Энтузиаст протестировал новейший процессор Loongson 3C5000

Сравнение процессоров Loongson 3A5000 и 3C5000
Некоторое время назад с энтузиаст связался с разработчиками процессора Loongson и ему удалось протестировать сервер на процессоре Loongson 3С5000 (сервер содержит 2 процессора с 16 ядрами каждый).
Раннее энтузиаст уже проводил тесты десктопного процессора Loongson 3A5000, поэтому его будем сравнивать с процессором Loongson 3С5000.
Характеристики процессоров Loongson 3A5000 и Loongson 3С5000:
Loongson 3A5000 | Loongson 3С5000 | |
Семейство ISA | RISC | RISC |
Архитектура | loongarch64 | loongarch64 |
Микроархитектура | GS464V | GS464V |
Частота (МГц) | 2500 | 2200 |
Ядра | 4 | 16 |
Тех процесс (нм) | 12 | 12 |
TDP (Вт) | 35 | 150 |
Кеш | 64 Кб L1I, 64 Кб L1D, 1 Мб L2 (0,25×4) 16 Мб L3 | 64 Кб L1I, 64 Кб L1D, 1 Мб L2 (0,25×4) 64 Мб L3 (16×4) |
Тип ОЗУ | DDR4–3200 | DDR4–3200 |
GFLOPs | 160 | 560 |
Год | 2021 | 2022 |
Были проведены следующие тесты:
Сразу переходим к результатам, но детали тестов смотрите далее.
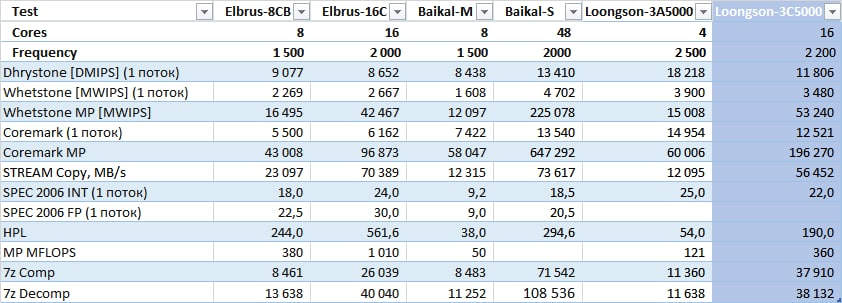
Результаты
Тест | Loongson 3A5000 | Loongson 3С5000 |
Dhrystone [DMIPS] | 18563 | 11806 |
Whetstone [MWIPS] | 3990 | 3480 |
Whetstone MP [MWIPS] | 15001 | 53408 (16 потоков) 106480 (32 потока) |
Linpack 100 [MFLOPS] | 2929 | 2600 |
Scimark 2 [Composite score] | 1487 | 1464 |
Coremark (1T; MT) | 14934; 58797 | 12521; 193271 |
MP MFLOPS | 121167 | 719903 |
7zip (Comp; Decomp; Tot) (MT) | 11360; 11638; 11081 | 37910; 38132; 38021 |
STREAM (Copy; Scale; Add; Triad) [MB/s] | 14593; 14641; 13276; 13719 | 56452; 54762; 57358; 57051 |
SPEC 2006 INT | 25 | 22 |
По результатам можно сделать вывод, что процессор Loongson 3C5000 примерно сравним с процессором Loongson 3A5000 на равных частотах.
