Генерация кода во время работы приложения: реальные примеры и техники
Генерация кода в рантайме — очень мощная и хорошо изученная техника, но многие разработчики все еще неохотно её используют. Обычно изучение Expression Trees начинают с какого-нибудь простого примера типа создания предиката (фильтра) или математического выражения. Но не Expression Trees единым жив .NET-разработчик. Совсем недавно появилась возможность генерировать код, используя сам компилятор — это делается с помощью API библиотек Roslyn/CodeAnalisys, предоставляющих, кроме всего прочего, еще и парсинг, обход и генерацию исходников.
Эта статья основана на докладе Raffaele Rialdi (Twitter: @raffaeler) на конференции DotNext 2017 Moscow. Вместе с Рафаэлем мы проанализируем реальные способы использования кодогенерации. В отдельных случаях они позволяют очень сильно улучшить производительность приложения, что в свою очередь приводит нас к дилемме — если сгенерированный код так полезен и мы собираемся его часто использовать, то как же отлаживать этот код? Это один из фундаментальных вопросов, возникающих в реальных проектах.
Рафаэль — практикующий архитектор, консультант и спикер, имеющий MVP в категории Developer Security начиная с 2003 года, который прямо сейчас занимается бэкендами enterprise-проектов, специализируясь на генерации кода и кроссплатформенной разработки для C# и C++.
Что такое генерация кода? Предположим, необходимо продемонстрировать производительность. Если просто показать бенчмарк — это был бы своего рода фокус, хитрый трюк. В статьях и докладах стоит избегать показа бенчмарков — не потому, что это опасно для автора, а потому, что бенчмарк демонстрирует только к один сценарий, и вряд ли он полезен для всех читателей. Читателя принуждают опробовать предложенные технологии и решить, подходят они или нет для его конкретных сценариев. Поэтому не стоит преувеличивать значение бенчмарков. Для себя я их делаю, они показывают приличные результаты.
Мы знаем, что программа с рефлексией по определению будет работать медленно. Ей необходимо загрузить метаданные ECMA-335 и интерпретировать их. Они представляют из себя очень компактный набор бинарных данных, их чтение достаточно сложное. Они должны быть компактными, поскольку не должны занимать слишком много памяти после сборки. После того, как эти артефакты развертываются, производительность оказывается неудовлетворительной, поскольку мы имеем дело с очень низкоуровневым API. Кстати говоря, рефлексии можно избежать, если загружать все эти артефакты напрямую из сборок. Об этом я не буду говорить в сегодняшнем докладе, но, если вам это интересно, такой метод я уже применял, чтобы избежать постоянной загрузки и сборки в памяти; можно освободить память от всего, кроме информации о типах.
Когда именно следует генерировать код? На том участке жизненного цикла приложения, когда появляется достаточно информации, позволяющей упростить алгоритм. Речь идет, например, об информации, которую можно получить из пользовательского интерфейса для фильтра, который сократил бы количество получаемых из базы данных записей. Или об информации о типах, загруженных в плагине. Крайне нежелательно тратить время на создание при помощи рефлексии общего алгоритма, который учитывал бы все возможные варианты. У разработчиков, к сожалению, есть тенденция пытаться делать разрабатываемые ими решения максимально общими, работающими во всех возможных и невозможных случаях. Для нашего программистского ума это естественный ход мыслей. Я предлагаю ровно противоположный подход: терпеливо ждать до тех пор, пока не будет достаточно информации для генерации максимально лаконичного кода.
В каких именно случаях может быть необходима генерация кода? Например, при использовании предикатов LINQ. Билдеры предикатов доступны уже давно. Или при использовании формул, скажем, из Excel. Или при загрузке типов из плагина, или при использовании Reactive Extensions. Кто из вас знаком с Reactive Extensions? Это замечательная библиотека, которая позволяет создавать потоки данных и применять выражения, способные фильтровать группы и изменять эти данные. Я покажу многие из этих примеров чтобы продемонстрировать возможности рефлексии.

Начнем с Expression в C#. На экране простой пример кода, в котором генерируется вызов Console.WriteLine. Возможно, кто-то спросит — зачем использовать рефлексию, если вы только что указали на недостатки использования рефлексии? Ответ не в том, чтобы отказаться от рефлексии вообще, а в том, чтобы убрать ее из наиболее используемых участков кода. Нужно найти точку во времени, в которой при помощи рефлексии можно будет извлечь необходимое количество данных, сгенерировать код и, к примеру, использовать делегирование внутри цикла, чтобы не ждать, пока код будет выполнен.
В коде я начинаю с того, что получаю точную перегрузку WriteLine, затем я создаю параметр, который впоследствии станет входным сообщением. После этого я создаю эквивалент метода Call. В вызове Expression.Call(null, methodInfo, message), null обозначает статический метод (WriteLine является статическим методом). Кроме того, в этом вызове также нужны аргументы с информацией о методе, и с сообщением.
После этого создается лямбда. Это очень просто, нужно указать параметры и тело лямбды. У уже созданной лямбды вызывается весьма полезный метод .Compile(). Он хорош тем, что напрямую и очень простым способом создает инструкцию в памяти. Нет исходного кода, нет ничего, что нужно было бы обрабатывать способами, описанными в «Dragon Book». Нет первой ступени компиляции, т. е. долгого и сложного анализа текста. Он не нужен, поскольку в случае с Expression мы уже знаем, что оно синтаксически верно. Это очень важно. Именно поэтому дерево выражений настолько громоздкое, у него крайне неприятная строгая типизация. Если вы уже когда-то пробовали составлять несколько выражений друг с другом, вы знаете, какая это нервотрепка. Но имея сформированное выражение, его действительно можно скомпилировать. Компилятор просто берет узлы дерева (т. е. определенные выражения), и создает соответствующий узел под тот код, который мы хотим вызвать. В конечном итоге мы формируем делегат, т. е. наиболее быстрое доступное средство для исполнения кода.

Покажу пример, в котором будет создан предикат. Очень простая функция, которая принимает на вход целое число и возвращает булево значение. Посмотрим на ее код. Для первого входного значения там создается параметр: Expression.Parameter(typeof(int), "x"). Один из входных аргументов этого метода — "x", не обращайте на него внимания, он нужен только для отладки. Переменная left обозначает левую часть выражения x > -10, right — правую. Из этих двух переменных создается бинарное выражение сравнения. Наконец, возвращается выражение Lambda. В данном случае это предпочтительнее, чем возвращать делегат, поскольку в случае необходимости будет возможность внести в нее изменения. Для этого можно использовать паттерн Visitor, который пронумерует все узлы внутри выражения, и изменит его очень точным образом. Не нужно никакой работы с текстом, сразу происходит переход к необходимому узлу.

Приведу пример, в котором необходимо посетить некоторый вызов. Предположим, происходит извлечение предикатов из узла where, поскольку код написан на LINQ. Имея нужное Expression, к нему можно написать Visitor. А найти этот Expression можно, поскольку where является вызовом метода расширения. Первый параметр where является IQueryable, и возвращает булево значение. Так что мы знаем, какая именно форма нам нужна. Если же необходимо к этому Expression что-либо добавить, это можно сделать на том месте, где на экране написано многоточие.
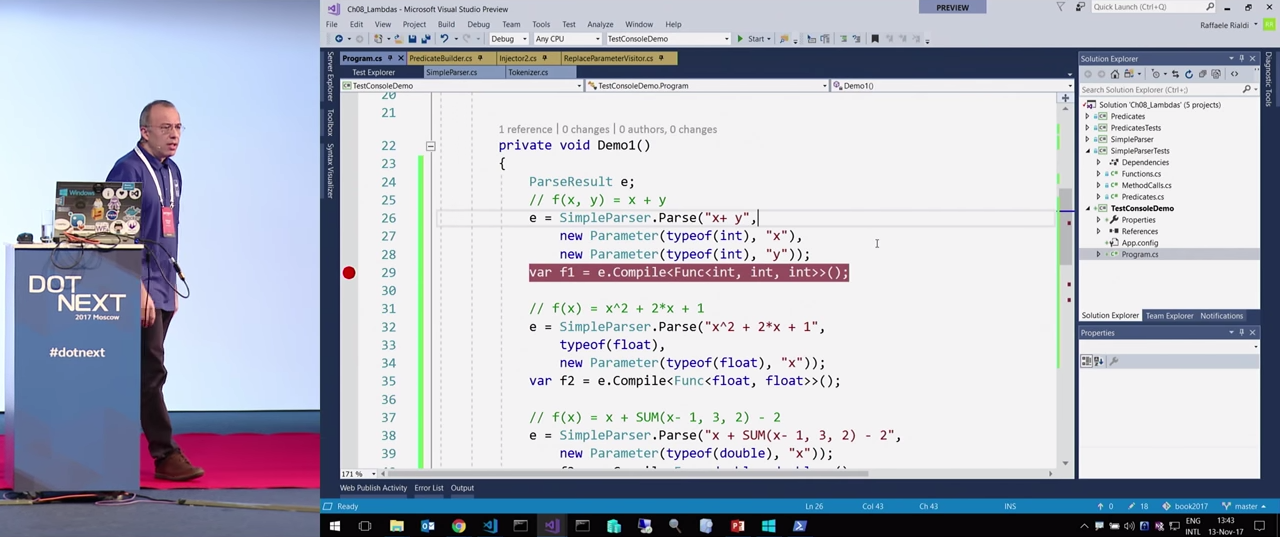
Чтобы не заскучать, давайте перейдем к демонстрациям. Изначально я не хотел писать средство для синтаксического анализа, поскольку это скучно, такая программа обычно получается медленная, и есть библиотеки, которые выполняют эту задачу лучше, чем самописный код. Мне нужно было нечто небольшое и легко изменяемое. А при написании средств синтаксического анализа приходишь к тому, что надо писать грамматику, приходится использовать много библиотек. Кроме того, хотелось написать инструмент таким образом, чтобы созданные после анализа узлы были похожи на то, что Expressions выражают на самом деле. В итоге я пришел к тому, чтобы представить, к примеру, выражение x + y (которое вы видите в коде) в форме текста, и затем распознать его.
То есть я попытался выразить параметры вручную. Я это сделал для простоты, и возможно, этого можно избежать. По крайней мере, важно указать типы, поскольку в Expression нельзя пользоваться первым этапом компиляции. К примеру, недоступно автоматическое преобразование типов или неявное преобразование типов, недоступно преобразование integer в double. Все это приходится делать вручную.
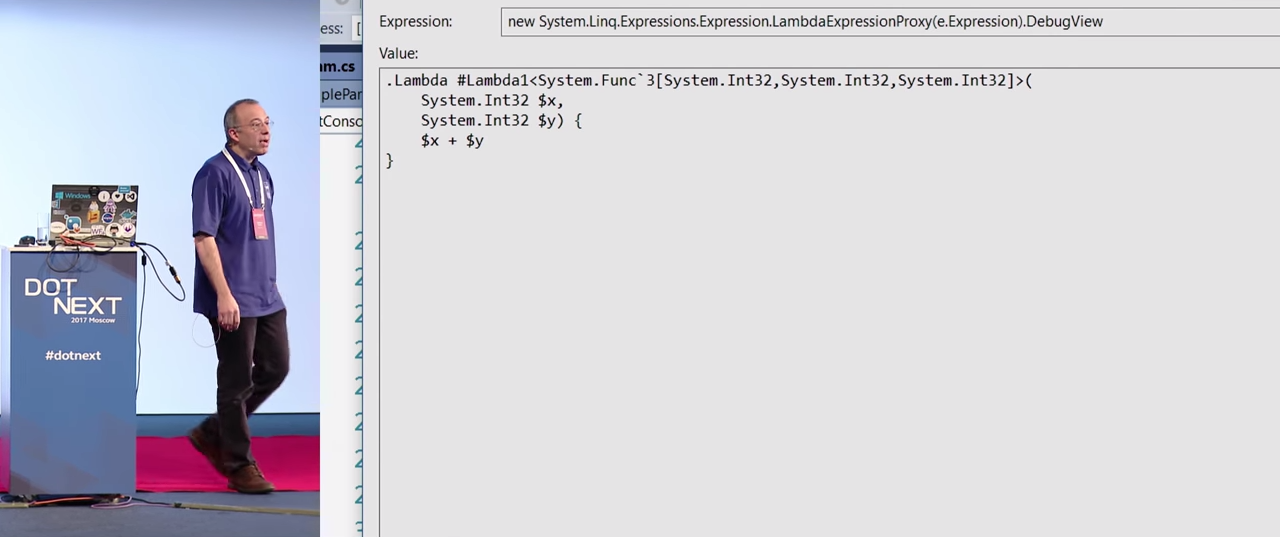
Если запустить в отладчике код, который вы видите на экране, то будет возвращено Expression. Лямбда представлена в отладчике Visual Studio достаточно странным образом, но ничего страшного в этом нет. Выглядит сложно, но в конце концов, это просто x + y, с этим можно жить.

