Эволюция архитектуры торгово-клиринговой системы Московской биржи. Часть 2

Это продолжение длинного рассказа о нашем тернистом пути к созданию мощной, высоконагруженной системы, обеспечивающей работу Биржи. Первая часть тут.
Таинственная ошибка
После многочисленных тестов обновлённая торгово-клиринговая система была введена в строй, и мы столкнулись с багом, про который впору писать детективно-мистическую повесть.
Вскоре после запуска на главном сервере одна из транзакций обработалась с ошибкой. При этом на резервном сервере всё было в порядке. Оказалось, что простая математическая операция вычисления экспоненты на главном сервере дала отрицательный результат от действительного аргумента! Продолжили изыскания, и в SSE2-регистре нашли отличие в одном бите, который отвечает за округление при работе с числами с плавающей запятой.
Написали простую тестовую утилиту для вычисления экспоненты с выставленным битом округления. Выяснилось, что в той версии RedHat Linux, которую мы использовали, был баг в работе с математической функцией, когда вставлялся злополучный бит. Мы сообщили об этом в RedHat, через некоторое время получили от них патч и накатили его. Ошибка больше не возникала, но было непонятно, откуда вообще взялся этот бит? За него отвечала функция fesetround из языка С. Мы тщательнейшим образом проанализировали свой код в поисках предполагаемой ошибки: проверили все возможные ситуации; рассмотрели все функции, которые использовали округление; пытались воспроизвести сбойную сессию; использовали разные компиляторы с разными опциями; применяли статический и динамический анализ.
Причину ошибки найти не удалось.
Тогда начали проверять аппаратную часть: провели нагрузочное тестирование процессоров; проверили оперативную память; даже прогнали тесты на очень маловероятный сценарий многобитовой ошибки в одной ячейке. Безрезультатно.
В конце концов остановились на теории из мира физики высоких энергий: в наш дата-центр прилетела какая-нибудь высокоэнергетическая частица, пробила стенку корпуса, попала в процессор и вызвала залипание триггерной защелки в том самом бите. Эта абсурдная теория получила название «нейтрино». Если вы далеки от физики элементарных частиц: нейтрино почти не взаимодействуют с окружающим миром, и уж точно не способны повлиять на работу процессора.
Поскольку найти причину сбоя так и не удалось, на всякий случай исключили «провинившийся» сервер из эксплуатации.
Спустя какое-то время мы начали улучшать систему горячего резервирования: ввели так называемые «тёплые резервы» (warm) — асинхронные реплики. Они получали поток транзакций, которые могут находиться в разных дата-центрах, но при этом warm«ы не поддерживали активного взаимодействия с другими серверами.
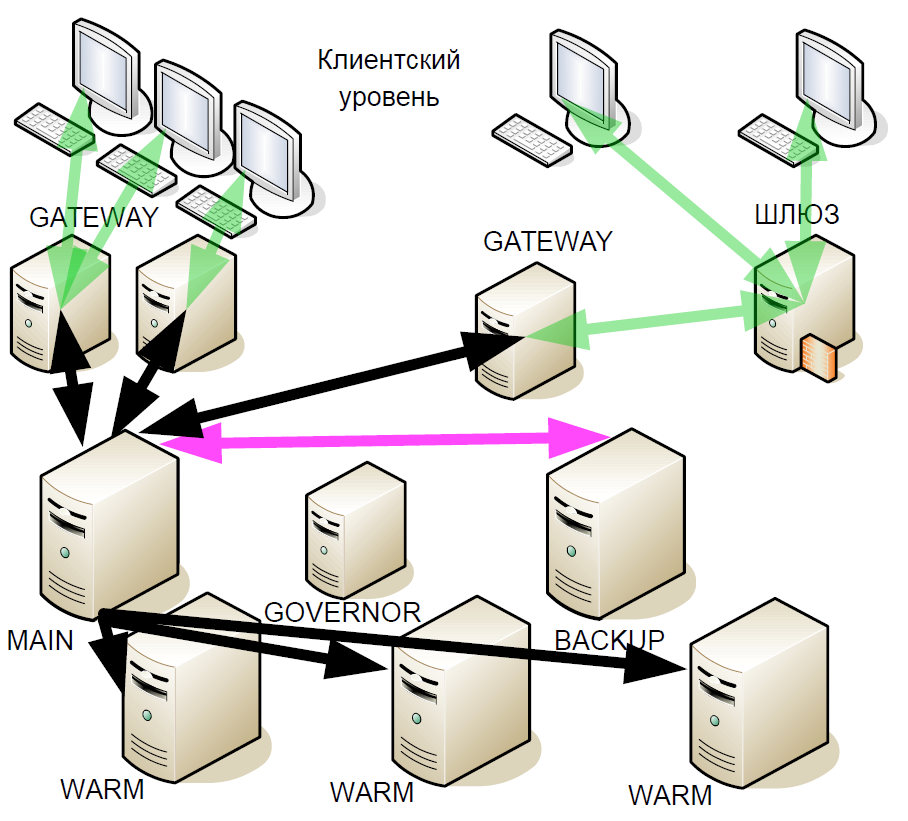
Для чего это было сделано? Если резервный сервер выходит из строя, то привязанный к главному серверу warm становится новым резервным. То есть после сбоя система не остаётся до конца торговой сессии с одним главным сервером.
