Функции IPP c поддержкой бордюров для обработки изображений в нескольких потоках
В результате длительного использования даже самых хороших программных продуктов постепенно выявляются те или иные их недостатки. Не стала исключением, и библиотека Intel Performance Primitives (IPP). К моменту выхода версии 8.0 выяснились некоторые проблемы, часть из которых относится к функциям обработки двумерных изображений.Для их решения в IPP 8.0 многие функции обработки изображений приведены к общему шаблону, позволяющему обрабатывать изображения по блокам (tiles), и, следовательно, эффективно распараллеливать на уровне приложения код, содержащий вызовы IPP функций. Новый API соответствующих IPP функций поддерживает бордюры нескольких типов, не использует внутреннее выделение динамической памяти, позволяет делить изображения на фрагменты произвольного размера и обрабатывать эти фрагменты независимо; упрощает использование и повышает производительность ряда функций. В данной статье подробно рассмотрен новый API и приведены примеры использования.Как было сказано выше, командой разработчиков IPP была проведена большая работа по изменению интерфейса двумерных функций и приведению его к единому стандартному «API с поддержкой бордюров» («новому АPI»). Зачем? Для ответа на этот вопрос давайте опишем проблемы, которые присутствовали в предыдущих версиях.1.1 Проблемы эффективности использования OpenMP в IPPИтак, первая проблема связана с тем, как использовать IPP в многопоточных приложениях. Иногда задача параллельной обработки изображения эффективнее решается на верхнем уровне, т.е. на уровне приложения. В этом случае, приложение само разбивает изображение на блоки и создает потоки для их параллельной обработки. Многопоточная версия IPP использует OpenMP с отключенным вложенным параллелизмом (по англ. nested threading). Если приложение использует другой инструмент для многопоточности или даже OpenMP, но другой версии, то при вызове из потока такого приложения IPP функции, в свою очередь будет создано несколько потоков, как это показано на рис. 1.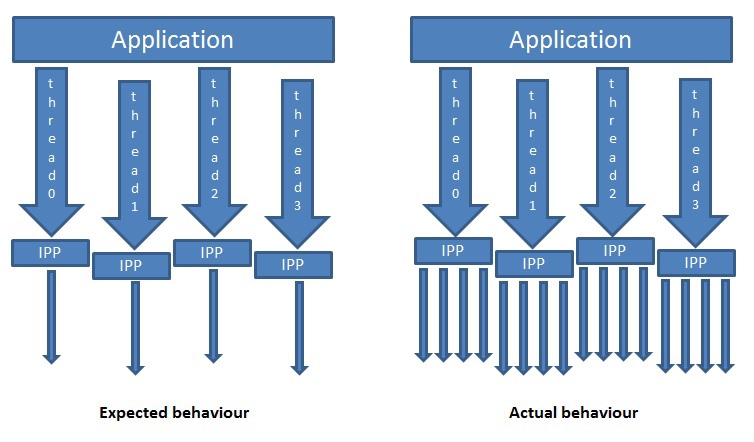 Рис 1. Двухуровневое распараллеливание (nested threading)
Рис 1. Двухуровневое распараллеливание (nested threading)
Такое двухуровневое распараллеливания вместо желаемого ускорения может привести к снижению производительности (по англ. oversubscription), которое можно объяснить тем, что различные средства распараллеливания работают одновременно и ведут борьбу за ресурсы-очереди, семафоры, физические потоки, выталкивают из кэша данные конкурирующих потоков и т.п.Приложение пользователя, в отличие от IPP, располагает информацией о том, как полученное изображение будет обрабатываться дальше, и может сформировать параллельные блоки таким образом, чтобы данные оставшиеся в кэше, использовались после предыдущего этапа обработки, а не зачитывались из памяти (по англ. data cache locality). Поясним подробнее, что же имеется в виду. IPP большей частью используется в клиентских машинах — десктопах, ноутбуках, топология которых в общем случае выглядит следующим образом рис. 2
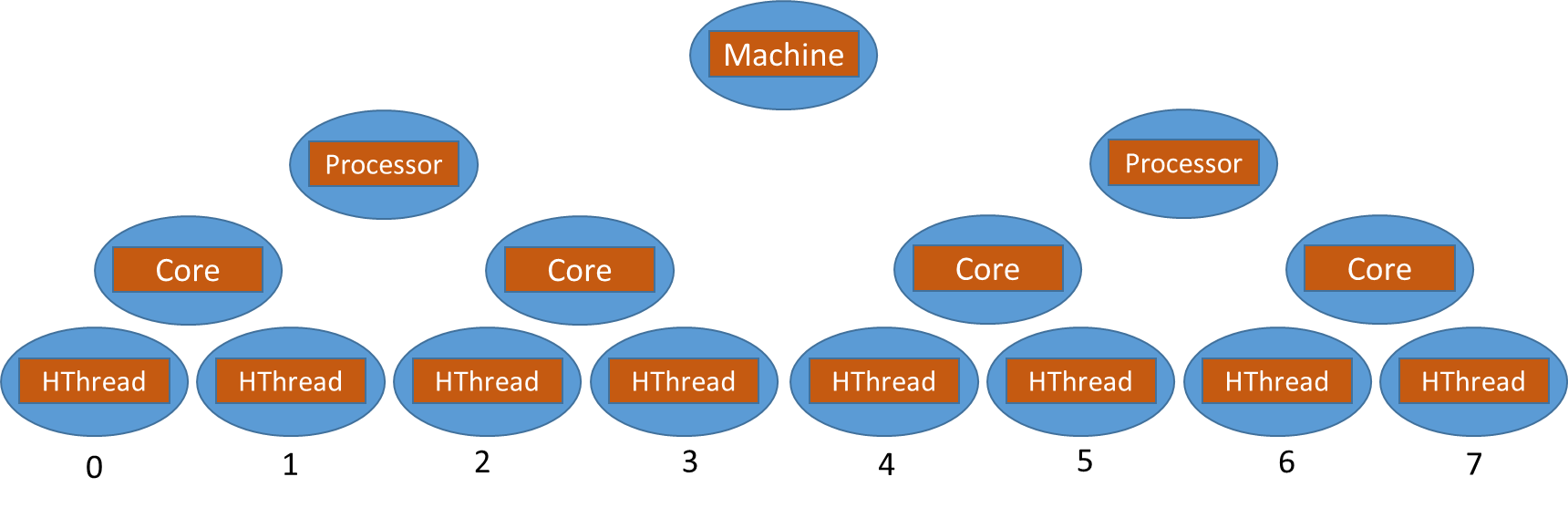 Рис. 2: Modern HW topology, HW threads numeration
Рис. 2: Modern HW topology, HW threads numeration
IPP используется и в HPC сегменте, при этом предполагается, что отличие HPC систем от клиентских лишь в количестве X процессоров. Нумерация потоков на рисунке условна и узнать физический номер потока можно через идентификатор принадлежащего ему APIC (по англ. Advanced Programmable Interrupt Controller), который является уникальным для каждого потока. Соответствие между логическим и физическим номером потока назначается операционной системой или используемым инструментом для параллелизации. Если запустить интенсивную вычислительную задачу в системе Windows и понаблюдать за ней в диспетчере задач, то можно заметить, что система иногда переключает ее с одного ядра на другое. Поэтому нет гарантии, что поток будет выполнен на одном и том же ядре в двух последовательных параллельных регионах. Для указания соответствия между потоком с определенным логическим номером и физическим (по англ. HW thread от слова hardware) потоком существует специальный термин — affinity. При установке affinity операционная система будет запускать логический поток в последовательных параллельных регионах на одном и том же HW потоке. В идеальном случае, полностью «чистой» системы указание affinity могло бы помочь решить проблемы производительности, связанные с тем, что логические потоки переключаются с одного HW потока на другой. Однако, в реальной современной системе выполняются сотни и возможно тысячи процессов. В любое время каждый такой процесс может быть выведен из спящего состояния и запущен на некотором HW потоке.