Посмотрим, как можно перевести написанную мной текстом функцию SUM(). Визуализатор текста показывает нам переменную e, в которой в данный момент находится результат перевода. Видно, что я определил FunctionsHelper с предопределенной функцией, так, как это делает Excel. Такого рода приложения должны предопределять своего рода словарь функций. Все это достаточно просто.
Попробуем пройти немного дальше в коде. Там есть функция GetFilter().
Как видим, это лямбда. Обычно в таких случаях возвращается Func и больше ничего. Но у компилятора есть особенная возможность, которая позволяет, в случае отсутствия в теле функции квадратных скобок, возвращать Expression. То есть автоматически создается Expression для этого представления. Это очень удобно, поскольку его по-прежнему можно изменять. Если вы хотите убрать число и заменить его чем-либо еще, можно просто написать Visitor для выражения и сделать при помощи него все необходимые изменения.

Посмотрим на вторую демонстрацию. В ней у нас с самого начала есть предикат Expression.
Я хочу сделать в него инъекцию, которая давала бы вывод на командную строку. Я передаю в инжектор предикаты и две лямбды и указываю при получении значения x каждый раз выводить {x} => YES или {x} => NO. Если мы посмотрим на то, как выглядит переменная injected после запуска приложения, то увидим функцию с оператором If, она была достаточно сильно изменена по сравнению со своим первоначальным значением.

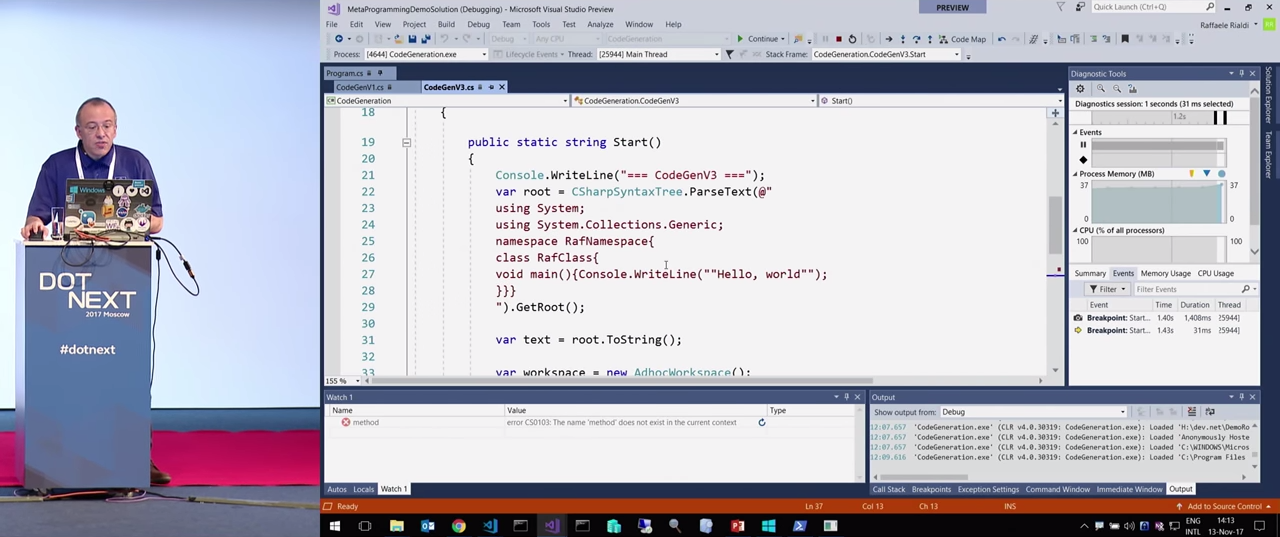
Итак, здесь на вход подается целое число, делается инъекция If, на консоль выводится YES или NO в зависимости от значения, и, наконец, возвращается обработанное выражением значение. Такого рода изменения кода уже вошли в практику, и они весьма мощные.
Есть проблема, на которую, вы, вероятно, уже обратили внимание — визуализатор, в котором я до сих пор показывал вам сгенерированный код, представляет информацию в достаточно странной форме. Программирование с выражениями дает определенные преимущества, но с точки зрения разработчика код получается «грязный».
Вернемся к демонстрации. Я уже говорил об отложенном выполнении: пока не будет завершено перечисление чисел, следующий код не будет выполнен. Если прямо сейчас дойти до toList, мы получим и список, и Console.WriteLine для них, которые в этом случае выполнятся автоматически.