Немного об архитектуре LoongArch
Loongson — процессор на основе сильно переработанной RISC архитектуре MIPS64, часть ненужных команд MIPS64 была удалена и добавлено большое число расширений (SIMD, шифрование, бинарная трансляция, виртуализация), всего порядка 2000+ инструкций.
lscpu 3A5000
Architecture: loongarch64
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Model name: Loongson-3A5000
CPU max MHz: 2500.0000
CPU min MHz: 225.0000
BogoMIPS: 4992.00
L1d cache: 64K
L1i cache: 64K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-3lscpu 3C5000
Architecture: loongarch64
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 1
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
CPU family: Loongson-64bit
Model name: Loongson-3C5000
BogoMIPS: 4400.00
L1d cache: 64K
L1i cache: 64K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
NUMA node1 CPU(s): 16-31
Flags: cpucfg lam ual fpu lsx lasx complex crypto lvz lbt_x86 lbt_arm lbt_mipsDhrystone
Dhrystone достаточно древний тест 80х годов, написан на C. Тестирует целочисленную арифметику и работу со строками. Результаты измеряются в Dhrystone/s и DMIPS. (DMIPS = Dhrystone/s делить на 1757).
Вывод теста Dhrystone на 3С5000
Dhrystone Benchmark, Version 2.1 (Language: C or C++)
Optimisation loongarch64 loongarch64 optimized
Register option not selected
10000 runs 0.00 seconds
100000 runs 0.00 seconds
1000000 runs 0.05 seconds
10000000 runs 0.48 seconds
20000000 runs 0.96 seconds
40000000 runs 1.93 seconds
80000000 runs 3.86 seconds
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. 1
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 80000010
Ptr_Glob-> Ptr_Comp: * 0x12eac82a0
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * 0x12eac82a0 same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7 Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 48.21
Dhrystones per Second: 20744304
VAX MIPS rating = 11806.66
Вывод теста Dhrystone на 3A5000
Dhrystone Benchmark, Version 2.1 (Language: C or C++)
Optimisation loongarch64 loongarch64 optimized
Register option not selected
10000 runs 0.00 seconds
100000 runs 0.00 seconds
1000000 runs 0.03 seconds
10000000 runs 0.31 seconds
20000000 runs 0.61 seconds
40000000 runs 1.23 seconds
80000000 runs 2.45 seconds
Final values (* implementation-dependent):
Int_Glob: O.K. 5 Bool_Glob: O.K. 1
Ch_1_Glob: O.K. A Ch_2_Glob: O.K. B
Arr_1_Glob[8]: O.K. 7 Arr_2_Glob8/7: O.K. 80000010
Ptr_Glob-> Ptr_Comp: * 0x1239782a0
Discr: O.K. 0 Enum_Comp: O.K. 2
Int_Comp: O.K. 17 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Next_Ptr_Glob-> Ptr_Comp: * 0x1239782a0 same as above
Discr: O.K. 0 Enum_Comp: O.K. 1
Int_Comp: O.K. 18 Str_Comp: O.K. DHRYSTONE PROGRAM, SOME STRING
Int_1_Loc: O.K. 5 Int_2_Loc: O.K. 13
Int_3_Loc: O.K. 7 Enum_Loc: O.K. 1
Str_1_Loc: O.K. DHRYSTONE PROGRAM, 1'ST STRING
Str_2_Loc: O.K. DHRYSTONE PROGRAM, 2'ND STRING
Nanoseconds one Dhrystone run: 30.66
Dhrystones per Second: 32616185
VAX MIPS rating = 18563.57
Whetstone
Тестирует арифметику с плавающей/фиксированной запятой, математические функции, ветвления, вызовов функций, присваиваний, работы с числами с фиксированной запятой, ветвлений. Результаты измеряются в MMIPS.
