Fault Tolerance Web Architecture for Our Cloud Solutions

Hi Habr,
I’m Artyom Karamyshev, a system administration team leader at Mail.Ru Cloud Solutions (MCS). We launched many products in 2019. We’ve aimed to make API services easily scalable, fault-tolerant, and ready to accommodate rapid growth. Our platform is running on OpenStack, and in this article, I describe all the component fault tolerance issues that we’ve resolved.
The overall fault tolerance of the platform is consists of its components fault tolerance. So, I’m going to show you step by step tutorial about all levels where we’ve found the risks.
Fault tolerance of physical architecture
The public segment of the MCS cloud based on two Tier III data centers having their own 200 Gb/s dark fiber connection between them. This connection is implemented via several routes, which provides its physical redundancy, while Tier III provides the required level of physical infrastructure fault tolerance.
The dark fiber is redundant at both physical and logic levels. We achieved channel redundancy in iterations, and we still keep improving communication between the data centers.
For instance, during the excavator’s works near one of the data centers, the pipe was damaged. It turned out that both primary and backup fiber-optic cables were inside the same pipe. Our fail-safe communication link to the data center turned out to have a single point of failure. So we’ve taken actions, including a supplementary optical link routed in a separate pit.
In our data centers, there are CSP points of presence to whom we send our prefixes via BGP. The best metric is chosen for each network destination enabling the best connection quality for each client. Whenever connection through a provider is lost, we re-route it through the other available providers.
If we have a failure on a provider’s side, we switch to another one automatically. In case of failure in one data center, we have a mirrored copy of our services in another one, which takes the total traffic.
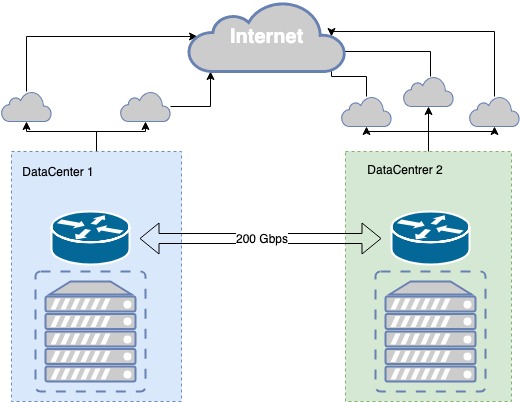
The fault tolerance of physical infrastructure
What we use for application-level fault tolerance
Our service developed with several open-source components.
ExaBGP: a service that implements some functions using BGP-based dynamic routing protocol. We use it extensively to announce our white IP addresses for user access to API.
HAProxy: a high load balancer that enables defining very flexible traffic balancing rules at different OSI model levels. We use it for load balancing of all services: databases, message brokers, API services, web services, and all our internal projects are using HAProxy.
API application: a python web application for managing user’s infrastructure and services.
Worker application (the Worker): in OpenStack services, this is an infrastructure daemon that enables the translation of API commands to infrastructure. For instance, in the Worker we create a disc, and this is done upon a request from the API application.
Standard OpenStack application architecture
Most services developed for OpenStack tend to follow a unified paradigm. A service generally comprises two parts: API and Workers (backend executors). Basically, an API is a WSGI application written in python, which is launched either as an independent process (daemon) or through a readily available Nginx or Apache Web server. The API processes a user’s request and conveys further execution instructions to the Worker application. The instructions are conveyed through a message broker — usually, it is RabbitMQ, as others are poorly supported. Workers process messages when they get to the broker and return a response when required.
This paradigm implies isolated common points of failure: RabbitMQ and database. RabbitMQ is isolated within a single service, and you can assign each service its own RabbitMQ. So, at MCS, we split those services as much as possible and create a dedicated database and a dedicated RabbitMQ for each project. This approach is better, because, in case of a disaster at some vulnerable points, only a part of service gets broken, but not the whole service.
The number of Worker applications is not limited by anything; therefore, API can be easily scaled horizontally after the balancers to enhance performance and fault tolerance.
Some services require coordination within the service when complex sequential operations occur between API and Workers. In this case, a single coordination center is used — a cluster system like Redis, Memcache or etcd — which enables Workers to tell one another which tasks are already taken («don’t take this one, cause I’m on it»). We use etcd. Generally, Workers extensively communicate with the database, writing to and reading from it. We use mariadb as our database, which resides in a multi-master cluster.
This classic single service organized in a standard way for OpenStack. It can be considered as a closed-loop system for which scaling and fault tolerance assurance methods are quite obvious. For instance, it is enough to place a load balancer before API to make it fault-tolerant. Workers can be upscaled by adding more Workers.
Still, the weak points of this whole arrangement are RabbitMQ and MariaDB. Their architecture is worth writing a separate article. Here, I’d like to focus on another aspect, API fault tolerance.
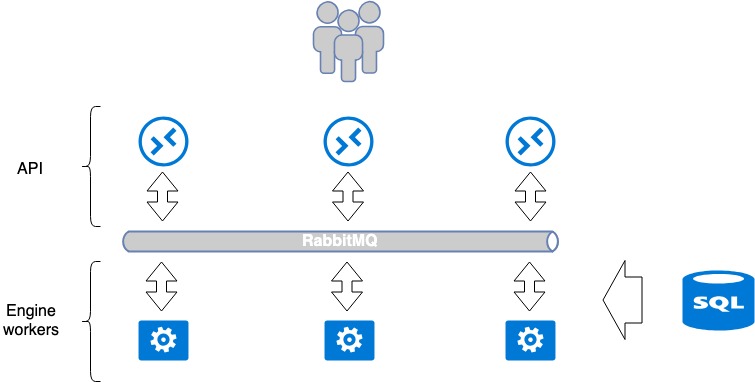
Openstack Application architecture. Cloud platform balancing and fault tolerance
Making HAProxy balancer fault tolerant using ExaBGP
To make our APIs scalable, fast, and fault-tolerant, we placed a balancer before them. We chose HAProxy. To my mind, it has all the necessary features: load balancing at several OSI levels, control interface, flexibility, and scalability, a number of balancing methods, and support of session tables.
The first issue to be resolved was assuring the fault tolerance of the balancer itself. In fact, the installation of a balancer creates another point of failure: when a balancer fails, its service dies. To avoid this, we used HAProxy in combination with ExaBGP.
ExaBGP enables service status checks. We used this to test HAProxy functioning and to withdraw HAProxy service from BGP in case of any issues.
ExaBGP+HAProxy arrangement
- Deploy the necessary software, ExaBGP, and HAProxy, on three servers.
- Create a loopback interface on each server.
- Assign the same white IP address to this interface on the three servers.
- The white IP address is announced to the Web via ExaBGP.
Fault tolerance is achieved by announcing the same IP address from all the three servers. From the network perspective, the same address is available from three different next hops. The router sees three identical routes, chooses the top priority route according to its own metric (usually it’s the same route), and the traffic flows to only one server.
In case of HAProxy operation issues or server failure, ExaBGP stops announcing the route, and traffic switches to another server smoothly.
Thus, we’ve achieved load balancer fault tolerance.
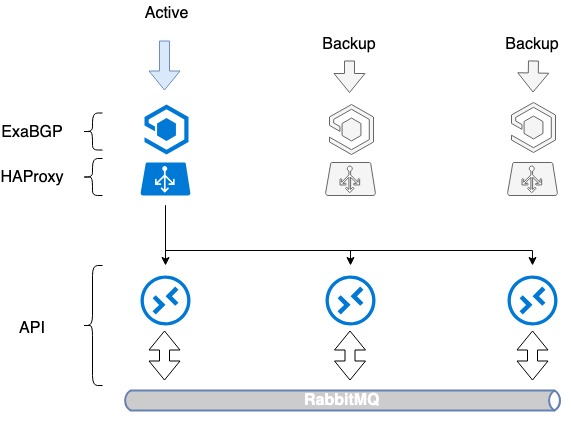
HAProxy load balancers fault tolerance
The resulting arrangement is not perfect: it makes HAProxy fail-proof, but it doesn’t distribute the load within services yet. So we extended the arrangement: we enabled balancing among several white IP addresses.
Balancing with DNS and BGP
The issue of load balancing before our HAProxies remained. It could be resolved quite easily, as we have done within our facilities.
Balancing the 3 servers requires 3 white IP addresses and a good old DNS. Each of those addresses is assigned to each HAProxy’s loopback interface and is announced to the Web.
In OpenStack, a service catalog used for resource management, which defines endpoint API for a particular service. In the catalog, we specify the domain name: public.infra.mail.ru, which is resolved via the DNS into three different IP addresses. As a result, the load gets distributed among the three addresses through the DNS.
However, as we do not control server choice priorities when white IP addresses are announced, this is not a good load balancing yet. Usually, only one server will be chosen according to IP address seniority, while the other two will stay idle since no metric specified in BGP.
We began to provide routes via ExaBGP with different metrics. Each load balancer announces all the three white IP addresses, but the main one (for that load balancer) is announced with the minimum metric. Thus, while all the three balancers are in service, calls to the first IP address come to the first load balancer, and calls to the second and the third addresses come to the second and the third load balancers, accordingly.
What happens if one of the load balancers fails? In case of any load balancer’s failure, its main address is still announced from the other two balancers, and traffic among them is redistributed. Thus, we provide several IP addresses at a time to the user via the DNS. Through DNS-based load balancing and different metrics, we achieve even load distribution to all the three load balancers, while maintaining fault tolerance.
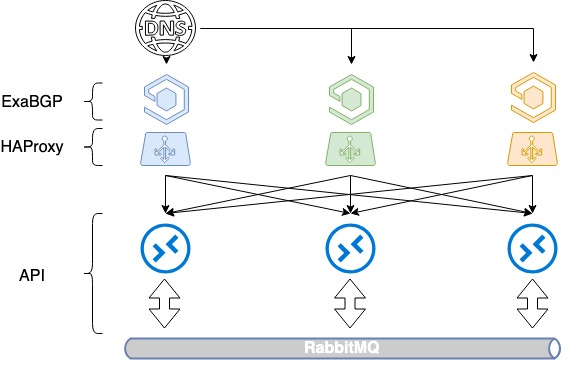
HAProxy balancing based on DNS + BGP
Interaction between ExaBGP and HAProxy
So, we have implemented fault tolerance based on route announcement termination for remediation in case of server failure. However, HAProxy can fail for the reason that differs from server failures, such as administration error or within-service fault. We wish to withdraw the failed load balancer from load operation in such cases as well, so we need another facility to do this.
Thus, we have expanded the former arrangement and implemented a heartbeat between ExaBGP and HAProxy. This is a software implementation of the interaction between ExaBGP and HAProxy, where ExaBGP uses custom scripts to check application status.
For this, a health checker needs to be set up in the ExaBGP configuration that will be able to check the status of HAProxy. In this case, we have set up a health backend in HAProxy, the check on the ExaBGP side being done by a simple GET request. If the announcement ceases to occur, then HAProxy is, most probably, out of service, and it should not be announced.
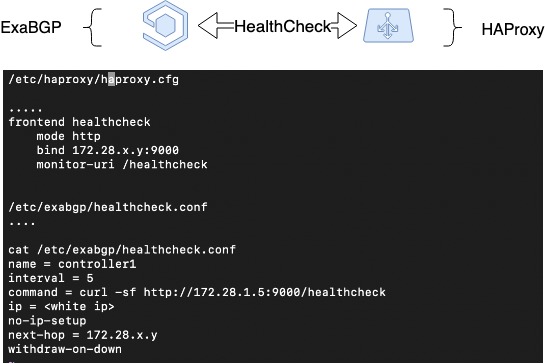
HAProxy Health Check
HAProxy Peers: session synchronization
The next thing to do was to synchronize sessions. It is difficult to arrange the preservation of client session information while operating through distributed load balancers. But HAProxy, one of the few balancers able to do that through the Peers feature, has capabilities for sharing a session table among different HAProxy processes.
There is a variety of load balancing methods: the basic ones, such as round-robin, and the advanced ones, where a client’s session is stored in memory, and the client gets to the same server as before. We chose to implement the latter option.
In HAProxy, stick tables are used to save client sessions in this implementation. They store the client’s original IP address, the chosen target address (backend), and some ancillary information. Generally, stick tables are used for storing the source IP + destination IP pair, which is especially beneficial for those applications which cannot convey user session context when switching over to another load balancer, for example, in the case of RoundRobin balancing.
If we can make a stick table to move from one HAProxy process to another (between which the load balancing occurs), then our balancers will be able to deal with a single pool of stick tables. That enables seamless switchover of client network if one of the load balancers fails, and client sessions continue to be handled on the same back ends that had been chosen earlier.
The issue that must be resolved before the proper operation could be ensured is the problem with the source IP address of the balancer, from which the session has been established. In this case, it is the dynamic address on the loopback interface.
Proper operation of peers can only be achieved in particular conditions. That is, TCP timeouts must be long enough, or otherwise, the switchover must be quick enough for TCP session not to be disconnected. However, this does not enable a seamless switchover.
We have a service in IaaS that built upon a similar technique. It is the Load Balancer as a Service for OpenStack named Octavia. It is based on two HAProxy processes and has built-in support for Peers. They have proven to work very well in this service.
The picture outlines movements of peer tables among three HAProxy instances and proposes a possible configuration for setting this up:
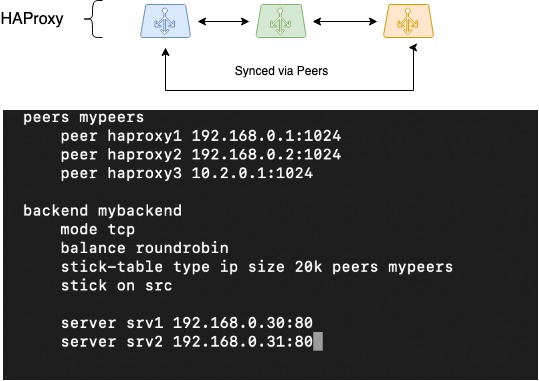
HAProxy Peers (session synchronization)
If you are going to implement a similar arrangement, its operation should be thoroughly tested. It is far from certain that it will work in the same form in 100% of instances. At least, you are not going to lose stick tables when a client IP needs to be stored.
Limiting the number of simultaneous requests from the same client
Any generally accessible services, including our APIs, can be subjected to an avalanche of requests. The reasons can be quite diverse, from a user error to a targeted attack. We are DDoS attacked at IP addresses from time to time. Clients make errors in their scripts, causing mini DDoS attacks on us.
This way or another, we need some additional protection. An obvious solution is to limit the number of API requests and avoid wasting CPU time processing malicious requests.
To implement such a limitation, we use rate limits that are arranged based on HAProxy, again, using stick tables. The limits can be set quite easily, and they enable limitation of the number of user requests to API. The algorithm stores the source IP from which requests are received, and limits the number of simultaneous requests from every single user. Of course, we have determined a mean API load profile for each service and set a limit that is ~10 times bigger. We keep monitoring the situation closely.
What does it look like in practice? We have customers who use our APIs regularly for autoscaling. They create two or three hundreds of virtual machines by the morning and delete them by the evening. For OpenStack, creating a virtual machine, coupled with PaaS services, means 1,000 API requests as a minimum, since interactions among services also run through APIs.
Task rearrangements like these result in a rather high load. We evaluated this load, collected daily peak data, multiplied it by ten, and there was our rate limit. We keep track of new developments. We often see scanner bots trying to find out if we have any CGA scripts that could be executed, and we cut them off diligently.
How to update codebase seamlessly
We implement fault tolerance at the level of code deploy processes as well. Faults may occur during roll-outs, but their impact on server availability can be minimized.
We keep updating our services all the time, and we should ensure that our codebase is updated with no effect on users. We could achieve this by using HAProxy control capabilities and implementing a graceful shutdown in our services.
To do that, we had to provide load balancer control and «appropriate» shutdown of services:
- In the case of HAProxy, control is performed through a stats file, which is essentially a socket and is defined in HAProxy configuration. Commands can be communicated to it via stdio. But our primary tool for configuration control is ansible; therefore, it has an integrated module for controlling HAProxy. We use it extensively.
- Most of our API and Engine services support graceful shutdown techniques: in case of a shutdown, they wait until final completion of the current task, whether that is an HTTP request or some auxiliary task. The same refers to a Worker. It knows all the tasks it performs, and it terminates upon successful completion for all of them.
Thanks to the above two points, the safe algorithm of our deployment looks as follows:
- A developer compiles a new code package (we use RPMs), tests it in the development environment, then tests it on the stage, and then send it to the staging repository.
- A developer sets a deploy objective with a description of «artifacts» in their maximum detail: the new package’s version, the description of its new functionality, and other deploy details when required.
- A system administrator starts the updating process. An ansible playbook is launched, which, in turn, does the following:
- Takes a package from the staging repository and updates the package version in the product repository accordingly;
- Compiles a list of backends of the service being updated;
- Shuts down the first service being updated in HAProxy and waits until the completion of its processes execution. With a graceful shutdown, we can be sure that all current client requests will be completed successfully.
- Code updating will occur upon a complete shutdown of APIs and Workers and HAProxy being stopped.
- Ansible launches services.
- It pulls particular «levers» that perform the unit testing across an array of predefined key tests. Basic verification of the new code occurs.
- If no error has been detected at the previous step, then the backend will be activated.
- Then we proceed to the next backend.
- Once all backends are updated, functional tests start. If those tests are not sufficient, the developer looks at any new functionality that they have implemented.
This ends the deploy.
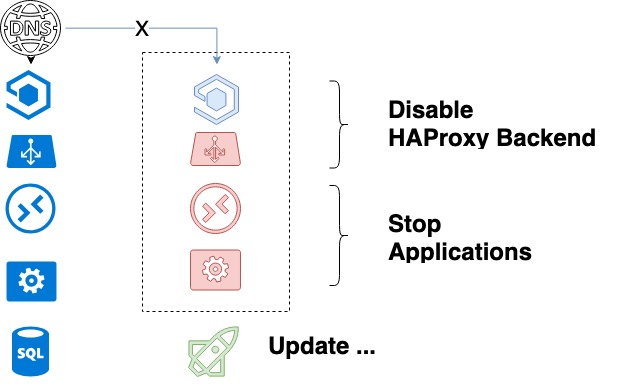
The service updating cycle
This arrangement would not work if we didn’t follow one additional rule. We keep both the old version and the new version operational. It is designed into any of our new software from its development stage that even if there are any changes in the service’s database, those changes will not break the previous code. As a result, the codebase is updated gradually.
Conclusion
As I share my own thoughts about fault-tolerant web architecture, I would like to highlight its key points once again:
- Physical fault tolerance.
- Network fault tolerance (load balancers, BGP).
- Fault tolerance of the third-party and own software.
Stable uptime to all!