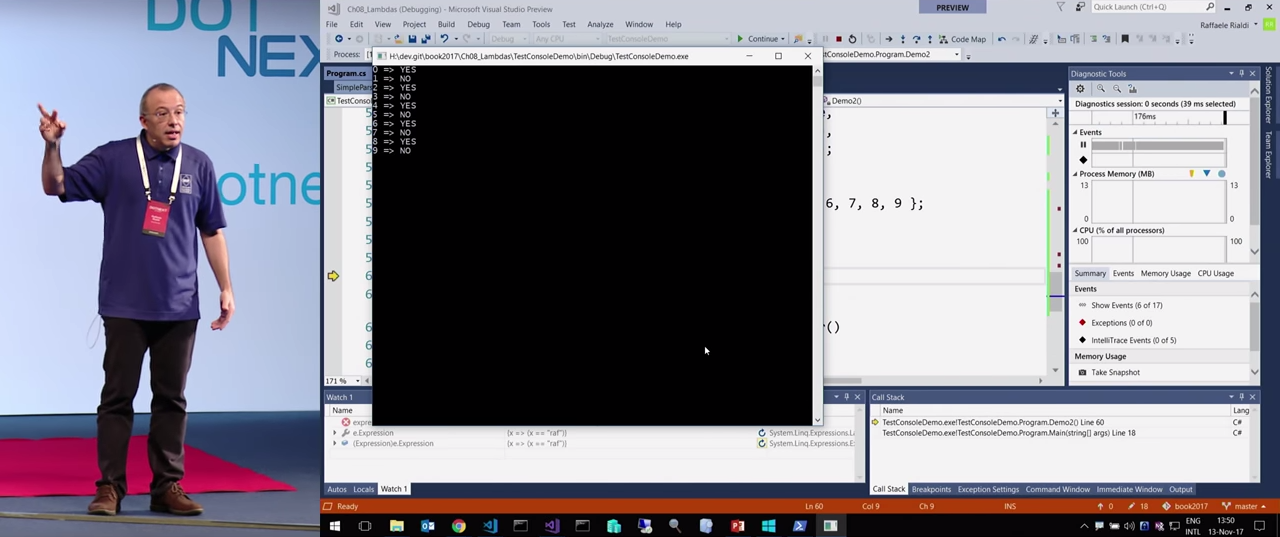
Всё это выглядит неплохо, но хочется попробовать нечто более сложное. Следующий пример пришел ко мне во сне. Я хочу создать лямбду, которая, будучи скомпилированной, преобразует данные в словаре (возможно, JSON) в определенном порядке. Задача достаточно обычная.
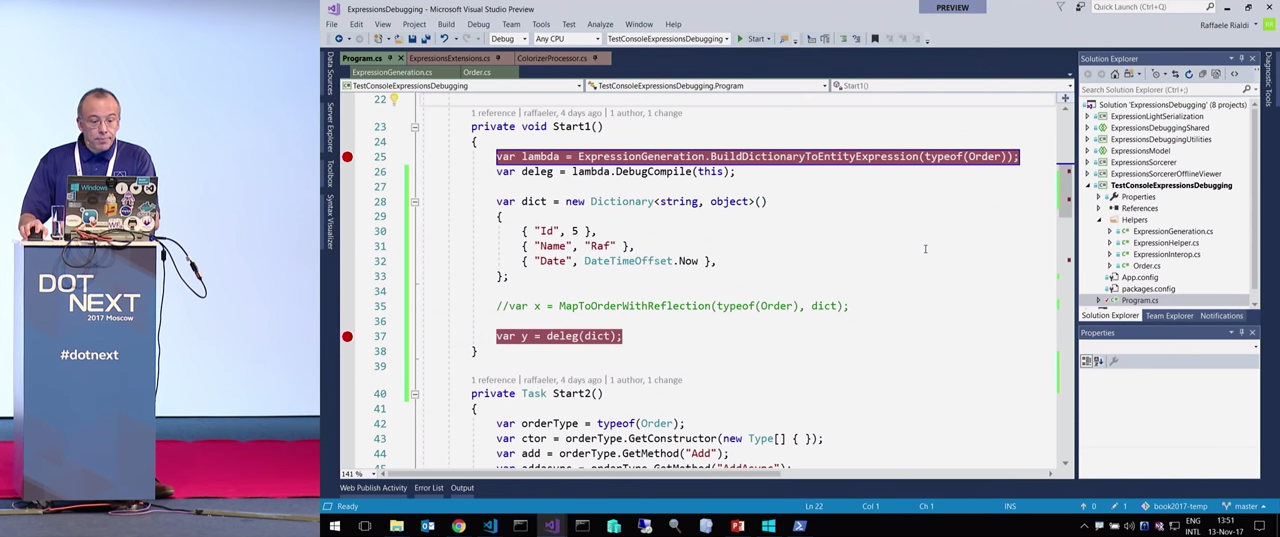
Если выполнять этот код при помощи рефлексии, результат получится такой, который вы сейчас видите на экране.

Происходит итерация по свойствам отображения, поиск соответствия в словаре для каждого свойства и копирование. Очевидно, этот код будет медленным. Если он выполняется только один раз, это не проблема, но если его нужно выполнить миллион раз — ну, вы поняли. Если это будет происходит в серверном приложении, потребляющем ресурсы сервера, кому-то это может не понравиться.
Попробуем решить эту проблему другим образом. Здесь в коде создается объект `Order, элементы которого будут поставлены в соответствие с поступающим на вход в класс словарем.
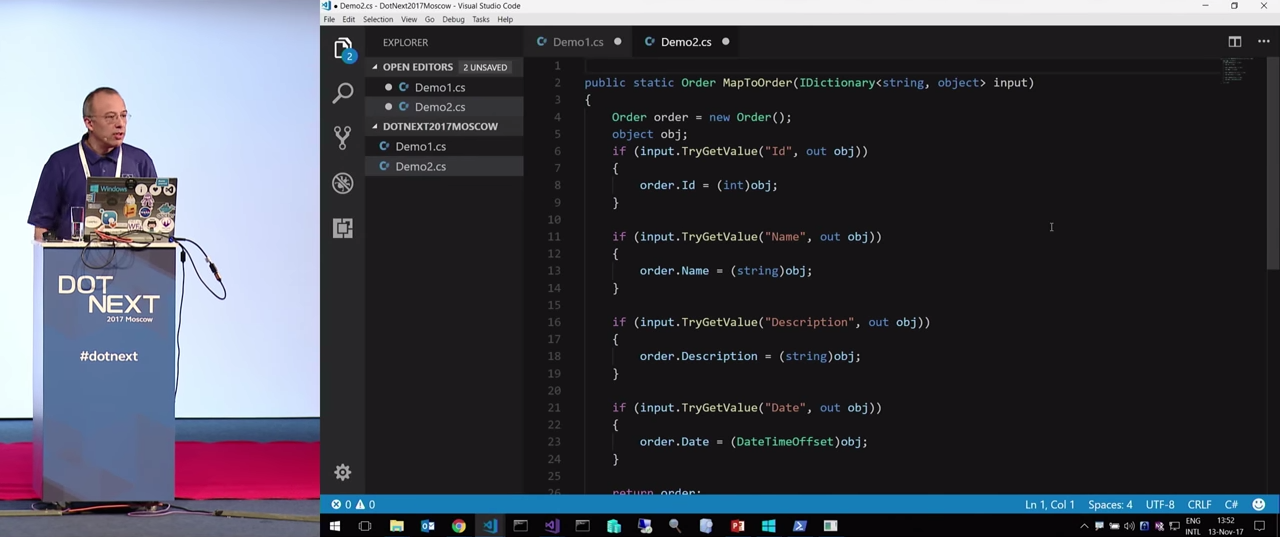
Из словаря извлекаются значения, затем они приводятся к необходимому типу, копируются, и это все совершенно жутко и скучно.
Но что, если я создам лямбду, которая уже будет знать объект Order?

Важно, что я указываю тип этого объекта. Заметьте, что я не использую Order определяется в плагине с отложенной загрузкой? В некоторых случаях дженерики могут помочь, но в данном случае их использование было бы нежелательным, поскольку нам может понадобиться абстрагироваться от этой информации.
Итак, посмотрим на нашу лямбду после компиляции.

Правда, она хороша? Код приятно читать. Он был сгенерирован при помощи Expressions. Давайте посмотрим на то, как они написаны в классе ExpressionGeneration.

Мы видим, что код похож на то, что я написал при помощи рефлексии. Определяется Expression.Parameter(), определяется переменная result, создается новый newEntityType с помощью Activator.CreateInstance, новый экземпляр присваивается переменной assign. Всё очень скучно. Затем я получаю метод через type.getMethod() и после этого обхожу свойства entityProps.
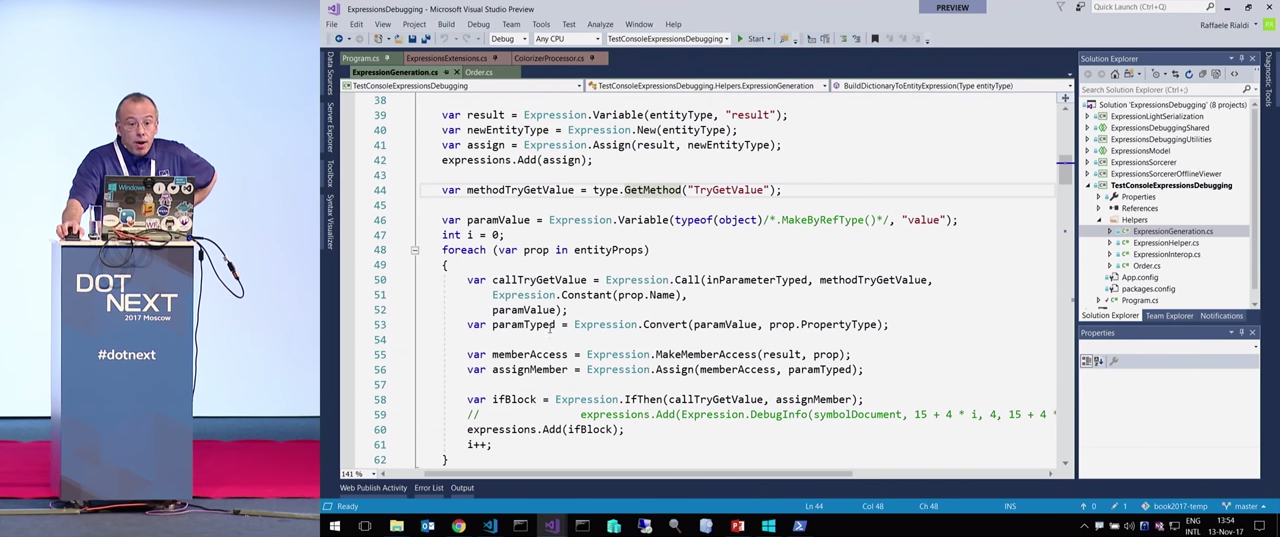
Создавать цикл в данном случае не нужно, поскольку мы знаем, сколько здесь будет свойств. Таким образом, здесь генерируются ровно те вызовы, которые нужны, чтобы извлечь необходимое значение для callTryGetValue.