Вывод теста Whetstone на 3С5000
32 CPUs Available
##############################################
Multithreading Single Precision Whetstones loongarch64 loongarch64 optimized
Using 32 threads - Mon Dec 12 16:29:23 2022
Calibrate
0.00406 Seconds 1 Passes (x 100)
0.01889 Seconds 5 Passes (x 100)
0.09340 Seconds 25 Passes (x 100)
0.46579 Seconds 125 Passes (x 100)
Use 2683 passes (x 100)
MFLOPS 1 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 595 595 595 595 595 595 595 595 590 574 574 554 554
MFLOPS 2 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 596 595 595 595 595 595 595 595 595 595 595 595 594 586 552 540
IFMOPS 6592 6591 6591 6590 6588 6587 6587 6586 6585 6583 6583 6582 6582 6581 6579 6579 6578 6576 6575 6574 6572 6571 6570 6569 6567 6566 6565 6563 5701 5650 5432 5387
FIXPMOPS 2159 2158 2158 2158 2158 2158 2157 2157 2157 2156 2156 2156 2156 2155 2155 2155 2155 2155 2155 2155 2154 2154 2154 2154 2154 2153 2153 2153 2152 2151 1996 1988
COSMOPS 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 99 98 98 96 96
MFLOPS 3 528 528 528 528 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 527 526 521 520 518 517
EQUMOPS 4396 4395 4395 4395 4395 4395 4394 4394 4394 4394 4394 4393 4393 4393 4393 4393 4393 4393 4393 4392 4392 4392 4392 4392 4392 4392 4392 4391 4390 4365 4359 4335
EXPMOPS 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 56 55 55 55 54 54
millisec 8133 8069 8035 8036 8046 8100 8056 8037 8040 8038 8042 8037 8039 8038 8039 8039 8039 8038 8040 8039 8041 8110 8047 8040 8044 8082 8058 8082 8045 8144 8113 8242
MWIPS 3299 3325 3339 3339 3335 3312 3331 3338 3337 3338 3336 3338 3337 3338 3338 3338 3337 3338 3337 3338 3337 3308 3334 3337 3335 3320 3330 3320 3335 3294 3307 3255
MWIPS MFLOPS MFLOPS MFLOPS Cos Exp Fixpt If Equal
Thread 1 2 3 MOPS MOPS MOPS MOPS MOPS
1 3299 596 552 518 99 56 2159 6592 4359
2 3325 596 596 528 99 56 1996 6590 4395
3 3339 596 596 528 99 56 2158 6591 4396
4 3339 596 596 528 99 56 2158 6591 4395
5 3335 596 596 527 99 55 2158 6588 4394
6 3312 596 596 528 96 56 2156 6587 4395
7 3331 596 596 526 98 56 2158 6587 4393
8 3338 596 596 527 99 56 2156 6585 4395
9 3337 596 596 527 99 56 2158 6586 4394
10 3338 596 596 527 99 56 2154 6583 4395
11 3336 596 596 527 99 56 2157 6582 4393
12 3338 596 596 527 99 56 2155 6582 4390
13 3337 596 596 527 99 56 2157 6583 4393
14 3338 596 595 527 99 56 2155 6579 4394
15 3338 596 596 527 99 56 2157 6581 4393
16 3338 590 596 527 99 56 2155 6578 4394
17 3337 596 596 527 99 56 2156 6579 4393
18 3338 595 595 527 99 56 2155 6575 4394
19 3337 596 596 527 99 56 2156 6576 4392
20 3338 596 595 527 99 56 2154 6574 4393
21 3337 596 595 527 99 56 2155 6571 4392
22 3308 595 595 527 99 54 2154 6572 4393
23 3334 595 596 527 99 56 2155 5650 4392
24 3337 595 595 527 99 56 2154 6570 4393
25 3335 574 595 527 99 56 2154 6569 4392
26 3320 595 595 520 99 56 2153 6566 4365
27 3330 554 586 527 99 56 2153 6567 4392
28 3320 595 595 527 98 55 2155 5432 4392
29 3335 574 595 527 99 56 2153 6565 4392
30 3294 595 594 521 99 54 2151 5701 4392
31 3307 554 540 527 99 56 2152 6563 4391
32 3255 595 595 517 96 55 1988 5387 4335
Total 106480 18929 18949 16840 3152 1774 68644 206382 140462
MWIPS 102841 Based on time for last thread to finish
Results Of Calculations Thread 1
MFLOPS 1 -1.12253940105438232 MFLOPS 2 -1.13133072853088379
IFMOPS 1.00000000000000000 FIXPMOPS 12.00000000000000000
COSMOPS 0.49911013245582581 MFLOPS 3 0.99999982118606567
