Формула для корейского, или распознаем хангыль быстро, легко и без ошибок
 На сегодняшний день сделать распознавание корейских символов может любой студент, прослушавший курс по нейросетям. Дайте ему выборку и компьютер с видеокартой, и через некоторое время он принесёт вам сеть, которая будет распознавать корейские символы почти без ошибок.
На сегодняшний день сделать распознавание корейских символов может любой студент, прослушавший курс по нейросетям. Дайте ему выборку и компьютер с видеокартой, и через некоторое время он принесёт вам сеть, которая будет распознавать корейские символы почти без ошибок.
Но такое решение будет обладать рядом недостатков:
Во-первых, большое количество необходимых вычислений, что влияет на время работы или требуемую энергию (что очень актуально для мобильных устройств). Действительно, если мы хотим распознавать хотя бы 3000 символов, то это будет размер последнего слоя сети. А если вход этого слоя равен хотя бы 512-ти, то получаем 512×3000 умножений. Многовато.
Во-вторых, размер. Тот же самый последний слой из предыдущего примера будет весить 512×3001 * 4 байт, то есть около 6-ти мегабайт. Это только один слой, вся сеть будет весить десятки мегабайт. Понятно, для настольного компьютера это проблема небольшая, но на смартфоне не все будут готовы хранить столько данных для распознавания одного языка.
В-третьих, такая сеть будет давать непредсказуемый результат на изображениях, которые не являются корейскими символами, но тем не менее используются в корейских текстах. В лабораторных условиях это не трудно, но для практического применения технологии этот вопрос придётся как-то решать.
И в-четвёртых, проблема в количестве символов: 3000, скорее всего, хватит чтобы, например, отличить в меню ресторана стейк от жареного морского огурца, но порой встречаются и более сложные тексты. Обучить сеть на большее количество символов будет сложно: она будет не только более медленной, но и возникнет проблема со сбором обучающей выборки, так как частота символов падает приблизительно экспоненциально. Конечно, можно доставать изображения из шрифтов и аугментировать их, но для обучения хорошей сети этого недостаточно.
И сегодня я расскажу, как нам удалось решить эти проблемы.
Как устроена корейская письменность
Корейская письменность, хангыль, является чем-то средним между китайским и европейским письмом. Внешне, это квадратные символы, напоминающие иероглифы, и на одной странице текста их можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков. Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать дифграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Например, если бы мы писали так же, то фразу «Привет, Хабр» можно было бы записать тремя блоками примерно так:

Каждый блок может состоять из двух, трёх или четырёх букв. При этом первой всегда идёт согласная, затем одна или две гласных, и в конце может стоять ещё одна согласная. Существует несколько разных способов объединения букв в блоки, то есть в разных блоках вторая буква, например, будет стоять в разных местах.
На картинке ниже изображены два блока, которые вместе образуют слово «хангыль». Первая буква каждого блока обозначается красным, гласные выделены синим, а финальная согласная — зелёным.

Источник изображения: Википедия.
Модифицируем блок хангыля
То есть получается, что один блок хангыля можно описать формулой: Ci V [V] [Cf], где Ci — начальная согласная (возможно, сдвоенная), V — гласная буква, а Cf — финальная согласная (тоже может быть сдвоенной). Такое представление неудобно для распознавания, поэтому изменим его.
Во-первых, объединим обе гласные. Получим формулу Ci V' [Cf], где V» — все возможные варианты объединения букв, считая отсутствие второй буквы. Поскольку в языке 10 гласных, можно было бы ожидать, что в результате получим 10 * (10 + 1) вариантов, но на практике не все они возможны, получается всего 21.
Далее, последней буквы может не быть. Добавим в множество ожидаемых букв в конце пустую. Тогда получим формулу Ci V» Cf*. Таким образом получается, что теперь корейский символ всегда состоит из трёх «букв». Можно учить сетку.
Конструируем сеть
Идея в том, что вместо распознавания символов целиком, мы будем распознавать отдельные буквы в них. Таким образом вместо одного огромного софтмакса в конце у нас получится три небольших, каждый размером примерно в несколько десятков. Они соответствуют первой, второй и третьей «буквам» в слоге. В итоге, у нас получилась такая архитектура:
картинка кликабельная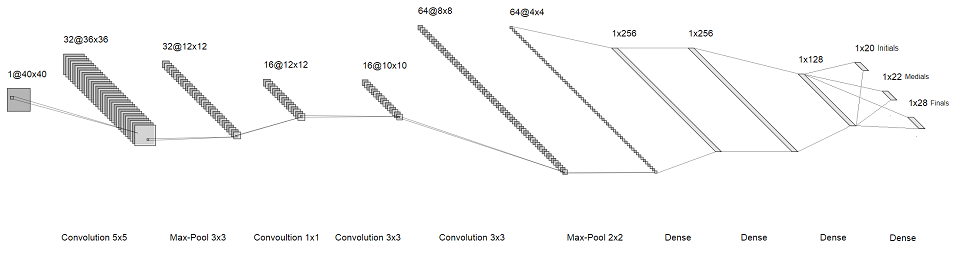
Обучаем, запускаем на отдельной выборке. Качество хорошее, сетка быстрая, да и весит мало. Попробуем вынести её из лабораторных условий в реальный мир.
Решаем проблемы
Первую проблему получим сразу: порой на вход попадают изображения, которые вообще не являются корейскими символами, и сеть на них ведёт себя крайне непредсказуемо. Можно, конечно, обучить ещё одну сеть, которая будет отличать корейские блоки от всего остального, но мы сделаем проще.
Сделаем то же самое, что сделали с третьей группой букв: добавим выход для отсутствия буквы. Тогда формула символа будет иметь такой вид: Ci* V»* Cf*. А в обучающую выборку добавим всякого мусора — китайских иероглифов, неправильно порезанных символов, европейских букв, и будем учить сеть отмечать на ней три пустые буквы.
Обучаем, тестируем. Работает, но проблемы остались. Оказывается, достаточно часто в сетку попадают, например, такие изображения:

Это правильный корейский блок, к которому приклеилась одинарная кавычка. И очевидно, что на них сеть прекрасно находит все три буквы, из которых состоит блок. Вот только изображение не является правильным, и нам требуется сигнализировать об этом. Возвращать тут пустые буквы неправильно, так как на изображении они есть. Попробуем применить то, что уже хорошо показало себя ранее: добавим ещё по два выхода для распознавания таких вот прилипших пунктуаторов. В каждом из них будет по одному дополнительному выходу для ситуации, когда ничего лишнего на изображении нет, но кроме того необходимо добавить ещё один выход для ситуации «пунктуатор есть, но он не распознан, вероятно мусор».
Обучили. Плохо получается у такой сетки распознавать пунктуаторы: запятую от скобки она отличает, а вот от точки уже с трудом. Можно увеличить сложность сетки, но не хочется. Распознаванием пунктуаторов займёмся потом, а пока будем просто выдавать, есть там что-то или нет. Этому сетка научилась хорошо.
С приклеенными пунктуаторами разобрались, но что делать, если наоборот, на изображении отсутствует часть ключа? Было такое вот слово из двух символов, но мы порезали его на символы неправильно:

Сеть тут без особых проблем определяет центральную букву. Это было бы очень полезным качеством, если бы нашей задачей было распознавать только выборку символов, но в реальном мире от этого вред: когда мы неправильно порезали строку на символы, мы должны передать эту информацию выше, так как иначе оставшийся кусочек потом распознается как какой-нибудь пунктуатор, и в результирующем тексте будет лишний символ.
Для решения этой задачи воспользуемся тем, что осталось от каких-то старых экспериментов многолетней давности. Идея распознавать корейские символы по буквам появилась ещё очень давно, и первые попытки были сделаны ещё до эпохи нейросетей, но практического применения эти решения не нашли. Зато с тех пор осталась интересные вещи:
- Разметка того, где у каждого блока какая буква стоит.
- Качественная, пусть и небыстрая вырезалка этих букв из символов.
Смахнув пыль, нагенерируем с помощью этого добра достаточное количество таких вот проблемных изображений без одной из букв и будем специально учить сеть отвечать на них пустую букву.
Всё, с разпознаванием корейских символов проблем больше нет, но жизнь снова вставляет палки в колёса.
Дело в том, что помимо символов хангыля корейские тексты состоят ещё из большого количества других символов: пунктуаторы, европейские символы (как минимум цифры) и китайские иероглифы. Но встречаются они, естественно, значительно реже. Разделим их на две группы: иероглифы и всё остальное, и обучим для каждой из них свою сетку. И сделаем простенький классификатор, который по результатам работы сети для распознавания корейских символов и по некоторым другим признакам (геометрическим, в первую очередь) будет отвечать, нужно ли хотя бы одну из них запускать, и если да, то какую. Европейских символов нужно распознавать немного, так что сетка будет маленькой, а для иероглифов… Спасает то, что в текстах они встречаются редко, поэтому закрутим наш классификатор так, чтобы он очень редко предлагал их распознавать.
Вообще, с этими двумя сетками возникает проблема адекватного ответа на изображениях, не являющихся символами, на которых её обучали, но о том, как решать эту проблему, мы расскажем в другой раз.
Проводим эксперименты
Первый. Есть две базы изображений, условно назовём их Real и Synthetic. Real состоит из реальных изображений, которые получены из отсканированных документов, а Synthetic — изображения, полученные из шрифтов. В первой базе присутствуют изображения для 2374-х блоков (остальные очень редкие), а из шрифтов мы достали все возможные 11172 символа. Попробуем обучить сеть на тех блоках, которые есть в Real (сами изображения будем брать из обеих баз), а протестируем на тех, которые есть только в Synthetic. Результаты:

То есть, примерно в 60% случаев сеть способна распознать те блоки, примеры которых она вообще не видела при обучении. Качество могло бы быть и выше, если бы не одна проблема: среди финальных букв присутствуют очень редкие, и при обучении сеть увидела очень мало изображений блоков в ними. Этим и объясняется низкое качество в последнем столбце. Если бы можно было выбрать 2374 блока, на которых мы обучаемся, по-другому, то качество, скорее всего, было бы заметно выше.
Второй. Сравним нашу сеть с «обычной» сетью, у которой в конце софтмакс. Хотелось бы сделать его размером 11172, но достаточное количество реальных изображений для редких блоков нам не найти, поэтому ограничимся 2374-мя. Качество и скорость работы этой сети зависят от размера скрытых слоёв. Учить будем только на Real, тестировать на ней же (на другой части, разумеется).

То есть даже если ограничиться распознаванием только 2374-х блоков, наша сеть оказывается быстрее и на том же уровне по качеству.
Третий. Предположим, что мы смогли где-то достать огромную базу всех 11172-х корейских блоков. Если мы на ней обучим сеть с софтмаксом, сколько она будет работать по времени? Все эксперименты проводить затратно, поэтому рассмотрим только сеть с размерами скрытых слоёв 256:

Получаем результаты

Без них ничего бы не получилось
Выражаю признательность моему коллеге Юре Чулинину, первоначальному автору идеи. Она запатентована в России, и, кроме того, аналогичная заявка подана в американское патентное ведомство (USPTO). Большое спасибо разработчику Мише Зацепину, который всё это реализовал и провёл все эксперименты.
Юрий Ватлин,
руководитель Complex Scripts group