В следующей строке вызывается метод Expression.Convert(), для него необходимо сделать приведение к типу, поскольку типы могут быть разные. Далее для доступа к свойству делается вызов Expression.MakeMemberAccess(). После этого делается вызов Expression.IfThen() для конструкции try-catch. Наконец, создается блок, т. е. открывающая и закрывающая скобка. И в результате мы получаем лямбду.
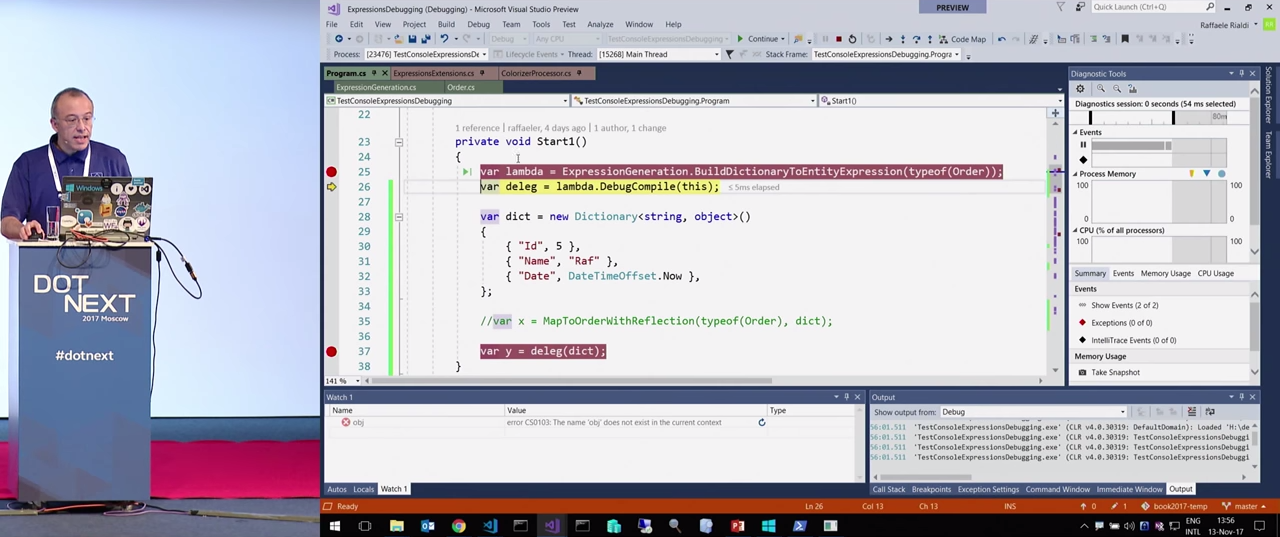
Я написал инструмент ExpressionsSorcerer. Можно взять его код и поместить в директорию %USERPROFILE%/Visual Studio 2017/Visualizers, и снова запусть отладку только что рассмотренного кода. На этот раз я смогу увидеть лямбду через визуализатор, она будет представлена в виде дерева.
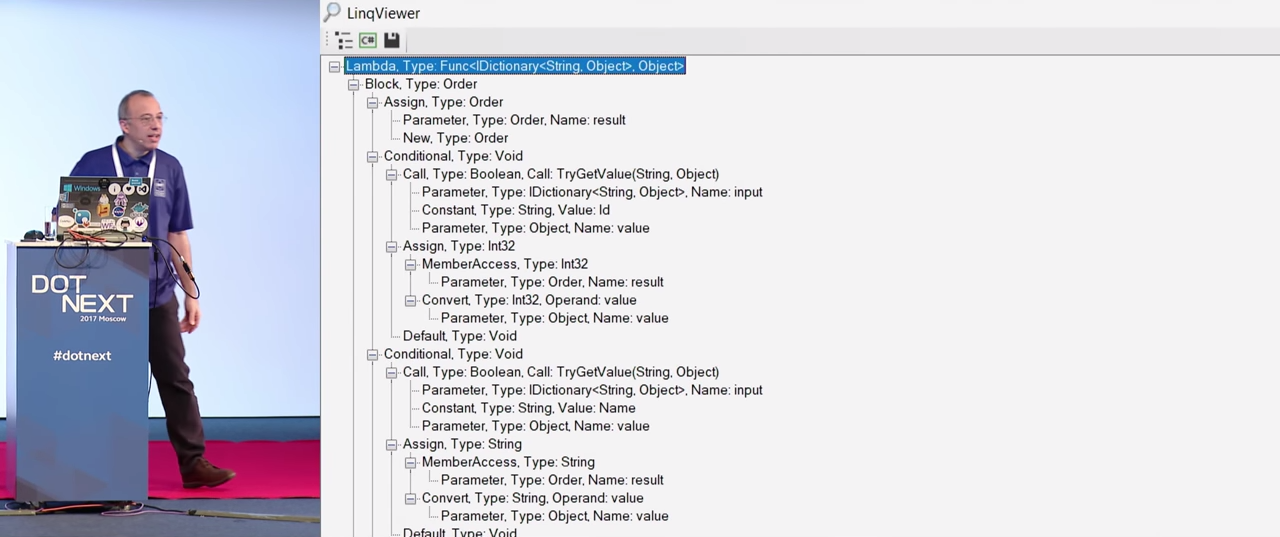
Такого рода операция может быть очень полезной, помогает задуматься, а что за чертовщину я тут написал? При выделении отдельного узла дерева в окне справа появляются свойства и их значения, что весьма удобно. Открываем вкладку «Show the decompiled source» («Показать декомпилированный источник»). Перед нами код, который я написал бы, если бы обладал той информацией, которая была передана генератору кода.

Но я и пальцем не притрагивался к этому коду. Я даже не генерировал C#-код. Я написал Expressions, т. е. в памяти находились только синтаксические узлы, и мне нужно было проводить декомпиляцию. Благодаря Roslyn здесь так же есть цветовая разметка, при необходимости она может быть изменена. Кроме того, я добавил атрибут DebuggableAttribute, поскольку мне не нужны оптимизации, которые могут возникнуть в ходе компиляции. Возможно, вы спросите, почему они мне не нужны? А в ответ у меня для вас будет еще один сюрприз.
Если скомпилируем с отладкой (нажатием «F11»), мы войдем в автоматически сгенерированный метод, которого мы своими руками не писали. Впечатляет, не правда ли? Здесь видны текущие значения переменных, можно проверить, нет ли ошибок в Expressions. Как видим, значения Description во входном аргументе не было, так что метод TryGetValue был использован не зря.

В конце рассматриваемой функции мы получаем переменную order с правильным числом значений.
Подведу промежуточный итог. Expressions охватывают практически весь язык, при помощи них можно генерировать операторы if, throw, catch, можно создавать сложные конструкции. Но для этого, скорее всего, понадобится специальный инструмент. В моем инструменте наиболее сложной для написания частью были неявные преобразования типов. Если вы создали переменную double x, и попытаетесь присвоить переменной с типом integer ее значение, вы получите исключение InvalidCastException. Причина заключается в том, что неявное преобразование выполняется компилятором, а у нас его не было. Поэтому пришлось заниматься некоторыми вещами, которые обычно выполняет компилятор.
Давайте я продемонстрирую некоторые более сложные выражения. На экране код, в котором создается очень простой объект var newObject = ExpressionInterop.BuildNewObject(ctor).

Если посмотреть на него в средстве визуализации, будет видно, как создается новый объект new Order().
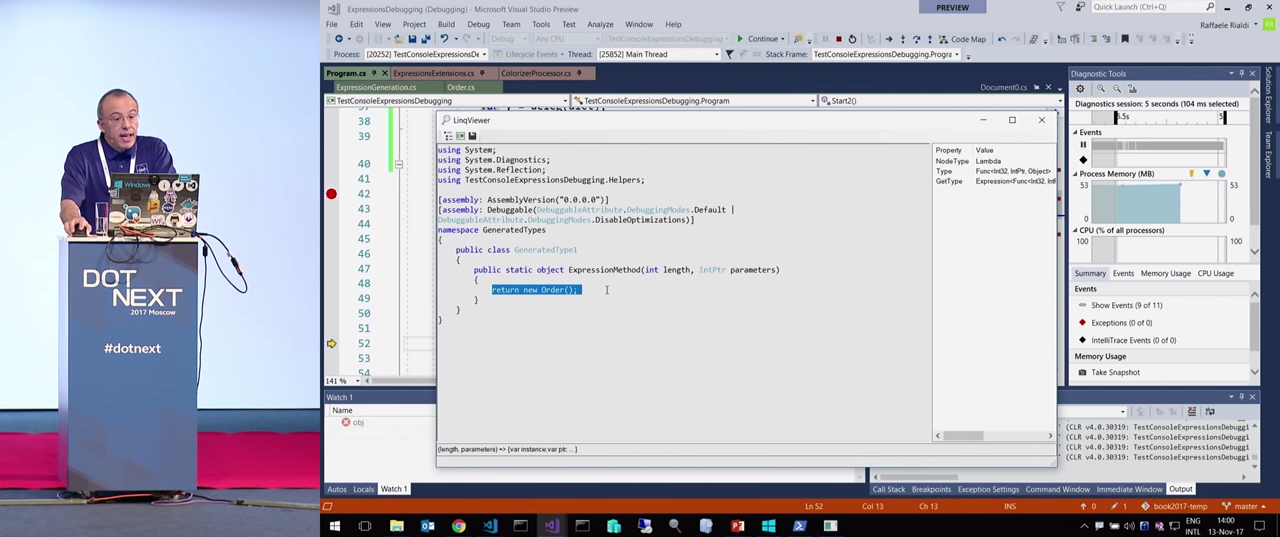
По уже упомянутым причинам, я всегда рекомендую использовать метод typeof(). Далее, через метод GetConstructor я получаю нужный мне конструктор, а затем через методы GetMethod — нужные методы. После этого создается новый объект, которому передается информация о конструкторе: ExpressionInterop.BuildNewObject(ctor). И так далее.
Я не буду подробнее на этом останавливаться. Но я хотел бы показать вам, как выглядит выражение, когда вы присваиваете значение свойству…
Вот артефакты компиляции:


Но если мы вернемся к настоящему Expression, оно выглядит достаточно запутанно. Одно из самых сложных созданных мной Expressions используется для маршалирования. Я сгенерировал код, который позволяет мне выполнить асинхронный код для AddAsync…