А когда новая версия системы была протестирована и запущена в эксплуатацию, снова возникла ошибка с округляющим битом. Более того, с увеличением количества warm-серверов ошибка стала появляться чаще. При этом вендору предъявить было нечего, поскольку конкретных доказательств нет.
В ходе очередного анализа ситуации возникла теория, что проблема может быть связана с ОС. Мы написали простую программу, которая в бесконечном цикле вызывает функцию fesetround, запоминает текущее состояние и проверяет его через sleep, причём делается это во множестве конкурирующих потоков. Подобрав параметры sleep и количества потоков, мы стали устойчиво воспроизводить сбой битов примерно через 5 минут работы утилиты. Однако служба поддержки Red Hat не смогла её воспроизвести. Тестирование других наших серверов показало, что ошибке подвержены лишь те из них, в которых установлены определённые процессоры. При этом переход на новое ядро решал проблему. В конце концов мы просто заменили ОС, а истинная причина бага так и осталась невыясненной.
И вдруг в прошлом году на Хабре вышла статья «Как я нашел баг в процессорах Intel Skylake». Описанная в ней ситуация была очень похожа на нашу, но автор продвинулся в расследовании дальше и выдвинул теорию, что ошибка была в микрокоде. А при обновлении ядер Linux производители также обновляют и микрокод.
Дальнейшее развитие системы
Хотя от ошибки мы избавились, эта история заставила снова пересмотреть архитектуру системы. Ведь мы не были защищены от повторения подобных багов.
В основу очередных доработок системы резервирования легли следующие принципы:
- Нельзя никому верить. Серверы могут работать неправильно.
- Мажоритарное резервирование.
- Обеспечение консенсуса. Как логическое дополнение к мажоритарному резервированию.
- Возможны двойные отказы.
- Живучесть. Новая схема горячего резервирования должна быть не хуже предыдущей. Торговля должна идти бесперебойно вплоть до последнего сервера.
- Незначительное увеличение задержки. Любой простой влечёт огромные финансовые потери.
- Минимальное взаимодействие по сети, чтобы задержка была как можно меньше.
- Выбор нового главного сервера за секунды.
Ни одно из имевшихся на рынке решений нам не подошло, а протокол Raft ещё только зарождался, поэтому мы создали собственное решение.

Сетевое взаимодействие
Кроме системы резервирования мы занялись модернизацией сетевого взаимодействия. Подсистема ввода-вывода представляла собой множество процессов, что наихудшим образом влияло на джиттер и задержку. Имея сотни процессов, обрабатывающих TCP-соединения, мы вынуждены были постоянно переключаться между ними, а в микросекундном масштабе это довольно длительная операция. Но хуже всего то, что когда процесс получал пакет на обработку, он отправлял его в одну очередь SystemV, а затем ждал события из другой очереди SystemV. Однако при большом количестве узлов поступление нового TCP-пакета в одном процессе и получение данных в очередь в другом представляют собой для ОС два конкурирующий события. В этом случае, если для обеих задач не будет доступных физических процессоров, одна будет обрабатываться, а вторая встанет в очередь ожидания. Предугадать последствия невозможно.