EQUMOPS 3.00000000000000000 EXPMOPS 0.93536460399627686
Numeric results of the other 31 threads were same as above
End of test Mon Dec 12 16:29:34 2022
##########################################
Single Precision C Whetstone Benchmark loongarch64 loongarch64 optimized, Mon Dec 12 16:28:37 2022
Calibrate
0.00 Seconds 1 Passes (x 100)
0.01 Seconds 5 Passes (x 100)
0.07 Seconds 25 Passes (x 100)
0.36 Seconds 125 Passes (x 100)
1.80 Seconds 625 Passes (x 100)
8.98 Seconds 3125 Passes (x 100)
Use 3480 passes (x 100)
Single Precision C/C++ Whetstone Benchmark
Loop content Result MFLOPS MOPS Seconds
N1 floating point -1.12475013732910156 596.310 0.112
N2 floating point -1.12274742126464844 730.378 0.640
N3 if then else 1.00000000000000000 4398.026 0.082
N4 fixed point 12.00000000000000000 65767.359 0.017
N5 sin,cos etc. 0.49911010265350342 94.350 3.069
N6 floating point 0.99999982118606567 527.722 3.557
N7 assignments 3.00000000000000000 3297.946 0.195
N8 exp,sqrt etc. 0.75110864639282227 55.667 2.326
MWIPS 3480.951 9.997
Вывод теста Whetstone на 3A5000
4 CPUs Available
##############################################
Multithreading Single Precision Whetstones loongarch64 loongarch64 optimized
Using 4 threads - Sun Dec 11 15:28:38 2022
Calibrate
0.00353 Seconds 1 Passes (x 100)
0.01669 Seconds 5 Passes (x 100)
0.08278 Seconds 25 Passes (x 100)
0.41330 Seconds 125 Passes (x 100)
Use 3024 passes (x 100)
MFLOPS 1 678 678 677 676
MFLOPS 2 678 676 676 670
IFMOPS 7495 7494 7493 7489
FIXPMOPS 2082 2082 2081 2080
COSMOPS 112 112 112 111
MFLOPS 3 600 599 599 597
EQUMOPS 4997 4991 4991 4967
EXPMOPS 63 63 63 63
millisec 8055 8068 8047 8083
MWIPS 3754 3748 3758 3741
MWIPS MFLOPS MFLOPS MFLOPS Cos Exp Fixpt If Equal
Thread 1 2 3 MOPS MOPS MOPS MOPS MOPS
1 3754 676 678 599 112 63 2082 7489 4991
2 3748 678 676 599 111 63 2080 7494 4991
3 3758 678 676 600 112 63 2081 7493 4997
4 3741 677 670 597 112 63 2082 7495 4967
Total 15001 2708 2700 2395 446 252 8325 29971 19946
MWIPS 14939 Based on time for last thread to finish
Results Of Calculations Thread 1
MFLOPS 1 -1.13214290142059326 MFLOPS 2 -1.13333344459533691
IFMOPS 1.00000000000000000 FIXPMOPS 12.00000000000000000
COSMOPS 0.50000011920928955 MFLOPS 3 0.99999982118606567
EQUMOPS 3.00000000000000000 EXPMOPS 0.93536460399627686
Numeric results of the other 3 threads were same as above
End of test Sun Dec 11 15:28:48 2022
##########################################
Single Precision C Whetstone Benchmark loongarch64 loongarch64 optimized, Sun Dec 11 15:27:54 2022
Calibrate
0.00 Seconds 1 Passes (x 100)
0.01 Seconds 5 Passes (x 100)
0.06 Seconds 25 Passes (x 100)
0.32 Seconds 125 Passes (x 100)
1.60 Seconds 625 Passes (x 100)
8.01 Seconds 3125 Passes (x 100)
Use 3900 passes (x 100)
Single Precision C/C++ Whetstone Benchmark
Loop content Result MFLOPS MOPS Seconds
N1 floating point -1.12475013732910156 676.608 0.111
N2 floating point -1.12274742126464844 828.798 0.632
N3 if then else 1.00000000000000000 0.000 0.000
N4 fixed point 12.00000000000000000 74584.969 0.016
N5 sin,cos etc. 0.49911010265350342 100.223 3.238
N6 floating point 0.99999982118606567 598.946 3.512
N7 assignments 3.00000000000000000 3742.728 0.193
N8 exp,sqrt etc. 0.75110864639282227 63.179 2.296
MWIPS 3900.650 9.998
Coremark
Современный тест, который должен заменить Dhrystone и Whetstone. Написан на C. Считает различные массивы, матрицы, сортировка массивов и т. д. Предназначался для запуска на всём: от микроконтроллеров до мощных процессоров.
