Ещё раз про хеш-коллизии в коммутаторах
Присказка
Поставили мы тут в тестовом режиме один коммутатор от Eltex-а — MES5248. И начали мы его по-всякому мучать — VLAN-ы настраивать, MSTP прикручивать и всячески изголяться. В лабораторных условиях видимых косяков не нашли — поставили под реальный живой трафик. И тут вылез странный глюк, на уровне неуловимого Джо — время от времени в ARP-таблице у отдельных записей отсутствовало значение в поле порт (да, они его в ARP-таблице выводят. Удобно). Попытки поймать за хвост, повторить не увенчались особым успехом. Техподдержка ломала голову себе и разработчикам, в конечном итоге пришли к наблюдению, что в ARP-таблице записи живут дольше, чем в MAC-таблице. И дольше, чем оно сконфигурировано, что, конечно баг, но не ужас какой смертельный. Осталось лишь проверить, что записи в MAC-таблице умирают по таймауту, естественной смертью, а не бывают убиты другими при хеш-коллизии.
Ну, проверять такое руками, вестимо, лень. Шутка ли — просмотри >2000 маков несколько раз подряд да найди дыры. Надо кодить. Делать под конкретный свич — дело неблагодарное, так что код получился под все свичи, которые есть в хозяйстве. Если интересно, что получилось — читайте сказку.
Сказка
В итоге родилась прожка, которая сперва чистит MAC-таблицу, а потом, примерно раз в минуту сливает её с коммутатора и анализирует. При этом считаются
1. Уникальные маки, наблюдавшиеся с начала тестирования. (Ever)
2. Уникальные маки, наблюдающиеся в текущий момент на коммутаторе.(Now)
3. Для каждого мака помнится момент времени, когда он первый раз появился в таблице. И если он в ней появляется снова через время, меньшее чем aging time — считается, что его по какой-то причине вышибло. (Early deaths)
4. Подсчитываются все такие маки. (то, что до слеша в Early deaths)
Кстати, я снимал fdb-таблицу telnet-ом, хотя можно и по snmp, о чём на хабре уже писали, в отличие от результатов UserSide, по дороге обнаружились коммутаторы, которые по telnet-у отдают fdb дико долго, а по snmp — мгновенно, например — DXS-3326GSR.
Наблюдения ведутся 20 минут.
К вящему моему удивлению, коммутатор, ради которого всё затевалось, показал себя на удивление хорошо — за время до aging time Now от Ever не отличалось и в Early deaths было пусто. Аналогично ведут себя Cisco 3750.
А вот в остальном зоопарке проблемы-таки обнаружились. Хотя большинство протестированных dlink-ов и имеют меньшую MAC-таблицу, но и общее количество адресов зачастую гораздо меньше. В результате нарисовался такой график — зависимости количества проблем от общего размера мак-таблицы.
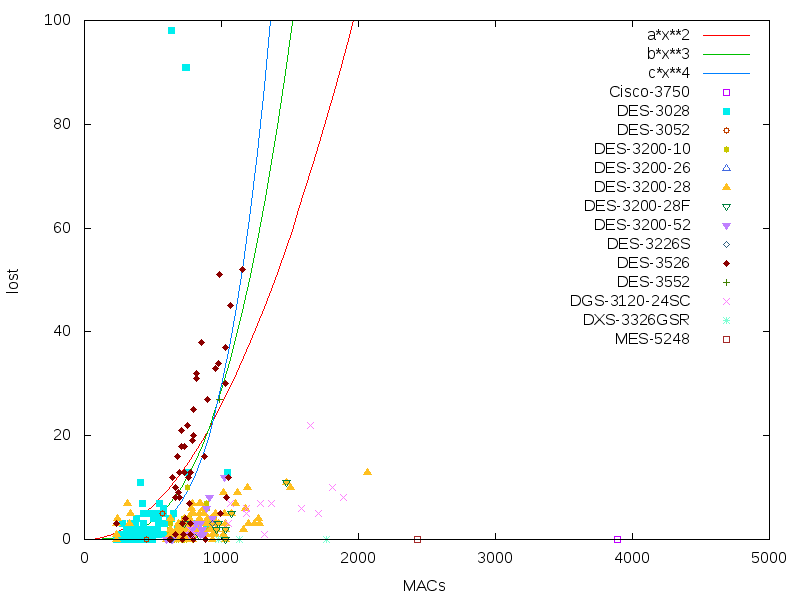
Собственно, какие выводы — разные коммутаторы одного вендора ведут себя по-разному и количество проблем растёт очень быстро от числа маков. Орг-вывод оперативный — уменьшать количество vlan-ов на 3526. Увеличить aging time на всём оборудовании.
Дальше — судя по всему, коммутаторы разбираются с хеш коллизиями принципаиально по-разному. Некоторые — выкидывают старые маки, другие — вероятно, как-то обходят коллизию при неплотно забитой таблице. Как именно они это делают, мне не ясно — либо считают адрес по второй хеш-функции, либо кладут новый адрес в соседнюю ячейку, либо тупа броадкастят трафик до нового мака, либо ещё что-то. Если это читают представители вендоров и эта информация не секретна — поделитесь в комментариях.
В планах — доработать прогу до сбора данных и управления по SNMP, отцепить от внутренних зависимостей, выложить в паблик. Соответственно, вопрос к сообществу — стоит ли вообще это делать?
Ещё интересен такой вопрос — какие есть мысли, как удалённо ловить ситуацию с броадкастом на новые маки и оценить количество и/или объём такого трафика?
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