В подобных ситуациях можно применить динамическое управление приоритетом процесса, но это потребует использования ресурсоёмких системных вызовов. В итоге мы перешли на один поток с использованием классического epoll, это сильно повысило скорость и уменьшило длительность обработки транзакции. Также мы избавились от отдельных процессов сетевого взаимодействия и от взаимодействия через SystemV, значительно сократили количество системных вызовов и начали контролировать приоритеты операций. На одной лишь подсистеме ввода-вывода удалось сэкономить порядка 8–17 микросекунд в зависимости от сценария. Эта однопоточная схема с тех пор применяется в неизменном виде, одного epoll-потока с запасом достаточно для обслуживания всех подключений.
Обработка транзакций
Рост нагрузки на нашу систему требовал модернизации почти всех её компонентов. Но, к сожалению, стагнация в росте тактовой частоты процессоров в последние годы уже не позволяла масштабировать процессы «в лоб». Поэтому мы решили разделить процесс Engine на три уровня, причём самым нагруженным из них является система проверки рисков, которая оценивает наличие средств на счетах и создаёт сами сделки. Но деньги могут быть в разных валютах, и нужно было придумать, по какому принципу разделять обработку запросов.
Логичное решение — разделить по валютам: один сервер торгует долларами, другой фунтами, третий евро. Но если при такой схеме отправить две транзакции на покупку разных валют, то возникнет проблема рассинхронизации кошельков. А синхронизировать сложно и накладно. Поэтому правильно будет отдельно шардировать по кошелькам и отдельно по инструментам. К слову, у большинства западных бирж задача проверки рисков не стоит так остро, как у нас, поэтому чаще всего это делается в офлайне. Нам же необходимо было реализовать онлайн-проверку.
Поясним на примере. Трейдер хочет купить 30 долларов, и запрос уходит на валидацию транзакции: мы проверяем, допущен ли этот трейдер до данного режима торгов, имеет ли он нужные права. Если всё в порядке, запрос уходит в систему проверки рисков, т.е. на проверку достаточности средств на заключение сделки. Там ставится пометка, что необходимая сумма на текущий момент заблокирована. Дальше запрос переадресуется торговой системе, которая одобряет или не одобряет данную транзакцию. Допустим, транзакция одобрена — тогда система проверки рисков помечает, что деньги разблокированы, и рубли превращаются в доллары.
В целом, система проверки рисков содержит сложные алгоритмы и выполняет большой объём очень ресурсоёмких вычислений, а не просто проверяет «остаток на счёте», как может показаться на первый взгляд.
Приступив к разделению процесса Engine на уровни, мы столкнулись с проблемой: имевшийся на тот момент код на этапах валидации и проверки активно использовал один и тот же массив данных, что требовало переписать всю кодовую базу. В результате мы позаимствовали у современных процессоров методику обработки инструкций: каждая из них разбивается на мелкие этапы и за один цикл параллельно выполняется несколько действий.
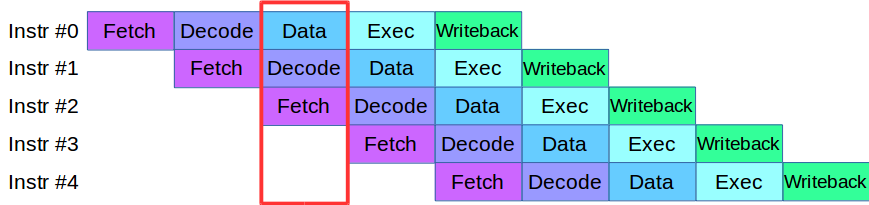
После небольшой адаптации кода мы создали конвейер параллельной обработки транзакций, в котором транзакция разбивалась на 4 этапа конвейера: сетевое взаимодействие, валидация, исполнения и публикация результата

Рассмотрим пример. У нас есть две системы обработки, последовательная и параллельная. Приходит первая транзакция, и в обеих системах отправляется на валидацию. Тут же приходит вторая транзакция: в параллельной системе она сразу же берётся в работу, а в последовательной кладётся в очередь в ожидании, пока первая транзакция пройдёт текущий этап обработки. То есть основное преимущество конвейерной обработки в том, что мы быстрее обрабатываем очередь транзакций.