Предположим, что в некотором приложении был тщательно рассчитан объем вычислений для каждого потока, и при этом, в соответствии с установленной affinity каждый поток приложения был запущен на соответствующем ему HW потоке. На рисунке — зеленым цветом.
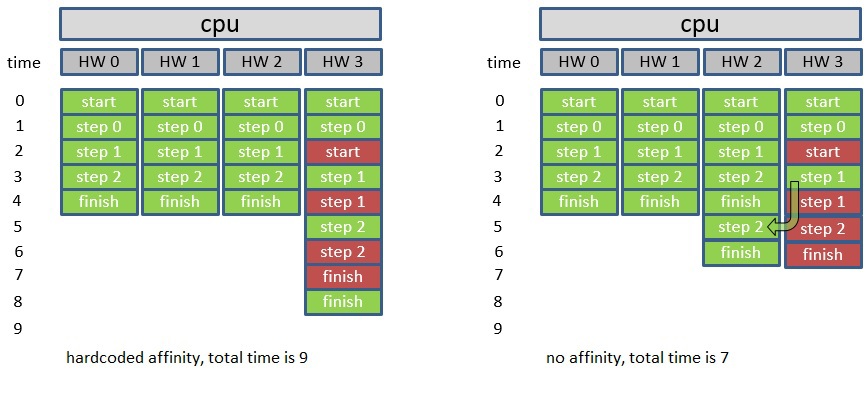
Через некоторое время операционная система может запустить другой процесс, к примеру, на HW потоке #3, который изображен красным цветом. Поскольку все потоки первого приложения жестко привязаны к HW потокам, то поток #3 будет ждать освобождения ресурсов другим процессом, а операционная система не сможет переключить его с HW потока #3, хотя потоки #0–2 могут уже завершиться и будут простаивать. Мы рассматриваем идеальную ситуацию, и видим, что в первом случае фиксированной affinity будет затрачено 9 условных единиц времени, а в случае, когда affinity не указана будет 7 единиц. Итак, в конечном итоге такая фиксированная установка affinity приводит к тому, что в отдельных случаях производительность будет высокой, а в других очень плохой.Теперь рассмотрим какие проблемы могут возникнуть, когда наоборот affinity не установлена, и операционная система может перераспределять потоки по своему усмотрению. Возьмем простой пример, реализующий фильтр Sobel. Он состоит из нескольких последовательных этапов, каждый из которых может быть распараллелен: Применяем вертикальный фильтр Sobel к исходному изображению и получаем временное изображение A (ippiFilterSobelVertBorder_8u16s_C1R)Применяем