Эволюция процессов CI/CD в more.tv
Про CI/CD написано много разных статей и в них рассказывают о том, как это помогает увеличить TTM (time to market), позволяет автоматизировать рутинные вещи (например автотесты и различные проверки) и как деплоить в продакшен без отказа в обслуживании.
Мы в more.tv — не исключение и тоже стремимся к улучшению этих показателей при организации CI/CD.
Я Дмитрий Зайцев — руководитель отдела DevOps, и в этой статье расскажу вам, по какому пути прошли мы, какие особенности есть в нашей работе, какие задачи решали на каждом этапе и к чему в итоге пришли.
Сразу отмечу — мы используем Gitlab, поэтому все процессы будут описаны именно в контексте использования Gitlab CI/CD.
Этап 0. С чего всё началось
Шёл 2019 год, времени до запуска у нас было немного, человеческий ресурс тоже ограничен. В наличии не более 10 микросервисов, три кластера Kubernetes (dev и 2 prod).
Мы решили ничего не катить автоматом, а развернуть сервисы руками силами инженеров. Для деплоя в dev — использовался bash-скрипт. При этом команд было несколько, так что деплой от команды к команде мог отличаться, так же, как и их чувство прекрасного. Откат, при необходимости, осуществлялся вручную инженером.
Если тезисно фиксировать, что у нас было:
Есть деплой в тестовую среду.
Выкатка в прод контролируется инженерами, сами релизы очень редки.
Какие при этом были проблемы:
Нет унификации процессов.
Скрипт деплоя часто сбоил, приходилось тратить время на его дебаг.
Откаты только вручную.
Тестов в пайплане не было никаких (только unit-тесты разработчиков).
Итак, мы запустились, началась фаза активного развития, количество микросервисов быстро росло (параллельно с этим продолжали распиливать старый монолит). Количество тестовых сред тоже увеличилось (теперь это stage и preprod, 2 prod).
Стало ясно, что дальше на этом CI/CD мы далеко не уедем, так что решили его модернизировать, чтобы получить следующие возможности:
Контроль состояния деплоя и как следствие — откаты релизов в случае неудачи.
Унификация процессов CI/CD без необходимости править gitlab-ci.yaml в каждом проекте микросервиса.
Возможность удалять сервисы на тестовых средах по кнопке.
Возможность в будущем добавлять дополнительные этапы.
Этап 1. Обновление CI/CD пайплайна
Во-первых, бороться решили с разными gitlab-ci.yaml в репозиториях сервисов. Когда сервисы можно пересчитать по пальцам одной руки, то редактировать каждый еще можно себе позволить. Когда их переваливает за десяток и число продолжает быстро расти — поддерживать это становится невозможно.
Поэтому мы воспользовались возможностью в gitlab-ci ссылаться на другие проекты и даже ветки. Так у нас появился отдельный репозиторий templates, в котором мы стали собирать различные общие процессы:
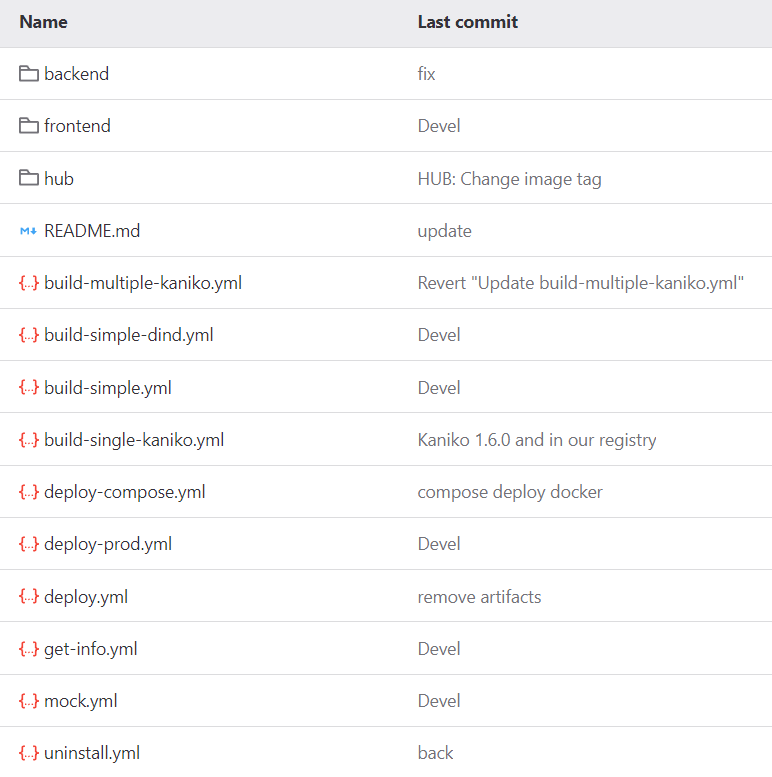
В самих микросервисах gitlab-ci.yaml стал выглядеть так
stages:
- tests
- update_latest_image
- release