… даже если в выражении нет кода, который мог бы представлять Task.
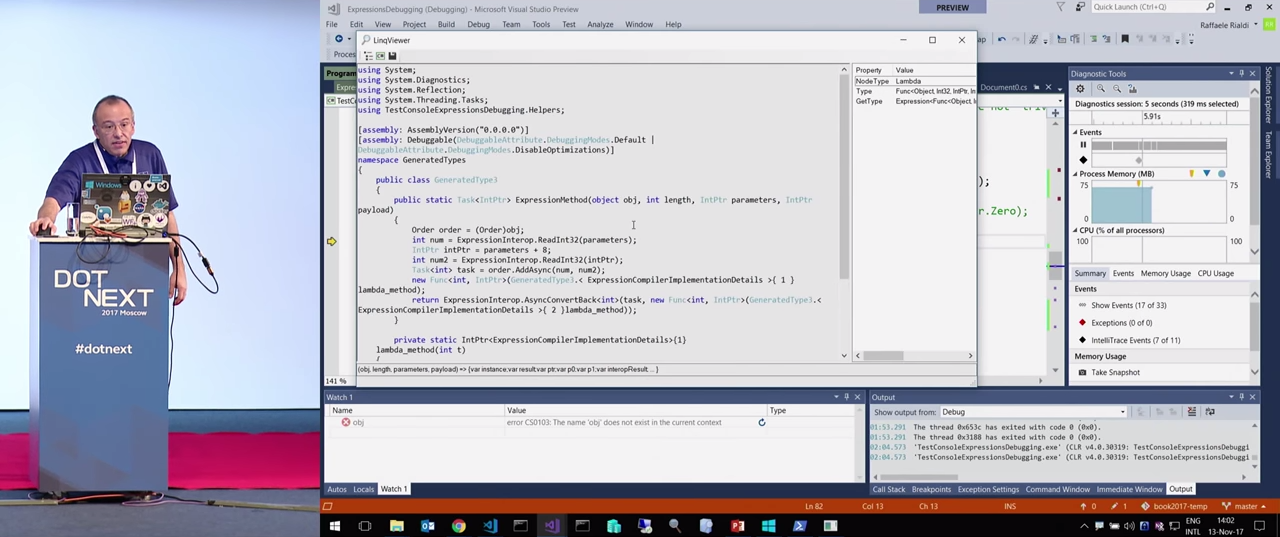
Код достаточно запутанный, перекомпилировать его не удастся, поскольку компилятор, Mono.Cecil, не может создать идеальную декомпиляцию. Возможно, ему это будет по силам в будущем. Кроме того, проблема здесь в том, что для Task необходимо сделать инъекцию внешней функции. Это нужно потому, что Expressions были созданы до асинхронных библиотек и до изменений в компиляторе для поддержки async/await. Поэтому невозможно провести генерацию с компилятором и воспользоваться await. Компилятор выполняет все волшебство, так что если вы воспользуетесь ILSpy и посмотрите на артефакт, созданный при помощи await, то увидите там колбек с продолжением. Код получается очень усложненным.
Итак, на чем мы остановились? Мы создали Expressions для генерирования определенных предикатов, функций, достаточно сложных кусков кода с конструкциями if-then-else, throw-catch и многого другого. Давайте теперь поговорим о Roslyn.

Roslyn — это платформа компилятора .NET, в течение уже нескольких лет работает как основной компилятор для C#. Иначе говоря, он правит нашим миром. Раньше мы мало что могли делать, но Roslyn открыл API для нас. Теперь при помощи API этого компилятора мы можем напрямую делать кучу всего. У нас есть форматирование, информация о символах, можно компилировать разные вещи, интерпретировать символы, влезать в метаданные, лежащие за ассемблером, и многое другое. Что касается цветовой разметки, то напрямую ей Roslyn не управляет. Он не указывает: «это должно быть зеленым, а то — синим». Просто есть классификация анализируемых лексем, и их можно по-разному отображать.
Таким образом, у нас доступно достаточно много инструментов, но есть проблема. В Roslyn нет строгой типизации. Есть синтаксические узлы, и они очень просты в использовании, поскольку любой элемент является синтаксическим узлом. Нет необходимости тратить внимание на то, чтобы соединять узлы друг с другом. Но у этого есть обратная сторона. Без той самой жесткой типизации, которая так сильно действует на нервы, когда работаешь с Expressions, мы никогда не знаем наверняка, будет ли правильно работать код, который мы пишем. Поэтому с Roslyn больше шансов возникновения ошибок, чем в коде, написанном с Expressions.
И все же, преимущества Roslyn велики. Им покрывается весь язык, т. е. создавать можно любые конструкции. Например, к Roslyn можно обратиться, если необходимо создавать новые типы во время выполнения программы. Предположим, я хочу создать DTO (Data Transfer Objects) несуществующего объекта во время выполнения. Я не хочу прибегать к помощи AutoMapper, поскольку AutoMapper обычно пользуются во время разработки. Созданный тип должен будет способен фильтровать события, каждое из которых будет различного типа. Если вы хотите указать Expression, его необходимо создать и затем работать с типом, представляющим эти данные. А для их десериализации понадобится DTO.
Первый и наиболее простой способ генерировать код при помощи Roslyn — средство синтаксического анализа, у которого есть API.

Оно анализирует текст, создает синтаксическое дерево, с которым дальше можно совершать самые разные операции: менять формат, делать красивые отступы, преобразовывать. Предположим, необходимо провести рефакторинг API, поменять имена переменных или заменить вызов, скажем, Console.WriteLine на Console.Write. Вместо того, чтобы создавать все с нуля, можно прочитать имеющийся код, использовать его как шаблон, и заменить только необходимое. Для этой цели очень хорошо подходит шаблон Visitor. Можно посетить некоторые из лексем в приложении, и, найдя нужную, заменить. Как видно из слайда, форматирование осуществляется весьма просто.
Если этой функциональности недостаточно, можно воспользоваться SyntaxGenerator. Это мощный высокоуровневый API, под ним есть синтаксическая фабрика. В нем можно объявлять пространства имен, классы, атрибуты, параметры, иначе говоря, это полноценный язык. А при помощи команды node.AdjustWhitespace() можно сделать стандартные пробелы между узлами.

Для начала посмотрим на несколько примеров работы этого инструмента. В первом из них мы используем SyntaxFactory, из которой получаем SyntaxTrivia, QualifiedName, CompilationUnit, UsingDirective. Возможно, вы скажете — это же еще хуже, чем деревья Expressions. Но то, что вы видите здесь — это низкоуровневый API. Знать его полезно, и его можно исследовать при помощи SDK для Roslyn. В нем можно увидеть, как создается синтаксическое дерево кода, как друг к другу присоединяются узлы в Roslyn. Это очень важно, поскольку, если вы не понимаете, как представить вызов метода, какие там дженерики, возвращаемое значение или еще что-то, это все можно увидеть здесь, в визуализаторе синтаксического дерева. Итак, это мощное средство, при помощи него можно создавать красивые диаграммы и многое другое.
Вернемся к нашему примеру, я снова запускаю в нем отладчик. После получения последнего синтаксического узла оказывается доступен исходный код. В теории, можно обойтись только синтаксическими узлами и избавиться от исходного кода, поскольку при компиляции, конечно, не хочется заново повторять синтаксический анализ всего дерева. Тем не менее, наличие кода может быть полезно по двум причинам. Во-первых, это единственный способ указать кодировку. Компилятор может ошибиться, если неправильно понимает кодировку исходного кода. Во-вторых, наличие кода очень важно при отладке. Даже в продакшне исходники сгенерированного кода стоит какое-то время хранить. Он может служить своего рода журналом.
Второй пример с Roslyn также очень простой.
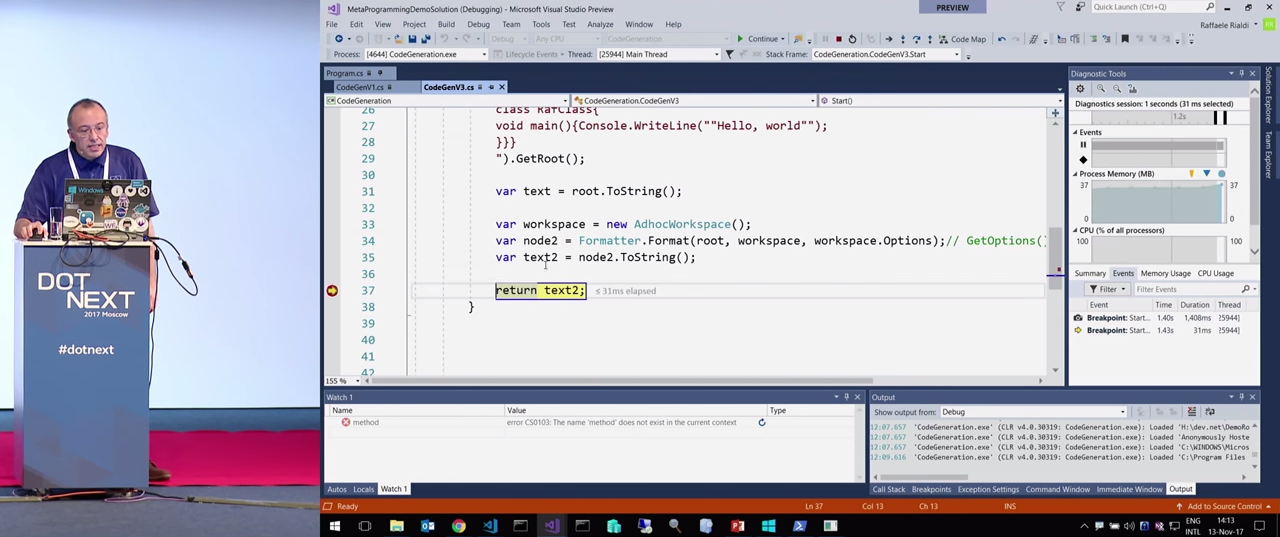
Мы можем сравнить сгенерированный код в переменной text:
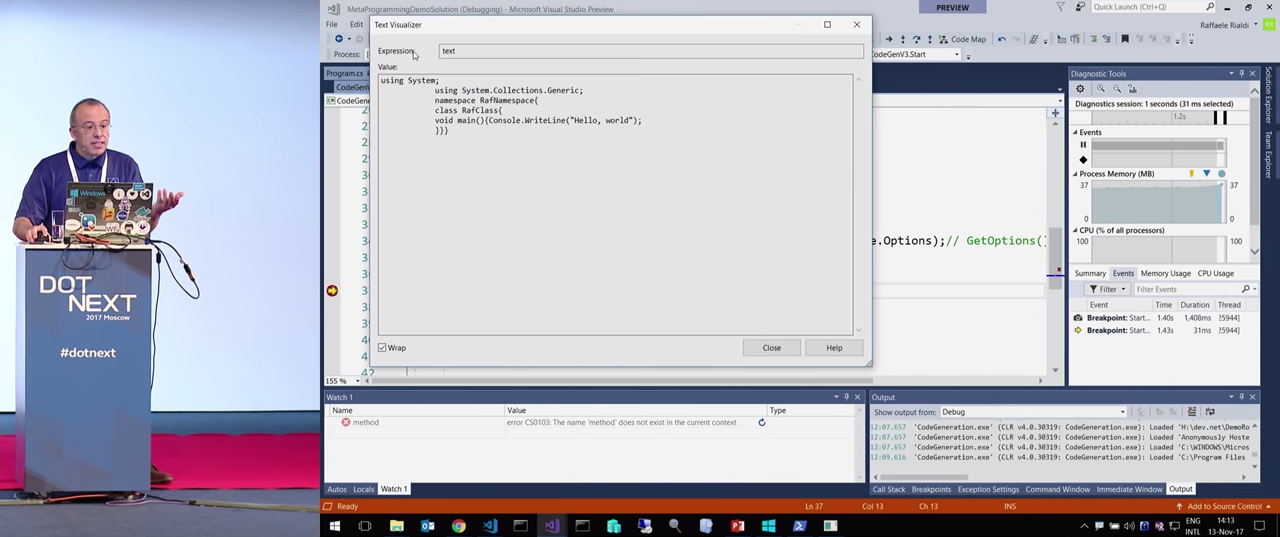
И то, как он стал выглядеть после форматирования (text2):

