Где смерть Кащеева?
Привет ребят, давайте для начала проверим вашу память. Итак: «На море на океане есть остров, на том острове дуб стоит, под дубом сундук зарыт, в сундуке — заяц, в зайце — утка, в утке — яйцо» в яйце — смерть Кощея!
 А теперь, внимание, вопрос — как это формализовать? Как приатачить к яйцу иголку и какова временная сложность детача смертии моей. Как перенести сказку в быль, как это выглядит на B-деревьях и почему на самом деле нет разницы между 2D и 1D.А было все так: давным давно, в неком царстве, некотором государстве, на одном сервисе с шейрингом геолокации очень захотелось Иванушке Дурачку на уровне ЧПУ разделить Москву (/RU/MOW/) и Область (/RU/MOS/). И вообще навести порядок, чтобы все лежало по полочкам красиво и по алфавиту. Но не получалось ему сокровища свои посчитать, и аккуратно разложить. А Василису, хоть и дурак, к сбережениям не пускал.Но решение было найдено.Совсем недалеко над каким-то златом успешно чах Чахлик, еще и смерть он свою прятал по науке.И если задача определения региональной (точнее полигональной) принадлежности некой иголки к некому сундуку выходит за рамки данной статьи, то нам ничто не мешает погрузиться в глубины зайца и посмотреть как он устроен на табличном уровне.PS: и не спрашивайте почему зайца.Итак — исходная задача состоит в определении неких вхождений в некие рубрики, но давайте уточним ТЗ:
А теперь, внимание, вопрос — как это формализовать? Как приатачить к яйцу иголку и какова временная сложность детача смертии моей. Как перенести сказку в быль, как это выглядит на B-деревьях и почему на самом деле нет разницы между 2D и 1D.А было все так: давным давно, в неком царстве, некотором государстве, на одном сервисе с шейрингом геолокации очень захотелось Иванушке Дурачку на уровне ЧПУ разделить Москву (/RU/MOW/) и Область (/RU/MOS/). И вообще навести порядок, чтобы все лежало по полочкам красиво и по алфавиту. Но не получалось ему сокровища свои посчитать, и аккуратно разложить. А Василису, хоть и дурак, к сбережениям не пускал.Но решение было найдено.Совсем недалеко над каким-то златом успешно чах Чахлик, еще и смерть он свою прятал по науке.И если задача определения региональной (точнее полигональной) принадлежности некой иголки к некому сундуку выходит за рамки данной статьи, то нам ничто не мешает погрузиться в глубины зайца и посмотреть как он устроен на табличном уровне.PS: и не спрашивайте почему зайца.Итак — исходная задача состоит в определении неких вхождений в некие рубрики, но давайте уточним ТЗ:
Есть «шейринг с геолокацией» — примерно 3 миллиона точек Которые как-то «лежат» в 300 тысячах кварталов, районов и других административных делений, вложенных друг в друга. В любой момент времени требуется найти все обьекты, входящие хоть в район города, хоть в континент. В общем задача состоит в обработке неких элементов, которые привязаны к некому дереву иеархий.Начнем с простого —, а реализации рубрик, каталогов или просто деревьев. Вариантов реализации не много, точнее нормализованный вариант реализации вообще вроде один:
{
id: entity_id,
parent: parentId
}
Есть некий элемент, и у него есть один родитель (если два — уже не деревья). Это все работает хорошо до тех пор, пока нам не надо производить некоторые операции над ветками.1. Найти все подрубрики == найти все районы города
2. Найти все элементы в подрубриках == найти все обьекты города
3. Найти всех своих родителей наверх == понять в какой стране город
4. Что-то посчитать, агрегиговать, сломать или починить.
Эти проблемы актуальны и для рубрик на сайте, и файлов на диске, и вообще чисто теоритических диванных изысканий.И есть несколько стандартных решений этой проблемы: 
1. Adjacent Set (AL) — en.wikipedia.org/wiki/Adjacency_listТаблица вида child, parent[, level], где просто указаны все родители нужного ребенка. Сколько родителей — сколько и записей.Это самый простой и самый «нормализованный» вариант. Абсолютно удобен, но может подавать на «выход» очень большие «облака» и генерировать километровые «кишки» таблиц. Из-за большого размера и размазанности работает, в общем, не моментально.