- deploy
- "get info"
- uninstall
include:
- project: ../templates
ref: devel
file: ../tests.yml
- project: ../templates
ref: devel
file: hub/build.yml
- project: ../templates
ref: devel
file: deploy.yml
- project: ../templates
ref: devel
file: deploy-prod.yml
- project: ../templates
ref: devel
file: get-info.yml
- project: ../templates
ref: devel
file: uninstall.ymlТакой подход позволил нам легко экспериментировать, не нарушая уже работающие процессы:
Делаем новую ветку в проекте в templates и называем её, например, test-CI.
Делаем новую ветку в ветке микросервиса и называем update CI.
В новой ветке вносим изменения в gitlab-ci.yaml, указывая в разделе ref название ветки test-CI.
Проводим тесты, не нарушая процесс разработки, а после успешных тестов вливаем все в основные ветки.
Сначала такой подход может выглядеть избыточным, но он не раз помогал нам проводить разные эксперименты без влияния на разработчиков и не нарушая их работу.
Чего мы добились этим этапом:
— Унифицировали процессы CI/CD. Теперь все располагается в одном проекте, а не разные gitlab-ci в каждом микросервисе.
— Изменения можно вносить независимо от основных рабочих процессов, а если вносятся в основные ветки — сразу распространяются на все проекты.
Во-вторых, мы взялись за шаблонизацию микросервисов.
Ехать дальше на bash скрипте было нельзя, поэтому мы решили сделать «все по-правильному». И выбрали Helm. А где helm — там очень много yaml-программирования.
Не буду подробно описывать, как мы обсуждали подходы к шаблонизированию, просто покажу, на чем остановились.
У нас появился репозиторий templates-kubernetes, в котором мы храним шаблоны всех наших микросервисов.
Name
service_1/helm
service_2/helm
service_3/helm
service_4/helm
service_5/helmВнутри каждого следующая структура:

В подкаталоге templates лежат наши шаблоны сущностей k8s (deployment, ingress, service и тд.), а в values ямликах — нужные значения для каждой среды. Например:
replicaCount:
min: 1
max: 1
targetCPUUtilizationPercentage: 70
resources:
requests:
cpu: 500m
memory: 100Mi
readinessProbe:
httpGet:
path: /
port: 8000
initialDelaySeconds: 6
periodSeconds: 3
# failureThreshold: 3 # this is default value
livenessProbe:
httpGet:
path: /
port: 8000
initialDelaySeconds: 60
periodSeconds: 3
failureThreshold: 10
archivator_worker:
enabled: false
#Tracing
opentracing:
enabled: true
#Canary
canary:
enabled: false
division: 2По структуре тут сразу можно увидеть и параметры hpa, и реквесты, и лимиты, и прочее. Можно включать дополнительные воркеры, трейсинг, которые уже описываются в шаблонах в папке templates.
Разработчики, постигшие helm, даже сами стали закидывать MR, когда разрабатывали новые сервисы, снимая таким образом работу с девпосов.
Отдельным вопросом стояло, что делать с секретами и переменными. Чего мы хотели добиться:
— Переменные разработчики должны видеть и при необходимости менять (на тестовых средах).