Вывод однопоточного теста Coremark на 3С5000
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 16048
Total time (secs): 16.048000
Iterations/Sec : 12462.612164
Iterations : 200000
Compiler version : GCC8.3.0 20190222 (Loongson 8.3.0-31 vec)
Compiler flags : -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x4983
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 12462.612164 / GCC8.3.0 20190222 (Loongson 8.3.0-31 vec) -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt / Heap
Вывод многопоточного теста Coremark на 3С5000
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 16557
Total time (secs): 16.557000
Iterations/Sec : 193271.727970
Iterations : 3200000
Compiler version : GCC8.3.0 20190222 (Loongson 8.3.0-31 vec)
Compiler flags : -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt
Parallel Fork : 16
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[1]crclist : 0xe714
[2]crclist : 0xe714
[3]crclist : 0xe714
[4]crclist : 0xe714
[5]crclist : 0xe714
[6]crclist : 0xe714
[7]crclist : 0xe714
[8]crclist : 0xe714
[9]crclist : 0xe714
[10]crclist : 0xe714
[11]crclist : 0xe714
[12]crclist : 0xe714
[13]crclist : 0xe714
[14]crclist : 0xe714
[15]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[1]crcmatrix : 0x1fd7
[2]crcmatrix : 0x1fd7
[3]crcmatrix : 0x1fd7
[4]crcmatrix : 0x1fd7
[5]crcmatrix : 0x1fd7
[6]crcmatrix : 0x1fd7
[7]crcmatrix : 0x1fd7
[8]crcmatrix : 0x1fd7
[9]crcmatrix : 0x1fd7
[10]crcmatrix : 0x1fd7
[11]crcmatrix : 0x1fd7
[12]crcmatrix : 0x1fd7
[13]crcmatrix : 0x1fd7
[14]crcmatrix : 0x1fd7
[15]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[1]crcstate : 0x8e3a
[2]crcstate : 0x8e3a
[3]crcstate : 0x8e3a
[4]crcstate : 0x8e3a
[5]crcstate : 0x8e3a
[6]crcstate : 0x8e3a
[7]crcstate : 0x8e3a
[8]crcstate : 0x8e3a
[9]crcstate : 0x8e3a
[10]crcstate : 0x8e3a
[11]crcstate : 0x8e3a
[12]crcstate : 0x8e3a
[13]crcstate : 0x8e3a
[14]crcstate : 0x8e3a
[15]crcstate : 0x8e3a
[0]crcfinal : 0x4983
[1]crcfinal : 0x4983
[2]crcfinal : 0x4983
[3]crcfinal : 0x4983
[4]crcfinal : 0x4983
[5]crcfinal : 0x4983
[6]crcfinal : 0x4983
[7]crcfinal : 0x4983
[8]crcfinal : 0x4983
[9]crcfinal : 0x4983
[10]crcfinal : 0x4983
[11]crcfinal : 0x4983
[12]crcfinal : 0x4983
[13]crcfinal : 0x4983
[14]crcfinal : 0x4983
[15]crcfinal : 0x4983
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 193271.727970 / GCC8.3.0 20190222 (Loongson 8.3.0-31 vec) -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt / Heap / 16:Fork
Вывод однопоточного теста Coremark на 3A5000
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 13392
Total time (secs): 13.392000
Iterations/Sec : 14934.289128
Iterations : 200000
Compiler version : GCC8.3.0