Так у нас появилась система ASTS+.
Правда, с конвейерами тоже не всё так гладко. Допустим, у нас есть транзакция, которая влияет на массивы данных в соседней транзакции, это характерная ситуация для биржи. Такую транзакцию нельзя исполнять в конвейере, потому что она может повлиять на другие. Эта ситуация называется data hazard, и подобные транзакции просто обрабатываются отдельно: когда находящиеся в очереди «быстрые» транзакции кончаются, конвейер останавливается, система обрабатывает «медленную» транзакцию, а затем снова запускает конвейер. К счастью, доля таких транзакций в общем потоке очень мала, поэтому конвейер останавливается так редко, что это не влияет на общую производительность.

Затем мы принялись решать проблему синхронизации трёх потоков исполнения. В результате родилась система на основе кольцевого буфера с ячейками фиксированного размера. В этой системе всё подчинено скорости обработки, данные не копируются.
- Все входящие сетевые пакеты попадают на стадию аллокации.
- Мы размещаем их в массиве и помечаем, что они доступны для стадии № 1.
- Пришла вторая транзакция, она снова доступна для стадии № 1.
- Первый поток обработки видит доступные транзакции, обрабатывает их и переводит на следующую стадию второго потока обработки.
- Затем он обрабатывает первую транзакцию и помечает соответствующую ячейку флагом
deleted— теперь она доступна для нового использования.
Таким образом обрабатывается вся очередь.
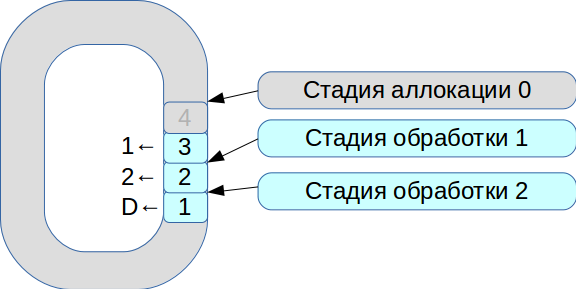
Обработка каждой стадии занимает единицы или десятки микросекунд. И если использовать стандартные схемы синхронизации ОС, то мы потеряем больше времени на самой синхронизации. Поэтому мы стали использовать spinlock. Однако это очень плохой тон в real-time системе, и RedHat строго-настрого не рекомендует так делать, поэтому мы применяем spinlock в течение 100 мс, а затем переходим в режим семафоров, чтобы исключить возможность deadlock.
В результате мы достигли производительности около 8 млн транзакций в секунду. И буквально через два месяца в статье про LMAX Disruptor увидели описание схемы с такой же функциональностью.
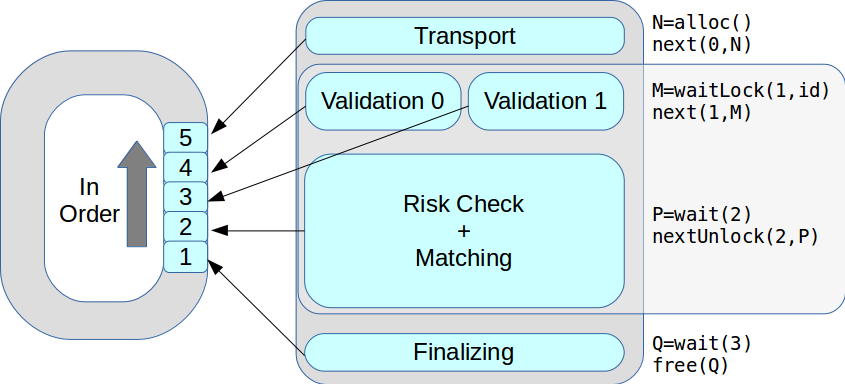
Теперь на одной стадии могло находиться несколько потоков исполнения. Все транзакции обрабатывались по очереди, в порядке поступления. В итоге пиковая производительность выросла с 18 тыс. до 50 тыс. транзакций в секунду.