— Секреты в проде недоступны никому, кроме эксплуатации. На тестовых средах такого ограничения нет.
Мы сделали два отдельных репозитория (variables и secrets). В первом храним все, что не нужно прятать, а что нужно — храним во втором. Если разработчику нужно внести изменения — делается MR, devops-инженер его подтверждает и он автоматически применяется на стендах. Разработчику остается только сделать редеплой сервиса. О том, как это делается, будет ниже, как и о том, как мы делим деплой в прод и тестовые среды.
Чего в итоге достигли:
— Шаблоны микросервисов хранятся в одном месте.
— Структура шаблонов упрощена и понятна с минимальной подготовкой.
— Переменные сервисов хранятся в понятном месте, доступном каждому разработчику.
— Получили версионирование изменений в переменных и секретах
— Секреты храним в недоступном для всех репозитории.
И третье, что мы хотели поменять — деплой. Скрипт деплоя падал, иногда зависал и тяжело поддерживался. Поэтому, если у нас есть helm, почему бы и не деплоить чарты.
Появился chartmuseum, стали пушить туда чарты, а потом деплоить все это в кластера k8s. Все максимально стандартно.
По итогу у нас получился вот такой пайплайн:

По кнопке Release — собирается образ и закачивается в gitlab registry .
По кнопкам деплоя — собирается чарт и деплоится в нужную среду (тут пока без релиза в продакшен). Также добавили парочку дополнительных задач, чтобы разработчики могли увидеть последние логи или удалить сервис целиком и потом перекатить.
После выполнения этих трех пунктов все наши основные проблемы на тот момент были устранены: унификация процессов CI/CD, единые шаблоны сервисов и процесс деплоя.
Процесс CI/CD после изменений выше выглядит следующим образом: разработчик создает Tag на ветку в репозитории разрабатываемого микросервиса, генерируется пайплайн. Сборка запускается автоматически, дальше по кнопке разработчик раскатывает на нужную среду образ и там уже проводятся тесты и, если нужно, катится на следующую среду. В продакшен мы все еще релизили руками.
И в целом это хорошо работало. В связке с гитлабом всегда можно было вернуться к предыдущему пайплайну и выкатить предыдущий тег. Образы мы именуем по short SHA commit — так легко можно идентифицировать, что сейчас раскатано.
Мы также задействовали функционал «Окружений» в гитлабе:
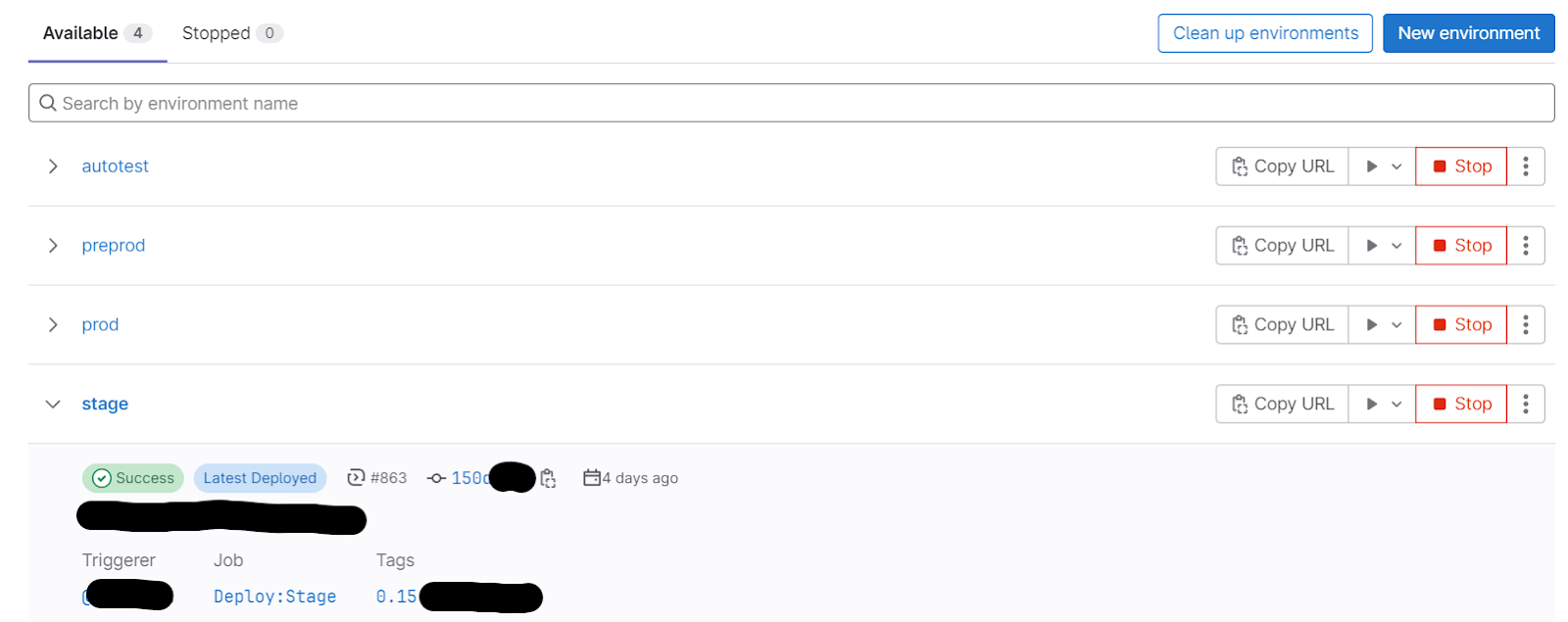
В окружение всегда можно провалиться и увидеть то, что было задеплоено, и историю деплоев. Это позволяет быстро взять предыдущий пайплайн и откатиться на нужную версию при необходимости. При этом сверху всегда отображается, что было выкачено последним.
Когда мы это все обкатали, самым сложным было перейти на эту схему. Количество сервисов выросло, а внедрение сопровождалось рядом не критичных, но все же проблем. Но даже несмотря на то, что многие проблемы мы закрыли, не все наши хотелки были реализованы. А потом разработчики пришли к нам с фидбеком и новыми проблемами, которые надо было решать.
Так мы подобрались к третьей реализации.
Этап 3. Деплой в продакшен и другие изменения CI/CD
Итак, мы хотим, чтобы разработчики деплоили в продакшен.
Работая над увеличением ТТМ, мы понимали, что возможность катить быстро и прозрачно (с откатами) — это must have. Но при этом мы отвечаем за эксплуатацию, и поэтому процесс должен быть еще и надежным.
Не углубляясь в детали, ниже то, что мы решили применять у себя.
1. Никаких миграций на базу данных автоматом. Если нужны миграции — через ручное обновление devops-инженером. У нас мультимастер, и поэтому вероятность положить тяжелой операцией кластер далеко не нулевая. Поэтому мы решили, что для безопасности мы это будем делать сами.
2. На этапе prod пайплайна мы не собираем образы. Есть исключения, но стараемся, чтобы их было минимум.
Так мы избегаем ситуации, в которой что-то случайно закомиченное в ветку может уехать в продакшен. Образ собирается на этапе выкатки на тестовые окружения. После проверок (так как short commit совпадает у двух тегов) можно не билдить новый образ, а воспользоваться им и выкатить.
3. Мы решили использовать в gitlab функционал protected tags.
Когда разработчики решают, что сервис готов идти в продакшен, создается специальный тег -prod. По этому тегу генерируется отдельный пайплайн, который могут запускать только «проверенные и знающие, что они делают» люди. Если у пользователя нет прав — кнопку нажать не получится.
Тут можно возразить — зачем вообще нажимать какую-то кнопку, если можно катить и автоматом? Наш подход в том, что деплой в прод — вещь ответственная, и нажимающий кнопку берет на себя ответственность за свои действия. Кнопки две, потому что кластера два.
История деплоев хранится в Environments, как рассказано выше.
Помимо этого в процессе еще улучшили:
Базовый функционал helm не позволяет отслеживать процесс деплоя. Поэтому мы решили использовать helmwave, в который встроен kubedog. Так можно следить за релизом, если не укладываемся в тайминги — то откатываем его. С момента начала использования helmwave сильно прокачался, и в целом проблем с ним нет
Шаблонизацию
Попользовавшись структурой helm-шаблонов сервисов, мы поняли, что получилось сложновато. Причем как для восприятия, так и для поддержки.
Подумали, как все это улучшить, и пришли к такому виду:
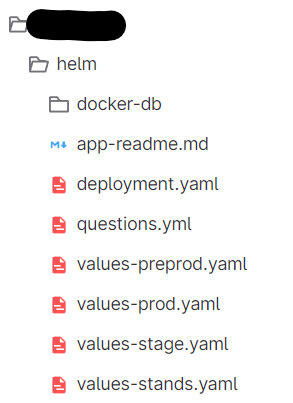
Как видите, убрана папка templates, вся шаблонизация сведена в один файл deployment.yaml
Values файл выглядит примерно так.
deployment:
app:
hpa:
minReplicas: 1
maxReplicas: 1
targetCPUUtilizationPercentage: 60
targetMemoryUtilizationPercentage: 80
container:
app:
jaegerHostAgent: true
image: ***
containerPort: ["***"]
command: "/bin/sh"
args:
- "/app/build/run.sh"
envFrom:
- api-env
secFrom:
- api-secret
livenessProbe:
httpGet:
path: /***
port: ***
initialDelaySeconds: 30
periodSeconds: 3
failureThreshold: 10
readinessProbe:
httpGet:
path: /***
port: ***
initialDelaySeconds: 3
periodSeconds: 3
resources:
requests:
cpu: 500m
memory: 100Mi
limits:
memory: 500Mi
service:
app:
type: ClusterIP
ports:
- name: base
port: ***
targetPort: ***
protocol: TCP
ingress:
app:
hosts:
service-url.test.ru:
http:
paths:
- path: /
pathType: Prefix
backend:
service:
port:
number: ***
networkpolicies:
app:
- egress-stage-db
- egress-mysql
- egress-grafana
- egress-rabbitmq-stage
Пример файла deployment.yaml
{{- range
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ $.Release.Name }}-{{ $key }}
namespace: {{ $.Release.Namespace }}
annotations:
{{ $.Release.Name }}: {{ $.Chart.AppVersion }}
spec:
strategy:
rollingUpdate:
maxSurge: 20%
maxUnavailable: 20%
type: RollingUpdate
selector:
matchLabels:
{{- if contains "canary" $key }}
app: {{ $.Release.Name }}-{{ $key | trimSuffix "-canary" }} # We will use old labels, but new (canary) deployment
{{- else }}
app: {{ $.Release.Name }}-{{ $key }}
{{- end }}
template:
metadata:
labels:
{{- if contains "canary" $key }}
app: {{ $.Release.Name }}-{{ $key | trimSuffix "-canary" }}
{{- else }}
app: {{ $.Release.Name }}-{{ $key }}
{{- end }}
version: {{ $val.version | default "v1" | quote }}
annotations:
rollme: {{ randAlphaNum 5 | quote }}
{{- with $.Values.defaultsDeployment.annotations }}
{{- toYaml . | nindent 8 }}
{{- end }}
{{- with .annotations }}
{{- toYaml . | nindent 8 }}
{{- end }}
spec:
{{- with $.Values.imagePullSecrets }}
imagePullSecrets:
{{- toYaml . | nindent 8 }}
{{- end }}
enableServiceLinks: {{ $.Values.enableServiceLinks }}
{{- with .hostAliases }}
hostAliases:
{{- toYaml . | nindent 6 }}
{{- end}}
{{- if .initContainer }}
initContainers:
{{- range $initContainer, $val := $val.initContainer }}
- name: {{ $initContainer }}
{{- if and .image .tag }}
image: "{{ .image }}:{{ .tag }}"
{{- else if .image }}
image: "{{ .image }}:{{ $.Values.image.tag }}"
{{- else if .tag }}
image: "{{ $.Values.image.image }}:{{ .tag }}"
{{- else -}}
image: "{{ $.Values.image.image }}:{{ $.Values.image.tag }}"
{{- end -}}
{{- if .imagePullPolicy }}
imagePullPolicy: {{ .imagePullPolicy }}
{{- else }}
imagePullPolicy: {{ $.Values.imagePullPolicy }}
{{- end }}
{{- if or .envFrom .secFrom }}
envFrom:
{{- range $key, $val := .envFrom }}
- configMapRef:
name: {{ $val }}
{{- end }}
{{- range $key, $val := .secFrom }}
- secretRef:
name: {{ $val }}
{{- end }}
{{- end }}
env:
- name: "TZ"
value: "Etc/UTC"
{{- with .env }}
{{- range . }}
- name: {{ .name }}
value: {{ .value | quote }}
{{- end }}
{{- end }}
{{- with .resources }}
resources:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- if .containerPort }}
ports:
- containerPort: {{ .containerPort }}
{{- end }}
{{- if .command }}
command: [{{ .command | quote }}]
{{- end }}
{{- with .args }}
args:
{{- toYaml . | nindent 8 }}
{{- end }}
{{- if or .fileMount .emptyDir }}
volumeMounts:
{{- end }}
{{- range $name, $path := .fileMount }}
- name: {{ $name }}
mountPath: {{ $path }}
subPath: file
{{- end }}
{{- range $name, $path := .emptyDir }}
- name: {{ $name }}
mountPath: {{ $path }}
{{- end }}
{{- with .securityContext }}
securityContext:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- end }}
{{- end }}
containers:
{{- range $container, $val := $val.container}}
- name: {{ $container }}
{{- if and .image .tag }}
image: "{{ .image }}:{{ .tag }}"
{{- else if .image }}
image: "{{ .image }}:{{ $.Values.image.tag }}"
{{- else if .tag }}
image: "{{ $.Values.image.image }}:{{ .tag }}"
{{- else -}}
image: "{{ $.Values.image.image }}:{{ $.Values.image.tag }}"
{{- end -}}
{{- with .lifecycle }}
lifecycle:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- if .imagePullPolicy }}
imagePullPolicy: {{ .imagePullPolicy }}
{{- else }}
imagePullPolicy: {{ $.Values.imagePullPolicy }}
{{- end }}
{{- if or .envFrom .secFrom }}
envFrom:
{{- range $key, $val := .envFrom }}
- configMapRef:
name: {{ $val }}
{{- if $.Values.dockerRabbit }}
- configMapRef:
name: {{ $.Chart.Name }}-rabbit
{{- end }}
{{- if $.Values.dockerRedis }}
- configMapRef:
name: {{ $.Chart.Name }}-redis
{{- end }}
{{- end }}
{{- range $key, $val := .secFrom }}
- secretRef:
name: {{ $val }}
{{- end }}
{{- range $key, $val := .secFrom }}
- secretRef:
name: {{ $val }}
{{- end }}
{{- end }}
env:
- name: "TZ"
value: "Etc/UTC"
{{- if .jaegerHostAgent }}
- name: JAEGER_AGENT_HOST
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: JAEGER_AGENT_PORT
value: "5775"
- name: JAEGER_URL
value: "" class="formula inline">(JAEGER_AGENT_HOST):
- name: JAEGER_HOST
value: "" class="formula inline">(JAEGER_AGENT_HOST)"
- name: JAEGER_PORT
value: "$(JAEGER_AGENT_PORT)"
{{- end }}
{{- with .env }}
{{- range . }}
- name: {{ .name }}
value: {{ .value | quote }}
{{- end }}
{{- if $.Values.customVars }}
env:
- name: RABBITMQ_DSN
value: "amqp://user:pass@{{ $.Chart.Name }}-rabbit:5672/"
- name: REDIS_HOST
value: "{{ $.Chart.Name }}-redis"
- name: RABBITMQ_HOST
value: "{{ $.Chart.Name }}-rabbit"
- name: RABBITMQ_USER
value: "user"
- name: RABBITMQ_PASSWORD
value: "pass"
{{- end }}
{{- end }}
{{- with .readinessProbe }}
readinessProbe:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- with .livenessProbe }}
livenessProbe:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- with .resources }}
resources:
{{- toYaml . | nindent 10 }}
{{- end }}
{{- if .containerPort }}
ports:
{{- range $port, $number := .containerPort }}
- containerPort: {{ $number }}
{{- end }}
{{- end }}
{{- if .command }}
command: [{{ .command | quote }}]
{{- end }}
{{- with .args }}
args:
{{- toYaml . | nindent 8 }}
{{- end }}
{{- if or .fileMount .emptyDir }}
volumeMounts:
{{- end }}
{{- range $name, $path := .fileMount }}
- name: {{ $name }}
mountPath: {{ $path }}
subPath: file
{{- end }}
{{- range $name, $path := .emptyDir }}
- name: {{ $name }}
mountPath: {{ $path }}
{{- end }}
{{- end }}
{{- if .jaegerAgent }}
- name: jaeger-agent
image: {{ $.Values.jaegerAgent.image }}
imagePullPolicy: {{ $.Values.jaegerAgent.imagePullPolicy }}
resources:
requests:
cpu: {{ $.Values.jaegerAgent.resources.requests.cpu }}
memory: {{ $.Values.jaegerAgent.resources.requests.memory }}
ports:
- containerPort: 5775
name: zk-compact-trft
protocol: UDP
- containerPort: 5778
name: config-rest
protocol: TCP
- containerPort: 6831
name: jg-compact-trft
protocol: UDP
- containerPort: 6832
name: jg-binary-trft
protocol: UDP
- containerPort: 14271
name: admin-http
protocol: TCP
args:
- --reporter.grpc.host-port=dns:///jaeger-collector-headless.{{ $.Release.Namespace }}:14250
- --reporter.type=grpc
{{- end }}
{{- if or $.Values.fileMountVolume $.Values.emptyDirVolume}}
volumes:
{{- end }}
{{- range $name, $path := $.Values.fileMountVolume }}
- name: {{ $name }}
configMap:
name: {{ $.Release.Name }}-filemount-{{ $name }}
{{- end }}
{{- range $dir, $name := $.Values.emptyDirVolume }}
- name: {{ $name }}
emptyDir: {}
{{- end }}
{{- with $.Values.nodeSelector }}
nodeSelector:
{{- toYaml . | nindent 8 }}
{{- end }}
{{- end }}Он похож на предыдущий, но здесь чуть больше информации. А ещё все ключевые вещи (типа ingress, hpa, network policies) в одном файле, не нужно собирать их из разных. Такая схема получилась намного более читаемой и понимаемой.
Так как релизы теперь у нас стали катить сами разработчики, мы сделали отдельный этап в пайплайне, где сначала создается релизная задача (она формирует задачу в Jira и прилинковывает к ней связанные задачи). Разработчик заполняет релиз в гитлабе, по кнопке данные автоматически парсятся и создается задача в Jira. Удобно для менеджеров
При нажатии на кнопку »Закрыть задачу» созданная на предыдущем этапе задача закрывается, в нужные каналы посылаются нотификации. Причем сразу формируется сообщение из релиза, созданного на этапе выше.
Сообщение в рабочий чат:
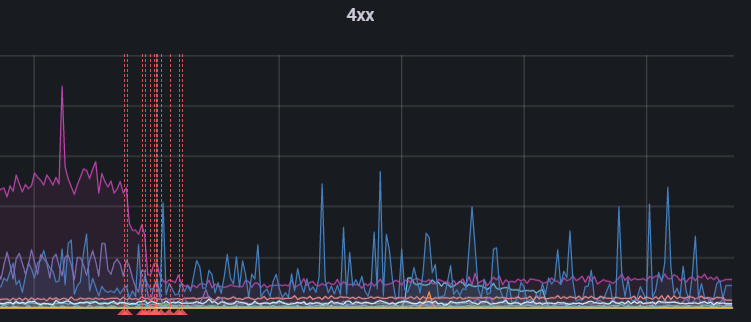
Ещё из полезного — деплои помечаются на графиках в графане, и можно сразу увидеть, есть ли корреляции в ошибках с недавними релизами
SAST, security check
По всем новым трендам в ИБ добавили в пайплайн проверки по безопасности. Это проверка образов с использованием trivy, статический анализ кода.
Также добавили обязательным этапом интеграционные тесты, которые написала наша команда QA. Если до этого они сами их запускали, то теперь это также встроено в конвейер. Сейчас на этапе внедрения интеграционные тесты на отдельном стенде для автотестов, чтобы еще больше автоматизировать этот процесс.
Текущий пайплайн для тестовых сред
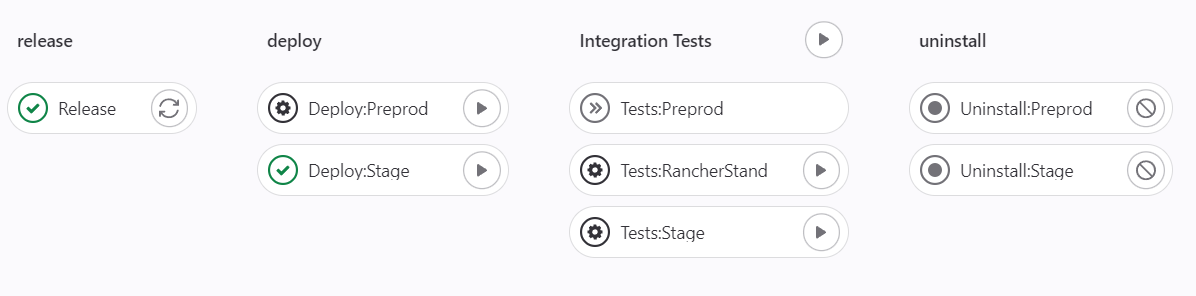
Текущий продовый пайплайн

Итоги
Как я и написал в начале поста, это пройденный нами путь построения CI/CD процесса.
Что мы получили в итоге?
Шаблонизированный подход к сервисам и этапам CI/CD. Уменьшает время погружения в структуру (отмечено на новых сотрудниках). Похожий подход пробуем применить и к остальной нашей инфраструктуре.
Контролируемые деплои на тестовые среды.
Деплой в продакшен разработкой, а не только инженерами эксплуатации. Количество релизов в сутки не ограничено, зависит от готовности команд и сейчас может доходить до десятков.
Наши разработчики теперь сами могут создавать шаблоны микросервисов, потому что «лезть в дебри helm» не нужно, достаточно скопировать основной шаблон и изменить values.
Проблем тоже стало меньше, потому что везде все одинаково с одинаковыми шаблонами и процессами. А это значит — меньше рутинных задач для devops-инженеров.
Наличие переменных в проекте helm-variables избавило от вопросов разработки и тестировщиков «А какое значение переменной у такого-то сервиса на такой-то среде?».
Наличие деплоя в продакшен разработчиками позволило сильно увеличить ТТМ. Есть внутренние регламенты, когда можно выкатывать и когда нет, но в остальном команды предоставлены сами себе. Если раньше в день могли быть единичные релизы, то сейчас могут быть по несколько раз на дню (релизы, хотфиксы и т.д.). При этом откаты происходят в исключительных случаях.
Когда пришлось внедрять новые этапы безопасности в пайплайн, то это заняло минимум времени — протестировали на паре сервисов, влили изменения в основную ветку шаблонов, и изменения доехали всем остальным.
При написании этой статьи я старался не углубляться в технические детали, а описать этапы, которые мы прошли. Если будут интересны технические детали, задавайте вопросы в комментариях, я постараюсь на них ответить.
Заглядывая в будущее, вижу, как полученный нами результат можно применить в набирающем популярность Platform engineering. Если это будет приносить пользу и разработке, и бизнесу, то мы обязательно это внедрим, а после и поделимся опытом.