Как видим, больше не осталось предлогов пользоваться StringBuilder-ом для создания кода.
Следующий пример.

Я беру кусок сгенерированного кода:

И преобразовываю его с помощью PostProcess(SyntaxNode root). Это возможно благодаря тому, что LINQ ищет узлы, которые мне нужны, и заменяет их на другие. Скажем, мне необходимо заменить команду Console.WriteLine на Console.Write. После этого нужно найти блок в скобках и добавить метод Console.ReadKey(). В итоге преобразованный код будет выполнять Console.Write и сразу за ним Console.ReadKey.
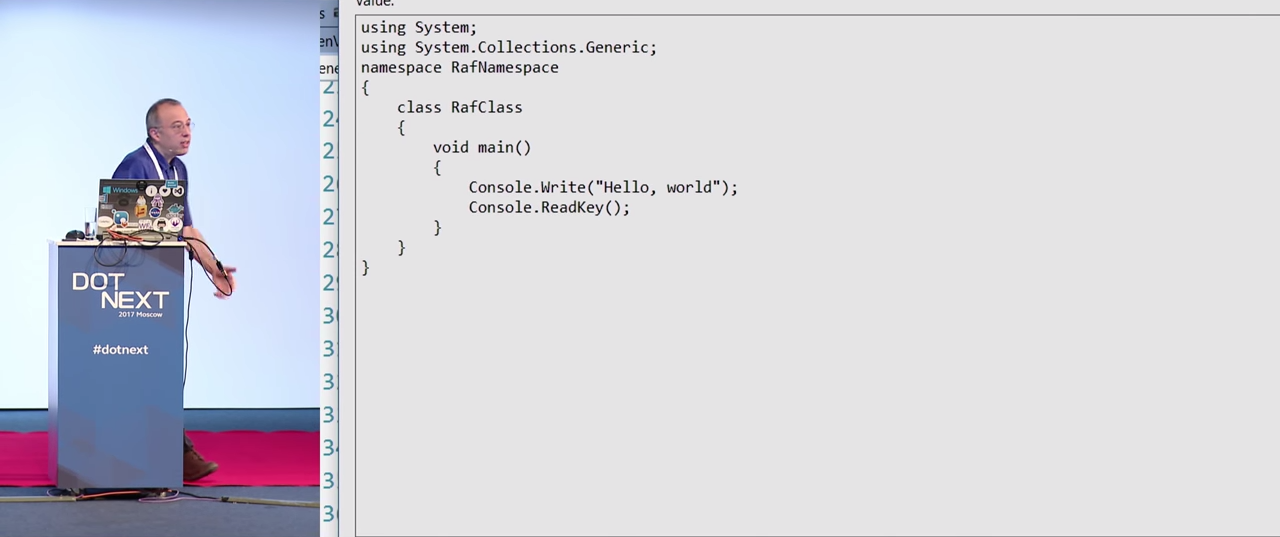
Таким образом, код можно изменять в зависимости от необходимости. Это несложно и дает огромное количество возможностей.
И еще один пример.
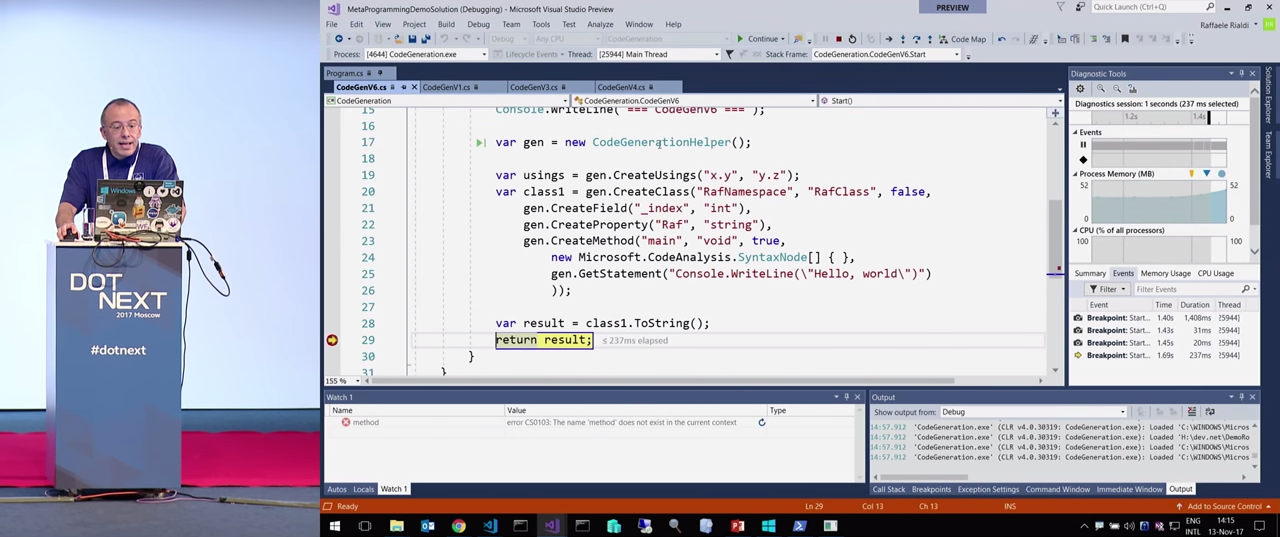
Я создал здесь высокоуровневый синтаксис, представленный объектом CodeGenerationHelper(). При помощи SyntaxGenerator можно абстрагироваться, чтобы создавать классы, их свойства и др.
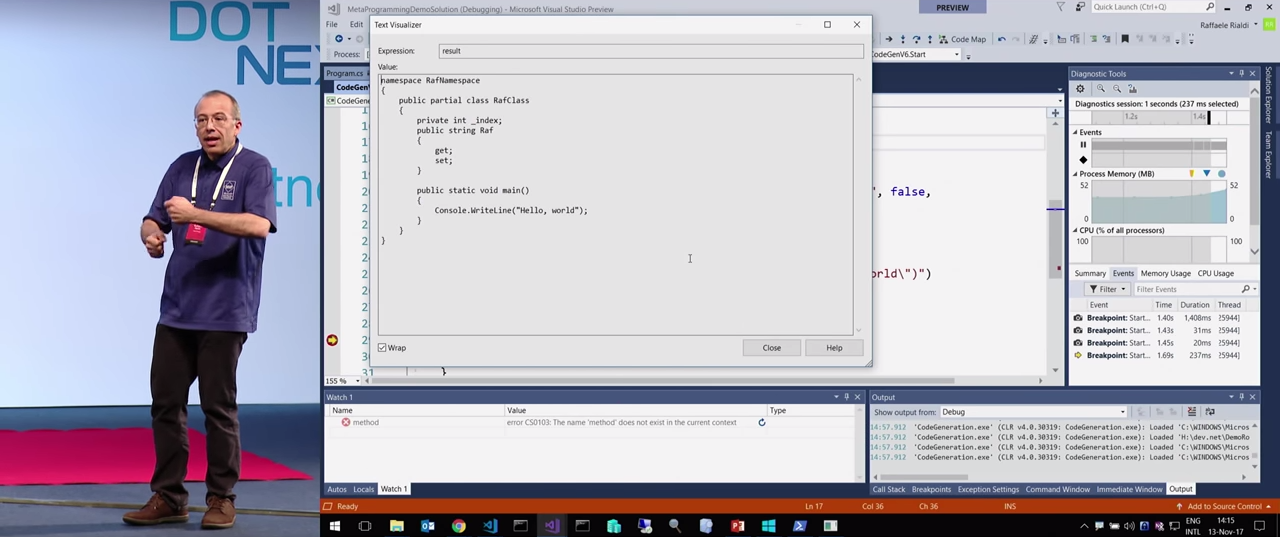
В данном примере создается POCO в качестве DTO, очень удобно.
Я хотел бы продемонстрировать вам еще один генератор, более продвинутый.