2. Materialized Path (MP)Это когда мы берем всех своих родителей и «материализуем» в одну строчку через запятую. А потом можем использовать оператор LIKE для поиска нужного.В принципе нормальный вариант, любимый студентами. Особенно хорош если перейти от основания 10, в том числе обычной строки, на чуть более бинарный (base32,64,92 или 254).Минус только один — не технологично, да и индексы в произвольном месте строки работают не очень красиво.PS: есть и технологичные решения — так называемые матричные деревья, когда ID узла это матрицы, а положения элементов — детерминанты их перемножения. С учетом некоммутативности умножения ключик получается реальным. Если после прочтения этого абзаца вы подумали про Жесть — так оно и есть.
3. Nested set (NS).Nested set table — это такая чтука про которую многие слышали, но мало кто знает как она работает и почему. Для многих NS — это такой плагинчик или библиотечка, которой можно пользоваться. А разбираться — влом.
Но именно этим и будем разбираться, потому что Nested set table (http://en.wikipedia.org/wiki/Nested_set_model) это:  1. Одна из материализаций skip-list
2. Одна из материализаций B-tree
3. В прямом переводе просто — вложенные интервалы
4. Они совсем не страшные.
5. Обеспечивают линейное хранение.
6. И они именно то, что нам нужно
Отличие от «обычных» child-parent схем заключается в том, что некий parent содержит два неких «числа» — начало своего интервала, и конец. А все его дети содержат «числа» где-то между этими значениями. Визуализировать можно по разному, в Википедии можно найти несколько страшных вариантов деревьев. Но если взять обычное дерево, разделить по уровням и нарисовать на бумажке — получатся списки с пропусками.
1. Одна из материализаций skip-list
2. Одна из материализаций B-tree
3. В прямом переводе просто — вложенные интервалы
4. Они совсем не страшные.
5. Обеспечивают линейное хранение.
6. И они именно то, что нам нужно
Отличие от «обычных» child-parent схем заключается в том, что некий parent содержит два неких «числа» — начало своего интервала, и конец. А все его дети содержат «числа» где-то между этими значениями. Визуализировать можно по разному, в Википедии можно найти несколько страшных вариантов деревьев. Но если взять обычное дерево, разделить по уровням и нарисовать на бумажке — получатся списки с пропусками.

 А взмахом палочки эта картинки превращается в B-tree. Потому что разницы, идеалогически, нет.В неком роде nested-set адресацию можно считать неким «space filling curve», некой кривой которая неразрывно рекурсивно пересекает все элементы некого дерева в порядке обхода.Если начальный интервал задать в 0–1, потом разделить в точке ½, а потом ¼,2/4,¾,8/16,50/128… то получится, что любой студент, который на первом курсе пытался вкурить в пределы и сходящиейся последовательности — курил мою траву. Хотя на самом деле это называется Дерево Штерна — Броко
А взмахом палочки эта картинки превращается в B-tree. Потому что разницы, идеалогически, нет.В неком роде nested-set адресацию можно считать неким «space filling curve», некой кривой которая неразрывно рекурсивно пересекает все элементы некого дерева в порядке обхода.Если начальный интервал задать в 0–1, потом разделить в точке ½, а потом ¼,2/4,¾,8/16,50/128… то получится, что любой студент, который на первом курсе пытался вкурить в пределы и сходящиейся последовательности — курил мою траву. Хотя на самом деле это называется Дерево Штерна — Броко Для многих cамое сложное в NS это их построение. Многих людей сразу пугают эти left/right/st и другие страшные слова и картинки употребляемые на различных сайтиках.На самом деле NS это просто интервалы, просто утверждение что детей можно найти где-то в коридоре значений родителей. Это не деревья, это числа, которые хранятся в плоских таблицах базы данных. Непрерывный ряд на числовой кривой.
Для многих cамое сложное в NS это их построение. Многих людей сразу пугают эти left/right/st и другие страшные слова и картинки употребляемые на различных сайтиках.На самом деле NS это просто интервалы, просто утверждение что детей можно найти где-то в коридоре значений родителей. Это не деревья, это числа, которые хранятся в плоских таблицах базы данных. Непрерывный ряд на числовой кривой.
В итоге строить NS можно проще: Вариант 1:
В базе данных считаем количество своих детей (COUNT (id)), а потом количество этого количества (count (count)). Таким образом «методом пузырька» полна емкость поднимается наверх. Остается только найти своего соседа, и как-то взять у него офсет — полную емкость его соседов левее.Это 4 SQL запроса, некоторые из которых надо выполнить пару раз.