горизонтальный фильтр Sobel к исходному изображению и получаем временное изображение B (ippiFilterSobelHorizBorder_8u16s_C1R)Вычисляем квадрат каждого элемента A и сохраняем результат снова в A (ippiSqr_16s_C1IRSfs)Вычисляем квадрат каждого элемента B и сохраняем результат снова в B (ippiSqr_16s_C1IRSfs)Получаем сумму изображений A и B, можем сохранить результат снова в A (ippiAdd_16s_C1IRSfs)Последний этап — корень квадратный из A (ippiSqrt_16u_C1IRSfs) и преобразование к 8u (ippiConvert_16s8u_C1R)
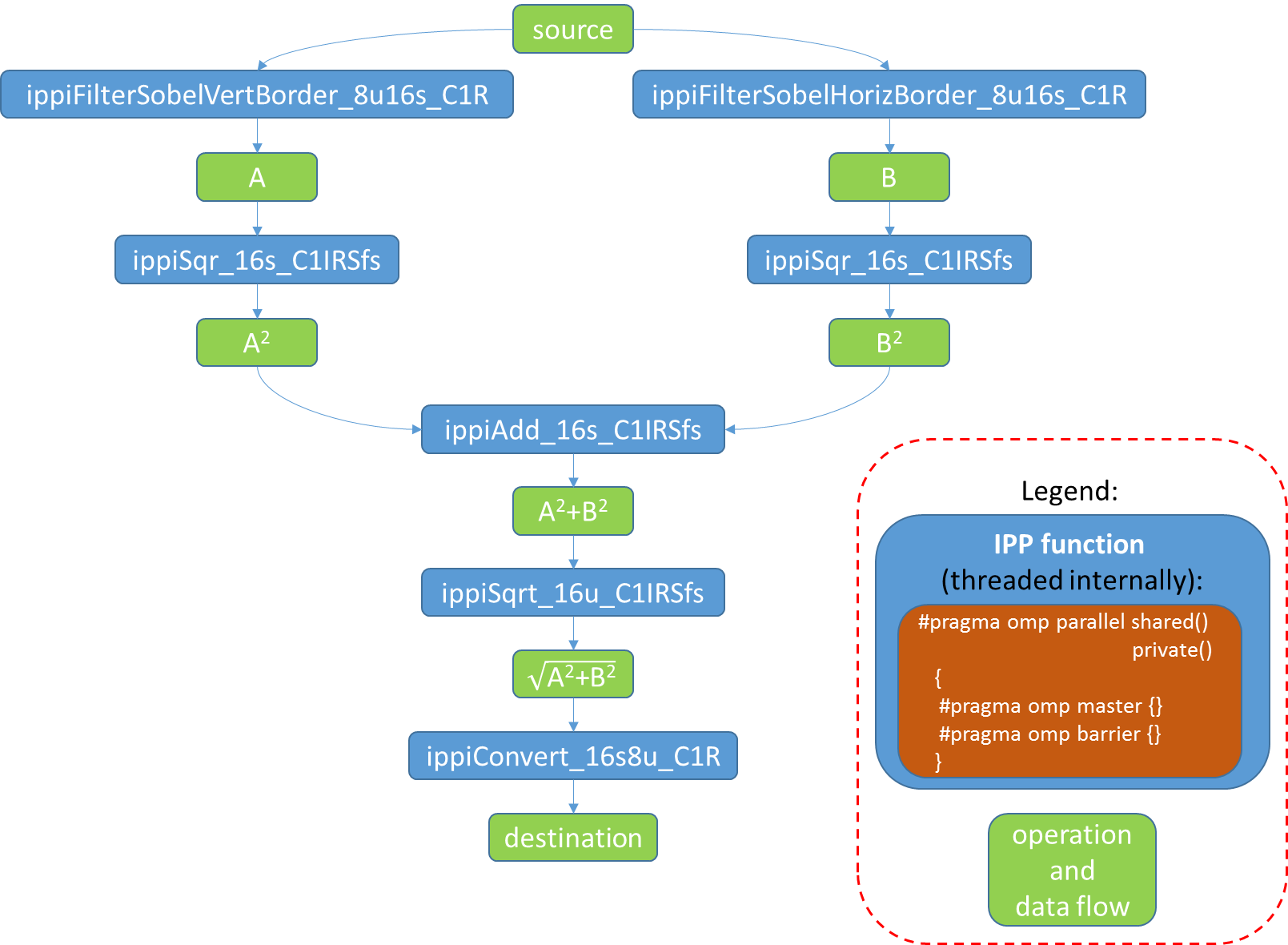 Рис. 3 Этапы реализация фильтра Sobel, которые могут иметь внутреннюю параллелизацию.
Рис. 3 Этапы реализация фильтра Sobel, которые могут иметь внутреннюю параллелизацию.
Каждая из внутренних функций может быть распараллелена. Однако такой подход представляется неэффективным, поскольку имеется 7 последовательных вызовов функций, у каждого из которых есть точки синхронизации для создания/завершения параллельных регионов. Перечисленные IPP функции используют простой шаблон разбиения изображения на блоки в параллельном регионе
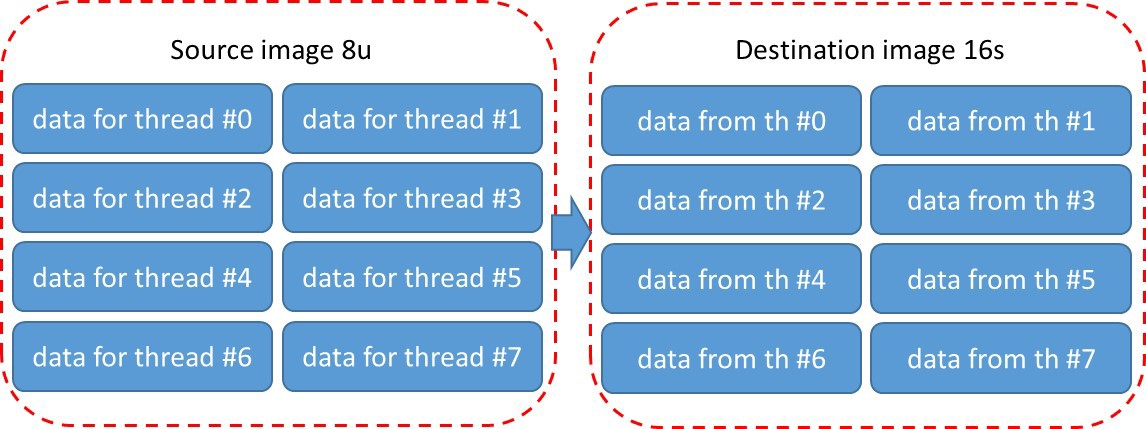 Рис. 4 Стандартный способ разбиения на блоки в IPP функциях
Рис. 4 Стандартный способ разбиения на блоки в IPP функциях
Рассмотрим, например, последовательный вызов ippiFilterSobelVertBorder_8u16s_C1R (src→A) и ippiSqr_16s_C1IRSfs (A→A2)). Сначала создается первый параллельный регион (region #1) для функции ippiFilterSobelVertBorder_8u16s_C1R, затем второй (region #2).