Мы все любим абстракции, не правда ли? Генератор синтаксиса, который может практически все, скорее всего, будет сложен в использовании. Для простоты его можно несколько ограничить под отдельный вариант использования. В коде вы видите два класса. В первом из них просто создаются свойства, как именно это происходит — я покажу в тесте. Но вначале я продемонстрирую работу генератора.
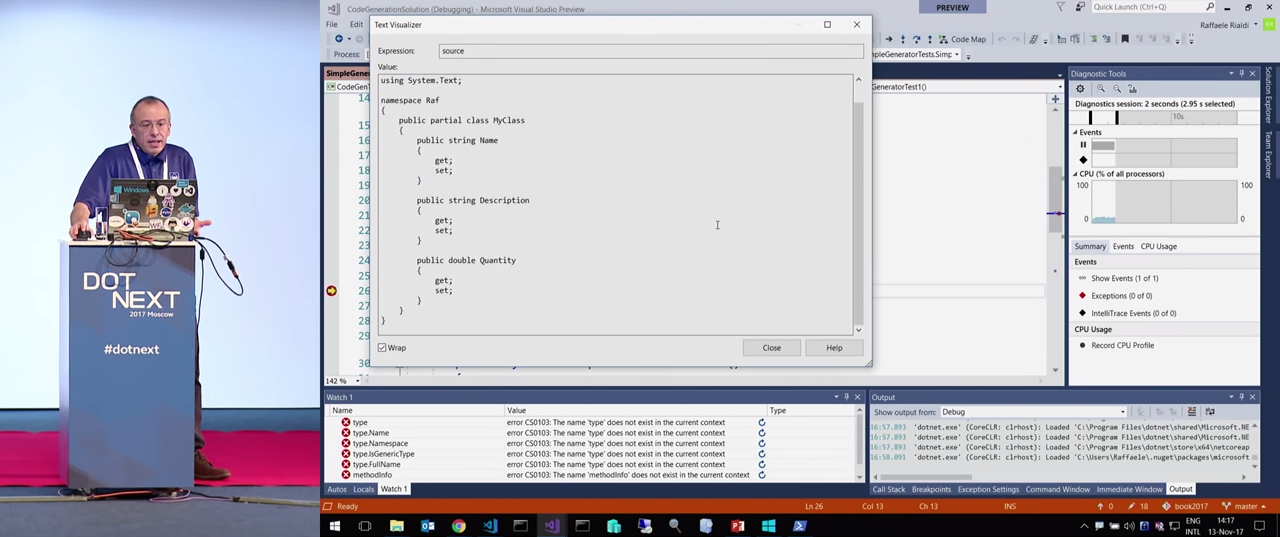
В сгенерированном коде мы видим, что создана абстракция, дающая нам ровно то, что ожидается от, к примеру, DTO. Создан очень простой класс, в котором находятся только свойства. И он имитирует тот, который я подал на вход. Итак, получилось очень полезное средство.
Во втором примере в моей абстракции делается вызов AddImplementINotifyPropertyChanged().
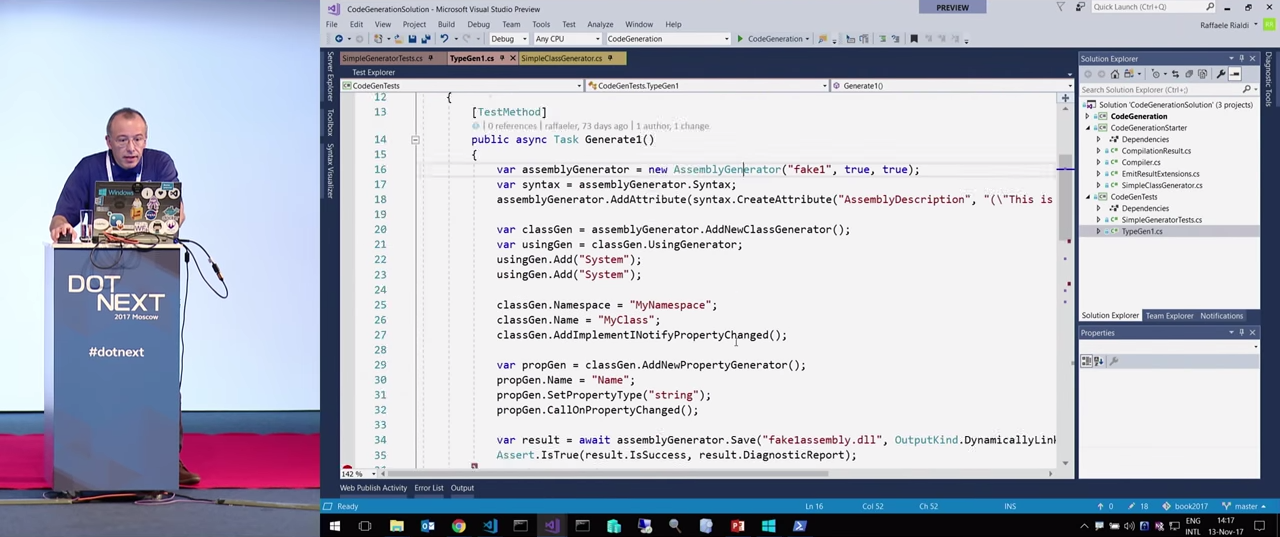
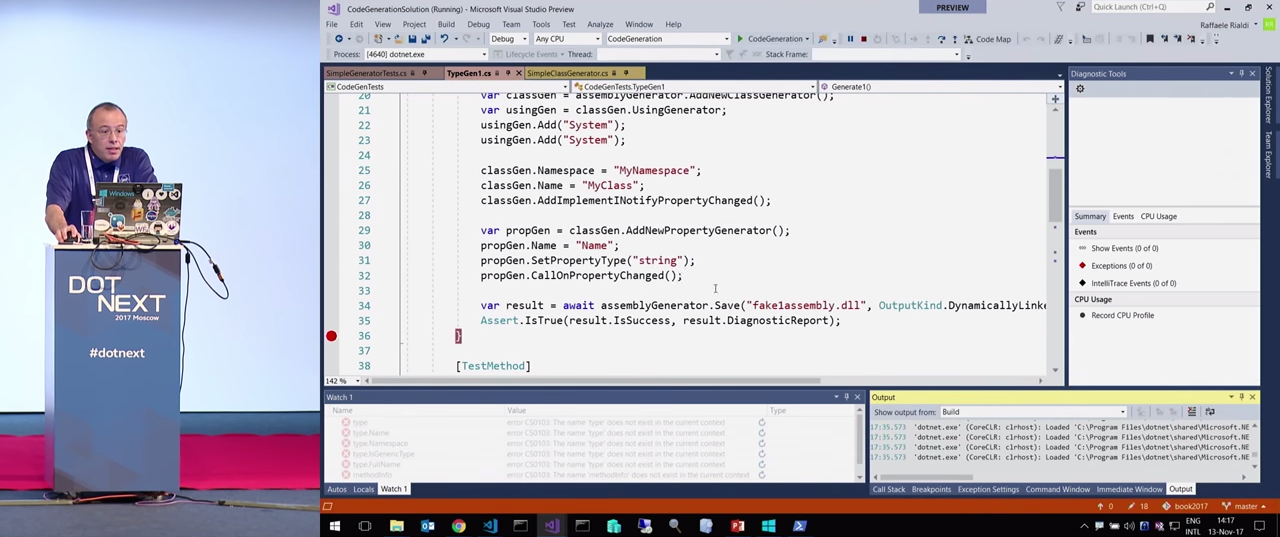
Так что, если посмотреть в визуализаторе на поле result.DiagnosticReport, мы увидим полную реализацию класса INotifyPropertyChanged.
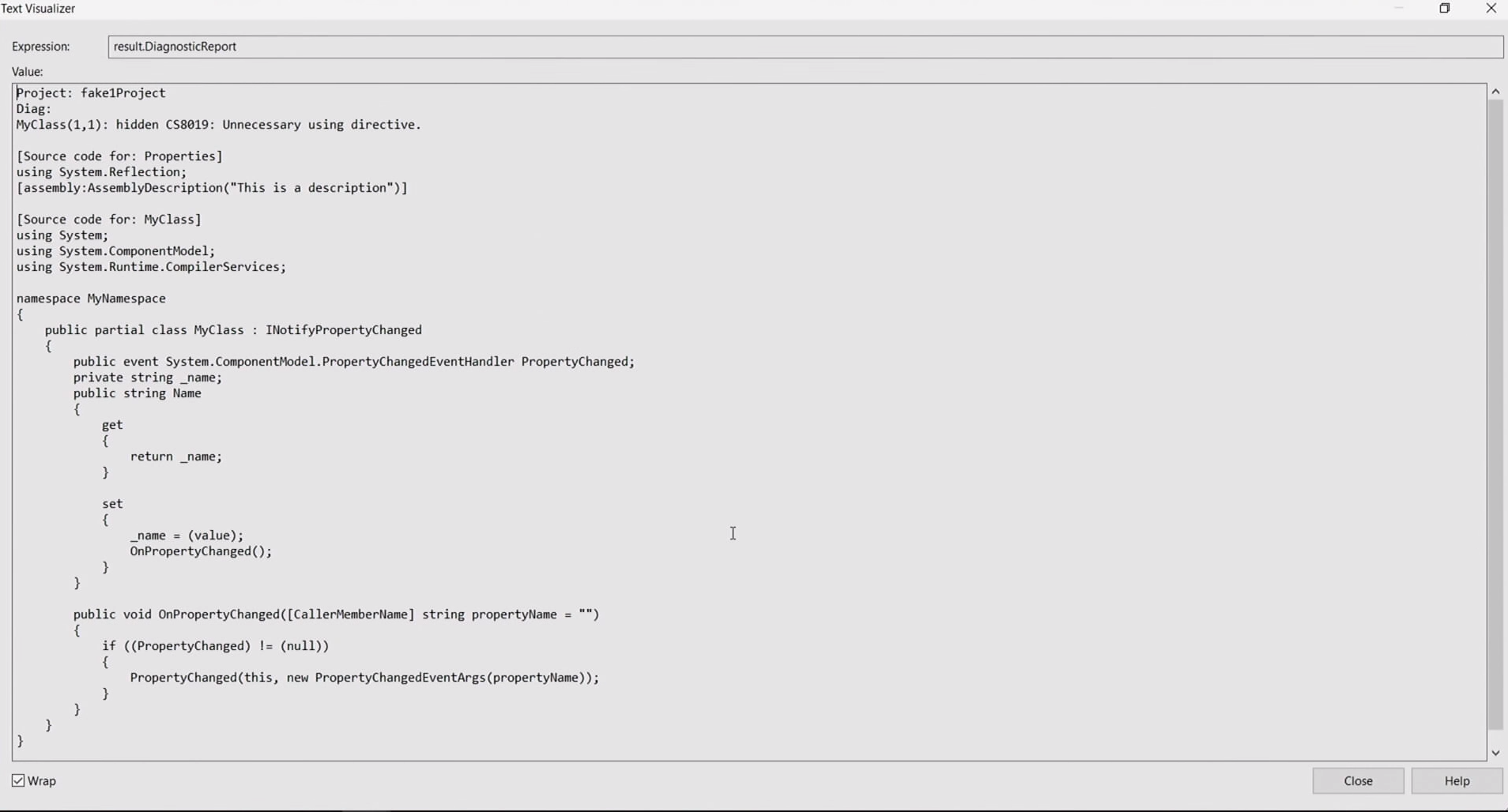
Тут есть объявление события, сеттер для string _name с вызовом OnPropertyChanged(), и реализация метода OnPropertyChanged, с [CallerMemberName] — т. е. так, как учат в руководствах. Это весьма неплохой результат. Некоторые из этих примеров я размещу на GitHub, чтобы вы могли напрямую с ними поработать.
Возникает вопрос —, а как все это волшебство происходит? Мне для этого пришлось написать достаточно много кода, как видите — в моем генераторе много классов, это просто оболочки для всех возможных действий SyntaxGenerator. Сейчас я всех их рассматривать не буду, но, если хотите, их можно обсудить позже. Кстати говоря, в наиболее простом из приведенных примеров дополнительных классов совсем немного. Посмотрим на класс SimpleClassGenerator.
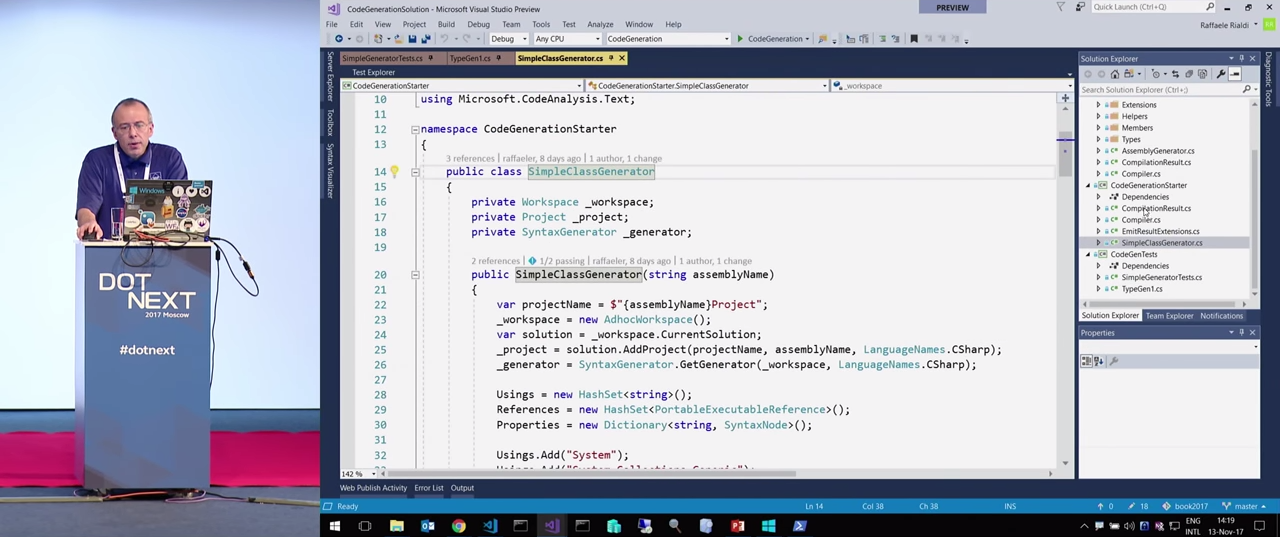
В конструкторе генерируется код, в поле HashSet хранятся нужные ссылки, например System.Runtime. Кстати говоря, большая часть продемонстрированного кода может работать и на .NET Core, и на .NET Framework, но я — поклонник .NET Core, поэтому демонстрации обычно делаю на основе него.