Биржевая система риск-менеджмента
Нет предела совершенству, и вскоре мы снова занялись модернизацией: в рамках ASTS+ начали выносить системы риск-менеджмента и расчётных операций в автономные компоненты. Разработали гибкую современную архитектуру и новую иерархическую модель риска, постарались везде, где возможно, использовать класс fixed_point вместо double.
Но сразу же возникла задача: как синхронизировать всю бизнес-логику, которая уже работает много лет, и перенести её в новую систему? В результате от первой версии прототипа новой системы пришлось отказаться. В основе второй версии, которая сегодня трудится в production, лежит один и тот же код, который работает и в торговой части, и в рисковой. В ходе разработки труднее всего было сделать git merge между двумя версиями. Наш коллега Евгений Мазуренок каждую неделю выполнял эту операцию и каждый раз очень долго ругался.
При выделении новой системы сразу пришлось решать задачу взаимодействия. При выборе шины данных необходимо было обеспечить стабильный джиттер и минимальную задержку. Для этого лучше всего подошла сеть InfiniBand RDMA: средняя длительность обработки в 4 раза меньше, чем в сетях 10 G Ethernet. Но по-настоящему нас подкупила разница в перцентилях — 99 и 99,9.
Конечно, у InfiniBand есть свои сложности. Во-первых, другой API — ibverbs вместо sockets. Во-вторых, почти нет широкодоступных open source messaging-решений. Мы попытались сделать свой прототип, но это оказалось очень непросто, поэтому выбрали коммерческое решение — Confinity Low Latency Messaging (ранее IBM MQ LLM).
Затем возникла задача правильного разделения рисковой системы. Если просто вынести Risk Engine и не сделать промежуточного узла, то транзакции из двух источников могут перемешиваться.
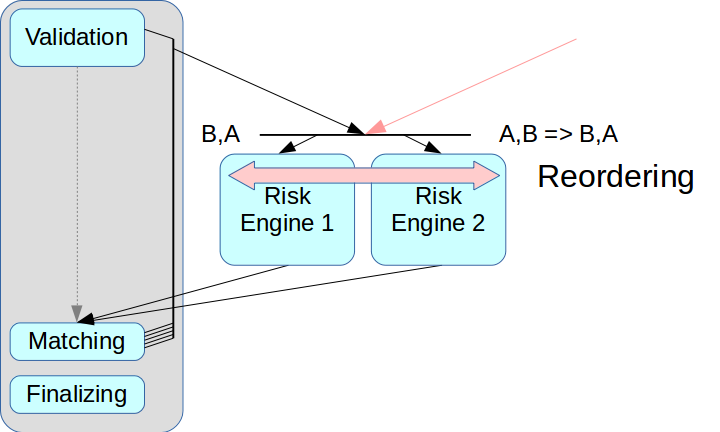
В так называемых Ultra Low Latency решениях есть режим reordering: транзакции от двух источников могут при поступлении выстраиваться в нужном порядке, это реализуется с помощью отдельного канала обмена информацией об очерёдности. Но мы пока не применяем этот режим: он усложняет весь процесс, а в ряде решений вообще не поддерживается. К тому же пришлось бы каждой транзакции присваивать соответствующие временны̒е метки, а в нашей схеме этот механизм очень трудно реализовать корректно. Поэтому мы использовали классическую схему с message broker, то есть с диспетчером, который распределяет сообщения между Risk Engine.
Вторая проблема была связана с клиентским доступом: при наличии нескольких Risk Gateway клиенту необходимо подключаться к каждому из них, и для этого придётся вносить изменения в клиентский слой. Мы хотели уйти от этого на данном этапе, поэтому в текущей схеме Risk Gateway обрабатывают весь поток данных. Это сильно ограничивает максимальную пропускную способность, но очень упрощает интегрирование системы.
Дублирование
В нашей системе не должно быть единой точки отказа, то есть все компоненты необходимо продублировать, в том числе брокер сообщений. Эту задачу мы решили с помощью системы CLLM: она содержит RCMS-кластер, в котором два диспетчера могут работать в режиме master-slave, и когда один выходит из строя, система автоматически переключается на другой.