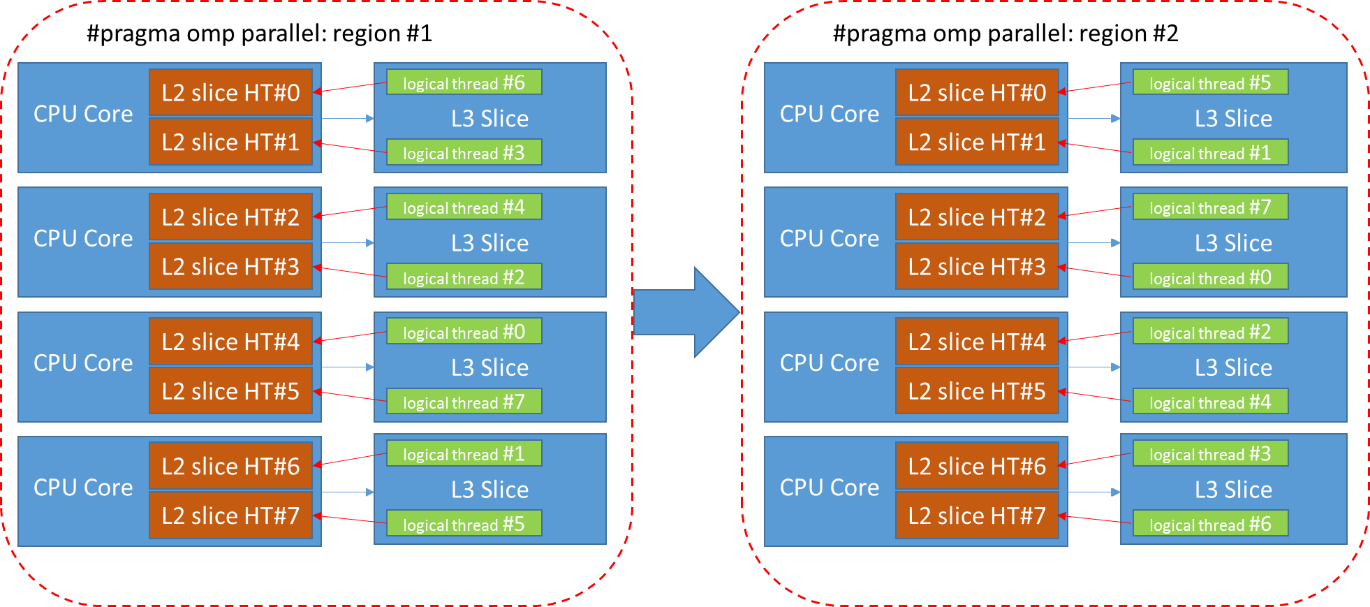 Рис. 5 Распределение логических потоков по hw потокам в двух последовательных параллельных регионах.
Рис. 5 Распределение логических потоков по hw потокам в двух последовательных параллельных регионах.
Логический поток #0 будет выполнятся на физическом потоке #4 и поэтому порция данных функции SobelVert будет сохранена в L2 и L3 кэшах, относящихся к физическому потоку #4. В следующем параллельном регионе #2, создаваемом функцией Sqr, разбиение изображения на блоки будет осуществляться по такому же шаблону, как и в первой функции, поэтому логический поток #0 будет ожидать данные доступными в кэше. Однако ОС запустила этот логический поток #0 на физическом #3. Данных в кэше не окажется и начнется интенсивный обмен данными между кэшами этих потоков, что приведет к замедлению времени выполнения приложения.
Еще одна проблема была связана с тем, что до выхода IPP версии 8.0 gold у пользователей возникала ситуация, что приложение и библиотека используют одинаковую версию OpenMP, но различные модели линковки. К примеру, статическая версия IPP использовала также статическую библиотеку OpenMP, а пользователь в своем приложении динамическую версию В этом случае OpenMP обнаруживает конфликт и выдает предупреждение о возможном снижении производительности. В IPP 8.0 теперь используется только динамическая версия OpenMP, поэтому после перехода на эту версию проблемы такого рода у пользователей библиотеки уже не должны возникать.Результатом рассмотренных выше проблем стало то, что, несмотря на повсеместную многоядерность, функции с новым API имеют только обычную однопоточную реализацию. Однако в нем учитывается возможность обработки изображения в параллельном режиме. Однако для IPP функций, которые уже присутствовали в IPP многопоточная OpenMP реализация сохранилась.
1.2 Проблемы бордюров при последовательной обработке изображений
Вторая проблема предыдущей версии АPI возникает при последовательной обработке изображения несколькими фильтрами. Он подразумевает, что все необходимые пиксели по краям региона интереса (сокращенно ROI от англ. region of interest) доступны в памяти. Поэтому, для получения выходного изображения шириной dstWidth и высотой dstHeight и фильтра размером kernelWidth X kernelHeight необходимо подать входное изображение шириной dstWidth+kernelWidth-1 и высотой dstHeight+kernelHeight-1, рис. 6b) и 6c).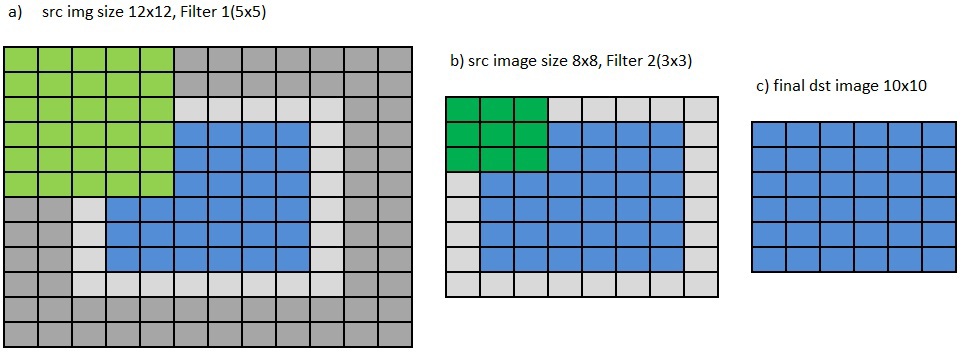 Рис. 6 Необходимость в дополнительных рядах пикселей вокруг ROI для последовательного применения нескольких фильтров в старом API.
Рис. 6 Необходимость в дополнительных рядах пикселей вокруг ROI для последовательного применения нескольких фильтров в старом API.
А если применяется последовательно 2,…, N фильтров, с размерами ядра kWidth1 X kHeight1, …, kWidthN X kHeightN то размер входного изображения соответственно должен быть (dstWidth+kWidth1+…+kWidthN — N) X (dstHeight+kHeight1+…+kHeightN-N), рис. 6a). В данном примере для того чтобы получить результирующее изображение размером 6×6 пикселей применяются два фильтра размером 5×5 и 3×3. Первое изображение имеет размер 6+5–1+3–1×6+5–1+3–1, т.е. 12×12 пикселей, а изображение, полученное после первого фильтра размер 8×8. Применяя к нему следующий фильтр размером 3×3 получаем итоговое изображение 6×6. Для того чтобы сформировать бордюры изображения можно воспользоваться IPP функциями ippiCopyReplicate (Mirror/Const)Border, однако это очень накладно с точки зрения производительности и дополнительно требуемой памяти под новое изображение с бордюром.Новый API позволяет избежать вызова таких функций и предоставляет выбор из трех вариантов обработки пикселей, находящихся вне ROI — по-прежнему считать их доступными в памяти, подставлять вместо них постоянное значение или использовать копию пикселей, лежащих на границе изображения. Более подробно будет рассказано далее.