Compiler flags : -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x4983
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 14934.289128 / GCC8.3.0 -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt / Heap
Вывод многопоточного теста Coremark на 3A5000
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 13646
Total time (secs): 13.646000
Iterations/Sec : 58625.238165
Iterations : 800000
Compiler version : GCC8.3.0
Compiler flags : -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt
Parallel Fork : 4
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[1]crclist : 0xe714
[2]crclist : 0xe714
[3]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[1]crcmatrix : 0x1fd7
[2]crcmatrix : 0x1fd7
[3]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[1]crcstate : 0x8e3a
[2]crcstate : 0x8e3a
[3]crcstate : 0x8e3a
[0]crcfinal : 0x4983
[1]crcfinal : 0x4983
[2]crcfinal : 0x4983
[3]crcfinal : 0x4983
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 58625.238165 / GCC8.3.0 -Ofast -DPERFORMANCE_RUN=1 -DUSE_FORK=1 -lrt / Heap / 4:Fork
MP MFLOPS
Выполняет операции с плавающей запятой на векторах.
Вывод теста MP-MFLOPS на 3С5000
32 CPUs Available
##############################################
64 Bit MP SSE MFLOPS Benchmark 1, 32 Threads, Mon Dec 12 16:22:54 2022
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 102400 2 80000 0.070316 233004 0.410898 Yes
Data in & out 1024000 2 8000 0.065234 251158 0.802311 Yes
Data in & out 10240000 2 800 0.213911 76593 0.976486 Yes
Data in & out 102400 8 80000 0.151069 433816 0.558756 Yes
Data in & out 1024000 8 8000 0.116899 560618 0.876281 Yes
Data in & out 10240000 8 800 0.199468 328554 0.985828 Yes
Data in & out 102400 32 80000 0.372965 702865 0.353359 Yes
Data in & out 1024000 32 8000 0.431096 608087 0.709574 Yes
Data in & out 10240000 32 800 0.364138 719903 0.962629 Yes
End of test Mon Dec 12 16:22:56 2022
Вывод теста MP-MFLOPS на 3A5000
4 CPUs Available
##############################################
64 Bit MP SSE MFLOPS Benchmark 1, 4 Threads, Sun Dec 11 15:22:37 2022
Test 4 Byte Ops/ Repeat Seconds MFLOPS First All
Words Word Passes Results Same
Data in & out 102400 2 10000 0.086061 23797 0.764063 Yes
Data in & out 1024000 2 1000 0.096334 21259 0.970753 Yes
Data in & out 10240000 2 100 0.597981 3425 0.997008 Yes
Data in & out 102400 8 10000 0.068533 119533 0.850919 Yes
Data in & out 1024000 8 1000 0.069136 118490 0.982347 Yes
Data in & out 10240000 8 100 0.593080 13813 0.998205 Yes
Data in & out 102400 32 10000 0.304694 107544 0.660093 Yes
Data in & out 1024000 32 1000 0.304863 107484 0.953624 Yes
Data in & out 10240000 32 100 0.620384 52819 0.995219 Yes
End of test Sun Dec 11 15:22:40 2022
7zip
Встроенный тест архиватора 7z.
