Facebook опубликовала датасет лиц с указанием пола, возраста и тональности цвета кожи
Facebook AI представила открытый исходный код набора данных, предназначенного для выявления предубеждений по возрасту, полу и цвету кожи в моделях компьютерного зрения и машинного обучения. Набор «Случайные беседы» (Casual Conversations) включает 45 186 видеороликов участников и является первым в своем роде датасетом, в котором люди сами указали свой возраст и пол.

Ранее исследования показали, что в современные модели классификации изображений, обученные в ImageNet, популярном наборе данных из открытых источников, автоматически закладываются человеческие предубеждения относительно расы, пола, веса и т. д. Осенью прошлого года исследователи Университета Колорадо в Боулдере продемонстрировали, что ИИ от Amazon, Clarifai, Microsoft и других поддерживает уровень точности выше 95% для цисгендерных мужчин и женщин, но ошибочно идентифицирует трансгендерных мужчин и женщин в 38% случаев. Независимые тесты систем основных поставщиков, проведенные проектом Gender Shades и Национальным институтом стандартов и технологий (NIST), также продемонстрировали, что технология распознавания лиц демонстрирует расовую и гендерную предвзятость.
В разработке нового датасета Facebook приняли участие более 3 тысяч человек. Они проживают в Атланте, Хьюстоне, Майами, Новом Орлеане и Ричмонде.
Facebook сообщает, что тональность кожи оценивается с помощью схемы классификации цвета, разработанной в 1975 году американским дерматологом Томасом Б. Фицпатриком. Шкала Фитцпатрика — это способ приблизительно оценить реакцию типов кожи на ультрафиолетовое излучение, от типа I (бледная кожа, которая не загорает) до типа VI (глубоко пигментированная кожа, которая никогда не сгорает). Кроме того, изображения соотносили с условиями окружающего освещения, что помогло измерить, как модели считывают разные оттенки кожи в условиях низкой освещенности.
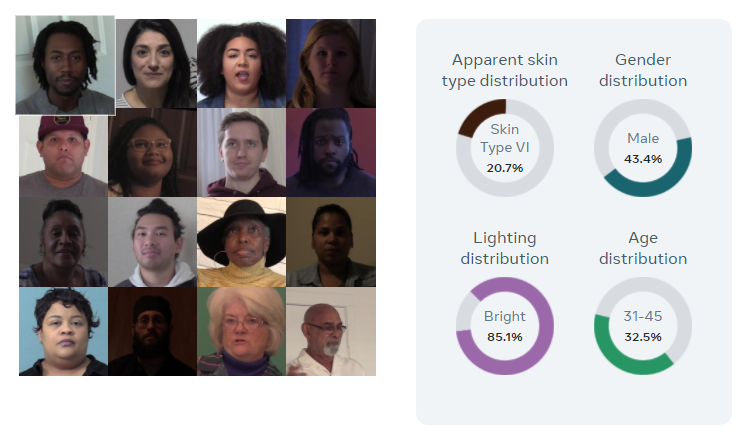
Facebook заявляет, что не собирал информацию о том, откуда родом участники проекта. Вопрос об их поле включал варианты ответа «мужской», «женский» и «другой».
 Для создания датасета с каждым участником записали по 15 роликов
Для создания датасета с каждым участником записали по 15 роликовКомпания отмечает, что продолжит разрабатывать подобные методы. Набор данных планируется расширить в следующем году, чтобы он стал еще более инклюзивным.
Кристиан Кантон, менеджер по исследованиям Facebook AI Red Team, рассказал, как набор данных может быть использован разработчиками. По его словам, через него можно пропускать камеры отслеживания, чтобы выявить слабые места.
Звуковая часть видеозаписей, как указал Кантон, также представляет потенциальный интерес.
Ранее Facebook показала модель машинного зрения SEER, которая, как утверждается, превзошла существующие модели искусственного интеллекта при прохождении теста ImageNet. Точность SEER составила 84,2%. ИИ был обучен с помощью миллиарда общедоступных изображений из Instagram. Как пишут в Facebook, в то время как многие модели ИИ обучаются на тщательно отобранных датасетах, SEER научился определять объекты, анализируя случайные изображения. В Facebook надеются, что она станет шагом для разработки моделей с «интеллектом человеческого уровня».