1.3 Прямой порядок коэффициентов фильтров и фиксированный якорь
В предыдущей версии API двумерных фильтров использовался обратный порядок коэффициентов в соответствии с формулой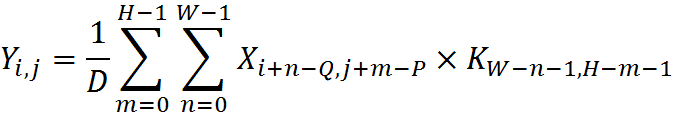 , где
, где 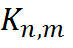 — значения ядра,
— значения ядра, 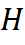 ,
, 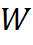 — горизонтальный и вертикальный размер ядра,
— горизонтальный и вертикальный размер ядра, 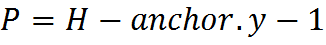 , anchor.y координата Y якоря,
, anchor.y координата Y якоря, 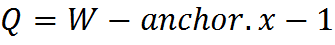 , anchor.x координата X якоря.Под термином якорь понимается позиция некоторой фиксированной ячейки внутри ядра, которая совмещается с обрабатываемым в данный момент пикслем. Таким образом с помощью якоря можно указать расположение ядра относительно пикселя.Для того, чтобы упростить использование функций, подаваемые на вход коэффициенты фильтров теперь используются в прямом порядке по формуле
, anchor.x координата X якоря.Под термином якорь понимается позиция некоторой фиксированной ячейки внутри ядра, которая совмещается с обрабатываемым в данный момент пикслем. Таким образом с помощью якоря можно указать расположение ядра относительно пикселя.Для того, чтобы упростить использование функций, подаваемые на вход коэффициенты фильтров теперь используются в прямом порядке по формуле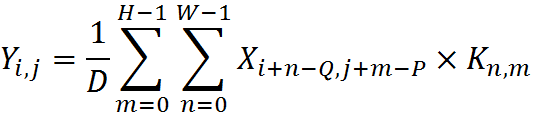
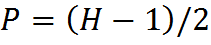 ,
, 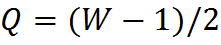 .
.
Рис. 6. демонстрирует различия между обратным и прямым порядком использования коэффициентов.
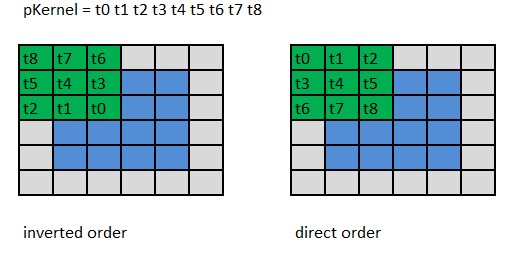 Рис. 6 Прямой и обратный порядок коэффициентов
Рис. 6 Прямой и обратный порядок коэффициентов
Также в новом API было убрано понятие якоря (anchor) рис. 7.Теперь он находится на фиксированной позиции Q= anchor.x=(kernelWidth-1)/2, P=anchor.y=(kernelHeight-1)/2.
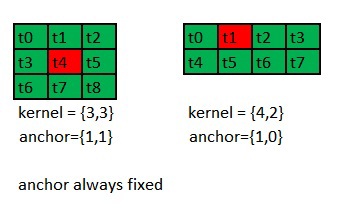 Рис. 7. Фиксированное положение якоря x=(kw-1)/2, y=(kh-1)/2
Рис. 7. Фиксированное положение якоря x=(kw-1)/2, y=(kh-1)/2
В принципе якорь определяет смещение в памяти, от подаваемого указателя на ROI, поэтому в новом API в случае «нестандартного» значения якоря, достаточно просто сместить ROI в необходимом направлении, см. рис. 8 на котором для различных значений якоря в старом API показан требуемый сдвиг ROI в новом API. Серым цветом показана одна и та же область памяти, а синим — указатель на ROI, подаваемый в функцию. В старом он неизменен, а в новом сдвигается.
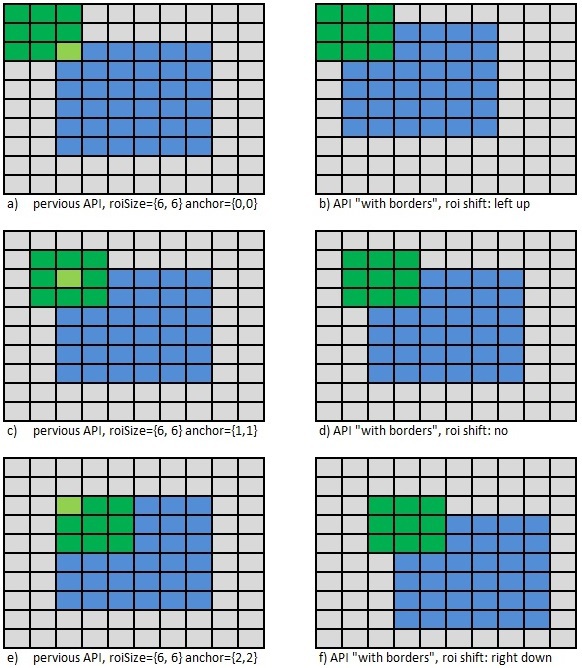 Рис. 8 Сдвиг ROI для «нестандартного» значения якоря
Рис. 8 Сдвиг ROI для «нестандартного» значения якоря
Для масок с четной шириной (высотой) при указании типа бордюра находящегося в памяти справа (внизу) от изображения должно быть доступно пикселей на один ряд больше.
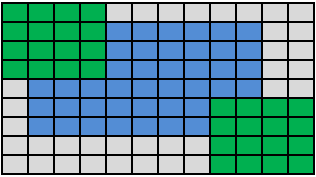 Рис. 9. Для маски с четной шириной (высотой) требуется на ряд пикселей больше справа (снизу).
Рис. 9. Для маски с четной шириной (высотой) требуется на ряд пикселей больше справа (снизу).
Помимо удобства использования, прямой порядок позволяет снизить накладные расходы внутри функции, связанные с перестановкой в обратном порядке коэффициентов. Часто коэффициенты ядра бывают симметричными и такое их транспонирование было излишним.
1.4 Отсутствие внутреннего выделения динамической памяти
В функциях, имеющих новый API, не используется внутреннее выделение динамической памяти с помощью операции malloc. Поскольку при выделении такой памяти в каком либо из потоков все остальные потоки останавливаются. Память теперь должна быть выделена вне обрабатывающих функций, а необходимый размер требуемых буферов может быть получен с помощью вспомогательных функций вида ippiGetBufferSize.
Использование функций с новым API рассмотрим на примере операции морфологии. Подробное описание свойств данной операции можно найти в литературе и в сети интернет. В общих чертах результатом данной операции является минимальный или максимальный элемент внутри некоторой окрестности пикселя. В первом случае операция называется Erode рис. 11, во втором Dilate, рис. 12 Рис. 10 Исходное изображение
Рис. 10 Исходное изображение
 Рис. 11 Операция Erode
Рис. 11 Операция Erode
 Рис. 12 Операция Dilate
Рис. 12 Операция Dilate
На первый взгляд, кажется, что название не соответствует полученному результату, тем не менее, все корректно. Поскольку операция Erode выбирает минимальное значение, а черный цвет формируется меньшими значениями, чем белый, то соседние с буквами пиксели заменяются черным цветом и возникает эффект утолщения букв. В случае же операции Dilate, наоборот края букв заменяются белыми пикселями и буквы становятся тоньше.
3.1 Пример кода для операции морфологии — Dilate Для того чтобы получить результат на рисунке 12 необходимо использовать следующие функцииIppStatus ippiMorphologyBorderGetSize_32f_C1R (int roiWidth, IppiSize maskSize, int* pSpecSize, int* pBufferSize) IppStatus ippiMorphologyBorderInit_32f_C1R (int roiWidth, const Ipp8u* pMask, IppiSize maskSize, IppiMorphState* pMorphSpec, Ipp8u* pBuffer) IppStatus ippiDilateBorder_32f_C1R (const Ipp32f* pSrc, int srcStep, Ipp32f* pDst, int dstStep, IppiSize roiSize, IppiBorderType borderType, Ipp32f borderValue, const IppiMorphState* pMorphSpec, Ipp8u* pBuffer) Первая функция вычисляет необходимый размер буферов, следующая инициализирует эти буферы, а третья функция осуществляет обработку изображения. Фрагмент кода, использующий эти функции выглядит следующим образом.Лист. 1 стандартная последовательность вызова функций ippiMorphologyBorderGetSize_32f_C1R (roiSize.width, maskSize, &specSize, &bufferSize); pMorphSpec = (IppiMorphState*)ippsMalloc_8u (specSize); pBuffer = (Ipp8u*)ippsMalloc_8u (bufferSize); ippiMorphologyBorderInit_32f_C1R (roiSize.width, pMask, maskSize, pMorphSpec, pBuffer); ippiDilateBorder_32f_C1R (pSrc, srcStep, pDst, dstStep, roiSize, border, borderValue, pMorphSpec, pBuffer); А целиком код приведен в Лист. 2
Лист. 2 Код обработки изображения
#define WIDTH 128
#define HEIGHT 128
int morph_dilate_st ()
{
IppiSize roiSize = { WIDTH, HEIGHT };
IppiSize maskSize = { 3, 3 };
IppStatus status;
int specSize = 0, bufferSize = 0;
IppiMorphState* pMorphSpec;
Ipp8u* pBuffer;
Ipp32f* pSrc;
Ipp32f* pDst;
int srcStep, dstStep;
Ipp8u pMask[3×3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 };
IppiBorderType border = ippBorderRepl;
int borderValue = 0;
int i, j;
pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep);
pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep);
for (j = 0; j
3.3 ippGetSize -вычисление размеров буферов
Функции, возвращающие размер буферов, содержат в названии суффикс GetSize.IppStatus ippiMorphologyBorderGetSize_32f_C1R (int roiWidth, IppiSize maskSize, int* pSpecSize, int* pBufferSize)Функции могут иметь различные входные параметры, характеризующие операцию и изображение, и возвращают размер используемой внутренней структуры данных pSpecSize (pStateSize) и размер используемого функцией буфера pBufferSize.Поскольку в новом API было устранено внутреннее выделение динамической памяти, то для выделения требуемой памяти следует использовать или средства операционной системы malloc, new и т.д. или же воспользоваться IPP функциями ippMalloc/ippiMalloc, которые удобны тем, что выделяют память и строки изображений по адресу, с выравниванием, оптимальным для используемой архитектуры. На x86 в большинстве случаев для увеличения производительности желательно, чтобы все массивы начинались на 64-байтной границе. Указанные IPP функции выделяют память, выровненную именно таким образом. А функция ippiMalloc еще и возвращает шаг между строками изображения такой, что начало каждой линии изображения тоже будет выровнено.Вполне возможно, что приложение будет использовать последовательно несколько IPP функций. В этом случае можно выделить один максимальный из всех по величине буфер и подавать его во все функции последовательно см. рис. ниже. Такой подход позволит уменьшить фрагментацию памяти и с большой вероятностью выделенный буфер будет переиспользоваться и, следовательно, находиться в кэше.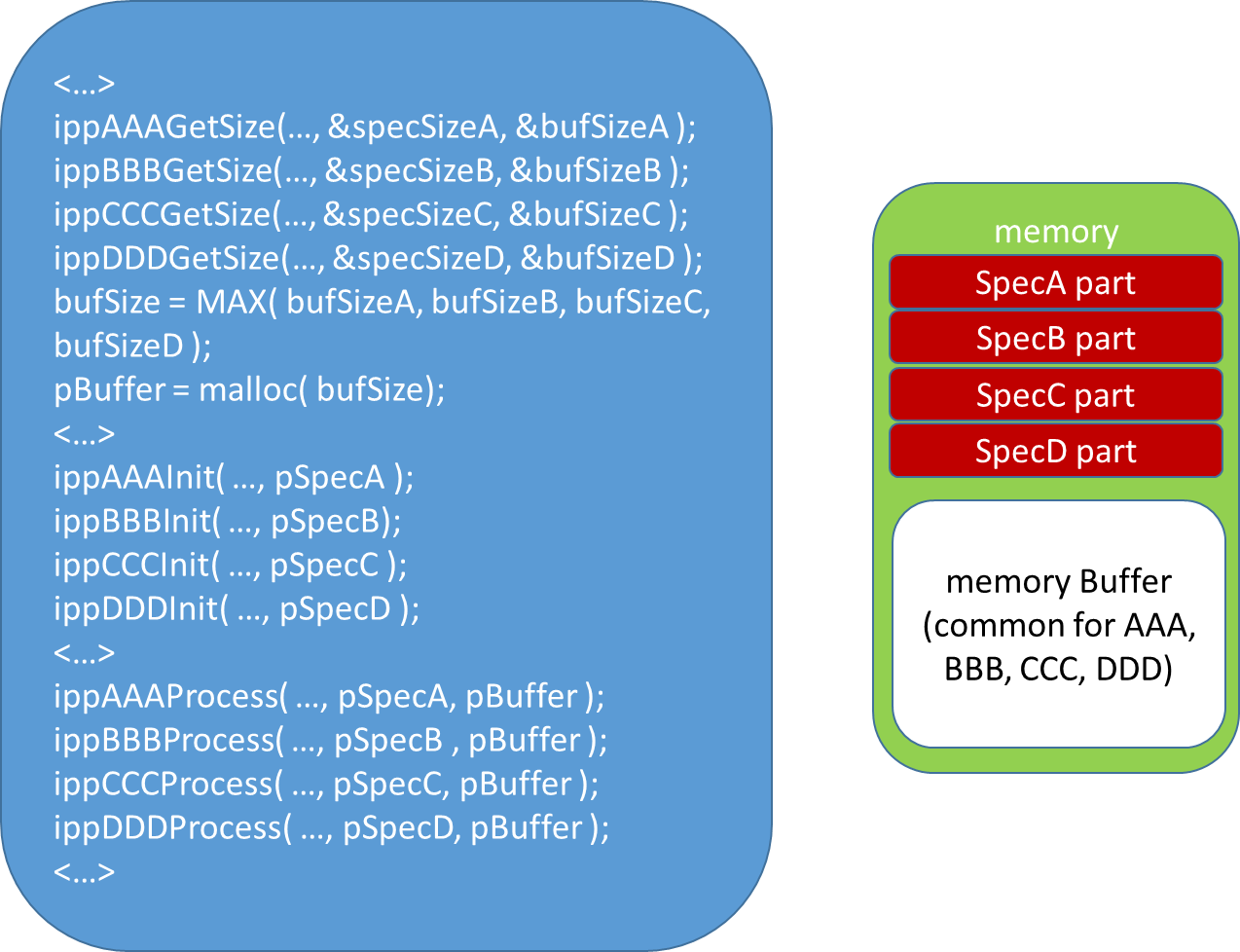 Рис. 14 Использование буфера максимального из необходимых размера позволяет уменьшить фрагментацию памяти и «подогреть» буфер
Рис. 14 Использование буфера максимального из необходимых размера позволяет уменьшить фрагментацию памяти и «подогреть» буфер
3.4 ippInit — инициализация внутренней структуры
Инициализация внутренних структур осуществляется функциями содержащих суффикс InitIppStatus ippiMorphologyBorderInit_32f_C1R (int roiWidth, const Ipp8u* pMask, IppiSize maskSize, IppiMorphState* pMorphSpec, Ipp8u* pBuffer)Внутренняя структура данных содержит таблицы коэффициентов, указателей и другие предварительно вычисленные данные. В IPP используется следующее правило — если в названии параметра используется слово Spec, то содержимое этой структуры является константой от вызова к вызову функции. Поэтому она может быть использована одновременно в нескольких потоках. Если применяется слово State, то это означает некоторое состояние, к примеру линию задержки в фильтре и такую структуру нельзя разделять между потоками. Содержимое pBuffer однозначно может измениться, поэтому для каждого потока необходимо выделять отдельный буфер.3.5 ippFuncBorder — обрабатывающая функция
Непосредственно обрабатывающие функции нового API содержат в названии слово BorderIppStatus ippiDilateBorder_32f_C1R (const Ipp32f* pSrc, int srcStep, Ipp32f* pDst, int dstStep, IppiSize roiSize, IppiBorderType borderType, Ipp32f borderValue, const IppiMorphState* pMorphSpec, Ipp8u* pBuffer)3.6 Поддерживаемые типы бордюров
В новом API используется три вида бордюров изображенияippBorderInMem, ippBorderConst, ippBorderRepl, см. рис. 15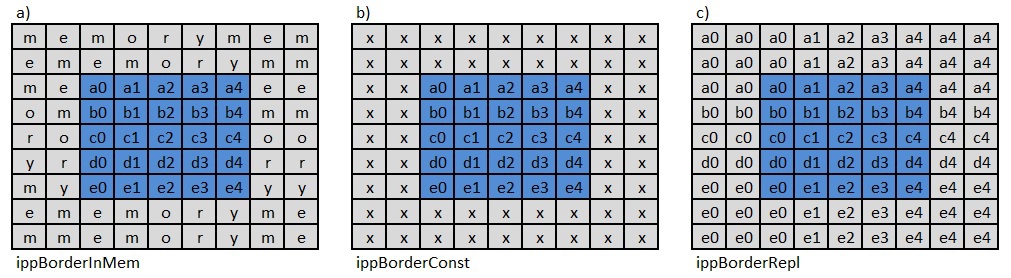 Рис 15. Три типа бордюра
Рис 15. Три типа бордюра
В первом случае ippBorderInMem функции доступны необходимые пиксели как внутри изображения, так и лежащие в памяти. Во втором — ippBorderConst используется фиксированное значение borderValue. Для многоканальных изображений используется массив значений. Формирование недостающих пикселей в случае ippBorderRepl показано на рис. 15с). Угловые пиксели изображения дублируются в две внешние стороны угла, а остальные граничные пиксели только в соответствующую им сторону от границы.К указанным типам бордюров могут применяться модификаторы, имеющие следующие значения
ippBorderInMemTop = 0×0010,
ippBorderInMemBottom = 0×0020,
ippBorderInMemLeft = 0×0040,
ippBorderInMemRight = 0×0080
Эти модификаторы предназначены для обработки изображения по блокам. Они объединяются с параметром borderType с помощью операции »|»