Вариант 2:
Преобразуем наше дерево в matpath, сортируем через strnatsort и подвешиваем некий auto_incriment на этот порядок. Числовая кривая готова. Остается только найти своего соседа (например справа), и использовать его «число» как правую границу.
В обоих случаях вставка и удаление — O (n), а иногда и O (1).NS это просто два числа, интервал между «булками» которого спрятано все самое вкусное. В общем случае кривая не обязана состоять из целых чисел, более того отлично ложится на дроби. Берем уже упомянутого Штерна — Броко и получаем кривую Коха.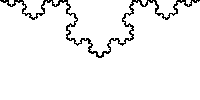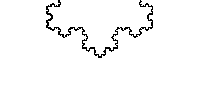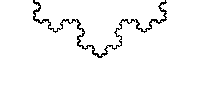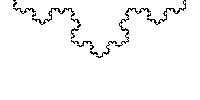
Надеюсь вы дочитали до этого момента, поняли что такое Вложенные Интервалы, осталось понять чем же они так хороши.Представим что у вас есть список всех отелей Hotellook (Aviasales). Представим что у вас есть привязка этих отелей в странам-регионам-городам-районам. Задача — найти все отели в Орехово-Борисово Южное (узкая выборка), все 5-ти звездочные отели Турции (большая выборка), и все отели в квадрате 100 метров от вас.
Решение ситуации 1:
WHERE hotels_to_regions_ns.id between ns.left and ns.right Решение ситуации 2:
WHERE hotels_to_regions_ns.id between ns.left and ns.right В том и секрет — никакой разницы нет. И в обоих случаях работает быстро.Решение ситуации 3 подразумевает некий координатный поиск. Но в обычных БД это очень сложная и дорогая операция — поиск по двойному ключу, или же по 2D (spatial) ключу — просто сложно, дорого и генерируется много чтений из разных мест диска. Ну просто потому что порядок хранения данных на диске 1D.Но решение ситуации остается почти что тем же самым:
WHERE hotels_to_mortoncode.z between ns.zleft and ns.zright Где мы используем Morton, он же Z-curve code для конвертации 2D координат в 1D кривую (об этом пару раз писалось на хабре), а потом сохраняем ее в кодах Грея (два бита на одно деление) и можем делать быстрые выборки по пирамиде (привет ObjectManager).Для многих не совсем понятно почему выборки быстрые — следует наверное пояснить. Morton коды, кроме того что являются «адресацией по quadtree» обладают еще одним свойством — коды для обьектов, которые рядом, будут рядом. maps multidimensional data to one dimension while preserving locality of the data points
Z — не самое удачное решение, но отлично подходит для быстрых выборок групп (тайлов) обьектов. Z-коды «держат» локальность данных, в том числе для обьектов одной ноды коды будут вообще одинаковые, или их вариативность будут зажата между left и right значениями элемента NS.Плюс — NS, как я уже говорил — некая материализация skip-листов, числовой кривой или даже B-деревьев. Технически разницы нет. Так что, когда вы храните данные в NS вы храните их в B-tree… то… подождите…
 В общем Z, Hilbert, GeoHash (Z коды в base64) и компания — это те же яNestedSet, вид с боку.Эти коды часто используются в различных GIS системах, в том числе Bing называется их quad-code и использует для адресации тайлов, и все этого без проблем работает и в 3D и в 4D пространстве.Сводя задачки в простую числовую кривую.И в стандартный NestedSet.Эффект всегда один — все начинает работать.
В общем Z, Hilbert, GeoHash (Z коды в base64) и компания — это те же яNestedSet, вид с боку.Эти коды часто используются в различных GIS системах, в том числе Bing называется их quad-code и использует для адресации тайлов, и все этого без проблем работает и в 3D и в 4D пространстве.Сводя задачки в простую числовую кривую.И в стандартный NestedSet.Эффект всегда один — все начинает работать.
Вот и сказочке конец, а кто слушал — молодец.
PS: С вами были kashey и esosedi, которые уже почти 7 лет используют NS и Z коды для выборки обьектов на карту. В число которых попали и отели HotelLook (это которые special.habrahabr.ru/aviasales/).PPS: Вступайте в ряды Фурье — сходимость! Равенство! Гильбертово пространство! PPPS: И не забывайте про мудрость веков!