Запускается так:
7z bВывод теста 7z на 3A5000
7-Zip (a) 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=zh_CN.UTF-8,Utf16=on,HugeFiles=on,64 bits,4 CPUs LE)
LE
CPU Freq: 64000000 - - - - - - - -
RAM size: 16165 MB, # CPU hardware threads: 4
RAM usage: 882 MB, # Benchmark threads: 4
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 11279 327 3352 10973 | 130124 396 2803 11102
23: 10681 325 3346 10883 | 127682 393 2810 11048
24: 11183 353 3406 12025 | 126626 395 2815 11116
25: 11099 360 3525 12673 | 124248 394 2805 11058
---------------------------------- | ------------------------------
Avr: 341 3407 11638 | 395 2808 11081
Tot: 368 3108 11360Вывод теста 7z на 3С5000
# 7z b
7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,32 CPUs LE)
LE
CPU Freq: 64000000 - - - - - - - -
RAM size: 129704 MB, # CPU hardware threads: 32
RAM usage: 7060 MB, # Benchmark threads: 32
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 62370 2796 2170 60674 | 878738 3138 2388 74938
23: 60911 2793 2222 62062 | 861051 3149 2366 74508
24: 59913 2867 2247 64419 | 832658 3112 2349 73085
25: 61317 2941 2380 70010 | 815385 3087 2351 72564
---------------------------------- | ------------------------------
Avr: 2849 2255 64291 | 3122 2363 73774
Tot: 2985 2309 69032
# 7z b -mmt16
7-Zip 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,32 CPUs LE)
LE
CPU Freq: - - - - - - - - -
RAM size: 129704 MB, # CPU hardware threads: 32
RAM usage: 3530 MB, # Benchmark threads: 16
Compressing | Decompressing
Dict Speed Usage R/U Rating | Speed Usage R/U Rating
KiB/s % MIPS MIPS | KiB/s % MIPS MIPS
22: 36575 1439 2473 35580 | 450711 1594 2412 38441
23: 36638 1469 2540 37330 | 443639 1589 2416 38384
24: 35836 1519 2537 38532 | 434708 1591 2399 38157
25: 35206 1523 2640 40198 | 421884 1573 2387 37546
---------------------------------- | ------------------------------
Avr: 1487 2548 37910 | 1587 2403 38132
Tot: 1537 2476 38021STREAM
Тест производительности ОЗУ.
Вывод теста STREAM на 3A5000
Function Best Rate MB/s Avg time Min time Max time
Copy: 16748.3 0.009969 0.009553 0.010576
Scale: 18735.0 0.009437 0.008540 0.010660
Add: 16333.2 0.015492 0.014694 0.016449
Triad: 17796.0 0.014789 0.013486 0.015294Вывод теста STREAM на 3C5000
Function Best Rate MB/s Avg time Min time Max time
Copy: 53623.8 0.024431 0.023870 0.025548
Scale: 49980.5 0.026965 0.025610 0.028581
Add: 48869.8 0.041190 0.039288 0.052376
Triad: 49102.3 0.040250 0.039102 0.043391Версия компилятора, ядра Linux
Ядро Linux на 3A5000:
Linux 4.19.167-rc5.lnd.1-loongson-3 #1 SMP Sat Apr 17 07:32:32 UTC 2021 loongarch64 loongarch64 loongarch64 GNU/LinuxВерсия компилятора на 3A5000:
gcc version 8.3.0 (Debian 8.3.0-6.lnd.vec.20).
Ядро Linux на 3C5000:
Linux 4.19.0-19-loongson-3 #1 SMP pkg_lnd10_4.19.190-7.7 Fri Nov 25 10:17:52 UTC 2022 loongarch64Версия компилятора на 3C5000:
cc (Loongnix 8.3.0-6.lnd.vec.34) 8.3.0
Заключение
Процессоры Loongson очень активно развиваются и догоняют по производительности процессоры мировых производителей на других архитектурах, имеют отличную документацию и набор портированного софта.
Другие результаты для сравнения: