Гайд по эвент-сорсингу
Считается, что эвент-сорсинг это просто паттерн работы с данными, но применение эвент-сорсинга на деле приводит к большому числу изменений в дизайне приложений. К тому же, сделать эвент-сорсинг правильно не так просто, с одной стороны потому, что нужно заранее ответить на большое количество вопросов, а с другой нужно знать на какие вопросы отвечать.
В этой статье попробую рассказать о том, что такое эвент-сорсинг, как он меняет дизайн приложений, постараюсь подсветить те вопросы, которые нужно учесть при проектировании и ещё поделюсь примером системы из двух приложений, написанных с применением эвент-сорсинга.
Пример системы
Начну сразу с примера системы. Система состоит из двух сервисов, оба написаны с применением эвент-сорсинга.
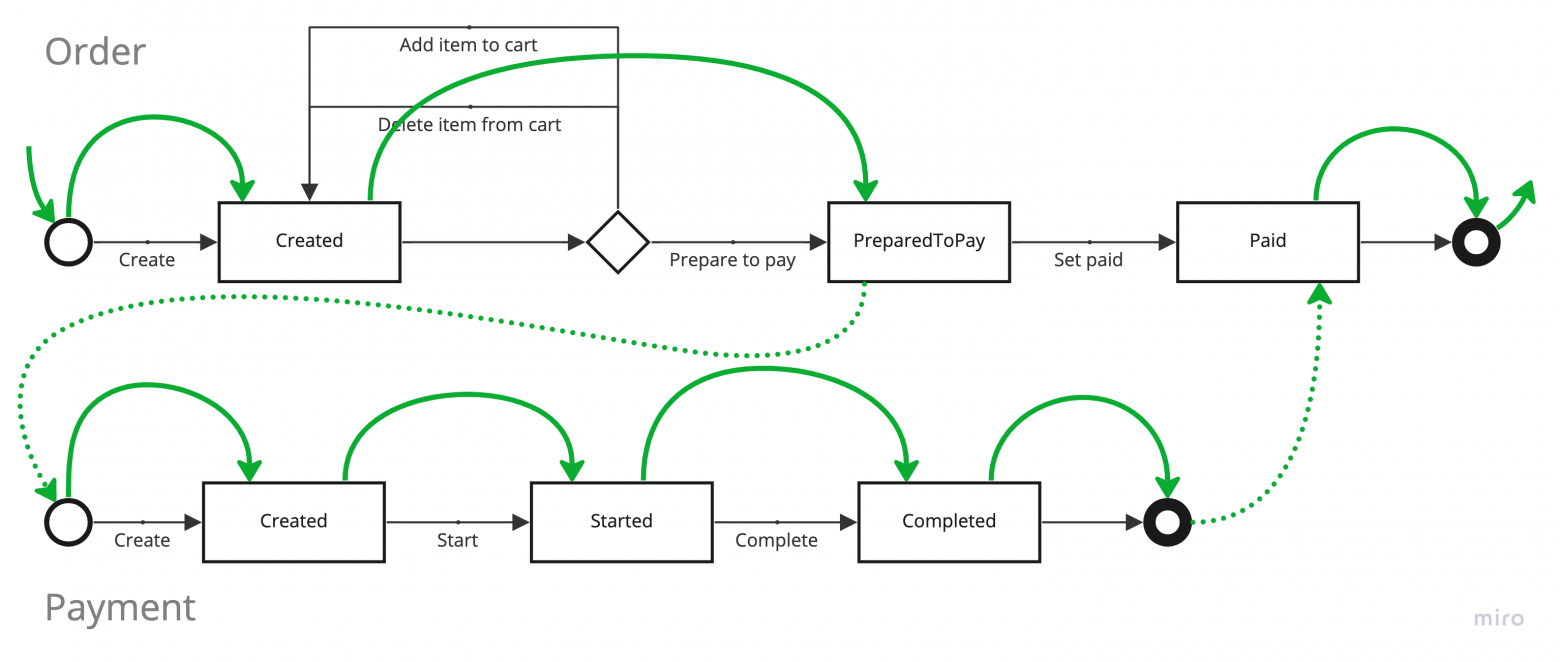
Первый сервис отвечает за проведение платежей. Так выглядит стейт-машина воображаемого платежа.
 1. Стейт-машина платежа
1. Стейт-машина платежа
Второй сервис отвечает за проведение заказов. Заказ представлен такой стейт-машиной.
 2.Стейт-машина заказа
2.Стейт-машина заказа
Предполагается, что для заказа необходима оплата, поэтому сервисы взаимодействуют друг с другом. Флоу заказа с учетом необходимости оплаты выглядит так.
 3. Флоу заказа целиком
3. Флоу заказа целиком
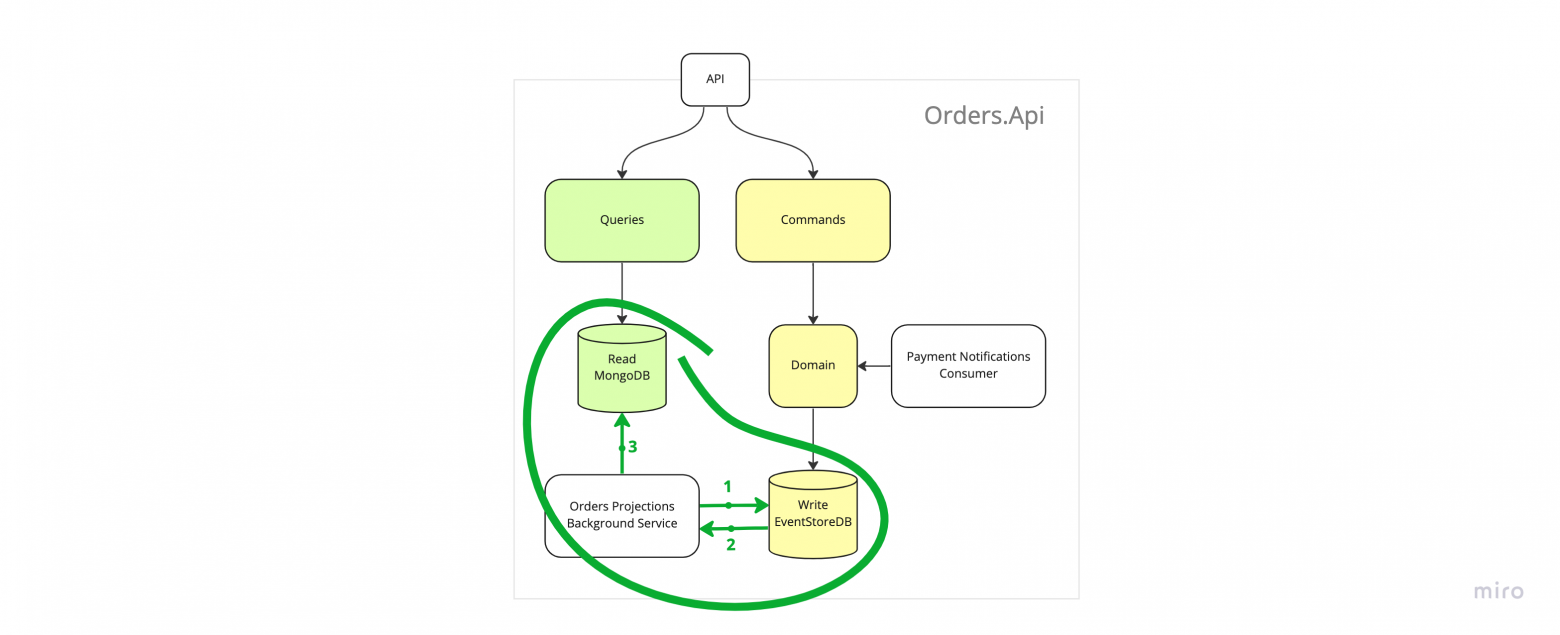
А так система выглядит на уровне компонентов.
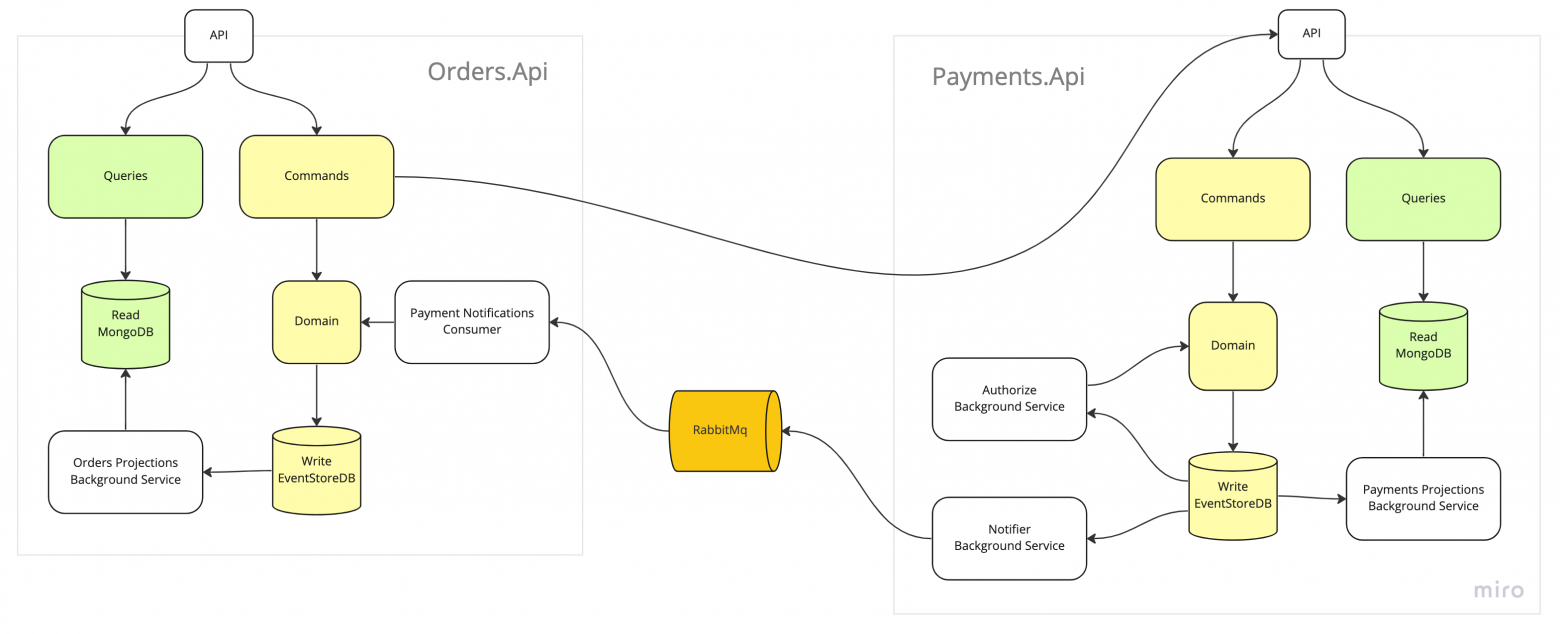 4. Система на уровне компонентов
4. Система на уровне компонентов
Это игрушечный пример, поэтому тут не будет обработки ошибок или сложной логики, но я постарался сделать пример таким, чтобы все его компоненты выглядели и работали как в реальном мире. В частности, я использовал настоящие базы данных, сделал подписки и интегрировал приложения через шину и АПИ. Можно было бы интегрировать только через шину, но для пример использовал два механизма.
Код приложений находится тут, там же есть e2e-тест, который создает и оплачивает заказ в соответствии с алгоритмом выше. Приложения докеризированы и в репозитории есть докер-компоуз файл, который позволяет без лишних сложностей собрать и запустить систему для того, чтобы поразбираться как и что работает. Команды для запуска в разных вариациях в ридми.
Смотреть и запускать код совершенно не обязательно, просто знайте, что такая возможность есть. Если всё же пойдёте смотреть — рекомендую обратить внимание на то, как выглядят эвенты и агрегаты, как используются эвенты для восстановления состояния агрегатов и как выглядят обработчики эвентов.
По ходу статьи я буду ссылаться на некоторые части системы, поэтому пробегитесь хотя бы по картинкам!
Что такое эвент-сорсинг
Теперь давайте разбираться что такое эвент-сорсинг. Цель главы — понять основные составляющие и выделить термины.
Оттолкнёмся от определения из статьи майкрософта. Да и, в целом, вся статья неплохая, рекомендую к прочтению, но только после моей!
Instead of storing just the current state of the data in a domain, use an append-only store to record the full series of actions taken on that data. The store acts as the system of record and can be used to materialize the domain objects. This can simplify tasks in complex domains, by avoiding the need to synchronize the data model and the business domain, while improving performance, scalability, and responsiveness. It can also provide consistency for transactional data, and maintain full audit trails and history that can enable compensating actions.
Ссылка: https://learn.microsoft.com/en-us/azure/architecture/patterns/event-sourcing
Объяснять буду на примере сервиса заказов.
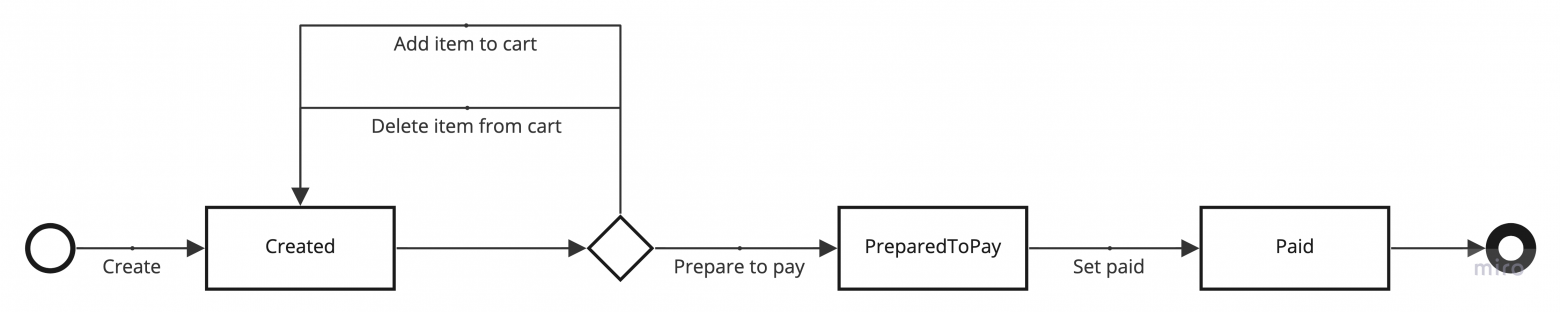 5. Стейт-машина заказа
5. Стейт-машина заказа
Основная идея эвент-сорсинга заключается в том, что нужно хранить состояние системы в виде упорядоченного неизменяемого лога возникающих в системе событий вместо того, чтобы хранить его в виде снимков состояний объектов.
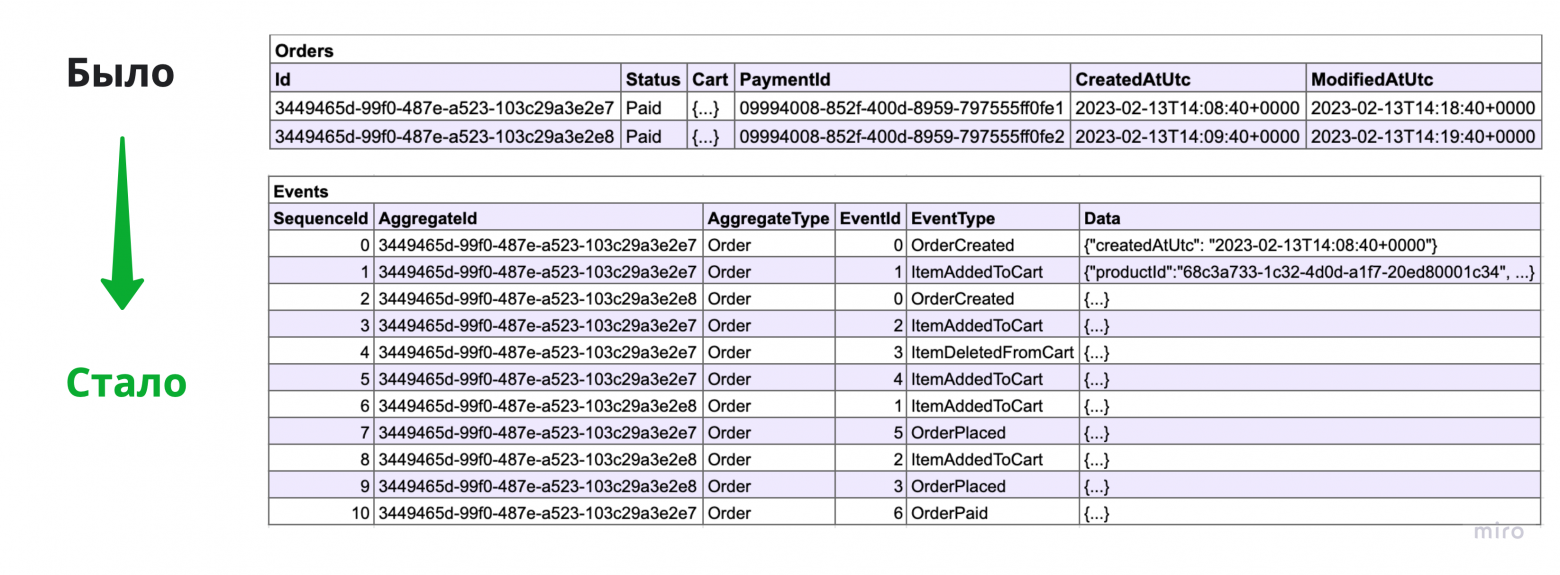 6. От снимков состояний к событиям
6. От снимков состояний к событиям
Когда состояние системы хранится в виде снимков состояния — состояние объекта в системе представлено изменяемой строкой или строками в базе данных. При обновлении состояния объекта мы перезаписываем строку новыми значениями.
Когда применяется эвент-сорсинг — состояние хранится в виде последовательности неизменяемых событий. При обновлении состояния объекта нужно сохранить новые события не меняя старые.
Событие в эвент-сорсинге это набор данных описывающий некоторый факт реального мира, когда событие уже произошло, как и в реальном мире, оно уже не может измениться.
В коде это некоторый неизменяемый объект, пример.
 7. Стрим
7. Стрим
Последовательность событий относящихся к одному объекту называют стримом. События внутри стрима должны быть упорядочены всегда для того, чтобы можно было их считать, применить в порядке возникновения и таким образом восстановить состояние объекта.
Стрим в коде удобно представить в виде DDD-агрегата, потому что стрим как и DDD-агрегат образует границу согласованности данных.
An Event Stream is a list of Events that form a consistency unit that you might call an aggregate if you practice Domain-Driven Design or otherwise an entity, business object, …
Ссылка: https://itnext.io/event-sourcing-explained-b19ccaa93ae4#:~: text=An Event Stream is a, keep it simple for now
 8. Лог
8. Лог
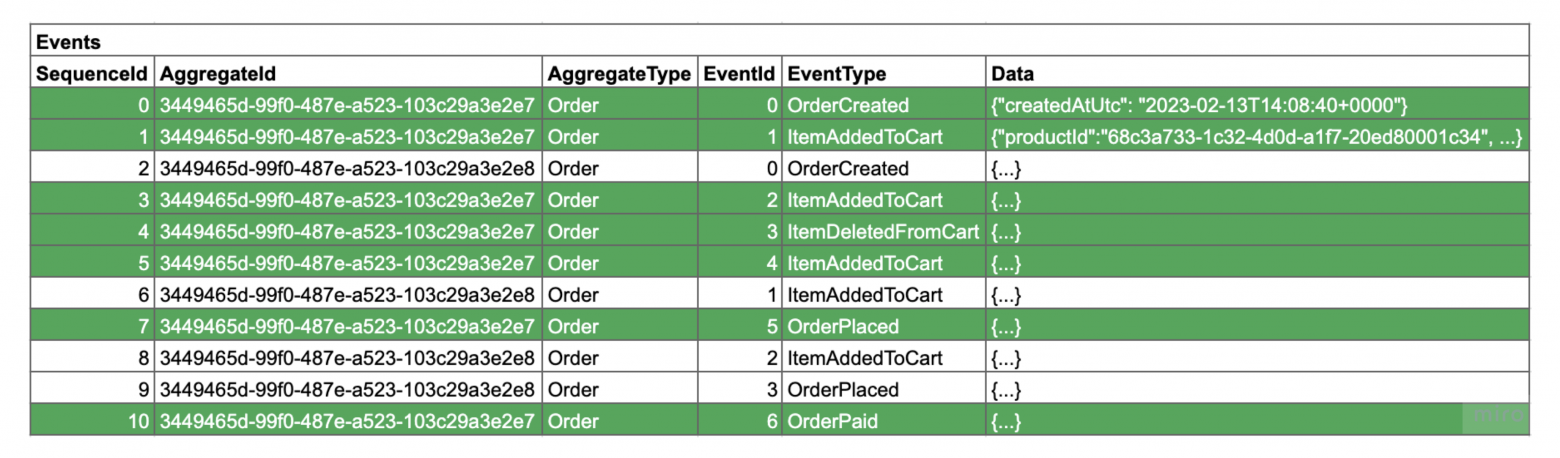
Пару слов о том, как события хранятся в базе данных. Возможны разные варианты, в зависимости от требований к системе, нагрузки и прочего, но в самом простом случае, все события хранятся в некоторой append-only таблице и глобально-упорядочены. Эту таблицу также называют логом.
 9. Эвент-стор
9. Эвент-стор
Базу данных, в которой хранятся логи, обычно называют эвент-стором. Эвент-стором может быть не каждая база данных, а только такая, которая предоставляет необходимые возможности для работы с данными. Для примера, нам нужна упорядоченность данных, возможность чтения отдельных стримов, возможность чтения событий в логе по порядку. На самом деле набор требований не определен строго и может варьироваться в зависимости от требований к системе. Подробно поговорим об эвент-сторах чуть позже.
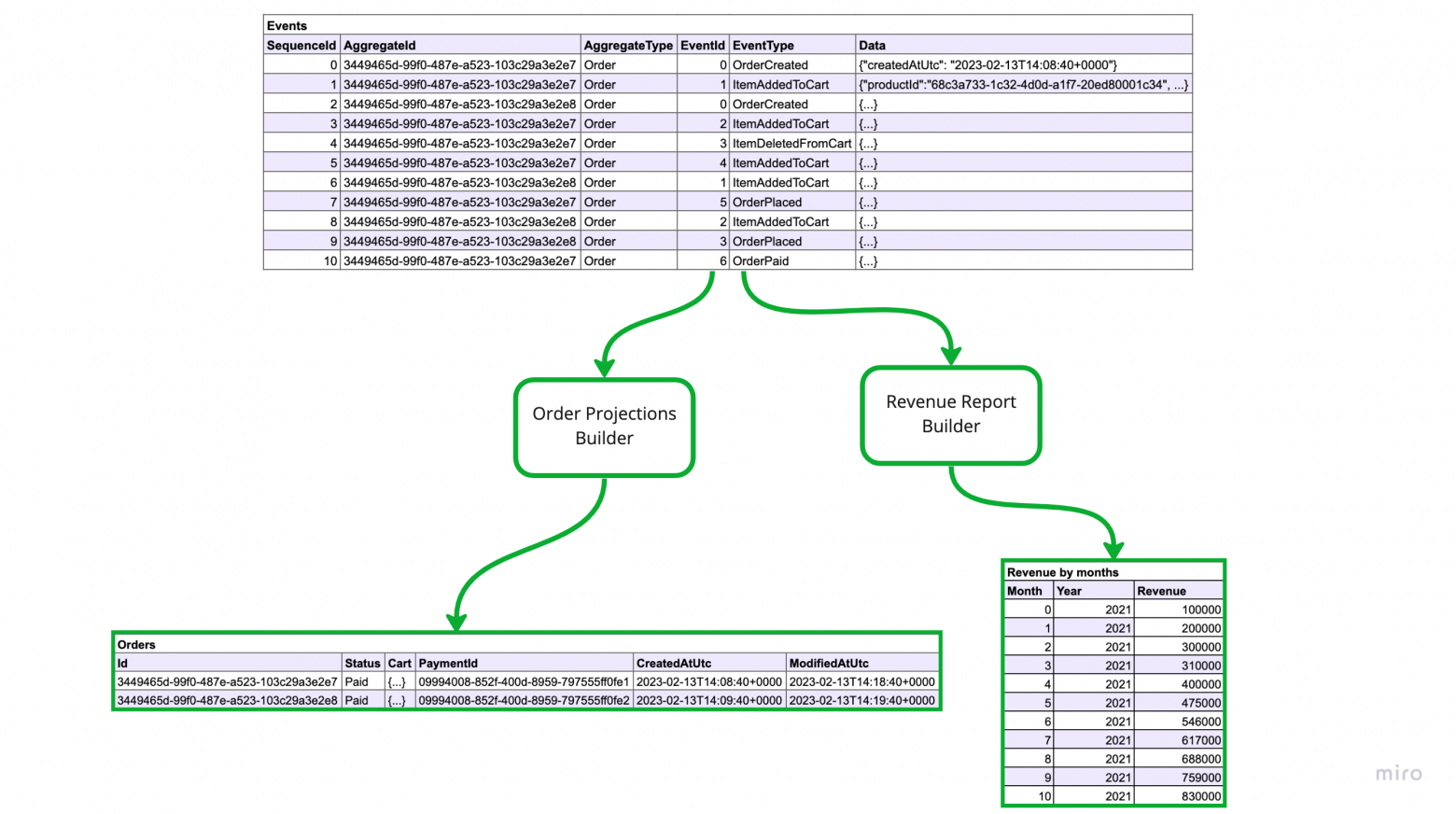
Одно из перечисленных выше требований — возможность чтения событий в логе по порядку или подписки — является самой главной фичей, которую даёт нам эвент-сорсинг и без него он просто теряет смысл. С помощью этого механизма мы можем строить проекции, а так же выполнять фоновую работу, например, делать вызовы сторонних сервисов. Также этот механизм заменяет транзакции.
 10. Лог
10. Лог
Начнем с проекций.
Проекции или как их ещё называют материализованные представления это состояние объекта или объектов в оптимизированном для чтения виде. В оптимизированном для чтения значит, что данные для обработки некоторого [get-]запроса подготовлены заранее и для их получения не требуется выполнения сложных операций, в частности, не нужно восстанавливать состояние объекта из стрима событий, а так же не нужно делать серии вызовов для того, чтобы получить все нужные для обработки запроса данные.
Примерами проекций могут быть снимки состояний объектов, отчеты и другие данные, которые необходимо показать на UI. К слову, если захочется сделать какой-то джоин (join), то сделать это можно будет только с помощью проекций, события джойнить сложновато :-)
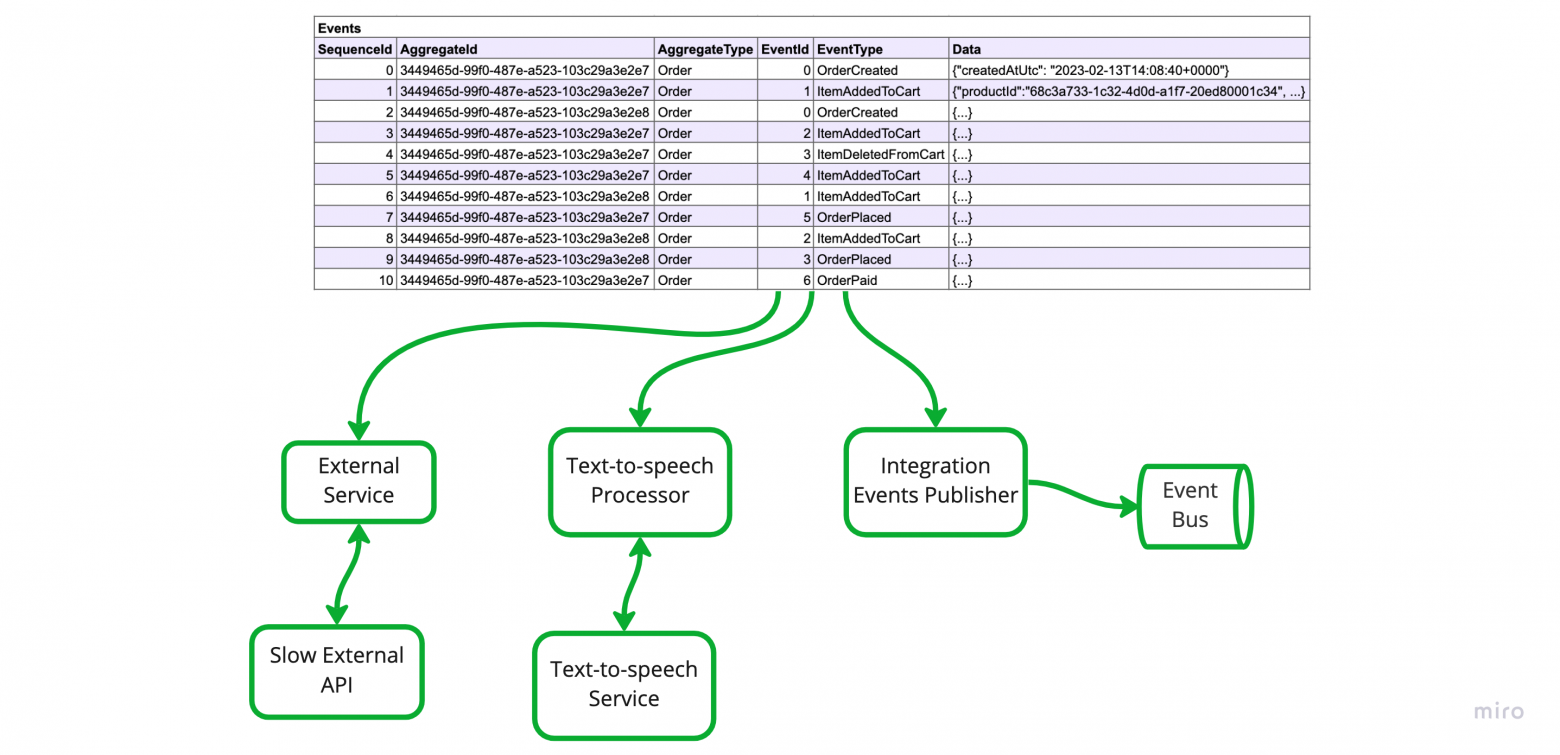 11. Фоновая работа
11. Фоновая работа
Теперь про фоновую работу.
Под этой фразой я понимаю запрос к некоторому внешнему сервису, который потребляет много ресурсов, CPU или времени — обращение к модулю text-to-speech или публикация интеграционных эвентов в шину, всё что угодно, что не относится напрямую к обработке текущего запроса. Имея возможность подписки на новые события, становится возможным выполнять эти задачи асинхронно, реактивно и в фоне, что делает нашу систему более отзывчивой и более контролируемой.
Я думаю вы уже догадались зачем нужно чтобы эвенты были упорядоченными, но проговорю на всякий случай. Порядок эвентов нужен, чтобы мы могли обрабатывать их всегда в одном и том же порядке порядке и могли хранить оффсеты уже обработанных записей.
 12. Оффсеты
12. Оффсеты
Концептуально обработка эвентов в фоне выглядит так же как в кафке, концепции буквально те же, лог = топик, партиции = шарды, консьюмер группы и консьюмеры даже можно называть так же.
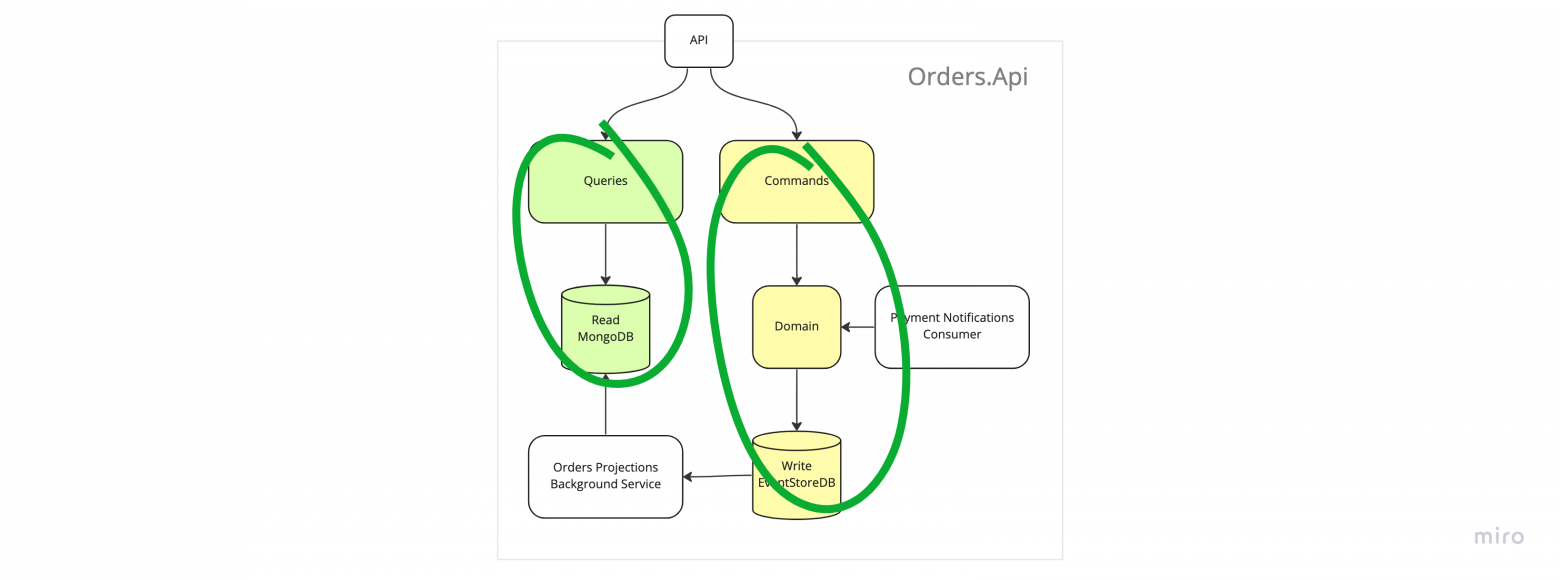 13. Обработка эвентов в фоне как в кафке
13. Обработка эвентов в фоне как в кафке
Мы можем добавлять новых консьюмеров на события в любое время, и так как мы храним все данные, мы можем обрабатывать события с нужного нам момента, с самого первого эвента в системе или с текущего момента, например.
Что касается транзакций.
Фоновая обработка эвентов избавляет нас от необходимости в транзакциях. Вообще, транзакции нужны для того, чтобы обеспечить консистентность данных. В случае когда мы используем транзакции мы имеем строгую консистентность (strong consistency), т.е. когда база данных нам отвечает ОК, это значит что все объекты изменились и все изменения записаны. В случае с эвент-сорсингом мы имеем консистентность в конечном счете (eventual consistency), но за то наша система становится отзывчивой, задачи очень хорошо отделяются друг от друга, что делает код проще и надёжнее.
Вкратце, это вся теория.
Влияние на архитектуру приложения
Как я сказал в начале, эвент-сорсинг влияет на архитектуру приложения. В моём понимании, влияние положительное, так как система становится более понятной за счет четкого распределения ответственности в коде и прозрачной работы с данными. Далее перечислю за счет чего.
Command Query Responsibility Segregation
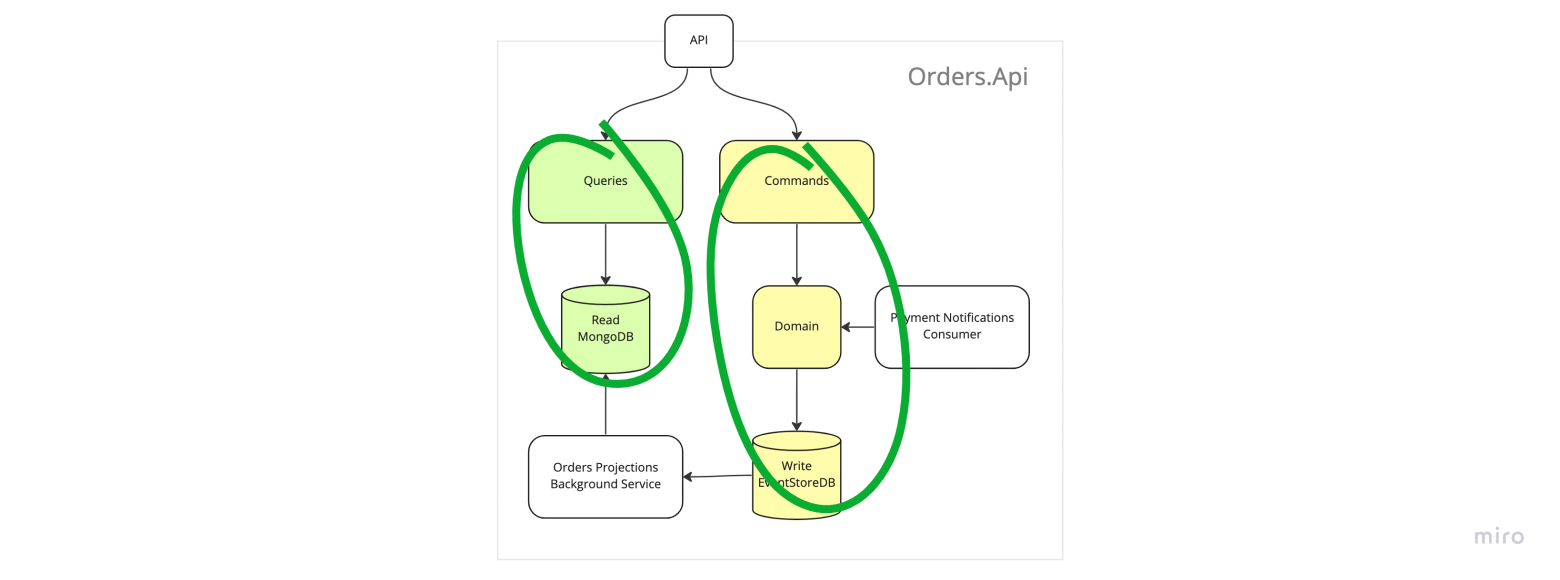 14. CQRS
14. CQRS
Следствием того, что в приложении с применением эвент-сорсинга нет транзакций, но есть проекции является то, что в таких приложениях изначально логически разделены модели данных для чтения (read) и для записи (write). По-сути, CQRS.
Domain Driven Design
Как я сказал выше, очень удобно моделировать стрим в коде в виде DDD-агрегата. Обе сущности определяют границу транзакционности, что играет нам на руку. К примеру, я привык моделировать агрегат в коде таким образом, чтобы он умел порождать новые эвенты, и восстанавливать свое состояние из потока эвентов. Примерно такая имплементация мне по душе. В более сложных кейсах ответственность можно поделить таким образом, чтобы логика была в одном классе, а состояние в другом.
Фоновая обработка
 15. Тяжелые операции смещаются в фоновые сервисы
15. Тяжелые операции смещаются в фоновые сервисы
Имея механизм подписок становится просто вынести обработку тяжёлых операций из обработчиков запросов в фоновые сервисы. Это позитивно влиеяет на отзывчивость системы, а так же даёт больше контроля над нагрузкой.
Акторы
На самом деле акторы не обязательно использовать, но на мой взгляд акторы очень естественно выглядят как обёртка над агрегатами. В дотнете особенно удачным решением выглядит фреймворк orleans и их концепция виртуальных акторов.
Использование акторов поможет оптимизировать нагрузку на базу данных, за счет того, что данные будут находиться в памяти и их не нужно будет перечитывать для обработки каждого запроса. Так же акторы снижают нагрузку на базу данных за счет уменьшения проблем связанных с конкаренси. Это применимо как для write так и для read нагрузки.
Что ещё стоит знать
В этом разделе я собрал вопросы, в которых точно стоит разобраться до того, как применять эвент-сорсинг.
Чем отличаются эвенты от команд
Основная идея, которая стоит за словом эвент в эвент-сорсинге заключается в том, что это набор данных описывающих событие, которое уже произошло. Эвент появляется в результате работы некоторого кода, например, выполнения команды. После того, как эвент создал он не примениться к агрегату только в случае ошибок в коде, других причин быть не должно логически, в частности, неправильно делать валидации с точки зрения доменной логики при восстановлении состояния агрегата из базы данных.
Команда же это описание некоторого задания. Концептуально, команда это объект у которого есть состояние — она может обрабатываться в данный момент, может быть выполнена и может иметь результат. Команда в результате работы может менять агрегаты, что приведет к возникновению новых эвентов.
Ещё есть такая концепция как команд-сорсинг. Суть заключается в том, чтобы хранить команды, которые исполняет система, для того, чтобы иметь возможность проиграть их заново. В результате такого воспроизведения мы получим другое (новое) системы. В эвент-сорсинге же мы храним состояние и можем воспроизводить одно конкретное состояние в разные моменты времени. Почитать ещё про команд-сорсинг можно тут.
Как скейлить допустимую read нагрузку
Представим, что у есть система, которая:
состоит из одного НЕшардированного лога
в рамках шарда эвенты упорядочены
есть обработчик, который обрабатывает эвенты последовательно 0, 1, 2, 3…
обработчик сохраняет свой оффсет, чтобы после перезапуска продолжить обработку с места остановки
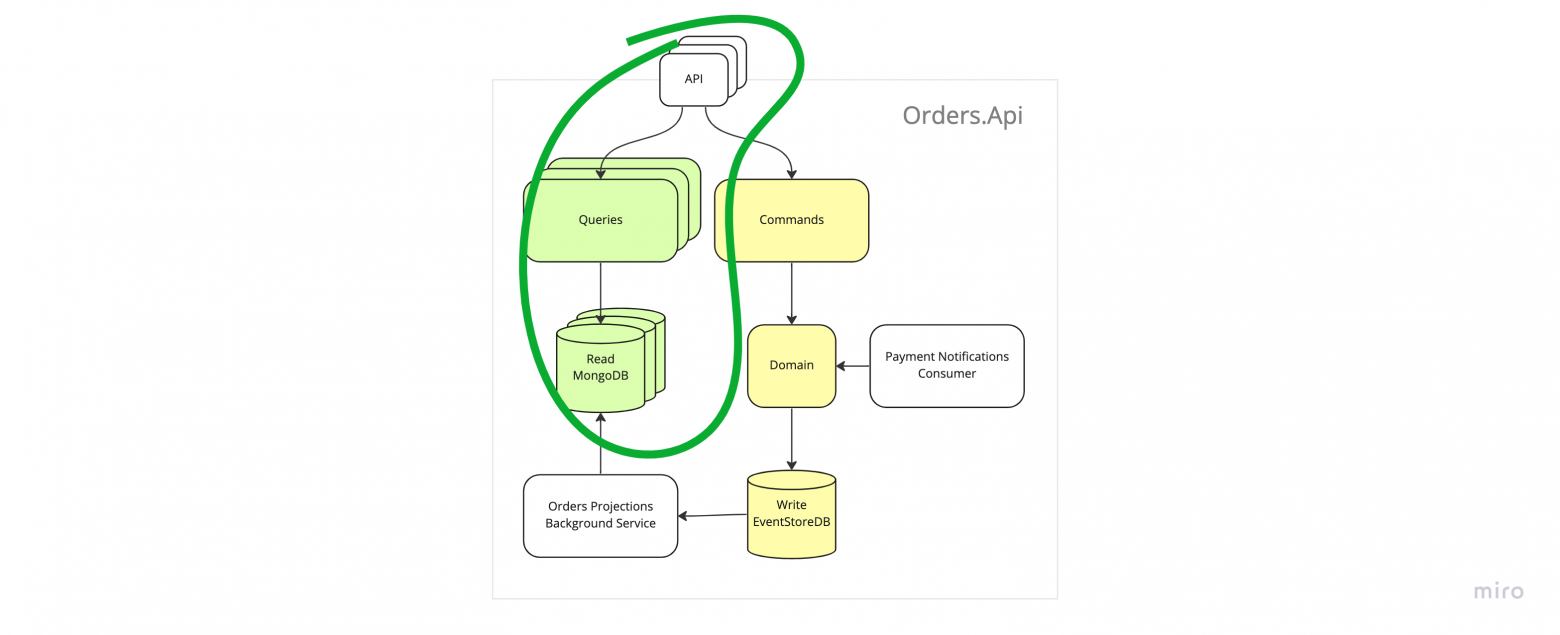 16. Скейлим read компоненты
16. Скейлим read компоненты
В случае проблем с нагрузкой на read компоненты мы можем просто увеличивать количество инстансов API и реплик базы данных и таким образом справляться с любой нужной нам нагрузкой. По-умолчанию всё скейлится горизонтально.
Более интересный случай, когда нам не хватает скорости, с которой работает какой-нибудь подписчик на write базу данных.
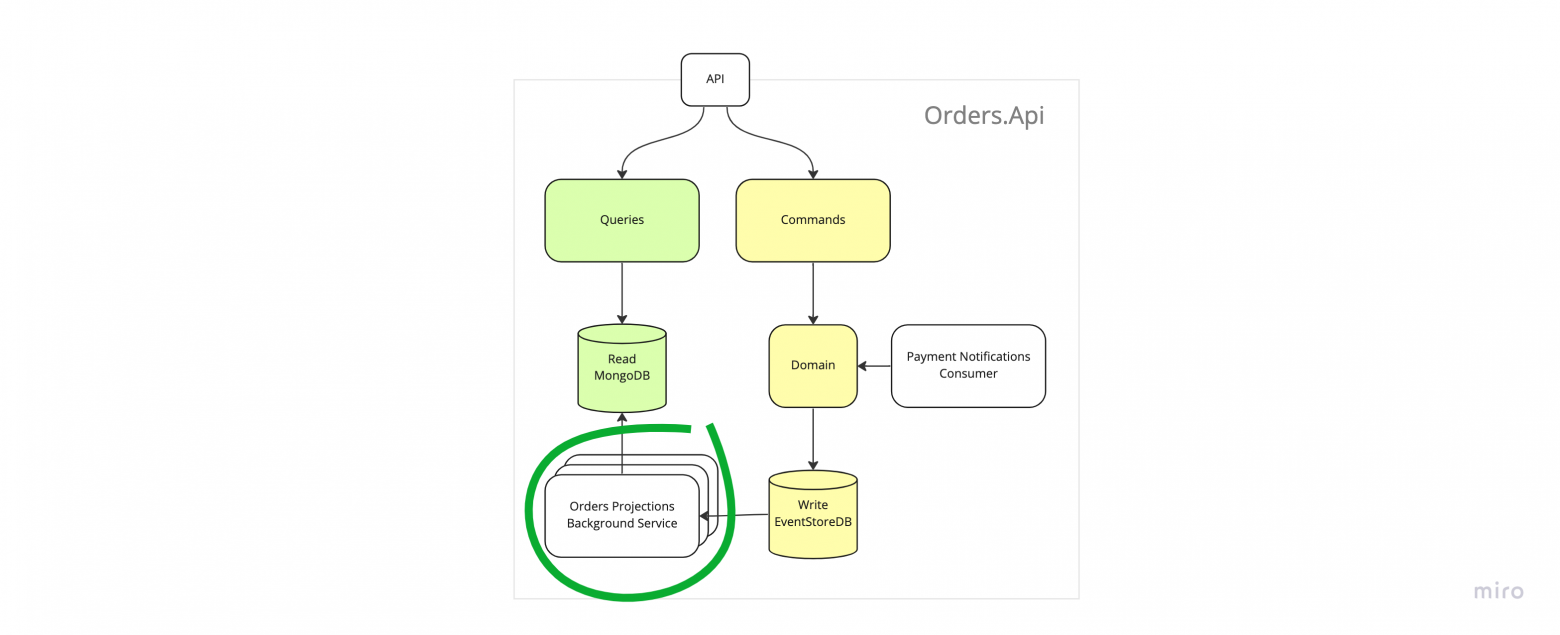 17. Скейлим обработчики эвентов
17. Скейлим обработчики эвентов
В данном случае придётся применять шардирование, например, самое банальное брать остаток от деления StreamId на N и таким образом делить наши ключи на N ренжей и распределять обработку на N обработчиков. Конечно, подход с отстатком от деления не самый гибкий и лучше применять какой-то более продвинутый.
Наиболее сложный момент при скейлинге обработчиков заключается в распределении ресурсов, в нашем случае ренжей хэшей, по обработчикам. В реальном мире даже самые простые приложения имеют несколько запущенных копий для обеспеычения отказоустойчивости, их количество может меняться в процессе работы и нужно уметь распределять нагрузку равномерно.
Если вы используете, например, MySql, то придётся всё сделать самостоятельно, если же вы используете, например, Azure Cosmos DB, то вопрос скейлинга решен из коробки. Тут можно почитать о том как это сделано в Azure Cosmos DB, обратите внимание на шардирование, ченжфид и балансировку.
Подходы могут быть разные в зависимости от задачи, например, если важно, чтобы события одного стрима обрабатывались последовательно, то нужно распределять работу так, чтобы события одного стрима попадали в один и тот же обработчик, если нет, то можно распределять опираясь на SequenceId, round-robin-ом или как-то ещё.
Как скейлить допустимую write нагрузку
В прошлом параграфе мы обсудили скейлинг read нагрузки в случае когда лог не шардирован. Шардирование лога позволяет скейлить допустимую write нагрузку.
 18. Скейлинг write компонентов
18. Скейлинг write компонентов
Всё что мы обсудили ранее справедливо и для лога с несколькими шардами, но есть нюансы. Например, теперь ресурсами являются не ренжи хешей, а шарды или партиции. Если вы используете и хеширование внутри шарда и шардирование вместе, то нужно количество обработчиков у вас будет умножаться при добавлении новых шардов, нужно это учитывать. В данном случае, также как и со чтением, нужно уметь распределять обработку логов по разным инстансам.
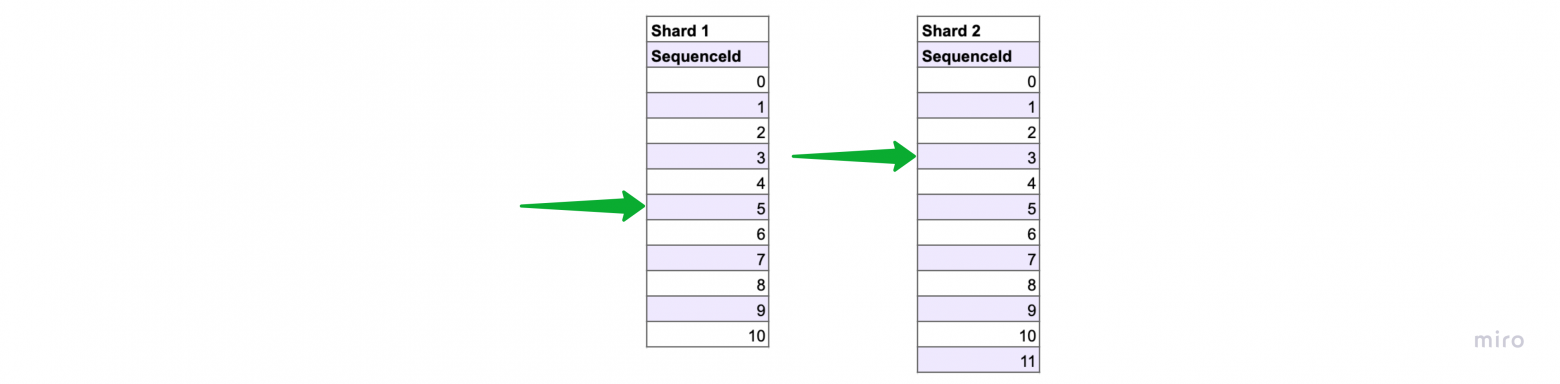 19. Несколько шардов
19. Несколько шардов
Хочется заметить, что когда в системе появляется несколько шардов (>1) эвенты перестают быть глобально упорядоченными, и становятся упорядоченными только в рамках шарда. Это повлияет на то, что теперь система, при проигрывании эвентов будет каждый раз делать это по-разному, потому что эвенты из разных шардов могут обрабатываться с разной скоростью, но в конечном счете система будет оказываться в одном и том же состоянии.
Как избежать head-of-line блокировок при обработке эвентов
С head-of-line блокировками вы столкнётесь, если будете делать медленные операций напрямую в обработчике эвентов из базы данных. Медленные операции это, например, вызовы АПИ внешних систем или вызовы какого-то ресурсоёмкого кода. Если это не учитывать, то возможна ситуация, когда обработка эвента 5 в первой линии затормозит и все последующие эвенты будут ожидать своей очереди до тех пор, пока эвент 5 не обработается.
 20. Head-of-line blocking
20. Head-of-line blocking
Чтобы избежать этой проблемы стоит эвенты превращать в команды, которые могут исполняться независимо друг от друга и перекладывать их в другую систему, которая может обеспечить нужную степень параллелизма. Для примера, сейчас я работаю над платёжным шлюзом и у меня независимо исполняются команды по каждому платежу. В случае, если один платёж подвиснет или будет проходить медленно, то это никак не зааффектит остальные.
Что делать если нужно удалить некоторые данные
Допустим нам нужно удалить некоторые данные из нашей системы, что мы можем сделать? Логическое удаление, которое по сути является обновлением, скорее всего нам не подойдет, потому что физически данные останутся в логе. Нам подходит только физическое удаление и мы можем:
Удалить один эвент физически — это приведет к тому, что станет невозможно восстановить состояние одного аггрегата, к тому же все проекции, которые использовали этот эвент требуется перестроить
Перезаписать данные некоторого эвента — это приведёт к тому, что все проекции, которые использовали этот эвент требуется перестроить
Удалить один стрим физически — это приведёт к тому, все проекции, которые использовали этот эвент требуется перестроить
Но это ещё не все — если данные эвента как-то распространялись по системе, то вычистить их повсеместно может быть очень сложно.
На мой взгляд единственное что можно сделать — заранее предусмотреть необходимые функциональные возможности. В данном случае это сводится к тому, чтобы добавить уровень косвенности и хранить ПД отдельно в таком хранилище, которое поддерживает удаление отдельных записей.
Все остальные решения сводятся к манипуляциям с данными и приводят к тому, что проекции и данные во внешних системах становятся неконсистентными и требуют перестроения.
Как делать UI
 21. Задержка обновления read моделей
21. Задержка обновления read моделей
Допустим мы показываем пользователю страницу на сайте, для чего используем некоторую проекцию и пользователь имеет возможность как-то менять данные на странице. Так как проекции (read модели) не строго-консистентны с write моделью, то они обновляются с некоторой задержкой, и нам нужно обработать ситуацию когда пользователь нажал на кнопку сохранения, но проекции ещё не обновились.
Какие решения:
Делать честный task-based UI. Это решение подразумевает то, что нужна некоторая инфраструктура для работы с [асинхронным] задачами, и, в частности, отслеживания состояния задач (в очереди → исполняется → результат). Главный недостаток этого решения в его высокой сложности.
Чуть более дешёвое — поллинг на фронтенде. При записи эвента нам известен его порядковый номер в стриме, можно опрашивать бэкенд до тех пор, пока модель не достигнет нужной версии. Недостаток в том, что нужно обеспечить возможность поллинга всех сущностей и достаточное количество ресурсов для обработки запросов.
Ещё более дешёвое — поллинг на бэкенде. Суть заключается в том, чтобы не завершать запрос в момент, когда мы сохранили эвент, а поллить read базу до тех пор пока нужная модель не достигнет нужной версии, примерно тоже самое, что в предыдущем пункте. Недостаток заключается в том, что ресурсы тоже будут расходоваться на поллинг, но ещё и сетевые подключения будут существовать относительно долго.
Ничего не делать. Главный недостаток — пользователи будут страдать, а с ними и вы от количество вопросов о том, почему всё не работает :-)
Стоит ли интегрировать сервисы с помощью эвент-сорсинга
Несколько раз мне попадалась идея о том, чтобы использовать эвент-сорсинг как средство интеграции [микро] сервисов. Я считаю, что это плохое решение потому что приводит к излишней связности и хрупкости. Если доменные эвенты используются для решения задач интеграции — это уже интеграционные эвенты и они предполагают наличие некоторого контракта, который нужно соблюдать, что накладывает ограничения на внесение изменений в код сервиса.
 22. Разделение интеграционных и доменных эвентов
22. Разделение интеграционных и доменных эвентов
Я за разумный подход, стоит применять эвент-сорсинг в ограниченных рамках, например, в рамках одного bounded context, допустим, сервис платежей может быть написан с применением event-sourcing, или сервис заказов может быть написан с применением event-sourcing. Но каждый из них — отдельный сервис и интегрируются они стандартно — с помощью интеграционных эвентов или АПИ.
Как архитекторы мы должны стремиться к тому, чтобы наша система оставалась максимально гибкой и могла удовлетворять любые потребности бизнеса, повсеместное и бездумное применение эвент-сорсинга, к сожалению, не способствует решению этой задачи.
Почитать ещё о проблемах интеграции сервисов с помощью эвент-сорсинга можно тут.
Что если в транзакции обновлять агрегаты
Возможно в предыдущем пункте у вас возникла идея использовать [распределенные] транзакции для обновления проекций. Думаю, это возможно, но есть и свои минусы:
Неконтролируемо растет сложность и время записей
Место где происходит запись в базу становится хрупким и сложным, так как требует внесения изменений каждый раз при изменении проекций
Если нужно будет добавить новые проекции, то придется писать два механизма обновления проекций. Первый тот, что умеет читать из лога последовательно, второй тот, что обновляет проекции в транзакциях
Если имеет место необходимость иметь read модель строго-консистентную с write моделью, то возможно эвент-сорсинг не самое подходящее решение. Стоит рассмотреть возможность сохранения ревизий объектов — тоже append-only сторедж, но хранить нужно не события, а версии снимков состояния объектов. Так делают блоговые движки, вроде wordpress — сохраняют ревизии постов.
Выбираем технологию для event store
Важнейший аспект эвент-сорсинга — хранение данных, поэтому выбор технологии для эвент-стора это один из главных вопросов. В этой главе поговорим о требованиях к технологии, рассмотрим несколько вариантов, проанализируем и оценим насколько они подходят для решения задачи. По аналогии вы сможете проанализировать и другие технологии. От выбора зависит то, какие задачи придётся решать самостоятельно — скейлинг, поллинг и упорядочивание данных, какие будут ограничения — возможно, не будет транзакций, что может быть полезно в ситуации, когда мы хотим зафиксировать несколько отдельных изменений в рамках одного запроса, а возможно технология окажется вовсе неподходящей.
Предлагаю дополнить ваш список требований к технологии такими вопросами:
Есть ли возможность упорядочить данные?
Это нужно для того, чтобы обеспечить возможность подписки на новые эвенты.
Есть ли готовые решения для подписки на новые эвенты?
Возможно прочитать отдельный стрим?
Возможно ли прочитать данные сразу после записи? (Уровень консистентности)
Это нужно для того, чтобы мы могли просто работать с данными. Если мы записали эвент в базу данных, но следующим запросом не можем его прочитать, то это может привести к нарушению работы бизнес-логики. Допустим мы можем сохранить эвент о том, что мы списали деньги. Следующим запросом прочитать стрим в котором не будет этого эвента, списать деньги ещё раз.
Как скейлить запись и чтение?
Нам интересно что предлагается из коробки для решения задачи и или существование популярные готовые решения.
Возможность модифицировать записанные данные
Важно так же рассмотреть влияние одних фич на другие. Возможно, это звучит сейчас загадочно, но я поясню когда такое произойдет.
Я не являюсь большим экспертом в каждой из технологий которые буду рассматривать дальше. Ответы на вопросы я старался писать опираясь на концептуальные возможности и документацию решения. Некоторые решения не подходят концептуально, но могут быть подогнаны костылями к нужному нам виду — это не мой путь и в таких случаях я буду считать технологию неподходящей.
