыдущих, гибкость в том что не ограничен одним типом, а можно настраивать, и в том что правила могут быть как разрешительные так и запретительные. В то время как в предыдущих, были разрешительные.
Принять/отклонить
В качестве параметра принимает строку, которая определяет поведение «принятия/отклонения» объекта, с которым будет работает фильтр:
accept-nodes,accept-ways,accept-relations,reject-nodes,reject-ways,reject-relations.
Здесь accept — принять, reject — отклонить.
Каждая задача фильтрует только указанный тип объекта, пропуская все остальные типы объектов. Т.е. если мы указываем accept-ways, то он отфильтрует все линии, оставив только те, что соответствуют фильтру, а узлы и отношения пройдут дальше попав на выходной поток, о них нужно будет позаботиться отдельно.
Фильтр по тегам
Когда у объекта есть тег, соответствующий одному из этих шаблонов, объект принимается или отклоняется в соответствии с режимом фильтрации. Каждая задача фильтрации тегов фильтрует только тип объекта, указанный в строке режима, пропуская все остальные типы объектов, не затрагивая их.
Шаблоны тегов не обязательны, если их не указать, то фильтр соответствует всем объектам данного типа.
osmosis \
--read-pbf tyumen.osm.pbf \
--tag-filter accept-ways highway=* \
--tag-filter reject-node \
--tag-filter reject-relations \
--write-xml output.osm.xml
В этом примере мы выбираем все линии дорог, отбрасываем все точки и отношения: accept-ways разрешительная задача, которая разрешает все линии которые соответствуют условию, reject-node и reject-relations — запретительные задачи, у которых нет условия, а значит они отбрасывают всё.
Множество значений
В рамках определенного шаблона тегов для одного ключа можно указать несколько значений, используя список, разделённый запятыми (работает опять же через логическое ИЛИ).
Модифицируем пример:
osmosis \
--read-pbf tyumen.osm.pbf \
--tag-filter accept-ways highway=* \
--tag-filter reject-ways highway=motorway,motorway_link \
--tag-filter reject-node \
--tag-filter reject-relations \
--write-xml output.osm.xml
Здесь мы выберем все линии дорог, а потом исключаем из них (в reject-ways) автомагистрали и съезды с автомагистралей.
Подстановочное значение * (одна звездочка) соответствует любому значению.
Обратите внимание, что каждая задача фильтрации тегов может принимать более одного шаблона тегов и примет (accept) или отклонит (reject) объект, если он соответствует любому из этих шаблонов. Иными словами, пар ключ=значение в одной задаче может быть несколько.

EBNF грамматика
Например мы захотим получить все места для спорта, отдыха и туризма:
osmosis \
--read-pbf tyumen.osm.pbf \
--tag-filter accept-nodes sport=* tourism=* leisure=* \
--tag-filter accept-ways sport=* tourism=* leisure=* \
--tag-filter reject-relations \
--write-xml rest-poi.osm.xml
Тут могла быть реклама VisitTyumen, но нет.
--used-node (--un)--used-way (--uw)
Ранее мы писали что каждая задача фильтрует только указанный тип объекта, пропуская все остальные типы объектов, а об остальных придётся побеспокоиться отдельно.
Например фильтруем мы линии, что делать с узлами? Отбросить? Можно и отбросить конечно, а что если мы хотим оставить те, что используется в линиях, которые мы ранее отфильтровали, а остальные отбросить?!
Вот для этого и существует --used-node — ограничивает поток узлов теми, которые используются в линиях и/или отношениях которые присутствуют во входном потоке.
Модифицируем уже рассмотренный ранее пример:
osmosis \
--read-pbf tyumen.osm.pbf \
--tag-filter accept-ways highway=* \
--tag-filter reject-ways highway=motorway,motorway_link \
--tag-filter reject-relations \
--used-node \
--write-xml output.osm.xml
Вещь полезная, ибо way — не совсем линии, координаты точек они не хранят, только ссылки на них (ref):
Координаты хранятся отдельно в узлах:
Поэтому если важна геометрия линии (way), то мало выбрать линии, надо ещё и выбрать узлы, а --used-node — единственный способ получить только используемые точки — отбросив остальные.
Задача --used-way аналогична, ограничивает поток линий (way) теми, которые используются в отношениях (relation) которые присутствуют во входном потоке.
Задачи по управлению потоком
Эти задачи позволяют манипулировать структурой потока. Манипуляций с данными, не проводят.
--write-null (--wn)
Отбрасывает все входные данные. По сути прерывает поток. Это полезно для проверки целостности входных файлов или тестирования каких-то задач на корректность написания.
Мы его уже использовали в некоторых примерах, чтобы избавить себя от необходимости сохранения результата в файл.
--merge (--m)
Объединяет два потока в один. Только два. Если вам нужно объединить три источника данных, придётся указывать эту задачу дважды. И так далее.
Если бы такой пазл существовал он бы выглядел вот так (головоломка выходит на новый уровень):

Для примера откроем три потока из разных файлов:
osmosis \
--read-pbf tyumen.osm.pbf \
--read-pbf tobolsk.osm.pbf \
--read-pbf ishim.osm.pbf \
--merge \
--merge \
--write-pbf merged.osm.pbf
Первый merge объединяет tyumen.osm.pbf и tobolsk.osm.pbf, создаёт поток, второй merge объединяет этот поток и поток из ishim.osm.pbf, создаёт поток, и затем мы сохраняем его в отдельный pbf файл, который содержит все три города.
Следующая команда создаст выходной файл, содержащий кафе, а также все пешеходные дороги и точки, на которые они ссылаются.
osmosis \
--read-pbf tyumen.osm.pbf \
--tag-filter reject-relations \
--tag-filter accept-nodes amenity=cafe \
--tag-filter reject-ways \
\
--read-pbf tyumen.osm.pbf \
--tag-filter reject-relations \
--tag-filter accept-ways highway=footway \
--used-node \
\
--merge \
--write-xml amenity-and-motorway.osm
В общем merge задача полезная — позволяет одной командой получить разношерстные данные, написав несколько последовательных блоков команд, и не мучаться со всякими reject и accept путаясь всё впихнуть в один tag-filter.
По сути из задач, полезных для добычи данных — всё. Если конечно не копать в сторону взаимодействия с БД, но это уже совсем другая история. Про эту историю уже тоже есть очерк на Хабре: Импорт OpenStreetMap. От бинарного исходника к таблице в БД в несколько шагов.
Заключение
Что ж, надеюсь я помог Вам разобраться в теме добычи геоданных из выгрузки OSM. Это не все возможности osmosis, но для получения данных в виде XML (почти человеческом) — достаточные.
Если Вам хочется глубже погрузится в мир OSM со всеми его преимуществами и недостатками, то вот несколько ссылок
И небольшой совет по поиску тегов OSM: не надо вычитывать всю документацию в поисках нужного тега — сначала смотрите как картографируют другие. Т.е. находите на карте (https://www.openstreetmap.org) один из интересующих Вас объктов, на правой панели инструментов выбираете «Что здесь?», кликаете на карту на интересующий Вас объект, и смотрите как он закартографирован.
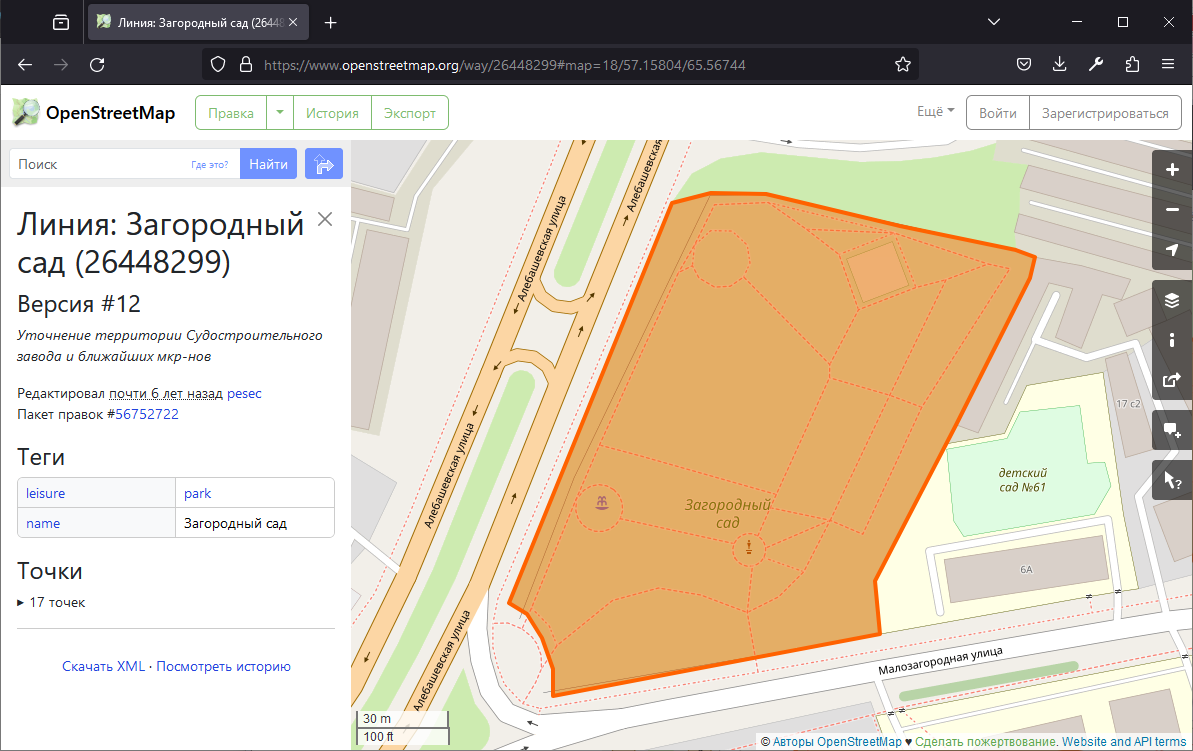
Просмотр тегов на карте
Это поможет понять в каком направлении копать документацию.
Удачи!