Работа с резервным ЦОДом
InfiniBand оптимизирован для работы в качестве локальной сети, то есть для соединения стоечного оборудования, а между двумя географически распределенными дата-центрами InfiniBand-сеть не проложить. Поэтому мы реализовали bridge/dispatcher, который по обычным Ethernet-сетям подключается к хранилищу сообщений и ретранслирует все транзакции во вторую IB-сеть. Когда нужна миграция с ЦОД, мы можем выбирать, с каким дата-центром сейчас работать.
Итоги
Всё вышеописанное было сделано не за один раз, понадобилось несколько итераций разработки новой архитектуры. Прототип мы создали за месяц, но доводка до рабочего состояния заняла более двух лет. Мы старались добиться наилучшего компромисса между увеличением длительности обработки транзакций и повышением надёжности системы.
Поскольку система была сильно обновлена, мы реализовали восстановление данных из двух независимых источников. Если хранилище сообщений по каким-то причинам функционирует неправильно, можно взять лог транзакций из второго источника — из Risk Engine. Этот принцип соблюдается в рамках всей системы.
Помимо прочего, нам удалось сохранить клиентский API, чтобы ни брокеры, ни кто-либо ещё не потребовали значительной переделки под новую архитектуру. Пришлось поменять какие-то интерфейсы, но вносить в модель работы значительные изменения не потребовалось.
Текущую версию нашей платформы мы назвали Rebus — как сокращение от двух самых заметных нововведений в архитектуре, Risk Engine и BUS.
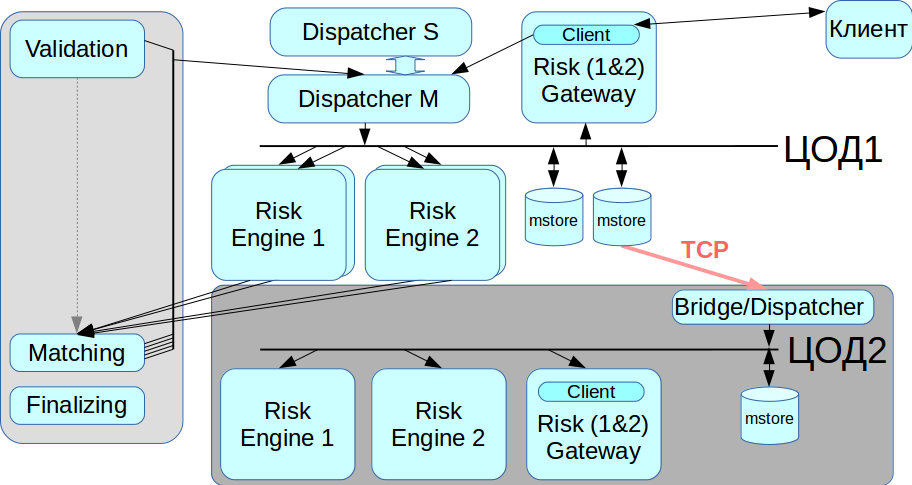
Изначально мы хотели выделить только клиринговую часть, но в результате получилась огромная распределённая система. Теперь клиенты могут взаимодействовать либо с торговым Gateway, либо с клирингом, либо с обоими сразу.
Чего мы в итоге добились:

Снизили уровень задержки. При небольшом объёме транзакций система работает так же, как и предыдущая версия, но при этом выдерживает гораздо более высокую нагрузку.
Пиковая производительность выросла с 50 тыс. до 180 тыс. транзакций в секунду. Дальнейшему повышению мешает единственный поток сведения заявок.
Есть два пути дальнейшего улучшения: распараллеливание matching и изменение схемы работы с Gateway. Сейчас все Gateway работают по репликационной схеме, которая при такой нагрузке перестаёт нормально функционировать.
Напоследок могу дать несколько советов тем, кто дорабатывает энтерпрайз-системы:
- Всё время будьте готовы к худшему. Проблемы всегда возникают неожиданно.
- Быстро переделать архитектуру, как правило, невозможно. Особенно, если нужно достичь максимальной надежности по множеству показателей. Чем больше узлов, тем больше нужно ресурсов на поддержку.
- Все специальные и проприетарные решения дополнительно потребуют ресурсы на исследование, поддержку и сопровождение.
- Не откладывайте решение вопросов надёжности и восстановления системы после сбоев, учитывайте их на начальном этапе проектирования.