Возвращаясь к классу SimpleClassGenerator, там есть также словарь строк IDictionary, в котором накапливается информация о синтаксических узлах. В методе GetSource() делается вызов к другому методу того же класса, BuildClass(), в котором просто добавляются объявления классов к синтаксическим узлам.

Затем в этом методе для каждого элемента в словаре я указываю лямбда-выражение, телом которого является вызов метода CreateProperty().
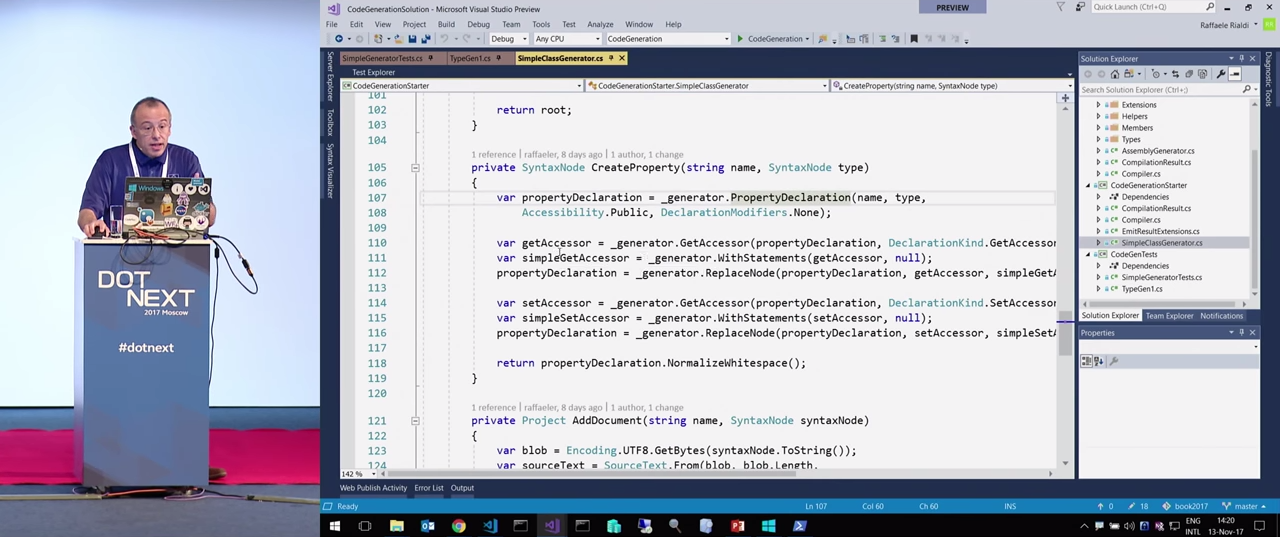
Там, в свою очередь, происходит создание тривиального свойства. Несмотря на то, что свойство тривиальное, метод получился большой. Причина этого проста. Обычно у свойств есть backfield. Чтобы сделать свойство тривиальным мне необходимо удалить часть кода и заменить его более простой аннотацией. Именно поэтому получение и указание Accessor занимает по три строчки.
Потратим последние несколько абзацев статьи на очевидный вопрос. Раз уж зашла речь о генерации кода, почему ничего не сказано об IL? Вы, наверное, представляли, что в докладе будет речь про Reflection.Emit, про ковыряние в памяти напрямую и такого рода вещи. Признаюсь, что обожаю ассемблер. Я родился с ним. Я начинал программировать на x86-ассемблере. На том этапе он действительно был нужен, была большая разница между тем, чтобы работать с переменной в памяти или с регистрами. Рассчитывать на компилятор было нельзя. Но теперь-то все иначе. Теперь нужен очень серьезный повод, чтобы обратиться к ассемблеру, а не просто желание «кодить ближе к железу». Мне-то это нравится, но это другой вопрос.
Возможность изменения кода IL может, действительно, быть очень полезной. Представьте, что есть сторонний файл .dll, и мы не знаем, что он делает. При помощи ILSpy можно открыть этот файл и посмотреть на код. Но здесь возникает знакомое ощущение: код перед глазами, но все равно непонятно, что именно будет происходить во время выполнения. Доступно огромное количество классов, которые поначалу ничего не говорят. Чтобы как-то разобраться, можно установить плагин Visual Studio для кода IL, который позволяет делать рефлексию во время выполнения и отлаживать код. Но теперь для каждого запуска нужно нажимать «F11», и после нескольких часов такой работы уже не остается терпения, а смысл кода все равно не ясен.
Есть вещи, которые в такой ситуации можно автоматизировать. Ведь, в сущности, наша работа сводится к автоматизации различных задач. Mono.Cecil — очень мощное средство. Оно позволяет извлекать инструкции, декомпилировать, фильтровать, просматривать, анализировать их содержимое, рассматривать аргументы инструкций. Представим сценарий, в котором необходимо опознать все вызовы из определенного участка кода. Похожих сценариев очень много, на GitHub много инструментов, выполняющих похожие задачи. Итак, я буду ждать вызовы и искать выполняющий их код. Но вместо того, чтобы при отладке нажимать «F11» на каждый вызов, я хочу инструментировать эт