4.1 Разбиение изображения на блоки
Новый API позволяет производить обработку изображения в нескольких потоках по блокам. Для правильного соединения полученных отдельных блоков изображения в единое выходное изображение, требуется применить к основному типу бордюра модификаторы соответствующие положению блока. К примеру, если имеется 16 потоков и используется тип бордюра ippBorderRepl, то значение borderType нужно формировать следующим образом рис. 16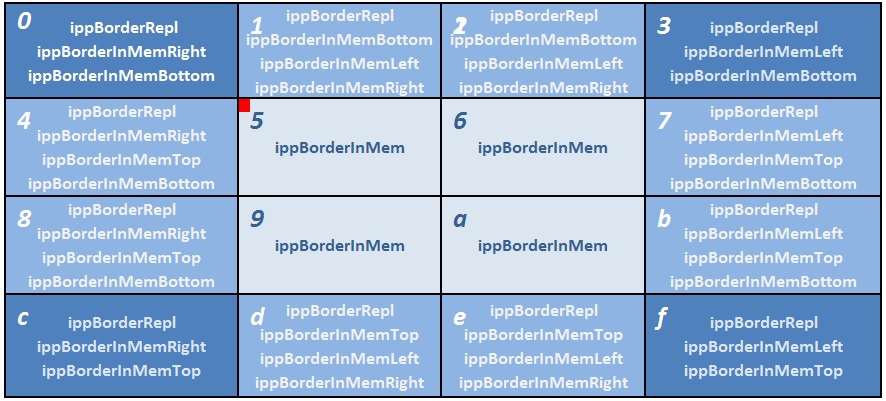 Рис. 16 Обработка изображения в 16 потоков по блокам
Рис. 16 Обработка изображения в 16 потоков по блокам
Блок номер 0 расположен в левой верхней части изображения. Поэтому необходимые для обработки, но недостающие пиксели слева и вверху блока будут дублироваться граничными, а необходимые пиксели справа и снизу блока будут загружаться из соседних блоков 1, 4 и 5, в соответствии с модификаторами ippBorderInMemRight|ippBorderInMemBottom. Блоки 1,2 не имеют пикселей лишь сверху, а с трех других сторон и углов окружены соседними блоками, в которых лежат нужные пиксели, поэтому указывается три модификатора ippBorderInMemBottom|ippBorderInMemRight|ippBorderInMemLeft. Для блоков 3,4,8,7, B, C, D, E, F модификаторы задаются аналогичным образом. Блоки 5,6,9, а находятся внутри изображения и поэтому для них можно указать все 4 модификатора, но проще использовать отдельное значение типа бордюра ippBorderInMem. Возвращаясь к блоку номер 0, комбинация модификаторов ippBorderInMemBottom|ippBorderInMemRight позволяет функции сделать вывод о том, что нужно использовать пиксели из блока номер 5. А для блока номер C в данную область будут дублироваться пиксели из блока D, но зато справа и сверху будут использованы пиксели из блока 9. Вся логика такого чтения пикселей из памяти или дублирования пикселей построена таким образом, чтобы результат обработки изображения как целого так и по блокам полностью совпадал.Также данный подход предполагает, что при указании модификатора ippBorderInMem* память действительно доступна. В некоторых частных случаях возможна следующая ситуация как на рис 17
 Рис. 17 Выход за границу изображения
Рис. 17 Выход за границу изображения
Если разбить изображение размером 1×2 на два блока по одному пикселю, и при этом использовать маску 5×5, то при обработке левого блока и указании для него как это и положено модификатора ippBorderInMemRight может произойти выход за границу выделенной памяти с непредсказуемыми последствиями. Поэтому при разбиении изображения на блоки и использовании модификатора ippBorderInMem следует обеспечить наличие kernelWidth/2 пикселей в памяти в нужную сторону.
4.2 Разбиение изображения на полосы
На рис. 16 изображен общий случай разбивки изображения на блоки для параллельной обработки и вообще говоря, реализация разбиения по блокам может быть и не такой простой задачей и возможно эффективнее разбивать изображение не на блоки, а на полосы, так как это показано на рис. 18. API с бордюрами позволяет осуществить и такое разбиение на блоки.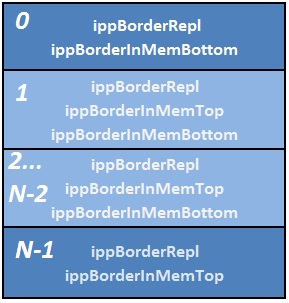 Рис. 18 Обработка по полосам.
Рис. 18 Обработка по полосам.
4.3 Пример кода с новым API для обработки в несколько OpenMP потоков
Приведем пример обработки изображения в несколько потоков. Для этого будем использовать OpenMP.Лист. 3 Код обработки изображения по блокам
#define WIDTH 128
#define HEIGHT 128
int morph_dilate_omp ()
{
IppiSize roiSize = { WIDTH, HEIGHT };
IppiSize maskSize = { 3, 3 };
IppStatus status;
int specSize = 0, bufferSize = 0;
IppiMorphState* pMorphSpec;
Ipp8u* pBuffer;
Ipp32f *pSrc, *pDst;
int srcStep, dstStep;
Ipp8u pMask[3×3] = { 1, 1, 1, 1, 1, 1, 1, 1, 1 };
IppiBorderType border = ippBorderRepl;
int borderValue = 0;
int nThreads = 16;
int i, j;
/*allocate memory*/
pSrc = ippiMalloc_32f_C1(WIDTH, HEIGHT, &srcStep);
pDst = ippiMalloc_32f_C1(WIDTH, HEIGHT, &dstStep);
/*fill image*/
for (j = 0; j
