FlexiCapture. Так ли он гибок, как называется?
 О продукте FlexiCapture, как показывает опыт, обычные пользователи за пределами компании знают совсем мало («Уж не этим ли ЕГЭ распознают?»), несмотря на то, что он используется во многих крупных организациях. Можно с этим мириться, считая, что продукт не для конечного пользователя, а корпоративный. А можно периодически рассказывать про него всякое, что будет не только полезно тем, кто с ним уже знаком, но и намекнёт далёким от продукта людям, что Flex — это не просто 4 буквы в названии.Наши партнеры из новосибирской компании АТАПИ Софтвер поделились своим приемами обработки разных сложных случаев. Это набор конкретных практических советов, которые, мы надеемся, будут вам полезны. Кроме того, каждая из этих историй подобна дзенскому коану — помогает раскрыть истинную природу FlexiCapture во всем ее многообразии.
О продукте FlexiCapture, как показывает опыт, обычные пользователи за пределами компании знают совсем мало («Уж не этим ли ЕГЭ распознают?»), несмотря на то, что он используется во многих крупных организациях. Можно с этим мириться, считая, что продукт не для конечного пользователя, а корпоративный. А можно периодически рассказывать про него всякое, что будет не только полезно тем, кто с ним уже знаком, но и намекнёт далёким от продукта людям, что Flex — это не просто 4 буквы в названии.Наши партнеры из новосибирской компании АТАПИ Софтвер поделились своим приемами обработки разных сложных случаев. Это набор конкретных практических советов, которые, мы надеемся, будут вам полезны. Кроме того, каждая из этих историй подобна дзенскому коану — помогает раскрыть истинную природу FlexiCapture во всем ее многообразии.
При обработке нестандартных таблиц будь безмятежен, как цветок лотосаОсновное предназначение ABBYY FlexiCapture — извлекать из документов определенные данные и заносить их в информационную систему. В России большинство документов унифицировано, поэтому обычно это не вызывает трудностей. К несчастью, такого не скажешь о зарубежных документах — скажем, о европейских счетах-фактурах — да и некоторые российские формы «отжигают» не хуже своих зарубежных собратьев. Часто встречаются случаи, когда необходимая информация в таблицах разграничена недостаточно четко, например, вот так: 
Здесь в таблице есть две строки с описанием товарных позиций. Если для распознавания такого документа использовать автоматический способ, номенклатурный номер товара (крайнее левое поле) попадет в отдельную колонку и будет распознан верно, а вот поля количество и артикул (третья колонка) попадут в одну и ту же колонку, хотя в нашей таблице это разные поля. Кроме того, в колонки может попасть много лишней текстовой информации — это создаст проблемы при верификации.
Разделить искомые данные на отдельные поля можно с помощью функциональности повторяющейся группы. В Flexilayout Studio создаем элемент типа «повторяющаяся группа» (Repeating Group). Каждый экземпляр группы будет соответствовать строке таблицы, внутри области которой уже организовывается поиск с использованием простых элементов (типа Static Text, Character String, Region и т.д.). В свою очередь, область каждой строки может быть так же выделена с помощью повторяющейся группы, предваряющей поиск непосредственно информации.
Это, пожалуй, лучшее решение для подобных случаев. Однако, надо не забывать, что кроме собственно распознавания, нам нужно привести данные из такой не совсем стандартной таблицы к обычному табличному виду:

Зачем это нужно? Операторам верификации проще обрабатывать данные, когда они представлены в виде таблицы. Кроме того, очень часто бывает, что стандартные и нестандартные таблицы поступают на верификацию друг за другом, и если делать для каждого случая отдельный шаблон, оператору будет трудно переключаться с одного способа представления данных на другой — поэтому он неминуемо начнет делать ошибки.
И еще один момент. На следующем примере видно, что представлять сложные нестандартные таблицы в виде повторяющейся группы в интерфейсе не совсем удобно — такое представление занимает много места.
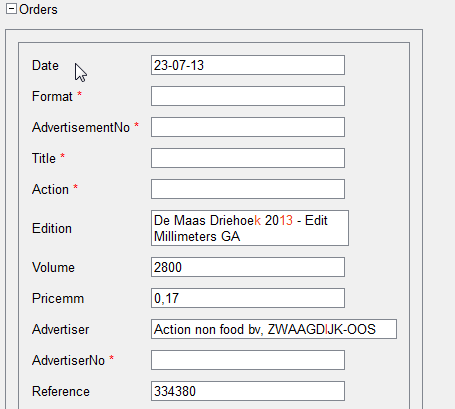
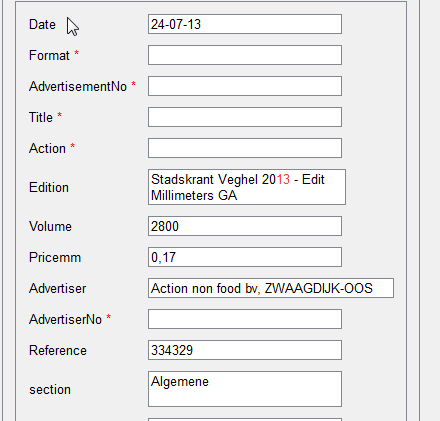
Сравним это с представлением аналогичных данных в виде таблицы:

Как мы видим, в таком виде (как таблица) данные занимают намного меньше места, и у оператора появляется возможность проверять документы быстрее — не тратя время на скроллинг.
Чтобы ускорить процесс верификации и сделать его единообразным, мы используем следующий подход:
На уровне гибкого описания ищем нужные данные с помощью повторяющейся группы, находим таким образом регионы отдельных строк. Затем в пределах региона каждой строки извлекаем необходимые поля.
Далее создаем фиктивную таблицу с таким же количеством строк, как в повторяющейся группе. Фиктивная таблица — это таблица, которая наложена в произвольном регионе, то есть она присутствует на форме данных, но не привязана к конкретному изображению документа.
В проекте FlexiCapture, в настройках определения документа, пишем простое скриптовое правило — оно будет копировать значения из полей, которые система находит в повторяющейся группе, в соответствующие колонки таблицы.
Сами поля на форме данных можно скрыть, так как вся информация теперь будет храниться и показываться в таблице.
Избегай пасти тигра, улучшая распознавание табличных данных
При работе с таблицами карма разработчика — большое количество различного текстового «мусора» в ячейках с данными. Например, нам надо извлечь цифровое значение Код по ОКВЭД и Дата внесения сведений в ЕГРЮЛ из следующей таблицы: 
Если сделать простую таблицу, то в ячейку с кодом будет попадать текстовое описание вида деятельности («Сдача внаем собственного недвижимого имущества»), которое нужно будет удалять либо разработчику с помощью скрипта, либо каждый раз вручную — оператору. Кроме того, в регион таблицы также могут попадать помарки, пометки, штампы, подписи и т.д.
Чтобы подобная лишняя информация не мешала распознаванию, мы можем на уровне гибкого описания отфильтровать эти объекты — задать правила, при помощи которых система будет автоматически находить их и игнорировать при распознавании. В случае с нашим примером достаточно будет настроить «игнор» всех текстовых объектов с русскими буквами и скобками.
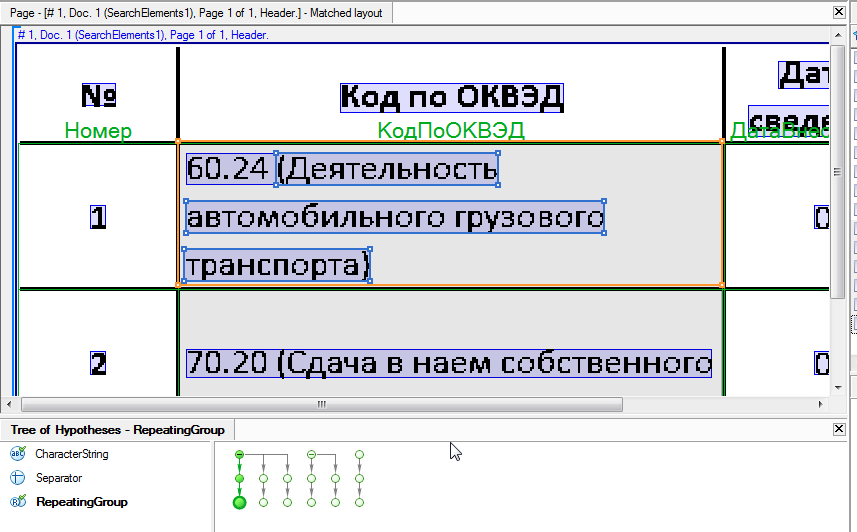
Как видно на рисунке ниже, во FlexiCapture 10 данное поле будет исключено из области распознавания (прямоугольники с серой штриховкой).

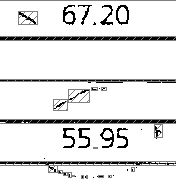
Или же можно пойти от обратного — сначала с помощью повторяющейся группы найти только нужные нам данные (цифровые коды), а затем исключить из распознавания все текстовые или иные объекты изображения из колонки «Код по ОКВЭД», отличные от непосредственно кода.Примеры таких подходов представлены на картинке ниже: слева мы исключили фиксированный текст MACHINE REAMER 600 первым способом, а на правой — все, кроме цифр, вторым способом:

Настрой вариационное распознавание поля — позволь зеркалу ума отделить красивое от не очень
Бывает так, что формат одного и того же поля сильно различается в однотипных документах. Например, в зарубежных счетах-фактурах может встречаться как обычный черный текст на белом фоне, так и белый текст на черном фоне. Подобную ситуацию мы можем видеть в бланках разнообразных анкет, опросников и т.д.

А бывает и так, что шаблон один, а в реальности на распознавание документы приходят вперемешку — в одних данные впечатаны на принтере, а в другие вписаны человеком так называемым рукопечатным способом.


Не меньше казусов порождает различный формат данных в одних и тех же полях. Если в одном документе будет указана дата в формате 23-февраля-2006, а в другом — 24/11/08, человек поймет, а программе желательно при этом указать разные настройки для этого поля.


Все эти случаи могут вызвать затруднения с распознаванием. ABBYY FlexiCapture позволяет создать два отдельных поля и задавать им разные настройки распознавания: инвертированный или обычный текст, печатный или рукопечатный, распознавание в общей рамке или рисование отдельной рамки на каждый символ. Затем при обработке каждого документа оператор вручную выбирает верный вариант для поля.
Но можно еще немного усовершенствовать процесс распознавания. Первый вариант — обрабатывать документы в разных типах пакетов. Но это тоже довольно неудобно, так как нужно разделять документы на этапе сканирования, да и операторы в конечном итоге могут просто запутаться, куда какой документ отправлять. Зачем грузить оператора лишней работой, когда с этой задачей может справиться программа?
Мы использовали следующий алгоритм. В том месте, где у нас должен находиться искомый текст, создаем три поля:
первое — скрытое от пользователя поле, которое распознает обычный текст,
второе — тоже скрытое поле, которое распознает текст как инвертированный,
третье — видимое пользователю поле, в котором оператору подается на проверку тот из результатов распознавания, который система оценивает как лучший.
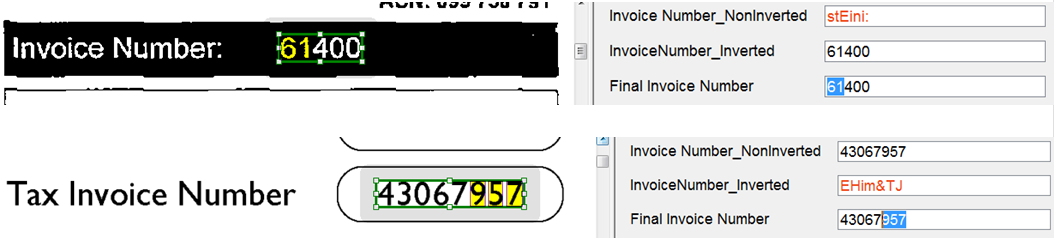
Лучший результат система может выбрать, например, исходя из количества так называемых «подозрительных символов» (Suspicious Symbols) — для этого нужно создать скриптовое правило, которое передает как результат распознавания значение поля с наименьшим количеством «подозрительных символов».
Аналогичный подход с тремя полями и выбором наилучшего варианта распознавания можно использовать для случаев разной разметки или печатного/рукопечатного текста в одном поле.
Как вернуть все сущее к единому: выделение дробной части чисел
Казалось бы, какая проблема может быть с дробями? Те же цифры и точки-запятые. Но иногда разделительные знаки дроби не распознаются или исчезают при сканировании, что может привести к неприятным последствиям. Например, итоговая сумма в бумажном счете-фактуре одна, а в электронном — другая (в ней появляется пара лишних нулей). Такое случается, например, при обработке документов, переданных по факсу, распознавании старых документов или с документов с плохим качеством печати.
В FlexiCapture решить такую задачу не очень сложно.
Обычно число знаков в дробной части варьируется от 0 до 2. Чтобы понять, есть ли в распознанном тексте разделитель, нам нужно:
Вычислить расстояние между последним и предпоследним символами в строке. Для этого от х координаты правой границы предпоследнего символа отнимаем х координату левой границы последнего символа. Это будет S1 Если число символов в строке равно двум: сравниваем S1 с некоторым коэффициентом, если S1 больше этого значения, то нужно добавить разделитель.
Если число символов в строке больше двух, то необходимо вычислить расстояние S2 между 2 и 3 символами с конца строки.
Посчитать отношения S1/S2 и S2/S1
Если какое-то из отношений больше коэффициента, например, 1.5, то вставляем разделитель между соответствующими символами.Это решение применялось в одном из наших проектов в Австралии. Ниже приведен пример исходного изображения и результаты распознавания — с нашим «улучшайзингом» и без него.
Если число символов в строке равно двум: сравниваем S1 с некоторым коэффициентом, если S1 больше этого значения, то нужно добавить разделитель.
Если число символов в строке больше двух, то необходимо вычислить расстояние S2 между 2 и 3 символами с конца строки.
Посчитать отношения S1/S2 и S2/S1
Если какое-то из отношений больше коэффициента, например, 1.5, то вставляем разделитель между соответствующими символами.Это решение применялось в одном из наших проектов в Австралии. Ниже приведен пример исходного изображения и результаты распознавания — с нашим «улучшайзингом» и без него.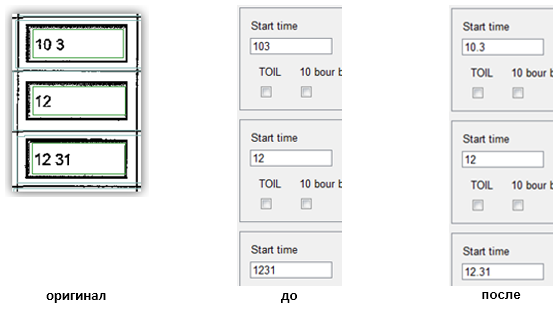
В счете-фактуре, кстати, результат распознавания довольно легко проверить по контрольной сумме. Если в распознанном документе значение поля «Итого» сойдется с суммой по таблице — значит, можно верифицировать результат распознавания без участия оператора. Также может помочь сравнение суммы цифрами с суммой прописью, если такая есть в документе.
Чтобы автоматизировать подбор коэффициентов, можно анализировать среднее расстояние между символами в строке, отношение между высотой и шириной символов и т.д., но, как правило, проще подобрать коэффициенты экспериментальным путем, или методом научного «тыка». Время, которые вы потратите на подбор этих коэффициентов, исчисляется минутами — в то время как оператору верификации такой подход может сэкономить часы работы.
Под взглядом Будды и на железном дереве распустятся цветы. Что делать, если вам нужен полный текстовый слой документа Мы уже писали, ABBYY FlexiCapture нужна, чтобы извлекать и сохранять конкретные данные из полей: цифры, имена контрагентов и прочее, полный текст документа, как правило, никого не интересует. Но случается и так, что нужно в одном потоке извлекать данные из полей для одних документов и распознавать текст целиком для других.Возможность извлекать весь текст документа в виде текстового файла может понадобиться, например, для индексации содержимого документа в различных поисковых системах — как широкого пользования, так и внутрикорпоративных.
Такая необходимость возникла у мэрии Новосибирска, которая обрабатывала документы органов власти — приказы, постановления и распоряжения. Им нужны были не только поля из «шапки» документа, по которым документ индексировался в архиве, но и результаты полнотекстового распознавания, чтобы была возможность потом найти документ по ключевому слову из основной части.
Во FlexiCapture уже давно есть возможность настроить экспорт распознанных документов в PDF с текстовым слоем. Но реальность такова, что многие внешние информационные системы не умеют искать по PDF-документам. Более того, что касается именно новосибирского архива, который хранит данные с начала 1920-х годов — многие бумажные первоисточники, которые мы видели, представляли собой довольно ветхие, выцветшие страницы, отпечатанные на печатной машинке. Можно ожидать, что результаты автоматического распознавания для таких файлов могут быть не очень качественными. В то же время именно текстовое содержимое такого архивного документа, а не его шапка, может быть очень важно. Поэтому хорошо бы иметь возможность во FlexiCapture на этапе проверки важных данных (в нашем случае это были номер приказа, дата и т.д.) проверить еще и результаты полнотекстового распознавания.
Решение нашлось. Во FlexiLayout Studio (об этом инструменте для создания гибких описаний мы уже писали) можно создать гибкое описание документа, которое позволит, помимо значимых структурированных данных, извлекать еще и весь текстовый слой документа. Делается это очень просто — например, с помощью повторяющейся группы, которая содержит все строки документа.
Если необходимо, этот текстовый слой можно даже проверить на станции верификации FlexiCapture. Также текст можно будет копировать, индексировать и экспортировать в текстовые форматы. В итоговом PDF-документе мы получим более качественный результат распознавания текстового слоя, так как этот результат будет проверен оператором.
Ниже приведен скриншот со страницы верификации ABBYY FlexiCapture. Как мы видим, теперь можно работать не только с полями, но и со всем текстом в документе.
Спасибо за терпение внимание, осталось всего 3 предложения Мы привели несколько инженерных лайфхаков, которые, надеемся, помогут вам в работе с нашим продуктом.Если есть, что добавить — вы решили какую-то еще нестандартную проблему при помощи FlexiCapture — мы будем рады почитать об этом в комментариях.Татьяна Ганьжина, ABBYY Россияпри активной поддержке специалистов «АТАПИ Софтвер».
